目錄
- 前言
- 一、DB-GPT總體概述
- 二、DB-GPT關鍵特性
- 1、私域問答&數據處理&RAG
- 2、多數據源&GBI
- 3、多模型管理
- 4、自動化微調
- 5、Data-Driven Multi-Agents&Plugins
- 6、隱私安全
- 三、服務器資源準備
- 1、創建實例
- 2、打開jupyterLab
- 四、DB-GPT啟動
- 1、激活 conda 環境
- 2、切換到 DB-GPT 目錄
- 3、導入 SQLite 樣例數據
- 五、DB-GPT運行
- 1、使用命令行工具啟動
- 2、訪問 DB-GPT 頁面
- 六、DB-GPT數據對話
- 1、安裝數據庫
- 2、添加數據源
- 3、綁定數據庫
- 4、對話體驗
- 1)選擇數據對話
- 2)開始數據對話
- 3)錯誤處理
- 4)數據對話1
- 5)數據對話2
- 總結
前言
在當今的人工智能時代,大模型技術的迅猛發展為各行各業帶來了前所未有的變革。這些大模型,以其強大的語言理解和生成能力,正在逐步成為智能化應用的核心。然而,如何高效地利用這些大模型,構建出滿足各種需求的應用,仍然是一個具有挑戰性的問題。DB-GPT,作為一個開源的AI原生數據應用開發框架,應運而生,旨在簡化大模型應用的開發過程,讓構建智能化應用變得觸手可及。本文將深入介紹DB-GPT的核心功能、關鍵特性,并通過實戰操作,展示如何利用DB-GPT進行數據應用開發。
一、DB-GPT總體概述

DB-GPT是一個開源的AI原生數據應用開發框架。目的是構建大模型領域的基礎設施,通過開發多模型管理(SMMF)、Text2SQL效果優化、RAG框架以及優化、Multi-Agents框架協作、AWEL(智能體工作流編排)等多種技術能力,讓圍繞數據庫構建大模型應用更簡單,更方便。

核心能力主要有以下幾個部分:
RAG(Retrieval Augmented Generation),RAG是當下落地實踐最多,也是最迫切的領域,DB-GPT目前已經實現了一套基于RAG的框架,用戶可以基于DB-GPT的RAG能力構建知識類應用。
- GBI:生成式BI是DB-GPT項目的核心能力之一,為構建企業報表分析、業務洞察提供基礎的數智化技術保障。
- 微調框架: 模型微調是任何一個企業在垂直、細分領域落地不可或缺的能力,DB-GPT提供了完整的微調框架,實現與DB-GPT項目的無縫打通,在最近的微調中,基于spider的準確率已經做到了82.5%
- 數據驅動的Multi-Agents框架: DB-GPT提供了數據驅動的自進化Multi-Agents框架,目標是可以持續基于數據做決策與執行。
- 數據工廠: 數據工廠主要是在大模型時代,做可信知識、數據的清洗加工。
- 數據源: 對接各類數據源,實現生產業務數據無縫對接到DB-GPT核心能力。
二、DB-GPT關鍵特性
1、私域問答&數據處理&RAG
DB-GPT支持通過內置、多文件格式上傳、插件自抓取等方式自定義構建知識庫,能夠對海量結構化和非結構化數據進行統一向量存儲與檢索,實現高效的知識管理。此外,DB-GPT還實現了基于RAG的框架,用戶可以基于DB-GPT的RAG能力構建知識類應用,為用戶提供更加智能的問答體驗。
2、多數據源&GBI
DB-GPT支持與多種數據源進行交互,包括但不限于Excel、各類數據庫和數倉,同時支持生成分析報告,為用戶提供深入的業務洞察。GBI,即生成式BI,是DB-GPT項目的核心能力之一,可以為構建企業報表分析、業務洞察提供基礎的數智化技術保障。
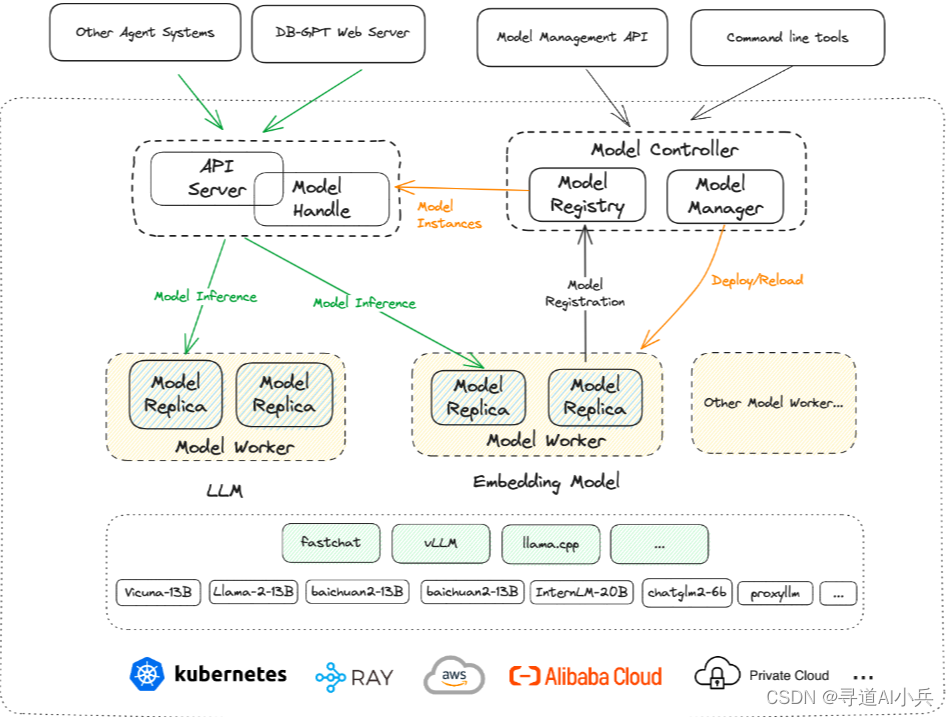
3、多模型管理
DB-GPT支持海量模型,包括多種開源和API代理的大語言模型,如LLaMA/LLaMA2、Baichuan、ChatGLM、文心、通義、智譜、星火等。用戶可以根據需求選擇合適的模型進行應用開發,極大地提高了開發的靈活性和便捷性。
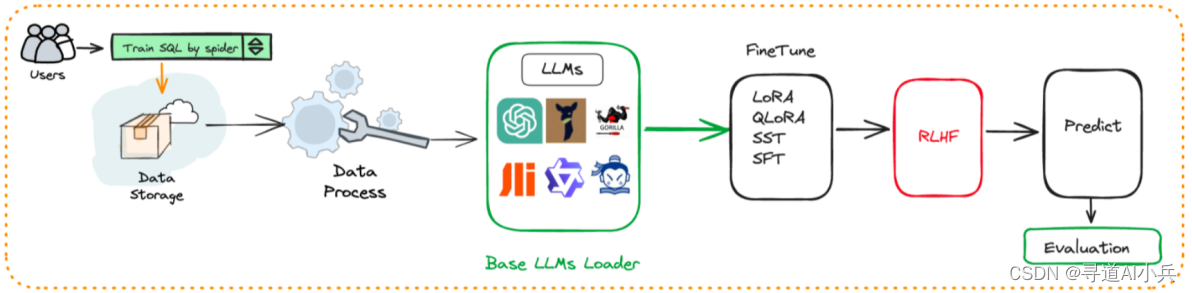
4、自動化微調
圍繞大語言模型、Text2SQL數據集、LoRA/QLoRA/Pturning等微調方法構建的自動化微調輕量框架, 讓TextSQL微調像流水線一樣方便。
5、Data-Driven Multi-Agents&Plugins
DB-GPT支持自定義插件執行任務,并且原生支持Auto-GPT插件模型,通過Agents協議采用Agent Protocol標準,實現智能體之間的協作和任務的高效執行。這種數據驅動的自進化Multi-Agents框架,可以持續基于數據做決策與執行,大大提高了應用的智能化水平。
6、隱私安全
DB-GPT注重數據隱私和安全,通過私有化大模型、代理脫敏等多種技術保障數據的隱私安全。這一點在當今這個數據安全日益受到重視的時代,顯得尤為重要。

三、服務器資源準備
DB-GPT剛好有支持AutoDL的鏡像,因此直接在AutoDL 云平臺時進行實踐操作;在AutoDL云平臺上,選擇一臺4090 GPU24G的服務器,為DB-GPT的運行提供必要的計算資源。打開jupyterLab,選擇“終端”啟動項,打開終端頁面,后續所有操作都基于終端進行操作。
1、創建實例
選擇一臺4090 GPU24G的服務器,進行創建實例。

2、打開jupyterLab
選擇”終端“啟動項,打開終端頁面,后續所有操作都基于終端進行操作。
四、DB-GPT啟動
1、激活 conda 環境
conda activate dbgpt
2、切換到 DB-GPT 目錄
cd /root/DB-GPT/
3、導入 SQLite 樣例數據
bash ./scripts/examples/load_examples.sh

五、DB-GPT運行
1、使用命令行工具啟動
dbgpt start webserver --port 6006
dbgpt 是 DB-GPT 項目的命令行工具,這里利用命令行工具來啟動(當然,你也可以使用命令 python dbgpt/app/dbgpt_server.py --port 6006 來啟動)。
這里使用 6006 端口來啟動服務,這個端口方便在 AutoDL 中開啟公網訪問。
鏡像中默認準備好了 Qwen-1_8B-Chat 和 text2vec-large-chinese 模型文件。

2、訪問 DB-GPT 頁面
在服務器示例列表中,找到自定義服務,點擊。

點擊 “訪問” 后自動打開的頁面如下:

六、DB-GPT數據對話
數據對話能力是通過自然語言與數據進行對話,主要是結構化與半結構化數據的對話,可以輔助做數據分析與洞察。在開始數據對話之前,我們首先需要添加數據源
1、安裝數據庫
步驟1:安裝MySQL數據庫
sudo apt-get update
sudo apt-get install mysql-server
sudo service mysql start
安裝啟動mysql完成之后,登錄mysql(默認無密碼)
mysql -u root -p

步驟2:創建數據庫用戶
CREATE USER 'gpt'@'localhost' IDENTIFIED BY 'gpt';
步驟3:給數據庫用戶賦權限
GRANT ALL PRIVILEGES ON *.* TO 'gpt'@'localhost';
FLUSH PRIVILEGES;
2、添加數據源
1)數據準備
目前DB-GPT支持多種數據庫類型。 選擇對應的數據庫類型添加即可。這里我們選擇的是MySQL作為演示,演示的測試數據:case_1_student_manager_mysql.sql
create database case_1_student_manager character set utf8;
use case_1_student_manager;CREATE TABLE students (student_id INT PRIMARY KEY,student_name VARCHAR(100) COMMENT '學生姓名',major VARCHAR(100) COMMENT '專業',year_of_enrollment INT COMMENT '入學年份',student_age INT COMMENT '學生年齡'
) COMMENT '學生信息表';CREATE TABLE courses (course_id INT PRIMARY KEY,course_name VARCHAR(100) COMMENT '課程名稱',credit FLOAT COMMENT '學分'
) COMMENT '課程信息表';CREATE TABLE scores (student_id INT,course_id INT,score INT COMMENT '得分',semester VARCHAR(50) COMMENT '學期',PRIMARY KEY (student_id, course_id),FOREIGN KEY (student_id) REFERENCES students(student_id),FOREIGN KEY (course_id) REFERENCES courses(course_id)
) COMMENT '學生成績表';INSERT INTO students (student_id, student_name, major, year_of_enrollment, student_age) VALUES
(1, '張三', '計算機科學', 2020, 20),
(2, '李四', '計算機科學', 2021, 19),
(3, '王五', '物理學', 2020, 21),
(4, '趙六', '數學', 2021, 19),
(5, '周七', '計算機科學', 2022, 18),
(6, '吳八', '物理學', 2020, 21),
(7, '鄭九', '數學', 2021, 19),
(8, '孫十', '計算機科學', 2022, 18),
(9, '劉十一', '物理學', 2020, 21),
(10, '陳十二', '數學', 2021, 19);INSERT INTO courses (course_id, course_name, credit) VALUES
(1, '計算機基礎', 3),
(2, '數據結構', 4),
(3, '高等物理', 3),
(4, '線性代數', 4),
(5, '微積分', 5),
(6, '編程語言', 4),
(7, '量子力學', 3),
(8, '概率論', 4),
(9, '數據庫系統', 4),
(10, '計算機網絡', 4);INSERT INTO scores (student_id, course_id, score, semester) VALUES
(1, 1, 90, '2020年秋季'),
(1, 2, 85, '2021年春季'),
(2, 1, 88, '2021年秋季'),
(2, 2, 90, '2022年春季'),
(3, 3, 92, '2020年秋季'),
(3, 4, 85, '2021年春季'),
(4, 3, 88, '2021年秋季'),
(4, 4, 86, '2022年春季'),
(5, 1, 90, '2022年秋季'),
(5, 2, 87, '2023年春季');
執行SQL,創建數據庫,創建數據表、添加數據

2)數據檢查
查看SQL之后,數據是否正常入庫

3、綁定數據庫
將我們創建的MySQL數據庫設置為數據源

配置好數據庫連接信息

4、對話體驗
用戶可以通過自然語言提問,DB-GPT會根據問題的語義理解,生成相應的SQL查詢語句,并將查詢結果以圖表、表格或數據的形式返回給用戶。這樣的交互方式極大地簡化了數據分析的復雜性,使得非技術用戶也能夠輕松地進行數據查詢和分析。
1)選擇數據對話
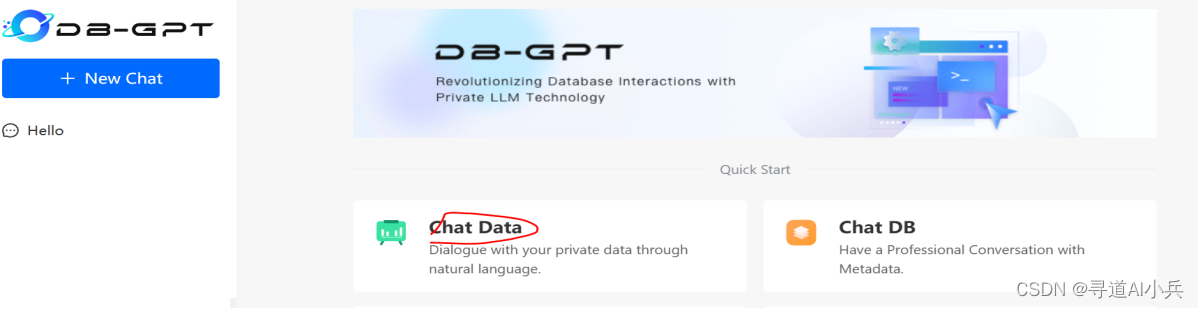
2)開始數據對話
此時界面上數據庫已經默認設置為我們前面綁定的數據庫了,也可以手動選擇
3)錯誤處理
在數據對話的過程中,可能會遇到一些問題,比如缺少必要的Python庫或者模型對某些查詢的處理不夠準確。例如,如果在提問咨詢時遇到“RuntimeError: ‘cryptography’ package is required for sha256_password or caching_sha2_password auth methods”的錯誤,就需要安裝相應的Python庫來解決問題。通過pip install cryptography命令安裝缺少的庫后,需要重新啟動DB-GPT以使更改生效。
pip install cryptography

安裝后重新啟動DB-GPT
4)數據對話1
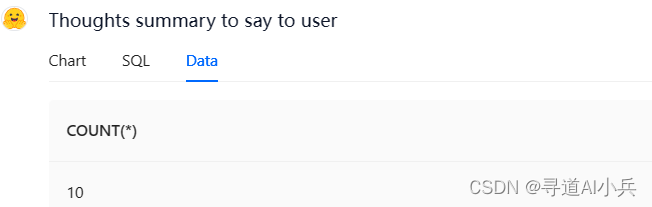
問題:請幫我查詢總共有多少學生?
可以看到數據查詢成功,而且還分3中方式返回Chart、SQL、Data

返回SQL語句,可以檢查相關的SQL是否正確

Data頁簽返回執行結果
SQL執行
還可以點擊上面的Editor按鈕,復制SQL,直接在頁面上執行,查看結果

5)數據對話2
后門連接問了兩次稍微比第一次復雜一點的請求,就搞不定了。

數據對話的體驗展示了DB-GPT在處理結構化和半結構化數據方面的能力,它能夠理解用戶的自然語言查詢,并準確地轉換成SQL語句,執行查詢并返回結果。用戶可以通過簡單的問答形式,獲取到他們需要的數據洞察,這對于數據分析和業務決策來說是非常有價值的。
總結
經過實戰測試,DB-GPT展現了其強大的功能、對多種模型的支持以及良好的界面體驗。但是在交互體驗和復雜任務處理方面存在一定的不足,如果模型的穩定性和任務拆解能力的進一步提升,DB-GPT有望成為大模型應用開發領域的優秀工具。
DB-GPT的開發團隊持續在優化其功能和性能,用戶社區的反饋和貢獻也是推動其進步的重要力量。隨著大模型技術的成熟和應用的普及,我們可以期待DB-GPT在未來能夠提供更加完善和強大的服務,幫助開發者輕松構建出智能、高效的應用,推動人工智能技術在各行各業的應用和發展。

🎯🔖更多專欄系列文章:AIGC-AI大模型探索之路
如果文章內容對您有所觸動,別忘了點贊、?關注,收藏!加入我,讓我們攜手同行AI的探索之旅,一起開啟智能時代的大門!
搭建多群組聯盟鏈)





![[Redis]基本全局命令](http://pic.xiahunao.cn/[Redis]基本全局命令)








)



