
文章目錄
- 一、背景
- 二、方法
- 2.1 模型結構
- 2.2 訓練 pipeline
- 三、模型設置
- 3.1 模型結構
- 3.2 訓練數據
- 3.3 訓練策略
- 3.4 評測 benchmark
- 四、效果
論文:TinyLLaVA: A Framework of Small-scale Large Multimodal Models
代碼:https://github.com/TinyLLaVA/TinyLLaVA_Factory
貢獻:
- 證明了使用小型 LLM 的情況下,只要模塊組合方式和訓練數據質量高,也能取得和大型 LLM 相當的效果
- 最好的 TinyLLaVA-3.1B (TinyLLaVA-share-Sig-Phi) 能夠取得和 LLaVA-1.5、QWen-VL 等 7b 大小的模型相當的效果
一、背景
雖然不斷擴大模型的容量能夠提升模型對很多不同任務的解決能力,但訓練龐大的模型需要很多的資源,如 Flamingo 為 80b,PaLM-E 為 562b,所以現在有很多 LLM 的模型也在降低模型參數量,降低到 7B 或 3B,但性能沒有下降很多
所以 LMM 也出現了類似的方向,如 OpenFlamingo 和 LLaVA 所做的模型是從 3b 到 15b,這樣也能提升模型的效率和可部署性
基于此,本文作者提出了 TinyLLaVA:
- 一個利用小型 LLM 實現大型 LMM 的模型框架,框架由視覺編碼器、小型 LLM 解碼器和中間連接器組成
- 作者探究了不同的 vision encoder、connector、language model、training data、train recipes 組合起來的效果
- 證明了通過更好的訓練組合方式和更高質量的數據,使用較小的 LMM 就能實現較大模型相當的性能
- 小型 LLM:Phi-2 [33], StableLM-2 [47], and TinyLlama [59]
- vision encoder: CLIP [44], and SigLIP [58]
- 最好的 TinyLLaVA-3.1B 能夠取得和 LLaVA-1.5、QWen-VL 等 7b 大小的模型相當的效果
小型的 LLM 模型:
- Phi-2
- TinyLlama
- StableLM-2
一些大型的 LMM 模型:
- Flamingo
- BLIP
- LLava
- InstructBLIP
一些小型的 LMM 模型:
- TinyGPT-V:使用 Phi
- LLava-Phi:使用 LLaVA-1.5 的結構,將 LLM 換成了 Phi-2
- MoE-LLaVA:給 LLaVA 引入了 Mixture-ofExperts [23] ,使用更少的參數量取得了和 LLaVA-1.5 相當的性能
本文作者會詳細的分析如何選擇模型、訓練策略、數據等方面,從而構建一個高水準的小型 LMM
二、方法
TinyLLaVA 的結構是根據 LLaVA 衍生而來的
2.1 模型結構
模型結構如圖 2 所示,由下面幾個部分組成:
- small-scale LLM
- vision encoder
- connector
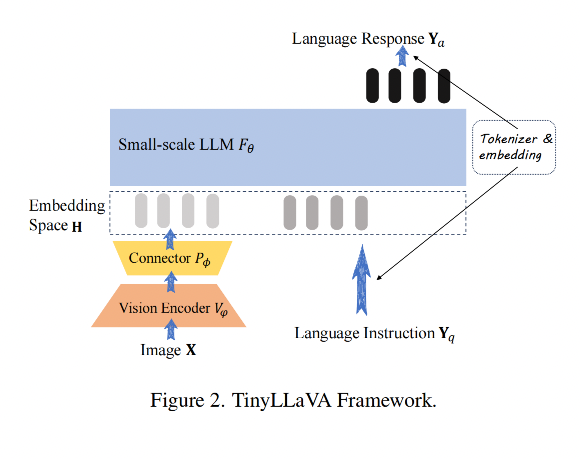
1、small-scale LLM
small-scale LLM 的輸入是一系列的向量 { h i } i = 0 N ? 1 \{h_i\}_{i=0}^{N-1} {hi?}i=0N?1?,該向量是長度為 N 且維度為 d 的 text embedding,輸出是下一個預測結果 { h i } i = 1 N \{h_i\}_{i=1}^{N} {hi?}i=1N?
一般 LLM 模型會綁定一個 tokenizer,用于將 input sequence { y i } i = 0 N ? 1 \{y_i\}_{i=0}^{N-1} {yi?}i=0N?1? 映射到 embedding space
2、Vision encoder
vision encoder 的輸入是 image X,輸出是一系列 visual patch features
3、Connector
連接器的作用是將 visual patch 特征映射到 text embedding 空間,將圖像特征和文本特征連接起來
2.2 訓練 pipeline
訓練的數據是 image-text pairs ( X , Y ) (X, Y) (X,Y),訓練分為預訓練和微調兩個階段
text sequence Y 是由一系列多輪對話組成,即 Y = Y q 1 , Y a 1 , . . . , Y q T , Y a T Y={Y_q^1, Y_a^1, ... , Y_q^T, Y_a^T} Y=Yq1?,Ya1?,...,YqT?,YaT?:
- 其中 T 是總共的輪數
- Y q T Y_q^T YqT? 是人類指令
- Y a T Y_a^T YaT? 是機器響應
1、預訓練來實現特征對齊
本階段的目標是為了在 embedding 空間更好的對齊 vision 和 text information
訓練使用的是 image-caption 形式的數據,即 ( X , Y a ) (X, Y_a) (X,Ya?),X 是圖像,Y 是 caption 描述
給定目標響應 Y a = { y i } i = 1 N a Y_a=\{y_i\}_{i=1}^{N_a} Ya?={yi?}i=1Na??,其中 N a N_a Na? 是 length,作者通過下面的方式來計算生成 Y a Y_a Ya? 的概率:
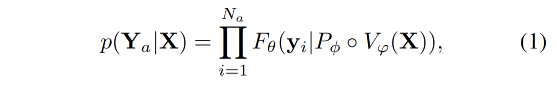
目標函數就變成了最大化上述概率的 log 似然:
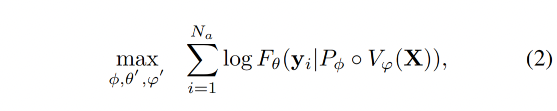
注意:作者在預訓練的時候也會讓 LLM 和 vision encoder 的部分參數參與訓練,因為考慮到使用小型的 LLM 如果只訓練 connector 的話可能訓練不好
2、有監督微調
使用圖像-文本對(X, Y)進行多輪對話的原始形式。
A 表示屬于 assistant responses 的所有 token 集合, A = { y ∣ y ∈ Y a t , f o r a n y t?=?1,?...,?T } A = \{y | y ∈ Y_a^t, for\ any\ \text{t = 1, ..., T}\} A={y∣y∈Yat?,for?any?t?=?1,?...,?T}, Y a t Y_a^t Yat? 表示在多輪對話中第 t 輪中助手的響應。A 是一個集合,包含了所有屬于助手響應的標記,即從每一輪對話中提取出的助手生成的所有標記。
假設有一個多輪對話,共有三輪(T = 3),每一輪對話中助手的響應分別如下:
- 第一輪(t=1):助手響應 “Hello, how can I help you?” 對應的標記集合可能是 {“Hello”, “,”, “how”, “can”, “I”, “help”, “you”, “?”}
- 第二輪(t=2):助手響應 “Sure, I can do that.” 對應的標記集合可能是 {“Sure”, “,”, “I”, “can”, “do”, “that”, “.”}
- 第三輪(t=3):助手響應 “Please wait a moment.” 對應的標記集合可能是 {“Please”, “wait”, “a”, “moment”, “.”}
那么,集合 A 將包含所有這些標記,即:
A = {“Hello”, “,”, “how”, “can”, “I”, “help”, “you”, “?”,
“Sure”, “,”, “I”, “can”, “do”, “that”, “.”,
“Please”, “wait”, “a”, “moment”}
在公式 (3) 中,這些標記用于計算對數似然函數,以優化模型參數,從而提高助手生成響應的準確性和相關性。
訓練的目標函數:最大化 assistant responses 的對數似然性來逐步進行訓練,作為監督微調期間的訓練目標。
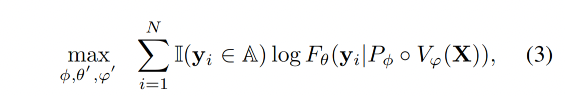
- N 是文本序列 Y 的長度,也就是一個句子中 token 的總數。
- 當 y i ∈ A y_i \in A yi?∈A 時, I ( y i ∈ A ) = 1 \mathbb{I}(y_i \in A)=1 I(yi?∈A)=1 ,否則為0。這里 I ( y i ∈ A ) \mathbb{I}(y_i \in A) I(yi?∈A) 是一個指示函數,用來判斷當前標記 y_i 是否屬于助手響應。如果是,則該項為1,否則為0。
在監督微調階段,也允許 LLM 和視覺編碼器部分參數微調。
三、模型設置
3.1 模型結構
1、小型 LLM
表 1 中展示了 LLM 的選擇,作者選擇了 3 個相對小型的模型,且這幾個模型基本涵蓋了不同小型模型的范圍:
- TinyLlama (1.1B) [59]
- StableLM-2-1.6B(1.6B) [47]
- Phi-2(2.7B) [33]

結論:
- Phi-2 對不同的 benchmark 表現都比較好,可能是由于其參數量更大
- Phi-2 variants 在 SQA-I 上超過了其他 variants,可能是由于其使用了 text-book 數據進行了訓練
- TinyLLaVA 在 POPE 上的表現比較好
- 證明:大的 language 模型在 base setting 時的表現更好
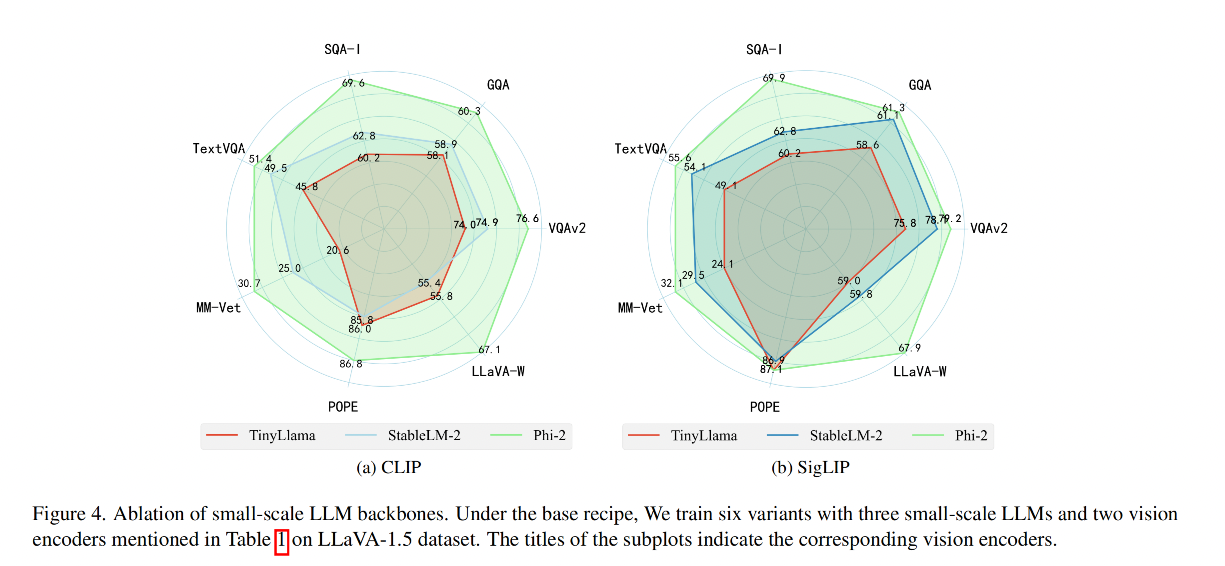
2、Vision encoder
通過對比發現 SigLIP 和小型 LLM 的結合能夠生成比 CLIP 更好的效果
效果:
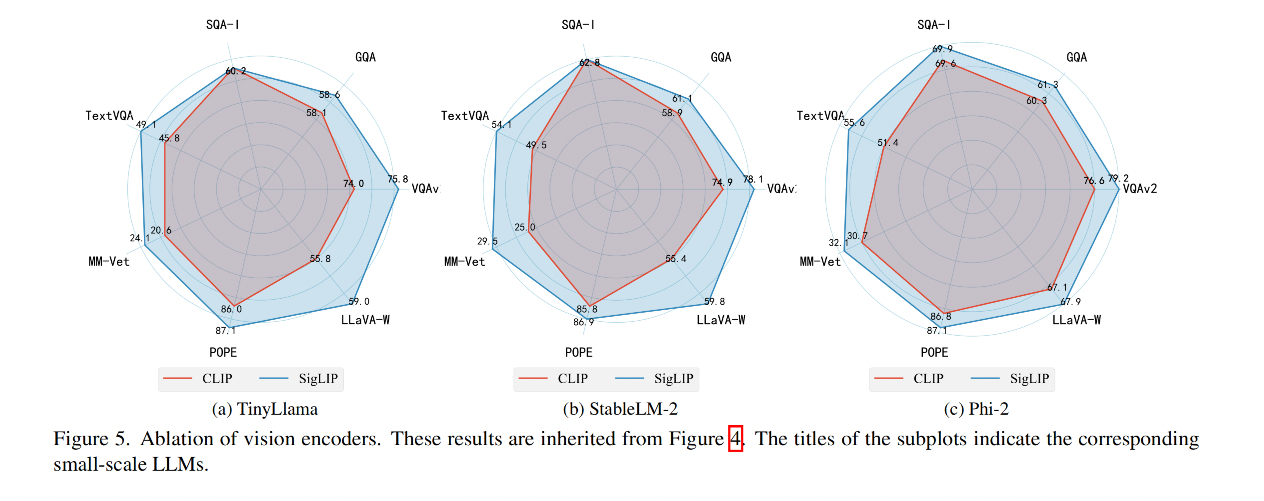
結論:
- 使用SigLIP [58]的模型變體相比于使用CLIP [44]的模型變體,在模型性能上有顯著提升,這在TextVQA [45]和LLaVA-W [38]基準測試中尤為明顯
- SigLIP 變體具有更高的輸入分辨率(384 vs. 336)和更多的視覺令牌(729 vs. 576),與CLIP相比。這些因素可能使SigLIP包含了更多有利于進行細粒度圖像理解的視覺信息。
3、Connector
作者繼承了 LLaVA-v1.5 中使用 MLP+GELU 的思想,同樣了使用了 resampler 進行了兩者效果的對比
效果對比:

結論:
- MLP 效果更好
總結:
- 經過上述對比,作者最終使用了如下搭配
- 較大的 LLM
- SigLIP(有更大的輸入分辨率和更多的 visual token)
- MLP
3.2 訓練數據
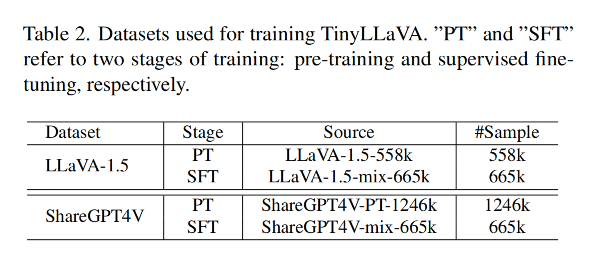
作者選擇了兩個不同的訓練數據,分別來自 LLaVA-1.5 [37] 和 ShareGPT4V [7],來驗證不同數據質量對 LMM 的影響
- LLaVA-1.5-PT: 包含 558k 的描述文字
- LLaVA-1.5-SFT 包含總計 665k 的視覺指令調優對話,這些對話是學術導向的視覺問答(VQA)[17, 22, 28, 45] 樣本、來自 LLaVA-Instruct [38] 和 ShareGPT [20] 的指令調優數據的組合。
- ShareGPT4V-PT [7] 包含由 Share-Captioner [7] 生成的 1246k 描述文字
- ShareGPT4V-SFT 數據集與 LLaVA-1.5-SFT [37] 類似,不同之處在于 LLaVA-1.5-SFT 中的 23K 詳細描述數據被隨機抽取自 100K ShareGPT4V 數據中的詳細描述替換。
效果對比:
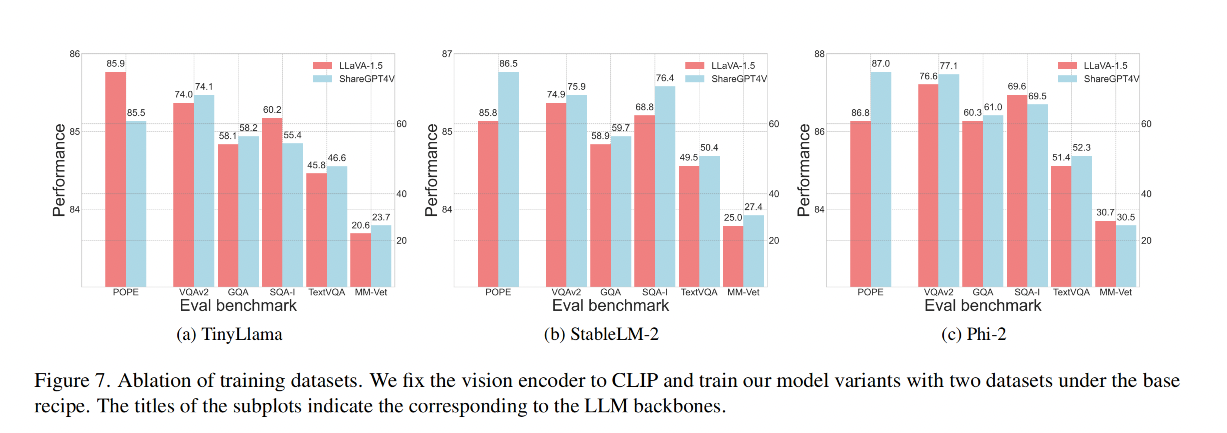
結論:使用 ShareGPT4V [7]
- 當在更大規模和更多樣化的ShareGPT4V [7]數據集上進行預訓練時,使用TinyLlama [59]作為小規模LLM的模型變體在評估性能上相比于LLaVA-1.5數據集[37]有整體提升。然而,在POPE [55]中觀察到明顯的性能下降
- 使用 ShareGPT4V [7] 時 StableLM-2和Phi-2的模型變體表現出全面的性能提升。
- 可能是由于TinyLlama [59]的參數不足,導致其無法充分適應大量數據,從而導致部分知識退化和更多幻覺生成。
這里是常見數據集的描述:
Here, we provide a brief overview of the key aspects each benchmark focuses on when assessing model capabilities.
? VQAv2 [17] contains image-question-answer tuples with images collected from the COCO dataset [36]. The test set of
VQAv2 evaluates models’ capabilities in terms of visual recognition, visual grounding, spatial reasoning as well as language
understanding.
? GQA [22] collected its data according to the scene graph structure provided by the Visual Genome [28] dataset. The test
set of GQA extensively evaluates models’ capabilities in terms of visual and compositional reasoning.
? TextVQA [45] is an image question answering dataset that contains images with texts. The test set of TextVQA requires
models to not only recognize textual information in the given images but also to reason over them.
? ScienceQA-IMG [40] is a subset of the ScienceQA [40] benchmark that contains images. The benchmark contains
scientific questions and answers collected from lectures and textbooks. During the evaluation, the model is prompted with
questions, choices, and relevant contexts, and is asked to predict the correct answers. This benchmark mainly evaluates models’
capabilities in reasoning with respect to scientific knowledge.
? POPE [55] benchmark is designed to evaluate the hallucination issues in LMMs. Its test samples incorporate positive
and negative objects (non-existent objects), which require the model to not only recognize positive samples accurately but
also correctly identify negative samples (measuring hallucination). It effectively assesses the model’s ability to handle
hallucinations.
? MM-Vet [56] is a comprehensive benchmark that evaluates LMMs on complicated multimodal tasks. MM-Vet uses
GPT-4 [1] to evaluate the outputs generated by LMMs. Its test set evaluates LMMs on six dimensions: visual recognition,
spatial reason- ing, common knowledge deduction, language generation, visual math reasoning, and OCR recognition.
? LLaVA-W benchmark includes 24 images and 60 questions, which are collected to evaluate LMMs’ capabilities in
challenging tasks and generalizability in novel domains [38].
? MME is a LMM evaluation benchmark that measures both perception and cognition abilities on a total of 14 subtasks [16].
This benchmark is automatically evaluated by GPT-4 [1].
? MMBench is a LMM evaluation benchmark that comprehensively assess models’ capabilities across 20 dimensions [39].
This benchmark is automatically evaluated by ChatGPT [42].
3.3 訓練策略
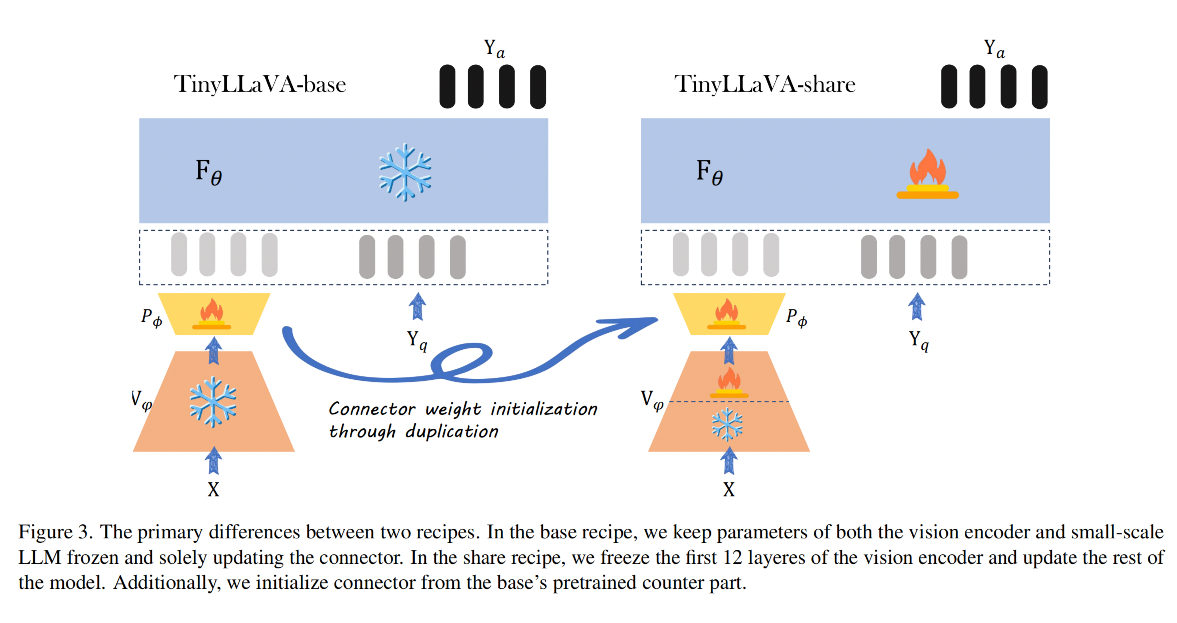
作者探究了兩個不同的訓練策略,即 llava-1.5 和 shareGPT4V,對比如圖 3
-
左側方法來源于 LLaVA-v1.5,命名為 base,作為 base 策略
- 在 pretrain 階段中,只更新 connector 的參數, LLM 和 vision encoder 都凍結,訓練 1 epoch,學習率為 1e-3,batch size 為 256
- 在 SFT 階段中,凍結 vision encoder,更新其他兩個模塊,訓練 1 epoch,學習率為 2e-5,batch size 為 128
-
右側方法來源于 ShareGPT4V[7],命名為 share
- 在 pretrain 階段中,作者使用 base 的 pretrain 階段訓練的 connector 來初始化這里的 connector,凍結 vision encoder 的前 12 層,更新其他層的參數,學習率為 2e-5,batch size 為 256
- 在 SFT 階段中,和 base 的一樣
效果對比:
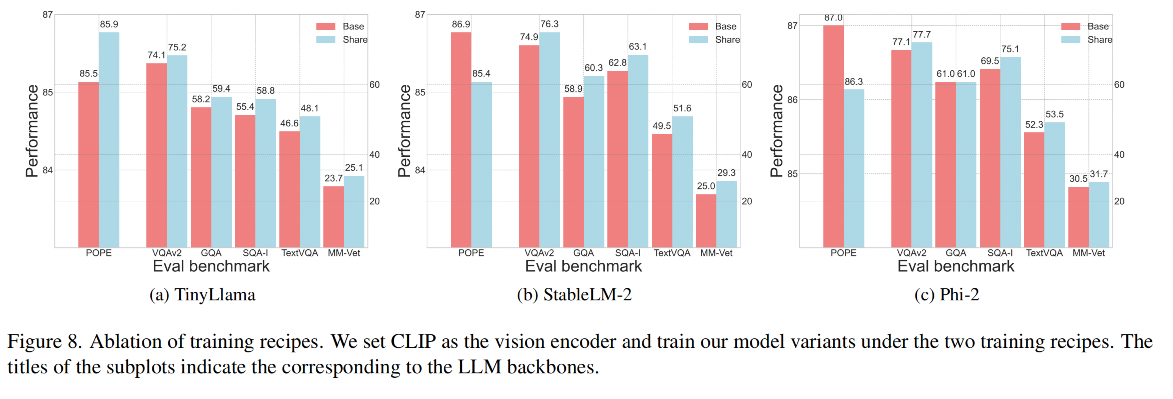
結論:
- 當模型在更大規模和更多樣化的ShareGPT4V數據集[7]上進行預訓練時,使用 share 可以顯著提升所有變體的性能。也就是當使用小規模LLM時,微調視覺編碼器可以提升性能,這與[27]中的結果相反,該結果指出在使用標準LLM時微調視覺編碼器會顯著降低性能。作者推測,是否微調視覺編碼器能夠提升性能取決于所伴隨的LLM的規模和訓練數據的規模,
- 故此使用 share 的模式微調 vision encoder 效果更好
總結:tinyllava 需要使用 share 方式,其他兩種更大的模型使用 share 時會引入幻覺
-
使用 share 策略時,StableLM-2 和 Phi-2 在其他 benchmark 上有性能提升,但在 pope 上性能下降了很多(說明有更多的幻覺),share 和 base 的差別就在于 pretrain 階段 share 訓練的參數更多,所以這肯定是導致這一現象的根本原因,
-
所以作者認為,使用較小 LLM 的模型變體在預訓練階段可能需要更多可訓練參數來很好地適應更大的數據集。因此,擁有更多可訓練參數使得使用 TinyLlama 的模型變體能夠在ShareGPT4V上取得更好的結果。然而,在預訓練期間使用更多可訓練參數對于較大的模型來說可能并不完全有利。例如,雖然使用StableLM-2和Phi-2的模型變體總體上表現出性能提升,但也引入了處理幻覺方面的更差表現。
-
結論1:在更大規模和更多樣化的數據上訓練模型變體使它們能夠實現整體更好的性能。
-
結論2:使用較小LLM的模型變體可能需要更多可訓練參數來減少幻覺
-
結論3:對于較大LLM的變體,使用更多可訓練參數反而會導致更多幻覺。
3.4 評測 benchmark
- four image questionanswering benchmarks: VQA-v2 [17], GQA [22], ScienceQA-IMG [40], TextVQA [45],
- five comprehensive benchmark: POPE [55], MM-Vet [56], LLaVAW (LLaVA-Bench-in-the-Wild) [38], MME [16] , MMBench [39].
四、效果
模型命名規則:TinyLLaVA-{recipe name}-{vision encoder}-{languagemodel}.
例如:TinyLLaVA-base-C-TL 就是使用 base recipe, CLIP,TinyLlama
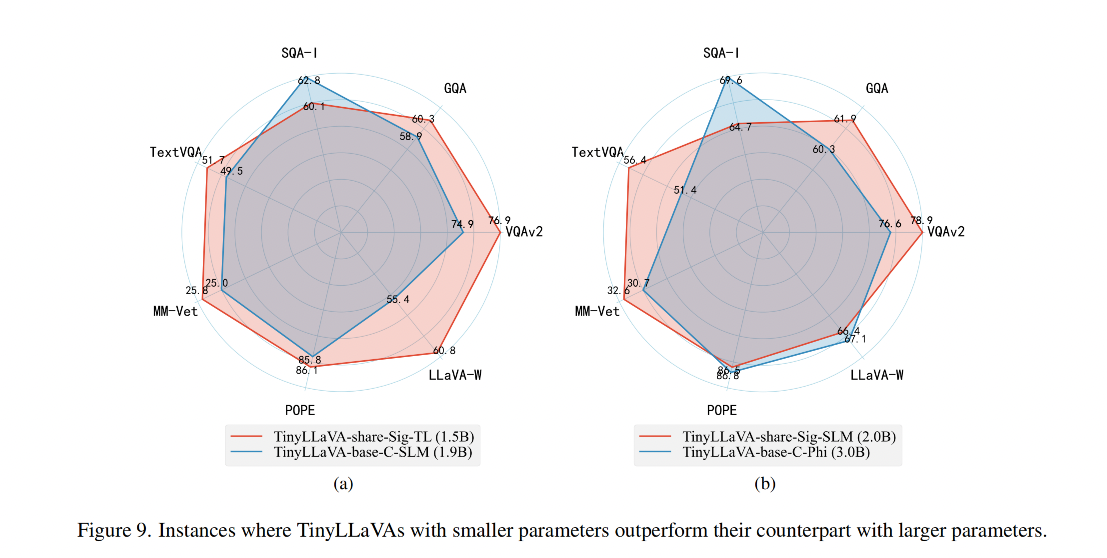
TinyLLaVA 的所有變體:
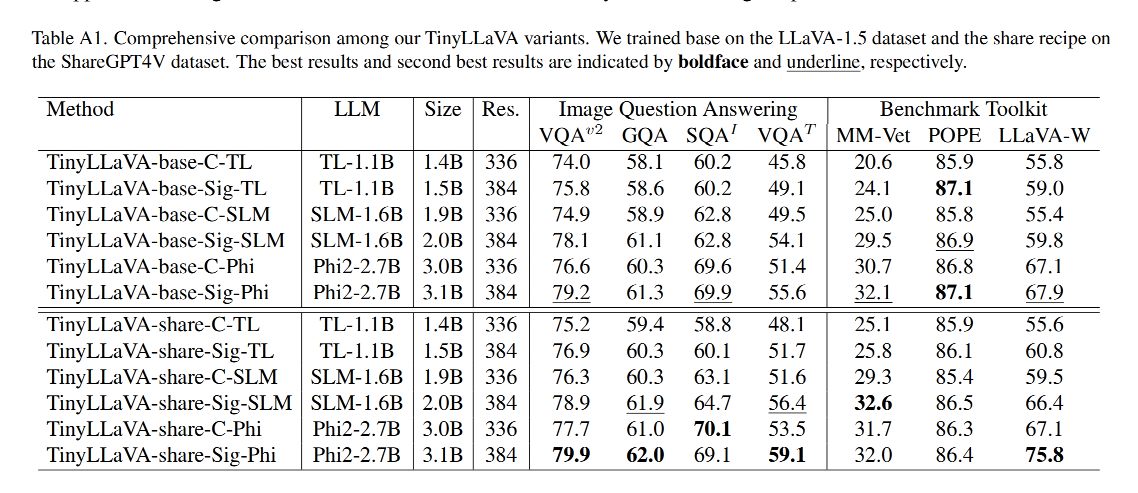
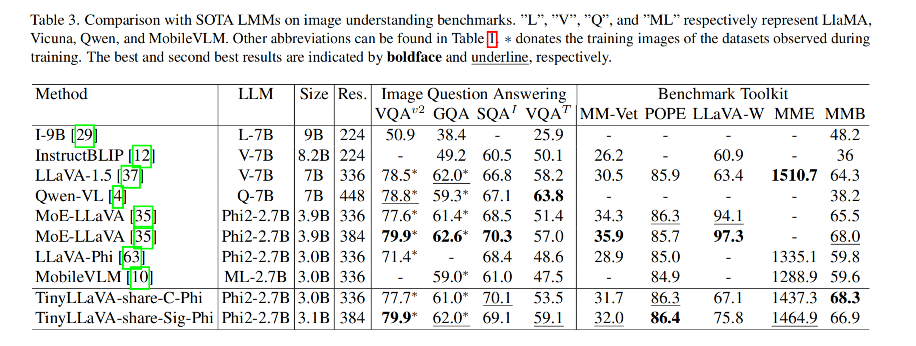
和其他模型的對比:
作者提出的最好的模型是 TinyLLaVA-3.1B (TinyLLaVA-share-Sig-Phi),和 7B 大小的 LLaVA-1.5 和 Qwen-VL 都取得了相當的效果
TinyLLaVA-3.1B 的一些可視化:








: 從“LangChain的六大組件”看“個人職業規劃”)





——Harmonyos通用事件之觸摸事件)






