【Image captioning】基于檢測模型網格特征提取——以Sydeny為例
今天,我們將重點探討如何利用Faster R-CNN檢測模型來提取Sydeny數據集的網格特征。具體而言,這一過程涉及通過Faster R-CNN模型對圖像進行分析,進而抽取出關鍵區域的特征信息,這些特征在網格結構中被系統地組織和表示。下面,我將引導大家深入了解這一特征提取流程。
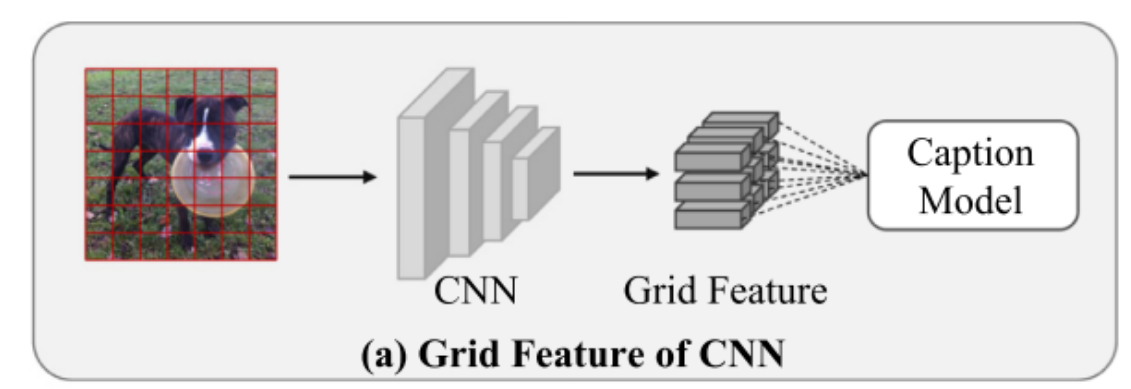
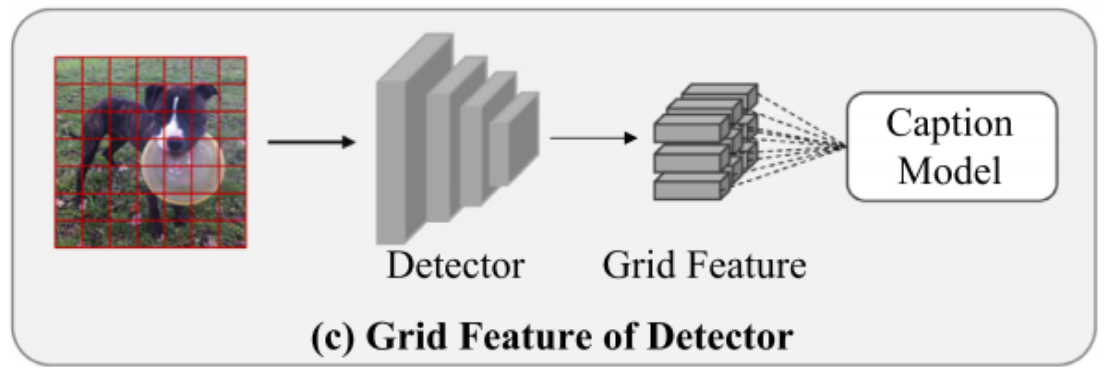
1. 數據的預處理
為了適應In Defense of Grid Features for Visual Question Answering論文提供的官方代碼,需要將自定義圖像數據集的標注和元數據調整成符合COCO數據集格式。COCO(Common Objects in Context)數據集是一種廣泛使用的視覺理解數據集,它不僅包含了豐富的圖像資源,還提供了詳盡的注解信息,包括圖像中的物體類別、邊界框等。
原始Sydeny遙感圖像字幕包含的有圖片imgs和對應的字幕信息dataset.json。
1.1 劃分數據集
根據dataset.json的中的信息,將圖片文件從一個源目







投融資周報|共38筆公開投融資事件,基礎設施領跑,游戲融資活躍)











