下面表中:主鍵id是聚簇索引,name是輔助索引。
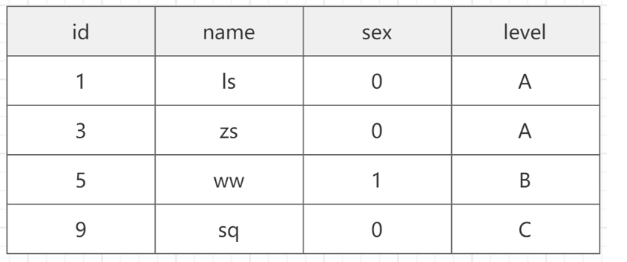
執行這樣一條SQL: select name from A where name="s;name字段是有索引,所以MYSQL在通過name進行査詢的時候,是需要掃描兩顆B+tree樹的。
- 第一遍:先通過二級索引定位主鍵值1。
- 第二遍:根據主鍵值在聚簇索引中定位具體的行記錄。回表指的就是:現根據輔助索引查詢到主鍵值,再根據主鍵值在聚簇索引中獲取行記錄,這就是回表。
使用覆蓋索引,來避免回表的問題:
- 覆蓋索引:如果一個索引包含了所有需要查詢的字段的值(不需要回表),這個索引就是覆蓋索引
- 覆蓋索引優化的思路:只需要在一顆索引樹上就能獲取SQL所需的列數據,無需回表,速度更快。
具體的實現方式:
- 將被查詢的字段建立聯合索引,這樣就可以避免回表,可以直接返回索引中的數據。
比如有這樣一條SQL:

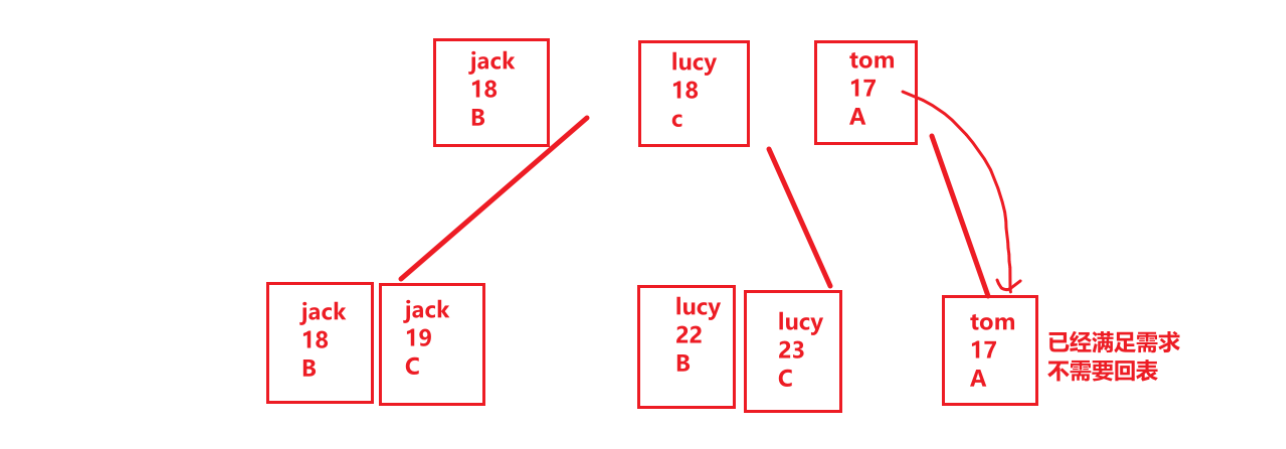
)

)









)
![Linux基礎命令[27]-gpasswd](http://pic.xiahunao.cn/Linux基礎命令[27]-gpasswd)


)


