屬性文法
也稱為屬性翻譯文法,由 Knuth 提出,以上下文無關文法為基礎
(1)為每個文法符號(終結符與非終結符)配備相關的屬性,代表與該文法符號相關的信息
(2)屬性文法對于每個產生式都配備了對應的語義規則,標明了語義關系的傳遞

屬性的分類
綜合屬性
自下而上的傳遞信息,根據產生式右部的符號屬性計算左部被定義符號的綜合屬性
在語法樹中,即根據子節點的屬性和自身的自身屬性來計算父節點的綜合屬性
繼承屬性
自上而下傳遞信息,根據右部候選式的符號屬性與左部的屬性計算右部候選式中符號的繼承屬性

屬性依賴
對于每個產生式 A → α A \to \alpha A→α都有對應的語義規則,每條規則的形式可以寫作:
b,c1,c2 等都為標識符對應的屬性
b = f ( c 1 , c 2 , . . . , c k ) b = f(c_1,c_2,...,c_k) b=f(c1?,c2?,...,ck?)
則我們說red:屬性 b 依賴于 c1,c2 等
這種依賴又分為我們所提到的綜合屬性或繼承屬性
(1)若 b 為綜合屬性,則 c1,c2 等為產生式右部文法符號的屬性
(2)若 b 為右部某個文法符號的繼承屬性,則 c1,c2 可能為產生式左部或右部任何符號的屬性
注意:因為終結符沒有子節點,所以終結符只有綜合屬性,由詞法分析器提供
語義規則
(1)對出現在右邊的繼承屬性和左邊的綜合屬性都必須提供相應的計算規則,而且只能使用相應產生式中的文法符號
(2)出現在左邊的繼承規則和右邊的綜合屬性不由對應產生式的屬性計算規則進行計算,而是由其他產生式的屬性規則計算或者由相關參數提供
帶注釋的語法樹
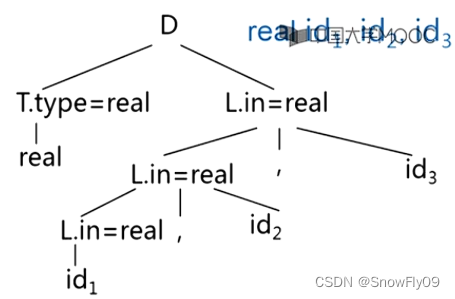
e.g.3*5+4n 利用第一組產生式
對于綜合屬性,一邊自下而上分析構建語法樹一邊使用語義規則代入
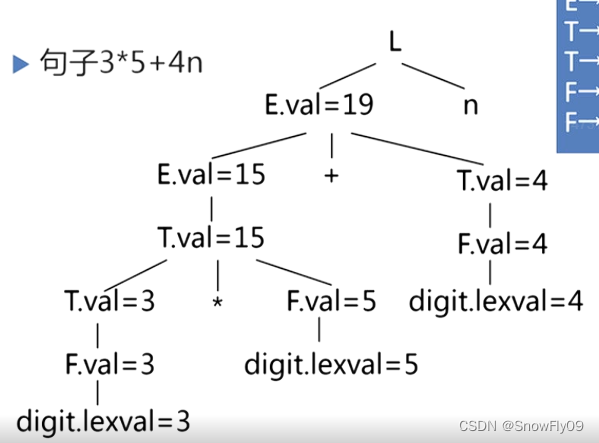
由此可以得到帶注釋的語法分析樹
對于繼承屬性,則先構建語法樹,然后自上而下填寫,對于 addtype,就是在符號表中填寫其對應名字,屬性對應 addtype 中后項(通常為父節點)所對應的屬性
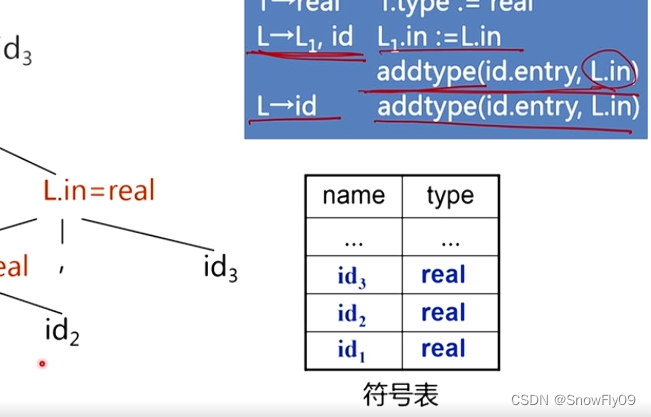
屬性計算
語義規則的計算可以用來:產生代碼/在符號表中存放信息/執行動作,blue:對輸入串的翻譯就是根據語義規則的計算
語法制導翻譯法就是將輸入串轉化為合適的語法樹,然后選擇適合的語法規則計算屬性
基于語法的語義分析方式是多樣的,主要有以下三種:
(1)依賴圖
(2)樹遍歷
(3)依賴掃描
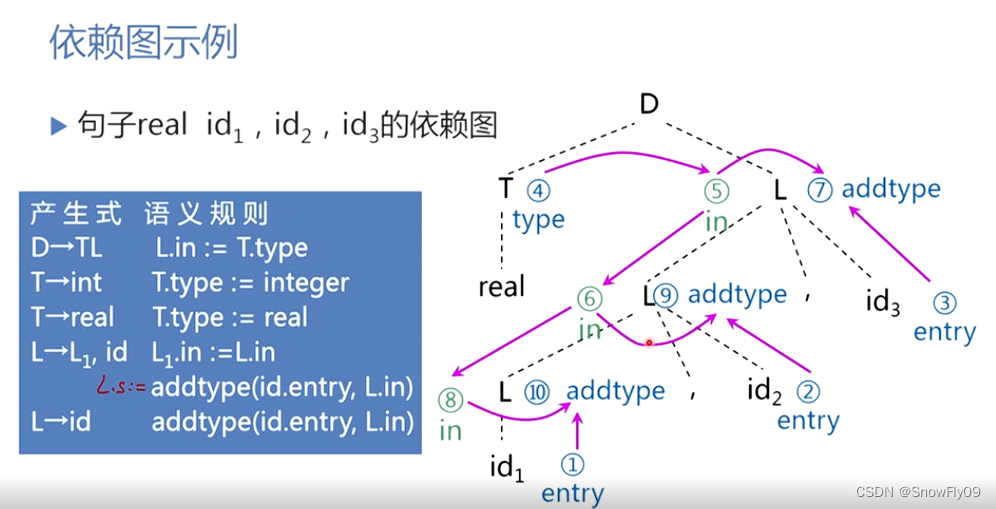
依賴圖
一顆語法樹中的節點的繼承屬性和綜合屬性的依賴關系可以由依賴圖來描述
若屬性 b 依賴于屬性 c,則從 c 有一條有向邊指向屬性 b
根據依賴圖,如果一個屬性文法不存在屬性之間的循環依賴關系(環),則稱則稱該文法是良定義的
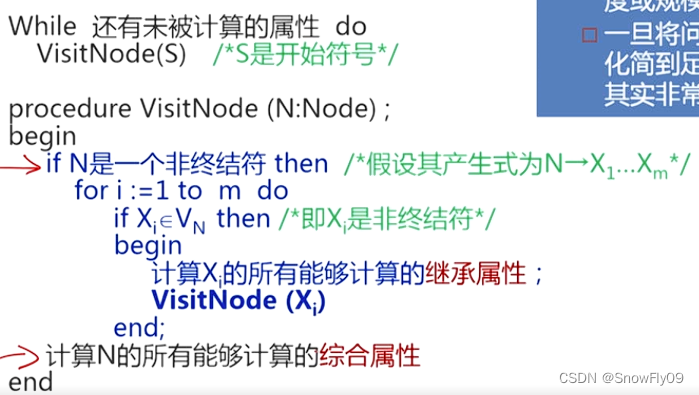
樹遍歷
假設語法樹已建立,且樹中已帶有開始符號的繼承屬性和終結符的綜合屬性,此后以某種遍歷順序遍歷語法樹,直到最終所有屬性都被計算出來
遞歸的調用 VisitNode 方法
一遍掃描
語法樹需要反復使用 visitNode,屬于多遍掃描,一遍掃描則是根據語法分析的過程同時計算屬性值
語義規則的計算時機:
(1)自上而下分析,一個產生式匹配輸入串成功時計算語義規則
(2)自下而上分析,一個產生式被歸約時計算語義規則
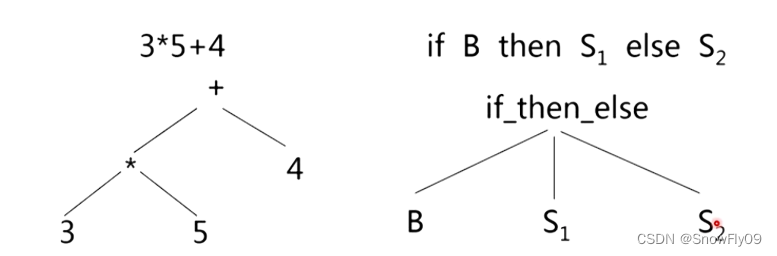
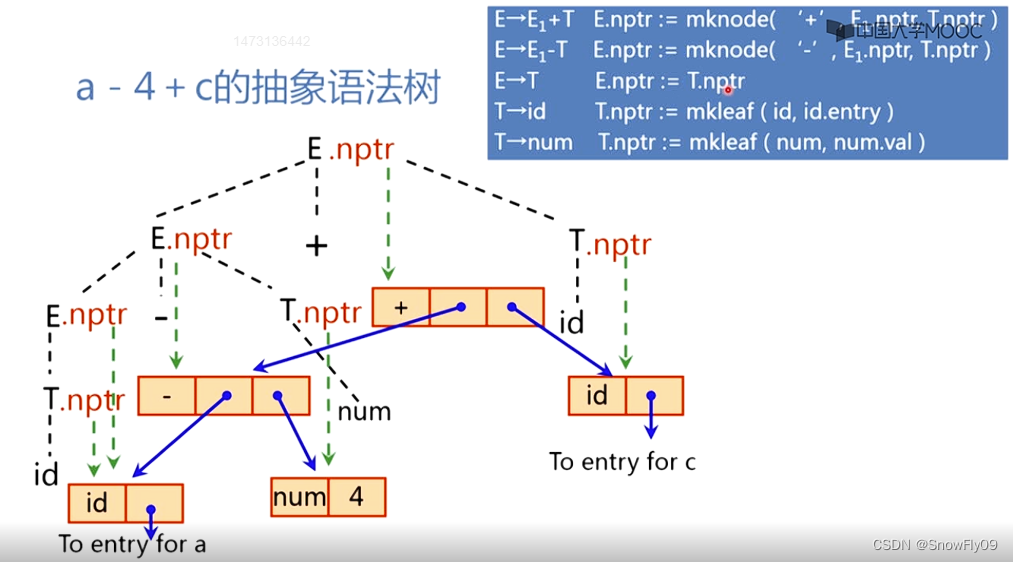
抽象語法樹:
建立表達式的抽象語法樹
mknode(op,left,right)建立運算符號節點,left 和 right 分別指向左子樹和右子樹
mkleaf(id,entry)建立標識符節點
mkleaf(num,val)建立數節點
一遍掃描與自下而上的語法分析器配合工作
S屬性文法
只含有綜合屬性,使用自下而上的分析器,在原本的狀態-符號棧中 增加附加域存放綜合屬性值
假設 A → X Y Z A \to XYZ A→XYZ對應的語義規則為 A . a = f ( X . x , Y . y , Z . z ) A.a = f(X.x,Y.y,Z.z) A.a=f(X.x,Y.y,Z.z)
歸約時,將 X、Y、Z 的狀態,符號,屬性彈出,然后將 A 的狀態符號屬性壓入棧頂
L 屬性文法
L 屬性文法適合一遍掃描的自上而下分析,通過深度優先地遍歷語法樹。對于 A → X 1 X 2 . . . X i A \to X_1X_2...X_i A→X1?X2?...Xi?,Xi 的繼承屬性依賴于:
(1)A 的繼承屬性
(2)Xi 左邊符號 X1,X2 等的屬性,而不包括右側
red:S屬性文法屬于 L 屬性文法
翻譯模式
語義規則只給出了屬性計算的定義,但是沒有給出屬性計算的先后順序,可以在屬性文法的基礎上進一步給出使用順序,就叫翻譯模式
翻譯模式:將語義規則與屬性用花括號括起來放在合適的位置上,用來表示語法制導翻譯的時機
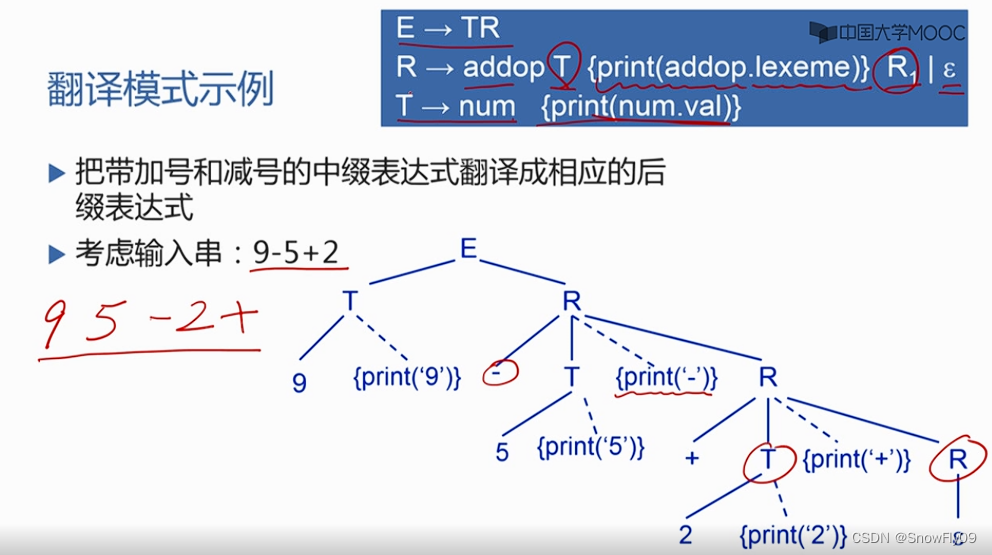
注意將中綴表達式換成了后綴表達式
(1)當只需要綜合屬性的時候,將賦值動作放在相應產生式最右側的末尾
T → T 1 ? F T . v a l : = T 1 . v a l × F . v a l T \to T_1*F\\ \\{T.val:=T_1.val\times F.val\\} T→T1??FT.val:=T1?.val×F.val
(2)如果既有綜合屬性又有繼承屬性,在建立翻譯模式時就必須保證:產生式右邊符號的繼承屬性必須在這個符號之前計算出來
(3)一個動作不能夠使用其右邊的綜合屬性
(4)產生式左部的非終結符的綜合屬性必須等其所有應用的屬性被計算出之后才能計算,且需要放在末尾計算
語義動作時機統一
如果能夠使所有語義動作都放在產生式的末尾,就可以使每次語義執行的時機統一
方法:
(1)添加一個產生式: M → ? M \to \epsilon M→?
(2)把嵌入在產生式中間的語義動作用 M 代替,并將這個動作放在產生式 M TO EPSILON 的末尾

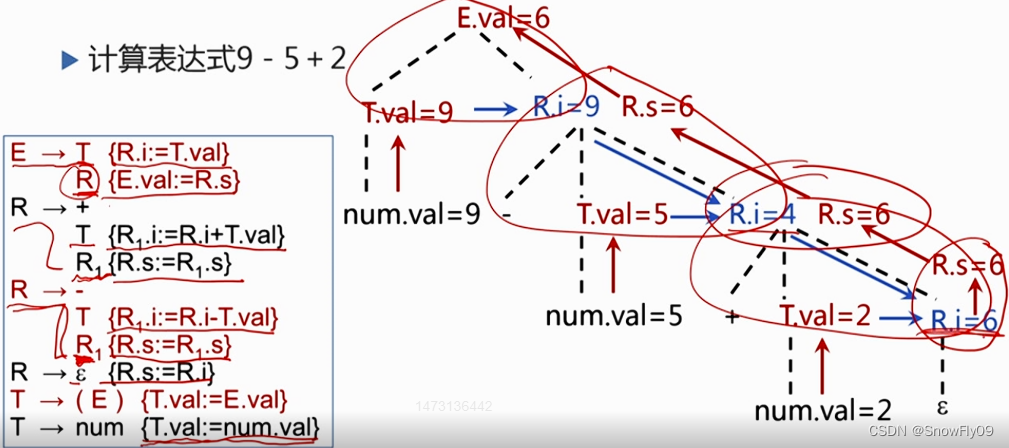
消除翻譯模式的左遞歸

這里可以理解 R.i 為繼承屬性,R.s 為綜合屬性,繼承屬性必須放在非終結符前,所以 Ri 的語義動作都在 Ri 前,Rs 則放在產生式最后給左部賦值
)



-鎖和事務模型(2)-事務模型)


)

)
)




——包含公式)


![[協議]stm32讀取AHT20程序示例](http://pic.xiahunao.cn/[協議]stm32讀取AHT20程序示例)
