一、爬蟲的基本概念
1.什么是爬蟲?
????????????????請求網站并提取數據的自動化程序
2.爬蟲的分類
??? 2.1 通用爬蟲(大而全)
??????? 功能強大,采集面廣,通常用于搜索引擎:百度,360,谷歌
??? 2.2 聚焦爬蟲,主題爬蟲(小而精)
??????? 功能相對單一(只針對特定的網站的特定內容進行爬取)
??? 2.3增量式爬蟲(只采集更新后的內容)
??????? 爬取更新后的內容,新聞,漫畫,視頻…(區分新老數據)
3.ROOT協議
????????什么是robots協議?
????????3.1 Robots協議的全稱是"網絡爬蟲排除標準" (Robots Exclusion Protocol),簡稱為Robots協議。
????????3.2 Robots協議的一個很重要作用就是網站告知爬蟲哪些頁面可以抓取,哪些不
行。君子協定:指代的是口頭上的協議,如果爬取了,可能會出現法律糾紛(商用).
二、爬蟲的基本流程
1.發起請求
????????通過HTTP庫向目標站點發起請求,即發起一個Request,請求可以包含額外的headers信息,等待服務器響應。
2.獲取響應內容
????????如果服務器能正常響應,會得到一個Response,Response的內容便是索要獲取的頁面內容,類型可能有HTML,Json字符串,二進制數據(如圖片視頻)等類型
3.解析內容
????????得到的內容可能是HTML,可以用正則表達式、網頁解析庫進行解析,可能是Json,可以直接轉為Json對象解析,可能是二進制數據,可能做保存或進一步處理
4.保存數據
?????? 保存形式多樣,可以保存為文本,也可保存至數據庫或者保存特定格式的文件
三、Request和Response
????????1.瀏覽器就發送消息給該網址所在的服務器,這個過程叫做HTTP Request。
????????2.服務器收到瀏覽器發送的消息后,能夠根據瀏覽器發送消息的內容,做相應處理,然
后把消息回傳給瀏覽器。這個過程叫做HTTP Response。
????????3.瀏覽器收到服務器的Response信息后,會對信息進行相應處理,然后展示。
????????4.Request
??? ????4.1 主要有GET、POST兩種類型
????????4.2 URL全稱統一資源定位符,如一個網頁文檔、一張圖片、一個視頻等都可
????????以用URL唯一來確定。
????????4.3 包含請求時的頭部信息,如User-Agent、Host、Cookies等信息。???????
????????4.4 請求時額外攜帶的數據如表單提交時的表單數據。
????????5.Reponse
??????? 5.1 響應狀態
有多種響應狀態,如200代表成功、301跳轉、404找不到頁面、502服務器錯誤
??????? 5.2 響應頭
?????????? 如內容類型、內容長度、服務器信息、設置Cookie等等。
??????? 5.3 響應體
?????????? 最主要的部分,包含了請求資源的內容, 如網頁HTML、圖片二進制數據等。
注意:在監測的時候用Ctrl+F調出搜索框
四、Requests模塊
?????? 作用:發送網絡請求,或得響應數據
開源地址:https://github.com/kennethreitz/requests![]() https://github.com/kennethreitz/requests
https://github.com/kennethreitz/requests
安裝: pip install requests -i https://pypi.douban.com/simple/
?????? 中文文檔 API: http://docs.python-requests.org/zh_CN/latest/index.html![]() http://docs.python-requests.org/zh_CN/latest/index.html
http://docs.python-requests.org/zh_CN/latest/index.html
?????? 官方文檔:??? Requests: 讓 HTTP 服務人類 — Requests 2.18.1 文檔![]() https://requests.readthedocs.io/projects/cn/zh-cn/latest/
https://requests.readthedocs.io/projects/cn/zh-cn/latest/
1.Requests請求
只能得到一個包的數據
url = 'https://www.baidu.com/'
response = requests.get(url)
print(response)#返回的是一個響應體對象print(response.text)#獲取響應體內容print(response.status_code)#響應狀態碼Get請求
url = 'https://httpbin.org/get'#url = 'https://httpbin.org/get?age=18&&name=zhangsan'data = {'name':'zhangsan','age':19}response = requests.get(url,params=data)#params攜帶get請求的參數進行傳參print(response.text)Post請求
rl = 'https://httpbin.org/post'data = {'name':'zhangsan','age':19}response = requests.post(url,data=data)#data:攜帶post請求需要的表單數據,在form里面形成print(response.text)自己理解:
對于Get來說,主要在網址輸入時即輸入URL的時候用到,而POST則是在網頁里面,比如翻譯時的單詞輸入等
??????
獲取Json數據
url = 'https://httpbin.org/get'result = requests.get(url)result_data = result.json()print(result_data)print(type(result_data))會發現Py里面的Json數據就是字典類型
獲取二進制據數據
url = 'https://b.bdstatic.com/searchbox/icms/searchbox/img/ci_boy.png'result = requests.get(url)#print(result.text) #二進制數據轉文本會顯示亂碼,strprint(result.content)#會發現是以b開頭的bite類型二進制數據,bytesdata = result.contentwith open('TuPian.png','wb') as f:? #wb是寫入二進制f.write(data)初步偽裝小爬蟲——添加headers
????????????? 瀏覽器用戶身份的標識,缺少的話服務器會認為你不是一個正常的瀏覽器用戶,而是一個爬蟲程序
?????? User-agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36 Edg/124.0.0.0
import requestsimport fake_useragentua = fake_useragent.UserAgent()ua_fake = ua.chromeurl = 'https://www.jianshu.com/'headers = {#'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36 Edg/124.0.0.0''User-Agent':ua_fake}result = requests.get(url,headers = headers)print(result.text)會話維持
?????? 例如爬取簡書的收藏的時候,如果不登陸就無法爬取,可以在headers里面增加cookie內容即可,但要注意的是cookie有對應的時間
import requestsimport fake_useragentua = fake_useragent.UserAgent()ua_fake = ua.chromeurl = 'https://www.jianshu.com/'headers = {#'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36 Edg/124.0.0.0''User-Agent':ua_fake,'cookie':''}result = requests.get(url,headers = headers)print(result.text)代理
import requestsp = {'http':'120.41.143.139:21037','https':'120.41.143.139:21037',
}url = 'https://www.jianshu.com/'headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36 Edg/124.0.0.0'}result = requests.get(url,headers = headers,proxies=p)print(result.text)?????? 注意的是這里的ip無效,后面繼續展開
五、正則表達式
?????? 1.正則表達式是對字符串操作的一種邏輯公式,就是用事先定義好的一些特殊字符以及這些特殊字符的組合,組成一個“規則字符串”,這個“規則字符串”用來表達對字符串的一種邏輯過濾
?????? 2.非Python獨有
????????3.Python里面是使用re模塊來實現的,不需要額外進行安裝,是內置模塊
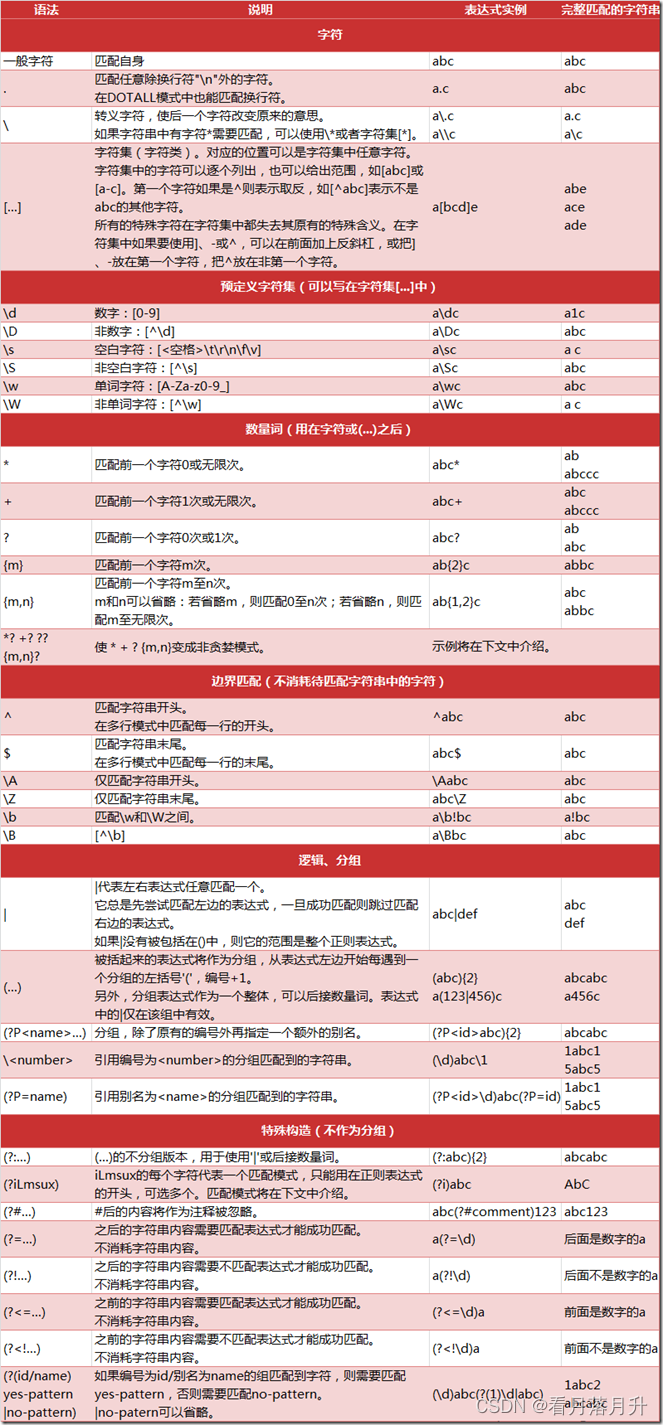
常見匹配模式
? ? ? ? ? ? ?
??????
re.match()方法的使用
import re#content = 'Hello 123 456789 World_This is a Regex Demo'#re.match('正則表達式','目標字符串')#result = re.match('Hello\s\d\d\d\s\d{6}\s\w{10}',content)#print(result.group())#result = re.match('H.*Demo',content)#result = re.match('Hello\s(\d{3})\s(\d{6})',content)#print(result.group(1))? #這里0表示最先出現的括號,1表示第二次出現的括號#print(result.group(1,2))??? #這是一個元組,后面處理較麻煩#content = 'Hello 123456789 World_This is a Regex Demo'#result = re.match('He.*(\d+).*Demo',content)#因為貪婪模式的存在,在He之后,Demo之前至少有一個數字字符,即9#print(result.group(1)) #打印的為9#加上?后,即為非貪婪#result = re.match('He.*?(\d+).*Demo',content)#print(result.group(1))#content = """Hello 123456789#World_This# is a Regex#? Demo"""#result = re.match('He.*?(\d+).*Demo',content,re.S)#re.S忽略換行符#print(result.group())#\轉義符,如果對\轉義,則需要兩個\\,也可以直接寫r,再接一個\#content = 'price is $9.99'#result = re.match('price\sis\s\$9.99',content) #$這個在正則表達式有自己的含義#print(result.group())search方法
search全文檢索,返回滿足表達式的第一個
#result = re.search('<a\s\href="/3.mp3"\ssinger="(.*)">(.*)</a>',html)#print(result.group(1))Findall方法
用一個大列表返回滿足所有的正則表達式結果
#result = re.findall('<a\s\href="(.*)"\ssinger="(.*)">(.*)</a>',html)#for i in result:#?? print(i)Re.sub()
#re.sub('要替換的目標的正則表達式','想要將前面匹配到的數據替換成什么','目標字符串')#sub_html = re.sub('<i.*</i>','',html)#result = re.findall('<a\s\href="(.*)"\ssinger="(.*)">(.*)</a>',sub_html)#for i in result:#?? print(i)


【8-18】)


—— 抽象類、接口、Object類和內部類)












