提問:作為DBA運維的你,是否有過這些煩惱
1、業務系統進行替換投產時,發現數據庫回放并行度低
2、雖然2個數據庫集群使用同一份數據,卻在關閉雙一后,二級從庫的回放效率依舊緩慢,不知是什么原因?
心中有章,遇事不慌
作為DBA的你,遇到問題無從下手,除了在問題面前徘徊,還能如何選擇?如果你一次或多次遇到該問題還是無法解決,又很懊惱,該如何排憂呢?關注公眾號,關注《包拯斷案》專欄,讓小編為你排憂解難~

#包拯秘籍#
一整套故障排錯及應對策略送給你,讓你像包拯一樣斷案如神:
?#首先
遇到此類問題后,我們要做到心中有章(章程),遇事不慌。一定要冷靜,仔細了解故障現象(與研發/用戶仔細溝通其反饋的問題,了解故障現象、操作流程、數據庫架構等信息)
#其次
我們要根據故障現象進行初步分析。心中要想:是什么原因導致回放數據慢?例如:是二級從庫出了問題,還是資源遇到瓶頸?
#然后
針對上述思考,我們需要逐步驗證并排除,確定問題排查方向。
#接著
確定了問題方向,進行具體分析。通過現象得出部分結論,通過部分結論繼續排查并論證。
#最后
針對問題有了具體分析后,再進行線下復現,最終梳理故障報告。
真刀實戰,我們能贏
說了這么多理論,想必實戰更讓你心動。那我們就拿一個真實案例進行分析---某國有大型商業銀行子業務系統要進行替換投產,在替換過程中遇到回放數據慢的問題,該如何快速分析處理:
1.故障發生場景
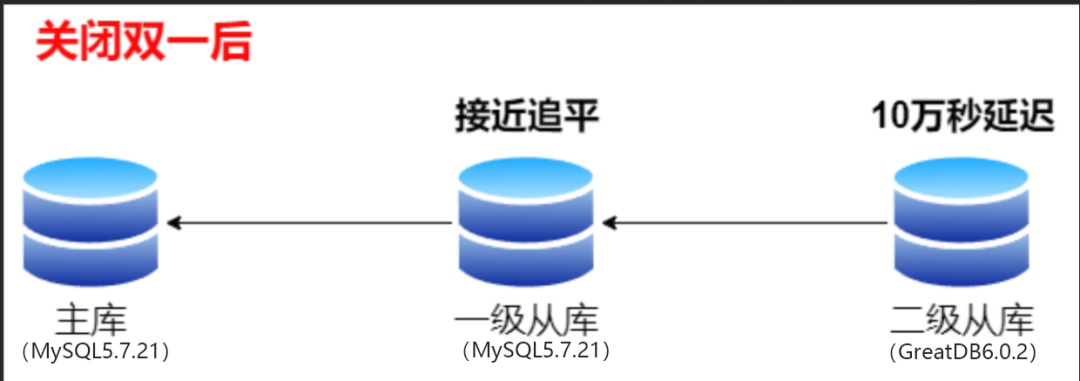
在項目現場兢兢業業準備數據庫替換上線的你,正計劃把客戶子業務系統中的數據庫從MySQL 5.7.21 替換到GreatDB最新版本,該業務系統采用主從級聯復制,原計劃流程如下:
1.?停止舊環境的一臺從庫(以下稱“一級從庫”),使用冷備方式拷貝一份數據文件副本到新環境。在新環境上使用原地替換的方式,將數據文件替換為GreatDB最新版本(以下稱“二級從庫”);
2.??第二天晚上,啟動之前停止的一級從庫,將二級從庫主從連接到一級從庫上,兩庫開始追趕近3天的增量數據;
3.?第三天凌晨,發現兩臺從庫應用增量數據緩慢,磁盤iops高。為加快追趕增量數據速度,關閉兩臺庫的雙一參數,iops顯著下降。一段時間后,一級從庫接近追平數據,而二級從庫則回放緩慢。發現二級從庫資源使用率較低,沒有瓶頸,因此利用show processlist 查看worker進程,發現回放并行度低,只能中止替換投產工作。

(示意圖)
(何為“雙一”:即系統變量 sync_binlog = 1 和 innodb_flush_log_at_trx_commit = 1,以便從庫的二進制日志和redo log 能即時同步到磁盤,否則已提交的二進制日志可能因意外宕機而丟失。)
2.故障分析
一級從庫和二級從庫使用同一份數據,在關閉雙一之前未看到明顯的延遲差異。關閉雙一后,一級從庫回放速度大幅提升,二級從庫回放效率依舊緩慢。正常情況下,如果資源沒有瓶頸,二級從庫應該會出現回放并行度下降的問題。
3.原理分析:結合并行復制原理進行分析
1)基本原理
通過事務分組,優化減少了生成二進制日志所需的操作數。當事務同時提交時,它們將在單個操作中寫入二進制日志。若事務能同時提交成功,則它們不會共享任何鎖,這就意味著它們沒有沖突,可以在Slave上并行執行。
2)事務合并機制
binlog中的事務記錄了兩個值:
-
last_commit:上個事務的提交順序號
-
sequence_number:本次事務的提交順序號
根據組提交和兩階段提交機制,last_commit值可以合并,即相近事務可以具有相同的last_commit值。事務分發時,last_commit work線程會檢查事務的last_commit, last_commit對應的上一事務完成提交后,本事務才能進行回放。last_commit相同的事務,可同時通過分發階段,即可以并行執行。
3)last_commit值的產生方式
事務提交時,可分成以下三個階段:
-
Stage 1:prepare
?獲取全局的提交號,固定為事務的last_commit值,進行innodb redo prepare。
-
Stage 2:binlog flush
進行redo刷盤,獲得innodb_flush_log_at_trx_commit 的生效點。將事務信息寫入binlog并進行刷盤,則獲得了sync_binlog 的生效點。
-
Stage 3:commit
進行innodb commit,更新全局提交號。
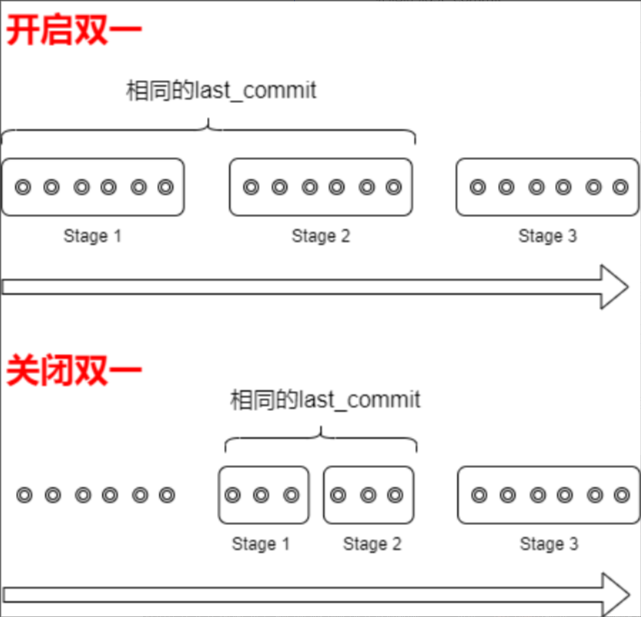
由于redo和binlog全局只有一份,因此此處只能串行執行。每個Stage同一時間只允許一個線程操作,其它線程的事務將進入每個stage設置的等待隊列。為提高效率,此時需引入組提交機制。當一個線程獲得執行stage的執行權限時,會將【等待隊列】中的事務合并執行提交任務。因此,各階段可以同時存在多個事務。在一定時間內,通過stage 1提交的事務,則具有了相同的last_commit值。
4)關閉雙一下的last_commit
當雙一關閉,執行stage 1和stage 2的時間就會大幅壓縮,等待隊列積累的事務長度會減少,提交就會很快進入Stage 3階段,全局提交號遞增頻率增加。binlog中事務記錄的last_commit值就會快速遞增。從庫使用讀取這份binlog進行回放,并行度就下降了。
???
如下圖所示,關閉雙一后,stage 1和stage 2的執行時間大幅壓縮:
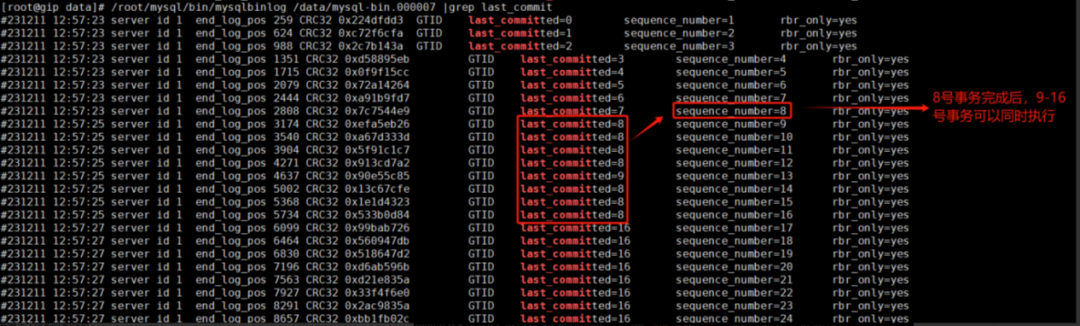
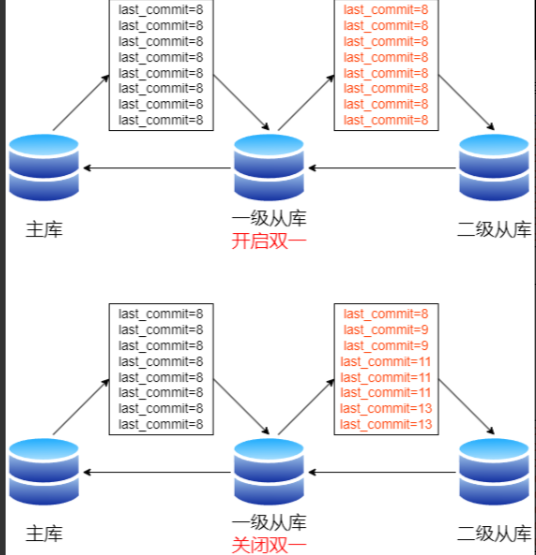
如下圖所示,開啟雙一情況下,一級從庫binlog的last_commit。二級從庫回放時,8號事務完成后,9-16號事務可以并行回放。
???
如下圖所示,關閉雙一情況下,一級從庫binlog的last_commit。二級從庫回放時,8號事務完成后,只有9號事務的last_commit為8,退化為串行回放。
??
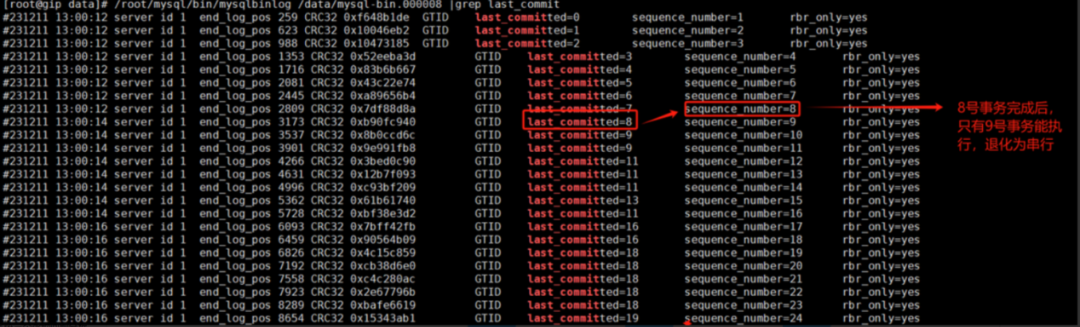
? ??
下圖為復制鏈路示意圖:關閉雙一前,一級/二級從庫能高并發回放。關閉雙一后,二級從庫并發降級。
4.故障優化方案
由于級聯復制追趕增量數據時,既要考慮釋放IO能力,也要兼顧降低last_commit的遞增數。
因此,可以參考以下方法:
1)設置innodb_flush_log_at_trx_commit=0,sync_binlog=1
sync_binlog保持為1,減緩事務進入Stage 3,降低【全局提交號】的遞增速度,保護并行度。
設置innodb_flush_log_at_trx_commit=0,降低IO消耗。同時,事務進入stage 1的效率提升,獲取相同last_commit的概率增大。
2)?設置slave_preserve_commit_order=0
若事務是回放線程發起的,在開啟slave_preserve_commit_order情況下,事務進入Stage 1等待隊列前,會先進入排隊狀態,以保證從庫事務提交順序和主庫保持一致,保護事務提交時間的線性增加。與此同時,會延緩事務進入stage 1隊列,降低提交效率和并行度。從庫延遲大時,可以考慮關閉。這個操作在高并發場景時效果尤其明顯。
3)優化刷臟,釋放iops能力
關閉double write,增大redo,增大buffer_pool,提高臟頁低水位線,調整innodb_io_capacity等。通過調整刷臟相關參數,減少刷臟消耗的磁盤IO。
4)不建議從庫調整組提交等待參數
binlog_group_commit_sync_no_delay_count,這一參數受限于從庫并發量,很難穩定觸發。
binlog_group_commit_sync_delay ,這一參數受限于從庫并行執行,無法通過此參數合并大量事務提交,容易進入無意義的空等,反而減慢事務回放。
5)改變last_commit算法(針對MySQL5.7.22以上版本,GreatDB全系版本支持)?
MySQL5.7.22引入了新的last_commit計算方法,提高并行度。
設置參數如下:
-?? transaction_write_set_extraction=XXHASH64
-?? binlog_transaction_dependency_tracking=WRITESET/WRITESET_SESSION
??
開啟后,事務提交會將改變的行保存在內存寫集合中。新事務提交會比對寫集合,沒有沖突則不遞增last_commit。沖突則清空寫集合,并改變last_commit,此舉可大幅提高并行度。
復盤總結
01
投產暫停原因:
本次替換投產工作暫停,是級聯復制二級從庫回放并行度低引起的,造成二級從庫大幅度延遲。主要是MySQL的級聯復制機制引起的,而非GreatDB問題。
02
維護措施:
替換過程中,一定要做好監控及定期巡檢,確保數據庫處于穩定運行狀態;
03
替換優化方案:
1)替換方案:
針對冷備數據目錄目前間隔兩天才啟動二級從庫追平數據的方案,可以優化替換策略:縮短二級從庫冷備目錄到開始追平數據之間的時間差(1天內),保證二級從庫實際可用的回放時間;
2)后期優化方案:
a.優化slave_preserve_commit_order、innodb_flush_log_at_trx_commit、sync_binlog等數據庫參數,以提升磁盤能力;
b.修改并行復制算法”WRITESET“,大幅提升并行度能力。













|PWM輸出)

 when compile netcdf-fortran)



