Schema與數據類型優化
BLOB和TEXT類型
BLOB和TEXT都是為存儲很大的數據而設計的字符串數據類型,分別采用二進制和字符方式存儲。
實際上它們分別屬于兩組不同的數據類型家族:字符類型是TINYTEXT,SMALLTEXT,TEXT,MEDIUMTEXT,LONGTEXT;對應的二進制類型是TINYBLOB,SMALLBLOB,BLOB,MEDIUMBLOB,LONGBLOB.BLOB是SMALLBLOB的同義詞,TEXT是SMALLTEXT的同義詞。
與其他類型不同,MySQL把每個BLOB和TEXT值當作一個獨立的對象處理。存儲引擎在存儲時通常會做特殊處理。當BLOB和TEXT值太大時,InnoDB會使用專門的"外部"存儲區域來進行存儲,此時每個值在行內需要1~4個字節存儲一個指針,然后再外部存儲區域存儲實際的值。
BLOB和TEXT家族之間僅有的不同時BLOB類型存儲的是二進制數據,沒有排序規則或字符集,而TEXT類型有字符集和排序規則。
MySQL對BLOB和TEXT列進行排序與其他類型是不同的:它只對每個列的最前max_sort_length字節而不是整個字符串做排序。如果只需要排序前面一小部分字符,則可以減小max_sort_length的配置,或者使用ORDER BY SUBSTRING(column, length).
MySQL不能將BLOB和TEXT列全部長度的字符串進行索引,也不能使用這些索引消除排序
磁盤臨時表和文件排序
因為Memory引擎不支持BLOB和TEXT類型,所以,如果查詢使用了BLOB或TEXT列并且需要使用隱式臨時表,將不得不使用MyISAM磁盤臨時表。即使只有幾行數據也是如此(Percona Server的Memory引擎支持BLOB和TEXT類型,同樣的場景下還是需要使用磁盤臨時表)。這會導致嚴重的性能開銷。即使配置MySQL將臨時表存儲再內存塊設備上(RAM Disk),依然需要許多昂貴的系統調用。最好的解決方案是盡量避免使用BLOB和TEXT類型。如果實在無法避免,有一個技巧是在所有用到BLOB字段的地方都使用SUBSTRING(column, length)將列值轉換為字符串(在ORDER BY 子句中也適用),這樣就可以使用內存臨時表了。但是要確保截取的子字符串足夠短,不會使臨時表的大小超過max_heap_table_size或tmp_table_size,超過以后MySQL會將內存臨時表轉換為MyISAM磁盤臨時表。
最壞情況下的長度分配對于排序的時候也是一樣的,所以這一招對于內存中創建大臨時表和文件排序,以及在磁盤上創建大臨時表和文件排序這兩種情況都很有幫助。
例如,假設有一個1000萬行的表,占用幾個GB的磁盤空間。其中有一個uft8字符集的VARCHAR(1000)的列,每個字符最多使用3個字節,最壞情況下需要3000字節的空間。如果在ORDER BY 中用到這個列,并且查詢掃描整個表,為了排序就需要超過30GB的臨時表。
如果EXPLAIN執行計劃的Extra列包含了"Using temporary",則說明這個查詢使用了隱式臨時表
使用枚舉類型(ENUM)代替字符串類型
有時候可以使用枚舉列代替常用的字符串類型。枚舉列可以把一些不重復的字符串存儲成一個預定義的集合。MySQL在存儲枚舉時非常緊湊,會根據列表值得數量壓縮到一個或者兩個字節中。MySQL會在內部將每個值在列表中得為止保存為整數,并且在表的.frm文件中保存"數字-字符串"映射關系的"查找表",
例如,
mysql> CREATE TABLE enum_test(e ENUM('fish', 'apple', 'dog') NOT NULL);
Query OK, 0 rows affected (0.03 sec)
mysql> INSERT INTO enum_test(e) VALUES('fish'), ('dog'),('apple');
Query OK, 3 rows affected (0.02 sec)
Records: 3 Duplicates: 0 Warnings: 0
這三行數據實際存儲為整數,而不是字符串。可以通過在數字上下問環境檢索看到這個雙重屬性:
mysql> SELECT e+0 FROM enum_test;
+-----+
| e+0 |
+-----+
| 1 |
| 3 |
| 2 |
+-----+
3 rows in set (0.05 sec)
如果使用數字作為ENUM枚舉常量,這種雙重性很容易導致混亂,例如ENUM(‘1’,‘2’,‘3’).建議盡量避免這么做。另外一個讓人吃驚的地方時,枚舉字段是按照內部存儲的整數而不是定義的字符串進行排序的:
mysql> SELECT e FROM enum_test ORDER BY e;
+-------+
| e |
+-------+
| fish |
| apple |
| dog |
+-------+
3 rows in set (0.05 sec)
一種繞過這種限制的方式是按照需要的順序來定義枚舉列。另外也可以在查詢中使用FIELD()函數顯式地指定排序順序,但這會導致MySQL無法利用索引消除排序。
mysql> SELECT e FROM enum_test ORDER BY FIELD(e, 'apple', 'dog','fish');
+-------+
| e |
+-------+
| apple |
| dog |
| fish |
+-------+
3 rows in set (0.07 sec)
如果在定義時就是按照字母的順序,就沒有必要這么做了。枚舉最不好的地方是,字符串列表是固定的,添加或刪除字符串必須使用ALTER TABLE,因此,對于一系列未來可能會改變的字符串,使用枚舉不是一個好主意,除非能接受只在列表末尾添加元素,這樣在MySQL5.1中就可以不用重建整個表來完成修改。
由于MySQL把每個枚舉值保存為整數,并且必須進行查找才能轉換為字符串,所以枚舉列有一些開銷。通常枚舉的列表都比較小,所以開銷還可以控制,但也不能保證一直如此。在特定情況下,把CHAR/VARCHAR列與枚舉列進行關聯可能會比直接關聯(CHAR/VARCHAR)列更慢。
為了說明這個情況,讀一個應用中的一張表進行了基準測試,看看在MySQL中執行上面說的關聯的速度如何。該表有一個很大的主鍵:
CREATE TABLE webservicecalls(
day date NOT NULL,
account smallint NOT NULL,
service varchar(10) NOT NULL,
method varchar(50) NOT NULL,
calls int NOT NULL,
items int NOT NULL,
time float NOT NULL,
cost decimal(9,5) NOT NULL,
updated datetime,
PRIMARY KEY(day,account, service, method)
) ENGINE=InnoDB;
這個表有11萬行數據,只有10MB大小,所以可以完全載入內存。service列包含了5個不同的值,平均長度為4個字符,method列包含了71個值,平均產犢為20個字符。
復制一下這個表,但是把service和method字段換成枚舉類型,表結構如下:
CREATE TABLE webservicecalls_enum(
...omitted...
service ENUM(... VALUES omitted ...) NOT NULL,
method ENUM(... VALUES omitted ...) NOT NULL,
...omitted...
) ENGINE=InnoDB;
然后我們用主鍵列關聯這兩個表,下面是所使用的查詢語句:
mysql> SELECT SQL_NO_CACHE COUNT(*) FROM webservicecalls JOIN webservicecalls USING(day, account,service,method);
用VARCHAR和ENUM分別測試了這個語句,結果如表所示
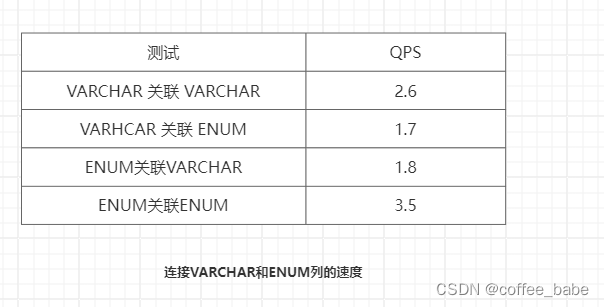
從上面的結果可以看到,當把列都轉換成ENUM以后,關聯變得很快。但是當VARCHAR列和ENUM列進行關聯時則慢很多。在本例中,如果不是必須和VARCHAR列進行關聯,那么轉換這些列為ENUM就是個好主意。這是一個通用的設計時間,在"查找表"時采用整數主鍵而避免采用基于字符串的值進行關聯。然而,轉換列為枚舉型還有另外一個好處。根據SHOW TABLE STATUS命令輸出結果中Data_length列的值,把這兩列轉換為ENUM可以讓表的大小縮小1/3.在某些情況下,即使可能出現ENUM和VARCHAR進行關聯的情況,這也是值得的(這很可能可以節省IO)。同樣,轉換后主鍵也只有原來的一半大小了,因為這是InnoDB表,如果表上有其他索引,減小主鍵大小會使得非主鍵索引也變得更小。

(該圖只是查詢Data_length,與上面的例子無關)

)
)
)














)
 中 webview和h5通信)