第十一章 文件及IO操作
文件的概述及基本操作步驟
文件:
- 存儲在計算機的存儲設備中的一組數據序列就是文件
- 不同類型的文件通過后綴名進行區分
文本文件:由于編碼格式的不同,所占磁盤空間的字節數不同(例如GBK編碼格式中一個中文字符占2字節,UTF-8編碼格式中一個中文字符占3字節)。
二進制文件:沒有統一的編碼,文件直接由0或1組成,需要使用指定的軟件才能打開。
?
Python操作文件的步驟:
1、打開文件
變量名 = open(filename,mode,encoding)
filename:要打開的文件路徑,若文件不存在則會創建文件,并不會報錯。
mode:打開文件的模式。只讀?,只寫(w),讀寫(r+)
encoding:編碼格式。
2、操作文件
變量名.read()
變量名.write(s) # s 表示字符串格式,其他格式不行
3、關閉文件
變量名.close()
# 學習過函數后,要習慣用函數編程
# 寫文件
def my_write():# (1)(創建)打開文件file = open('a.txt', 'w', encoding='utf-8')# (2)操作文件file.write('偉大的中國夢')# (3)關閉file.close()# 讀取文件
def my_read():# (1)(創建)打開文件file = open('a.txt', 'r', encoding='utf-8')# (2)操作文件s = file.read()print(type(s), s)# (3)關閉file.close()# 主程序運行
if __name__ == '__main__':my_write() # 調用函數my_read()
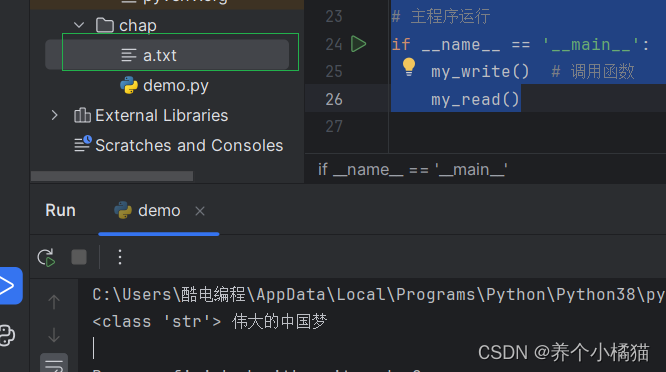
文件的寫入操作
文件的狀態和操作過程:

文件的打開模式:
| 文件的打開模式 | 模式說明 |
|---|---|
| r | 以只讀模式打開,文件指針在文件的開頭,如果文件不存在,程序拋異常 |
| rb | 以只讀模式打開二進制文件,如圖片文件 |
| w | 覆蓋寫模式,文件不存在創建,文件存在則內容覆蓋 |
| wb | 覆蓋寫模式寫入二進制數據,文件不存在則創建,文件存在則覆蓋 |
| a | 追加寫模式,文件不存在創建,文件存在,則在文件最后追加內容 |
| + | 與 w / r / a 等一同使用,在原功能的基礎上增加同時讀寫功能 |
文件的讀寫方法:
| 讀寫方法 | 描述說明 |
|---|---|
| file.read(size) | 從文件中讀取size個字符或字節,如果沒有給定參數,則讀取文件中的全部內容 |
| file.readline(size) | 讀取文件中的一行數據,如果給定參數,則為讀取這一行中的size個字符或字節 |
| file.readlines() | 從文件中讀取所有內容,結果為列表類型 |
| file.write(s) | 將字符串s寫入文件 |
| file.writelines(lst) | 將內容全部為字符串的列表lst寫入文件 |
| file.seek(offset) | 改變當前文件操作指針的位置,英文占一個字節,中文GBK編碼占兩個字節,UTF-8編碼占三個字節 |
def my_write(s):# (1)打開(創建)文件file = open('b.txt', 'a', encoding='utf-8')# (2)寫入內容file.write(s)file.write('\n') # 換行# (3)關閉file.close()# file.writelines(lst) 將內容全部為字符串的列表lst寫入文件 |
def my_write_lst(file, lst):# (1)打開文件f = open(file, 'a', encoding='utf-8')# (2)操作文件f.writelines(lst)# (3)關閉f.close()if __name__ == '__main__':my_write('偉大的中國夢')my_write('北京歡迎你')# 準備數據lst = ['姓名\t', '年齡\t', '成績\n', '張三\t', '30\t', '98'] # 要寫入的列表里面的內容必須全部是字符串my_write_lst('c.txt', lst)

文件的讀取操作
def my_read(filename):# (1)打開文件file = open(filename, 'w+', encoding='utf-8')# (2)操作file.write('你好啊') # 寫入完成后文件的指針在最后# file.seek(offset) 修改文件指針的位置file.seek(0)# 讀取# s = file.read() # 讀取全部內容# s = file.read(2) # 2指 2個字符# s = file.readline() # 讀取一行數據# s = file.readline(2) # 讀取一行中的2個字符# s = file.readlines() # 逐行讀取全部,一行為列表中的一個元素,s是列表類型# 讀取 “好啊”file.seek(3) # 3個字節,一個中文占三個字節,utf-8s = file.read() # 讀取全部(從指針處開始,讀取指針后面的全部內容)print(type(s), s)# (3)關閉file.close()if __name__ == '__main__':my_read('d.txt')

文件復制
學習了文件的寫入和讀取操作后便可以實現文件復制。文件復制實際上就是讀和寫操作,而且是邊讀邊寫。
def copy(src, new_path):# 文件的復制就是邊讀邊寫操作# (1)打開源文件file1 = open(src, 'rb')# (2)打開目標文件file2 = open(new_path, 'wb')# (3)開始復制,邊讀邊寫s = file1.read() # 源文件讀取所有file2.write(s) # 向目標文件寫入所有# (4)關閉-->先打開的后關,后打開的先關。file2.close()file1.close()if __name__ == '__main__':src = './google.jpg' # . 代表的是當前目錄new_path = '../chap1/copy_google.jpg' # .. 表示的是上級目錄,相當于windows后退copy(src, new_path)print('文件復制完畢')

這里需要注意的問題:
- 在關閉多個文件時,先打開的后關,后打開的先關。
- 寫文件路徑時 . 與 .. 的使用
with語句的使用
with語句:
又稱上下文管理器,在處理文件時,無論是否產生異常,都能保證with語句執行完畢后關閉已經打開的文件,這個過程是自動的,無需手動操作。
語法結構:
with open(…) as file:
??pass
注意:
with語句是可以嵌套的。例子見下方代碼中的文件復制 copy() 。
def write_fun():with open('aa.txt', 'w', encoding='utf-8') as file:file.write('2022北京冬奧會歡迎你')def read_fun():with open('aa.txt', 'r', encoding='utf-8') as file:print(file.read())def copy(src_file, target_file):# 復制--->先讀后寫with open(src_file, 'r', encoding='utf-8') as file:with open(target_file, 'w', encoding='utf-8') as file2:file2.write(file.read()) # 將讀取的內容直接寫進文件if __name__ == '__main__':write_fun()read_fun()# 文件復制copy('./aa.txt', './dd.txt')

一維數據和二維數據的存儲與讀取
數據的組織維度:
也稱為數據的組織方式或存儲方式,在Python中常用的數據組織方式可分為一維數據、二維數據和高維數據。
- 一維數據:通常采用線性方式組織數據,一般使用Python中的列表、元組或者集合進行存儲數據。
- 二維數據:二維數據也稱表格數據,由行和列組成,類似于Excel表格,在Python中使用二維列表進行存儲。
- 高維數據:高維數據則是使用Key-Value方式進行組織數據,在Python中使用字典進行存儲數據。在Python中內置的 json 模塊專門用于處理JSON(JavaScript Object Notation)格式的數據。
# 存儲和讀取一維數據
def my_write():# 一維數據,可以使用列表,元組或集合lst = ['張三', '李四', '王五', '陳六', '麻七']# csv:逗號分隔值,數據之間使用英文的逗號進行分隔。with open('student.csv', 'w', encoding='utf-8') as file:file.write(','.join(lst)) # 將列表轉成字符串def my_read():with open('student.csv', 'r', encoding='utf-8') as file:s = file.read()lst = s.split(',') # 字符串分割print(lst)# 存儲和讀取二維數據(表格數據)--->使用二維列表進行存儲
def my_write_table():lst = [['商品名稱', '單價', '采購數據'],['水杯', '98.5', '20'],['鼠標', '89', '100']]with open('table.csv', 'w', encoding='utf-8') as file:for item in lst: # item的數據類型是列表line = ','.join(item)file.write(line)file.write('\n') # 換行def my_read_table():data = [] # 存儲讀取的數據with open('table.csv', 'r', encoding='utf-8') as file:lst = file.readlines() # 逐行讀取全部內容,每一行是列表中的一個元素# print(type(lst), lst) #<class 'list'> ['商品名稱,單價,采購數據\n', '水杯,98.5,20\n', '鼠標,89,100\n']for item in lst: # item是字符串類型# 字符串切片--->將末尾的 \n 切掉new_lst = item[:len(item) - 1].split(',') # 結果是列表data.append(new_lst)print(data)if __name__ == '__main__':my_write()my_read()my_write_table()my_read_table()
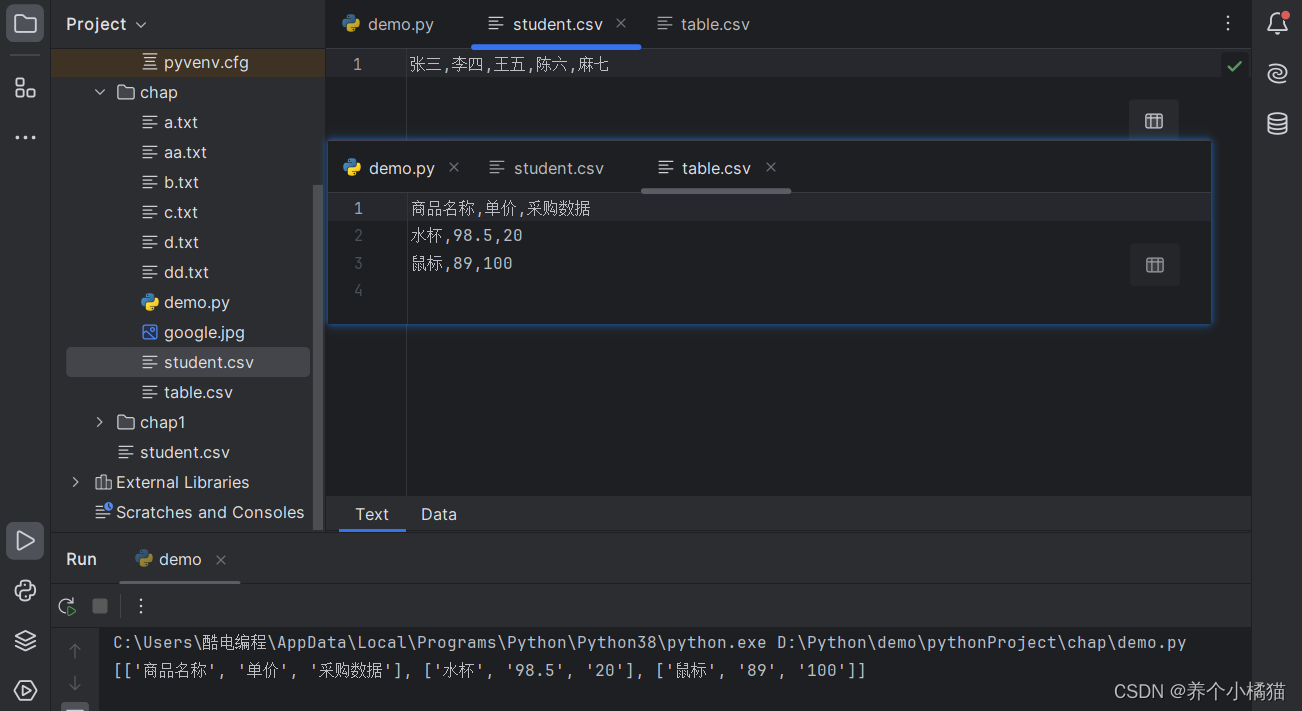
注意上述代碼中提到的 .csv 格式的文件:
逗號分隔值(Comma-Separated Values,CSV,有時也稱為字符分隔值,因為分隔字符也可以不是逗號),其文件以純文本形式存儲表格數據(數字和文本)。【csv:逗號分隔值,數據之間使用英文的逗號進行分隔。】
高維數據的存儲和讀取
- 高維數據:高維數據則是使用Key-Value方式進行組織數據,在Python中使用字典進行存儲數據。在Python中內置的 json 模塊專門用于處理JSON(JavaScript Object Notation)格式的數據。
json模塊的常用函數:
| 函數名稱 | 描述說明 |
|---|---|
| json.dumps(obj) | 將Python數據類型轉成JSON格式過程,編碼過程 |
| json.loads(s) | 將JSON格式字符串轉成Python數據類型,解碼過程 |
| json.dump(obj,file) | 與dumps()功能相同,將轉換結果存儲到文件file中 |
| json.load(file) | 與loads()功能相同,從文件file中讀入數據 |
import json# 準備高維數據
lst = [{'name': '張三', 'age': 18, 'score': 90},{'name': '李四', 'age': 20, 'score': 99},{'name': '王五', 'age': 23, 'score': 89}
]# 編碼
# ensure_ascii-->正常顯示中文。indent-->增加數據的縮進,為了美觀,使得JSON格式的字符串更具有可讀性
s = json.dumps(lst, ensure_ascii=False, indent=4)
print(type(s)) # 編碼 list-->str,列表中是字典
print(s)# 解碼
lst2 = json.loads(s)
print(type(lst2))
print(lst2)# 編碼到文件中
with open('student.txt', 'w', encoding='utf-8') as file:json.dump(lst, file, ensure_ascii=False, indent=4)# 解碼到程序中
with open('student.txt', 'r', encoding='utf-8') as file:lst3 = json.load(file) # 直接是列表類型print(type(lst3))print(lst3)
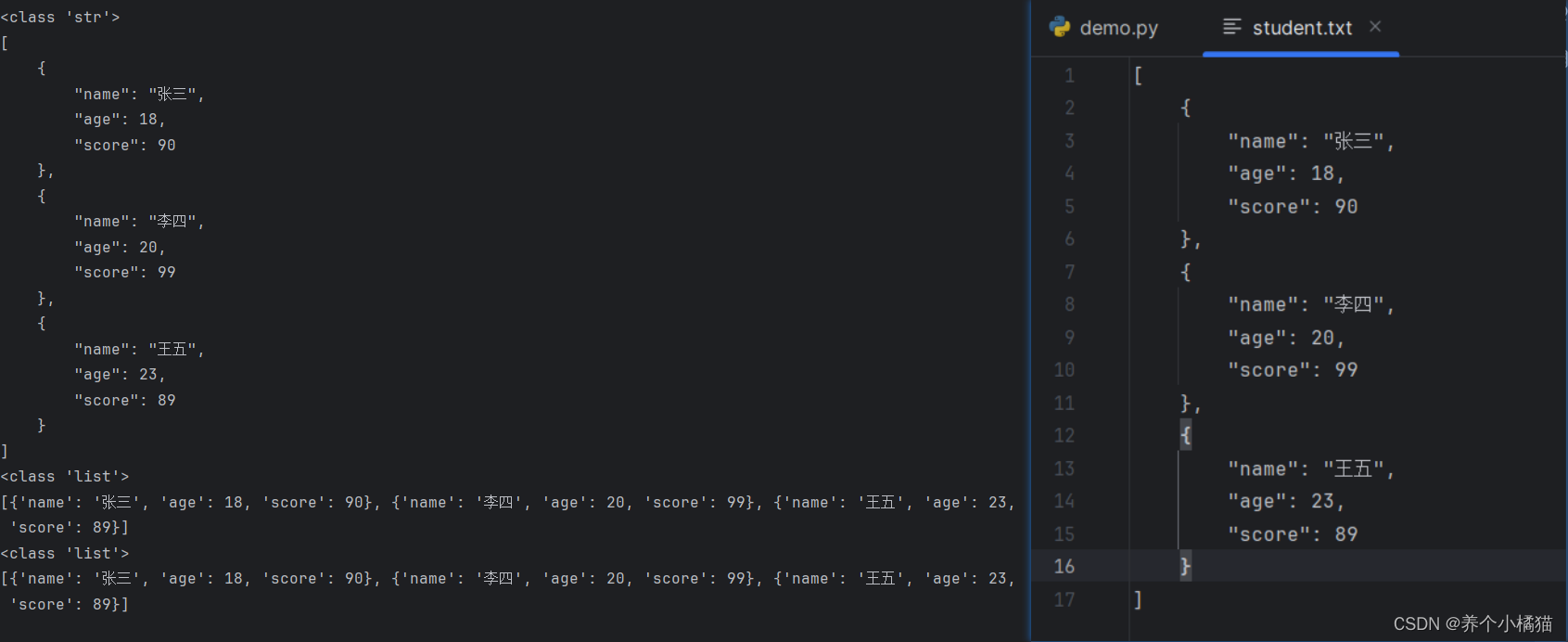
os模塊中常用的函數
os模塊:
Python內置的與操作系統文件相關的模塊,該模塊中語句的執行結果通常與操作系統有關,即有些函數的運行效果在Windows操作系統和MacOS系統中不一樣。
目錄與文件的相關操作:
| 函數名稱 | 描述說明 |
|---|---|
| getcwd() | 獲取當前的工作路徑 |
| listdir(path) | 獲取path路徑下的文件和目錄信息,如果沒有指定path,則獲取當前路徑下的文件和目錄信息 |
| mkdir(path) | 在指定路徑下創建目錄(文件夾) |
| makedirs(path) | 創建多級目錄 |
| rmdir(path) | 刪除path下的空目錄(只能刪除空目錄,若目錄下有內容則不能刪除) |
| removedirs(path) | 刪除多級目錄 |
| chdir(path) | 把path設置為當前工作路徑(rh指的是change) |
| walk(path) | 遍歷目錄樹,結果為元組,包含所有路徑名、所有目錄列表和文件列表 |
| remove(path) | 刪除path指定的文件 |
| rename(old,new) | 將old重命名為new |
| stat(path) | 獲取path指定的文件信息 |
| startfile(path) | 啟動path指定的文件 |
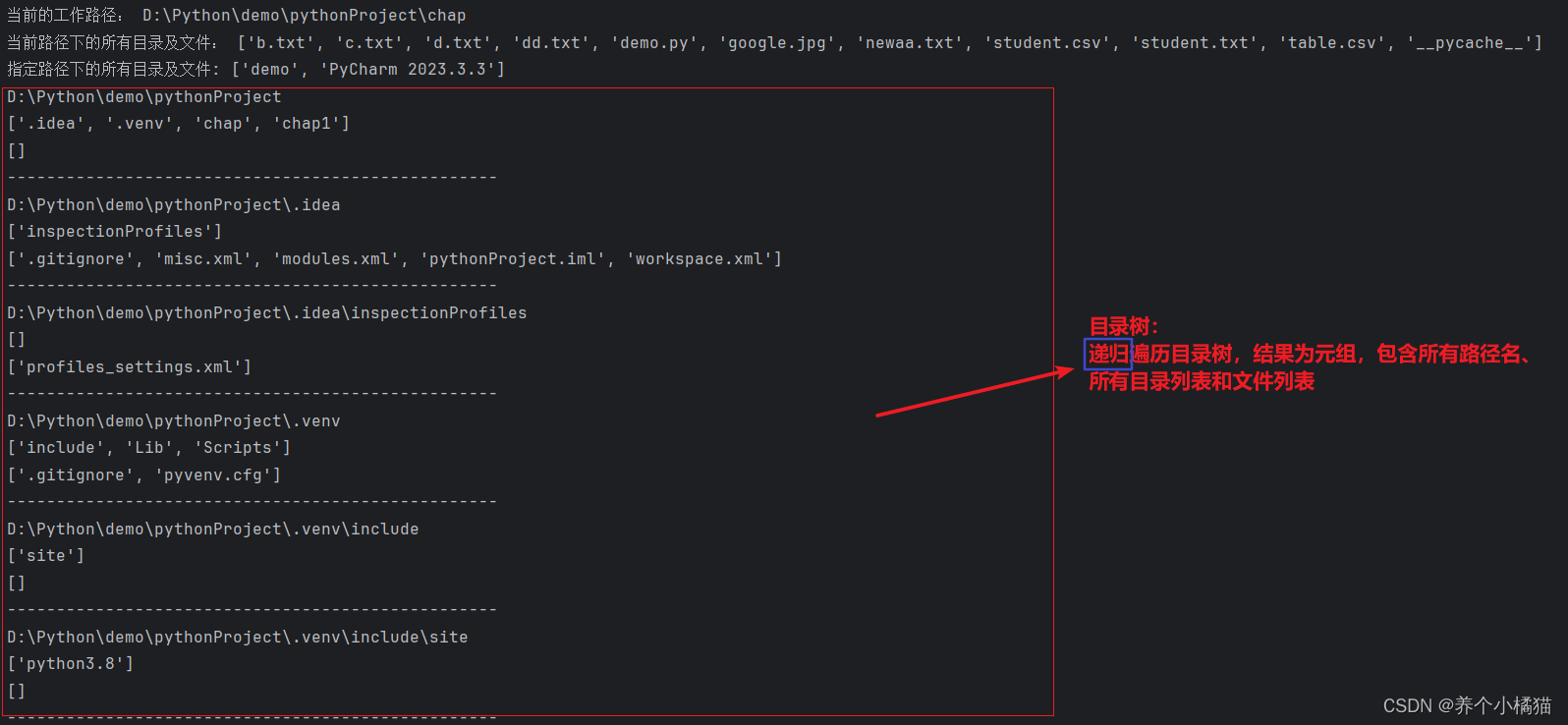
import osprint('當前的工作路徑:', os.getcwd())
lst = os.listdir()
print('當前路徑下的所有目錄及文件:', lst)
print('指定路徑下的所有目錄及文件:', os.listdir('D:/Python'))# 創建目錄
os.mkdir('study') # 如果要創建的文件夾存在,則程序報錯FileExistsError
os.makedirs('./aa/bb/cc') # 創建多級目錄# 刪除目錄
os.rmdir('./study') # 如果要刪除的目錄不存在,則程序報錯FileNotFoundError
os.removedirs('./aa/bb/cc') # 刪除多級目錄# 改變當前的工作路徑
# os.chdir('D:/Python')
# print('當前的工作路徑:', os.getcwd()) # 再寫代碼,工作路徑就是D:/Python# 遍歷目錄樹--->遞歸操作
for dirs, dirlst, filelst in os.walk('D:\Python\demo\pythonProject'):print(dirs)print(dirlst)print(filelst)print('-' * 50)# 刪除文件
os.remove('./a.txt') # 如果要刪除的文件不存在,程序報錯FileNotFoundError
# 重命名
os.rename('./aa.txt', './newaa.txt')# 轉換時間格式
import time
def date_format(longtime):s = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(longtime))return s# 獲取文件信息
info = os.stat('./newaa.txt')
print(type(info))
print(info)print('最近一次訪問時間:', date_format(info.st_atime))
print('在Windows操作系統中顯示的文件的創建時間:', date_format(info.st_ctime))
print('最后一次修改時間:', date_format(info.st_mtime))
print('文件的大小(單位是字節):', info.st_size)# 啟動路徑下的文件
os.startfile('calc.exe') # 打開計算器
os.startfile(r'C:\Users\酷電編程\AppData\Local\Programs\Python\Python38\python.exe')

?
關于Python中文件路徑問題的說明:
import osos.startfile(r'C:\Users\酷電編程\AppData\Local\Programs\Python\Python38\python.exe') # 字符串前加r
os.startfile('C:/Users/酷電編程/AppData/Local/Programs/Python/Python38/python.exe') # 使用 /
os.startfile('C:\\Users\\酷電編程\\AppData\\Local\\Programs\\Python\\Python38\\python.exe') # 使用雙反斜杠 \\
'''
說明(有關文件路徑的問題):
在Windows操作系統下,在Python中有時表示文件路徑時用 \ 沒有問題,
但有時則會出錯,因為在Python中 \ 是轉義字符,因此當出錯時可以用雙反斜杠\\進行再轉義。
另外也可以在字符串前面加 r ,r的作用是去除轉義字符,即忽略該字符串中的所有轉義字符,視為正常字符。
同時,以 r 開頭的字符串常用于正則表達式,對應者re模塊。最好的方式是使用 / ,這種不會出錯。
'''
os.path子模塊中常用的函數
os.path模塊:
是os模塊的子模塊,也提供了一些目錄或文件的操作函數。
| 函數名稱 | 描述說明 |
|---|---|
| abspath(path) | 獲取目錄或文件的絕對路徑(abs:絕對值) |
| exists(path) | 判斷目錄或文件在磁盤上是否存在,結果為bool類型,如果目錄或文件在磁盤上存在,結果為True,否則為False |
| join(path,name) | 將目錄與目錄名或文件名進行拼接,相當于字符串的“+”操作 |
| splitext() | 分別獲取文件名和后綴名 |
| basename(path) | 從path中提取文件名 |
| dirname(path) | 從path中提取路徑(不包含文件名) |
| isdir(path) | 判斷path是否是有效路徑(路徑不包含文件名) |
| isfile(path) | 判斷file是否是有效文件 |
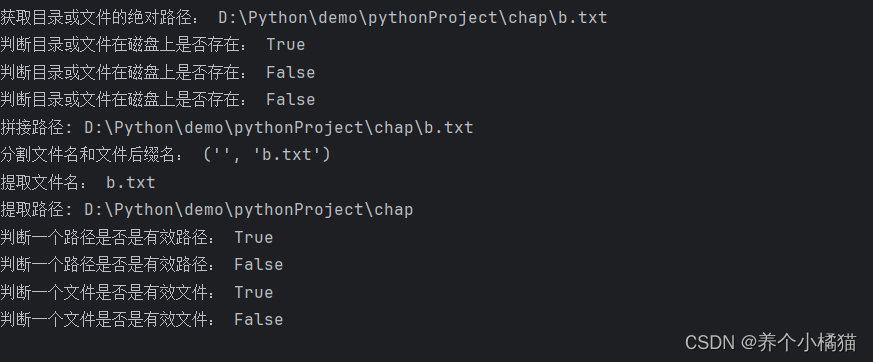
import os.pathprint('獲取目錄或文件的絕對路徑:', os.path.abspath('./b.txt'))
print('判斷目錄或文件在磁盤上是否存在:', os.path.exists('b.txt')) # 相對路徑 True
print('判斷目錄或文件在磁盤上是否存在:', os.path.exists('newb.txt')) # False
print('判斷目錄或文件在磁盤上是否存在:', os.path.exists('./好好學習')) # False
print('拼接路徑:', os.path.join(r'D:\Python\demo\pythonProject\chap', 'b.txt'))
print('分割文件名和文件后綴名:', os.path.split('b.txt')) # 元組類型# 提取路徑與提取文件名經常一起使用
print('提取文件名:', os.path.basename(r'D:\Python\demo\pythonProject\chap\b.txt')) # b.txt
print('提取路徑:', os.path.dirname(r'D:\Python\demo\pythonProject\chap\b.txt')) # D:\Python\demo\pythonProject\chap# 注意:路徑不包括文件名
print('判斷一個路徑是否是有效路徑:', os.path.isdir(r'D:\Python\demo\pythonProject\chap')) # True
print('判斷一個路徑是否是有效路徑:', os.path.isdir(r'D:\Python\demo\pythonProject\chap2')) # Falseprint('判斷一個文件是否是有效文件:', os.path.isfile(r'D:\Python\demo\pythonProject\chap\b.txt')) # True
print('判斷一個文件是否是有效文件:', os.path.isfile(r'D:\Python\demo\pythonProject\chap\bbb.txt')) # False
章節習題

file = open('a.txt', 'w+', encoding='utf-8')
lst = ['北京', '上海', '天津']
file.writelines(lst)
file.seek(0)
for item in file:print(item)
file.close()

?
?

?
?

練習題
練習一
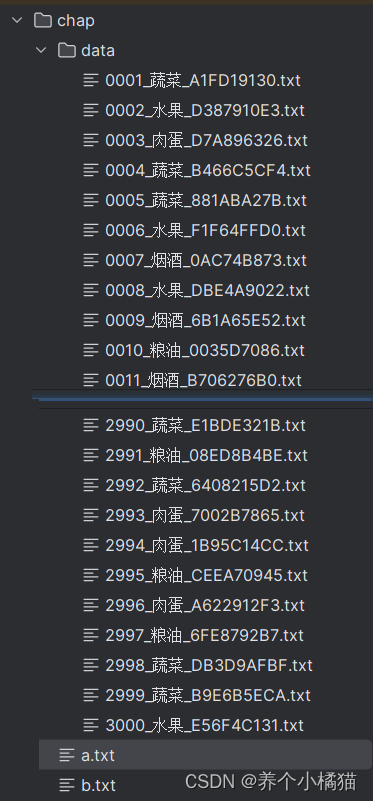
批量創建文件。
需求:
在指定路徑下批量創建3000份文本文件,文件名格式為序號_物資類別_用戶識別碼組成。
1)序號從0001到3000
2)物資類別包括:水果、煙酒、糧油、肉蛋、蔬菜
3)用戶識別碼為9位的隨機十六進制數碼
import random
import os
import os.path# 函數式編程
def create_filename():filename_lst = []lst = ['水果', '煙酒', '糧油', '肉蛋', '蔬菜'] # 物資的類別code = ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9', 'A', 'B', 'C', 'D', 'E', 'F']for i in range(1, 3001):filename = ''# 拼接文件名--->1、序號if i < 10:filename += '000' + str(i)elif i < 100:filename += '00' + str(i)elif i < 1000:filename += '0' + str(i)else:filename += str(i)# 拼接文件名--->2、物資類別filename += '_' + random.choice(lst)# 拼接文件名--->3、識別碼s = ''for i in range(9):s += random.choice(code)filename += '_' + sfilename_lst.append(filename)return filename_lst# 創建文件的函數
def create_file(filename):with open(filename, 'w') as file:passif __name__ == '__main__':# 在指定的路徑下創建文件path = './data'if not os.path.exists(path):os.mkdir(path)# 開始創建文件lst = create_filename() # 調用獲取文件名函數for item in lst:create_file(os.path.join(path, item) + '.txt')# print(create_filename())
練習二
批量創建文件夾。
需求:
在指定路徑newdir下批量創建指定個數的目錄(文件夾),如果newdir目錄不存在,則創建。
import os
import os.pathdef mkdirs(path, num):for item in range(1, num + 1):os.mkdir(path + '/' + str(item))if __name__ == '__main__':path = './newdir'if not os.path.exists(path):os.mkdir(path)num = eval(input('請輸入要創建的目錄個數:'))mkdirs(path, num)'''
# 上面是老師寫的,這里是自己寫的,同樣能實現相同的功能
import os
import os.pathdef create_dir(num):path = './newdir'if not os.path.exists(path):os.mkdir(path)os.chdir(path)for i in range(1, num + 1):os.mkdir(f'{i}')if __name__ == '__main__':num = int(input('請輸入要創建的目錄個數:'))create_dir(num)
'''

練習三
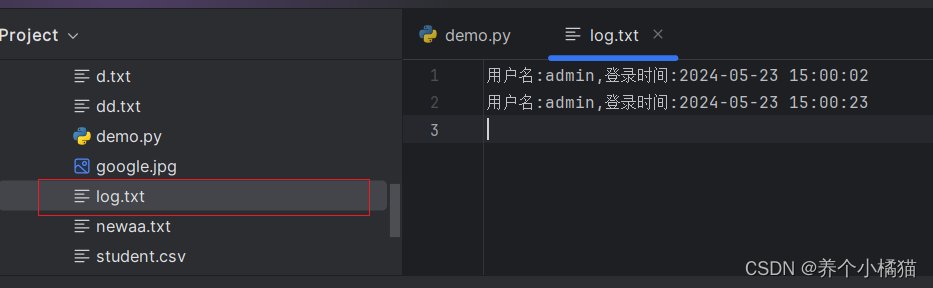
記錄用戶登錄日志并查看。
需求:
創建XX客服管理系統的登錄界面,每次登錄時,將用戶的登錄日志寫入文件中,并且可以在程序中查看用戶的登錄日志。
import timedef show_info():print('請輸入提示數字,執行相應的操作:0.退出 1.查看登錄日志')# 記錄日志
def write_loginfo(username):# 追加寫模式with open('log.txt', 'a', encoding='utf-8') as file:s = f'用戶名:{username},登錄時間:{time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(time.time()))}'file.write(s)file.write('\n')# 讀取日志的操作
def read_loginfo():with open('log.txt', 'r', encoding='utf-8') as file:while True:# readline()只會讀取一行,但是讀取完一行之后讀寫指針會指向下一行,第二次循環時readline()會將第二行讀取出來,...,以此類推...line = file.readline()if line == '':breakelse:print(line, end='')if __name__ == '__main__':username = input('請輸入用戶名:')pwd = input('請輸入密碼:')if username == 'admin' and pwd == 'admin':print('登錄成功')# 將登錄信息寫入日志文件write_loginfo(username)# 提示用戶操作show_info()num = eval(input('請輸入要操作的數字:'))while True:if num == 0:print('退出成功')break # 退出whileelif num == 1:print('查看登錄日志')read_loginfo()show_info() # 再調一次顯示信息else:print('對不起,您輸入的數字有誤')show_info()num = eval(input('請輸入要操作的數字:'))else:print('用戶名或密碼不正確')

練習四
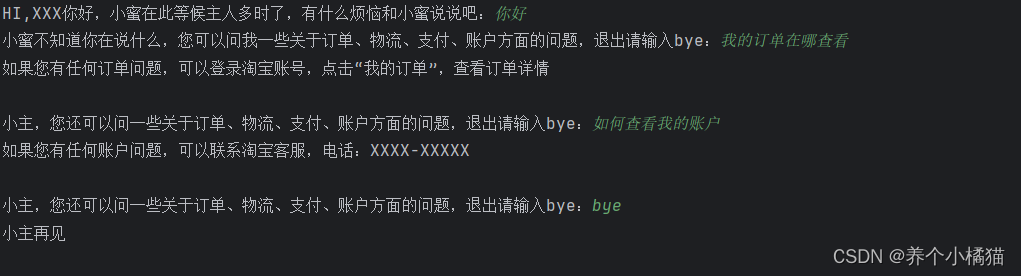
模擬淘寶客服自動回復。
需求:
淘寶客服為了快速回答買家問題,設置了自動回復的功能,當有買家咨詢時,客服自助系統會首先使用提前規劃好的內容進行回復,請用Python程序實現這一功能。
要回復的內容模版在 reply.txt 文件內:

def find_answer(question):with open('reply.txt', 'r', encoding='utf-8') as file:while True:# readline()只會讀取一行,但是讀取完一行之后讀寫指針會指向下一行,第二次循環時readline()會將第二行讀取出來,...,以此類推...line = file.readline() # 第一次 訂單|如果您有任何訂單問題,可以登錄淘寶賬號,點擊“我的訂單”,查看訂單詳情if line == '':break # 退出的是while循環# 字符串的劈分操作keyword = line.split('|')[0]reply = line.split('|')[1]if keyword in question:return replyreturn Falseif __name__ == '__main__':question = input('HI,XXX你好,小蜜在此等候主人多時了,有什么煩惱和小蜜說說吧:')while True:if question == 'bye':break # 退出循環else:# 開始查找要回復的答案reply = find_answer(question)if reply == False: # 函數的返回值如果是Falsequestion = input('小蜜不知道你在說什么,您可以問我一些關于訂單、物流、支付、賬戶方面的問題,退出請輸入bye:')else:print(reply)question = input('小主,您還可以問一些關于訂單、物流、支付、賬戶方面的問題,退出請輸入bye:')print('小主再見')


)

![[4]CUDA中的向量計算與并行通信模式](http://pic.xiahunao.cn/[4]CUDA中的向量計算與并行通信模式)






)







