前言
隨著人工智能技術的不斷發展,多模態大模型作為一種新型的機器學習技術,逐漸成為人工智能領域的熱點話題。多模態大模型能夠處理多種媒體數據,如文本、圖像、音頻和視頻等,并通過學習不同模態之間的關聯,實現更加智能化的信息處理。
近年來,文檔解析與向量化技術在加速多模態大模型訓練與應用中扮演著至關重要的角色。這些技術不僅提高了數據處理的速度和效率,還優化了模型的性能和準確性。今天,我們就來探討一下這些技術如何助力多模態大模型的訓練與應用。
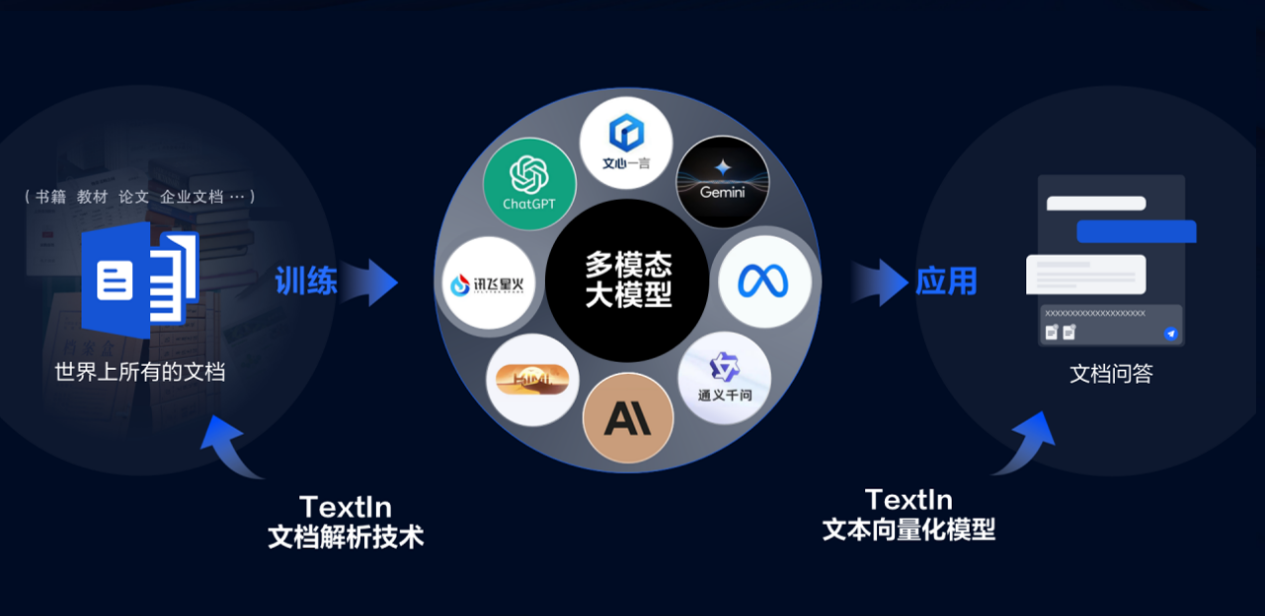
一、文檔解析技術
文檔解析技術主要負責對各種類型的文檔進行結構化處理,提取出文檔中的關鍵信息,并將其轉化為計算機可讀的格式。在多模態大模型訓練中,文檔解析技術可以處理包括文本、圖像、音頻、視頻等在內的多種模態數據。
文檔解析技術背景
文檔解析技術能夠自動識別和提取文檔中的文字信息,包括段落、句子、單詞、標點符號等。通過自然語言處理(NLP)技術,可以進一步對文本進行分詞、詞性標注、命名實體識別等操作,為后續的數據處理和模型訓練提供豐富的語義信息。

核心訴求
- 閱讀順序還原準確
- 元素識別準確,尤其是表格、段落、公式、標題
- 識別速度快
- 支持論文等多種排版文檔
現有大模型文檔解析問題
- 表格/無線表無法解析/錯亂
- 按照閱讀順序解析
- 無法解析掃描版/圖片版文檔
- 文檔編碼出錯誤
典型技術難點
1. 版面檢測

技術難點:文檔可能具有復雜的布局和格式,包括文本、圖像、圖形、表格等多種元素,這些元素的布局和排列方式各不相同,使得版面檢測變得復雜。
技術挑戰:需要開發先進的圖像處理技術和深度學習算法,以準確識別文檔中的不同元素,并確定它們在文檔中的位置和關系。此外,還需要考慮文檔的多樣性,包括不同的字體、顏色、大小等。
2.閱讀順序還原
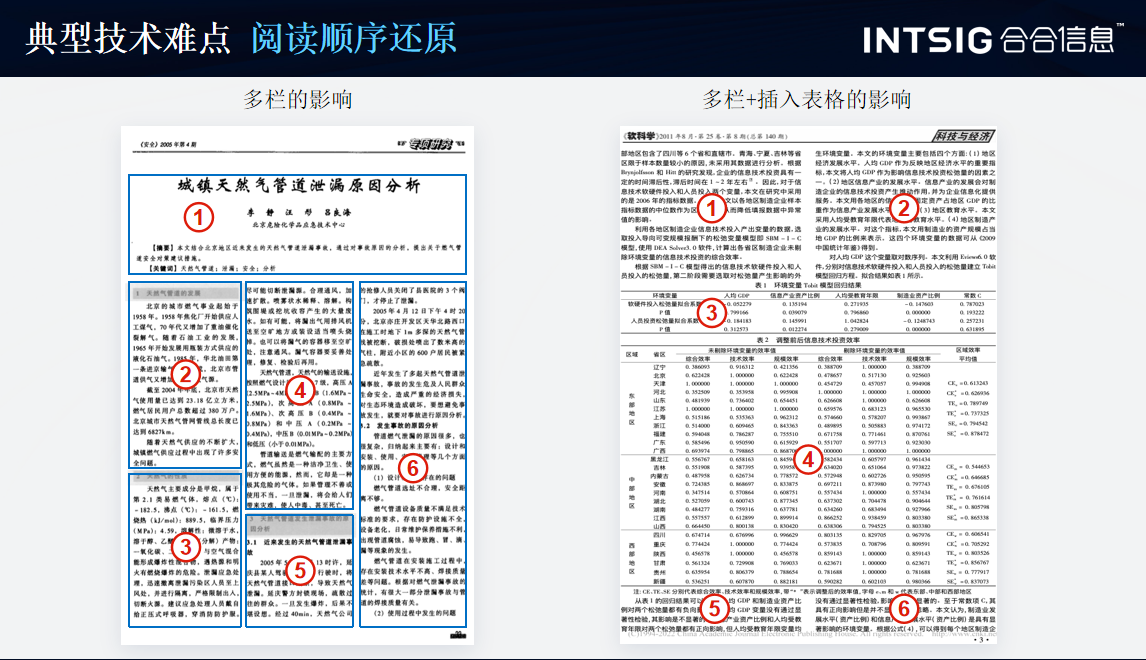
技術難點:在一些復雜的文檔中,如古籍或特殊格式的文檔,文字的排列方式可能不符合常規的從左到右、從上到下的閱讀順序,這增加了閱讀順序還原的難度。
技術挑戰:需要利用自然語言處理技術和上下文信息,結合文檔的版面結構和元素關系,來推斷出正確的閱讀順序。此外,還需要處理可能存在的噪聲和干擾信息。
3.表格還原
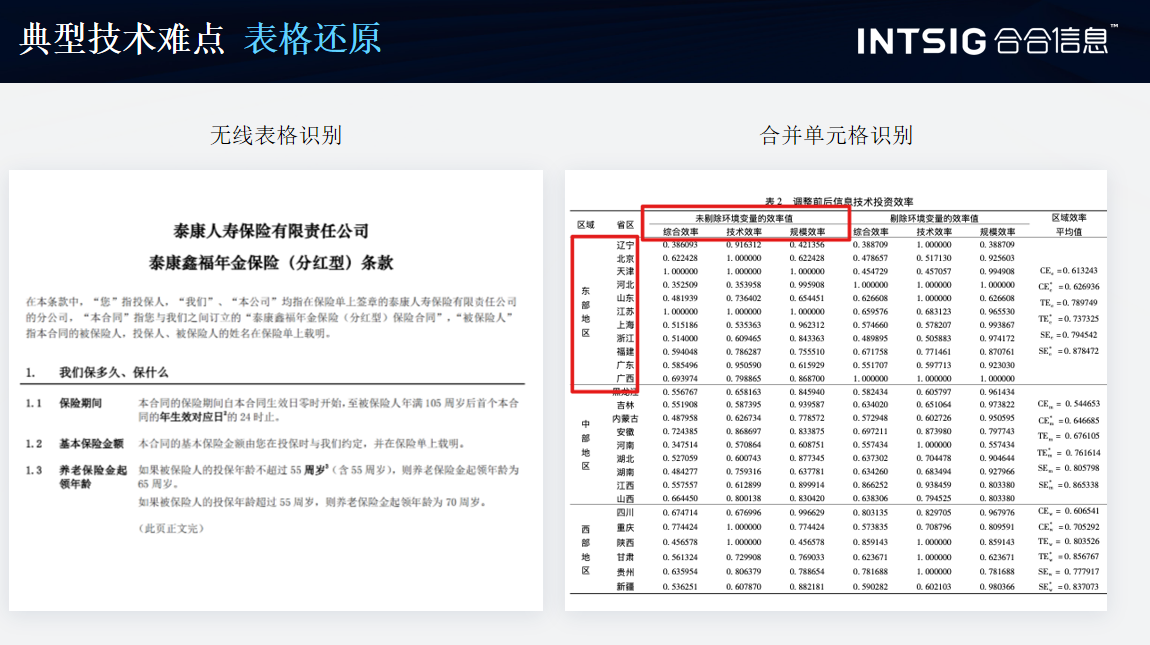
技術難點:表格通常包含大量的數據和結構信息,而且表格的布局和樣式各異,這使得表格還原成為一個具有挑戰性的任務。
技術挑戰:需要開發高精度的表格檢測和識別算法,以準確識別表格的邊界、行、列和單元格等元素。同時,還需要考慮表格內部的數據結構和關系,以便將表格還原為可編輯和可分析的形式。
4.公式識別

技術難點:公式通常包含復雜的數學符號、運算符和表達式,而且公式的排版和布局也各不相同,這使得公式識別成為一個困難的任務。
技術挑戰:需要開發專門的公式識別和解析算法,以準確識別公式中的各個元素和符號,并理解它們之間的關系和含義。此外,還需要考慮公式的多樣性和復雜性,以及可能存在的排版和布局差異。
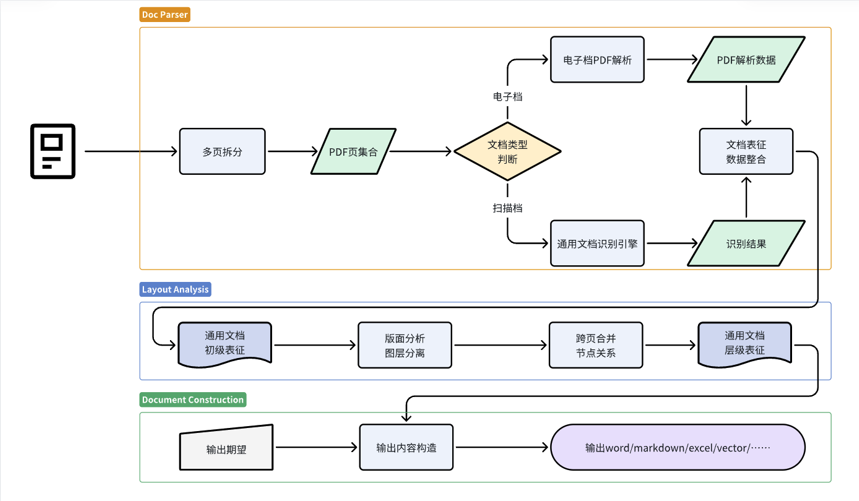
二、合合信息TextIn文檔解析技術
合合信息TextIn文檔解析技術采用深度學習、自然語言處理(NLP)和計算機視覺(CV)等先進技術,能夠自動從各類文檔中提取、識別和理解關鍵信息。專門用于處理和分析各種格式的文檔數據。它為我們展示了一套文檔解析方法,包括文檔拆分、基礎表征和文檔重建三部分,旨在將多元異構的文檔轉化為大模型可理解的形式。
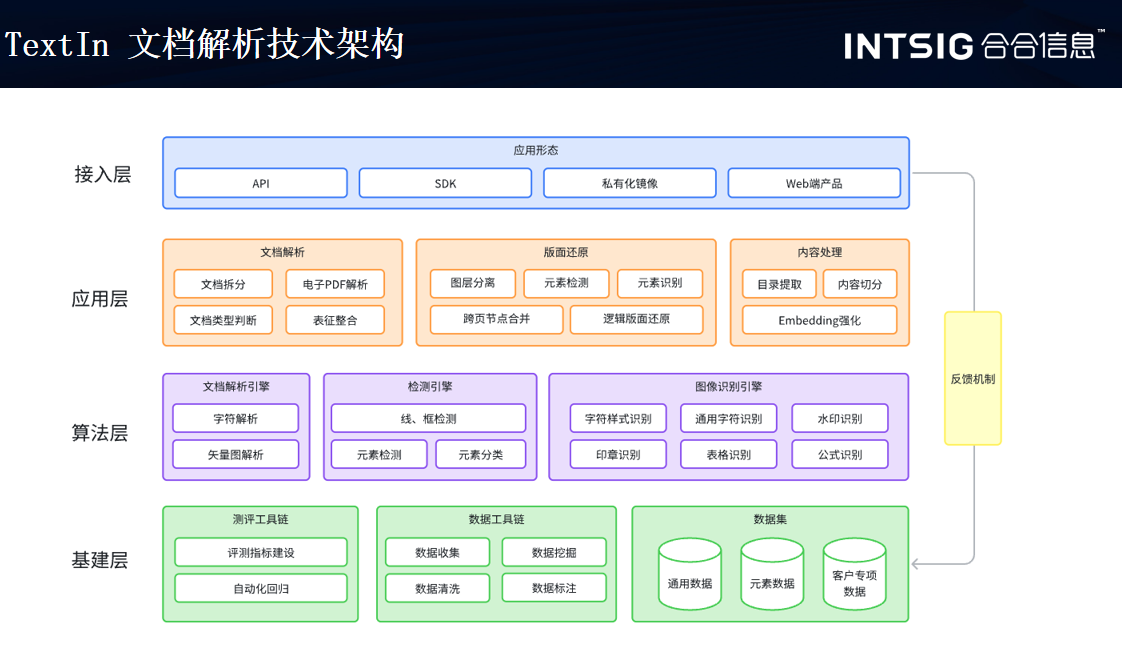
版面分析是文檔圖像還原的核心,通過解決版面分析的痛點,合合信息基于深度學習的方法將圖像文檔以數字化的手段更精準地轉化為文檔數據,應用于多種使用場景、提升工作效率。在文檔處理過程中,合合信息的關鍵技術Layout-engine 和 Catalog-engine 是兩個重要的組件,它們各自承擔著不同的角色和功能。
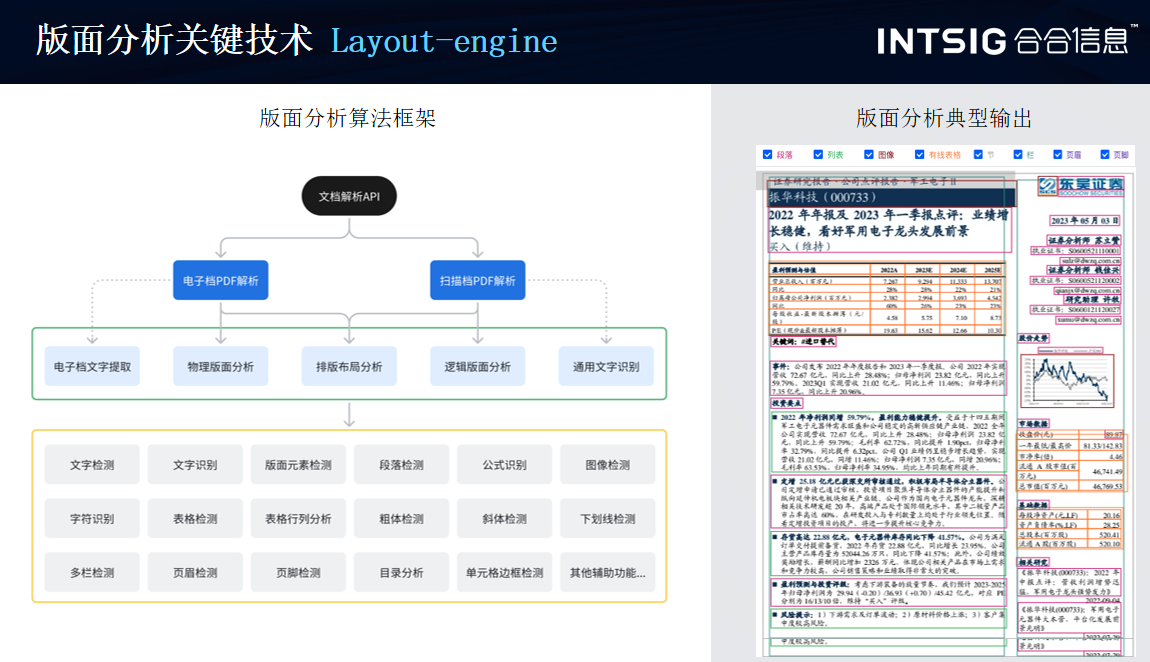
Layout-engine 是版面分析的核心引擎,負責自動檢測和識別文檔中的版面元素及其布局。
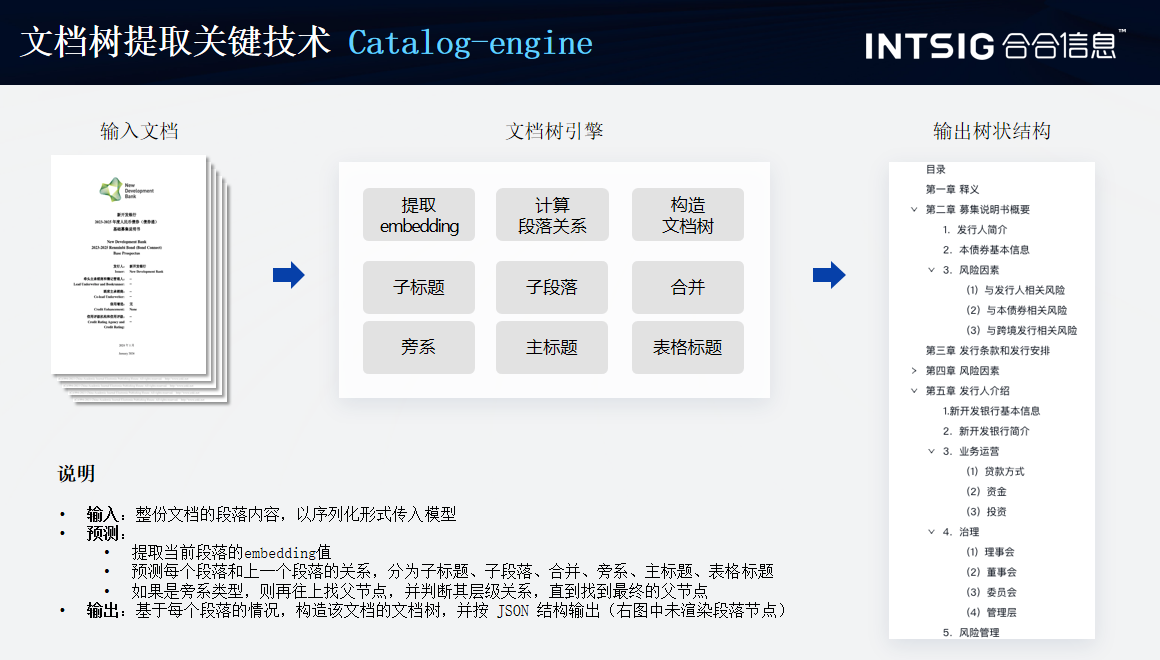
Catalog-engine 在版面分析中扮演著目錄或索引的角色,用于管理和組織識別出的版面元素。
技術特點
- 高精度:TextIn采用先進的深度學習模型,對文檔的識別和信息提取具有很高的準確率。它能夠處理各種復雜場景下的文檔數據,確保信息的準確性。
- 高效率:TextIn具備快速處理大量文檔的能力,可以在短時間內完成大量數據的解析和處理。這使得用戶能夠更快速地獲取所需信息,提高工作效率。
- 易用性:TextIn提供了簡單易用的API接口和可視化界面,方便用戶進行集成和定制。用戶可以根據自己的需求快速構建適合自己的文檔解析系統。
- 可擴展性:TextIn支持多種語言和字符集,具有良好的可擴展性。用戶可以根據需要添加新的語言模型和字符集,以適應不同場景下的文檔處理需求。
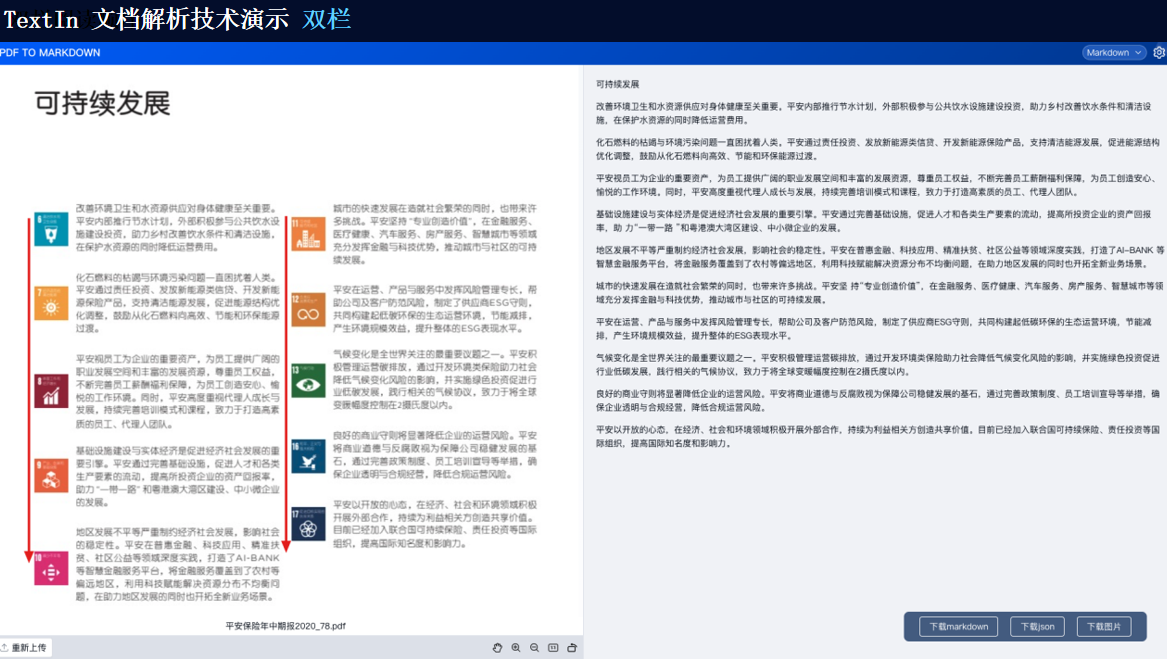
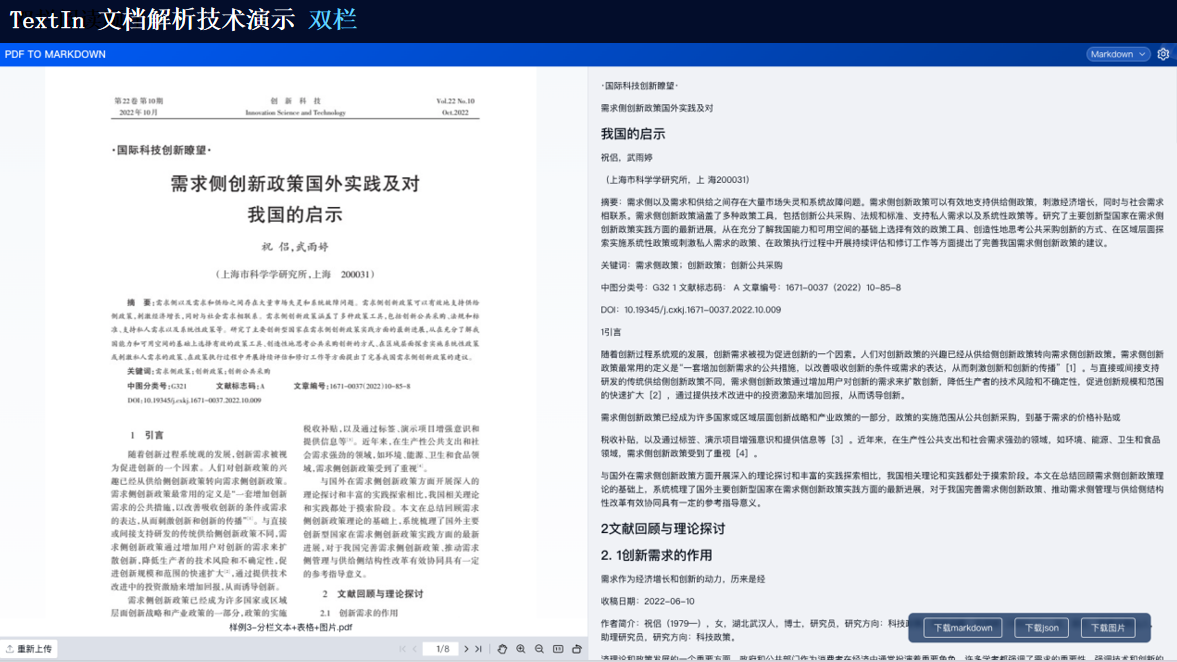
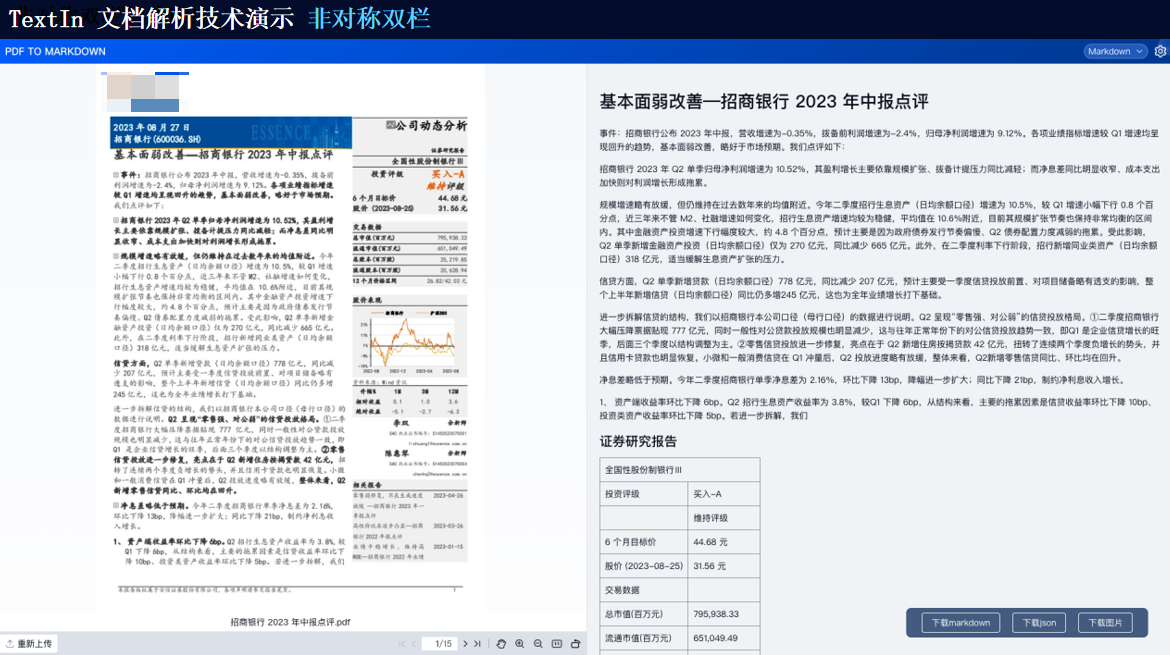
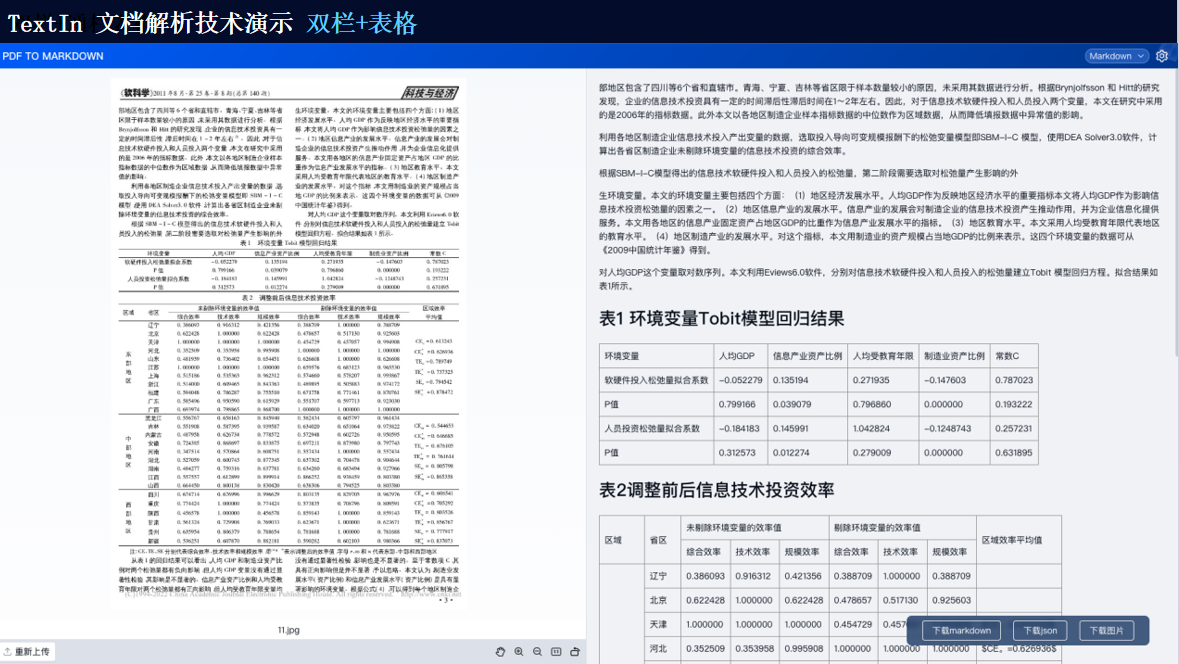
技術演示
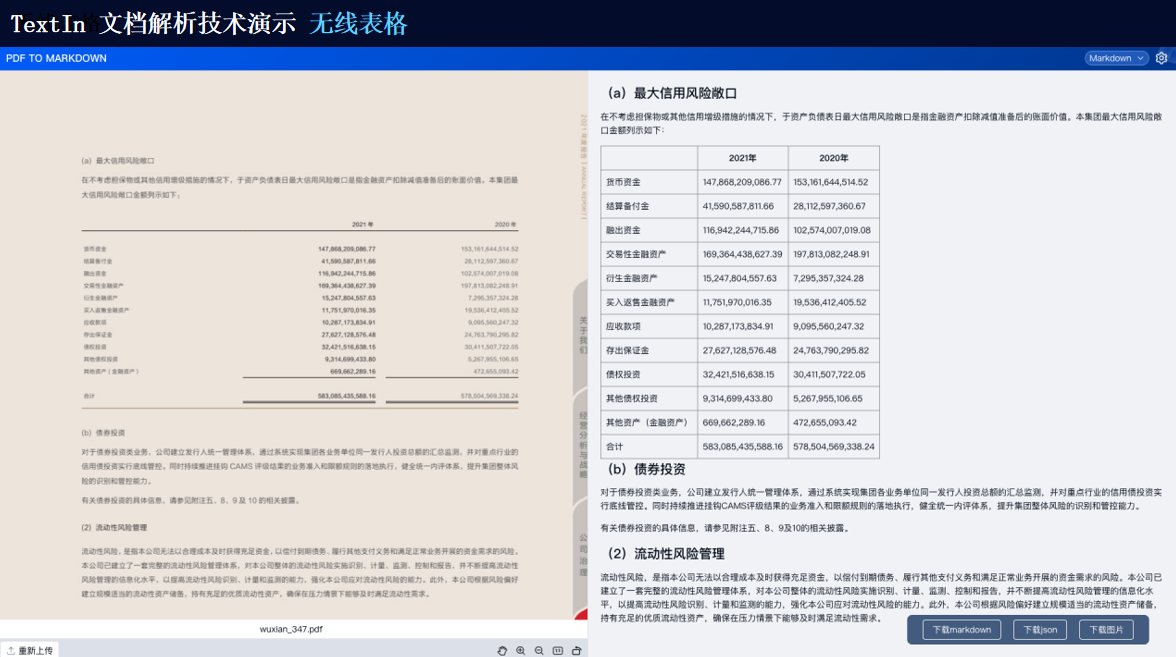
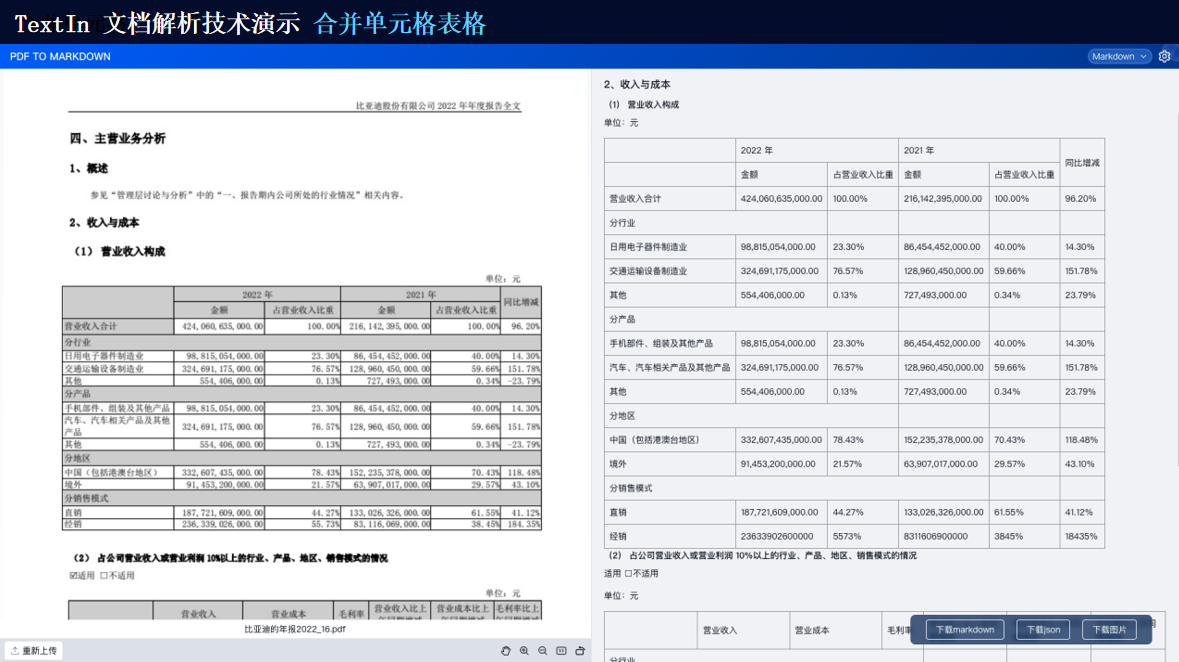
TextIn支持對多種格式的文檔進行識別,包括掃描件、圖片、PDF等。它能夠自動檢測文檔中的文本、圖像、表格等元素,并進行高精度識別。
?
?
?
?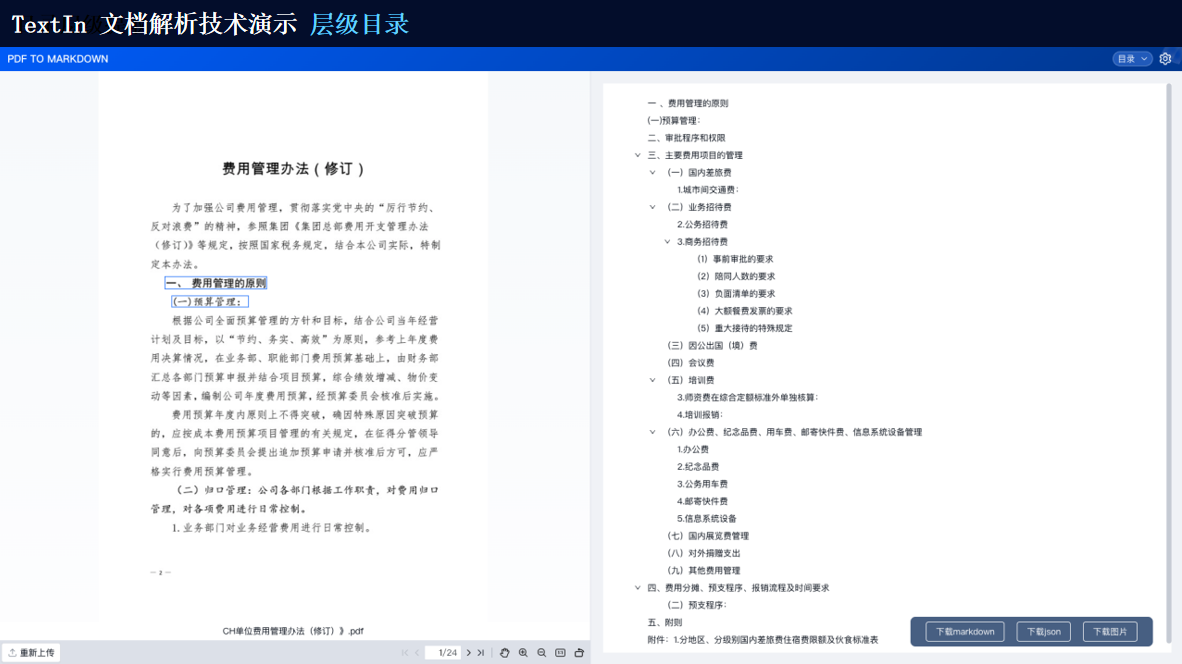
由此可見,TextIn能夠處理多種類型的復雜格式文檔以及跨語言文檔等。通過先進的圖像識別、自然語言處理和深度學習技術,它能夠為我們提供高效、準確的文檔處理和分析服務,滿足各種應用場景的需求。
文檔解析技術+大模型演示
將文檔解析技術與大模型結合使用,可以充分發揮兩者的優勢,實現更高效、更準確的文檔處理。

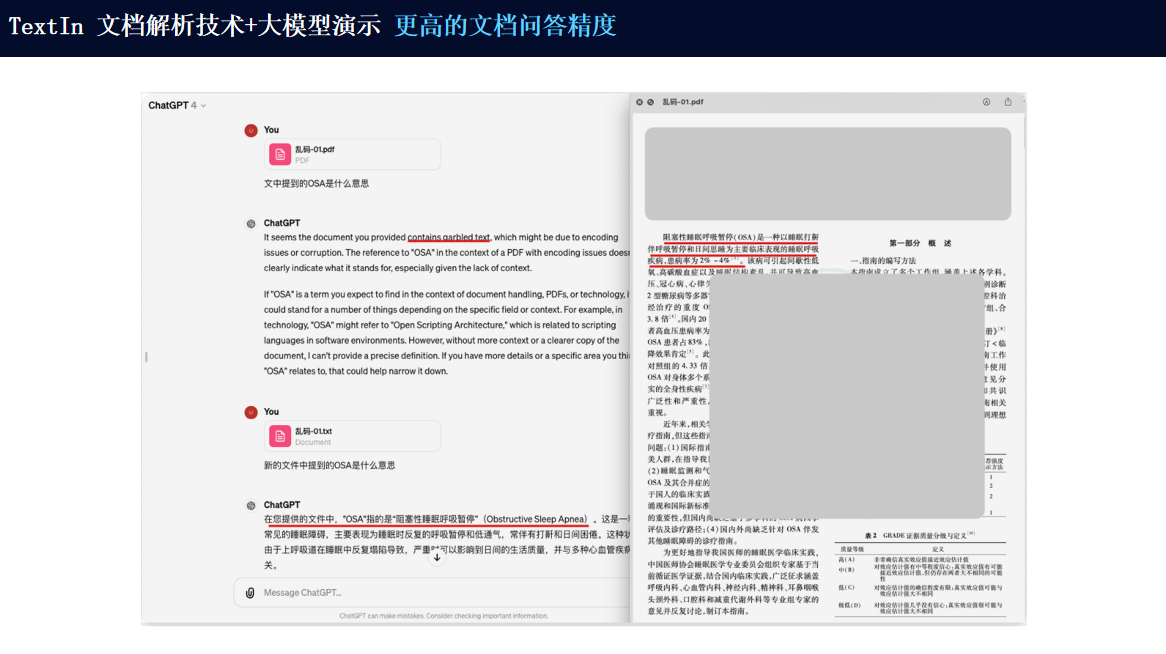
由此看來,無論您是在哪個行業領域工作,都可以考慮使用強大的TextIn來提高您的工作效率和質量。
三、文本向量化技術
向量化技術是將文本、圖像、音頻等模態數據轉化為數值向量的過程。這些數值向量可以作為機器學習模型的輸入,從而實現多模態數據的融合和處理。
文本向量化技術可以將文本數據轉化為數值向量。常見的文本向量化方法包括詞袋模型(Bag of Words)、TF-IDF、Word2Vec、BERT等。這些方法能夠將文本中的單詞或句子轉化為高維向量空間中的點,從而方便進行相似度計算、分類、聚類等操作。
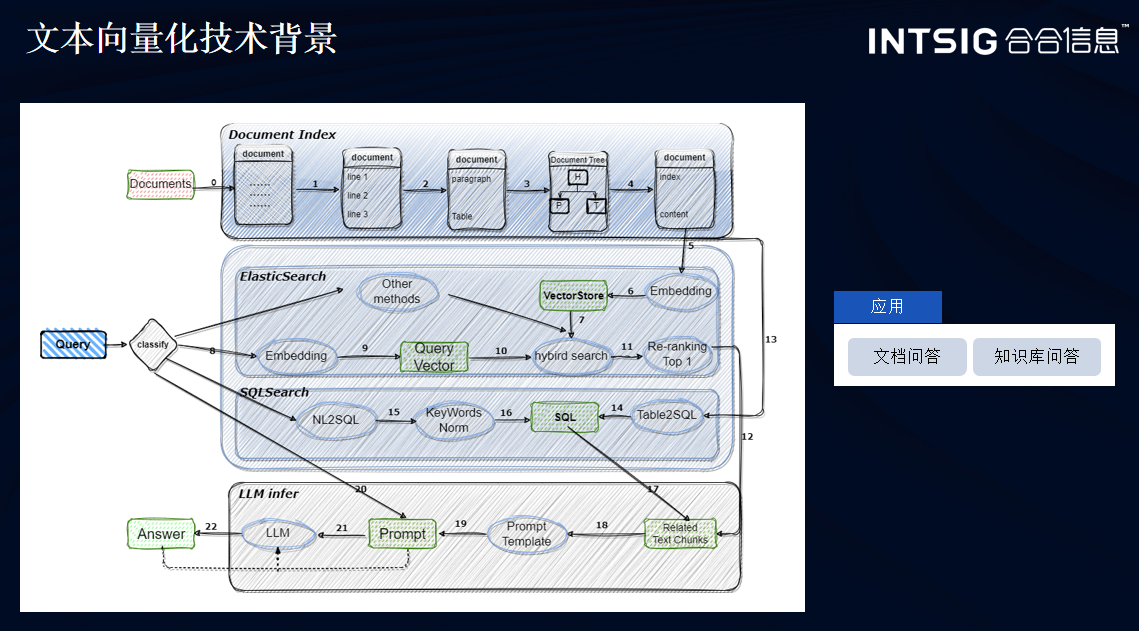
文本向量化模型
文本向量化模型是自然語言處理(NLP)中的一項核心技術,它可以將單詞、句子或圖像特征等高維的離散數據轉換為低維的連續向量,從而將文本數據轉換為計算機能夠處理的數值型向量形式。
近期,合合信息發布了文本向量化模型acge_text_embedding(簡稱“acge模型”),獲得MTEB中文榜單(C-MTEB)第一的成績,從 Chinese Massive Text Embedding Benchmark 中可以看到目前最新的針對中文海量文本embedding的各項任務的排行榜,針對不同的任務場景均有單獨的排行榜。
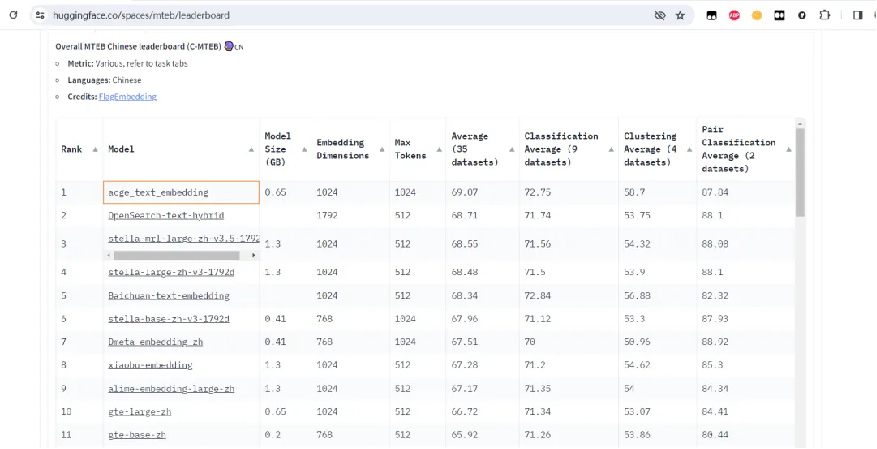
此次合合信息的acge模型,榮獲的就是C-MTEB榜單的第一。?相關成果將有助于大模型更快速地在千行百業中產生應用價值。
結語
文檔解析與向量化技術在加速多模態大模型訓練與應用中發揮著重要作用。通過這些技術,我們可以更高效地處理多模態數據,提高模型的性能和準確性,并推動人工智能技術的發展和應用。
合合信息是一家人工智能及大數據科技企業,基于自主研發的智能文字識別及商業大數據核心技術,為全球C端用戶和多元行業B端客戶提供數字化、智能化的產品及服務。
歡迎各位感興趣的朋友訪問 合合信息旗下的OCR云服務產品——TextIn的官方網站,了解更多關于智能文字識別產品和技術的信息,體驗智能圖像處理、文字表格識別、文檔內容提取等產品,更多驚喜等著你哦,快來試試吧:合合信息TextIn智能文字識別產品
銷售數據分析)


 文件上傳)















