Serial回收器:串行回收
- Serial收集器是最基本、歷史最悠久的收集器JDK1.3之前新生代唯一的選擇
- Hotpot中Client模式下的默認新生代垃圾收集器
- 采用復制算法,串行回收“Stop-the-world”機制的方式執行內存回收
- 除了年輕代之外,Serial收集器還提供用于執行老年代垃圾收集的Serial Old收集器,Serial Old收集器同樣采用了串行回收和“Stop-the-world”機制,只不過內存回收算法使用的是標記-壓縮算法
- Serial Old是運行在Client模式下的默認老年代垃圾回收器
- Serial Old在Server模式下有兩個用途①與新生代Parallel Scavenge配合使用②作為老年代CMS收集器的后備垃圾收集方案
- 優勢:簡單而高效,對于限定單個CPU的環境來說,Serial由于沒有線程交互的開銷,專心做垃圾收集
- 在用戶的桌面應用場景中,可用內存一般不大,可以在較短時間內完成垃圾收集,只要不頻繁發生,使用串行回收器可以接受
- 在Hotspot虛擬機中,使用-XX:+UseSerialGC參數可以指定年輕代和老年代都使用Serial
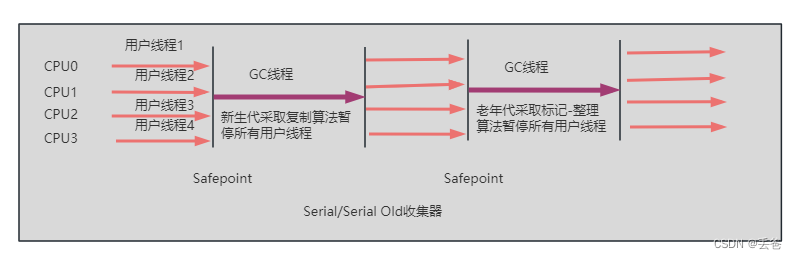
注:Serial收集器是一個單線程收集器,單線程不僅僅說明它只會使用一個CPU或一條收集線程去完成垃圾收集工作,更重要的是在它進行垃圾收集時,必須暫停其他所有的工作線程,直到它收集結束(Stop The World)
//運行參數:-XX:+PrintCommandLineFlags -XX:+UseSerialGC
public class GCUseTest {public static void main(String[] args) {List<byte[]> list = new ArrayList<>();while (true) {byte[] arr = new byte[100];list.add(arr);try {Thread.sleep(10);} catch (InterruptedException e) {e.printStackTrace();}}}
}
//運行結果
-XX:InitialHeapSize=534181568 -XX:MaxHeapSize=8546905088 -XX:+PrintCommandLineFlags -XX:+UseCompressedClassPointers -XX:+UseCompressedOops -XX:-UseLargePagesIndividualAllocation -XX:+UseSerialGC
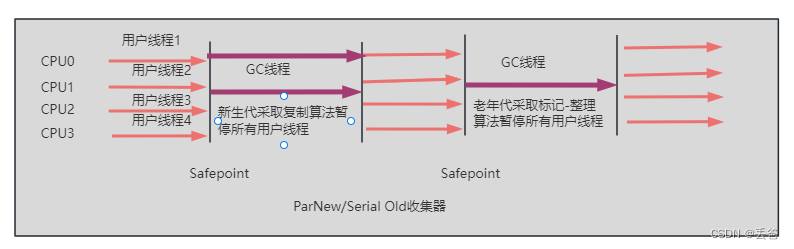
ParNew回收器:并行回收
- Serial收集器的多線程版本
- Par是Parallel的縮寫,New:只處理的是新生代
- ParNew收集器除了采用并行回收的方式執行內存回收外,兩款垃圾收集器之間幾乎沒有任何區別,ParNew收集器在年輕代中同樣也是采用復制算法、"Stop-The-World"機制
- ParNew是很多JVM運行在Server模式下新生代的默認垃圾收集器
- 對于新生代,回收次數頻繁,使用并行方式高效
- 對于老年代,回收次數少,使用串行方式節省資源(并行需要線程切換,串行活動線程切換)
- 參數配置:
- -XX:+UseParNewGC手動指定使用ParNew收集器執行內存回收任務,表示年輕代使用并行收集器,不影響老年代,JDK9已經被移除了
- -XX:ParallelGCThreads 限制線程數量,默認開啟和CPU數量相同的線程數
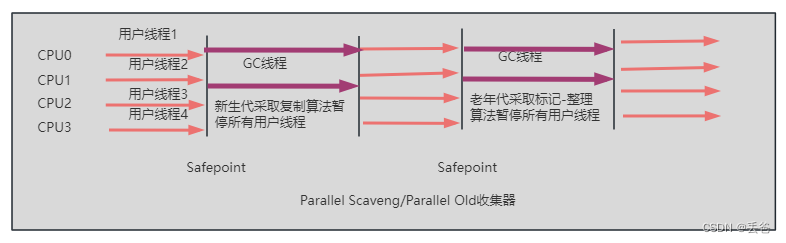
Parallel Scavenge回收器:吞吐量優先
- Parallel Scavenge收集器同樣也采用了復制算法、并行回收和“Stop-The-World”機制
- 和ParNew收集器不同,Parallel Scavenge收集器的目標則是達到一個可控制的吞吐量,它被稱為吞吐量優先的垃圾收集器
- 自適應調節策略也是Parallel Scavenge與ParNew一個重要區別
- 高吞吐量可以高效地利用CPU時間,盡快完成程序的運算任務,主要適合運算而不需要太多交互的任務,因此,常見在服務器環境中使用,如執行批量處理、訂單處理、工資支付、科學計算的應用程序
- Parallel收集器在JDK1.6時提供了用于執行老年代垃圾收集的Parallel Old收集器,用來代替老年代的SerialOld收集器
- Parallel Old收集器采用標記-壓縮算法,便同樣也是基于并行回收和Stop-the-world
- JDK8中默認垃圾收集器
- 參數配置
- -XX:+UseParallelGC:手動指定年輕代使用Parallel并行收集器執行內存回收任務
- -XX:+UseParallelOldGC:手動指定老年代都是使用并行回收器
- 分別適用于新生代和老年代,默認jdk8開啟
- 上面兩個參數,默認開啟一個,另一個也開啟**(互相激活)**
- -XX:ParallelGCThreads:設置年輕代并行收集器的線程數,最好與CPU核心數相等,以避免過多的線程數影響垃圾收集性能。
- 默認情況下,當CPU數量小于8個,ParallelGCThreads的值等于CPU數量
- 當CPU數量大于8個,ParallelGCThreads的值等于3 + [5 * CPU_Count]/8
- -XX:MaxGCPauseMills:設置垃圾收集器最大停頓時間,單位毫秒
- 為了盡可能把停頓時間控制在MaxGCPauseMills以內,收集器在工作時會調整Java堆大小或者其他一些參數
- 對于用戶來講,停頓時間越短體驗越好,但是在服務器端,我們注重高并發,整體的吞吐量,所以服務器端適合Parallel,進行控制
- 該參數使用需謹慎
- -XX:GCTimeRatio:垃圾收集時間占總時間的比例(1/(N+1))用于衡量吞吐量的大小
- 取值范圍(0,100),默認99,也就是垃圾回收時間不超過1%
- 當前一個-XX:MaxGCPauseMillis參數有一定矛盾性,暫停時間越長,Ratio參數容易超過設定的比例
- -XX:UseAdaptiveSizePolicy:設置Parallel Scavenge收集器具有自適應調節策略
- 在這種模式下,年輕代的大小、Eden和Surivior的比例、晉升老年代的對象年齡等參數會被自動調整,已達到在堆大小、吞吐量和停頓時間之間的平衡點
- 在手動調優比較困難的場合,可以直接使用這種自適應的方式,僅指定虛擬機的最大堆、目的的吞吐量(GCTimeRatio)和停頓時間(MaxGCPauseMills),讓虛擬機自己完成調優工作
CMS回收器-低延遲
- 在JDK1.5時期,Hotpot推出了一款在強交互應用中幾乎可認為有劃時代意義的垃圾收集器,CMS(Concurrent-Mark-Sweep)收集器,它第一次實現了讓垃圾收集線程與用戶線程同時工作
- CMS收集器的關注點是盡可能縮短垃圾收集時用戶線程的停頓時間,停頓時間越短就越適合與用戶交互的程序,良好的響應速度對能提升用戶體驗
- 目前很大一部分的Java應用集中在互聯網站或BS系統的服務器上,這類應用尤其重視服務的響應速度,希望系統停頓時間最短,以給用戶帶來較好體驗,CMS符合這類應用
- CMS采用標記-清除算法,并且也會Stop-The-World
- JDK14已經刪除
CMS工作原理
- 初始標記(Initial-Mark)階段:這個階段中,程序中所有的工作線程都會因為Stop-the-World機制而出現短暫的暫停,這個階段的主要任務僅僅標記出GCRoots能直接關聯的對象,一旦標記完成后就會恢復之前被暫停的所有應用線程,由于直接關聯的對象比較小,所以速度很快
- 并發標記(Concurrent-Mark)階段:從GC Roots的直接關聯對象開始遍歷整個對象圖的過程,這個過程耗時較長但是不需要停頓用戶線程,可以與垃圾收集線程一起并發運行
- 重新標記(Remark)階段:由于在并發標記階段中,程序的工作線程會和垃圾收集線程同時運行或交叉運行,因此為了修正并發標記期間,因用戶程序繼續動作而導致產生變動的那一部分對象的標記記錄,這個階段的停頓時間會比初始標記階段稍長一些,但也遠比并發標記階段的時間短
- 并發清除(Concurrent-Sweep)階段:此階段清理掉標記階段判斷的已經死亡的對象,釋放內存空間,由于不需要移動存活對象,所以這個階段也是可以與用戶線程同時并發的
待續… …



















