CUDA中的向量計算與并行通信模式
- 本節開始,我們將利用GPU的并行能力,對其執行向量和數組操作
- 討論每個通信模式,將幫助你識別通信模式相關的應用程序,以及如何編寫代碼
1.兩個向量加法程序
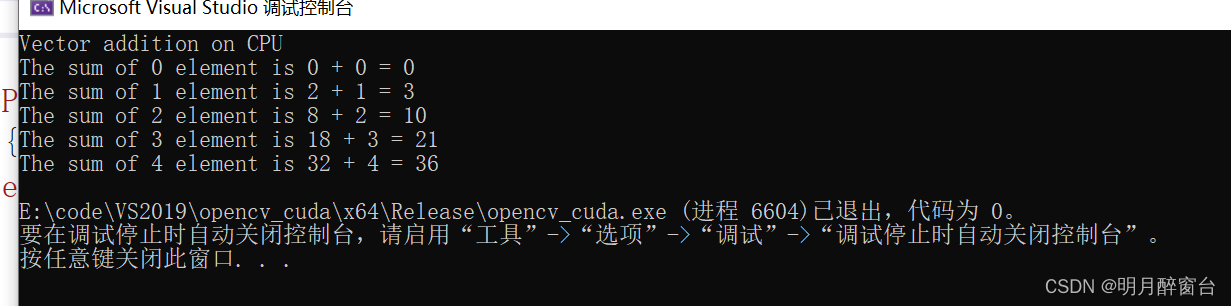
- 先寫一個通過cpu實現向量加法的程序
- 如下所示,向量相加實際上是模仿GPU的寫法,在GPU中,tid 代表特定的某個線程的ID。
- 如果你的cpu是雙核的,可以在每個核心上運行一個線程,分別將tid初始化為0和1,然后每次循環的時候+2,這樣的話可以實現一個核激素那偶數元素的和,一個核計算基數元素的和,通過兩個線程的實現并行計算
#include "stdio.h"
#include<iostream>
//Defining Number of elements in Array
#define N 5
//Defining vector addition function for CPU
void cpuAdd(int *h_a, int *h_b, int *h_c) {int tid = 0; while (tid < N){h_c[tid] = h_a[tid] + h_b[tid];tid += 1;}
}int main(void) {int h_a[N], h_b[N], h_c[N];//Initializing two arrays for additionfor (int i = 0; i < N; i++) {h_a[i] = 2 * i*i;h_b[i] = i;}//Calling CPU function for vector additioncpuAdd (h_a, h_b, h_c);//Printing Answerprintf("Vector addition on CPU\n");for (int i = 0; i < N; i++) {printf("The sum of %d element is %d + %d = %d\n", i, h_a[i], h_b[i], h_c[i]);}return 0;
}
- 而總所周知,NVIDIA GPU包含多個塊,每個塊又包含多個線程,因此可以通過GPU實現更多線程并行計算向量的和,最大程度提高速度
- 可以將代碼修改為核函數如下:
#include "stdio.h"
#include<iostream>
#include <cuda.h>
#include <cuda_runtime.h>//Defining number of elements in Array
#define N 5//Defining Kernel function for vector addition
__global__ void gpuAdd(int* d_a, int* d_b, int* d_c) {//Getting block index of current kernelint tid = blockIdx.x; // handle the data at this indexif (tid < N)d_c[tid] = d_a[tid] + d_b[tid];
}int main(void) {//定義主機數組變量int h_a[N], h_b[N], h_c[N];//定義設備指針變量int* d_a, * d_b, * d_c;//分配顯卡內存cudaMalloc((void**)&d_a, N * sizeof(int));cudaMalloc((void**)&d_b, N * sizeof(int));cudaMalloc((void**)&d_c, N * sizeof(int));//Initializing Arraysfor (int i = 0; i < N; i++) {h_a[i] = 2 * i * i;h_b[i] = i;}// Copy input arrays from host to device memorycudaMemcpy(d_a, h_a, N * sizeof(int), cudaMemcpyHostToDevice);cudaMemcpy(d_b, h_b, N * sizeof(int), cudaMemcpyHostToDevice);//設置內核參數為5個塊,每個塊一個線程 ,并像核函數傳遞參數gpuAdd << <N, 1 >> > (d_a, d_b, d_c);//將計算結果從顯卡拷貝到主機cudaMemcpy(h_c, d_c, N * sizeof(int), cudaMemcpyDeviceToHost);printf("Vector addition on GPU \n");//Printing result on consolefor (int i = 0; i < N; i++) {printf("The sum of %d element is %d + %d = %d\n", i, h_a[i], h_b[i], h_c[i]);}//Free up memorycudaFree(d_a);cudaFree(d_b);cudaFree(d_c);return 0;
}
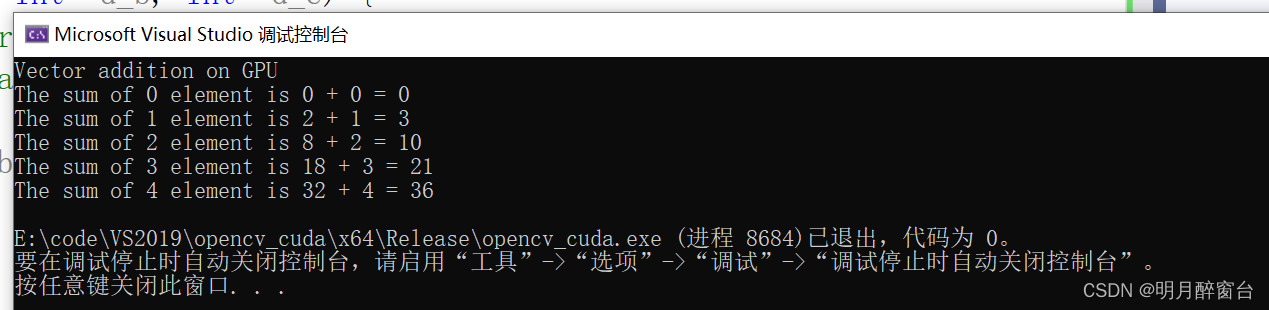
- 以上可以發現,通過GPU并行運算,或者多個線程的并行計算,明顯的減少了數組的處理時間。比起CPU上的串行計算,提高了吞吐率
- 在此說一下吞吐量的含義:只對網絡、設備端口、虛電路或者其他設施,單位時間內成功的傳送數據的數量(以比特、字節、分貝等測量)
2. 對比CPU代碼和GPU代碼的延遲
- CPU的加法程序和GPU的加法程序都是以一個模塊化的方式來編寫的
- N的值較小時,看不出cpu與GPU的差異,但是當N值很大時,會發現兩者計算效率的顯著差異
- 下邊將展示如何為并行計算計時并對兩者時間進行比較
clock_t start_d = clock();printf("Doing GPU Vector add\n");gpuAdd << <N, 1 >> > (d_a, d_b, d_c);cudaThreadSynchronize();clock_t end_d = clock();double time_d = double(end_d - start_d) / CLOCKS_PER_SEC;printf("No of elements in Array: %d \n Device time %f second \n Host time %f second \n ",N, time_d, time_h);
3. 對向量的每個元素進行平方
- 前邊調用內核函數時啟用了N個塊,每個塊一個線程執行計算;另一種也可以只啟動1個塊,塊里邊有N個線程,淡然也可以啟用N個塊,每個塊M個線程
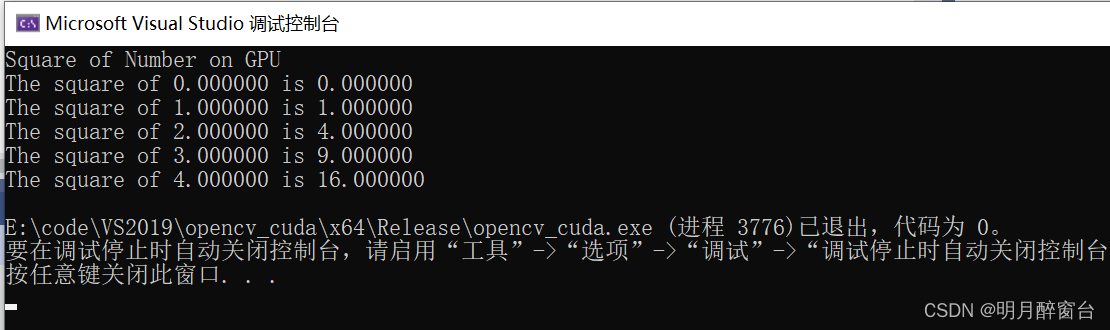
- 下邊通過啟用一個塊中的N個線程來執行向量每個元素的平方運算
#include "stdio.h"
#include<iostream>
#include <cuda.h>
#include <cuda_runtime.h>
//Defining number of elements in Array
#define N 5
//Kernel function for squaring number
__global__ void gpuSquare(float *d_in, float *d_out) {//Getting thread index for current kernelint tid = threadIdx.x; // handle the data at this indexfloat temp = d_in[tid];d_out[tid] = temp*temp;
}int main(void) {//Defining Arrays for hostfloat h_in[N], h_out[N];//Defining Pointers for devicefloat *d_in, *d_out;// allocate the memory on the gpucudaMalloc((void**)&d_in, N * sizeof(float));cudaMalloc((void**)&d_out, N * sizeof(float));//Initializing Arrayfor (int i = 0; i < N; i++) {h_in[i] = i;}//Copy Array from host to devicecudaMemcpy(d_in, h_in, N * sizeof(float), cudaMemcpyHostToDevice);//Calling square kernel with one block and N threads per blockgpuSquare << <1, N >> >(d_in, d_out);//Coping result back to host from device memorycudaMemcpy(h_out, d_out, N * sizeof(float), cudaMemcpyDeviceToHost);//Printing result on consoleprintf("Square of Number on GPU \n");for (int i = 0; i < N; i++) {printf("The square of %f is %f\n", h_in[i], h_out[i]);}//Free up memorycudaFree(d_in);cudaFree(d_out);return 0;
}
-
需注意
- 每當使用這種方式啟動N個線程并行的時候,需要注意每個塊的最大線程不超過 512 或 1024
- 現在所有計算能力/顯卡算力在 3.0 - 7.5 的GPU卡,每個塊最大1024個線程
- 如果N是2000,而你的GPU卡線程的最大數量是512,那么不能寫成
<< <12 000 > >>,而應該使用<< <4,500 > >>,應該理性的選擇合適數量的塊和每個塊具有的線程數量
4. 并行通信模式
- 當多個線程并行執行時,它們遵循一定的通信模式,知道它們在顯存里哪里輸入,哪里輸出
4.1 映射
- 一對一操作,每個線程或任務讀取單一輸入,產生單一輸出,就是Map模式
d_out[i] = d_in[i] * 2
4.2 收集
- 此模式下,每個線程或者任務,具有多個輸入,并產生單個輸出,保存到存儲器的單一位置,即Gather模式:
out[i] = (in[i-1] + in[i] + in[i+1]) / 3
4.3 分散式
- Scatter 模式,線程或者任務讀取單一輸入,單項存儲器產生多個輸出,比如數組排序:
out[i-1] += 2 * in[i] and out[i+1] += 3 * in[i]
4.4 蒙版
- 當線程或者任務要從數組中讀取固定形狀的相鄰元素時,這叫stencil模式,在圖像處理中非常有用。比如想用一個3X3或者5X5的窗口進行滑動濾波
- 代碼類似Gather
4.5 轉置
- 當想要輸入矩陣行主序,輸出矩陣想要列主序,或者有一個結構數組(SoA),想轉換成一個數組結構(AoS),它是特別有用的。Transpose模式如下:
out[i+j*128] = in[j + i*128]






)












