


大數據產業創新服務媒體
——聚焦數據?· 改變商業
一說到計算機視覺,大多數人第一時間聯想到的便是“人臉識別”、“自動駕駛“、道路檢測”等跟我們日常生活息息相關的關鍵詞。而在2024年的5月末,微軟在GitHub上面上傳了這樣一個計算機視覺的項目,完全不包含這些關鍵詞,卻吸引來了無數人圍觀,短短兩天時間就沖到了700顆星。
這個項目就是Pytorch-Wildlife。項目成立的初衷是因為人類活動導致全球生物多樣性急劇下降,對野生動物種群的全面監控變得尤為迫切。
可是想要完全利用人力,來對某一種群或者某一塊棲息地進行24小時監控,這顯然是不現實的。不僅僅是因為成本過于高昂,而是人類肉眼很難完整觀察清楚一些行動迅敏的動物,這就會導致沒有辦法準確記錄物種以及棲息地情況。于是在這個大背景下,Pytorch-Wildlife誕生了。
PyTorch-Wildlife是一個用于創建、修改和共享強大 AI 保護模型的平臺。這些模型可用于各種應用,包括相機陷阱圖像(當檢測到動物經過時進行拍照)、俯視圖像、水下圖像以及生物聲學。通俗來講,項目是利用數據集和深度學習架構來實現保護野生動物的目的。
項目的原理其實并不復雜。首先,利用了Megadetector v5進行對象檢測,這是一個預先訓練好的模型,用以過濾掉空圖像或含有非動物對象(如人類和車輛)的圖像。
 圖:亞馬遜叢林的動物
圖:亞馬遜叢林的動物
Megadetector是基于Yolov5檢測模型架構,專門為動物檢測設計的深度學習模型。能夠處理來自不同地區和生態系統的大約300萬張動物圖像。
接下來,對所拍攝的視頻和圖像進行采集,把采集得到的數據喂給Megadetector v5進行識別篩選。其中,對于視頻數據,每段視頻按30fps的幀率被拆分成圖像幀,如果原視頻幀率低于30fps,則使用原始幀率。這種取舍可以平衡模型的運行效率以及識別精準度。
針對檢測到的動物對象,Pytorch-Wildlife會將它們裁剪并調整至256x256像素的尺寸,并根據圖像級別的標注為每個裁剪圖像分配標簽。
大多數深度學習模型,尤其是卷積神經網絡(CNN),它對輸入的素材是有嚴格規范的。256x256其實是一個常見的選擇,因為它既能保持一定的圖像細節,又不會使計算負擔過大。
在裁剪之后,利用Pytorch-Wildlife的分類微調模塊,采用ResNet-50作為基礎模型架構,進行動物的識別訓練。訓練設置包括60個訓練周期,批量大小為128,采用隨機梯度下降優化器,并設定學習率在每20個周期后衰減。
以往來看,開發者需要對模型進行微調,模型才能夠更好地理解和區分特定的動物類別,提高在實際野生動物監測任務中的識別準確率。而Pytorch-Wildlife框架提供的微調模塊則簡化了這一過程,使得即使是沒有深厚技術背景的研究人員,也能利用先進的深度學習技術進行動物識別模型的定制化訓練。
Pytorch-Wildlife團隊準備兩份案例,第一個是在亞馬遜叢林中檢測動物。
亞馬遜雨林是世界上最大的熱帶雨林,是地球上生物多樣性最豐富的地區之一。亞馬遜雨林里的動物數量是非常驚人的,已知的動物種類超過了10萬種,這包括鳥類、哺乳動物、爬行動物、兩棲動物以及其他無脊椎動物等。但是這個數字僅僅是已記錄和描述的物種,現代學者普遍認為,還有成千上萬甚至是數百萬種動物物種尚未被發現和描述。由于亞馬遜雨林的廣闊和復雜性,新的物種仍在不斷被發現,因此確切的動物種類數量是一個不斷變化且難以精確統計的數字。
Pytorch-Wildlife使用了一個包含41904張圖像的數據集,這些圖像覆蓋了36個已標記的動物屬,其中33569張用于訓練,8335張用于驗證。
在亞馬遜雨林項目中,模型實現了92%的識別準確率,針對90%的數據集在98%的置信度閾值下正確預測。這意味著,大部分動物圖像能夠被準確分類,只有少量需要人工審核。
除了亞馬遜叢林的案例外,Pytorch-Wlidlife還有一個在加拉帕戈斯群島的項目。這個項目的背景非常獨特,雖然加拉帕戈斯群島的動物種類也很多,然而這個脆弱的生態系統正面臨外來入侵物種的重大威脅,這些物種可能改變本地物種的種群動態并導致它們滅絕。
Pytorch-Wlidlife檢測到,一些負鼠通過船只、陸地等手段,正在入侵加拉帕戈斯群島的生態。對本地生物構成了競爭壓力,因此連續的監測和管理對于維持生態平衡至關重要。
項目中使用的數據集包含491471段視頻,這些視頻被標記為“負鼠”或“非負鼠”。數據集被劃分為訓練集和驗證集,分別包含343053段和148418段視頻。
經過驗證,Pytorch-Wildlife平臺訓練的模型針對入侵的負鼠識別達到了98%的準確率。比如下面兩張圖,由于是夜間拍攝的緣故,即便是人的肉眼也很難第一時間分清兩種動物。第一張圖片是當地的食蟻獸,第二張是外來入侵物種負鼠。
 圖:食蟻獸
圖:食蟻獸
 圖:負鼠
圖:負鼠
這部片接下來要怎么拍?
Pytorch-Wildlife在監控和識別上初步取得了成功,不過這對于保護生態平衡上來說顯然還是遠遠不夠的。未來Pytorch-Wildlife將會連接LILA:BC數據集,進一步提高對物種識別的能力。
LILA數據集指的是亞歷山大圖書館的標注信息庫:生物與保護(Labeled Information Library of Alexandria:Biology and Conservation),這是一個專注于生物學和野生動物保護領域的數據集庫,提供了多樣化的開放數據資源,用于促進野生動植物的監測、保護生物學研究以及生態系統的管理。
LILA數據集包含大量經過標注的信息,比如圖片、視頻和其他類型的數據,這些數據有助于科學家和保護工作者利用機器學習和深度學習技術來識別和跟蹤野生動物,評估生物多樣性。此外,通過使用LILA進行與訓練,還能夠監測生態系統的健康狀況。
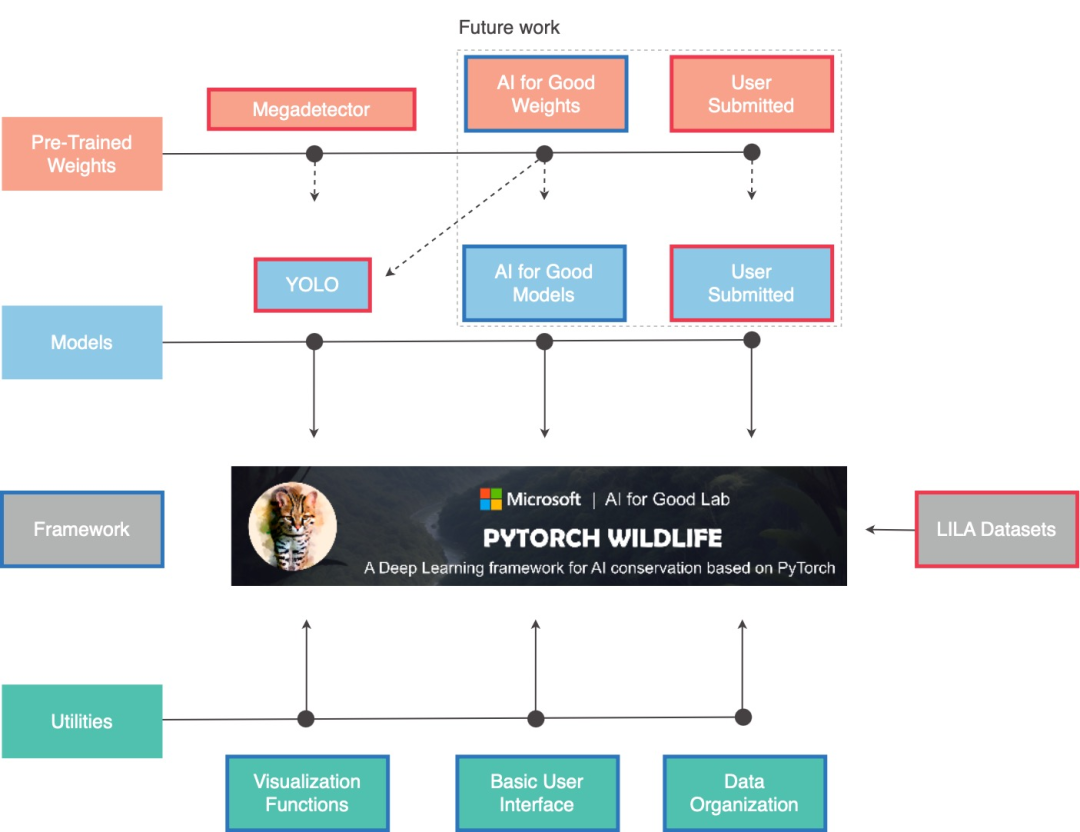 圖:Pytorch-Wildlife未來的規劃圖
圖:Pytorch-Wildlife未來的規劃圖
數據猿也體驗了一下Megadetector的實力。識別模型選擇Megadetector v5,檢測模型選擇的是亞馬遜叢林。可以明顯看出,只要是亞馬遜叢林中出現的動物,Megadetector都能很好的識別出來。
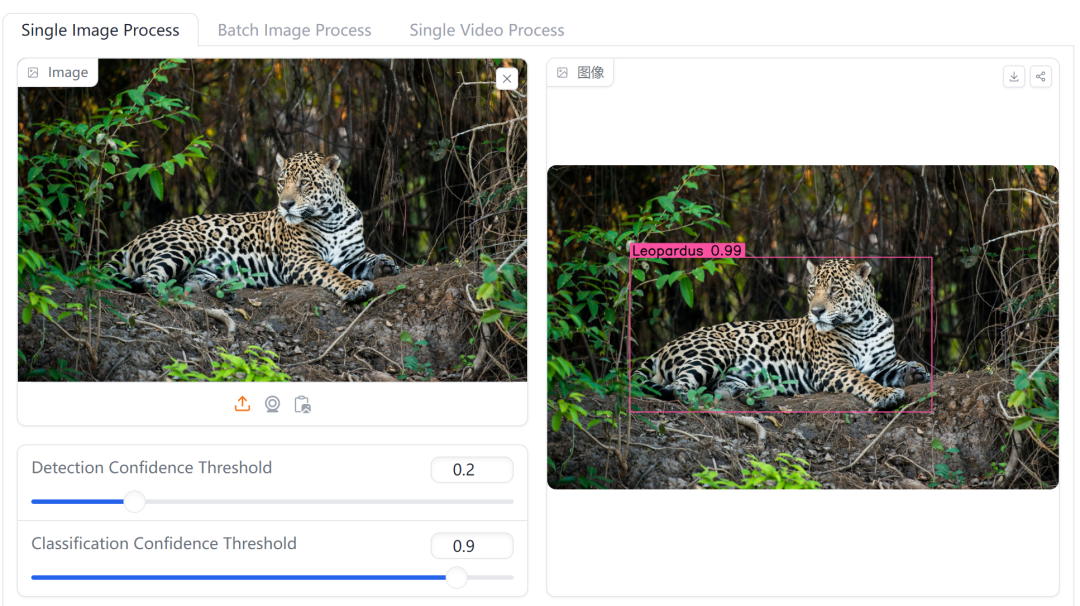 圖:亞馬遜叢林中的豹子
圖:亞馬遜叢林中的豹子
不過像是數據猿LOGO這種卡通動物形象,即便把識別閾值拉滿,Megadetector也沒有辦法識別出來。相反,如果是真實的動物,Megadetector只需要很低的閾值就能識別。
 圖:Megadetector無法識別卡通動物形象
圖:Megadetector無法識別卡通動物形象
根據開發團隊的介紹,Megadetector的最新版本,也就是Megadetector v6即將上線,識別率遠超v5版本,同時消耗的計算資源更低。目前,使用Megadetector v5檢測一張圖片耗時約為20秒,而v6版本將會讓耗時小于15秒。
另外Megadetector v6還會支持更多的低預算設備,這是因為在亞馬遜叢林等地,溫熱潮濕的生態環境會使得拍攝設備損壞率提高,沒辦法長期維持成本高昂的拍攝設備。然而成本較低的拍攝設備會導致拍攝畫面的分辨率低下,幀數低下等等,對Megadetector的識別作業起到非常負面的影響。
在未來,Pytorch-Wildlife會支持更多種類的識別方式,比如鳥瞰圖、水下拍攝。這何嘗不是一種新的云養殖野生動物的方法?
AI For Good
Pytorch-Wildlife屬于典型的AI For Good項目,這個概念由微軟提出,不過與其說是概念,更像是一種倡議。它是指在推動人工智能技術的發展與應用,以解決全球性的社會、環境和經濟挑戰,促進可持續發展。這一理念鼓勵科研人員、企業、政府、非政府組織以及社會各界合作,利用人工智能的力量創造正面影響,確保技術進步惠及全人類和地球生態。
不一定非得是動物,其他類似的方式都可以算是AI For Good。例如,通過機器學習算法監測森林砍伐、海洋污染、氣候變化和生物多樣性減少,以及開發智能系統優化資源利用和能源管理。
事實上,Pytorch-Wildlife的核心,Megadetector,幾乎沒有辦法復刻任何的商業途徑。但這個項目依然擁有足夠高的關注度,說明人們關注AI,使用AI技術,眼里并不是只有它的商業化能力,而是如何去使用AI,來建設賴以生存的家園。當然了,也有一部分人是沖著這個項目可以免費看真正的野生動物去的。
國內也有不少AI公司著手于類似的項目,比如百度的“綠色伙伴計劃”,通過AI來減少碳排放。根據記錄,百度地圖“低碳計劃”全年累計訪問量超過 4000 萬人次,累計可減少碳排放量超 3800 噸。
還有騰訊的“自然風險評估”,應用AI調優技術,騰訊2023年當年減少用電量約5000兆瓦時,避免碳排放2851.5噸。
文:火焰翼人?/?數據猿
責編:凝視深空?/?數據猿





)










)




含動圖)
_2)

