文章目錄
- 摘要
- 一、介紹
- 二、SQL算法原語
- 2.1、Variables
- 2.2、Functions
- 2.3、Conditions
- 2.4、Loops
- 2.5、Errors
- 三、案例研究
- 3.1、對數據庫友好的SQL映射
- 3.2、性能結果
- 四、結論以及未來工作
摘要
??盡管SQL在簡單的分析查詢中無處不在,但它很少用于更復雜的計算,如機器學習、線性代數和其他計算密集型算法。這些算法通常以過程方式編程,看起來與聲明性SQL查詢非常不同。然而,SQL實際上提供了執行各種計算的構造。在本文中,我們展示了如何將過程結構轉換為SQL-啟用復雜的SQL-only算法。在算法中使用SQL可以使計算更接近數據,只需要最小的用戶權限,并增加軟件的可移植性。生成的SQL算法的性能在很大程度上取決于底層DBMS和SQL代碼。令人驚訝的是,我們發現像HyPer這樣的查詢引擎可以實現非常高的性能——在某些情況下甚至勝過像NumPy這樣的最先進的線性代數包。
一、介紹
??理論上,任意計算都可以用SQL來表示。然而,這通常被認為是一種理論觀察,而不是一種實際方法。在SQL中直接表示復雜算法的一個障礙是,算法通常是用過程語言表示的。SQL的聲明性使得編寫統計學習或優化算法的查詢變得非常重要。
??目前,復雜的算法是在數據庫系統之外實現的,使用用戶定義函數(udf),或者依賴于系統特定的dbms內操作符。直接在SQL中表達算法有四個主要好處:
- 近數據計算
??使用SQL算法,使得數據保留在數據庫中,SQL查詢引擎可以立即開始計算。并且只顯示計算結果,而不顯示底層數據,則可以確保更高的數據隱私。 - 靈活性
??使用SQL可以自由定制修改,且只需要最小的用戶權限就可以執行各種計算。 - 高度抽象
??SQL算法的向量化、并行甚至分布式執行由底層DBMS自動完成 - 可移植性
??如果SQL算法使用由多個DBMS供應商支持的通用SQL子集,那么該算法無需修改即可在其他DBMS上運行。
二、SQL算法原語
??在本節中,我們將過程語言的算法原語映射到SQL的聲明性語法。為了演示這種轉換,我們將展示Python和PostgreSQL的SQL方言中的代碼片段。
2.1、Variables
??在SQL中,Variables可以表示為關系或關系中的值。這里的關系指的是一些數據結構,如標量、向量、矩陣、張量、集合、哈希表,甚至樹和圖。在SQL計算期間,可以使用WITH子句創建新變量。WITH子句允許命名子查詢。然后可以在主查詢中的幾個位置引用這些命名的子查詢。然而,與過程語言中的變量不同,SQL中使用with子句創建的變量是不可變的。要更新SQL變量,必須創建一個新變量。對于這類原語的python與SQL轉換的例子如下:

2.2、Functions
??函數在大多數編程語言中都是必不可少的。SQL標準允許創建SQL函數,但并不是所有系統都支持。所以有一種替代方法是用WITH構造,從而允許將本地函數嵌入到SQL查詢中。

2.3、Conditions
??標準SQL不提供分支結構,例如if-else來控制程序流。在SQL中,最接近if-else語句的結構是CASE語句。但是,CASE語句決定表達式的結果,因此類似于三元操作符而不是控制結構
??要在SQL中模擬條件控制流,UNION ALL構造是合適的。UNION ALL構造將兩個或多個SELECT語句的結果組合在一起。通過只組合那些滿足SELECT語句WHERE子句條件的結果,就可以模擬條件控制流(見清單3)。UNION ALL的唯一限制是各個SELECT語句中列的數量和列的數據類型必須匹配。

2.4、Loops
??在SQL中,循環有兩種變體,它們是通過遞歸查詢實現的,符合SQL標準[11]。大多數dbms都支持第一種變體,它是一個簡單的循環,在子查詢中沒有遞歸引用(參見清單4),如下

??第二種變體包含子查詢中的遞歸引用,據我們所知,它只在PostgreSQL、DuckDB和HyPer中得到完全支持,如下

??第二個循環變體允許在FROM子句的子查詢中使用清單5中的遞歸工作表x。這些子查詢也可以是遞歸的。如果對工作表的遞歸引用在FROM子句中出現超過一次,PostgreSQL將產生一個錯誤。可以通過在FROM子句中創建一個新變量并在以后的計算中引用它來避免這個錯誤(參見清單5中針對PostgreSQL的變通方法)我們大量利用子查詢中的遞歸引用在SQL中實現各種算法。通過在子查詢中支持遞歸引用,DBMS供應商可以在其產品中啟用僅sql算法。
??遞歸查詢的限制因素是缺乏擁有多個工作表的可能性。在遞歸中只允許有一個工作表。如果算法需要在每次迭代中更新多個變量,則必須立即將它們全部打包到工作表中。在迭代期間,這些變量必須從工作表中解包,然后再為下一次迭代重新打包。
2.5、Errors
??具有實用價值的SQL程序應該對錯誤的輸入數據提供反饋。為了在SQL中實現輸入驗證,我們使用UNION ALL構造。在清單6中,計算了三種狀態下概率分布的熵。概率的一個性質是它們大于等于零并且它們對所有狀態的和是1。在創建錯誤關系時,在WHERE子句中檢查這些前提條件。如果檢測到錯誤輸入,則Errors應該包含相應的錯誤消息。

三、案例研究
??這里使用基于梯度下降的邏輯回歸作為案例研究,以證明以數據庫友好風格編寫的SQL算法是實用的。邏輯回歸是一種流行的二元分類機器學習方法,它會導致以下凸優化問題:

??下面是一個用python寫的基于梯度下降的邏輯回歸

3.1、對數據庫友好的SQL映射
??計算梯度是算法中最耗時的操作。如果性能很重要,那么用于計算梯度的SQL代碼必須是數據庫友好的。在這里,梯度計算主要由線性代數運算組成。SQL中的線性代數計算通常映射為一種格式,該格式顯式存儲向量或矩陣的每個值的索引。向量和矩陣的這種表示類似于用于稀疏線性代數的坐標格式(COO)。下面顯示了如何在SQL中使用COO樣式計算清單7中的梯度。

??在SQL中使用COO風格進行線性代數的一個優點是它的通用性,也就是說,SQL代碼不依賴于矩陣中的列數。在使用COO風格時,默認情況下也支持稀疏線性代數。此外,正在進行積極的研究,以開發查詢引擎,以減少類coo線性代數查詢的執行時間[16]。然而,coo風格的SQL代碼的性能可能不足,因為顯式索引、糟糕的局部性和將數據轉換為正確格式的昂貴轉換會增加內存消耗。此外,SQL中co風格的線性代數嚴重依賴于連接。在清單8中,連接在WHERE子句中指定。
??SQL中coo風格線性代數的另一種方法是將關系本身視為向量或矩陣。關系的行和列對應于線性代數的行和列向量。向量和矩陣的這種表示類似于它們在密集線性代數中的表示。清單9顯示了清單7中使用SQL中的密集線性代數樣式的梯度計算。

??這里的梯度計算避免了連接,并且不需要為向量和矩陣提供顯式索引。因此,我們稱這種計算是數據庫友好的。特性f1、f2和標簽y存儲在單個關系x中。在梯度計算過程中,特征和標簽被傳播以避免不必要的連接。例如,請查看在創建關系cse和v時如何選擇特征f1和f2。例如在創建關系u時,當再次需要f1和f2時,這些“不必要的”選擇避免了連接。
3.2、性能結果
??我們比較了NumPy、HyPer和PostgreSQL之間基于梯度下降的邏輯回歸的性能。
- NumPy是一個用于高性能科學計算的Python包。我們將NumPy鏈接到數學內核庫(MKL)版本2020.0.2。英特爾的MKL庫廣泛使用矢量指令和多核處理。
- HyPer是一個面向列的內存DBMS,在OLTP和OLAP工作負載下都能實現高性能[17]。我們使用Tableau公開的Hyper API版本0.0.13287。
- PostgreSQL是一個廣泛使用的、開源的、面向rowwororiented的DBMS。我們使用PostgreSQL 12.8版本。
??在我們的測量中,我們使用一臺帶有Intel i910980XE 18核處理器(36個超線程)的機器,運行Ubuntu 20.04.1 LTS,內存為128 GB。每個內核的基頻為3.0 GHz,最大turbo頻率為4.6 GHz,支持AVX-512矢量指令集。對于HyPer和PostgreSQL,我們測量了兩種不同邏輯回歸實現的性能。一種是基于coo風格的線性代數,另一種是數據庫友好型的,使用無連接的密集風格進行線性代數(詳細信息請參閱前一小節)。對于數據庫測量,我們使用臨時表。我們不使用數據庫索引。在運行邏輯回歸求解器時,我們以每秒迭代次數來報告性能。一次迭代計算梯度并更新前一次迭代的權重。我們驗證所有實現計算相同的權重,從而獲得相同的模型精度。
??下圖顯示了具有32個特征和100萬個樣本的數據集的基于梯度下降的邏輯回歸的性能。雖然HyPer上的數據庫友好實現實現了每秒100多次迭代,但PostgreSQL上的性能與它的COO實現沒有什么不同。與HyPer相比,PostgreSQL的性能非常低,因為HyPer是一個使用查詢編譯的高效并行DBMS。因此,我們在進一步的測量中忽略了PostgreSQL。然而,令人驚訝的是,HyPer的速度幾乎是NumPy的三倍。下面的測量探討了HyPer優于NumPy的條件

??圖2顯示了性能取決于用于計算的線程數。當使用兩個線程時,HyPer和NumPy的執行情況大致相同。當使用兩個以上的線程時,HyPer上的數據庫友好實現比NumPy快。隨著可用內核數量的增加(線程數≤18),HyPer的性能會穩步提高。通過超線程的額外并行化,HyPer獲得了更高的性能。與HyPer相比,NumPy中梯度計算的并行化很差。盡管MKL在并行化線性代數操作方面通常非常有效,但對于圖2中包含32個特征的示例來說,它就失敗了。

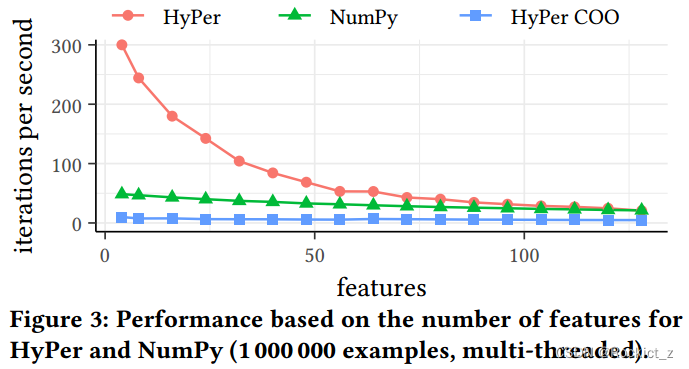
??在圖3中,我們將特征的數量在4到128之間變化。我們把它留給實現來決定使用多少線程。NumPy利用數據集中所有18個核心和4個特征,但如圖3所示,這種情況的效率相當低。圖3顯示,當數據集中少于128個特征時,HyPer是最快的替代方案。然而,HyPer和NumPy之間的性能差距隨著數據集中特征數量的增加而縮小。在128個功能下,NumPy甚至比HyPer還要快一點
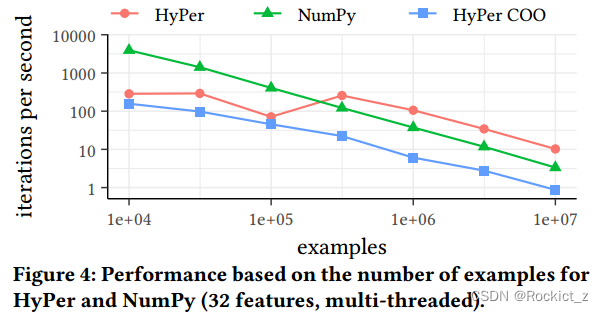
??圖4顯示了性能作為數據集中示例數量的函數。測量結果以對數標度表示。對于數據集中少于或等于105個示例,NumPy是最快的選擇。NumPy將矩陣和向量連續地存儲在內存中,因此當數據集適合緩存時,它將受益于良好的局部性。此外,由于權重更新依賴于先前計算的權重,因此對于小數據集,有效的并行化無法發揮作用。同樣,為了進行基準測試,我們重復運行算法100次迭代。在HyPer中,這些時間包括緩存SQL查詢的運行時。對于較小的數據量,查詢的設置成本不會攤銷。因此,對于小問題,NumPy要快得多。在HyPer中,測量中存在不規則性。對于數據集中的106個示例,HyPer每秒執行的迭代次數多于105個示例。這種不規律的原因是HyPer只通過一個線程執行少于或等于105個示例的所有查詢。
四、結論以及未來工作
??純sql算法不是一個理論噱頭,但可以具有很高的實用價值。它們提供了諸如近數據計算、代碼更改的靈活性、對底層DBMS體系結構的高度抽象以及可移植性等優點。我們展示了如何用SQL表示算法原語。通過使用這些原語,可以在SQL中實現計算密集型算法。在案例研究中,我們提供了數據庫友好的SQL代碼,它避免了線性代數操作的連接。事實證明在HyPer上的數據庫友好型SQL實現甚至可以在更大的數據集上優于NumPy。
??算法中的循環通常包含對先前迭代數據的復雜計算。我們演示了如何在SQL中通過在WITH recursive的FROM子句中使用對工作表的遞歸引用來實現這種循環。像PostgreSQL、DuckDB或HyPer這樣支持遞歸引用的dbms,已經可以使用SQL進行各種計算。擴展DBMS以支持子查詢中的遞歸引用將是很簡單的,我們希望本文能夠促使DBMS開發人員實現這一特性。
??在未來的工作中,我們計劃使用編譯將命令式結構自動轉換為SQL。編譯器方法也可以將線性代數操作轉換為SQL。為了使線性代數操作的轉換盡可能高效,需要進一步探索SQL中無連接線性代數的局限性。深度學習似乎也是我們計劃探索的一個有趣的用例。通過使用外部工具(如我們的矩陣演算[13-15])計算導數并將其轉換為SQL,剩下要做的唯一事情就是在SQL中實現優化算法,這是可能的,正如我們在案例研究中所展示的那樣。因此,我們相信SQL機器學習和其他形式的SQL計算密集分析非常有前途。
))






)



)


)


)

)