slam14講(第9,10講 后端)
- 后端分類
- 基于濾波器的后端
- 線性系統和卡爾曼濾波
- 非線性系統和擴展卡爾曼濾波
- BA優化
- H矩陣的稀疏性和邊緣化
- H矩陣求解的總結
- 位姿圖優化
- 公式推導
- 基于滑動窗口的后端
- 個人見解
- 舊關鍵幀的邊緣化
后端分類
- 基于濾波器的后端。常見的擴展卡爾曼EKF,無跡卡爾曼UKF,粒子濾波PF,或者是fastlio2中使用的誤差狀態卡爾曼ESIKF(本質上迭代過程等效于高斯牛頓法,優化當前幀的狀態)。還有許多其他濾波器,本質上是基于一階馬爾可夫性假設,就是認為當前的狀態 x k x_k xk?只與 x k ? 1 x_{k-1} xk?1?有關,與歷史之前的狀態無關,來簡化卡爾曼濾波過程中預測更新的運算。
- 基于非線性優化的后端。這種方法就可以考慮第k幀之前所有歷史幀的狀態,類似一個全局的思維,通過構建全局狀態的優化問題,來優化所有幀的狀態(包括位姿和特征點),特別能夠依靠回環檢測來提高狀態的全局一致性。
- 滑動窗口濾波和優化。
(1)滑動窗口濾波其實應該就是基于濾波器的后端的一個變種,認為一階馬爾可夫性假設太極端了,所以想選擇一定數量的關鍵幀,共同考慮多個幀去解算出當前幀的狀態。
(2)滑動窗口優化應該也是基于非線性優化的后端的一個變種,認為隨著SLAM過程,關鍵幀增多,優化耗時會增加,所以想選擇一些離當前時刻接近的關鍵幀而不是全部關鍵幀來一起優化
基于濾波器的后端
這里首先將狀態的符號簡化,狀態包含相機位姿( x k x_k xk?)和特征點( y m y_m ym?)。
x k = def? { x k , y 1 , … , y m } \boldsymbol{x}_k \stackrel{\text { def }}{=}\left\{\boldsymbol{x}_k, \boldsymbol{y}_1, \ldots, \boldsymbol{y}_m\right\} xk?=?def?{xk?,y1?,…,ym?}
那么經典的運動和觀測方程就可以簡化:(注意狀態上的符號, x ^ \hat{\boldsymbol{x}} x^代表狀態的后驗, x ˇ \check{\boldsymbol{x}} xˇ代表狀態的預測,這個定義是為了跟slam14講ppt里一致)
{ x k = f ( x ^ k ? 1 , u k ) + w k z k = h ( x k ) + v k k = 1 , … , N \left\{\begin{array}{l}\boldsymbol{x}_k=f\left(\hat{\boldsymbol{x}}_{k-1}, \boldsymbol{u}_k\right)+\boldsymbol{w}_k \\ \boldsymbol{z}_k=h\left(\boldsymbol{x}_k\right)+\boldsymbol{v}_k\end{array} \quad k=1, \ldots, N\right. {xk?=f(x^k?1?,uk?)+wk?zk?=h(xk?)+vk??k=1,…,N
我們已知的是k-1時刻狀態的后驗 x ^ k ? 1 \hat{x}_{k-1} x^k?1?和輸入 u k u_k uk?,想求的是當前k時刻狀態 x ^ k \hat{x}_{k} x^k?的后驗分布
P ( x ^ k ∣ x 0 , u 1 : k , z 1 : k ) P\left(\hat{\boldsymbol{x}}_k \mid \boldsymbol{x}_0, \boldsymbol{u}_{1: k}, \boldsymbol{z}_{1: k}\right) P(x^k?∣x0?,u1:k?,z1:k?)
根據貝葉斯法則,書上給出的式子是這樣的:
P ( x ^ k ∣ x 0 , u 1 : k , z 1 : k ) ∝ P ( z k ∣ x ˇ k ) P ( x ˇ k ∣ x 0 , u 1 : k , z 1 : k ? 1 ) P\left(\hat{\boldsymbol{x}}_k \mid \boldsymbol{x}_0, \boldsymbol{u}_{1: k}, \boldsymbol{z}_{1: k}\right) \propto P\left(\boldsymbol{z}_k \mid \check{\boldsymbol{x}}_k\right) P\left(\check{\boldsymbol{x}}_k \mid \boldsymbol{x}_0, \boldsymbol{u}_{1: k}, \boldsymbol{z}_{1: k-1}\right) P(x^k?∣x0?,u1:k?,z1:k?)∝P(zk?∣xˇk?)P(xˇk?∣x0?,u1:k?,z1:k?1?)
但是在我看來,假設了一階馬爾可夫性,直接都可以簡化成最基本的貝葉斯濾波的形式。
P ( x ^ k ∣ x ^ k ? 1 , u k , z k ) ∝ P ( z k ∣ x ˇ k ) P ( x ˇ k ∣ x ^ k ? 1 , u k ) P\left(\hat{\boldsymbol{x}}_k \mid \hat{\boldsymbol{x}}_{k-1}, \boldsymbol{u}_{k}, \boldsymbol{z}_{k}\right) \propto P\left(\boldsymbol{z}_k \mid \check{\boldsymbol{x}}_k\right) P\left(\check{\boldsymbol{x}}_k \mid \hat{\boldsymbol{x}}_{k-1}, \boldsymbol{u}_{k}\right) P(x^k?∣x^k?1?,uk?,zk?)∝P(zk?∣xˇk?)P(xˇk?∣x^k?1?,uk?)
很明顯上面式子中左邊的是當前k時刻狀態 x ^ k \hat{x}_{k} x^k?的后驗分布,右邊的第一項是似然分布,第二項是預測即先驗分布。因為后驗分布、似然分布和先驗分布都屬于高斯分布,所以就可以通過經典的卡爾曼濾波公式來求當前k時刻狀態 x ^ k \hat{x}_{k} x^k?的后驗分布。
線性系統和卡爾曼濾波
如果考慮線性系統,那就是經典的卡爾曼濾波系統。運動方程和觀測方程可以由下面的式子表示:
{ x k = A k x k ? 1 + u k + w k z k = C k x k + v k k = 1 , … , N \left\{\begin{array}{l}\boldsymbol{x}_k=\boldsymbol{A}_k \boldsymbol{x}_{k-1}+\boldsymbol{u}_k+\boldsymbol{w}_k \\ \boldsymbol{z}_k=\boldsymbol{C}_k \boldsymbol{x}_k+\boldsymbol{v}_k\end{array} \quad k=1, \ldots, N\right. {xk?=Ak?xk?1?+uk?+wk?zk?=Ck?xk?+vk??k=1,…,N
其中過程噪聲 w k ~ N ( 0 , R ) \boldsymbol{w}_k \sim N(\mathbf{0}, \boldsymbol{R}) wk?~N(0,R) 和觀測噪聲 v k ~ N ( 0 , Q ) \quad \boldsymbol{v}_k \sim N(\mathbf{0}, \boldsymbol{Q}) vk?~N(0,Q) 都服從高斯分布。然后就是根據卡爾曼濾波的5個步驟,求出后驗估計 x ^ k \hat{x}_{k} x^k?。
x ˇ k = A k x ^ k ? 1 + u k (1) \check{\boldsymbol{x}}_k=\boldsymbol{A}_k \hat{\boldsymbol{x}}_{k-1}+\boldsymbol{u}_k \tag{1} xˇk?=Ak?x^k?1?+uk?(1)
P ˇ k = A k P ^ k ? 1 A k T + R (2) \quad \check{\boldsymbol{P}}_k=\boldsymbol{A}_k \hat{\boldsymbol{P}}_{k-1} \boldsymbol{A}_k^{\mathrm{T}}+\boldsymbol{R} \tag{2} Pˇk?=Ak?P^k?1?AkT?+R(2)
K = P ˇ k C k T ( C k P ˇ k C k T + Q k ) ? 1 (3) \boldsymbol{K}=\check{\boldsymbol{P}}_k \boldsymbol{C}_k^{\mathrm{T}}\left(\boldsymbol{C}_k \check{\boldsymbol{P}}_k \boldsymbol{C}_k^{\mathrm{T}}+\boldsymbol{Q}_k\right)^{-1} \tag{3} K=Pˇk?CkT?(Ck?Pˇk?CkT?+Qk?)?1(3)
x ^ k = x ˇ k + K ( z k ? C k x ˇ k ) (4) \hat{\boldsymbol{x}}_k=\check{\boldsymbol{x}}_k+\boldsymbol{K}\left(\boldsymbol{z}_k-\boldsymbol{C}_k \check{\boldsymbol{x}}_k\right) \tag{4} x^k?=xˇk?+K(zk??Ck?xˇk?)(4)
P ^ k = ( I ? K C k ) P ˇ k (5) \hat{\boldsymbol{P}}_k=\left(\boldsymbol{I}-\boldsymbol{K} \boldsymbol{C}_k\right) \check{\boldsymbol{P}}_k \tag{5} P^k?=(I?KCk?)Pˇk?(5)
于是這就得到了后驗 x ^ k \hat{x}_{k} x^k?的均值和協方差,用于k+1時刻的預測。
非線性系統和擴展卡爾曼濾波
本質上是在卡爾曼濾波基礎上對運動方程和觀測方程進行線性化(一階泰勒展開),在此基礎上也是經過5個公式推出 x k x_k xk?的后驗分布。這里就不展開了,公式都是大同小異。
BA優化
主要就是通過Bundle Adjustment(BA),來構建最小二乘問題,通過非線性優化的方法優化相機位姿和特征點的位置。
下面這個圖就很好描述了相機的觀測方程:
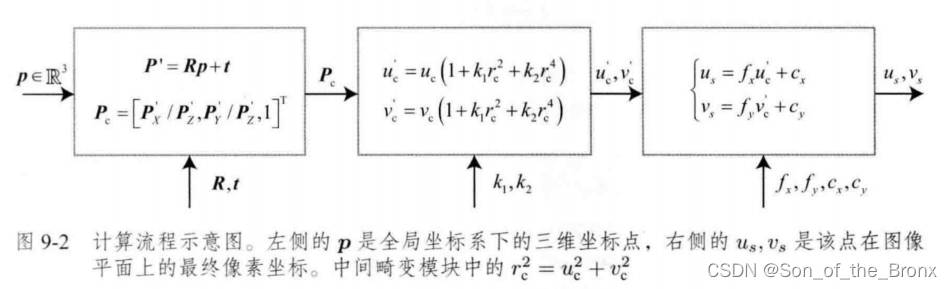
然后就是根據其他時刻的相機與特征點,構建出全局的重投影誤差
1 2 ∑ i = 1 m ∑ j = 1 n ∥ e i j ∥ 2 = 1 2 ∑ i = 1 m ∑ j = 1 n ∥ z i j ? h ( T i , p j ) ∥ 2 \frac{1}{2} \sum_{i=1}^m \sum_{j=1}^n\left\|\boldsymbol{e}_{i j}\right\|^2=\frac{1}{2} \sum_{i=1}^m \sum_{j=1}^n\left\|\boldsymbol{z}_{i j}-h\left(\boldsymbol{T}_i, \boldsymbol{p}_j\right)\right\|^2 21?i=1∑m?j=1∑n?∥eij?∥2=21?i=1∑m?j=1∑n? ?zij??h(Ti?,pj?) ?2
其中i是相機位姿的序號,j就是相機位姿i看到的特征點。
為了優化這個目標函數,需要求目標函數對相機位姿和特征點的雅可比,然后通過高斯牛頓來優化相機位姿和特征點:
1 2 ∥ f ( x + Δ x ) ∥ 2 ≈ 1 2 ∑ i = 1 m ∑ j = 1 n ∥ e i j + F i j Δ ξ i + E i j Δ p j ∥ 2 \frac{1}{2}\|f(\boldsymbol{x}+\Delta \boldsymbol{x})\|^2 \approx \frac{1}{2} \sum_{i=1}^m \sum_{j=1}^n\left\|\boldsymbol{e}_{i j}+\boldsymbol{F}_{i j} \Delta \boldsymbol{\xi}_i+\boldsymbol{E}_{i j} \Delta \boldsymbol{p}_j\right\|^2 21?∥f(x+Δx)∥2≈21?i=1∑m?j=1∑n? ?eij?+Fij?Δξi?+Eij?Δpj? ?2
其中狀態x定義成所有待優化的變量:
x = [ T 1 , … , T m , p 1 , … , p n ] T \boldsymbol{x}=\left[\boldsymbol{T}_1, \ldots, \boldsymbol{T}_m, \boldsymbol{p}_1, \ldots, \boldsymbol{p}_n\right]^{\mathrm{T}} x=[T1?,…,Tm?,p1?,…,pn?]T
F i j \boldsymbol{F}_{i j} Fij?和 E i j \boldsymbol{E}_{i j} Eij?分別是誤差對相機位姿和特征點的偏導。
最后的優化問題也可以簡化成:
1 2 ∥ f ( x + Δ x ) ∥ 2 = 1 2 ∥ e + F Δ x c + E Δ x p ∥ 2 \frac{1}{2}\|f(\boldsymbol{x}+\Delta \boldsymbol{x})\|^2=\frac{1}{2}\left\|\boldsymbol{e}+\boldsymbol{F} \Delta \boldsymbol{x}_c+\boldsymbol{E} \Delta \boldsymbol{x}_p\right\|^2 21?∥f(x+Δx)∥2=21?∥e+FΔxc?+EΔxp?∥2
最后根據高斯牛頓法,都是需要求解一個增量方程
H Δ x = g \boldsymbol{H} \Delta \boldsymbol{x}=\boldsymbol{g} HΔx=g
對于高斯牛頓法,H矩陣就是
H = J T J = [ F T F F T E E T F E T E ] \boldsymbol{H}=\boldsymbol{J}^{\mathrm{T}} \boldsymbol{J}=\left[\begin{array}{ll}\boldsymbol{F}^{\mathrm{T}} \boldsymbol{F} & \boldsymbol{F}^{\mathrm{T}} \boldsymbol{E} \\ \boldsymbol{E}^{\mathrm{T}} \boldsymbol{F} & \boldsymbol{E}^{\mathrm{T}} \boldsymbol{E}\end{array}\right] H=JTJ=[FTFETF?FTEETE?]
實際上這個H矩陣由于特征點的個數往往很多,所以H矩陣規模很大,直接求逆會很耗時,但是H矩陣是有一定的結構,利用這個結構可以加速優化過程。
H矩陣的稀疏性和邊緣化
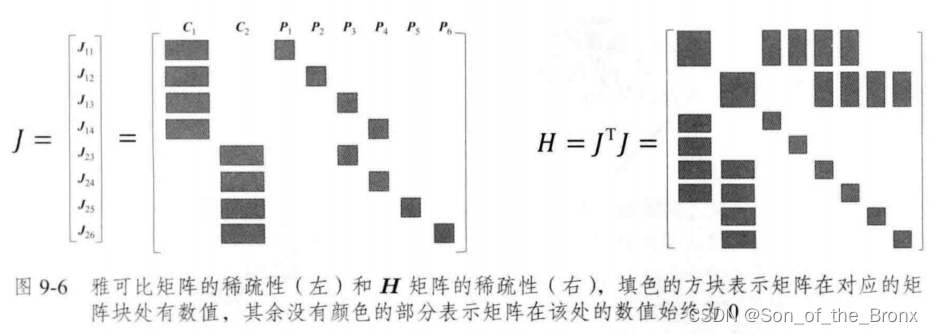
首先這里書本舉一個例子說明:
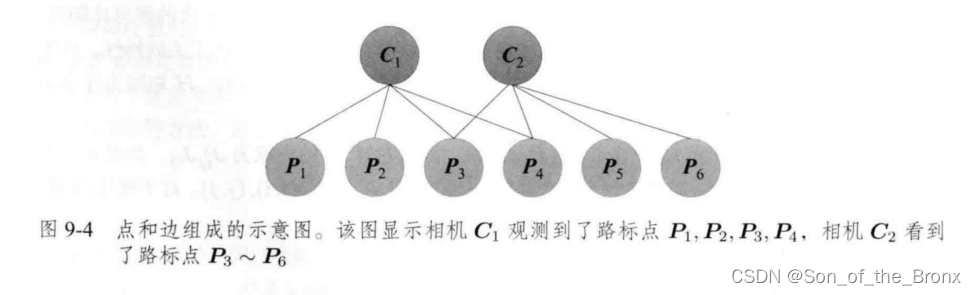
其中圖中有 C 1 C_1 C1?和 C 2 C_2 C2?兩個相機位姿和六個特征點,連線代表有觀測關系。
這時全局重投影的目標函數為
1 2 ( ∥ e 11 ∥ 2 + ∥ e 12 ∥ 2 + ∥ e 13 ∥ 2 + ∥ e 14 ∥ 2 + ∥ e 23 ∥ 2 + ∥ e 24 ∥ 2 + ∥ e 25 ∥ 2 + ∥ e 26 ∥ 2 ) \frac{1}{2}\left(\left\|\boldsymbol{e}_{11}\right\|^2+\left\|\boldsymbol{e}_{12}\right\|^2+\left\|\boldsymbol{e}_{13}\right\|^2+\left\|\boldsymbol{e}_{14}\right\|^2+\left\|\boldsymbol{e}_{23}\right\|^2+\left\|\boldsymbol{e}_{24}\right\|^2+\left\|\boldsymbol{e}_{25}\right\|^2+\left\|\boldsymbol{e}_{26}\right\|^2\right) 21?(∥e11?∥2+∥e12?∥2+∥e13?∥2+∥e14?∥2+∥e23?∥2+∥e24?∥2+∥e25?∥2+∥e26?∥2)
首先以 e 11 e_{11} e11?對狀態x求偏導,可以得到下面的雅可比
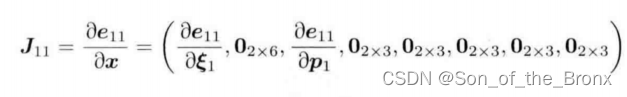
同理其他誤差的雅可比都會有這種形式: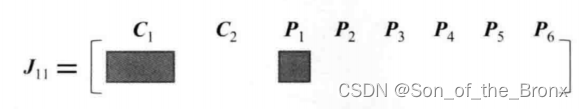
整體的雅可比J和H矩陣就會如同下圖所示
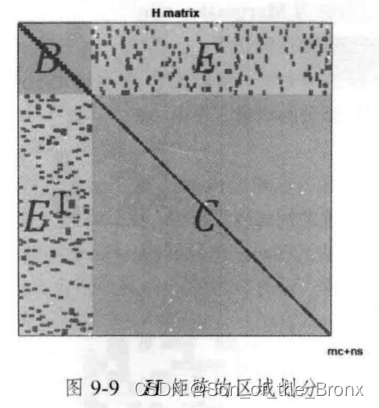
然后對H矩陣進行下圖的劃分:
增量方程也可以按照劃分,變成下面的形式
[ B E E T C ] [ Δ x c Δ x p ] = [ v w ] \left[\begin{array}{ll}\boldsymbol{B} & \boldsymbol{E} \\ \boldsymbol{E}^{\mathrm{T}} & \boldsymbol{C}\end{array}\right]\left[\begin{array}{l}\Delta \boldsymbol{x}_{\mathrm{c}} \\ \Delta \boldsymbol{x}_p\end{array}\right]=\left[\begin{array}{l}\boldsymbol{v} \\ \boldsymbol{w}\end{array}\right] [BET?EC?][Δxc?Δxp??]=[vw?]
對這個線性方程組的求解可以通過邊緣化(可通過schur消元進行邊緣化,也就是書中的方法。當然也有其他方法進行邊緣化,本質都是加快增量方程的求解速度)。邊緣化的過程如下:
[ I ? E C ? 1 0 I ] [ B E E T C ] [ Δ x c Δ x p ] = [ I ? E C ? 1 0 I ] [ v w ] \left[\begin{array}{cc}\boldsymbol{I} & -\boldsymbol{E} \boldsymbol{C}^{-1} \\ 0 & \boldsymbol{I}\end{array}\right]\left[\begin{array}{cc}\boldsymbol{B} & \boldsymbol{E} \\ \boldsymbol{E}^{\mathrm{T}} & \boldsymbol{C}\end{array}\right]\left[\begin{array}{c}\Delta \boldsymbol{x}_{\mathrm{c}} \\ \Delta \boldsymbol{x}_p\end{array}\right]=\left[\begin{array}{cc}\boldsymbol{I} & -\boldsymbol{E} \boldsymbol{C}^{-1} \\ 0 & \boldsymbol{I}\end{array}\right]\left[\begin{array}{c}\boldsymbol{v} \\ \boldsymbol{w}\end{array}\right] [I0??EC?1I?][BET?EC?][Δxc?Δxp??]=[I0??EC?1I?][vw?]
最終整理得到:
[ B ? E C ? 1 E T 0 E T C ] [ Δ x c Δ x p ] = [ v ? E C ? 1 w w ] \left[\begin{array}{cc}\boldsymbol{B}-\boldsymbol{E} \boldsymbol{C}^{-1} \boldsymbol{E}^{\mathrm{T}} & 0 \\ \boldsymbol{E}^{\mathrm{T}} & \boldsymbol{C}\end{array}\right]\left[\begin{array}{l}\Delta \boldsymbol{x}_{\mathrm{c}} \\ \Delta \boldsymbol{x}_p\end{array}\right]=\left[\begin{array}{c}\boldsymbol{v}-\boldsymbol{E} \boldsymbol{C}^{-1} \boldsymbol{w} \\ \boldsymbol{w}\end{array}\right] [B?EC?1ETET?0C?][Δxc?Δxp??]=[v?EC?1ww?]
因為右上角為0,就可以先把 Δ x c \Delta \boldsymbol{x}_{\mathrm{c}} Δxc?計算出來,因為c是對角塊矩陣,所以它的求逆相對簡單。將求出 Δ x c \Delta \boldsymbol{x}_{\mathrm{c}} Δxc?后再帶入原方程就可以解出 Δ x p \Delta \boldsymbol{x}_{\mathrm{p}} Δxp?。
H矩陣求解的總結
這個邊緣化的概念是從概率論的角度來看的。實際上這個求解步驟就是固定 Δ x p \Delta \boldsymbol{x}_{\mathrm{p}} Δxp?,然后求解 Δ x c \Delta \boldsymbol{x}_{\mathrm{c}} Δxc?,最后再算出 Δ x p \Delta \boldsymbol{x}_{\mathrm{p}} Δxp?。從概率公式上:
P ( x c , x p ) = P ( x c ∣ x p ) P ( x p ) P\left(\boldsymbol{x}_{\mathrm{c}}, \boldsymbol{x}_p\right)=P\left(\boldsymbol{x}_{\mathrm{c}} \mid \boldsymbol{x}_p\right) P\left(\boldsymbol{x}_p\right) P(xc?,xp?)=P(xc?∣xp?)P(xp?)
最終是求得了 x c \boldsymbol{x}_\mathrm{c} xc?的條件概率分布,和 x p \boldsymbol{x}_\mathrm{p} xp?的邊緣分布,所以稱邊緣化。在消元的時候實際上是將特征點的部分信息融入了求解 x c \boldsymbol{x}_\mathrm{c} xc?的過程,所以 x c \boldsymbol{x}_\mathrm{c} xc?是條件概率分布。
需要注意的是,這個邊緣化在滑動窗口的方法中也有所應用。
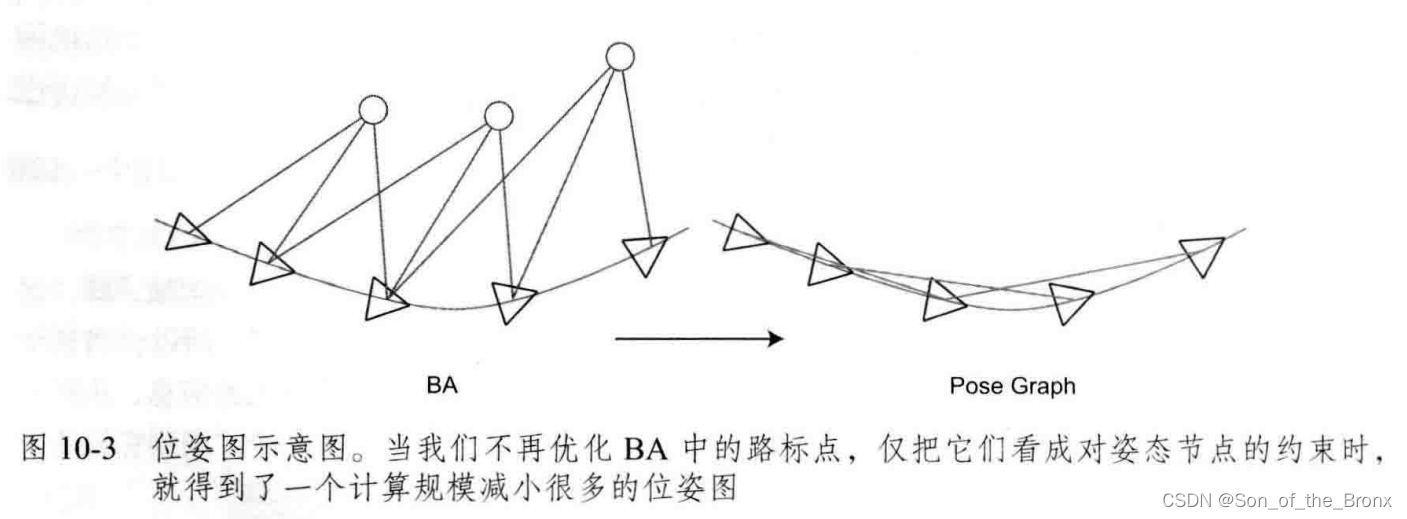
位姿圖優化
位姿圖優化在視覺SLAM中可以看成是BA優化的簡化版。因為BA優化需要將特征點考慮進去,優化的變量包括相機位姿和特征點的位置,大部分是放在特征點優化上了,所以位姿圖的意義在于構建一個只有軌跡的圖優化問題,特征點看成是一幀相機位姿中確定的點,不再去優化特征點的位置,省去了大量特征點優化的計算。
公式推導
假設通過IMU積分或者視覺slam估計了 T i T_i Ti?和 T j T_j Tj?之間的一個運動 Δ T i j \Delta \boldsymbol{T}_{i j} ΔTij?,然后取他們李群之間的差值對應的李代數為誤差:
e i j = Δ ξ i j = ln ? ( T i j ? 1 T i ? 1 T j ) ∨ \boldsymbol{e}_{i j}=\Delta \boldsymbol{\xi}_{i j} = \ln \left(\boldsymbol{T}_{i j}^{-1} \boldsymbol{T}_i^{-1} \boldsymbol{T}_j\right)^{\vee} eij?=Δξij?=ln(Tij?1?Ti?1?Tj?)∨
緊接著就是經典的對 T i T_i Ti?和 T j T_j Tj?加左擾動對擾動求導
e ^ i j = ln ? ( T i j ? 1 T i ? 1 exp ? ( ( ? δ ξ i ) ∧ ) exp ? ( δ ξ j ∧ ) T j ) ∨ \hat{\boldsymbol{e}}_{i j}=\ln \left(\boldsymbol{T}_{i j}^{-1} \boldsymbol{T}_i^{-1} \exp \left(\left(-\boldsymbol{\delta} \boldsymbol{\xi}_i\right)^{\wedge}\right) \exp \left(\delta \boldsymbol{\xi}_j^{\wedge}\right) \boldsymbol{T}_j\right)^{\vee} e^ij?=ln(Tij?1?Ti?1?exp((?δξi?)∧)exp(δξj∧?)Tj?)∨
因為上式擾動項被夾在中間,所以可以通過下面的伴隨性質:
exp ? ( ξ ∧ ) T = T exp ? ( ( Ad ? ( T ? 1 ) ξ ) ∧ ) \exp \left(\boldsymbol{\xi}^{\wedge}\right) \boldsymbol{T}=\boldsymbol{T} \exp \left(\left(\operatorname{Ad}\left(\boldsymbol{T}^{-1}\right) \boldsymbol{\xi}\right)^{\wedge}\right) exp(ξ∧)T=Texp((Ad(T?1)ξ)∧)
將擾動挪到最右邊,最終得到下面的式子:
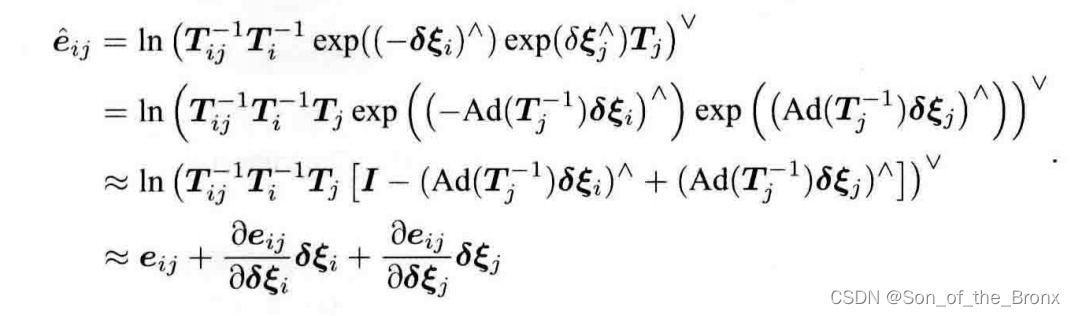
其實對于這個式子我不是很能理解從第三個式子到第四個式子的轉變,經過與其他人的交流,得知還需要借助ln(1+x)的泰勒展開結合se(3)的BCH近似來化簡,下面就是自己手寫的推導過程(從第三個式子開始推導):

對于一開始的公式,我想的是直接從第二個式子展開,忽略了se(3)的BCH近似,結果雅可比跟書上那個是類似的,只不過書上多了一個可以忽略的 J r J_r Jr?:
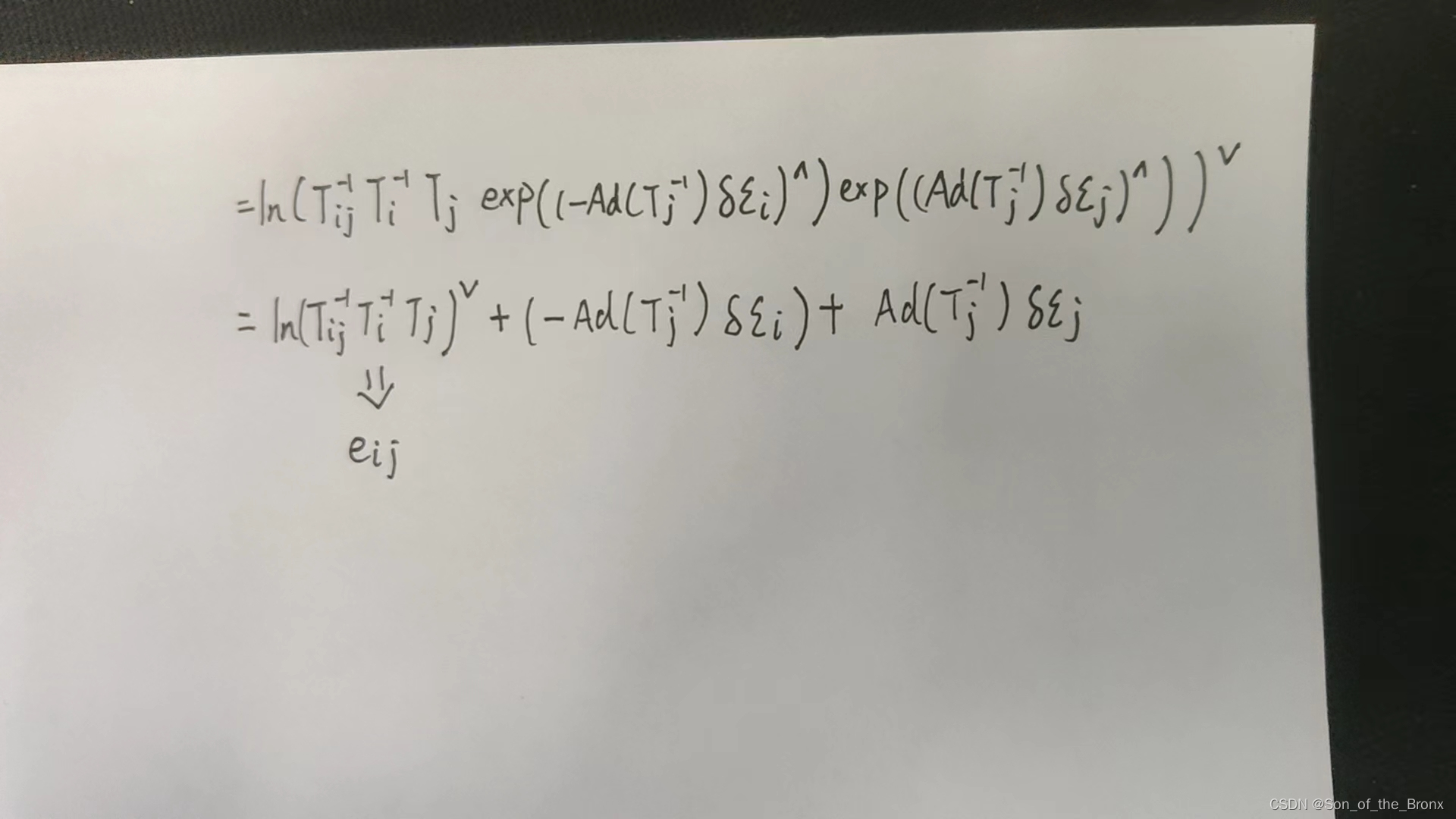
后續的過程就是根據雅可比去求增量方程,求解增量方程優化相機位姿,高斯牛頓的劇情又來了。
基于滑動窗口的后端
這里只考慮滑動窗口BA優化,因為書上對滑動窗口這部分介紹的東西比較少。
個人見解
為什么會想用滑動窗口的方式?就是因為在slam的過程中,圖像來了就算一幀,一幀需要優化一個相機位姿和幾百個特征點。時間一長,特征點數量就飛速增長,雖然可以采用關鍵幀的策略,但是關鍵幀的數量也是會隨著slam的過程逐漸增多。所以就產生控制BA規模的想法,最簡單的方法就是僅僅保存離當前幀時間最近的N個關鍵幀,依靠這些關鍵幀做BA優化。在新增關鍵幀和關鍵點的時候是比較好操作的,但是在刪除一個舊的關鍵幀時,就需要邊緣化的操作。
舊關鍵幀的邊緣化
具體其實可以參考一篇博客,寫的非常清晰:邊緣化中矩陣運算的一點細節
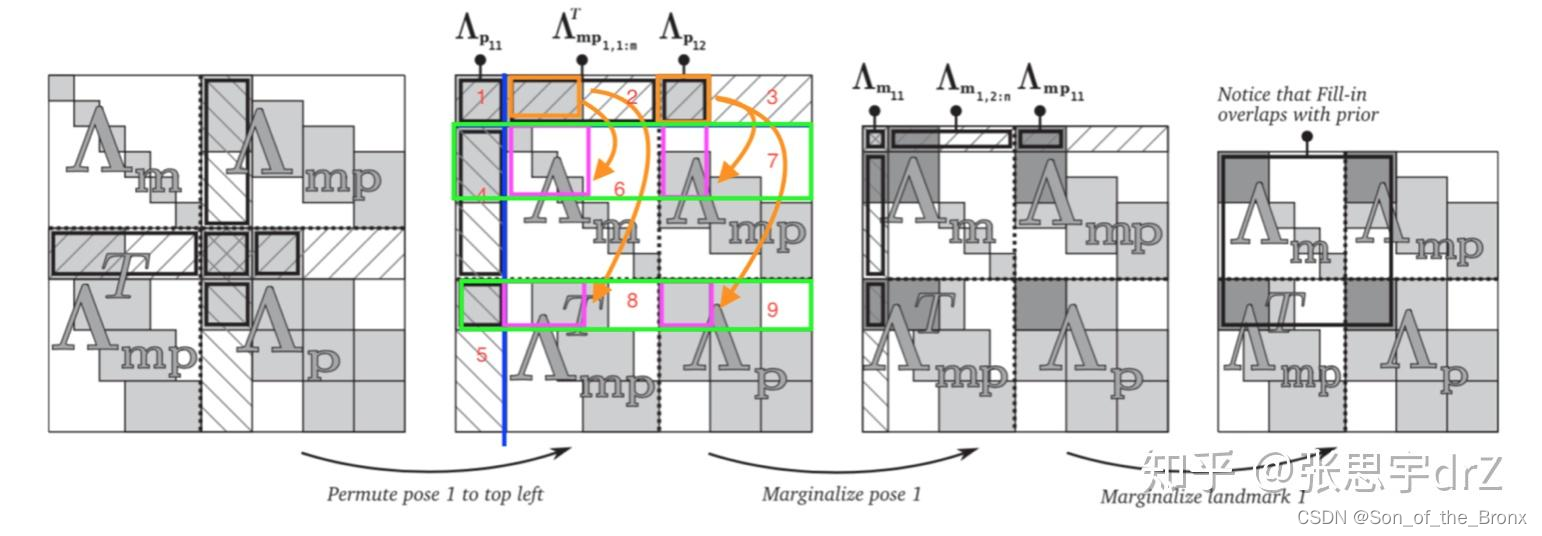
邊緣化的過程可以簡要的由上面的圖片來表示。這個就是整個滑動窗口的BA優化中H矩陣, A m A_m Am?代表的是特征點的部分, A p A_p Ap?代表相機位姿的部分。先邊緣化相機位姿,這時候有關這個相機位姿的信息就會在schur消元的過程中 Fill-in A m A_m Am?中,然后就是邊緣化這個相機位姿的特征點,也是通過schur消元中 Fill-in A m A_m Am?中,但是Fill-in的范圍是一致的,不會有新的空白區域被 Fill-in ,最終就可以得到邊緣化后的H矩陣。
其實看到最后的H矩陣, A m A_m Am?沒法保證自身是對角塊矩陣,所以在后續優化求解的時候,就無法通過之前稀疏方式去迭代求解了。這個問題應該也會有一些SLAM框架去解決,采取其他邊緣化策略保證 A m A_m Am?對角塊矩陣的特性。

![AT_abc351_c [ABC351C] Merge the balls 題解](http://pic.xiahunao.cn/AT_abc351_c [ABC351C] Merge the balls 題解)
)



)












)