在高可用的三大架構設計(基于數據層的高可用、基于業務層的高可用,以及融合的高可用架構設計)中。僅僅解決了業務連續性的問題:也就是當服務器因為各種原因,發生宕機,導致MySQL 數據庫不可用之后,快速恢復業務。但對有狀態的數據庫服務來說,在一些核心業務系統中,比如電商、金融等,還要保證數據一致性。
這里的“數據一致性”是指在任何災難場景下,一條數據都不允許丟失(一般也把這種數據復制方式叫作“強同步”)。
本篇文章我們就來看一看,怎么在這種最高要求(數據一致性)的業務場景中,設計 MySQL 的高可用架構。
一、復制類型的選擇
在前面的文章中,我們已經知道銀行、保險、證券等核心業務,需要嚴格保障數據一致性。那么要想實現數據的強同步,在進行復制的配置時,就要使用無損半同步復制模式。
在 MySQL 內部就是要把參數 rpl_semi_sync_master_wait_point 設置成 AFTER_SYNC 。
但是在高可用設計時,當數據庫 FAILOVER 完后,有時還要對原來的主機做額外的操作,這樣才能保證主從數據的完全一致性。
我們來看這樣一張圖:  從圖中可以看到,即使啟用無損半同步復制,依然存在當發生主機宕機時,最后一組事務沒有上傳到從機的可能。圖中宕機的主機已經提交事務到 101,但是從機只接收到事務 100。如果這個時候 Failover,從機提升為主機,那么這時:
從圖中可以看到,即使啟用無損半同步復制,依然存在當發生主機宕機時,最后一組事務沒有上傳到從機的可能。圖中宕機的主機已經提交事務到 101,但是從機只接收到事務 100。如果這個時候 Failover,從機提升為主機,那么這時: 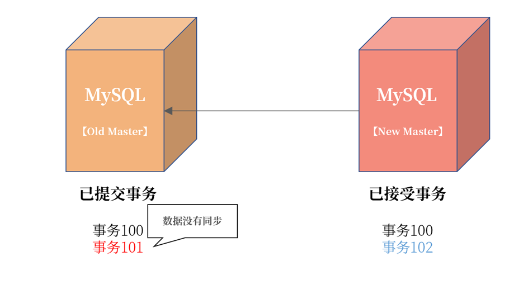 可以看到當主從切換完成后,新的 MySQL 開始寫入新的事務102,如果這時老的主服務器從宕機中恢復,則這時事務 101 不會同步
可以看到當主從切換完成后,新的 MySQL 開始寫入新的事務102,如果這時老的主服務器從宕機中恢復,則這時事務 101 不會同步



















)