作者:someone鏈接:https://www.zhihu.com/question/304259901/answer/3455648666來源。
1. AMBA CHI簡介
一致性總線接口(CHI)是AXI一致性擴展(ACE)協議的演進。它是Arm的AMBA總線的一部分。AMBA是一種免費可用、全球采用的開放標準,用于SoC中功能模塊的連接和管理。它有助于一次性正確開發具有大量控制器和外設的多處理器設計。CHI適用于需要一致性的各種應用,包括移動、網絡、汽車和數據中心。AMBA CHI旨在維護組件數量和流量不斷增長的系統中的性能。
2. CHI介紹
CHI旨在實現可擴展性,用于構建小型、中型或大型系統。這些系統使用多個組件,范圍從處理器集群、圖形處理器和內存控制器,到 I/O 橋、PCIe子系統和互聯本身。
CHI 網絡拓撲CHI 定義了CHI網絡中的不同組件,但沒有定義用于連接這些組件的拓撲。這種拓撲靈活性允許用戶根據性能、功耗和面積要求驅動組件連接。
拓撲有:
? 環形拓撲(ring)。在環中,每個組件直接連接到另外兩個組件,形成一個所有組件都可以相互通信的環。這種拓撲的缺點是延遲隨環中組件數量的增加而線性增加。這是因為事務必須遍歷環,直到到達目的地。ring拓撲最適合中等規模的系統。
? 網格拓撲(mesh)。與環相比,mesh包含更多事務到達目的地的路徑,因此減少了事務的傳輸時間。這提供了更高的系統帶寬,但是占用了更多的面積。mesh拓撲最適合大規模系統。
? 交叉開關(crossbar)。這種拓撲允許每個節點連接到每個可能的節點。這種設計提供了最佳性能,因為每個組件都與需要通信的組件直接連接。這種拓撲的缺點是連接所有組件的成本。這是因為隨著每個附加組件,系統所需的導線數量可能會顯著增加。因此crossbar最適合小型系統。下圖展示了可以實現 CHI 協議的不同類型的拓撲:
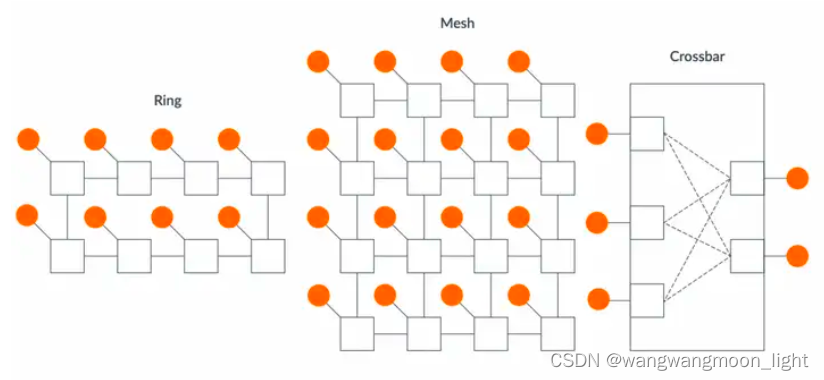
圖中,圓圈表示網絡中的請求者和從組件。方形表示用于在請求者和從端之間路由事務的中間組件。
CHI協議迭代
目前CHI協議有六個版本:A到F。本導論描述A到C的版本以及它們的主要差異。CHI-A是CHI協議的第一個版本。它提供了一個傳輸層,具有減少擁塞的功能。CHI-A 描述了CHI的基本行為。包括:
新通道、CHI 術語和組件命名的定義
請求、監聽過濾器和緩存狀態轉換的示例
事務排序、獨占訪問和分布式虛擬內存(DVM)操作的規則。
CHI-B擴展了CHI-A,但不能直接向后兼容 CHI-A。它添加了支持 Armv8.1和Armv8.2 系統擴展的功能,例如:
更大的物理地址寬度
原子事務
DVM 的 VMID 擴展
通道字段、事務結構和RAS特性的描述
直接內存傳輸和直接緩存傳輸功能,減少內存和監聽訪問延遲
CHI 緩存行狀態
CHI使用了類似于ACE的一致性模型,增加了對監聽過濾器和基于目錄的系統的支持,以實現監聽擴展。
CHI使用與ACE相同的術語來定義緩存狀態,并添加了部分和空緩存行狀態。緩存行狀態術語包括:
有效和無效,用于描述緩存行是否存在于本地緩存中。
如果緩存行有效,則必須是唯一或共享的:唯一意味著緩存行僅存在于此緩存中,而不在任何其他請求者本地緩存中。僅當緩存行處于唯一狀態時,才能對本地緩存行進行存儲。共享意味著緩存行存在于此緩存中,并且可能存在于其他請求者本地緩存中,也可能不存在。
如果緩存行有效,它必須是Clean或Dirty的:Clean表示緩存不負責更新主內存。由于在另一個緩存中進行的先前更新,緩存行仍然可以保存與主內存不同的值。Dirty表示相對于主內存修改了緩存行。當此行從此緩存中逐出時,請求者必須確保更新主內存,或者將臟責任傳遞給系統中的另一個組件。
一行可以處于部分和空狀態:空緩存行沒有有效的數據字節,但行的所有權仍然屬于請求者。部分緩存行可以具有一些有效字節,包括無字節或所有字節。這是因為狀態已更新,但尚未寫入有效字節,或者因為已寫入所有字節,但尚未更新狀態。在此狀態下監聽緩存行時,可以給出的響應有額外的限制。將這些術語組合以描述如下圖所示的七種緩存行狀態:

在MOESI的基礎上額外增加兩個狀態。該圖包含以下緩存行狀態:
無效(Invalid,對應I態)緩存行不在緩存中。
Unique Dirty,對應M態此緩存行僅存在于此緩存中,并相對于主內存進行了修改。在此狀態下,請求者可以對緩存行執行寫操作,因為該行已處于唯一狀態。如果監聽指示,緩存行必須轉發給請求者。
Unique Dirty Partial此緩存行僅存在于此緩存中,并被認為相對于主內存進行了修改。它可以具有一些有效字節,其中一些包括無字節或所有字節。在此狀態下,請求者可以對緩存行執行寫操作,因為該行已處于唯一狀態。對于監聽,即使監聽指示也不能將緩存行直接轉發給原始請求者。
Shared Dirty,對應O態相對于主內存修改了此緩存行,而且這個特定的緩存有責任更新主內存。由于緩存行是共享的,它可能存在于一個或多個本地緩存中,但這并不是必須的。如果該行存在于多個緩存中,這些緩存將在共享干凈狀態下擁有此行。
Unique Clean,對應E態與主內存相比,緩存行沒有被修改,并且僅存在于單個本地緩存中。它可以在不通知其他緩存的情況下進行修改。Unique Clean Empty緩存行僅存在于此緩存中,但沒有有效字節。緩存行可以在不通知其他緩存的情況下進行修改。如果監聽請求該行,則不得將該行返回給Home或直接轉發給原始請求者。
Shared Clean,對應S態緩存行可能存在于一個或多個本地緩存中。與主內存相比,該行可能已被修改,但此緩存不負責在逐出時將行寫回內存。
3. CHI協議基礎
CHI協議通過節點類型對系統中的不同組件進行分類,并提供了節點之間通信的方法。
節點
主要有三種類型的節點:請求節點(RN)、home節點(HN)和從節點(SN)。此外還有雜項節點(MN)。
RN生成事務,如讀和寫請求,這些事務發送到HN。
HN負責對請求進行排序,向SN生成事務,并可以發出監聽或處理DVM操作。
這些節點類型可以進一步分為以下幾類:
RN節點是完全一致的、I/O一致的或具有DVM支持的I/O一致的:
完全一致的請求節點(RN-F),包含一致的緩存并將接受和響應監聽;
I/O一致的請求節點(RN-I),沒有一致的緩存,不能接受監聽
具有DVM支持的I/O一致請求節點(RN-D),具有與RN-I相同的功能,還可以接受DVM消息
home節點可以是完全一致的、非一致的或雜項的:
完全一致的home節點(HN-F)對一致內存的所有請求進行排序并向RN-F發出監聽
非一致的home節點(HN-I)對I/O子系統的請求進行排序雜項節點(MN)處理請求節點發送的DVM事務。這些有時作為HN-D節點實現
適用于普通內存或外設和普通內存的從屬節點(SN-F):
SN-F連接到支持一致內存空間的存儲器設備。例如,內存控制器將連接到SN-F節點。適用于外設或普通內存的SN-F連接到I/O外設或非一致內存以下表格總結了每個節點類別的行為:

在系統中的某些組件也可以被分類為請求者或完成者,如下所述:
? 請求者是通過發出請求消息啟動事務的組件。術語“請求者”可以是獨立發起事務的組件;術語“請求者”也可以是互聯組件,其發出下游請求消息,可獨立或作為系統中正在發生的其他事務的副作用。
? 完成者是響應從其他組件接收到的事務的組件。完成者可以是互聯組件(如HN或MN),也可以是位于互聯之外的組件(如從屬組件)。
系統地址映射
系統中的每個組件都被分配一個唯一的節點ID(node ID)。CHI使用系統地址映射(SAM)將物理地址轉換為目標節點ID。為了能夠確定發出請求的目標節點ID,每個RN和HN都必須具有SAM。
以下圖示展示了RN SAM將物理地址映射到HN節點ID,以及HN SAM將物理地址映射到SN節點ID:
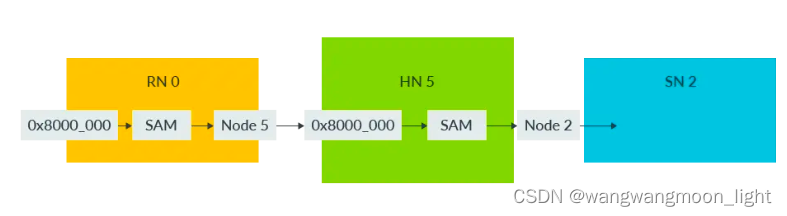
在這個圖中,事件的順序如下:
地址為0x8000_0000的事務通過節點0中的RN SAM。
RN SAM確定目標為節點5。事務路由到節點5的HN。
HN接收到事務。
HN通過其HN SAM傳遞地址,并確定目標為節點2。
事務被路由到節點2的SN。
RN SAM必須滿足以下要求:它必須完全描述整個系統地址空間任何不對應于物理組件的物理地址必須映射到一個可以提供適當錯誤響應的節點所有RN必須對RN SAM有一致的視圖。例如,無論是哪個RN發出的,地址0xFF00_0000必須始終指向同一個HN。
注:SAM的確切格式和結構完全由實現定義。CHI規范沒有提供關于如何將地址映射到node ID的指導。
節點通道
與ACE相比,CHI使用不同的通道:
請求(REQ):發送讀和寫請求、緩存維護請求和DVM請求。
響應(RSP):發送各種類型消息的完成響應,范圍從寫和緩存管理響應到無數據監聽響應和操作完成確認。
監聽(SNP):發出監聽或發送DVM操作。
數據(DAT):發送寫和讀數據,以及帶數據的監聽響應。
注:以TX為前綴的通道用于發送消息,以RX為前綴的通道用于接收消息。
下圖顯示了RN-F上CHI請求者接口上的通道:

當RN-F發出讀請求時,它在其TXREQ通道上發送請求。當讀數據返回時,RN-F在其RXDAT通道上接收數據。每個節點上的TX信號連接到目標節點上的RX信號。在SNP通道上有以下約束:
只有HN-F和MN在SNP通道上發出消息
RN-F僅在SNP通道上接受監聽
MN僅在SNP通道上接受DVM消息監聽
Flit
所有協議消息都以Flit的形式發送。
Flit是一種打包的控制字段和標識符集合,用于傳遞協議消息。在Flit中發送的一些控制字段包括操作碼、內存屬性、地址、數據和錯誤響應。每個通道需要不同的Flit控制字段。例如,請求通道上用于讀或寫的Flit需要地址字段,而數據通道上的Flit需要數據和字節使能字段。與PCIe或以太網協議中的字段不同,Flit中的字段不會在多個數據包上串行化。相反,它們是并行發送的。以下圖示顯示了一個請求Flit,以及Flit操作碼的詳細信息: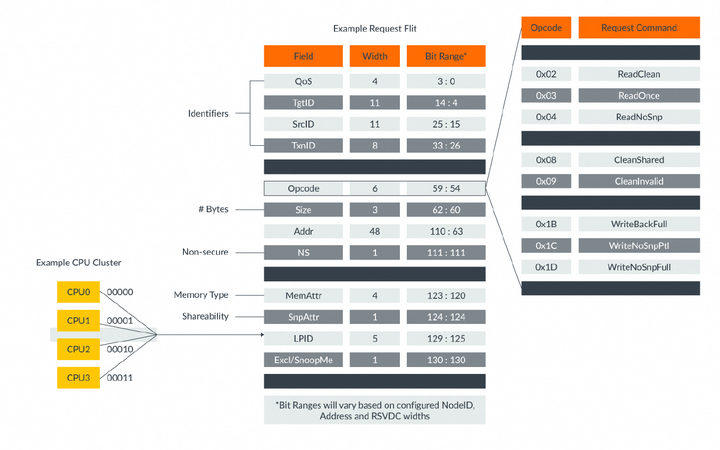 在CHI中傳遞Flit的握手機制與ACE中的不同。每個通道都有一個FLITV信號,發射器將該信號設置為高電平以表示Flit有效。只有當發射器先前收到接收器的信用時,才能發送Flit。信用通過LCRDV信號指示,并在上升的CLK邊沿上確認。為了在Flit中提供額外的信息,CHI定義了多個標識符字段。例如:源ID字段(SrcID)用于在CHI網絡中路由Flit。該字段標識Flit的發送者,并且每個Flit都有SrcID字段。源ID的值是發送消息的組件的節點ID。目標ID字段(TgtID)也用于在網絡中路由Flit。目標ID值是接收消息的節點的節點ID。除了監聽Flit之外,每個Flit都包含targetID字段。監聽通道不包含targetID的原因是CHI使用實現來確定哪些節點接收到監聽。HN-F可以使用任何機制來路由監聽,例如向所有RN-F廣播監聽,或使用snoop filter僅針對RN-F的子集。無論使用什么機制,當監聽Flit離開互連時,它已經針對特定節點。事務ID字段(TxnID)出現在每個Flit中。TxnID用于標識源節點和目標節點之間的每個事務。來自RN的每個未完成(outstanding)請求都必須具有唯一的TxnID。請求操作碼(Opcode)出現在REQ Flit中。它指定了事務類型,并且是決定事務結構的主要字段。例如不同類型的讀請求,寫請求或無數據請求。數據緩沖區ID(DBID)僅出現在響應和數據Flits中。目標節點使用DBID來表示可以接收寫數據,并釋放需要完成確認的事務。對于寫操作,請求者在收到完成者的響應中的DBID值之前不能發送寫數據。一些讀事務以完成確認結束,這是請求者表示已收到讀數據的地方。將讀數據發送回請求者時,數據flit包含一個DBID值,供請求者在發送完成確認消息時使用。以下表格總結了每種標識符可以用于哪種Flit類型:
在CHI中傳遞Flit的握手機制與ACE中的不同。每個通道都有一個FLITV信號,發射器將該信號設置為高電平以表示Flit有效。只有當發射器先前收到接收器的信用時,才能發送Flit。信用通過LCRDV信號指示,并在上升的CLK邊沿上確認。為了在Flit中提供額外的信息,CHI定義了多個標識符字段。例如:源ID字段(SrcID)用于在CHI網絡中路由Flit。該字段標識Flit的發送者,并且每個Flit都有SrcID字段。源ID的值是發送消息的組件的節點ID。目標ID字段(TgtID)也用于在網絡中路由Flit。目標ID值是接收消息的節點的節點ID。除了監聽Flit之外,每個Flit都包含targetID字段。監聽通道不包含targetID的原因是CHI使用實現來確定哪些節點接收到監聽。HN-F可以使用任何機制來路由監聽,例如向所有RN-F廣播監聽,或使用snoop filter僅針對RN-F的子集。無論使用什么機制,當監聽Flit離開互連時,它已經針對特定節點。事務ID字段(TxnID)出現在每個Flit中。TxnID用于標識源節點和目標節點之間的每個事務。來自RN的每個未完成(outstanding)請求都必須具有唯一的TxnID。請求操作碼(Opcode)出現在REQ Flit中。它指定了事務類型,并且是決定事務結構的主要字段。例如不同類型的讀請求,寫請求或無數據請求。數據緩沖區ID(DBID)僅出現在響應和數據Flits中。目標節點使用DBID來表示可以接收寫數據,并釋放需要完成確認的事務。對于寫操作,請求者在收到完成者的響應中的DBID值之前不能發送寫數據。一些讀事務以完成確認結束,這是請求者表示已收到讀數據的地方。將讀數據發送回請求者時,數據flit包含一個DBID值,供請求者在發送完成確認消息時使用。以下表格總結了每種標識符可以用于哪種Flit類型:
4. 事務流程
事務是節點完成請求所需的系統消息集合。本節包括以下示例:在請求者和完成者之間的寫請求中使用標識符完成ReadNoSnp事務所需的消息序列從請求節點到完成節點的WriteNoSnp事務流程
4.1 寫請求和標識符
以下示例展示了在請求者和完成者之間的寫請求中使用標識符。請求者被分配節點ID 1,完成者被分配節點ID 2。事件順序如下:1. 請求者向完成者發送TxnID為3的寫請求。請求者中的SrcID字段填充了請求者的節點ID。目標ID(TgtID)字段填充了完成者的節點ID。此步驟如下圖所示: 2. 完成者將請求的事務ID和源ID分配給一個可用的數據緩沖槽。在本例中,請求被分配了數據緩沖區ID(DBID)0。3. 完成者向請求者發送帶有TxnID 3和DBID值0的DBIDResp消息,如下圖所示:
2. 完成者將請求的事務ID和源ID分配給一個可用的數據緩沖槽。在本例中,請求被分配了數據緩沖區ID(DBID)0。3. 完成者向請求者發送帶有TxnID 3和DBID值0的DBIDResp消息,如下圖所示: 4. 請求者使用接收到的DBID作為TxnID向完成者發送寫數據。5. 當事務完成時,對應于DBID 0的緩沖槽將被釋放。
4. 請求者使用接收到的DBID作為TxnID向完成者發送寫數據。5. 當事務完成時,對應于DBID 0的緩沖槽將被釋放。
4.2 ReadNoSnp事務流程
以下示例展示了ReadNoSnp事務的flow。請求節點0發出ReadNoSnp請求,完成節點5提供讀數據。具體flow如下:1. 請求節點0向CHI互連發出一個ReadNoSnp,目標為Home節點3。該事務在請求者節點的TXREQ通道上發送。此步驟如下圖所示: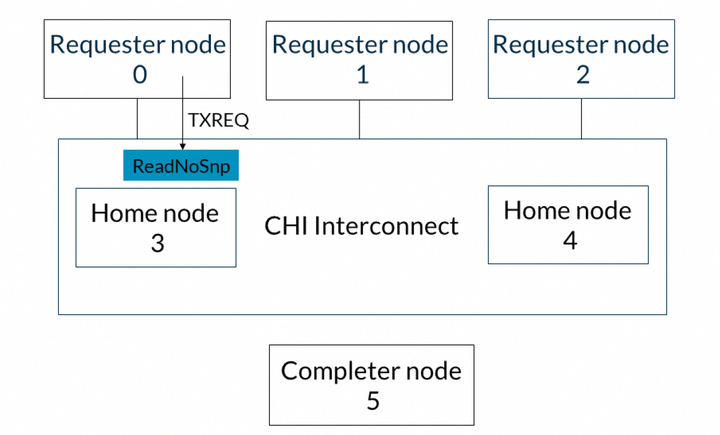 2. Home節點3在其TXREQ通道上向完成節點5發出ReadNoSnp請求,以檢索數據,如下圖所示:
2. Home節點3在其TXREQ通道上向完成節點5發出ReadNoSnp請求,以檢索數據,如下圖所示: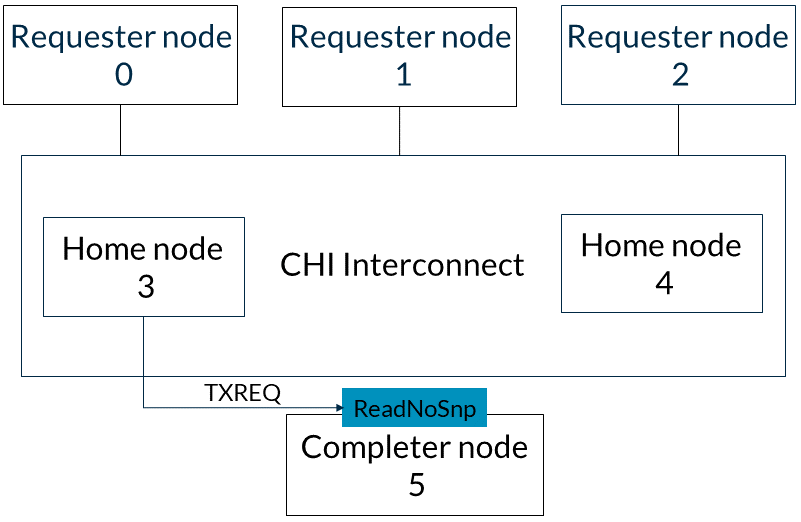 3. 完成節點5在其TXDAT通道上發出CompData響應,將數據返回給Home節點3,如圖所示:
3. 完成節點5在其TXDAT通道上發出CompData響應,將數據返回給Home節點3,如圖所示: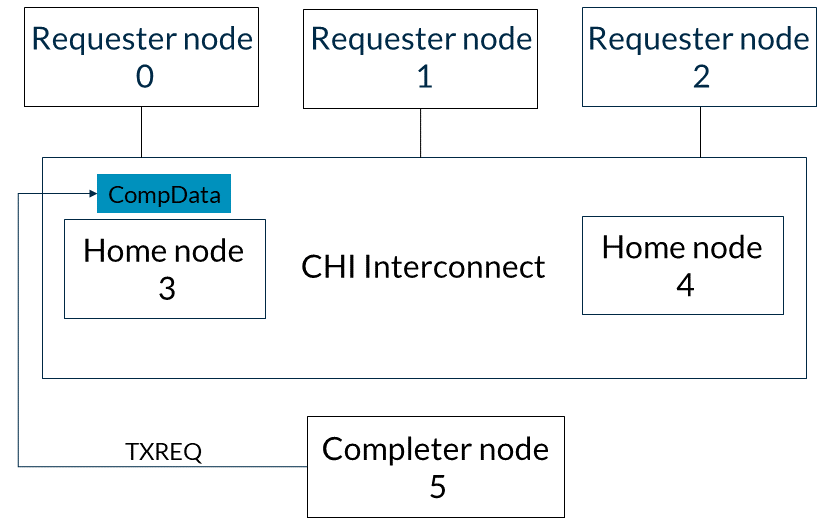 4. 基節點3將CompData響應發送給請求節點0。請求節點0在其RXDAT通道上接收數據,如圖:
4. 基節點3將CompData響應發送給請求節點0。請求節點0在其RXDAT通道上接收數據,如圖:
4.3 WriteNoSnp事務流程
本節介紹了從請求節點0到完成節點5的WriteNoSnp事務的流程。以下描述了事件的順序:1. 請求節點0在TXREQ通道上向基節點3發送WriteNoSnp消息,如圖所示: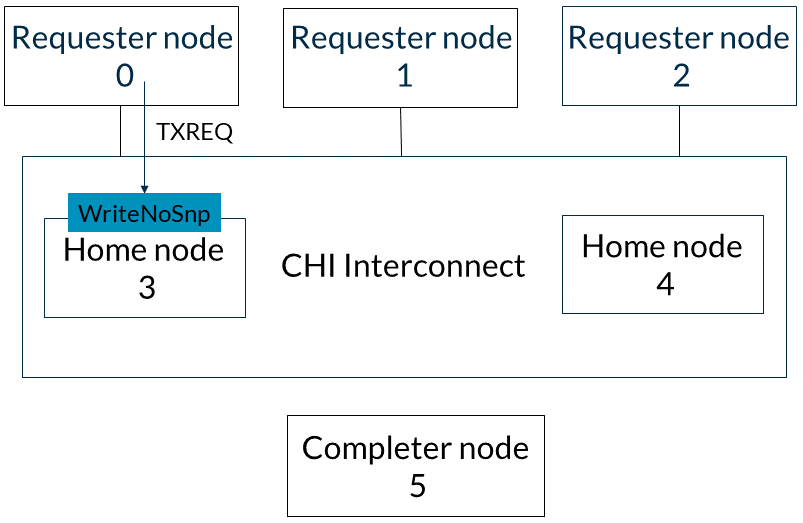 2. 基節點3向請求節點0響應一個CompDBIDResp消息。此響應表明它可以接受寫數據,并且WriteNoSnp對其他請求者是可觀察的。此消息通過基節點的TXRSP通道發送。此步驟如下圖所示:
2. 基節點3向請求節點0響應一個CompDBIDResp消息。此響應表明它可以接受寫數據,并且WriteNoSnp對其他請求者是可觀察的。此消息通過基節點的TXRSP通道發送。此步驟如下圖所示: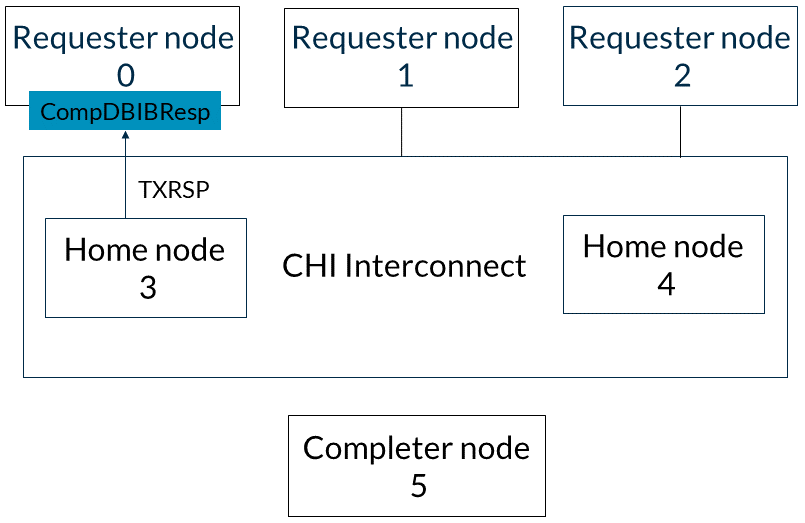 3. 以下兩個步驟可以按任意順序發生:(a)home節點3向完成節點5發出WriteNoSnp消息,并收到CompDBIDResp響應,如圖所示:
3. 以下兩個步驟可以按任意順序發生:(a)home節點3向完成節點5發出WriteNoSnp消息,并收到CompDBIDResp響應,如圖所示: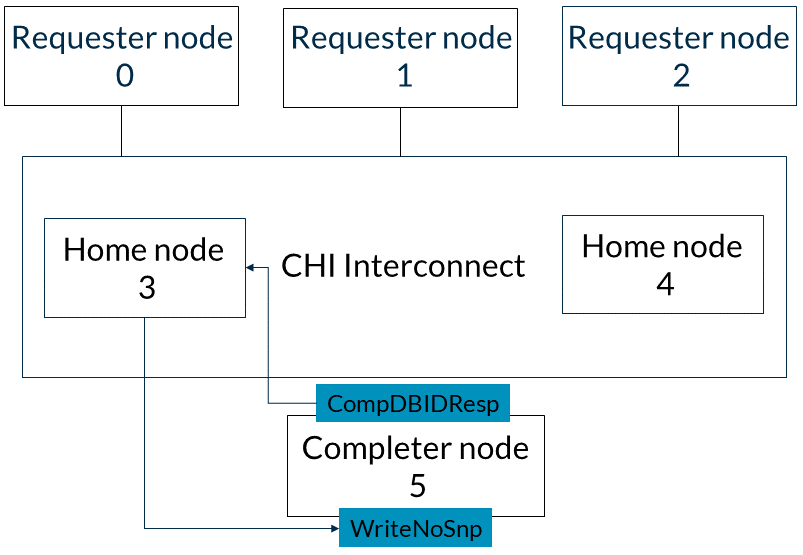 (b)或者,請求節點0可以通過其TXDAT通道將WriteNoSnp的寫數據發送到home節點3,如圖所示:
(b)或者,請求節點0可以通過其TXDAT通道將WriteNoSnp的寫數據發送到home節點3,如圖所示: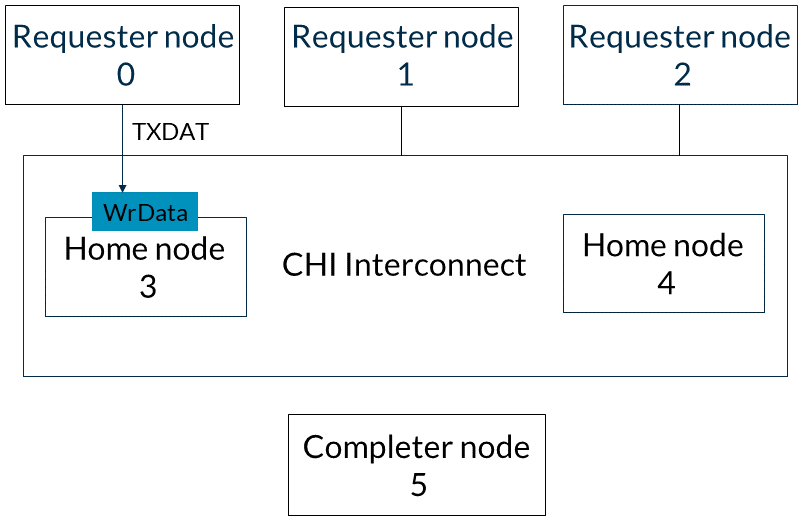 4. 在收到來自完成節點的CompDBIDResp和來自請求節點的寫數據后,基節點3在TXDAT通道上將寫數據發送到完成節點5,如圖所示:
4. 在收到來自完成節點的CompDBIDResp和來自請求節點的寫數據后,基節點3在TXDAT通道上將寫數據發送到完成節點5,如圖所示:
4.4 完成確認
CHI使用完成確認(Completion Acknowledgment)響應來維護以下事務的順序:由完全一致請求節點(RN-F)發起的事務由這些RN-F事務引發的監聽事務完成確認確保在一致事務完成后,按順序在RN-F之后接收到監聽事務。HN-F可以通過暫停事務來維護事務順序。例如,RN-F可能已經有一個正在處理的針對特定緩存行的未完成事務。如果系統中的另一個請求者發起一個導致對同一行進行監聽的事務,HN-F可以暫停這個后來的事務。當原始的RN-F完成一致事務時,RN-F使用其TXRSP通道向HN-F發送完成確認(CompAck)消息。然后,HN-F解除等待完成確認的監聽阻塞。這種機制與ACE中的RACK/WACK功能類似。并非CHI中的每個事務都需要完成確認。請求Flit包含一個ExpCompAck字段,用于表示何時需要完成確認。如果需要完成確認,RN-F在請求中將ExpCompAck設置為1,并在請求完成時發出CompAck響應。流程如下:請求節點(RN-F)發起一個具有ExpCompAck = 1的請求。基節點完成請求。基節點向RN-F發送Comp或CompData。RN-F向基節點發送CompAck。基節點現在可以向RN-F發送等待中的監聽。以下示例展示了在需要讀請求中的完成確認時發送的消息:1. 請求者向完成者發送一個讀請求,請求地址為0x8000,ExpCompAck字段設置為1,如圖所示: 2. 完成者為讀地址分配一個任意的DBID位置,阻止互連發出針對將來一致請求的監聽。這個位置如圖所示:
2. 完成者為讀地址分配一個任意的DBID位置,阻止互連發出針對將來一致請求的監聽。這個位置如圖所示: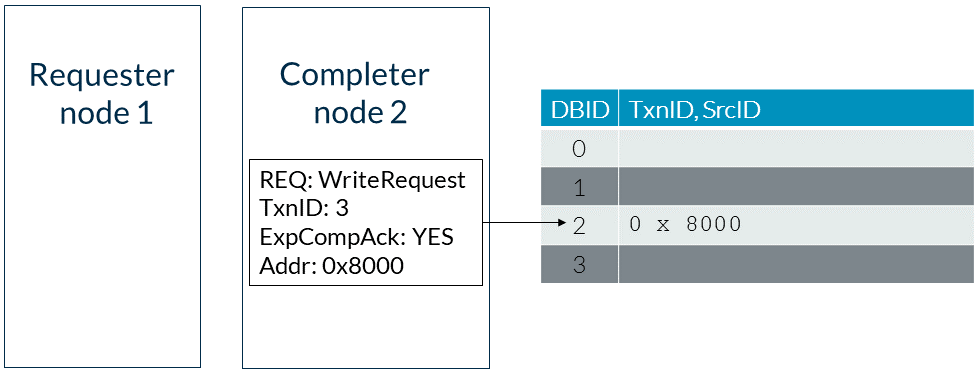 3. 完成者使用CompData響應回應請求者,同時表示事務完成并發送讀數據。響應中的DBID字段填充了用于存儲讀地址的DBID位置。這一步如下圖所示:
3. 完成者使用CompData響應回應請求者,同時表示事務完成并發送讀數據。響應中的DBID字段填充了用于存儲讀地址的DBID位置。這一步如下圖所示: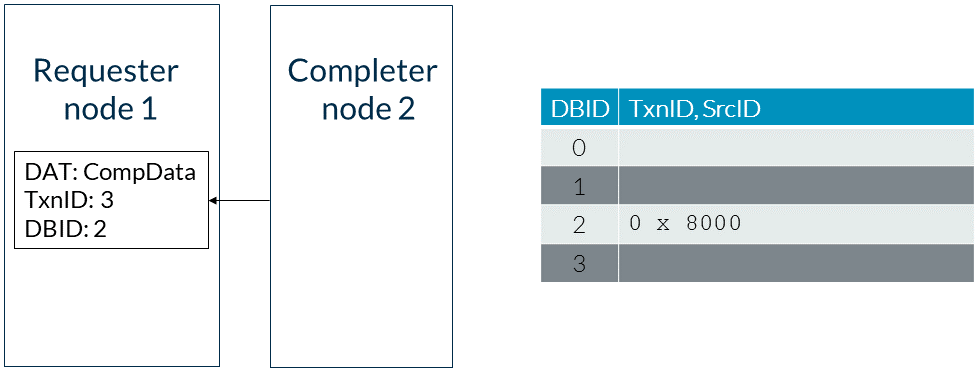 4. 請求者發送一個CompAck消息。CompAck使用從完成者那里接收到的DBID值作為事務ID,如圖所示:
4. 請求者發送一個CompAck消息。CompAck使用從完成者那里接收到的DBID值作為事務ID,如圖所示: 完成者清除地址0x8000的DBID位置,允許互連向該位置發出未來的監聽。
完成者清除地址0x8000的DBID位置,允許互連向該位置發出未來的監聽。
4.5 帶有監聽的CompAck
本示例展示了在需要多個請求節點訪問相同可緩存內存位置的完成確認時發送的消息。在此示例中,CHI互連向所有緩存請求者廣播監聽。或者,它可以使用監聽過濾器并僅針對本地存在該行的請求者。以下列表描述了事件的順序:1. 請求者節點0向基節點3發送地址A的MakeUnique消息。當請求者節點0向基節點3發出完成確認時,此事務完成。這一步如下圖所示: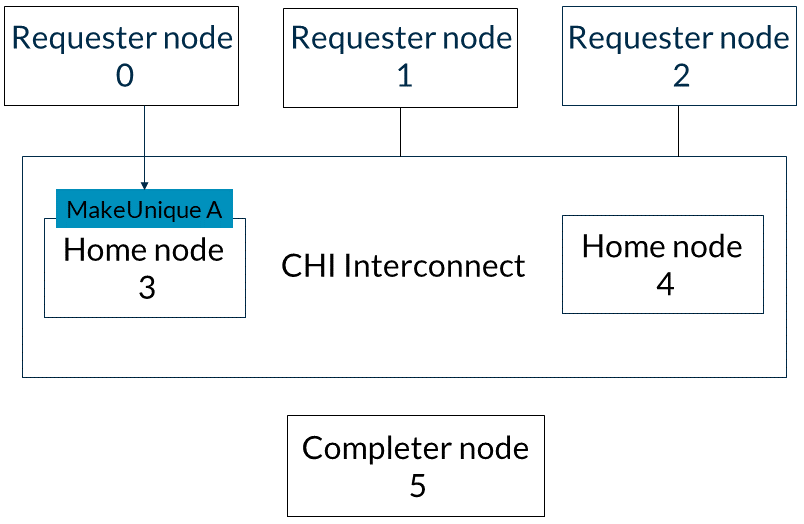 2. 基節點3向請求者節點1和2發送地址A的SnpMakeInvalid監聽,如圖所示:
2. 基節點3向請求者節點1和2發送地址A的SnpMakeInvalid監聽,如圖所示: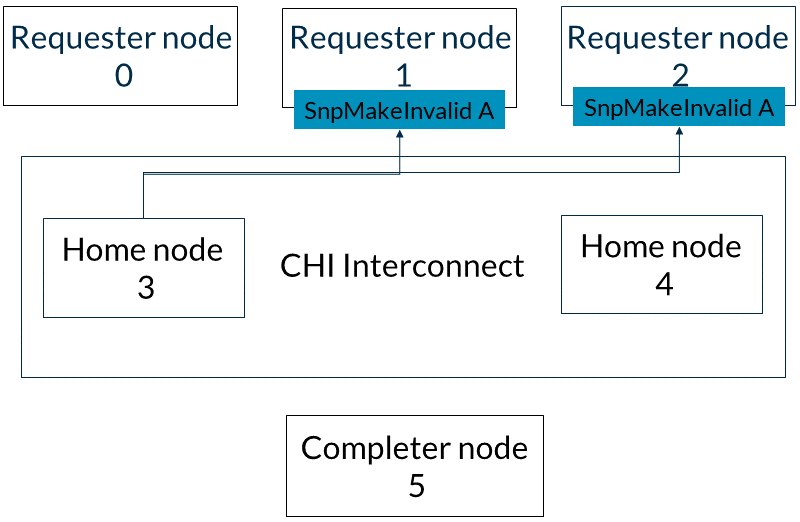 3. 請求者節點1和2以SnpResp_1響應。這些響應意味著地址A已失效。基節點3可以按任意順序接收SnpResp_I。這一步如下圖所示:
3. 請求者節點1和2以SnpResp_1響應。這些響應意味著地址A已失效。基節點3可以按任意順序接收SnpResp_I。這一步如下圖所示: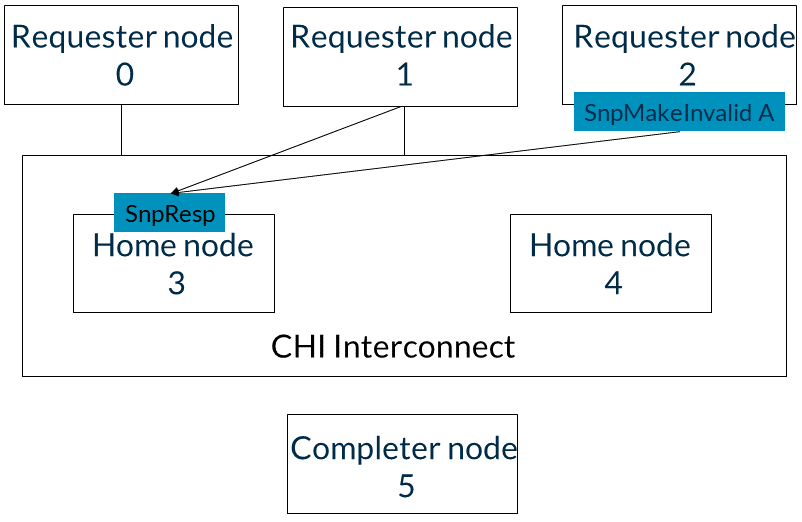 4. 請求者節點2向基節點3發送地址A的ReadShared請求。請注意,基節點3仍未對請求者節點0的MakeUnique消息作出回應。現在,直到請求者節點0發送MakeUnique的完成確認消息,由ReadShared請求生成的監聽將被阻塞。這一步如下圖所示:
4. 請求者節點2向基節點3發送地址A的ReadShared請求。請注意,基節點3仍未對請求者節點0的MakeUnique消息作出回應。現在,直到請求者節點0發送MakeUnique的完成確認消息,由ReadShared請求生成的監聽將被阻塞。這一步如下圖所示: 5. 由于在步驟3中收到的監聽響應,基節點3向請求節點0發送Comp_UC消息。6. 請求節點0發送CompAck消息并解除對地址A的監聽阻塞。7. 基節點3為地址A生成向請求節點0和1的SnpShared監聽。8. 請求節點1以SnpResp響應,表示它沒有數據。9. 請求節點0以SnpRespData響應,發送地址A的最新數據。基節點3可以按任意順序接收這兩個響應。10. 收到兩個監聽響應后,基節點3將監聽數據返回給請求節點2。11. 請求節點2向基節點3發送完成確認。基節點3可以向地址A生成未來的監聽。
5. 由于在步驟3中收到的監聽響應,基節點3向請求節點0發送Comp_UC消息。6. 請求節點0發送CompAck消息并解除對地址A的監聽阻塞。7. 基節點3為地址A生成向請求節點0和1的SnpShared監聽。8. 請求節點1以SnpResp響應,表示它沒有數據。9. 請求節點0以SnpRespData響應,發送地址A的最新數據。基節點3可以按任意順序接收這兩個響應。10. 收到兩個監聽響應后,基節點3將監聽數據返回給請求節點2。11. 請求節點2向基節點3發送完成確認。基節點3可以向地址A生成未來的監聽。
4.6 端點順序和請求順序
CHI中的事務可以按端點順序(endpoint order)和請求順序(request order)排序,如下所述:端點順序保持從單個請求者到單個從屬地址范圍的事務順序。例如,在端點順序中,向從屬的可編程寄存器組發出多個設備訪問。請求順序保持來自單個請求者到同一地址的事務順序。例如,當向重疊的非緩存地址(如Normal NC、Device-GRE和Device-nGRE)發出多個請求時,需要排序。當設置請求順序時,CHI不要求地址匹配的精確粒度,粒度由實現定義。注:如果設置端點順序,請求順序是隱含的。請求Flit中有一個2–bit的Order字段用來控制order類型。只有一些請求類型可以使用請求順序和端點順序。這些請求類型是:ReadNoSnp和任何ReadOnce類型的請求:請求者發出需要排序的ReadNoSnp或ReadOnce類型請求從屬接受請求并以ReadReceipt消息回應。ReadReceipt信號表明可以發出下一個有序請求通過發出ReadReceipt響應,從屬保證它按接收到的順序來維護請求WriteNoSnp和WriteUnique類型的請求:請求者發出需要排序的WriteNoSnp或WriteUnique類型請求從屬以DBIDResp消息回應以表示可以接受消息。DBIDResp響應表示數據緩沖區插槽可用于接受寫數據,并且請求者可以發出下一個有序請求。通過發出DBIDResp,從屬保證按收到的順序維護請求事件順序如下:請求者使用ReqOrder設置向從屬發起讀請求1。請求者向從屬發出帶有ReqOrder設置的讀請求2,但由于請求1仍未完成,請求者被阻止發送請求。從屬以ReadReceipt消息回應讀請求1,表示請求已被接受。以任意順序: 請求者向從屬發送讀請求2。從屬將讀請求1的讀數據返回給請求者。
4.7 請求重試
有時目標節點可能沒有足夠的資源來接受請求。為防止在資源不可用時阻塞請求通道,CHI提供了一個請求重試機制。請求重試機制使用協議信用(Protocol Credits)來指示資源可用性。確定和記錄處理請求所需的協議信用(PCrd)類型是從節點的責任。該機制可以使用不同類型的協議信用來跟蹤不同的資源。例如,讀請求和寫請求可以使用單獨的數據緩沖區,因此每個緩沖區可以使用不同類型的協議信用來指示可用性。不同類型的協議信用值由實現定義。以下示例描述了伴隨請求重試發送的消息序列。在此示例中,請求者節點1發出請求,因為完成者無法接受請求。以下描述了事件順序:1. 每個請求最初都是在沒有協議信用的情況下發出的。請求Flit中有一個名為AllowRetry的控制字段。第一次發送請求時將此字段設置為YES表示請求沒有使用協議信用。當AllowRetry為YES時,請求中的PCrdType字段必須為0。以下圖表顯示了請求設置: 2. 在此示例中,目標節點由于請求者緩沖區已滿而無法接受請求,因此返回一個RetryAck消息。3. RetryAck響應Flit中設置了一個PCrdType字段,其值表示需要重試請求所需的信用類型。在此示例中,PCrdType的值為2,如圖所示:
2. 在此示例中,目標節點由于請求者緩沖區已滿而無法接受請求,因此返回一個RetryAck消息。3. RetryAck響應Flit中設置了一個PCrdType字段,其值表示需要重試請求所需的信用類型。在此示例中,PCrdType的值為2,如圖所示: 4. 當目標節點可以接受請求時,它在RSP通道上發送一個PCrdGrant消息。PCrdGrant響應Flit使用PCrdType字段來指示已變為可用的協議信用類型。請求者只有在PCrdGrant消息和RetryAck響應中的協議信用類型匹配時才能重試請求。在這個例子中,兩個字段都必須設置為2。如果協議信用類型匹配,目標節點現在可以保證接受請求。5. 請求者重新發出請求,并將AllowRetry字段設置為0。將AllowRetry字段設置為0表示向目標節點指示請求正在使用已授予的協議信用。
4. 當目標節點可以接受請求時,它在RSP通道上發送一個PCrdGrant消息。PCrdGrant響應Flit使用PCrdType字段來指示已變為可用的協議信用類型。請求者只有在PCrdGrant消息和RetryAck響應中的協議信用類型匹配時才能重試請求。在這個例子中,兩個字段都必須設置為2。如果協議信用類型匹配,目標節點現在可以保證接受請求。5. 請求者重新發出請求,并將AllowRetry字段設置為0。將AllowRetry字段設置為0表示向目標節點指示請求正在使用已授予的協議信用。
5. DVM操作
CHI協議支持DVM(分布式虛擬內存)操作,CHI使用DVM操作來管理虛擬內存。DVM是分布式虛擬內存的縮寫,是CHI用于管理虛擬地址空間和物理地址空間映射的一種機制。DVM操作可以使系統中的不同節點共享一致的虛擬內存視圖,從而提高性能和安全性。
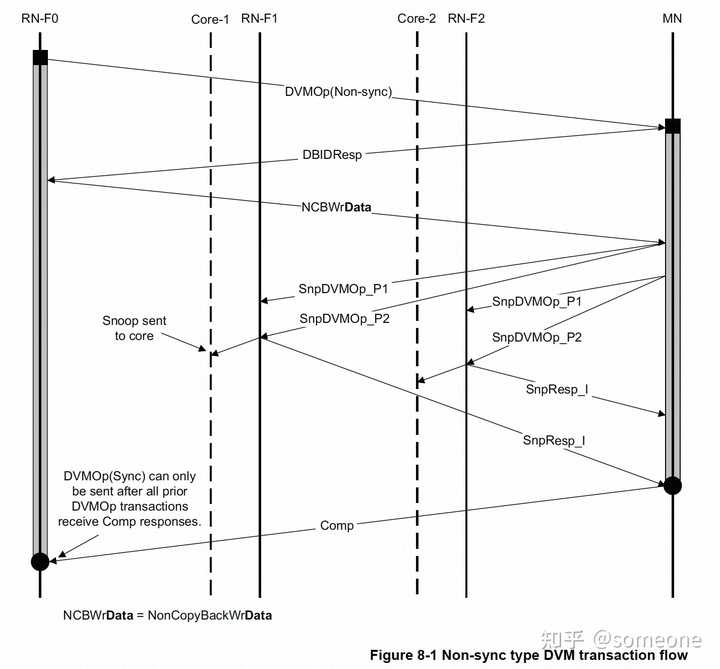
- DVM transaction flowCHI定義了兩種類型的DVM操作:DVM Non-sync和DVM Sync。在CHI中,所有DVM的操作都分為兩個part發送到MN。這與ACE不同,ACE有的DVM操作需要兩個part,而有的操作只需要1個part。下面描述了CHI中DVM操作的part順序:DVM的第1個part作為請求發送給MN,Opcode字段設置為DVMOp。請求Flit使用地址字段來編碼操作的屬性。DVM的第2個part作為數據Flit發送,只有在請求節點收到MN的DBID response后才發送。第2個part攜帶了DVM操作的目標地址。當MN收到DVM操作的兩個part時,MN會向參與一致性域的RN生成DVM Snoop。MN在節點監聽通道上發送兩部分的DVM Snoop。DVM Snoop的兩個part必須使用相同的TxnID和Opcode SnpDVMOp,并使用以下參數:第1個part使用地址字段來編碼操作屬性和目標地址的高位第2個part使用地址字段發送地址的其余位為了區分這兩個part,CHI要求地址字段的bit[3]設置為0以表示第1個part,設置為1表示第2個part。DVM snoop的第2個part可能在第1個part之前到達RN。DVM Non-sync的flow如下圖所示:
 DVM sync的flow如下圖所示:
DVM sync的flow如下圖所示:
2. DVM操作類型
CHI定義了兩種類型的DVM操作:非同步DVM(DVM Non-Sync)和同步DVM(DVM Sync)。DVM操作的屬性決定了RN在響應DVM Snoop之前是否必須等待操作完成。DVM sync只執行同步操作,沒有其他操作。DVM non-sync包括以下3種操作:TLB InvalidateInstruction cache InvalidateBranch Predictor InvalidateDVM non-sync不需要等DVM操作執行完成就可以進行更多的DVM操作,這允許有多個outstanding的DVM non-sync。在以下示例中,RN-F可以發出多個Branch Predictor或Instruction Cache Invalidate,接收的RN-F或RN-D不必立即執行操作:RN-F或RN-D收到一個指示DVM Non-Sync的DVM Snoop。RN-F或RN-D向MN發出Snoop響應。Snoop響應確認收到DVM消息,但不表示RN已經執行了DVM操作。MN向發起RN-F發送Completion消息,表示已接受DVM操作。為確保所有outstanding的DVM請求已執行,需要執行以下步驟:RN-F向MN發出DVM sync操作。任何需要由DVM Sync完成的DVM請求必須在發出DVM Sync之前收到它們的完成響應。MN在監聽(snoop)通道上向所有RN-F和RN-D發出DVM Snoop。每個目標RN確保其所有未完成的DVM操作已執行。每個RN向MN發出一個Snoop響應,表示所有操作已執行。MN向最初發出DVM sync的RN-F發送DVM Sync的Completion響應。CHI DVM Sync與ACE中的DVM Sync類似。兩者都檢查之前發出的DVM操作是否已完成。不同之處是CHI不需要DVM完成消息。注:Arm核會因DSB指令產生DVM Sync。然而,實現可以選擇僅在尚未同步的DVM操作存在時,才因DSB發出DVM Sync。3. DVM操作flow本節描述了一個TLB invalidate DVM請求,之后跟一個DVM sync操作,并展示以下事件:DVM請求的不同部分MN生成的監聽操作DVM sync如何確保之前的DVM操作已執行事件的順序如下:RN0發一個TLB invalidate DVM請求給MN。MN回一個DBIDResp給RN0,表示可以接受DVM請求的第二部分。RN0向MN發出寫數據消息。這是DVM消息的第二部分。MN將DVM請求的兩個部分發送給RN1。RN1通過向MN發送snoop響應來確認DVM請求。MN接收到snoop響應。MN向RN0發出完成消息。RN0向MN發出一個DVM同步操作。MN向RN0發出DBIDResp消息。RN0向MN發送寫數據消息。這是DVM同步消息的第二部分。MN向RN1發出DVM sync監聽操作。RN1完成所有outstanding的DVM操作。RN1向MN發送監聽響應,表示已完成所有操作。MN向RN0發出完成消息。這是對DVM sync請求的響應。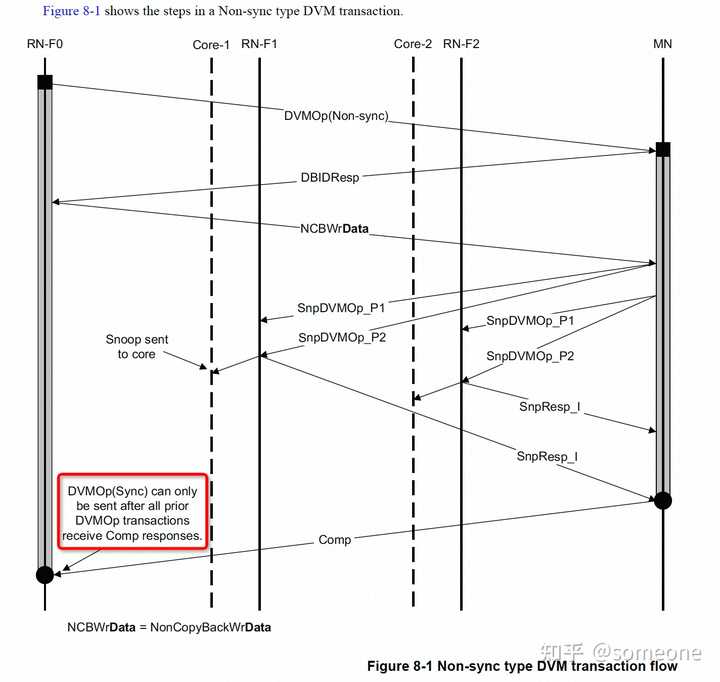

6. 緩存貯存(cache stash)
緩存貯存是一種在系統內指定緩存中(例如L2、L3等)貯存數據的機制。CHI-B引入這個特性以提高系統性能。緩存貯存機制通過在數據即將使用的地方附近分配一個緩存行來提高系統性能。當使用數據時,這將導致更低的內存訪問延遲。cache stash請求由RN節點(RNI/RND/RNF)發起。緩存貯存請求是一個建議,而不是一個強制性動作,即在系統中的特定緩存內貯存特定的緩存行。接收緩存貯存請求的設備可以忽略該請求。CHI主要支持兩種形式的緩存貯存:包含寫數據的貯存事務,以及無數據的貯存事務。兩種形式的緩存貯存都可以將不同的緩存級別作為貯存目標。緩存貯存支持已添加到ACE5-Lite協議中。CHI協議在緩存貯存方面非常靈活,允許貯存請求采用多種形式。
事務流程
緩存貯存的基本事務流程如下:1.RN在請求通道上發起一個緩存貯存請求。2.緩存貯存請求傳給HN-F。3.HN-F可以:? 忽略cache stash請求。RN-F將Stashing Snoop視為非stash版本并做出相應的響應。或者,? 接受cache stash請求并生成針對RN-F的監聽。RN-F響應并將緩存行取到其緩存中。4.被指定進行stash的RN-F收到一種特殊類型的snoop請求,稱為Stashing Snoop。RN-F可以:使用DataPull機制提供一個相關聯緩存行讀請求的snoop response在不使用DataPull的情況下提供監聽響應,然后為該緩存行發出獨立的讀請求在不獲取該緩存行的情況下提供監聽響應,忽略cache stash hint 貯存監聽請求所有cache stash請求都會發送到HN-F節點。當HN-F處理cache stash請求時,它會向目標RN-F生成stashing snoop。CHI定義了四種不同的stashing snoop請求,每種請求對應于初始的cache stash事務。如下表所示,主要是兩大類:WriteUniqueStash(帶寫數據)和StashOnce(不帶數據)。
cache stash控制字段
CHI為緩存貯存添加了請求、監聽、響應和數據Flit的控制字段。這些字段表示:貯存目標的NodeIDRN-F內的特定邏輯處理器緩存,如L2緩存是否使用DataPull機制Request Flit對于cache stash請求使用以下字段:StashNID保存貯存目標的節點ID。如果RN-F被選為貯存目標,StashNID字段將填充RN-F的節點ID。StashNIDValid。如果在貯存時應使用StashNID字段,StashNIDValid將為1。StashLPID指定RN-F內的邏輯處理器ID。此字段允許將較低級別的緩存(如L2緩存)指定為貯存目標。StashLPIDValid。如果在貯存時應使用StashLPID字段,StashLPIDValid將為1。Snoop Flit還包含以下字段:? StashLPID和StashLPIDValid。如果緩存貯存請求指示StashLPID有效(StashLPIDValid = 1),監聽將使用緩存狀態請求中的StashLPID值。如果沒有指定StashLPID(StashLPIDValid = 0),則貯存的數據可以放置在RN-F內的共享緩存中。? DoNotDataPull:如果此字段設置為1,則貯存目標無法請求DataPull,因此無法使用DataPull機制。帶寫數據的事務如果請求者正在寫入新數據并需要一個目標來存儲該數據,則發出WriteUniqueStash事務。寫入的數據可以是完整或部分緩存行。CHI使用以下操作碼之一來指示帶有貯存暗示的寫:? WriteUniquePtlStash表示部分緩存行寫? WriteUniqueFullStash表示完整緩存行寫本節介紹I/O請求者如何發出帶有寫數據的貯存暗示。stash事務的目標是系統中的RN-F。事件順序如下:1. RN-I發出帶有寫數據的WriteUniqueFullStash請求。為簡化起見,此示例未描述HN-F的DBIDResp。如下圖所示: 2. HN-F接受貯存請求,然后向RN-F發出SnpMakeInvalidStash請求,如下圖所示:
2. HN-F接受貯存請求,然后向RN-F發出SnpMakeInvalidStash請求,如下圖所示: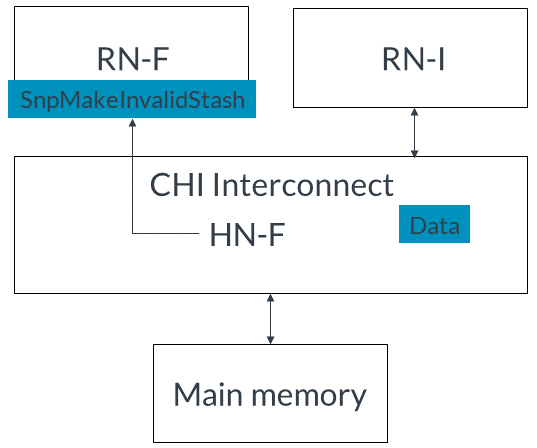 3. RN-F接收到NH-F的監聽。4. RN-F接受貯存暗示并發出監聽響應,如圖所示:
3. RN-F接收到NH-F的監聽。4. RN-F接受貯存暗示并發出監聽響應,如圖所示: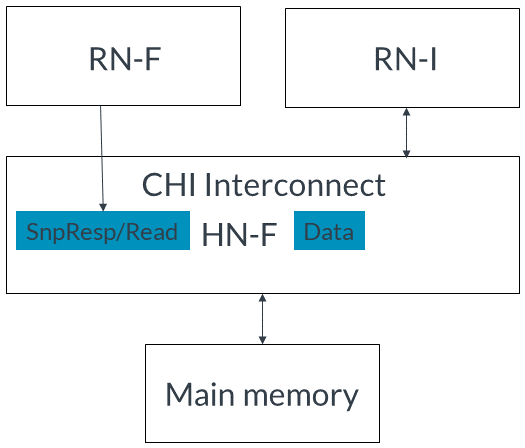 5. 如果使用DataPull機制,RN-F發出隱式讀請求的監聽響應,或者發出監聽響應和單獨的讀請求。為簡化起見,本示例中使用隱式監聽響應和讀請求,但未使用完整的DataPull流程。6. HN-F將從RN-I接收到的寫數據發送給RN-F。無寫數據的事務請求方在將緩存用作貯存目標但不寫入數據時,使用無數據貯存事務。CHI對于無數據貯存請求使用以下操作碼:如果預期貯存目標會讀取緩存行,則發出StashOnceShared。此操作碼表示在分配后,緩存行應處于共享狀態。如果預期貯存目標會寫入緩存行,則發出StashOnceUnique。此操作碼表示緩存行應處于唯一狀態,從而使貯存目標在將來需要時能立即寫入緩存行。以下示例描述了沒有寫數據的stash hint。RN-I向RN-F發送貯存請求,將RN-F作為貯存目標,并且HN-F和RN-F都接受貯存暗示。事件順序如下:1. RN-I向HN-F發出StashOnceUnique請求,指示RN-F是目標且沒有寫數據。如下圖所示:
5. 如果使用DataPull機制,RN-F發出隱式讀請求的監聽響應,或者發出監聽響應和單獨的讀請求。為簡化起見,本示例中使用隱式監聽響應和讀請求,但未使用完整的DataPull流程。6. HN-F將從RN-I接收到的寫數據發送給RN-F。無寫數據的事務請求方在將緩存用作貯存目標但不寫入數據時,使用無數據貯存事務。CHI對于無數據貯存請求使用以下操作碼:如果預期貯存目標會讀取緩存行,則發出StashOnceShared。此操作碼表示在分配后,緩存行應處于共享狀態。如果預期貯存目標會寫入緩存行,則發出StashOnceUnique。此操作碼表示緩存行應處于唯一狀態,從而使貯存目標在將來需要時能立即寫入緩存行。以下示例描述了沒有寫數據的stash hint。RN-I向RN-F發送貯存請求,將RN-F作為貯存目標,并且HN-F和RN-F都接受貯存暗示。事件順序如下:1. RN-I向HN-F發出StashOnceUnique請求,指示RN-F是目標且沒有寫數據。如下圖所示: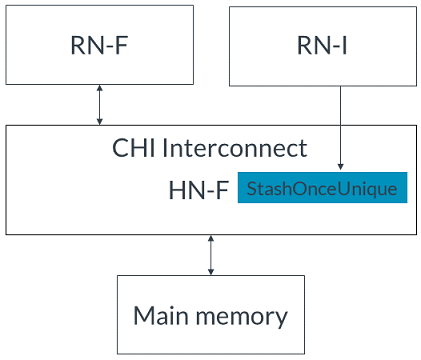 2. HN-F接受貯存請求。3. HN-F向主內存發出ReadNoSnp請求以獲取緩存行,并向RN-F發出 SnpStashUnique 監聽,如圖所示:
2. HN-F接受貯存請求。3. HN-F向主內存發出ReadNoSnp請求以獲取緩存行,并向RN-F發出 SnpStashUnique 監聽,如圖所示: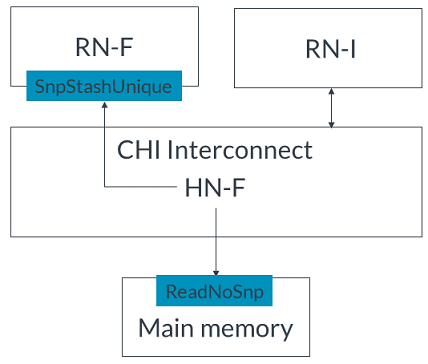 4. 主內存將緩存行返回給HN-F,如圖所示:
4. 主內存將緩存行返回給HN-F,如圖所示: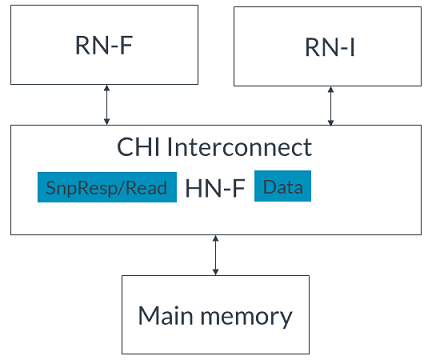 5. RN-F對監聽作出回應,請求緩存行。6. HN-F將緩存行轉發給RN-F。stash請求不一定需要一個有效的貯存目標。如果未指定貯存目標,則請求中的目標HN-F成為貯存目標。然后,HN-F選擇是否將緩存行分配到其緩存中。以下步驟描述了無寫數據的貯存暗示,目標是系統緩存。事件的順序如下:RN-I向HN-F發出StashOnceShared請求。將StashNIDValid字段設置為0以設置HN-F為target。HN-F向主內存發出ReadNoSnp請求以獲取指定的緩存行。主內存將緩存行返回給HN-F。HN-F將緩存行分配到其緩存中。DataPull機制DataPull機制是通過Snoop響應暗示讀請求的一種方式,因此不需要單獨的讀請求來獲取要貯存的緩存行。DataPull僅適用于貯存Snoop請求,而不適用于其他任何snoop。接收要求DataPull的請求的RN-F可以選擇是否使用DataPull或發送單獨的讀請求。如果RN-F選擇不請求DataPull,它會響應snoop,然后可以稍后發送讀請求以獲取緩存行。有關DataPull允許的所有Snoop響應的信息,請參閱AMBA 5 CHI架構規范。在本節中,我們描述了RF-F利用DataPull機制作為貯存事務的一部分接收數據的過程。DataPull的完整事務流程如下:1.HN-F發出貯存Snoop并將Snoop Flit中的DoNotDataPull字段設置為0。這表明RN-F貯存目標可以請求DataPull。2.接收到DoNotDataPull = 0的RN-F可以選擇在其Snoop響應中請求DataPull。在此示例中,RN-F選擇請求DataPull。3.RN-F通過在Response Flit中設置兩個字段來請求DataPull:? 將DataPull字段設置為1? 使用將用于返回讀數據的TxnID填充DBID字段4.RN-F接收到讀取的數據。5.RN-F向HN-F發送CompAck消息。以下圖示顯示了StashOnceUnique事務的DataPull機制的時序:
5. RN-F對監聽作出回應,請求緩存行。6. HN-F將緩存行轉發給RN-F。stash請求不一定需要一個有效的貯存目標。如果未指定貯存目標,則請求中的目標HN-F成為貯存目標。然后,HN-F選擇是否將緩存行分配到其緩存中。以下步驟描述了無寫數據的貯存暗示,目標是系統緩存。事件的順序如下:RN-I向HN-F發出StashOnceShared請求。將StashNIDValid字段設置為0以設置HN-F為target。HN-F向主內存發出ReadNoSnp請求以獲取指定的緩存行。主內存將緩存行返回給HN-F。HN-F將緩存行分配到其緩存中。DataPull機制DataPull機制是通過Snoop響應暗示讀請求的一種方式,因此不需要單獨的讀請求來獲取要貯存的緩存行。DataPull僅適用于貯存Snoop請求,而不適用于其他任何snoop。接收要求DataPull的請求的RN-F可以選擇是否使用DataPull或發送單獨的讀請求。如果RN-F選擇不請求DataPull,它會響應snoop,然后可以稍后發送讀請求以獲取緩存行。有關DataPull允許的所有Snoop響應的信息,請參閱AMBA 5 CHI架構規范。在本節中,我們描述了RF-F利用DataPull機制作為貯存事務的一部分接收數據的過程。DataPull的完整事務流程如下:1.HN-F發出貯存Snoop并將Snoop Flit中的DoNotDataPull字段設置為0。這表明RN-F貯存目標可以請求DataPull。2.接收到DoNotDataPull = 0的RN-F可以選擇在其Snoop響應中請求DataPull。在此示例中,RN-F選擇請求DataPull。3.RN-F通過在Response Flit中設置兩個字段來請求DataPull:? 將DataPull字段設置為1? 使用將用于返回讀數據的TxnID填充DBID字段4.RN-F接收到讀取的數據。5.RN-F向HN-F發送CompAck消息。以下圖示顯示了StashOnceUnique事務的DataPull機制的時序: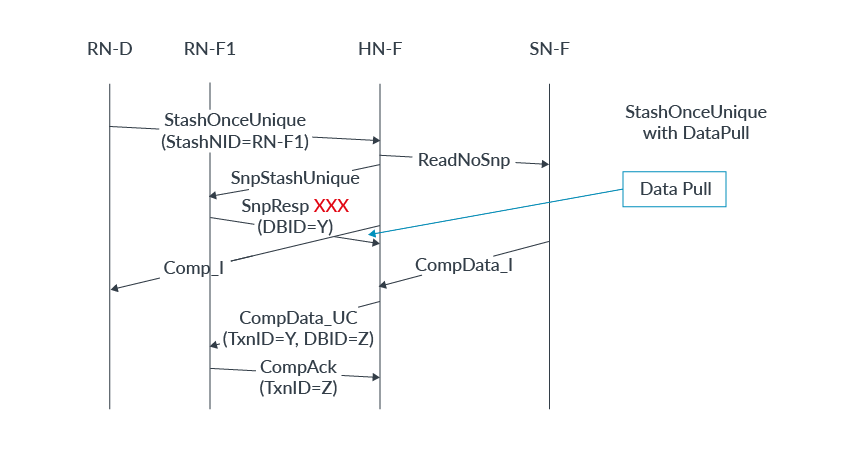 在此圖示中,示例系統包含:發起請求的一個RN-D一個作為貯存目標的RN-F一個HN-F一個SN-F示例中的完整事務流程如下:1.RN-D向HN-F發出StashOnceUnique請求。StashNID字段的值表示RN-F1是貯存目標。2.HN-F接受貯存請求。3.HN-F發出:? 一個ReadNoSnp請求到SN-F? 一個SnpStashUnique Snoop到RN-F14.HN-F向RN-D發送完成響應。5.RN-F1接受貯存暗示。6.RN-F1使用SnpResp_I_Read DataPull請求響應SnpStashUnique。SnpResp_I_Read響應表示隱式讀請求。DBID字段將事務ID設置為Y。7.SN-F將緩存行返回給HN-F。8.HN-F將緩存行轉發給RN-F1,其中:? TxnID = Y? DBID = Z9.RN-F1向HN-F發出完成確認響應,TxnID = Z。下一個示例顯示了WriteUniquePtlStash事務的DataPull機制的時序:
在此圖示中,示例系統包含:發起請求的一個RN-D一個作為貯存目標的RN-F一個HN-F一個SN-F示例中的完整事務流程如下:1.RN-D向HN-F發出StashOnceUnique請求。StashNID字段的值表示RN-F1是貯存目標。2.HN-F接受貯存請求。3.HN-F發出:? 一個ReadNoSnp請求到SN-F? 一個SnpStashUnique Snoop到RN-F14.HN-F向RN-D發送完成響應。5.RN-F1接受貯存暗示。6.RN-F1使用SnpResp_I_Read DataPull請求響應SnpStashUnique。SnpResp_I_Read響應表示隱式讀請求。DBID字段將事務ID設置為Y。7.SN-F將緩存行返回給HN-F。8.HN-F將緩存行轉發給RN-F1,其中:? TxnID = Y? DBID = Z9.RN-F1向HN-F發出完成確認響應,TxnID = Z。下一個示例顯示了WriteUniquePtlStash事務的DataPull機制的時序: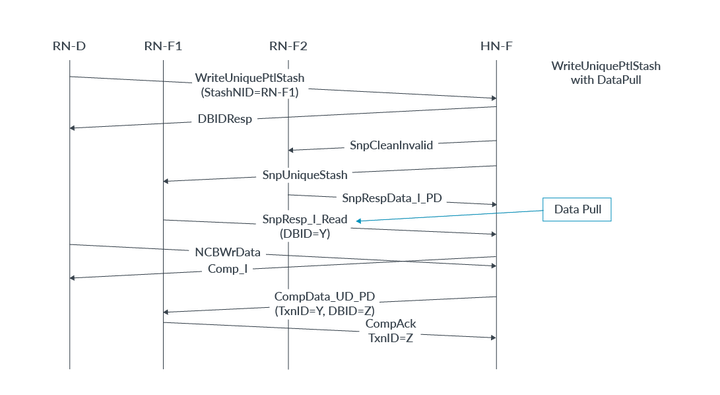 在此示例中,系統具有:? 一個RN-D節點? 兩個RN-F節點:RN-F1和RN-F2。當發送貯存請求時,RN-F2持有緩存行。? 一個HN-F節點示例中的事務流程如下:1.RN-D向HN-F發出WriteUniquePtlStash請求。貯存目標是RN-F1。2.HN-F接受貯存請求。3.HN-F向RN-D返回DBIDResp。4.HN-F生成一個SnpCleanInvalid Snoop到RN-F2。這是因為RN-F2持有緩存行,并將SnpUniqueStash發送到貯存目標RN-F1。5.RN-F2使緩存行無效。6.RN-F2返回一個帶有Dirty數據的Snoop響應給HN-F。7.RN-F1發出一個帶有隱式讀請求的Snoop響應。DBID字段將貯存數據的TxnID設置為Y。8.HN-F接收到Snoop響應。9.HN-F向RN-D發出完成響應。10.RN-D將貯存請求的寫數據發送給HN-F。HN-F現在同時擁有寫數據和Snoop響應中的數據。HN-F為緩存行創建新數據。11.NH-F將緩存行的所有權發送給RN-F1。響應字段為:? TxnID = Y? DBID = Z12.RN-F1發送一個帶有TxnID = Z的CompAck響應。7. I/O釋放(Deallocation)CHI-B為I/O請求者提供了釋放(deallocation)完全一致性節點里的緩存行的能力。I/O deallocate事務提供了一個暗示,即應該使cacheline無效,并且臟數據應該寫回到內存或丟棄。因為這些請求僅僅是暗示,一個完全一致節點可以選擇不使緩存行無效,而只是將數據返回給I/O請求者。換句話說,如果忽略了使緩存行無效的暗示,這些請求將被視為普通的ReadOnce事務。因為可以被忽略,I/O釋放請求不是緩存維護操作CMO的替代品。CHI為I/O釋放定義了兩種請求類型:ReadOnceCleanInvalid和ReadOnceMakeInvalid。這兩種請求都有助于避免cache污染,因為在不久的將來不再使用這些數據。這兩種請求類型的區別在于,ReadOnceMakeInvalid不需要將臟數據寫入到下一級內存,這可能導致系統中的臟數據被丟棄。在使用這種類型的請求時必須謹慎。I/O釋放事務示例本節描述兩個示例。第一個示例使用ReadOnceCleanInvalid并將臟數據寫回主內存。第二個示例使用ReadOnceMakeInvalid并丟棄臟數據。這兩個示例中的系統都有:完全一致請求節點(RN-F)。RN-F以臟狀態持有請求的緩存行I/O一致請求節點(RN-I)CHI互連主存在第一個示例中,ReadOnceCleanInvalid事務讀取數據使其無效,并將其寫回主存。完整流程如下:1. RN-I向HN-F發出ReadOnceCleanInvalid事務,如下圖所示:
在此示例中,系統具有:? 一個RN-D節點? 兩個RN-F節點:RN-F1和RN-F2。當發送貯存請求時,RN-F2持有緩存行。? 一個HN-F節點示例中的事務流程如下:1.RN-D向HN-F發出WriteUniquePtlStash請求。貯存目標是RN-F1。2.HN-F接受貯存請求。3.HN-F向RN-D返回DBIDResp。4.HN-F生成一個SnpCleanInvalid Snoop到RN-F2。這是因為RN-F2持有緩存行,并將SnpUniqueStash發送到貯存目標RN-F1。5.RN-F2使緩存行無效。6.RN-F2返回一個帶有Dirty數據的Snoop響應給HN-F。7.RN-F1發出一個帶有隱式讀請求的Snoop響應。DBID字段將貯存數據的TxnID設置為Y。8.HN-F接收到Snoop響應。9.HN-F向RN-D發出完成響應。10.RN-D將貯存請求的寫數據發送給HN-F。HN-F現在同時擁有寫數據和Snoop響應中的數據。HN-F為緩存行創建新數據。11.NH-F將緩存行的所有權發送給RN-F1。響應字段為:? TxnID = Y? DBID = Z12.RN-F1發送一個帶有TxnID = Z的CompAck響應。7. I/O釋放(Deallocation)CHI-B為I/O請求者提供了釋放(deallocation)完全一致性節點里的緩存行的能力。I/O deallocate事務提供了一個暗示,即應該使cacheline無效,并且臟數據應該寫回到內存或丟棄。因為這些請求僅僅是暗示,一個完全一致節點可以選擇不使緩存行無效,而只是將數據返回給I/O請求者。換句話說,如果忽略了使緩存行無效的暗示,這些請求將被視為普通的ReadOnce事務。因為可以被忽略,I/O釋放請求不是緩存維護操作CMO的替代品。CHI為I/O釋放定義了兩種請求類型:ReadOnceCleanInvalid和ReadOnceMakeInvalid。這兩種請求都有助于避免cache污染,因為在不久的將來不再使用這些數據。這兩種請求類型的區別在于,ReadOnceMakeInvalid不需要將臟數據寫入到下一級內存,這可能導致系統中的臟數據被丟棄。在使用這種類型的請求時必須謹慎。I/O釋放事務示例本節描述兩個示例。第一個示例使用ReadOnceCleanInvalid并將臟數據寫回主內存。第二個示例使用ReadOnceMakeInvalid并丟棄臟數據。這兩個示例中的系統都有:完全一致請求節點(RN-F)。RN-F以臟狀態持有請求的緩存行I/O一致請求節點(RN-I)CHI互連主存在第一個示例中,ReadOnceCleanInvalid事務讀取數據使其無效,并將其寫回主存。完整流程如下:1. RN-I向HN-F發出ReadOnceCleanInvalid事務,如下圖所示: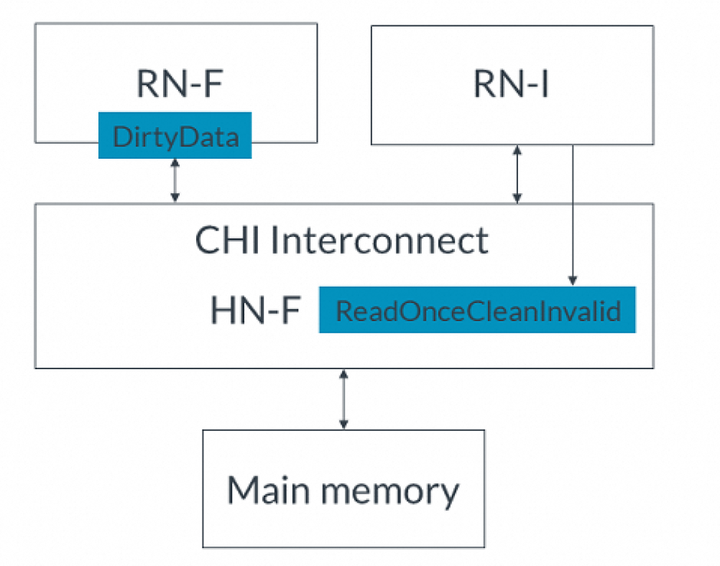 2. HN-F向RN-F發送SnpUnique請求,請求緩存行,如下圖所示:
2. HN-F向RN-F發送SnpUnique請求,請求緩存行,如下圖所示: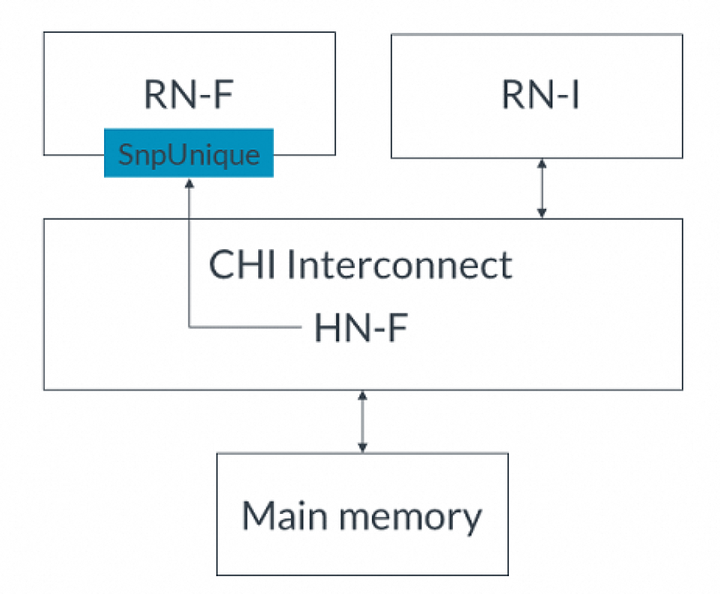 3. RN-F使緩存行無效并將臟數據發送到HN-F。4. HN-F將數據返回給RN-I并將數據寫入主內存,使其保持干凈狀態。在第二個示例中,ReadOnceMakeInvalid事務讀取數據并使RN-F中的緩存行無效,但是沒有將臟數據寫入主內存,而是丟棄了數據。完整流程如下:RN-I向HN-F發出ReadOnceMakeInvalid事務。HN-F向RN-F發送SnpUnique請求,請求緩存行。RN-F使緩存行無效并將臟數據發送到HN-F。HN-F將數據返回給RN-I,然后丟棄臟數據。注:如果在代理讀取已失效的臟緩存行之前將其覆蓋,ReadOnceMakeInvalid請求可能導致數據丟失。僅在知道將來不再使用此數據時才使用此事務。8. DMT、DCT和PrefetchTgt在CHI-A中,讀數據和Snoop數據都通過Home Node傳輸,然后發起請求的節點才接收到它。通過Home Node傳輸增加了這些請求的訪問延遲。為了減少延遲,CHI-B增加了直接內存傳輸(DMT)和直接緩存傳輸(DCT)機制。下表總結了CHI-A和CHI-B中從SN或RN到RN的數據傳輸差異:
3. RN-F使緩存行無效并將臟數據發送到HN-F。4. HN-F將數據返回給RN-I并將數據寫入主內存,使其保持干凈狀態。在第二個示例中,ReadOnceMakeInvalid事務讀取數據并使RN-F中的緩存行無效,但是沒有將臟數據寫入主內存,而是丟棄了數據。完整流程如下:RN-I向HN-F發出ReadOnceMakeInvalid事務。HN-F向RN-F發送SnpUnique請求,請求緩存行。RN-F使緩存行無效并將臟數據發送到HN-F。HN-F將數據返回給RN-I,然后丟棄臟數據。注:如果在代理讀取已失效的臟緩存行之前將其覆蓋,ReadOnceMakeInvalid請求可能導致數據丟失。僅在知道將來不再使用此數據時才使用此事務。8. DMT、DCT和PrefetchTgt在CHI-A中,讀數據和Snoop數據都通過Home Node傳輸,然后發起請求的節點才接收到它。通過Home Node傳輸增加了這些請求的訪問延遲。為了減少延遲,CHI-B增加了直接內存傳輸(DMT)和直接緩存傳輸(DCT)機制。下表總結了CHI-A和CHI-B中從SN或RN到RN的數據傳輸差異: 為了支持DMT和DCT操作,在請求、Snoop和數據flit中添加了額外的標識符。這些額外的字段指定了以下信息,以便正確地將數據和任何需要的響應路由到正確的端點:讀數據的最終目標(end target)原始請求的TxnID向SN-F發出請求的HN,或者向RN-F發出Snoop的HN。HN仍然需要CompAck通知,說明DMT或DCT已完成。CHI-B還增加了Prefetch Target(PrefetchTgt)事務,以減少內存訪問的延遲。PrefetchTgt直接從RN-F發送到SN-F,不需要返回任何數據。存儲器控制器可以將此作為提示,并為PrefetchTgt請求緩沖數據。如果在數據位于緩沖區時收到對該數據的普通請求,緩沖區將提供更快的訪問時間。本節描述DMT、DCT和PrefetchTgt的事務流程,并描述每個flit中的額外標識符字段,使用示例說明如何在每個消息中分配標識符字段。8.1 直接內存傳輸(DMT)在以下示例中,可以比較讀請求在有DMT和沒有DMT的情況下,讀取數據所采取的路徑。對于沒有DMT的讀請求,事務流程如下:CPU向HN-F發出讀請求。HN-F在地址上緩存未命中,并向內存控制器發出讀請求。內存控制器獲取讀請求的數據,然后將數據發送回HN-F。HN-F將讀取的數據返回給請求緩存行的CPU。在到達目的地之前,讀取的數據需要返回到HN-F。使用DMT的事務流程如下:CPU向HN-F發出讀請求。HN-F在地址上緩存未命中,并向內存控制器發出讀請求。內存控制器獲取讀請求的數據。內存控制器將數據直接發送給CPU,而不經過HN-F。使用DMT時,讀取的數據繞過HN-F,直接發送給發出讀請求的CPU。大多數讀請求都可以使用DMT機制,包括由cache stash操作產生的隱式DataPull讀。不能使用DMT的請求包括:獨占(exclusive)訪問ReadNoSnp請求,其中ExpCompAck = 0 且 Order != 0ReadOnce請求,其中ExpCompAck = 0 且 Order != 0為了支持DMT,CHI包含以下標識符字段:請求Flit使用返回節點ID(ReturnNID)和返回事務ID(ReturnTxnID)字段數據Flit使用Home node ID(HomeNID)字段下面的示例顯示了DMT事務的流程,重點關注標識符字段的使用:
為了支持DMT和DCT操作,在請求、Snoop和數據flit中添加了額外的標識符。這些額外的字段指定了以下信息,以便正確地將數據和任何需要的響應路由到正確的端點:讀數據的最終目標(end target)原始請求的TxnID向SN-F發出請求的HN,或者向RN-F發出Snoop的HN。HN仍然需要CompAck通知,說明DMT或DCT已完成。CHI-B還增加了Prefetch Target(PrefetchTgt)事務,以減少內存訪問的延遲。PrefetchTgt直接從RN-F發送到SN-F,不需要返回任何數據。存儲器控制器可以將此作為提示,并為PrefetchTgt請求緩沖數據。如果在數據位于緩沖區時收到對該數據的普通請求,緩沖區將提供更快的訪問時間。本節描述DMT、DCT和PrefetchTgt的事務流程,并描述每個flit中的額外標識符字段,使用示例說明如何在每個消息中分配標識符字段。8.1 直接內存傳輸(DMT)在以下示例中,可以比較讀請求在有DMT和沒有DMT的情況下,讀取數據所采取的路徑。對于沒有DMT的讀請求,事務流程如下:CPU向HN-F發出讀請求。HN-F在地址上緩存未命中,并向內存控制器發出讀請求。內存控制器獲取讀請求的數據,然后將數據發送回HN-F。HN-F將讀取的數據返回給請求緩存行的CPU。在到達目的地之前,讀取的數據需要返回到HN-F。使用DMT的事務流程如下:CPU向HN-F發出讀請求。HN-F在地址上緩存未命中,并向內存控制器發出讀請求。內存控制器獲取讀請求的數據。內存控制器將數據直接發送給CPU,而不經過HN-F。使用DMT時,讀取的數據繞過HN-F,直接發送給發出讀請求的CPU。大多數讀請求都可以使用DMT機制,包括由cache stash操作產生的隱式DataPull讀。不能使用DMT的請求包括:獨占(exclusive)訪問ReadNoSnp請求,其中ExpCompAck = 0 且 Order != 0ReadOnce請求,其中ExpCompAck = 0 且 Order != 0為了支持DMT,CHI包含以下標識符字段:請求Flit使用返回節點ID(ReturnNID)和返回事務ID(ReturnTxnID)字段數據Flit使用Home node ID(HomeNID)字段下面的示例顯示了DMT事務的流程,重點關注標識符字段的使用: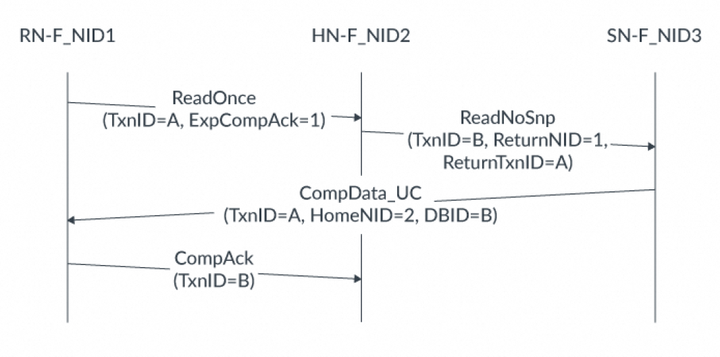 示例中的DMT流程以如下方式使用標識符字段:RN-F向HN-F發送TxnID = A和ExpCompAck = 1的ReadOnce請求HN-F的緩存中沒有請求的數據,因此它向SN-F發ReadNoSnp請求。ReadNoSnp請求包括:TxnID = BReturnNID = 1。這表示應將讀取的數據發送到節點ID為1的RN-FReturnTxnID = A。這與原始ReadOnce請求的TxnID匹配當SN-F準備好返回數據時,它發送帶有以下內容的CompData_UC消息:TxnID = A。這與SN-F收到的ReturnTxnID的值匹配HomeNID = 2。這是HN-F的節點IDDBID = B。這與HN-F發送的ReadNoSnp的TxnID匹配RN-F向HN-F發送具有TxnID = B的CompAck消息。這與CompData_UC中的DBID字段匹配。HN-F收到CompAck后,可以停止跟蹤它發送給SN-F的ReadNoSnp消息。在CHI-B中,針對某些 ReadOnce和ReadNoSnp事務,包含了一種優化的DMT順序。該順序要求SN-F節點識別請求Order字段中的值0x1,并向HN-F發送ReadReceipt響應。此項新增功能可減少HN-F節點處事務的生命周期,從而有可能釋放資源。相比之下,CHI-A在Order 字段中將值 0x1 標記為保留,并且不要求SN-F提供 ReadReceipt。允許發送 ReadReceipt響應的節點是HN至RN 和 SN-I至HN-I。下圖顯示了一個ReadOnce事務的優化的DMT示例,其中HN-F緩存中沒有請求的地址:
示例中的DMT流程以如下方式使用標識符字段:RN-F向HN-F發送TxnID = A和ExpCompAck = 1的ReadOnce請求HN-F的緩存中沒有請求的數據,因此它向SN-F發ReadNoSnp請求。ReadNoSnp請求包括:TxnID = BReturnNID = 1。這表示應將讀取的數據發送到節點ID為1的RN-FReturnTxnID = A。這與原始ReadOnce請求的TxnID匹配當SN-F準備好返回數據時,它發送帶有以下內容的CompData_UC消息:TxnID = A。這與SN-F收到的ReturnTxnID的值匹配HomeNID = 2。這是HN-F的節點IDDBID = B。這與HN-F發送的ReadNoSnp的TxnID匹配RN-F向HN-F發送具有TxnID = B的CompAck消息。這與CompData_UC中的DBID字段匹配。HN-F收到CompAck后,可以停止跟蹤它發送給SN-F的ReadNoSnp消息。在CHI-B中,針對某些 ReadOnce和ReadNoSnp事務,包含了一種優化的DMT順序。該順序要求SN-F節點識別請求Order字段中的值0x1,并向HN-F發送ReadReceipt響應。此項新增功能可減少HN-F節點處事務的生命周期,從而有可能釋放資源。相比之下,CHI-A在Order 字段中將值 0x1 標記為保留,并且不要求SN-F提供 ReadReceipt。允許發送 ReadReceipt響應的節點是HN至RN 和 SN-I至HN-I。下圖顯示了一個ReadOnce事務的優化的DMT示例,其中HN-F緩存中沒有請求的地址: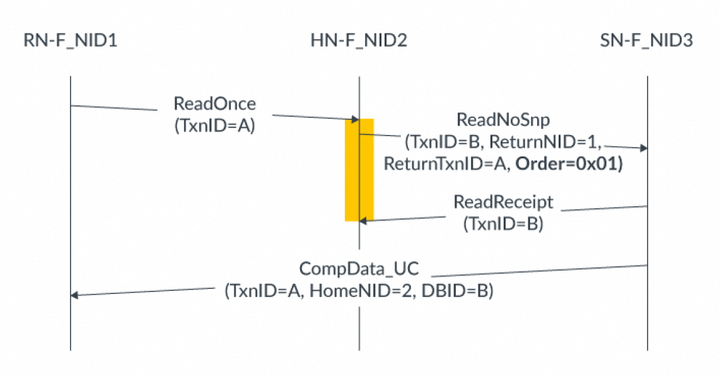 在此示例中,事務流程如下:RN-F向HN-F發出TxnID = A的ReadOnce請求。HN-F向SN-F發出ReadNoSnp請求:Order = 0x01,TxnID = B。ReturnNID字段獲取RN-F的節點ID。ReturnTxnID字段獲取原始ReadOnce請求的TxnID。SN-F接受事務。SN-F向HN-F發出ReadReceipt。當數據準備好時,SN-F使用原始TxnID將讀數據發送到RN-F。HN-F收到ReadReceipt后,立即deallocate請求。這種deallocates減少了HN-F處事務的生命周期,并釋放了資源。如果是CHI-A,那么HN-F需要等待從RN-F收到CompAck 響應,然后才能停止跟蹤ReadNoSnp事務。8.2 prefetch target為了進一步增強DMT,CHI-B提供了PrefetchTgt請求,以減少SN-F處內存訪問延遲。PrefetchTgt消息是從RN直接發送到SN-F的提示。該請求不需要響應,因此RN不會將其作為未完成(outstanding)請求進行跟蹤。SN-F可以選擇忽略請求,或者獲取指定地址的數據。如果SN-F決定獲取數據,它會將數據緩沖,直到收到該地址的正常讀請求。假設在不久的將來,通過HN-F節點的正常路徑上會有一個單獨的讀事務。在SN-F處對數據進行緩沖可減少讀事務的內存訪問延遲,并隱藏HN-F系統緩存中進行的本地查找的任何額外延遲。由于不需要響應,PrefetchTgt中的TxnID字段不適用,CHI-B要求在發送請求時將其設置為0。例如,RN向SN-F發出請求。這是完成PrefectTgt事務所需的唯一步驟,雙方都不會發送其他Flit。PrefetchTgt請求可能會提前很長時間發送,以至于SN-F會將緩沖數據驅逐(evict)出去,為其他讀請求騰出空間。為了避免PrefetchTgt請求造成擁塞,CHI-B使用Data Flit中的DataSource字段來報告使用PrefetchTgt的有效性。此字段由內存控制器設置,表示讀取的數據是否受益于之前的PrefetchTgt提示。DataSource字段可能的值為:0x6表示PrefetchTgt請求有用0x7表示讀取的數據未從PrefetchTgt中受益,且無效如果足夠多的PrefetchTgt請求被確定為無效,RN可以停止發出這些請求。通常,RN只實現RN系統地址映射(RN SAM)。此SAM針對HN-F,且不知道SN-F的節點ID。為了支持PrefetchTgt事務,RN也需要HN系統地址映射。HN SAM將地址轉換為SN-F TgtID。例如,PrefetchTgt提示可以用來優化DMT。CPU在DMT讀取未命中之前發出PrefetchTgt請求。在PrefetchTgt事務之后,當DDR控制器收到讀請求時,已經準備好讀數據。完整流程如下:CPU向DDR控制器發出PrefetchTgt提示。DDR控制器接受提示并開始獲取數據。兩件事情并行發生:CPU向HN-F發出與PrefetchTgt相同地址的讀請求;DDR控制器開始接收讀數據并將其緩沖,以備后續讀取。CPU向HN-F發出讀請求。讀請求在HN-F處緩存未命中。HN-F向DDR內存發出讀請求。由于數據已經在DDR控制器處緩沖,DDR立即將讀取的數據返回給CPU。通過使用PrefetchTgt請求,DMT讀事務在DDR內存訪問中幾乎沒有延遲。8.3 直接緩存傳輸(DCT)為了減少監聽命中延遲,CHI-B使用直接緩存傳輸機制(DCT)。DCT類似于對監聽的DMT,并允許從RN-F的監聽數據繞過HN-F,直接到達原始請求者。當數據需要在請求者之間來回傳輸時,此機制有助于提高系統性能。受益于DCT的用例包括信號量(semaphores)和生產者-消費者工作負載。可以比較讀請求在使用和不使用DCT的情況下讀數據的路徑。在沒有DCT的情況下,整個系統流程如下:CPU A向HN-F發出讀請求。該請求在HN-F處緩存未命中。HN-F向持有緩存行的CPU B發出監聽。CPU B將緩存行的數據返回給HN-F。HN-F將數據返回給CPU A。使用相同的初始事務并添加DCT,整個系統流程有如下優化:CPU A向HN-F發出讀請求。該請求在HN-F處緩存未命中。HN-F向持有緩存行的CPU B發出監聽。CPU B繞過HN-F,直接將數據返回給發出讀請求的CPU A。通過使用DCT,snoop hit的訪問延遲得到降低。8.4 forward snoop請求為了支持DCT,CHI-B增加了forward snoop請求。forward snoop請求告訴被監聽的RN-F將監聽數據直接發送到原始請求者。除了原子事務和獨占讀取外,所有可監聽的讀都可以使用DCT。forward snoop在監聽Flit中引入了新的標識符字段,如下所示:forward節點ID(FwdNID),其功能類似于DMT中的ReturnNID。它保存原始請求者的節點ID。forward事務ID(FwdTxnID),其功能類似于DMT中的ReturnTxnID。它保存原始讀請求的TxnID。Return To Source (RetToSrc)指示RN-F除了要把監聽數據發送給請求的RN-F,還要發送給HN-F。將數據發送到HN-F可以使將來針對該地址的請求在HN-F緩存中命中,并避免產生額外的監聽。在響應forward snoop時,響應和數據Flit都使用新的forward狀態(FwdState)字段。該字段告訴HN-F在任何本地監聽過濾器跟蹤中,向請求RN-F提供了什么緩存狀態。被監聽的RN-F中的cache state,即forward snoop的結果,會像往常一樣在RESP字段中提供給請求RN-F。原始請求者會在CompData消息中接收到監聽數據,作為正常的讀數據響應,如下圖所示:
在此示例中,事務流程如下:RN-F向HN-F發出TxnID = A的ReadOnce請求。HN-F向SN-F發出ReadNoSnp請求:Order = 0x01,TxnID = B。ReturnNID字段獲取RN-F的節點ID。ReturnTxnID字段獲取原始ReadOnce請求的TxnID。SN-F接受事務。SN-F向HN-F發出ReadReceipt。當數據準備好時,SN-F使用原始TxnID將讀數據發送到RN-F。HN-F收到ReadReceipt后,立即deallocate請求。這種deallocates減少了HN-F處事務的生命周期,并釋放了資源。如果是CHI-A,那么HN-F需要等待從RN-F收到CompAck 響應,然后才能停止跟蹤ReadNoSnp事務。8.2 prefetch target為了進一步增強DMT,CHI-B提供了PrefetchTgt請求,以減少SN-F處內存訪問延遲。PrefetchTgt消息是從RN直接發送到SN-F的提示。該請求不需要響應,因此RN不會將其作為未完成(outstanding)請求進行跟蹤。SN-F可以選擇忽略請求,或者獲取指定地址的數據。如果SN-F決定獲取數據,它會將數據緩沖,直到收到該地址的正常讀請求。假設在不久的將來,通過HN-F節點的正常路徑上會有一個單獨的讀事務。在SN-F處對數據進行緩沖可減少讀事務的內存訪問延遲,并隱藏HN-F系統緩存中進行的本地查找的任何額外延遲。由于不需要響應,PrefetchTgt中的TxnID字段不適用,CHI-B要求在發送請求時將其設置為0。例如,RN向SN-F發出請求。這是完成PrefectTgt事務所需的唯一步驟,雙方都不會發送其他Flit。PrefetchTgt請求可能會提前很長時間發送,以至于SN-F會將緩沖數據驅逐(evict)出去,為其他讀請求騰出空間。為了避免PrefetchTgt請求造成擁塞,CHI-B使用Data Flit中的DataSource字段來報告使用PrefetchTgt的有效性。此字段由內存控制器設置,表示讀取的數據是否受益于之前的PrefetchTgt提示。DataSource字段可能的值為:0x6表示PrefetchTgt請求有用0x7表示讀取的數據未從PrefetchTgt中受益,且無效如果足夠多的PrefetchTgt請求被確定為無效,RN可以停止發出這些請求。通常,RN只實現RN系統地址映射(RN SAM)。此SAM針對HN-F,且不知道SN-F的節點ID。為了支持PrefetchTgt事務,RN也需要HN系統地址映射。HN SAM將地址轉換為SN-F TgtID。例如,PrefetchTgt提示可以用來優化DMT。CPU在DMT讀取未命中之前發出PrefetchTgt請求。在PrefetchTgt事務之后,當DDR控制器收到讀請求時,已經準備好讀數據。完整流程如下:CPU向DDR控制器發出PrefetchTgt提示。DDR控制器接受提示并開始獲取數據。兩件事情并行發生:CPU向HN-F發出與PrefetchTgt相同地址的讀請求;DDR控制器開始接收讀數據并將其緩沖,以備后續讀取。CPU向HN-F發出讀請求。讀請求在HN-F處緩存未命中。HN-F向DDR內存發出讀請求。由于數據已經在DDR控制器處緩沖,DDR立即將讀取的數據返回給CPU。通過使用PrefetchTgt請求,DMT讀事務在DDR內存訪問中幾乎沒有延遲。8.3 直接緩存傳輸(DCT)為了減少監聽命中延遲,CHI-B使用直接緩存傳輸機制(DCT)。DCT類似于對監聽的DMT,并允許從RN-F的監聽數據繞過HN-F,直接到達原始請求者。當數據需要在請求者之間來回傳輸時,此機制有助于提高系統性能。受益于DCT的用例包括信號量(semaphores)和生產者-消費者工作負載。可以比較讀請求在使用和不使用DCT的情況下讀數據的路徑。在沒有DCT的情況下,整個系統流程如下:CPU A向HN-F發出讀請求。該請求在HN-F處緩存未命中。HN-F向持有緩存行的CPU B發出監聽。CPU B將緩存行的數據返回給HN-F。HN-F將數據返回給CPU A。使用相同的初始事務并添加DCT,整個系統流程有如下優化:CPU A向HN-F發出讀請求。該請求在HN-F處緩存未命中。HN-F向持有緩存行的CPU B發出監聽。CPU B繞過HN-F,直接將數據返回給發出讀請求的CPU A。通過使用DCT,snoop hit的訪問延遲得到降低。8.4 forward snoop請求為了支持DCT,CHI-B增加了forward snoop請求。forward snoop請求告訴被監聽的RN-F將監聽數據直接發送到原始請求者。除了原子事務和獨占讀取外,所有可監聽的讀都可以使用DCT。forward snoop在監聽Flit中引入了新的標識符字段,如下所示:forward節點ID(FwdNID),其功能類似于DMT中的ReturnNID。它保存原始請求者的節點ID。forward事務ID(FwdTxnID),其功能類似于DMT中的ReturnTxnID。它保存原始讀請求的TxnID。Return To Source (RetToSrc)指示RN-F除了要把監聽數據發送給請求的RN-F,還要發送給HN-F。將數據發送到HN-F可以使將來針對該地址的請求在HN-F緩存中命中,并避免產生額外的監聽。在響應forward snoop時,響應和數據Flit都使用新的forward狀態(FwdState)字段。該字段告訴HN-F在任何本地監聽過濾器跟蹤中,向請求RN-F提供了什么緩存狀態。被監聽的RN-F中的cache state,即forward snoop的結果,會像往常一樣在RESP字段中提供給請求RN-F。原始請求者會在CompData消息中接收到監聽數據,作為正常的讀數據響應,如下圖所示: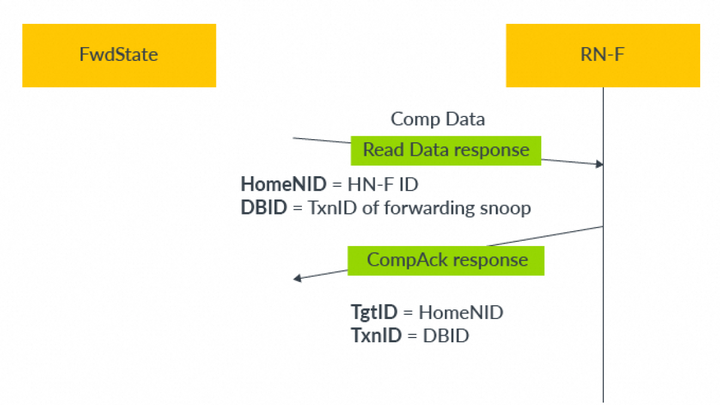 在此圖中,響應包含與DMT響應相同的HomeNID和DBID字段:HomeNID字段包含被繞過的HN-F的節點IDDBID字段包含forward snoop的TxnID然后,RN-F將這些字段用作發送給HN-F的CompAck響應的TgtID和TxnID。以下兩個示例展示了當RetToSrc設置為0或1時,標識符字段如何填充。下圖顯示了當RetToSrc = 0時,DCT的事務流程:
在此圖中,響應包含與DMT響應相同的HomeNID和DBID字段:HomeNID字段包含被繞過的HN-F的節點IDDBID字段包含forward snoop的TxnID然后,RN-F將這些字段用作發送給HN-F的CompAck響應的TgtID和TxnID。以下兩個示例展示了當RetToSrc設置為0或1時,標識符字段如何填充。下圖顯示了當RetToSrc = 0時,DCT的事務流程: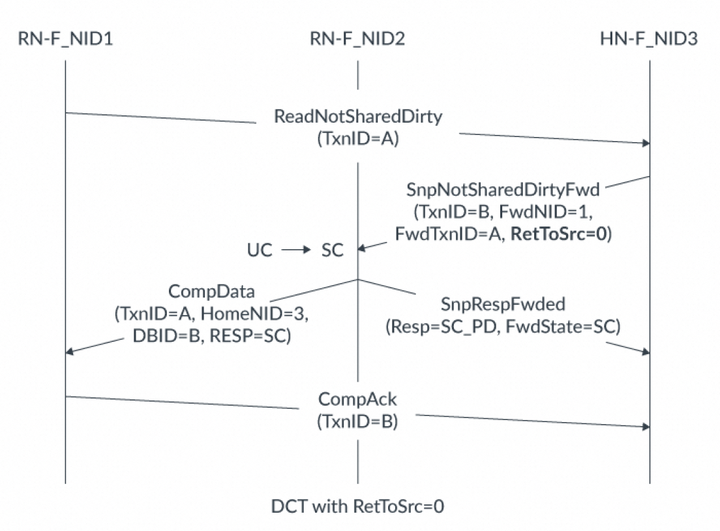 在此圖中,事務流程如下:RN-F_NID1向HN-F發送ReadNotSharedDirty請求。該請求TxnID = A。該請求在HN-F處緩存未命中。HN-F向RN-F_NID2發出SnpNotSharedDirtyFwd監聽。監聽具有:TxnID = B。FwdNID = 1,該值與RN-F_NID1的節點ID匹配,表示它是監聽數據的目的地。FwdTxnID = A,該值與讀請求的原始TxnID匹配。RetToSrc = 0由于請求中的RetToSrc設置為0,RN-F_NID2使用SnpRespFwded消息回應HN-F。此響應中有兩個重要字段:RESP顯示緩存行從UC狀態變成SC狀態。FwdState告訴HN-F發送給原始請求者的緩存狀態。在此示例中,即SC狀態。RN-F_NID2向RN-F_NID1發送CompData消息,其中包括:TxnID = A,這是監聽請求中的FwdTxnID值。HomeNID = 3,這是HN-F的節點ID。DBID = B,這是監聽請求的TxnID。RESP = SC(Shared Clean),這顯示了數據以SC狀態提供,與監聽響應中的FwdState字段值相匹配。RN-F_NID1向HN-F發送CompAck消息,TxnID = B。這完成了ReadNotSharedDirty請求。下圖顯示了相同的ReadNotSharedDirty請求,但RetToSrc = 1:
在此圖中,事務流程如下:RN-F_NID1向HN-F發送ReadNotSharedDirty請求。該請求TxnID = A。該請求在HN-F處緩存未命中。HN-F向RN-F_NID2發出SnpNotSharedDirtyFwd監聽。監聽具有:TxnID = B。FwdNID = 1,該值與RN-F_NID1的節點ID匹配,表示它是監聽數據的目的地。FwdTxnID = A,該值與讀請求的原始TxnID匹配。RetToSrc = 0由于請求中的RetToSrc設置為0,RN-F_NID2使用SnpRespFwded消息回應HN-F。此響應中有兩個重要字段:RESP顯示緩存行從UC狀態變成SC狀態。FwdState告訴HN-F發送給原始請求者的緩存狀態。在此示例中,即SC狀態。RN-F_NID2向RN-F_NID1發送CompData消息,其中包括:TxnID = A,這是監聽請求中的FwdTxnID值。HomeNID = 3,這是HN-F的節點ID。DBID = B,這是監聽請求的TxnID。RESP = SC(Shared Clean),這顯示了數據以SC狀態提供,與監聽響應中的FwdState字段值相匹配。RN-F_NID1向HN-F發送CompAck消息,TxnID = B。這完成了ReadNotSharedDirty請求。下圖顯示了相同的ReadNotSharedDirty請求,但RetToSrc = 1: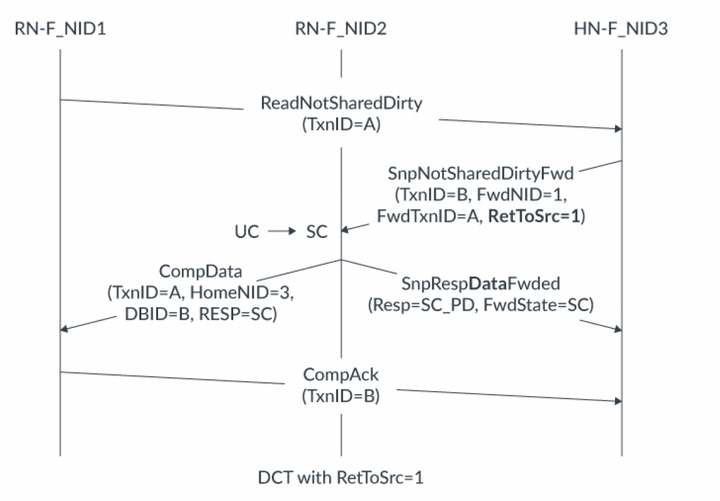 在此圖中,事務流程如下:1.RN-F_NID1向HN-F發出TxnID = A的ReadNotSharedDirty請求。2.請求在HN-F處緩存未命中。3.HN-F向RN-F_NID2發出SnpNotSharedDirtyFwd監聽。監聽具有:TxnID = BFwdNID = 1FwdTxnID = ARetToSrc = 14.RN-F_NID2使用CompData消息將緩存行轉發到RN-F_NID1,其中包含以下字段:TxnID設置為監聽中的FwdTxnID值。DBID設置為監聽中的TxnID值。RESP顯示返回的緩存行可以在SC狀態下緩存。5.由于RetToSrc = 1,RN-F_NID2將緩存行發送到HN-F。緩存行以SnpRespDataFwded消息發送,其中FwdState = SC(共享干凈)和RESP = SC_PD(共享干凈_傳遞臟)。RESP中的此值告訴HN-F,緩存行在RN-F2處于SC狀態,且RN-F2將該緩存行的回寫責任傳遞給HN-F。6.收到監聽數據后,RN-F_NID1向HN-F發送帶有TxnID = B的CompAck響應。9. 原子操作9.1 原子操作基礎為支持Armv8.1架構中添加的原子指令,CHI-B提供了原子事務。互連使用原子事務將原子操作及其操作數從一個設備傳輸到另一個設備。使用原子操作而不是獨占訪問可以減少其他代理無法訪問數據的時間。原子事務可以執行多個原子操作,并且可以在處理器內部或外部執行。原子操作是在沒有另一個請求者干擾的情況下執行的讀-修改-寫序列。與AXI中的獨占訪問一樣,原子事務允許請求者修改內存的特定區域的數據,同時確保其他請求者的寫入不會破壞數據。在AXI3和4以及CHI-A中,請求者獲取數據,執行操作,然后將結果寫回以完成原子訪問。CHI-B包含將原子操作傳輸到互連的選項,這允許操作更靠近數據所在位置執行。這提高了效率,減少了數據對其他請求者不可訪問的時間。為執行原子操作,目標需要一個算術邏輯單元(ALU)。也就是說,要使用原子操作,HN、SN或兩者都需要一個ALU。在CHI-B及更高版本中,原子事務支持是可選的,因此HN和SN并不總是需要具有ALU。請求者有一個配置引腳BROADCASTATOMIC,可以用于在下游系統不支持原子事務時阻止請求者生成原子事務。完整的原子事務結構是:請求者向互連發出原子事務HN或SN具有ALU,因此它執行原子操作根據操作,互連可能將地址的原始數據返回給請求者由RN-F節點在其內部執行的原子操作稱為近原子(near-atomics)。在請求者外部執行的原子操作稱為遠原子(far-atomics)。RN-F可以在其cache系統中執行近原子操作。near-atomics可能發生的原因有:RN-F在其cache中以unique狀態持有數據,因此不需要外部事務。互聯不支持原子事務,因此原子操作必須抑制在請求者處。當互聯支持原子事務時,請求節點(RN)可以向下游發出far-atomics。far-atomics在靠近數據所在的位置執行,無論是在互連中還是在保存數據的下級中。RN節點發far-atomics的原因有:請求節點將cache line保持在一致性節點的share狀態。請求節點不持有cache line。內存位置是非一致性的內存類型。9.2 事務類型CHI-B中添加了以下4種原子事務類型:AtomicStore AtomicLoad AtomicSwap AtomicCompare每個示例中的系統都有一個Requester、內存單元和一個ALU。本節系列圖中的數據表示為:AddrData表示內存中的當前數據TxnData表示隨原子請求發送的數據實線箭頭表示總是傳輸的數據 虛線箭頭表示僅當滿足某些條件時發送的數據。AtomicStore下圖展示了一個AtomicStore在一個完全支持原子的系統中是如何進行的:
在此圖中,事務流程如下:1.RN-F_NID1向HN-F發出TxnID = A的ReadNotSharedDirty請求。2.請求在HN-F處緩存未命中。3.HN-F向RN-F_NID2發出SnpNotSharedDirtyFwd監聽。監聽具有:TxnID = BFwdNID = 1FwdTxnID = ARetToSrc = 14.RN-F_NID2使用CompData消息將緩存行轉發到RN-F_NID1,其中包含以下字段:TxnID設置為監聽中的FwdTxnID值。DBID設置為監聽中的TxnID值。RESP顯示返回的緩存行可以在SC狀態下緩存。5.由于RetToSrc = 1,RN-F_NID2將緩存行發送到HN-F。緩存行以SnpRespDataFwded消息發送,其中FwdState = SC(共享干凈)和RESP = SC_PD(共享干凈_傳遞臟)。RESP中的此值告訴HN-F,緩存行在RN-F2處于SC狀態,且RN-F2將該緩存行的回寫責任傳遞給HN-F。6.收到監聽數據后,RN-F_NID1向HN-F發送帶有TxnID = B的CompAck響應。9. 原子操作9.1 原子操作基礎為支持Armv8.1架構中添加的原子指令,CHI-B提供了原子事務。互連使用原子事務將原子操作及其操作數從一個設備傳輸到另一個設備。使用原子操作而不是獨占訪問可以減少其他代理無法訪問數據的時間。原子事務可以執行多個原子操作,并且可以在處理器內部或外部執行。原子操作是在沒有另一個請求者干擾的情況下執行的讀-修改-寫序列。與AXI中的獨占訪問一樣,原子事務允許請求者修改內存的特定區域的數據,同時確保其他請求者的寫入不會破壞數據。在AXI3和4以及CHI-A中,請求者獲取數據,執行操作,然后將結果寫回以完成原子訪問。CHI-B包含將原子操作傳輸到互連的選項,這允許操作更靠近數據所在位置執行。這提高了效率,減少了數據對其他請求者不可訪問的時間。為執行原子操作,目標需要一個算術邏輯單元(ALU)。也就是說,要使用原子操作,HN、SN或兩者都需要一個ALU。在CHI-B及更高版本中,原子事務支持是可選的,因此HN和SN并不總是需要具有ALU。請求者有一個配置引腳BROADCASTATOMIC,可以用于在下游系統不支持原子事務時阻止請求者生成原子事務。完整的原子事務結構是:請求者向互連發出原子事務HN或SN具有ALU,因此它執行原子操作根據操作,互連可能將地址的原始數據返回給請求者由RN-F節點在其內部執行的原子操作稱為近原子(near-atomics)。在請求者外部執行的原子操作稱為遠原子(far-atomics)。RN-F可以在其cache系統中執行近原子操作。near-atomics可能發生的原因有:RN-F在其cache中以unique狀態持有數據,因此不需要外部事務。互聯不支持原子事務,因此原子操作必須抑制在請求者處。當互聯支持原子事務時,請求節點(RN)可以向下游發出far-atomics。far-atomics在靠近數據所在的位置執行,無論是在互連中還是在保存數據的下級中。RN節點發far-atomics的原因有:請求節點將cache line保持在一致性節點的share狀態。請求節點不持有cache line。內存位置是非一致性的內存類型。9.2 事務類型CHI-B中添加了以下4種原子事務類型:AtomicStore AtomicLoad AtomicSwap AtomicCompare每個示例中的系統都有一個Requester、內存單元和一個ALU。本節系列圖中的數據表示為:AddrData表示內存中的當前數據TxnData表示隨原子請求發送的數據實線箭頭表示總是傳輸的數據 虛線箭頭表示僅當滿足某些條件時發送的數據。AtomicStore下圖展示了一個AtomicStore在一個完全支持原子的系統中是如何進行的: 當ALU 收到 AtomicStore 事務時,它會執行事務子操作碼中指示的子操作。ALU 使用事務中的 TxnData 和 AddrData 作為操作數。運算完成后,ALU 將結果存儲到內存中。AtomicStore可以執行八個子操作碼。這些子操作碼在 AtomicStore 和 AtomicLoad 的子操作碼中進行了審查。一些子操作是有條件的,因此AtomicStore 事務并不總是需要將新數據寫入內存。AtomicLoad下圖顯示了AtomicLoad 如何在完全支持原子的系統中進行:
當ALU 收到 AtomicStore 事務時,它會執行事務子操作碼中指示的子操作。ALU 使用事務中的 TxnData 和 AddrData 作為操作數。運算完成后,ALU 將結果存儲到內存中。AtomicStore可以執行八個子操作碼。這些子操作碼在 AtomicStore 和 AtomicLoad 的子操作碼中進行了審查。一些子操作是有條件的,因此AtomicStore 事務并不總是需要將新數據寫入內存。AtomicLoad下圖顯示了AtomicLoad 如何在完全支持原子的系統中進行: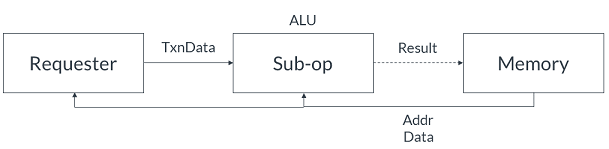 AtomicLoad類似于 AtomicStore,因為它可以執行八個子操作碼并在條件通過時更新內存。子操作碼在 AtomicStore 和AtomicLoad 的子操作碼中進行了審查。AtomicLoad和 AtomicStore 的區別在于 AtomicLoad 將原始的AddrData 值返回給 Requester。AtomicSwap下圖展示了一個AtomicSwap在一個完全支持原子的系統中是如何進行的:
AtomicLoad類似于 AtomicStore,因為它可以執行八個子操作碼并在條件通過時更新內存。子操作碼在 AtomicStore 和AtomicLoad 的子操作碼中進行了審查。AtomicLoad和 AtomicStore 的區別在于 AtomicLoad 將原始的AddrData 值返回給 Requester。AtomicSwap下圖展示了一個AtomicSwap在一個完全支持原子的系統中是如何進行的: AtomicSwap執行無條件性,不執行子操作。AtomicSwap 將TxnData 與指定位置的數據進行交換。新數據寫入內存,原始數據返回給Requester。AtomicCompare AtomicCompare事務與之前的原子事務不同,因為它發送兩個數據值并執行以下操作:SwapValue CompareValue下圖顯示了AtomicCompare 如何在完全支持原子的系統中進行:
AtomicSwap執行無條件性,不執行子操作。AtomicSwap 將TxnData 與指定位置的數據進行交換。新數據寫入內存,原始數據返回給Requester。AtomicCompare AtomicCompare事務與之前的原子事務不同,因為它發送兩個數據值并執行以下操作:SwapValue CompareValue下圖顯示了AtomicCompare 如何在完全支持原子的系統中進行: AtomicCompare的工作方式如下:? ALU獲取當前數據和 CompareValue 并檢查它們是否相等。?事務執行以下操作之一:o如果比較的值相等,則使用 SwapValue 更新內存位置。o如果比較值不相等,則不更新內存。?無論比較結果如何,該內存位置(AddrData)的原始數據總是返回給請求者。AtomicStore 和AtomicLoad的子操作碼 AtomicStore和AtomicLoad 可以執行八個子操作碼。下表總結了這些子操作碼,表示更新內存中的值的條件,以及任何相應的更新值:
AtomicCompare的工作方式如下:? ALU獲取當前數據和 CompareValue 并檢查它們是否相等。?事務執行以下操作之一:o如果比較的值相等,則使用 SwapValue 更新內存位置。o如果比較值不相等,則不更新內存。?無論比較結果如何,該內存位置(AddrData)的原始數據總是返回給請求者。AtomicStore 和AtomicLoad的子操作碼 AtomicStore和AtomicLoad 可以執行八個子操作碼。下表總結了這些子操作碼,表示更新內存中的值的條件,以及任何相應的更新值: AtomicStore 和 AtomicLoad的子操作碼結果檢查原子事務的響應不指示條件原子操作是否成功發生。如果請求者想知道原子事務是否更新了內存位置,請求者會在原子操作完成后執行正常的地址讀取。或者,它可以使用返回的數據來計算條件是否通過。參考:Introducing the AMBA Coherent Hub InterfaceAMBA5 CHI Architecture SpecificationAtomic transactions in AMBA CHI
AtomicStore 和 AtomicLoad的子操作碼結果檢查原子事務的響應不指示條件原子操作是否成功發生。如果請求者想知道原子事務是否更新了內存位置,請求者會在原子操作完成后執行正常的地址讀取。或者,它可以使用返回的數據來計算條件是否通過。參考:Introducing the AMBA Coherent Hub InterfaceAMBA5 CHI Architecture SpecificationAtomic transactions in AMBA CHI

——流式TTS文字轉實時語音播放)

 JNI實現流程源碼分析)
STM32建立HAL工程)





capture使用技巧_1)




)

 ——使用LINQ進行對象類型初始化)

(非常詳細版))