前言
僅記錄學習過程,有問題歡迎討論
大模型訓練相關知識:
問題:
- 數據集過大,快速訓練
- 模型過大,gpu跑不完
方案:
- 數據并行訓練:
復制數據(batch_size)到多個gpu,各自計算loss,再反傳更新;至少需要一張卡能訓練一個樣本 - 模型并行:
模型的不同層放到不同的gpu上,解決了單卡不夠大的問題,但是需要更多的通訊時間了(一次訓練需要傳播很多次)【時間換空間】 - 張量并行:
將張量劃分到不同的gpu上(張量左右分割),進一步減少對單卡的需求,【時間換空間】
可以混合使用
浮點精度損失:
float32:
使用32位二進制來表示一個浮點數。第一位用于表示符號位(正或負),
接下來的八位用于表示指數,剩下的23位用于表示尾數或分數部分。Float32的數值范圍大約在±3.4E+38之間
0.2 = 0.00110(B)~、
DeepSpeed(零冗余優化器)
優化訓練的方案
ZeRo:
- 相當于張量并行,gradients,parameters,分散到不同gpu計算。速度變慢
ZeRo -offload
添加內存幫助顯卡計算哈哈
大模型的蒸餾: 小模型直接學習文本數據之外,還學習大模型預測的結果
大模型的剪枝: 刪除大模型中不重要的部分,減少模型大小
PEFT微調:(當大模型對某個方面表現不好)
- 預訓練模型+微調數據集
原始權重不動,增加一部分可訓練的權重,去結合之前的部分
prompt tuning:
- 預訓練模型+提示詞(提前告訴模型需要訓練什么)(添加在input data)
P-tuning V2:訓練虛擬token(添加在emb)
- 該方法將 Prompt 轉換為可以學習的 Embedding 層,并用MLP+LSTM的方式來對Prompt Embedding進行一層處理。
Adapter: 新增可訓練的層(添加在fft后)
LoRa(目前比較流行):
- 通過低秩分解來模擬參數的改變量,從而以極小的參數量來實現大模型的間接訓練(最后再擴大)。
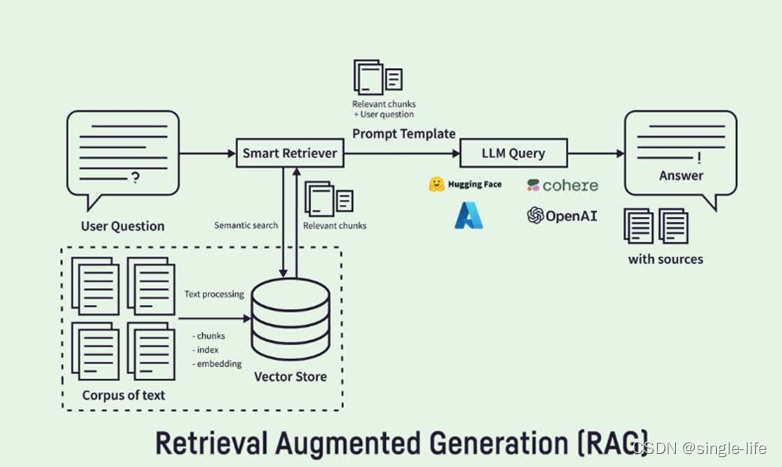
RAG(Retrieve Augmented Generation):
- 模型幻覺問題,遇見不知道的問題,會亂答
召回部分和Prompt相似的段落,重新輸入模型,獲取可靠答案。
優勢(主要就這兩條):
(1)可擴展性:減少模型大小和訓練成本,并能夠快速擴展知識。
(2)準確性:模型基于事實進行回答,減少幻覺的發生。
難點:
(1)數據標注:需要對數據進行標注,以提供給模型進行檢索。
(2)檢索算法:需要設計高效的檢索算法,以提高檢索的效率和準確率。
BPE(Byte pair encoding):壓縮算法
-
RAG針對詞表vocab的以下問題
1.測試過程出現詞表沒有的詞
2.詞表過大
3.不同語種,切分粒度不同 -
如aaabdaaaabc ==> XdXac
在nlp中,針對語料中出現的重復詞,添加到vocab中,再切分,再添加 -
BPE通過構建跨語言共享的子詞詞匯表,提高了模型處理多種語言的能力,有效解決了不同語言間詞匯差異大、低頻詞和OOV問題,增強了模型的泛化能力和翻譯性能。
代碼:
使用lora對大模型進行微調:
使用的是序列標注的ner代碼
main.py
# -*- coding: utf-8 -*-import torch
import os
import random
import os
import numpy as np
import logging
from config import Config
from model import TorchModel, choose_optimizer
from evaluate import Evaluator
from loader import load_data
from peft import get_peft_model, LoraConfig, TaskTypelogging.basicConfig(level=logging.INFO, format='%(asctime)s - %(name)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)"""
模型訓練主程序
"""def peft_wrapper(model):peft_config = LoraConfig(r=8,lora_alpha=32,lora_dropout=0.1,target_modules=["query", "value"])return get_peft_model(model, peft_config)def main(config):# 創建保存模型的目錄if not os.path.isdir(config["model_path"]):os.mkdir(config["model_path"])# 加載訓練數據train_data = load_data(config["train_data_path"], config)# 加載模型model = TorchModel(config)model = peft_wrapper(model)# 標識是否使用gpucuda_flag = torch.cuda.is_available()if cuda_flag:logger.info("gpu可以使用,遷移模型至gpu")model = model.cuda()# 加載優化器optimizer = choose_optimizer(config, model)# 加載效果測試類evaluator = Evaluator(config, model, logger)# 訓練for epoch in range(config["epoch"]):epoch += 1model.train()logger.info("epoch %d begin" % epoch)train_loss = []for index, batch_data in enumerate(train_data):optimizer.zero_grad()if cuda_flag:batch_data = [d.cuda() for d in batch_data]input_id, labels = batch_data # 輸入變化時這里需要修改,比如多輸入,多輸出的情況loss = model(input_id, labels)loss.backward()optimizer.step()train_loss.append(loss.item())if index % int(len(train_data) / 2) == 0:logger.info("batch loss %f" % loss)logger.info("epoch average loss: %f" % np.mean(train_loss))evaluator.eval(epoch)model_path = os.path.join(config["model_path"], "epoch_%d.pth" % epoch)# torch.save(model.state_dict(), model_path)return model, train_dataif __name__ == "__main__":model, train_data = main(Config)
model.py
# -*- coding: utf-8 -*-import torch
import torch.nn as nn
from torch.optim import Adam, SGD
from torchcrf import CRF
from transformers import BertModel"""
建立網絡模型結構
"""class ConfigWrapper(object):def __init__(self, config):self.config = configdef to_dict(self):return self.configclass TorchModel(nn.Module):def __init__(self, config):super(TorchModel, self).__init__()self.config = ConfigWrapper(config)max_length = config["max_length"]class_num = config["class_num"]# self.embedding = nn.Embedding(vocab_size, hidden_size, padding_idx=0)# self.layer = nn.LSTM(hidden_size, hidden_size, batch_first=True, bidirectional=True, num_layers=num_layers)self.bert = BertModel.from_pretrained(config["bert_path"], return_dict=False)self.classify = nn.Linear(self.bert.config.hidden_size, class_num)self.crf_layer = CRF(class_num, batch_first=True)self.use_crf = config["use_crf"]self.loss = torch.nn.CrossEntropyLoss(ignore_index=-1) # loss采用交叉熵損失# 當輸入真實標簽,返回loss值;無真實標簽,返回預測值def forward(self, x, target=None):# x = self.embedding(x) #input shape:(batch_size, sen_len)# x, _ = self.layer(x) #input shape:(batch_size, sen_len, input_dim)x, _ = self.bert(x)predict = self.classify(x) # ouput:(batch_size, sen_len, num_tags) -> (batch_size * sen_len, num_tags)if target is not None:if self.use_crf:mask = target.gt(-1)return - self.crf_layer(predict, target, mask, reduction="mean")else:# (number, class_num), (number)return self.loss(predict.view(-1, predict.shape[-1]), target.view(-1))else:if self.use_crf:return self.crf_layer.decode(predict)else:return predictdef choose_optimizer(config, model):optimizer = config["optimizer"]learning_rate = config["learning_rate"]if optimizer == "adam":return Adam(model.parameters(), lr=learning_rate)elif optimizer == "sgd":return SGD(model.parameters(), lr=learning_rate)if __name__ == "__main__":from config import Configmodel = TorchModel(Config)

![[雜項]優化AMD顯卡對DX9游戲(天諭)的支持](http://pic.xiahunao.cn/[雜項]優化AMD顯卡對DX9游戲(天諭)的支持)
))


復現(一))



)

)
——記憶化搜索)


和以數據為中心(Data-Centric)的區別)


)
