1 from_pretrained
- 從預訓練模型配置中實例化一個 PyTorch 預訓練模型
- 默認情況下,模型使用
model.eval()設置為評估模式(Dropout 模塊被禁用)- 要訓練模型,應該首先使用
model.train()將其設置回訓練模式
- 要訓練模型,應該首先使用
1.1 主要參數
| pretrained_model_name_or_path | 需要加載的模型,可以是:
|
| from_tf | (bool, 可選,默認為 False) - 從 TensorFlow 檢查點保存文件中加載模型權重 |
| force_download | (bool, 可選,默認為 False) - 是否強制(重新)下載模型權重和配置文件,覆蓋已存在的緩存版本 |
| local_files_only | (bool, 可選,默認為 False) - 是否只查看本地文件(即,不嘗試下載模型) |
1.1.1?大模型推理相關主要參數
| torch_dtype | (str 或 torch.dtype, 可選) — 覆蓋默認的 torch.dtype,并在特定的數據類型下加載模型
|
| device_map |
|
| quantization_config | huggingface 筆記:AutoTokenizer,AutoClass-CSDN博客 一個量化配置參數字典 |
1.2 舉例
from transformers import LlamaModelm=LlamaModel.from_pretrained('meta-llama/Meta-Llama-3-8B')
m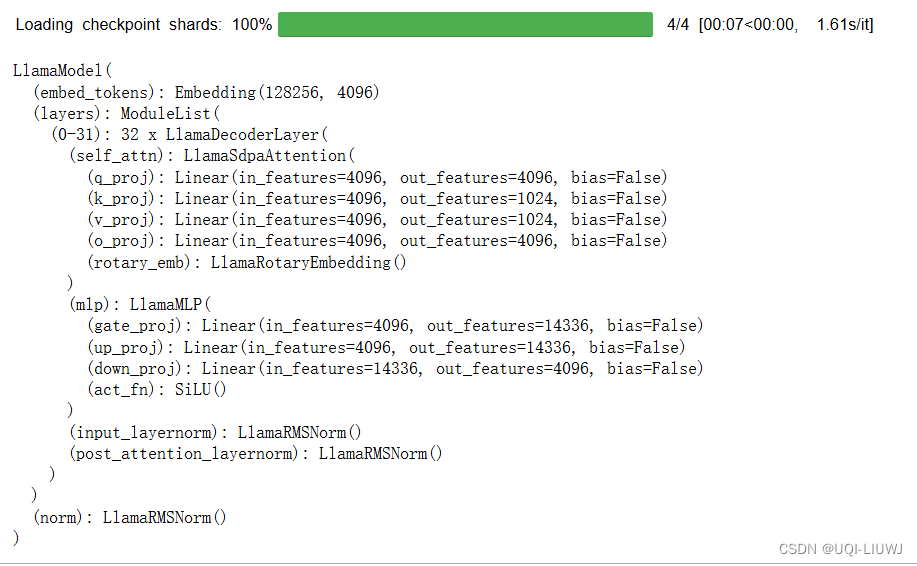
2 can_generate
- 該模型是否能夠使用
.generate()方法生成序列。 - 該函數返回一個布爾值,指示該模型是否支持使用
.generate()方法來生成序列。 - 這通常用于判斷某個模型是否具備生成文本的能力,例如語言模型或文本到文本的轉換模型。
m.can_generate()
#False3 get_input_embeddings
返回模型的輸入嵌入,即將詞匯映射到隱藏狀態的 PyTorch 模塊
m.get_input_embeddings()
#Embedding(128256, 4096)4?get_memory_footprint
獲取模型的內存占用(以字節為單位)
m.get_memory_footprint()
#300197068805?get_output_embeddings
返回模型的輸出嵌入,即將隱藏狀態映射到詞匯的 PyTorch 模塊
6?init_weights
初始化權重
7?resize_token_embeddings
resize_token_embeddings(new_num_tokens)- 嵌入矩陣中的新令牌數量。
- 增加大小將在末尾添加新初始化的向量。
- 減少大小將從末尾移除向量。
- 如果未提供或為 None,則只返回指向模型的輸入令牌
torch.nn.Embedding模塊的指針,不進行任何操作。
8?set_input_embeddings
set_input_embeddings(value: nn.Module)
自定義模型的輸入嵌入層,通過提供一個新的 nn.Module 來替換默認的輸入嵌入

MySQL 索引)
)






:從搭建實驗環境到實戰演練的全面教程)






JNI方式 獲取)


:Linux 系統上 C 程序的編譯與調試)