目錄
零、前言
一、一些基本術語
二、關系模式
2.1. 什么是關系模式
2.2.?示例
三、數據依賴
3.1. 函數依賴
3.1.1. 完全函數依賴
3.1.2. 部分函數依賴
3.1.3. 傳遞函數依賴
3.2. 多值依賴
3.3. 連接依賴
四、規范化
4.1. 第一范式(1NF)
4.2. 第二范式(2NF)
4.3. 第三范式(3NF)
4.4. 巴斯-科德范式(BCNF)
4.5. 第四范式(4NF)
4.6. 第五范式(5NF)
4.7. 第六范式(6NF)
五、反規范化
5.1. 冗余列
5.2. 派生列
5.3.?表重組
5.4.?表分割
5.4.1. 水平分割
5.4.2.?垂直分割
零、前言
????????為了更好的理解數據庫設計的規范化和反規范化,我們需要先弄清楚什么是函數依賴,以及函數依賴的分類,而要理解函數依賴,就要先明白什么是關系模式。所以,本文從關系模式開始,再依次講解函數依賴和規范化以及反規范化。

一、一些基本術語
屬性 (Attribute): 在現實世界中,要描述一個事物常常取若干特征來表示。這些特征稱為屬性。例如學生通過學號、姓名、性別、系別、年齡、籍貫等屬性來描述。
域 (Domain): 每個屬性的取值范圍對應一個值的集合,稱為該屬性的域。例如,學號的域是6位整型數;姓名的域是10位字符;性別的域為{男,女}等。
目或度 (Degree): 目或度指的是一個關系中屬性的個數。
候選碼 (Candidate Key): 若關系中的某一屬性或屬性組的值能唯一的標識一個元組,則稱該屬性或屬性組為候選碼。
主碼 (Primary Key): 或稱主鍵,若一個關系有多個候選碼,則選定其中一個作為主碼。
主屬性 (Prime Attribute): 包含在任何候選碼中的屬性稱為主屬性。不包含在任何候選碼中的屬性稱為非主屬性 (Non-Prime Attribute)。
外碼 (Foreign Key): 如果關系模式 R 中的屬性或屬性組不是該關系的碼,但它是其他關系的碼,那么該屬性集對關系模式R 而言是外碼。例如,客戶與貸款之間的借貸聯系 c-1(c-id,loan-no), 屬性c-id是客戶關系中的碼,所以c-id 是外碼;屬性 loan-no是貸款關系中的碼,所以loan-no 也是外碼。
全碼 (All-key): 關系模型的所有屬性組是這個關系模式的候選碼,稱為全碼。例如,關系模式R(T,C,S), 屬性 T 表示教師,屬性C 表示課程,屬性S 表示學生。假設一個教師可以講授多門課程,某門課程可以由多個教師講授,學生可以聽不同教師講授的不同課程,那么,要想區分關系中的每一個元組,這個關系模式R 的碼應為全屬性 T、C和 S,即ALL-KEY。
二、關系模式
2.1. 什么是關系模式
????數據庫的關系模式是關系型數據庫中用于描述數據庫結構和數據之間關系的一種方式。它是對數據庫中關系(表)的邏輯結構進行定義,可以形式化地表示為:R(U,D,dom,F),其中每個元素都有特定的語義,使用這樣的表示方法可以幫助數據庫設計者規范地描述數據庫中的數據結構,以及數據之間的邏輯關系。這有助于確保數據的完整性和準確性,并為數據庫的查詢和操作提供了一個清晰的基礎。
通常,我們可以將關系模式簡記為R(U)。
- R:表示關系的名稱,代表數據庫中的一個表或關系。
- U:表示關系R的屬性集合。這些屬性定義了關系中的列。
- D:表示屬性集合U中每個屬性的域或數據類型集合。域是對屬性可能值的限制,確保每個屬性的值都屬于其指定的數據類型。
- dom:表示屬性集合U中每個屬性的值域,是屬性到域的映像集合;
- F:表示關系R的函數依賴集合。
2.2.?示例
????假設我們有一個關系模式叫做“學生成績”,它用于存儲學生的信息和他們的成績。我們可以用R(U,D,dom,F)來描述這個關系模式:
- R:“學生成績”
- U:{學號, 姓名, 課程, 成績}
- D:{整數, 字符串, 字符串, 浮點數}
- dom:
成績:分數,例如“90.5”
課程:課程名稱,例如“數學”
姓名:學生的名字,例如“張三”
學號:唯一的 student ID,例如“S12345”
F:{學號→姓名, (學號,課程)→成績}
????在這個例子中,學號決定了學生的姓名和課程,因為每個學生只有一個學號,而且每個課程的成績也是由特定的學號和課程共同決定的。這樣的函數依賴集合確保了數據的完整性和一致性。例如,如果我們有一個學生的學號是“S12345”,那么我們可以通過學號查找到對應學生的姓名。同時,如果我們知道一個學生選修了“數學”課程,我們可以查找該課程的成績。
????以上關系模式,可以簡記為:學生成績(學號, 姓名, 課程, 成績)
三、數據依賴
3.1. 函數依賴
????在上述關系模式中的說明中,我們提到了函數依賴(F),數據庫中的函數依賴是描述關系型數據庫中表的屬性之間相互依賴關系的概念。它反映了表中數據屬性之間的邏輯關系,即一個屬性或屬性集是否能夠決定另一個屬性或屬性集的值。
????在關系型數據庫中,一個關系(表)由多個屬性(列)組成。函數依賴定義了這些屬性之間的規則,說明了一個屬性的值如何決定另一個屬性的值。函數依賴有助于確保數據的準確性和一致性。
????通俗來講,函數依賴是使關系模式的屬性間的數據依賴達到一種“函數”的效果,即根據一個或多個屬性,能夠推導出唯一的另一個屬性,它描述的實際上是屬性之間1對1或n對1的關系。
????函數依賴主要有三種類型:完全函數依賴、部分函數依賴以及傳遞函數依賴。
3.1.1. 完全函數依賴
? ? 當一個屬性集合A完全決定另一個屬性集合B時,我們說B完全函數依賴于A。這意味著A中的每個值都決定了B中的一個唯一值。例如,(學號,課程號)?→ 成績,這里學號和課程號單獨拿出來都不能決定成績,只有學號和課程號一起才能決定一個成績。
3.1.2. 部分函數依賴
??????????????? ??當一個屬性集合A的部分成員決定了另一個屬性集合B時,我們說B部分函數依賴于A。這意味著A中的某些值可能決定多個B的值。例如,(學號,課程號)?→ 學生姓名,這里學號和課程號放在一起可以決定學生的姓名,但是它不滿足完全函數依賴,因為學號單獨拿出來也能決定學生姓名。
3.1.3. 傳遞函數依賴
??????????????????當一個屬性集合A通過中間屬性集合B決定另一個屬性集合C時,我們說C傳遞函數依賴于A。這意味著A中的每個值通過B決定了C中的一個唯一值。例如,學號 → 所在班級,所在班級?→ 班主任,這里班主任依賴于所在班級,而所在班級又依賴于學號。
3.2. 多值依賴
????多值依賴是函數依賴的一種擴展,它用于描述一個屬性集合對另一個屬性集合的多值關系。在關系模式R(A, B, C)中,如果對于R中的任意兩個元組t1和t2,當t1在屬性A上的值等于t2在屬性A上的值時,t1在屬性B上的值集合必須等于t2在屬性B上的值集合,那么我們說B多值依賴于A,記作A →→ B。多值依賴表達了屬性間的一種更為復雜的關系。
?????與函數依賴描述1對1或n對1的關系不同,多值依賴主要描述屬性之間1對n或m對n的關系。如下圖,在圖中的關系模式中,其屬性關系為:科目與學生之間、科目與教師之間均存在多對多的關系,但學生和教師之間沒有任何直接關系:

????將這些對應關系拆分則得到了如下兩個子關系:

????此時,我們稱學生、科目和教師這三個屬性之間存在多值依賴。
3.3. 連接依賴
? ??根據《計算機科學技術名詞 》第三版的定義,如果將關系 R的所有屬性在R的實例I上分別進行投影操作,然后將這些投影的結果進行連接運算后其結果仍等于I,則稱該實例I 滿足連接依賴。
? ? 以上定義或許不太好理解,這里還是以上面提到的關系為例,但在這個關系模式中,其語義約束變為:學生與科目之間、學生與教師之間、科目與教師之間均存在多對多的對應條件:
????將這些對應關系拆分則得到了如下三個子關系:

????此時重新將R1、R2和R3三張子表進行自然連接運算之后,可以無損地還原出原始關系R,則我們稱學生、科目和教師這三個屬性之間存在連接依賴。
????到這里便可以發現,連接依賴和多指依賴都是由多對多或多對一的聯系而產生的,如果三個屬性之間任意兩個屬性均存在多對多或多對一的關系,則稱這三個屬性之間存在連接依賴, 否則稱這三個屬性之間存在多值依賴。
四、規范化
????????數據庫設計規范化(Database Normalization)是數據庫設計中的一種重要方法,旨在通過優化數據庫結構來提高數據的一致性和完整性,減少數據冗余,增強數據修改的靈活性,并降低數據查詢的復雜性。規范化通常涉及將大表拆分成更小、更專門的表,并通過定義表之間的關系來連接這些表。通常可以通過判斷分解后的模式達到幾范式來評價模式規范化的程度。范式從低到高依次為:1NF、2NF、3NF、BCNF、4NF以及5NF。在實際應用中,3NF已經足夠滿足大多數數據庫設計的需求。下面依次對這些范式進行說明:
4.1. 第一范式(1NF)
????若存在學生表如下:

????在此學生表中,Courses包含了學生所選的所有課程,這種表設計使得查詢某課程被哪些學生選擇變得復雜,并且在新增選課、取消選課時也需要先分解Courses字段才能進行處理。為了解決這種問題,提出了1NF。
????1NF的目標是確保表中的每一列都是不可分割的基本數據項,主要關注的是確保每列的原子性,即沒有集合、數組、記錄等復雜數據類型。例如,供應者和它所提供的零件信息,關系模式 FIRST和函數依賴集F 如下:
????FIRST(Sno,Sname,Status,City,Pno,Qty)
????F={Sno → Sname,Sno → Status,Status → City,(Sno,Pno)→ Qty}
? ??對具體的關系 FIRST 如圖所示,可以看出,每一個分量都是不可再分的數據項,所以是1NF的。

4.2. 第二范式(2NF)
? ? 在以上關系模式中,我們可以看到它的候選碼為(Sno,Pno),存在部分函數依賴(Sno可以單獨推斷出Sname和Status),這就導致其存在插入異常和刪除異常的問題,所謂插入異常,是指按照關系模式實體完整性規定主碼不能取空值或部分取空值(由于候選碼只有一個,所以(Sno,Pno)也是主碼)。這樣,當某個供應者的某些信息未提供時(如 Pno), 則不能進行插入;而刪除異常是指若供應商S4的P2零件銷售完了,并且以后不再銷售P2零件,那么應刪除該元組,可S4 又是客觀存在的,不能因此刪除。而為了解決插入異常和刪除異常,就有了2NF。
????2NF的目的是消除部分函數依賴,要求非主鍵列必須完全依賴于整個主鍵,而不能僅依賴于主鍵的一部分。比如,為了消除以上示例中的部分函數依賴,我們可以將FIRST關系分解為:
????FIRST1(Sno,Sname,Status,City)
????FIRST2(Sno,Pno,Qty)
????因為分解后的關系模式FIRST1的碼為 Sno, 非主屬性 Sname、Status、City完全依賴于碼Sno, 所以屬于2NF; 關系模式FIRST2的碼為 (Sno,Pno), 非主屬性Qty完全依賴于碼,所以也屬于2NF。
4.3. 第三范式(3NF)
????在滿足了2NF之后,繼續分析可以發現,由于關系FIRST1中存在傳遞函數依賴(Sno → Status,Status → City),導致其存在修改操作的不一致性的問題,修改操作的不一致性是指:如Status=20對應的City從天津搬到了上海,則有可能導致一些Status=20的數據被修改,而另一些未被修改,導致數據產生不一致性,為了解決這種問題,就需要3NF
????3NF的目的是消除傳遞函數依賴,也就是說,非主鍵列必須直接依賴于主鍵,而不能依賴于其他非主鍵列。為了使前面的關系達到3NF,我們將FIRST1進一步分解為:
????FIRST11(Sno,Sname,Status)
????FIRST12(Status,City)?
? ??通過上述分解,數據庫模式FIRST轉換為FIRST11(Sno,Sname,Status), FIRST12(Status,City),FIRST2(Sno,Pno,Qty)3個子模式。由于這3個子模式都達到了3NF, 因此分解后的數據庫模式達到了3NF。
4.4. 巴斯-科德范式(BCNF)
? ? BCNF是3NF的一種改進形式,它有三點要求:
所有非主屬性對每一個碼都是完全函數依賴
所有的主屬性對每一個不包含它的碼,也是完全函數依賴
沒有任何屬性完全函數依賴于非碼的任何一組屬性
????簡單來講,就是所有關系的左側都必須能夠定位到唯一的一條數據。例如:存在關系模式如下:
????R(a,b,c,d)
??? F((a,b)→c,(a,c)→d)
????在以上關系模式中,候選鍵為(a,b),由于其中不存在非主鍵列對主鍵的部分依賴,同樣也不存在非逐漸列對主鍵的傳遞依賴,所以它是滿足3NF的,但d對候選碼(a,b)不為完全函數依賴,所以違反了上述3點中的第一點,即不滿足BCNF。為了使之滿足BCNF,我們可以對關系進行拆分:
? ? R1(a,b,c)
????R2(a,c,d)
4.5. 第四范式(4NF)
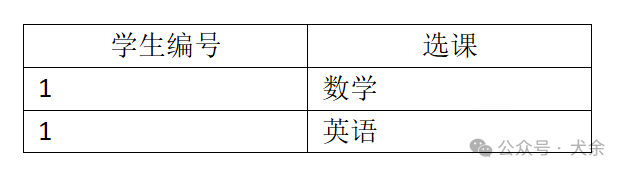
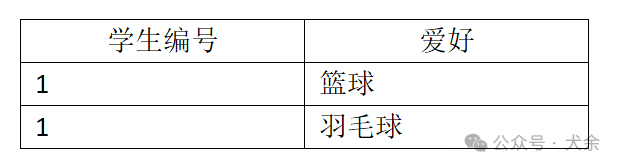
????????假設存在如下表:

? ? 在該表中,候選鍵為(學生編號,選課,愛好),即全部屬性都是主屬性,且其不存在函數依賴,所以它是滿足BCNF的,但是由于學生編號和選課之間、學生編號和愛好之間分別存在多值依賴,且選課和愛好之間沒有任何關系,所以這里存在數據冗余,每多一個選課都要添加兩條記錄(對應籃球和羽毛球)。4NF的目的就是為了解決這種冗余,即消除關系中的多對多關系,將之拆分成多個1對多關系,例如上述表為了滿足4NF,我們可以將之拆分為如下兩張表:
4.6. 第五范式(5NF)
????在上一小節的例子中,如果補充一點約束:只有愛好為籃球的學生才可以選數學和語文,只有愛好為羽毛球的學生才可以選英語和化學,那么此時由于學生編號、愛好和選課三個屬性之間任意兩個屬性之間都存在多值約束,此時這三個屬性之間就變成了連接依賴,不存在多值依賴,也就自然滿足了4NF,而在4NF的基礎上,進一步消除其不由候選碼隱含的連接依賴,就得到了5NF。所謂“消除其不由候選碼隱含的連接依賴”,就是要保證不存在任何依賴屬性不為候選碼的連接依賴。例如上面所述關系中,其候選碼為(學生編號,選課,愛好),而在其連接依賴中,學生編號→選課和學生編號→愛好之間的連接屬性為學生編號,愛好→選課和學生編號→愛好之間的連接屬性為愛好,愛好→選課和學生編號→選課之間的連接屬性為選課,可見它們的連接屬性均不為候選碼,所以它不滿足5NF。
????為了使上述關系滿足5NF,我們需要針對對其連接依賴進行拆分,將之拆分為R1(學生編號,選課),R2(學生編號,愛好)和R3(選課,愛好)。
4.7. 第六范式(6NF)
????6NF是為了處理時間數據獨立變化的情況而創建的,以避免不必要的重復。其結果是表無法進一步分解;在大多數情況下,表包括主鍵和單個非鍵屬性。如下圖:
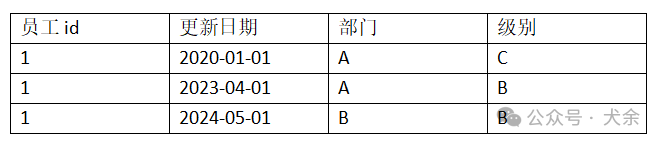
????在該關系表中,部門和級別往往是隨著時間獨立變化的,這就導致該表中可能存在大量的重復數據(比如級別不變但部門一直在調整),為了避免這種冗余數據,我們可以將表拆分為如下兩張表,以滿足6NF:

????通過將“時變數據”隔離到自己的表中,與時限屬性相關的操作變得更加高效和清晰。此結構使處理和查詢時態數據變得更加容易。在實踐中,6NF一般僅應用于需要復雜時態數據管理的系統。此外,雖然 6NF 有助于處理時態數據,但它可能會以多個表的形式引入復雜性,這可能需要在查詢期間進行復雜的連接。
五、反規范化
????在關系模式的規范化過程中,會導致關系的概念愈來愈單一化,在響應用戶查詢時,往往需要涉及多表的關聯操作,導致查詢性能下降。為此需要對關系模式進行修正,對部分影響性能的關系模式進行處理,包括分解、合并、增加冗余屬性等。這種修正稱之為反規范化設計,反規范化通過有意地違反數據庫設計中的規范化原則,將數據冗余存儲在多個表中,通過減少表之間的連接來提高查詢性能,從而加快查詢速度。但是,反規范化也會增加數據冗余,增加數據更新和維護的難度。因此,在進行規范化時,需要仔細考慮權衡各種因素,以確保數據的一致性完整性。
????反規范化數據庫不應該與從未進行過標準化的數據庫相混淆。常見的反規范化操作有冗余列、派生列、表重組和表分割,其中表分割又分為水平分割和垂直分割。反規范化會在數據庫中形成數據冗余,為解決數據冗余帶來的數據不一致性問題,設計人員往往需要額外采用數據同步的方法來解決這種數據不一致性。常見的方法有應用程序同步、批量處理同步和觸發器同步等。
5.1. 冗余列
????冗余列是指在一個表中重復存儲相同的信息,以便于快速訪問和提高查詢效率。例如,如果一個訂單表中包含了客戶ID和地址ID,而這些信息又分別存儲在另一個客戶表和地址表中,那么可以在訂單表中直接存儲這些冗余信息,從而避免了多次表連接的需要,提高查詢速度。
5.2. 派生列
????派生列是基于其他列計算得出的列。在反規范化設計中,可以通過添加派生列來存儲計算結果,這樣可以減少對原始數據的查詢次數。例如,如果一個銷售表中需要頻繁計算總金額,可以在該表中添加一個派生列來存儲這個總金額,從而提高查詢效率。
5.3.?表重組
????表重組是指重新組織數據庫中的表結構,使其更適合于特定的查詢需求。這種方法通常涉及到將多個小表合并成一個大表,或者將一個大表拆分成多個小表。這樣做的目的是減少表之間的關系,簡化查詢邏輯,從而提高查詢性能。
5.4.?表分割
????表分割是指將一個大表根據某些條件分割成多個小表。每個小表只包含部分數據,但這些小表共同構成了原來的大表。這種方法可以有效地利用分布式數據庫系統的特性,通過將數據分布到不同的服務器上,可以顯著提高查詢性能和數據處理能力。
5.4.1. 水平分割
????水平分割是根據數據行的特點進行分割,分割之后所得的所有表的結構都相同,而存儲的數據不同。例如我國的身份證號碼若放在一個表中,由于我國人口眾多,因此數據量大,進行身份證查詢時效率低。這時可以按省份對它進行水平分割,把不同區域的身份證號分別存儲在不同的表中,查詢時只需根據省份代碼檢索相應的表,這顯然能提高查詢速度。水平分割會給應用增加復雜度,特別在查詢所有數據需要union(并)操作。在許多數據庫應用中,這種復雜性會超過它帶來的優點,因此,只有當表中數據具有很好獨立性時才適合使用此方法。
5.4.2.?垂直分割
????垂直分割是根據數據列的特點進行分割,分割之后所得的所有表中除了都含有主碼列外其余列都不相同。一般在一個表中某些列常用,而另外一些列不常用的情況下可以采用垂直分割,分割時把操作時常用與不常用的列分別放入不同的表中,這就使得數據行變小,一個數據頁就能存放更多的數據,在查詢時就會減少I/O次數,而且大多數據操作只在少數或者一個表中進行,從而提高系統性能,但其缺點是查詢所有數據時需要join(鏈接)操作。





)













