1. 碎碎念
我這答案做的可能不對,如果不對,歡迎大家指出錯誤
2. 答案
1.1 判斷正誤
(1) N ( log N ) 2 N(\text{log}N)^{2} N(logN)2是 O ( N 2 ) O(N^{2}) O(N2)的。
(2) N 2 ( log N ) 2 N^{2}(\text{log}N)^{2} N2(logN)2和 N ( log N ) 2 N(\text{log}N)^{2} N(logN)2具有相同的增長速度。
【答】(1)根據 O ( 1 ) < O ( log ? 2 n ) < O ( n ) < O ( n log ? 2 n ) < O ( n 2 ) < O ( n 3 ) < O ( 2 n ) < O ( n ! ) < O ( n n ) O(1)<O\left(\log _{2} n\right)<O(n)<O\left(n \log _{2} n\right)<O\left(n^{2}\right)<O\left(n^{3}\right)<O\left(2^{n}\right)<O(n!)<O\left(n^{n}\right) O(1)<O(log2?n)<O(n)<O(nlog2?n)<O(n2)<O(n3)<O(2n)<O(n!)<O(nn)
故當 n → ∞ n\to \infty n→∞時, N < N log N < N 2 N<N\text{log}N<N^{2} N<NlogN<N2, 1 < log N < N 1<\text{log}N<N 1<logN<N,所以 N < N ( log N ) 2 < N 3 N<N(\text{log}N)^{2}<N^{3} N<N(logN)2<N3,用不等式法沒法求出它到底和 O ( N 2 ) O(N^{2}) O(N2)的關系,于是我們只能通過求二者的數列極限之比來比較大小,由廣義的洛必達法則:
廣義的洛必達法則:
設 f ( x ) f(x) f(x)和 g ( x ) g(x) g(x)在 U o ( x 0 ) \stackrel{o}{U}\left(x_{0}\right) Uo?(x0?)上可導(即在 x 0 x_{0} x0?的去心鄰域內可導),若滿足:
- g ′ ( x ) ≠ 0 g'(x)\ne0 g′(x)=0;
- lim ? x → x 0 g ( x ) = ∞ \lim\limits _{x \rightarrow x_{0}} g(x)=\infty x→x0?lim?g(x)=∞,且 lim ? x → x 0 f ( x ) \lim\limits _{x \rightarrow x_{0}}f(x) x→x0?lim?f(x)存不存在隨意;
- lim ? x → x 0 f ′ ( x ) g ′ ( x ) \lim\limits _{x \rightarrow x_{0}} \frac{f^{\prime}(x)}{g^{\prime}(x)} x→x0?lim?g′(x)f′(x)?存在;
則有 lim ? x → x 0 f ( x ) g ( x ) = lim ? x → x 0 f ′ ( x ) g ′ ( x ) \lim\limits _{x \rightarrow x_{0}} \frac{f(x)}{g(x)}=\lim\limits _{x \rightarrow x_{0}} \frac{f^{\prime}(x)}{g^{\prime}(x)} x→x0?lim?g(x)f(x)?=x→x0?lim?g′(x)f′(x)?
f ( x ) = x ( log ( x ) ) 2 f(x)=x(\text{log}(x))^{2} f(x)=x(log(x))2和 g ( x ) = x 2 g(x)=x^{2} g(x)=x2是初等函數,在它們的定義域(包括正無窮點是可導的),由海涅定理,將函數極限歸結為數列極限,則 lim ? N → ∞ N ( log N ) 2 N 2 = lim ? N → ∞ ( log N ) 2 N = 廣義洛必達法則,此處以log=ln為例子,其他底的結果是一樣的? lim ? N → ∞ 2 log N N 1 = lim ? N → ∞ 2 log N N = 0 \lim\limits_{N \to \infty} \frac{N(\text{log}N)^{2}}{N^{2}}=\lim\limits_{N \to \infty} \frac{(\text{log}N)^{2}}{N} \stackrel{\text { 廣義洛必達法則,此處以log=ln為例子,其他底的結果是一樣的 }}{=}\lim\limits_{N \to \infty}\frac{\frac{2\text{log}N}{N}}{1}=\lim\limits_{N \to \infty}\frac{2\text{log}N}{N}=0 N→∞lim?N2N(logN)2?=N→∞lim?N(logN)2?=?廣義洛必達法則,此處以log=ln為例子,其他底的結果是一樣的?N→∞lim?1N2logN??=N→∞lim?N2logN?=0,所以當 n → ∞ n\to \infty n→∞時, N ( log N ) 2 < N 2 N(\text{log}N)^{2}<N^{2} N(logN)2<N2,故 N ( log N ) 2 N(\text{log}N)^{2} N(logN)2不是 O ( N 2 ) O(N^{2}) O(N2)的,錯誤。
(2)由于 lim ? N → ∞ N 2 ( log N ) 2 N ( log N ) 2 = lim ? N → ∞ N = ∞ \lim\limits_{N \to \infty} \frac{N^{2}(\text{log}N)^{2}}{N(\text{log}N)^{2}}=\lim\limits_{N \to \infty}N=\infty N→∞lim?N(logN)2N2(logN)2?=N→∞lim?N=∞,所以當 n → ∞ n\to \infty n→∞時, N 2 ( log N ) 2 < N ( log N ) 2 N^{2}(\text{log}N)^{2}<N(\text{log}N)^{2} N2(logN)2<N(logN)2, N 2 ( log N ) 2 N^{2}(\text{log}N)^{2} N2(logN)2和 N ( log N ) 2 N(\text{log}N)^{2} N(logN)2不具有相同的增長速度。
1.2 填空題
(1)給定 N × N N\times N N×N的二維數組 A A A,則在不改變數組的前提下,查找最大元素的時間復雜度是( )。
【答】查找最大元素的時間復雜度是 O ( N 2 ) O(N^{2}) O(N2),因為要雙層for循環,第一層遍歷行,規模為 N N N,第二層遍歷列,規模為 N N N然后去不斷比較找到最大元素
(2)斐波那契而數列 F N F_{N} FN?的定義為: F 0 = 0 , F 1 = 1 , F N = F N ? 1 + F N ? 2 , N = 2 , 3 , . . . F_{0}=0,F_{1}=1,F_{N}=F_{N-1}+F_{N-2},N=2,3,... F0?=0,F1?=1,FN?=FN?1?+FN?2?,N=2,3,...。用遞歸函數計算 F N F_{N} FN?的空間復雜度是( );時間復雜度是( )。
【答】空間復雜度為 O ( N ) O(N) O(N),時間復雜度為 O ( ( 1 + 5 2 ) n ) O\left(\left(\frac{1+\sqrt{5}}{2}\right)^{n}\right) O((21+5??)n),具體解析過程如下:
補充個前置知識,差分方程:
(1)差分方程:設序列 a 0 , a 1 , . . . , a n , . . . a_{0}, a_{1}, ..., a_{n}, ... a0?,a1?,...,an?,...簡記為 { a n } \{a_{n}\} {an?},一個把 a n a_{n} an?與某些個 a i ( i < n ) a_{i}(i<n) ai?(i<n)聯系起來的等式稱作關于序列 { a n } \{a_{n}\} {an?}的差分方程(又稱為遞推方程,遞歸方程)
(2)差分方程的階:差分方程 f ( n ) = f ( n ? 1 ) + f ( n ? 2 ) + . . . f(n)=f(n-1)+f(n-2)+... f(n)=f(n?1)+f(n?2)+...中最大下標與最小下標之差稱為差分方程的階。
(3) k k k階常系數線性差分方程:設差分方程滿足:
{ H ( n ) ? a 1 H ( n ? 1 ) ? a 2 H ( n ? 2 ) ? ? ? a k H ( n ? k ) = f ( n ) H ( 0 ) = b 0 , H ( 1 ) = b 1 , H ( 2 ) = b 2 , ? , H ( k ? 1 ) = b k ? 1 \left\{\begin{array}{l} H(n)-a_{1} H(n-1)-a_{2} H(n-2)-\cdots-a_{k} H(n-k)=f(n) \\ H(0)=b_{0}, H(1)=b_{1}, H(2)=b_{2}, \cdots, H(k-1)=b_{k-1} \end{array}\right. {H(n)?a1?H(n?1)?a2?H(n?2)???ak?H(n?k)=f(n)H(0)=b0?,H(1)=b1?,H(2)=b2?,?,H(k?1)=bk?1??
其中 a 1 , a 2 , . . . , a k a_{1},a_{2},...,a_{k} a1?,a2?,...,ak?為常數, a k ≠ 0 a_{k}\ne0 ak?=0,這個方程稱作 k k k階常系數線性差分方程, b 0 , b 1 , . . . b k ? 1 b_{0},b_{1},...b_{k-1} b0?,b1?,...bk?1?為 k k k個初值,當 f ( n ) = 0 f(n)=0 f(n)=0時稱這個差分方程為齊次方程;
(4)常系數線性齊次差分方程的特征根:
{ H ( n ) ? a 1 H ( n ? 1 ) ? a 2 H ( n ? 2 ) ? ? ? a k H ( n ? k ) = 0 H ( 0 ) = b 0 , H ( 1 ) = b 1 , H ( 2 ) = b 2 , ? , H ( k ? 1 ) = b k ? 1 \left\{\begin{array}{l} H(n)-a_{1} H(n-1)-a_{2} H(n-2)-\cdots-a_{k} H(n-k)=0 \\ H(0)=b_{0}, H(1)=b_{1}, H(2)=b_{2}, \cdots, H(k-1)=b_{k-1} \end{array}\right. {H(n)?a1?H(n?1)?a2?H(n?2)???ak?H(n?k)=0H(0)=b0?,H(1)=b1?,H(2)=b2?,?,H(k?1)=bk?1??
方程 x k ? a 1 x k ? 1 ? ? ? a k = 0 x^{k}-a_{1} x^{k-1}-\cdots-a_{k}=0 xk?a1?xk?1???ak?=0稱作該差分方程的特征方程,特征方程的根
(5)一階常系數線性差分方程:
H ( n ) ? a H ( n ? 1 ) = f ( n ) H(n)-a H(n-1)=f(n) H(n)?aH(n?1)=f(n)
其中 a ≠ 0 a\ne0 a=0,
當 f ( n ) ≠ 0 f(n)\ne0 f(n)=0,則稱此方程為一階常系數非齊次差分方程;
當 f ( n ) = 0 f(n)=0 f(n)=0,則稱此方程為一階常系數齊次差分方程(5.1)一階線性齊次差分方程通解的求法(特征根法):
對于差分方程 H ( n ) ? a H ( n ? 1 ) = 0 H(n)-aH(n-1)=0 H(n)?aH(n?1)=0,特征方程為 x ? a = 0 x-a=0 x?a=0,特征根為 x = a x=a x=a,故一階線性齊次差分方程的 H ( n ) ? a H ( n ? 1 ) = 0 H(n)-aH(n-1)=0 H(n)?aH(n?1)=0的通解為 H ˉ ( n ) = C ? a n ( C 為任意常數 ) \bar{H}(n)=C \cdot a^{n}(C為任意常數) Hˉ(n)=C?an(C為任意常數)
(5.2)一階線性非齊次差分方程通解的求法(齊次通接+非齊次特解):
H(n)-aH(n-1)=f(n)的通解=齊次方程H(n)-aH(n-1)=0的通解+非齊次的一個特解,其主要有下面兩種類型:(5.2.1) f ( n ) = P t ( n ) f(n)=Pt(n) f(n)=Pt(n)型
方程 H ( n ) ? a H ( n ? 1 ) = f ( n ) H(n)-aH(n-1)=f(n) H(n)?aH(n?1)=f(n)
特解: H ? ( n ) = n k Q t ( n ) H^{*}(n)=n^{k} Q t(n) H?(n)=nkQt(n)( Q t ( n ) Qt(n) Qt(n)是與 P t ( n ) Pt(n) Pt(n)通次的待定多項式)
其中 k = { 0 , 若? 1 不是特征方程的特征根? 1 , 若? 1 是特征方程的特征根? k=\left\{\begin{array}{l} 0, \text { 若 } 1 \text { 不是特征方程的特征根 } \\ 1, \text { 若 } 1 \text { 是特征方程的特征根 } \end{array}\right. k={0,?若?1?不是特征方程的特征根?1,?若?1?是特征方程的特征根??
(5.2.2) f ( n ) = A β n f(n)=A \beta^{n} f(n)=Aβn型( A A A是某個常數, β ≠ 1 \beta\ne1 β=1):
方程的特解為: H ? ( n ) = { p ? β n , β 不是特征方程的特征根? p ? n e ? β n , β 是特征方程的特征根? e ,?其中? p 為待定常數? H^{*}(n)=\left\{\begin{array}{l} p \cdot \beta n, \beta \text { 不是特征方程的特征根 } \\ p \cdot n^{e} \cdot \beta^{n}, \beta \text { 是特征方程的特征根 } e \end{array} \text {, 其中 } p\right. \text { 為待定常數 } H?(n)={p?βn,β?不是特征方程的特征根?p?ne?βn,β?是特征方程的特征根?e?,?其中?p?為待定常數?(6)二階常系數線性差分方程:
H ( n ) ? a H ( n ? 1 ) + b H ( n ? 2 ) = f ( n ) H(n)-a H(n-1)+bH(n-2)=f(n) H(n)?aH(n?1)+bH(n?2)=f(n)
其中 a a a為任意常數, b ≠ 0 b\ne0 b=0,
當 f ( n ) ≠ 0 f(n)\ne0 f(n)=0,則稱此方程為二階常系數非齊次差分方程;
當 f ( n ) = 0 f(n)=0 f(n)=0,則稱此方程為二階常系數齊次差分方程
特征方程為 x 2 + a x + b = 0 x^{2}+ax+b=0 x2+ax+b=0
特征根為 x 1 , 2 = ? a ± a 2 ? 4 b 2 x_{1,2}=\frac{-a \pm \sqrt{a^{2}-4b}}{2} x1,2?=2?a±a2?4b??(6.1)二階常系數線性齊次差分方程通解的求法(特征根法):
通解為 H ˉ ( n ) = { C 1 x 1 n + C 2 x 2 n 且? C 1 , C 2 為任意常數,? x 1 ≠ x 2 且均為實根? ( C 1 + C 2 n ) x n 且? C 1 , C 2 為任意常數,? x 1 = x 2 且均為實根? r n ( C 1 cos ? θ n + C 2 sin ? θ n ) 且? r = α 2 + β 2 又? tan ? θ = β α , x 1 , 2 = α ± β i 且為一對共軛復根? \bar{H}(n)=\left\{\begin{array}{l} C_{1} x_{1}^{n}+C_{2} x_{2}^{n} \text { 且 } C_{1}, C_{2} \text { 為任意常數, } x_{1} \neq x_{2} \text { 且均為實根 } \\ \left(C_{1}+C_{2} n\right) x^{n} \text { 且 } C_{1}, C_{2} \text { 為任意常數, } x_{1}=x_{2} \text { 且均為實根 } \\ r^{n}\left(C_{1} \cos \theta n+C_{2} \sin \theta n\right) \text { 且 } r=\sqrt{\alpha^{2}+\beta^{2}} \text { 又 } \tan \theta=\frac{\beta}{\alpha}, x_{1,2}=\alpha \pm \beta i \text { 且為一對共軛復根 } \end{array}\right. Hˉ(n)=? ? ??C1?x1n?+C2?x2n??且?C1?,C2??為任意常數,?x1?=x2??且均為實根?(C1?+C2?n)xn?且?C1?,C2??為任意常數,?x1?=x2??且均為實根?rn(C1?cosθn+C2?sinθn)?且?r=α2+β2??又?tanθ=αβ?,x1,2?=α±βi?且為一對共軛復根??
(6.2)二階線性非齊次差分方程通解的求法**(齊次通接+非齊次特解)**:(6.2.1) f ( n ) = P t ( n ) f(n)=Pt(n) f(n)=Pt(n)型
特解為 H ? ( n ) = n k Q t ( n ) H^{*}(n)=n^{k} Q t(n) H?(n)=nkQt(n),其中 k = { 0 , 若? 1 不是特征根? 1 , 若? 1 是特征單根? 2 , 若? 1 是特征重根? k=\left\{\begin{array}{l} 0, \text { 若 } 1 \text { 不是特征根 } \\ 1, \text { 若 } 1 \text { 是特征單根 } \\ 2, \text { 若 } 1 \text { 是特征重根 } \end{array}\right. k=? ? ??0,?若?1?不是特征根?1,?若?1?是特征單根?2,?若?1?是特征重根??
(6.2.2) f ( n ) = A β n f(n)=A \beta^{n} f(n)=Aβn型( A A A是某個常數, β ≠ 1 \beta\ne1 β=1):
特解為 H ? ( n ) = { p ? β n , β 不是特征根? p ? n x ? β n , β 是特征重根? x H^{*}(n)=\left\{\begin{array}{l} p \cdot \beta^{n}, \beta \text { 不是特征根 } \\ p \cdot n^{x} \cdot \beta^{n}, \beta \text { 是特征重根 } x \end{array}\right. H?(n)={p?βn,β?不是特征根?p?nx?βn,β?是特征重根?x?
(6.2.3) f ( n ) = p ( p 為常數 ) f(n)=p(p為常數) f(n)=p(p為常數):
當特征根不為1時,將 p p p帶入原方程求解特解,當特征根為1時,則特解 H ? ( n ) = p n H^{*}(n)=pn H?(n)=pn
根據題目,斐波那契數列的遞歸函數應該寫成如下C語言代碼:
int fib(int n){if(n==0){return 0;}else if(n==1){return 1;}else{return fib(n-1) + fib(n-2);}
}
題目中要求求的就是遞歸函數版本,則先分析空間復雜度:
由于函數遞歸調用的時候必定涉及到函數調用棧,所以得提前說一下,棧是一種線性的先進后出的數據結構,調用函數的時候,其底層是維護了一個函數調用棧,具體怎么做,請看下面的解答:假設問題規模的 n = 5 n=5 n=5
首先,fib(5)進棧:

fib(4)進棧:

fib(3)進棧:

fib(2)進棧:

fib(2)出棧:
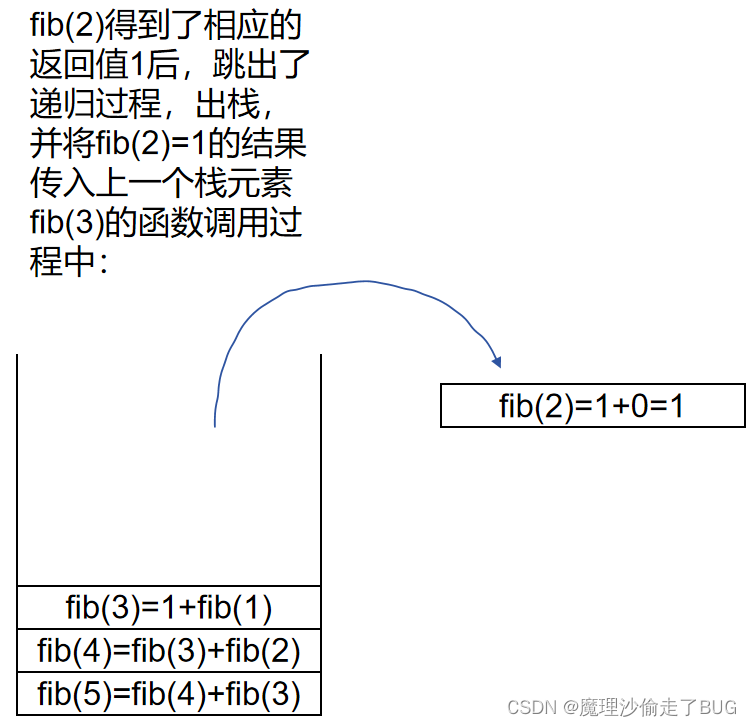
fib(3)出棧:
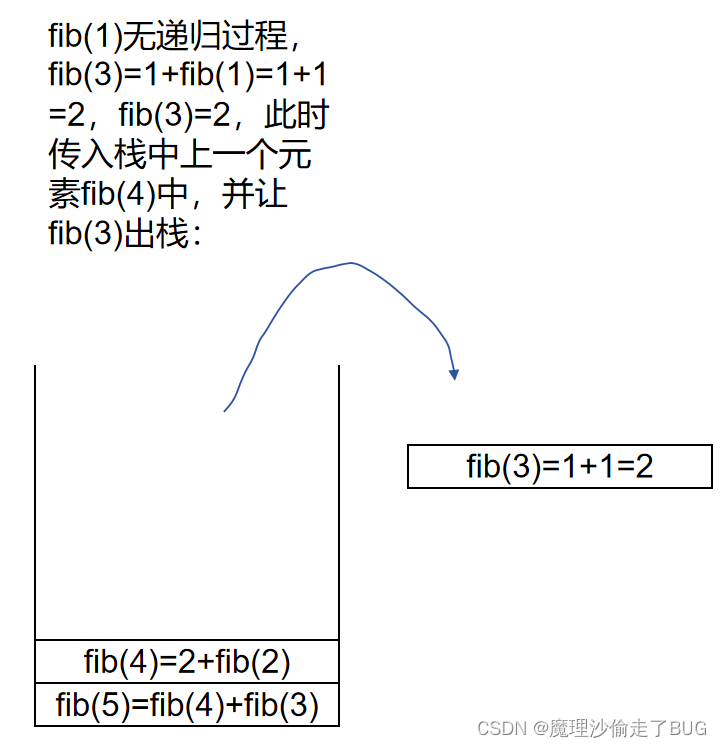
fib(2)進棧:

fib(2)出棧:
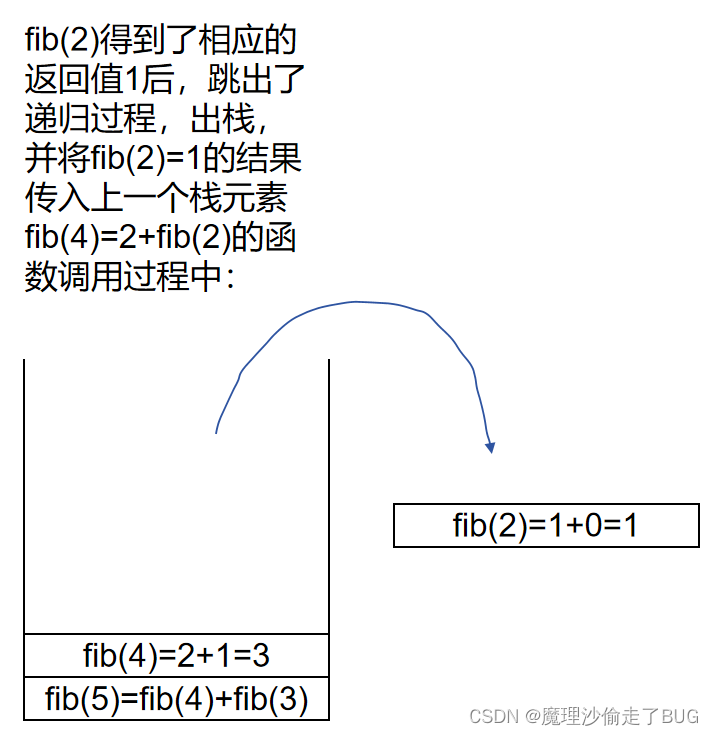
fib(4)出棧:
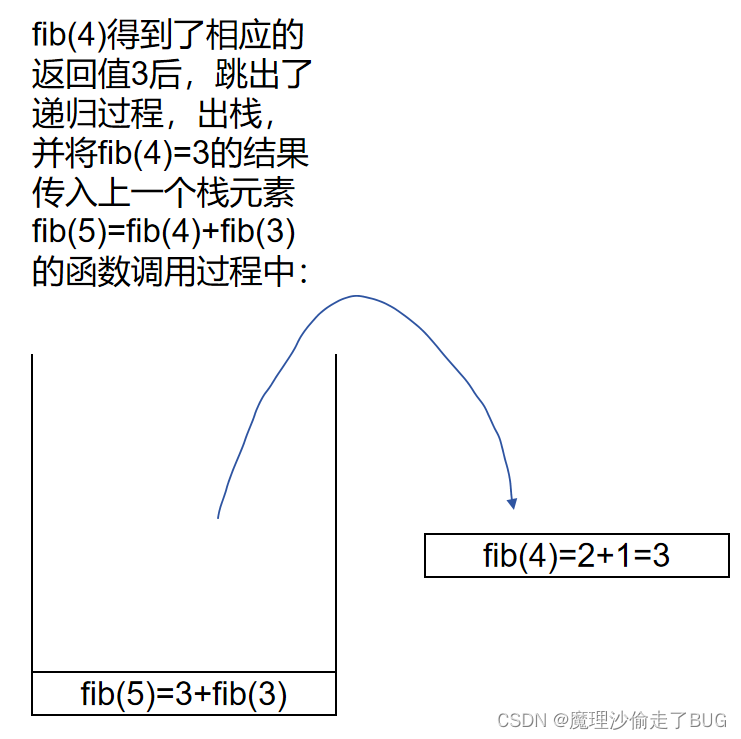
fib(3)進棧:

fib(2)進棧:

fib(2)出棧:
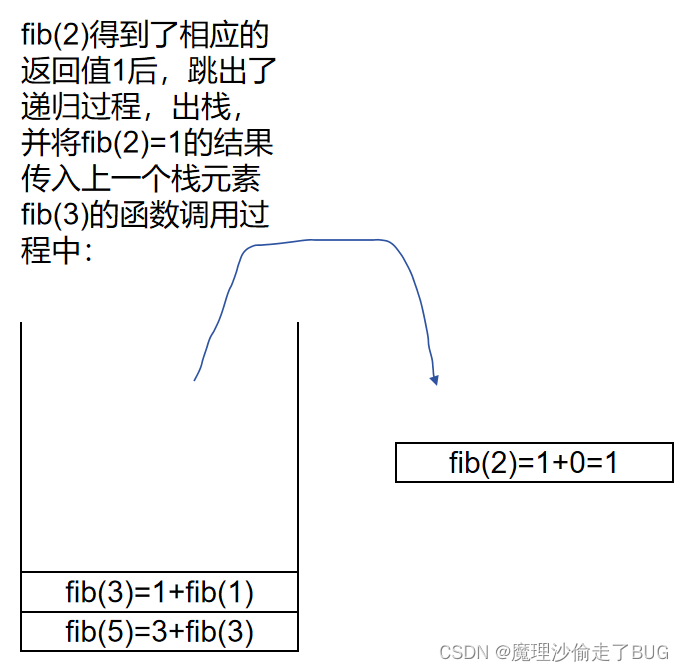
fib(3)出棧:
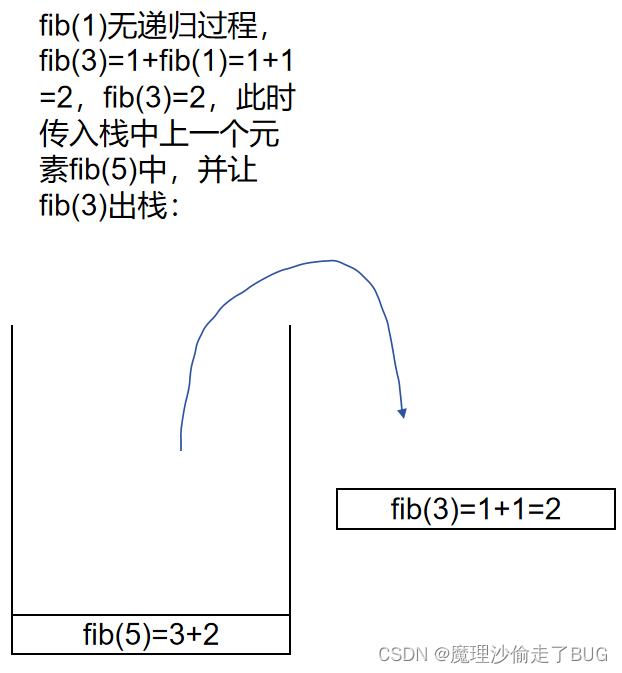
fib(5)出棧:
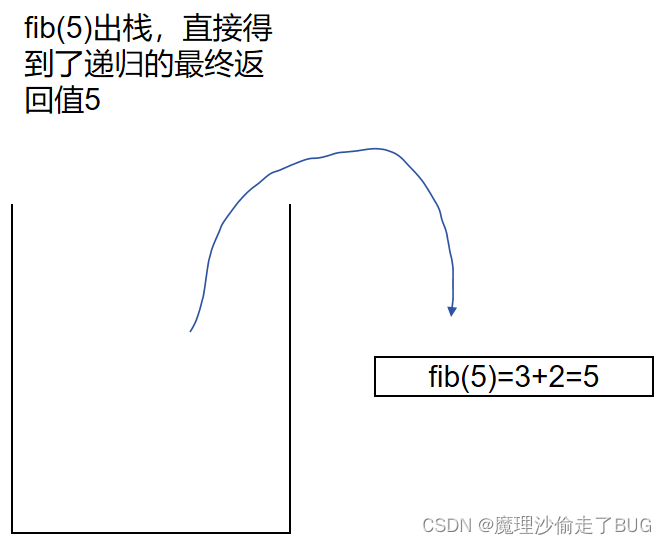
到此,我們來觀察一下,我們發現,占用棧內存最多的是這種情況:
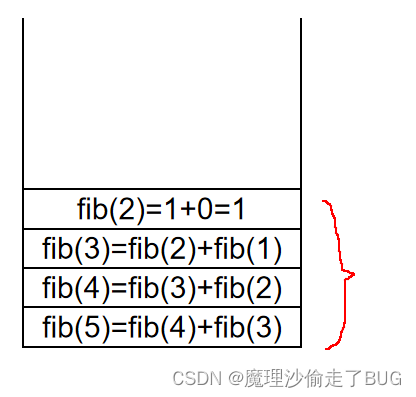
輸入規模為 N = 5 N=5 N=5占用了 O ( 4 ) O(4) O(4)的空間復雜度,經過數學歸納法推理得知,輸入規模為 N N N時,空間復雜度為 O ( N ? 1 ) = O ( N ) O(N-1)=O(N) O(N?1)=O(N)
接下來我們探究一下時間復雜度,其實遞歸函數完全對應著時間復雜度函數 T ( N ) T(N) T(N)的遞推過程,即 T ( N ) = T ( N ? 1 ) + T ( N ? 2 ) , T ( 0 ) = 0 , T ( 1 ) = 1 T(N)=T(N-1)+T(N-2), T(0)=0, T(1)=1 T(N)=T(N?1)+T(N?2),T(0)=0,T(1)=1,亦即 T ( N ) ? T ( N ? 1 ) ? T ( N ? 2 ) = 0 T(N)-T(N-1)-T(N-2)=0 T(N)?T(N?1)?T(N?2)=0,這個方程恰好是二階齊次線性差分方程,其特征方程為 x 2 ? x ? 1 = 0 x^{2}-x-1=0 x2?x?1=0,特征根為 x 1 = 1 + 1 + 4 2 = 1 + 5 2 x_{1}=\frac{1+ \sqrt{1+4}}{2}=\frac{1+\sqrt{5}}{2} x1?=21+1+4??=21+5??, x 2 = 1 ? 1 + 4 2 = 1 ? 5 2 x_{2}=\frac{1- \sqrt{1+4}}{2}=\frac{1-\sqrt{5}}{2} x2?=21?1+4??=21?5??,即有兩個不等的特征實根,則方程通解為 T ˉ ( n ) = C 1 ( 1 + 5 2 ) n + C 2 ( 1 ? 5 2 ) n , C 1 , C 2 為任意常數? \bar{T}(n)=C_{1}\left(\frac{1+\sqrt{5}}{2}\right)^{n}+C_{2}\left(\frac{1-\sqrt{5}}{2}\right)^{n}, C_{1}, C_{2} \text { 為任意常數 } Tˉ(n)=C1?(21+5??)n+C2?(21?5??)n,C1?,C2??為任意常數?,由于 T ( 0 ) = 0 , T ( 1 ) = 1 T(0)=0,T(1)=1 T(0)=0,T(1)=1,即
{ T ˉ ( 0 ) = C 1 + C 2 = 0 T ˉ ( 1 ) = C 1 ( 1 + 5 2 ) + C 2 ( 1 ? 5 2 ) = 1 \left\{\begin{array}{l} \bar{T}(0)=C_{1}+C_{2}=0 \\ \bar{T}(1)=C_{1}\left(\frac{1+\sqrt{5}}{2}\right)+C_{2}\left(\frac{1-\sqrt{5}}{2}\right)=1 \end{array}\right. {Tˉ(0)=C1?+C2?=0Tˉ(1)=C1?(21+5??)+C2?(21?5??)=1?
求得 C 1 = 5 5 , C 2 = ? 5 5 C_{1}=\frac{\sqrt{5}}{5},C_{2}=-\frac{\sqrt{5}}{5} C1?=55??,C2?=?55??
所以原時間復雜度函數為 T ( n ) = 5 5 ( ( 1 + 5 2 ) n ? ( 1 ? 5 2 ) n ) {T}(n)=\frac{\sqrt{5}}{5}\left(\left(\frac{1+\sqrt{5}}{2}\right)^{n}-\left(\frac{1-\sqrt{5}}{2}\right)^{n}\right) T(n)=55??((21+5??)n?(21?5??)n),所以時間復雜度為 O ( ( 1 + 5 2 ) n ? ( 1 ? 5 2 ) n ) O\left(\left(\frac{1+\sqrt{5}}{2}\right)^{n}-\left(\frac{1-\sqrt{5}}{2}\right)^{n}\right) O((21+5??)n?(21?5??)n)
當 n → ∞ n\to \infty n→∞時,由于 ∣ 1 + 5 2 ∣ > 1 , ∣ 1 ? 5 2 ∣ < 1 |\frac{1+\sqrt{5}}{2}|>1,|\frac{1-\sqrt{5}}{2}|<1 ∣21+5??∣>1,∣21?5??∣<1,
所以 lim ? n → ∞ ( 1 + 5 2 ) n = ∞ , lim ? n → ∞ ( 1 ? 5 2 ) n = 0 \lim\limits_{n \to \infty} \left(\frac{1+\sqrt{5}}{2}\right)^{n}=\infty ,\lim\limits_{n \to \infty} \left(\frac{1-\sqrt{5}}{2}\right)^{n}=0 n→∞lim?(21+5??)n=∞,n→∞lim?(21?5??)n=0
所以,最終的時間復雜度為 O ( ( 1 + 5 2 ) n ) O\left(\left(\frac{1+\sqrt{5}}{2}\right)^{n}\right) O((21+5??)n)
這玩意的時間復雜度是指數爆炸級別的,遠大于 O ( n k ) , k > 0 O(n^{k}),k>0 O(nk),k>0
【注】關于 lim ? n → ∞ ( 1 ? 5 2 ) n = 0 \lim\limits_{n \to \infty} \left(\frac{1-\sqrt{5}}{2}\right)^{n}=0 n→∞lim?(21?5??)n=0的證明,這里引用一下蘇德礦高等數學第三版中的證明:

【拓展】這個斐波那契數列還有一個循環的版本,我們來分析一下循環版本的復雜度:
循環版本應該寫成如下C語言代碼:
int fib(int n){//當n=0時if(n==0){return 0;}//當n=1時if(n==1){return 1;}//當n=2時int fn_1=1; //n-1為1int fn_2=0; //n-2為0int fn_1_2_sum = fn_1 + fn_2; //f(n-1)+f(n-2)為結果//當n>2即n>=3時for(int i = 3; i <= n ; i++){//f(n-1)與f(n-2)都各自往前移動一項fn_2 = fn_1;fn_1 = fn_1_2_sum ;fn_1_2_sum = fn_1 + fn_2;}return fn_1_2_sum ;
}
全程就用了3個變量,相當于空間復雜度是 O ( 3 ) O(3) O(3),也就是常數級的空間復雜度,最終空間復雜度為 O ( 1 ) O(1) O(1),一個for循環,循環變量i從3遍歷到n,時間復雜度為 O ( n ? 3 ) = O ( n ) O(n-3)=O(n) O(n?3)=O(n)
1.3 試分析下面一段代碼的時間復雜度:
if(A>B){for(i=0;i<N;i++)for(j=N*N;j>i;j--)A+=B;
}
else{for(i=0;i<N*2;i++)for(j=N*2;j>i;j--)A+=B;
}
【答】如果進入if條件,那么最外層循環最多執行N次,內層循環中,當i=0時,j自減的最多,j從 N 2 N^{2} N2開始自減,一直自減到j為1時,就停止自減了,因為j減少到0時,j>i這個條件不滿足,無法進入內層循環,則內層循環最多執行 N 2 ? 1 N^{2}-1 N2?1,則if條件下的時間復雜度為 O if ( N ( N 2 ? 1 ) ) = O if ( N 3 ? N ) = O if ( N 3 ) O_{\text{if}}(N(N^{2}-1))=O_{\text{if}}(N^{3}-N)=O_{\text{if}}(N^{3}) Oif?(N(N2?1))=Oif?(N3?N)=Oif?(N3)
再看else條件下,外層循環,i從0開始自增到2N-1的時候執行次數最多,即外層循環最多執行 2 N ? 1 2N-1 2N?1次,內層循環,j從 2 N 2N 2N開始自減,當i=0時自減次數最多,自減到1,則內層循環最多執行 2 N ? 1 2N-1 2N?1次,則else條件下的時間復雜度為 O else ( ( 2 N ? 1 ) ( 2 N ? 1 ) ) = O else ( 4 N 2 ? 4 N + 1 ) = O else ( N 2 ) O_{\text{else}}((2N-1)(2N-1))=O_{\text{else}}(4N^{2}-4N+1)=O_{\text{else}}(N^{2}) Oelse?((2N?1)(2N?1))=Oelse?(4N2?4N+1)=Oelse?(N2)
所以總的時間復雜度為 T ( n ) = max { O if ( N 3 ) , O else ( N 2 ) } = O ( N 3 ) T(n)=\text{max}\{O_{\text{if}}(N^{3}),O_{\text{else}}(N^{2})\}=O(N^{3}) T(n)=max{Oif?(N3),Oelse?(N2)}=O(N3)
1.4 分析例1.2中兩個版本的PrintN函數的時間、空間復雜度,并測試它們的實際運行效率。對N=100, 1000, 10000, 100000運行程序,將兩版本的N-時間曲線繪在一張圖里進行比較分析。
#include <stdio.h>// 循環打印1到N的全部整數
void CirPrintN(int N)
{int i = 0;for(i = 1; i<=N; i++){printf("%d\n", i);}
}
// 遞歸打印1到N的全部整數
void RecPrintN(int N)
{if(N>0){RecPrintN(N-1);printf("%d\n", N);}
}int main()
{int N = 0;scanf("%d", &N);CirPrintN(N);return 0;
}【答】第一個循環版本PrintN只有一層for循環,從1打印到N,循環版本PrintN的時間復雜度為 O ( N ) O(N) O(N),遞歸版本的PrintN也是打印N次,可以直接看出遞歸了N次,則遞歸版本PrintN的時間復雜度為 O ( N ) O(N) O(N),對于循環版本PrintN,我們看到,只用了一個變量i存儲,空間復雜度為 O ( 1 ) O(1) O(1),對于遞歸版本的PrintN,我們能想象到函數調用棧這樣一個情況,等到RecPrint(1)入棧后(此時函數調用棧中有RecPrint(N)到RecPrint(2)所有的遞歸調用過程)才會依次出棧,此時可以看出,空間復雜度為 O ( n ) O(n) O(n),這個也可以取一個具體的N然后畫圖說明,類似1.2題(2)。
然后我們用之前提到的【數據結構陳越版筆記】第1章 概論C語言中的計時工具對兩種方法進行計時,代碼如下:
#include <stdio.h>
#include <time.h>
#include <math.h>clock_t start = 0; //開始時間
clock_t stop = 0; //結束時間
double duration = 0.0; //算法一共運行了多長時間#define MAXN 100 // 打印的最大整數N
#define MAXK 1 // 被測函數最大重復調用次數// 循環打印1到N的全部整數
void CirPrintN(int N)
{int i = 0;for (i = 1; i <= N; i++){printf("%d\n", i);}
}
// 遞歸打印1到N的全部整數
void RecPrintN(int N)
{if (N > 0){RecPrintN(N - 1);printf("%d\n", N);}
}// 此函數用于測試被測函數*f,并且根據case_n輸出相應的結果
// case_n是輸出的函數編號:1代表函數f1;2代表函數f2
void run(void (*f)(int), int case_n)
{int i = 0;start = clock();//重復調用函數以獲得充分多的時鐘打點數for (i = 0; i < MAXK; i++) // 調用MAXK次{(*f)(MAXN);}stop = clock();duration = ((double)(stop - start)) / CLK_TCK; // 轉換為秒數printf("ticks%d= %f \n", case_n, (double)(stop - start));printf("duration%d = % 6.2e \n", case_n, duration);
}int main()
{run(CirPrintN,1);run(RecPrintN,2);return 0;
}經過運行代碼,得知(每個人機器跑出的結果應該是不太一樣的)
當 N = 100 N=100 N=100時,循環法運行了 2 × 1 0 ? 3 s 2\times10^{-3}\text{s} 2×10?3s,遞歸法運行了了 3 × 1 0 ? 3 s 3\times10^{-3}\text{s} 3×10?3s;
當 N = 1000 N=1000 N=1000時,循環法運行了 2.4 × 1 0 ? 2 s 2.4\times10^{-2}\text{s} 2.4×10?2s,遞歸法運行了了 2.4 × 1 0 ? 2 s 2.4\times10^{-2}\text{s} 2.4×10?2s;
當 N = 10000 N=10000 N=10000時,循環法運行了 2.7 × 1 0 ? 1 s 2.7\times10^{-1}\text{s} 2.7×10?1s,遞歸法出現了函數調用棧溢出錯誤;
當 N = 10000 = N=10000= N=10000=時,循環法運行了 2.42 s 2.42\text{s} 2.42s,遞歸法出現了函數調用棧溢出錯誤;
我們用N從1到3500,步長為1,對兩種算法進行N和運行時間的取值,然后結果保存成csv文件(1.csv是循環法的數據,2.csv是遞歸法的數據,均保存在根目錄中),再用Python matplotlib畫圖(我目前只會用matplotlib畫圖),取N最大為3500是,再取大一些,會出現函數調用棧溢出情況,這樣修改后的C語言代碼如下:
#include <stdio.h>
#include <time.h>
#include <math.h>
#include <stdlib.h>
#include <string.h>//N與運行時間的數據寫入CSV文件,id為1指代循環法,id為2指代遞歸法
void WriteToCsv(int id, int N, long double duration)
{FILE* fp = NULL;if (id == 1){fp = fopen("1.csv", "a+"); //在文件末尾繼續寫入新數據,而不是覆蓋}else{fp = fopen("2.csv", "a+"); }if (fp == NULL) {fprintf(stderr, "fopen() failed.\n");exit(EXIT_FAILURE);}fprintf(fp, "%d,%.18Lf\n", N, duration); //保存18位小數,具體情況視機器的情況而定fclose(fp);
}clock_t start = 0; //開始時間
clock_t stop = 0; //結束時間
long double duration = 0.0; //算法一共運行了多長時間#define MAXN 3500 // N從1測試到3500,實測我電腦3993開始遞歸的函數調用棧溢出,為了保險測試到3500
#define MAXK 1 // 被測函數最大重復調用次數// 循環打印1到N的全部整數
void CirPrintN(int N)
{int i = 0;for (i = 1; i <= N; i++){printf("%d\n", i);}
}
// 遞歸打印1到N的全部整數
void RecPrintN(int N)
{if (N > 0){RecPrintN(N - 1);printf("%d\n", N);}
}// 此函數用于測試被測函數*f,并且根據case_n輸出相應的結果
// case_n是輸出的函數編號:1代表函數f1;2代表函數f2
void run(void (*f)(int), int case_n)
{//從1到MAXN傳參for (int i = 1; i <= MAXN; i++){start = clock();(*f)(i);stop = clock();duration = ((long double)(stop - start)) / CLK_TCK; // 轉換為秒數printf("ticks%d= %Lf \n", case_n, (long double)(stop - start));printf("duration%d = % 6.2e \n", case_n, duration);WriteToCsv(case_n, i, duration); //將N和運行時間寫入csv文件}
}int main()
{run(CirPrintN, 1);run(RecPrintN, 2);return 0;
}
Python繪圖代碼如下(需要pandas和matplotlib庫):
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['font.family'] = 'SimHei' # 設置中文字體# 讀取CSV文件
df1 = pd.read_csv('1.csv')
df2 = pd.read_csv('2.csv')# 繪制折線圖
plt.figure(figsize=(10, 5)) # 設置圖的大小# 繪制1.csv的數據
plt.plot(df1['N'], df1['duration'], color='red', marker='^', label='循環法PrintN折線') # 紅色線條,三角標記# 繪制2.csv的數據
plt.plot(df2['N'], df2['duration'], color='blue', marker='o', label='遞歸法PrintN折線') # 藍色線條,圓圈標記plt.title('PrintN函數N-運行時間折線圖') # 設置圖標題
plt.xlabel('N') # 設置x軸標簽
plt.ylabel('運行時間:s') # 設置y軸標簽
plt.grid(True) # 顯示網格
plt.legend() # 顯示圖例
plt.show() # 顯示圖形
最后將兩個算法的N和運行時間繪制折線圖到一張圖上:
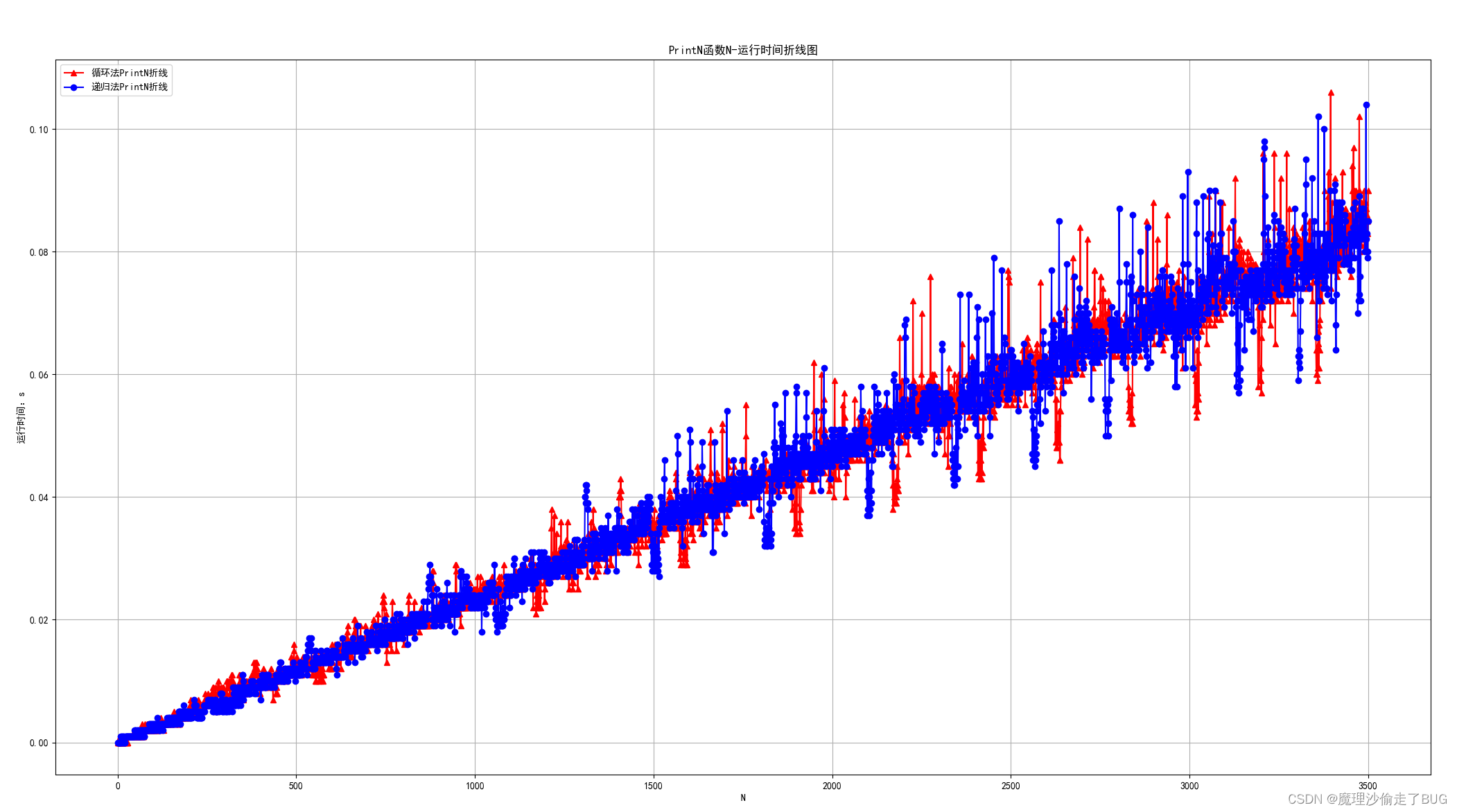
可以看到,時間差不多,畢竟都是O(n)復雜度的算法。
1.5 測試例1.3中秦九韶算法與直接法的效率差別。令 f ( x ) = 1 + ∑ i = 1 100 x i / i f(x)=1+\sum\limits_{i=1}^{100} x^{i} / i f(x)=1+i=1∑100?xi/i,計算 f ( 1.1 ) f(1.1) f(1.1)的值。利用clock()函數得到兩種算法在同一機器的運行時間。
【答】將之前的代碼(詳見【數據結構陳越版筆記】第1章 概論)魔改成:
#include <stdio.h>
#include <time.h>
#include <math.h>clock_t start = 0; //開始時間
clock_t stop = 0; //結束時間
double duration = 0.0; //算法一共運行了多長時間#define MAXN 10 // 多項式最大項數,即多項式階數+1
#define MAXK 1e7 // 被測函數最大重復調用次數// n為多項式的項數,a數組存儲的是多項式各系數
//普通的循環法求多項式的和
double f1(int n, double a[], double x)
{int i = 0;double p = a[0];for (i = 1; i <= n; i++){p += (a[i] * pow(x, i));}return p;
}//秦九韶法求多項式的和
double f2(int n, double a[], double x)
{int i = 0;double p = a[n];for (i = n; i > 0; i--){p = a[i - 1] + x * p; //從最里面的括號開始算}return p;
}// 此函數用于測試被測函數*f,并且根據case_n輸出相應的結果
// case_n是輸出的函數編號:1代表函數f1;2代表函數f2
void run(double (*f)(int, double*, double), double a[], int case_n)
{int i = 0;start = clock();//重復調用函數以獲得充分多的時鐘打點數for (i = 0; i < MAXK; i++) // 調用MAXK次{(*f)(MAXN - 1, a, 1.1);}stop = clock();duration = ((double)(stop - start)) / CLK_TCK; // 轉換為秒數printf("ticks%d= %f \n", case_n, (double)(stop - start));printf("duration%d = % 6.2e \n", case_n, duration);
}int main()
{int i = 0;double a[MAXN]; //系數數組for (i = 0; i < MAXN; i++){a[i] = 1.0/(double)i;//系數這兒改動一下}run(f1, a, 1);run(f2, a, 2);return 0;
}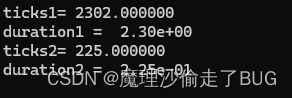
普通循環法求多項式是2.3s,而秦九韶法只需要 2.25 × 1 0 ? 1 s 2.25\times10^{-1}\text{s} 2.25×10?1s
1.6 試分析最大子列和算法1.3的空間復雜度。
【答】最大子列和算法1.3的代碼:
// 比較三個數中最大數的宏定義
#define MAX3(A, B, C) (( A > B ? A : B) > C) ? ( A > B ? A : B) : C// 分治法遞歸求最大子列和
int DivideAndConquer(int* List, int left, int right)
{int MaxLeftSum = INT_MIN; // 左子列的最大和int MaxRightSum = INT_MIN; // 右子列的最大和int MaxLeftBorderSum = INT_MIN; //跨越中點的子列的左側的和int MaxRightBorderSum = INT_MIN; //跨越中點的子列的右側的和int LeftBorderSum = 0; //跨越中點的子列的左側的和(不一定是最大的)int RightBorderSum = 0; //跨越中點的子列的右側的和int middle = 0; //分治法求分界點的變量s// left與right重合時,遞歸停止,也就是子列只有一個數字// 這是最小的子列,其和就是這一個元素,如果它的和// 也就是這一個元素為負數或者0,則應該返回0(根據題意)// 如果是LeetCode53,則應該直接返回List[left],不需要加判斷條件// 因為LeetCode53是需要對比負數和的if(left == right){if(List[left] > 0){return List[left];}else{return 0;}}// 求解中點,向右移動一位相當于除2middle = (right + left)>>1; // 此處也可以等價成(right - left)/2 + left,但是這樣寫會超時//遞歸求解左子列和右子列的最大和MaxLeftSum = DivideAndConquer(List, left, middle);MaxRightSum = DivideAndConquer(List, middle + 1, right);//求跨越中點的子列的最大和MaxLeftBorderSum = INT_MIN; //每次求和之前,要將最大值變為無窮小,方便比較LeftBorderSum = 0;//找跨越中點的子列的左側的最大和(從中點向左遍歷)for(int i = middle; i>=left; i--){LeftBorderSum += List[i];if(LeftBorderSum > MaxLeftBorderSum){MaxLeftBorderSum = LeftBorderSum;}}//找跨越中點的子列的右側的最大和(從中點向右遍歷)MaxRightBorderSum = INT_MIN; //每次求和之前,要將最大值變為無窮小,方便比較RightBorderSum = 0;for(int i = middle + 1; i<=right; i++){RightBorderSum += List[i];if(RightBorderSum > MaxRightBorderSum){MaxRightBorderSum = RightBorderSum;}}// 返回左子列,跨越中點的子列和右子列三者中的最大值return MAX3(MaxLeftSum, MaxLeftBorderSum + MaxRightBorderSum, MaxRightSum);
}
int maxSubArray(int* List, int N) {return DivideAndConquer(List, 0, N-1);
}卡卡!我們還是畫圖吧,不畫圖硬推太難了:
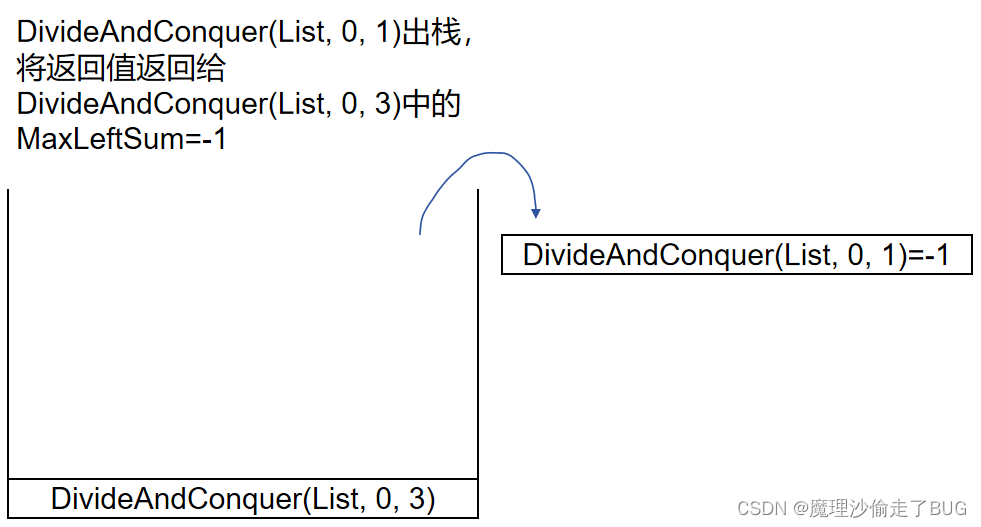
假設存在這樣一個數組[-1,-2,0],求其最大子列和,下面畫出其函數調用棧的圖:
第1步:

第2步:

第3步:

第4步:

第5步:

第6步:

第7步:

第8步:
第9步:

第10步:
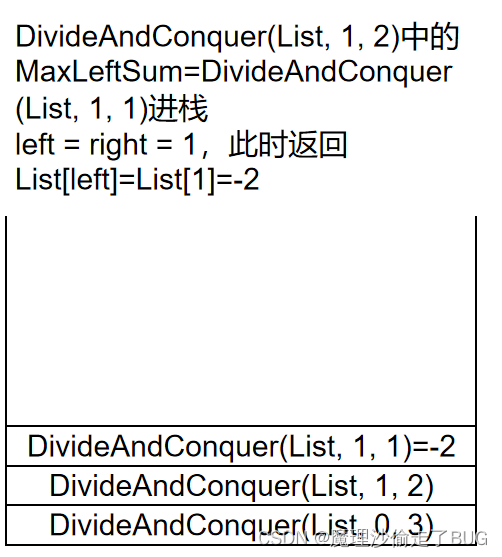
第11步:

第12步:

第13步:

第14步:

第15步:

第16步:

第17步:
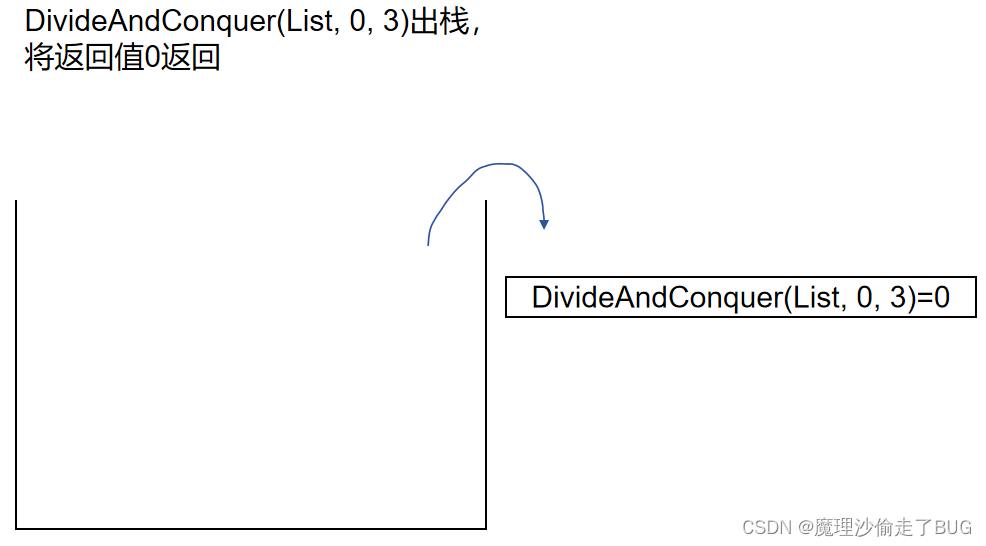
可以看到,函數調用棧最深的時候有三個遞歸過程,恰好對應3個元素,所以其空間復雜度應為 O ( N ) O(N) O(N)
1.7 測試最大子列和4種算法的實際運行效率。簡單起見,可令List中全部整數位1。當N=2, 4, 6, 8, 10, …, 28, 30時,將各算法的N-時間曲線繪在一張圖上,其中時間以毫秒為單位:當N=1000, 2000, …, 10000時,以秒為單位繪出各算法的時間增長曲線。兩幅圖有什么不同?為什么?
【答】4種算法的代碼如下:
時間復雜度為 O ( N 3 ) O(N^{3}) O(N3)的暴力法:
#include <stdio.h>//暴力法
int MaxSubseqSum1(int List[], int N)
{int ThisSum = 0; //當前子列的和int MaxSum = 0; //最大子列和,默認賦值為0,如果和為負數,就只能返回0//i是子列左端位置for (int i = 0; i < N; i++){//j是子列右端位置for (int j = i; j < N; j++){ThisSum = 0;// 把子列和(從List[i]加到List[j])加一起for (int k = i; k <= j; k++){ThisSum += List[k];}// 如果當前和超過之前的最大和,則最大和賦值成這個if (ThisSum > MaxSum){MaxSum = ThisSum;}}}return MaxSum;
}
時間復雜度為 O ( N 2 ) O(N^{2}) O(N2)的暴力法:
#include <stdio.h>//暴力法2
int MaxSubseqSum2(int List[], int N)
{int ThisSum = 0; //當前子列的和int MaxSum = 0; //最大子列和,默認賦值為0,如果和為負數,就只能返回0//i是子列左端位置for (int i = 0; i < N; i++){ThisSum = 0; // ThisSum清零的工作就放到了j這個循環的外層//j是子列右端位置for (int j = i; j < N; j++){ThisSum += List[j];// 如果當前和超過之前的最大和,則最大和賦值成這個if (ThisSum > MaxSum){MaxSum = ThisSum;}}}return MaxSum;
}
時間復雜度為 O ( N log N ) O(N\text{log}N) O(NlogN)的分治法:
// 比較三個數中最大數的宏定義
#define MAX3(A, B, C) (( A > B ? A : B) > C) ? ( A > B ? A : B) : C// 分治法遞歸求最大子列和
int DivideAndConquer(int* List, int left, int right)
{int MaxLeftSum = INT_MIN; // 左子列的最大和int MaxRightSum = INT_MIN; // 右子列的最大和int MaxLeftBorderSum = INT_MIN; //跨越中點的子列的左側的和int MaxRightBorderSum = INT_MIN; //跨越中點的子列的右側的和int LeftBorderSum = 0; //跨越中點的子列的左側的和(不一定是最大的)int RightBorderSum = 0; //跨越中點的子列的右側的和int middle = 0; //分治法求分界點的變量s// left與right重合時,遞歸停止,也就是子列只有一個數字// 這是最小的子列,其和就是這一個元素,如果它的和// 也就是這一個元素為負數或者0,則應該返回0(根據題意)// 如果是LeetCode53,則應該直接返回List[left],不需要加判斷條件// 因為LeetCode53是需要對比負數和的if(left == right){if(List[left] > 0){return List[left];}else{return 0;}}// 求解中點,向右移動一位相當于除2middle = (right + left)>>1; // 此處也可以等價成(right - left)/2 + left,但是這樣寫會超時//遞歸求解左子列和右子列的最大和MaxLeftSum = DivideAndConquer(List, left, middle);MaxRightSum = DivideAndConquer(List, middle + 1, right);//求跨越中點的子列的最大和MaxLeftBorderSum = INT_MIN; //每次求和之前,要將最大值變為無窮小,方便比較LeftBorderSum = 0;//找跨越中點的子列的左側的最大和(從中點向左遍歷)for(int i = middle; i>=left; i--){LeftBorderSum += List[i];if(LeftBorderSum > MaxLeftBorderSum){MaxLeftBorderSum = LeftBorderSum;}}//找跨越中點的子列的右側的最大和(從中點向右遍歷)MaxRightBorderSum = INT_MIN; //每次求和之前,要將最大值變為無窮小,方便比較RightBorderSum = 0;for(int i = middle + 1; i<=right; i++){RightBorderSum += List[i];if(RightBorderSum > MaxRightBorderSum){MaxRightBorderSum = RightBorderSum;}}// 返回左子列,跨越中點的子列和右子列三者中的最大值return MAX3(MaxLeftSum, MaxLeftBorderSum + MaxRightBorderSum, MaxRightSum);
}
int maxSubArray(int* List, int N) {return DivideAndConquer(List, 0, N-1);
}
時間復雜度為 O ( N ) O(N) O(N)的在線處理(動態規劃)法:
int maxSubArray(int* nums, int numsSize){int result=0;//最開始假定最大值為0,因為這個題目要求的是負數和算為0,如果和LeetCode53一樣需要負數和,此處應設置為INT_MINint count =0;//子數組的求和結果for(int i=0;i<numsSize;i++){count = count + nums[i];//count大于假定的最大值,就讓假定的最大值等于countif(count > result){result = count;}//加和小于等于0,則其不是最大連續子序列,讓count從0開始加//如果加和變成負數,說明從nums[i]開始向前到nums[0]的數無論怎么取連續子數組都只能小于等于result//result記錄的是nums[i]之前的數字的最大連續子數組的和//所以,就沒必要再回到前面去找加和了,直接從nums[i]向后加和對比//如果從nums[i]開始到最后的加和中出現了加和大于nums[i]之前的最大連續子數組的和result//那就讓result賦值為nums[i]后面的最大連續子數組的和的值//這樣就找到了最大連續子數組的和if(count<0){count =0;}}return result;
}
魔改一下計時的那個代碼如下:
#include <stdio.h>
#include <time.h>
#include <math.h>
#include <stdlib.h>
#include <string.h>//N與運行時間的數據寫入CSV文件
//1指的是時間復雜度為O(N^3)的暴力法
//2指的是時間復雜度為O(N^2)的暴力法
//3指的是時間復雜度為O(NlogN)的分治法
//4指的是時間復雜度為O(N)的在線處理(動態規劃)法
void WriteToCsv(int id, int N, long double duration)
{FILE* fp = NULL;switch (id){case 1:fp = fopen("1.csv", "a+");break;case 2:fp = fopen("2.csv", "a+");break;case 3:fp = fopen("3.csv", "a+");break;case 4:fp = fopen("4.csv", "a+");break;default:fprintf(stderr, "fopen() failed.\n");exit(EXIT_FAILURE);}if (fp == NULL) {fprintf(stderr, "fopen() failed.\n");exit(EXIT_FAILURE);}fprintf(fp, "%d,%.18Lf\n", N, duration); //保存18位小數,具體情況視機器的情況而定fclose(fp);
}clock_t start = 0; //開始時間
clock_t stop = 0; //結束時間
long double duration = 0.0; //算法一共運行了多長時間#define MAXN 30 // 最多測試到長度為30的全為1的數組//時間復雜度為O(N^3)的暴力法
int MaxSubseqSum1(int* List, int N)
{int ThisSum = 0; //當前子列的和int MaxSum = 0; //最大子列和,默認賦值為0,如果和為負數,就只能返回0//i是子列左端位置for (int i = 0; i < N; i++){//j是子列右端位置for (int j = i; j < N; j++){ThisSum = 0;// 把子列和(從List[i]加到List[j])加一起for (int k = i; k <= j; k++){ThisSum += List[k];}// 如果當前和超過之前的最大和,則最大和賦值成這個if (ThisSum > MaxSum){MaxSum = ThisSum;}}}return MaxSum;
}//時間復雜度為O(N^2)的暴力法
int MaxSubseqSum2(int* List, int N)
{int ThisSum = 0; //當前子列的和int MaxSum = 0; //最大子列和,默認賦值為0,如果和為負數,就只能返回0//i是子列左端位置for (int i = 0; i < N; i++){ThisSum = 0; // ThisSum清零的工作就放到了j這個循環的外層//j是子列右端位置for (int j = i; j < N; j++){ThisSum += List[j];// 如果當前和超過之前的最大和,則最大和賦值成這個if (ThisSum > MaxSum){MaxSum = ThisSum;}}}return MaxSum;
}//時間復雜度為O(NlogN)的分治法
// 比較三個數中最大數的宏定義
#define MAX3(A, B, C) (( A > B ? A : B) > C) ? ( A > B ? A : B) : C// 分治法遞歸求最大子列和
int DivideAndConquer(int* List, int left, int right)
{int MaxLeftSum = INT_MIN; // 左子列的最大和int MaxRightSum = INT_MIN; // 右子列的最大和int MaxLeftBorderSum = INT_MIN; //跨越中點的子列的左側的和int MaxRightBorderSum = INT_MIN; //跨越中點的子列的右側的和int LeftBorderSum = 0; //跨越中點的子列的左側的和(不一定是最大的)int RightBorderSum = 0; //跨越中點的子列的右側的和int middle = 0; //分治法求分界點的變量s// left與right重合時,遞歸停止,也就是子列只有一個數字// 這是最小的子列,其和就是這一個元素,如果它的和// 也就是這一個元素為負數或者0,則應該返回0(根據題意)// 如果是LeetCode53,則應該直接返回List[left],不需要加判斷條件// 因為LeetCode53是需要對比負數和的if (left == right){if (List[left] > 0){return List[left];}else{return 0;}}// 求解中點,向右移動一位相當于除2middle = (right + left) >> 1; // 此處也可以等價成(right - left)/2 + left,但是這樣寫會超時//遞歸求解左子列和右子列的最大和MaxLeftSum = DivideAndConquer(List, left, middle);MaxRightSum = DivideAndConquer(List, middle + 1, right);//求跨越中點的子列的最大和MaxLeftBorderSum = INT_MIN; //每次求和之前,要將最大值變為無窮小,方便比較LeftBorderSum = 0;//找跨越中點的子列的左側的最大和(從中點向左遍歷)for (int i = middle; i >= left; i--){LeftBorderSum += List[i];if (LeftBorderSum > MaxLeftBorderSum){MaxLeftBorderSum = LeftBorderSum;}}//找跨越中點的子列的右側的最大和(從中點向右遍歷)MaxRightBorderSum = INT_MIN; //每次求和之前,要將最大值變為無窮小,方便比較RightBorderSum = 0;for (int i = middle + 1; i <= right; i++){RightBorderSum += List[i];if (RightBorderSum > MaxRightBorderSum){MaxRightBorderSum = RightBorderSum;}}// 返回左子列,跨越中點的子列和右子列三者中的最大值return MAX3(MaxLeftSum, MaxLeftBorderSum + MaxRightBorderSum, MaxRightSum);
}
int MaxSubseqSum3(int* List, int N) {return DivideAndConquer(List, 0, N - 1);
}//時間復雜度為O(N)的在線處理(動態規劃)法
int MaxSubseqSum4(int* nums, int numsSize) {int result = 0;//最開始假定最大值為0,因為這個題目要求的是負數和算為0,如果和LeetCode53一樣需要負數和,此處應設置為INT_MINint count = 0;//子數組的求和結果for (int i = 0; i < numsSize; i++){count = count + nums[i];//count大于假定的最大值,就讓假定的最大值等于countif (count > result){result = count;}//加和小于等于0,則其不是最大連續子序列,讓count從0開始加//如果加和變成負數,說明從nums[i]開始向前到nums[0]的數無論怎么取連續子數組都只能小于等于result//result記錄的是nums[i]之前的數字的最大連續子數組的和//所以,就沒必要再回到前面去找加和了,直接從nums[i]向后加和對比//如果從nums[i]開始到最后的加和中出現了加和大于nums[i]之前的最大連續子數組的和result//那就讓result賦值為nums[i]后面的最大連續子數組的和的值//這樣就找到了最大連續子數組的和if (count < 0){count = 0;}}return result;
}//創建一個長度為N的全1序列
int* createOnes(int N)
{int* result = (int*)malloc(sizeof(int) * N);for (int i = 0; i < N; i++){result[i] = 1;}return result;
}// 此函數用于測試被測函數*f,并且根據case_n輸出相應的結果
// case_n是輸出的函數編號:
//1指的是時間復雜度為O(N^3)的暴力法
//2指的是時間復雜度為O(N^2)的暴力法
//3指的是時間復雜度為O(NlogN)的分治法
//4指的是時間復雜度為O(N)的在線處理(動態規劃)法
void run(int (*f)(int*, int), int case_n)
{//從2到MAXN,取偶數值生成全為1的數組然后計時對比for (int i = 2; i <= MAXN; i=i+2){int* arr = createOnes(i);start = clock();// 運行10^6次,讓時間明顯一些for (int j = 0; j <= 10e6; j++){(*f)(arr, i);}stop = clock();duration = ((long double)(stop - start)) / CLK_TCK; // 轉換為秒數printf("ticks%d= %Lf \n", case_n, (long double)(stop - start));printf("duration%d = % 6.2e \n", case_n, duration);WriteToCsv(case_n, i, duration); //將N和運行時間寫入csv文件}
}int main()
{run(MaxSubseqSum1, 1);run(MaxSubseqSum2, 2);run(MaxSubseqSum3, 3);run(MaxSubseqSum4, 4);return 0;
}
最后在根目錄生成了100000次運行的時間和N的關系的CSV文件,然后用以下Python腳本畫圖:
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['font.family'] = 'SimHei' # 設置中文字體# 讀取CSV文件
df1 = pd.read_csv('1.csv')
df2 = pd.read_csv('2.csv')
df3 = pd.read_csv('3.csv')
df4 = pd.read_csv('4.csv')# 還原真實數據,之前是用100000次取得時間,這次除回去,求得平均時間
df1['duration'] = df1['duration'] / 100000
df2['duration'] = df2['duration'] / 100000
df3['duration'] = df3['duration'] / 100000
df4['duration'] = df4['duration'] / 100000# 時間以ms為單位,再乘1000
df1['duration'] = df1['duration'] * 1000
df2['duration'] = df2['duration'] * 1000
df3['duration'] = df3['duration'] * 1000
df4['duration'] = df4['duration'] * 1000# 繪制折線圖
plt.figure(figsize=(10, 5)) # 設置圖的大小# 繪制1.csv的數據
plt.plot(df1['N'], df1['duration'], color='red', marker='^', label=r'時間復雜度為$O(N^{3})$的暴力法') # 紅色線條,三角標記# 繪制2.csv的數據
plt.plot(df2['N'], df2['duration'], color='blue', marker='o', label=r'時間復雜度為$O(N^{2})$的暴力法') # 藍色線條,圓圈標記# 繪制3.csv的數據
plt.plot(df3['N'], df3['duration'], color='green', marker='*', label=r'時間復雜度為$O(N\text{log}N)$的分治法') # 藍色線條,圓圈標記# 繪制4.csv的數據
plt.plot(df4['N'], df4['duration'], color='orange', marker='x', label=r'時間復雜度為$O(N)$的在線處理法') # 藍色線條,圓圈標記plt.title('N-運行時間折線圖') # 設置圖標題
plt.xlabel('N') # 設置x軸標簽
plt.ylabel('運行時間:ms') # 設置y軸標簽
plt.grid(True) # 顯示網格
plt.legend() # 顯示圖例
plt.show() # 顯示圖形
最后得到N-運行時間曲線圖為:
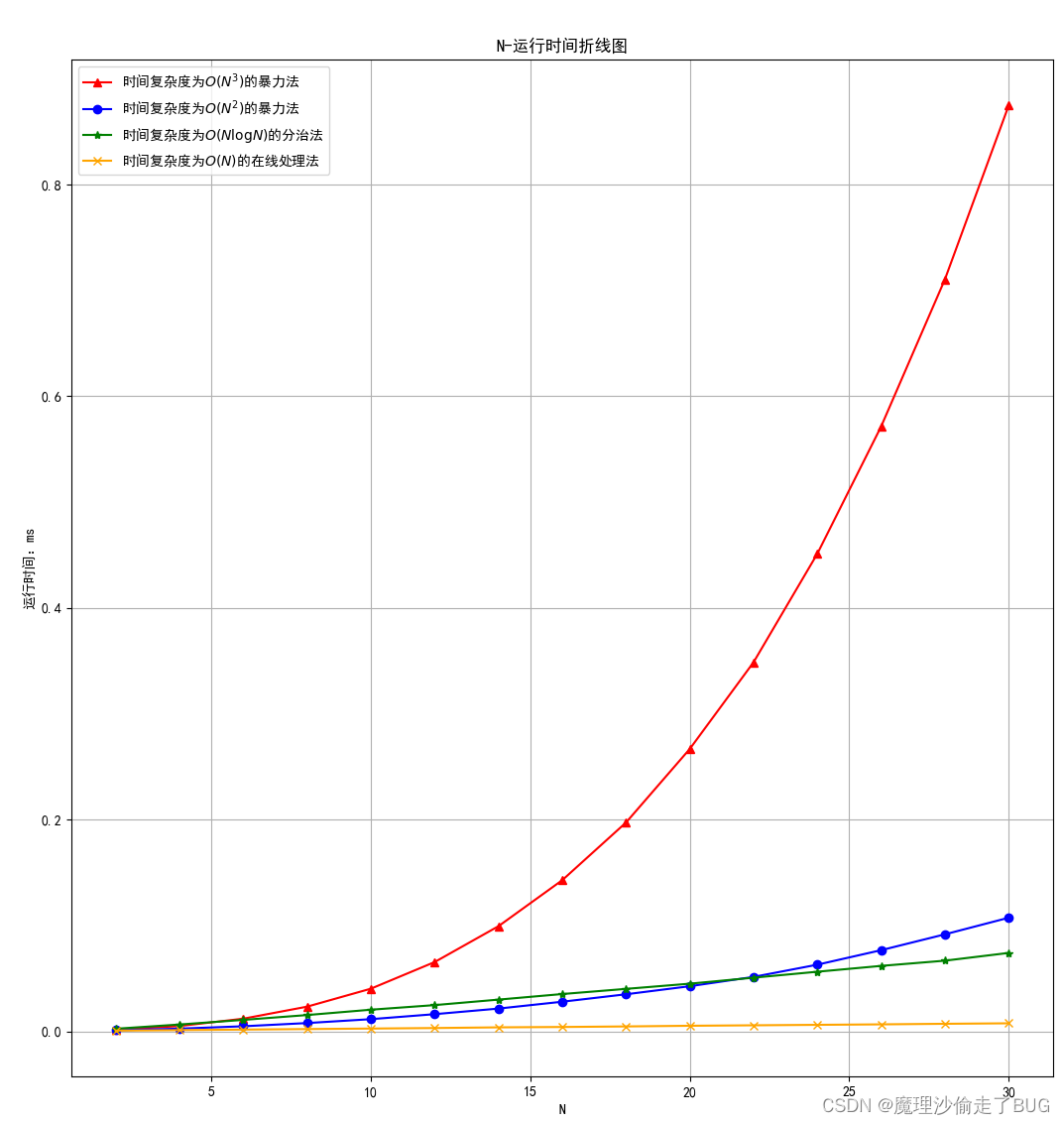
要繪制時間增長曲線圖(就是繪制時間復雜度函數的值),就要算一下當前四個算法在處理一個規模的問題需要多少秒,但是這樣很難捕捉,題目要求是從1000取到10000,步長為1000這樣寫,那我們就要求規模為1000的問題處理起來需要多少秒,對于暴力法直接正常求解,對于其他兩種方法,需要多次運行,運行100次再除100取平均,因為直接計算會是0s,精度不夠,于是將上面的run函數改為:
void run(int (*f)(int*, int), int case_n)
{int* arr = createOnes(1000);start = clock();if (case_n == 1 || case_n == 2){(*f)(arr, 1000);}else{for (int i = 0; i < 100; i++){(*f)(arr, 1000);}}stop = clock();duration = ((long double)(stop - start)) / CLK_TCK; // 轉換為秒數printf("ticks%d= %Lf \n", case_n, (long double)(stop - start));printf("duration%d = % 6.2e \n", case_n, duration);WriteToCsv(case_n, 1000, duration); //將N和運行時間寫入csv文件
}
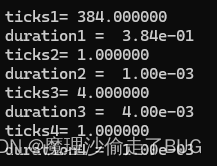
最后,暴力法1運行規模1000需要 3.84 × 1 0 ? 1 s 3.84\times10^{-1}\text{s} 3.84×10?1s,暴力法2運行規模1000需要 1 × 1 0 ? 3 s 1\times10^{-3}\text{s} 1×10?3s,分治法運行規模1000需要 4 × 1 0 ? 5 s 4\times10^{-5}\text{s} 4×10?5s,在線處理法運行規模1000需要 1 × 1 0 ? 5 s 1\times10^{-5}\text{s} 1×10?5s,因為每個機器的運行時間不一樣,所以我們分別設四種算法的真正的時間復雜度函數為 T 1 ( N ) = a N 3 , T 2 ( N ) = b N 2 , T 3 ( N ) = c N log N , T 4 ( N ) = d N , a , b , c , d 均為任意常數 T_{1}(N)=aN^{3},T_{2}(N)=bN^{2},T_{3}(N)=cN\text{log}N,T_{4}(N)=dN,a,b,c,d均為任意常數 T1?(N)=aN3,T2?(N)=bN2,T3?(N)=cNlogN,T4?(N)=dN,a,b,c,d均為任意常數,常數是為了估計真正的時間復雜度函數, T 1 ( 1000 ) = a 1 0 9 = 3.84 × 1 0 ? 1 s , a = 3.84 × 1 0 ? 10 T_{1}(1000)=a10^{9}=3.84\times10^{-1}\text{s},a=3.84\times10^{-10} T1?(1000)=a109=3.84×10?1s,a=3.84×10?10, T 2 ( 1000 ) = b 1 0 6 = 1 × 1 0 ? 3 s , b = 1 × 1 0 ? 9 T_{2}(1000)=b10^{6}=1\times10^{-3}\text{s},b=1\times10^{-9} T2?(1000)=b106=1×10?3s,b=1×10?9, T 3 ( 1000 ) = c 1000 log 2 1000 = 4 × 1 0 ? 5 s , c = 4.012 × 1 0 ? 9 T_{3}(1000)=c1000\text{log}_{2}1000=4\times10^{-5}\text{s},c=4.012\times10^{-9} T3?(1000)=c1000log2?1000=4×10?5s,c=4.012×10?9(底數選2是因為二分法), T 4 ( 1000 ) = 1000 d = 1 × 1 0 ? 5 s , d = 1 × 1 0 ? 8 T_{4}(1000)=1000d=1\times10^{-5}\text{s},d=1\times10^{-8} T4?(1000)=1000d=1×10?5s,d=1×10?8,最終得到的估計的時間復雜度函數為:
T 1 ( N ) = 3.84 × 1 0 ? 10 N 3 s T_{1}(N)=3.84\times10^{-10}N^{3}\text{s} T1?(N)=3.84×10?10N3s
T 2 ( N ) = 1 × 1 0 ? 9 N 2 s T_{2}(N)=1\times10^{-9}N^{2}\text{s} T2?(N)=1×10?9N2s
T 3 ( N ) = 4.012 × 1 0 ? 9 N log 2 N s T_{3}(N)=4.012\times10^{-9}N\text{log}_{2}N\text{s} T3?(N)=4.012×10?9Nlog2?Ns
T 4 ( N ) = 1 × 1 0 ? 8 N s T_{4}(N)=1\times10^{-8}N\text{s} T4?(N)=1×10?8Ns
最后使用如下Python腳本畫出時間增長曲線:
import matplotlib.pyplot as plt
import numpy as npplt.rcParams['font.family'] = 'SimHei' # 設置中文字體# log函數
def log(base, x):return np.log(x) / np.log(base)x = np.linspace(1000, 10000, 10) # 生成1000到10000之間的10個數據點作為x軸
y1 = 3.84e-10 * x * x * x # 暴力法1時間復雜度函數
y2 = 1e-9 * x * x # 暴力法2時間復雜度函數
y3 = 4.012e-9 * x * log(2, x) # 分治法時間復雜度函數
y4 = 1e-8 * x # 在線處理法時間復雜度# 創建一個Matplotlib圖表
plt.figure(figsize=(10, 6)) # 設置圖表的大小# 繪制折線圖
plt.plot(x, y1, label=r'$T_{1}(N)=3.84\times10^{-10}N^{3}\text{s}$', color='blue', linewidth=2)
plt.plot(x, y2, label=r'$T_{2}(N)=1\times10^{-9}N^{2}\text{s}$', color='red', linewidth=2)
plt.plot(x, y3, label=r'$T_{3}(N)=4.012\times10^{-9}N\text{log}_{2}N\text{s}$', color='green', linewidth=2)
plt.plot(x, y4, label=r'$T_{4}(N)=1\times10^{-8}N\text{s}$', color='orange', linewidth=2)# 添加標題和標簽
plt.title('時間增長曲線')
plt.xlabel('N')
plt.ylabel('時間:s')# 添加圖例
plt.legend()# 自定義坐標軸范圍
plt.xlim(1000, 10000)
plt.ylim(0, 400)# 添加網格線
plt.grid(True, linestyle='--', alpha=0.6)# 顯示圖像
plt.show()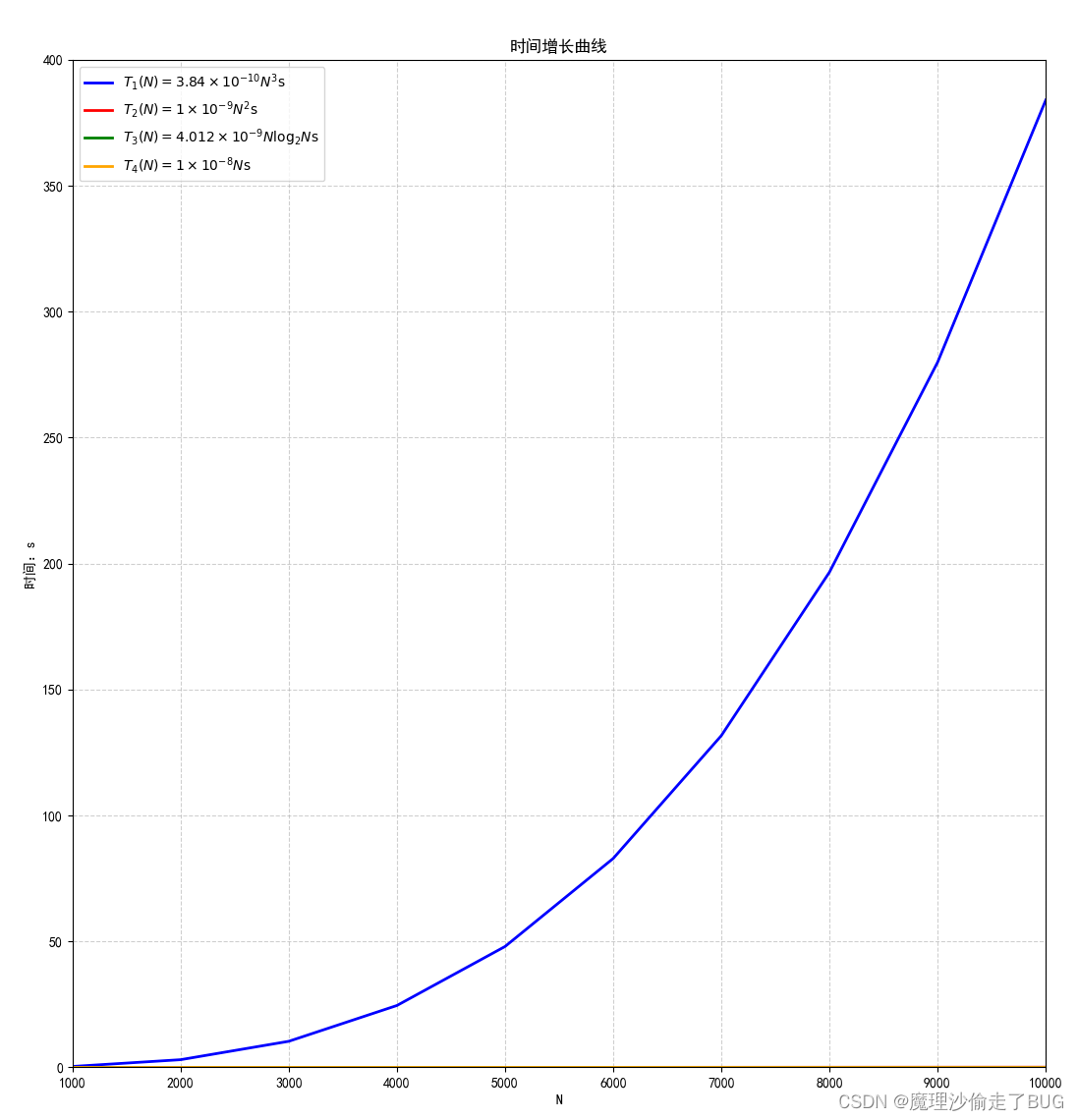
兩幅圖增長趨勢是一樣的,只不過一個N-運行時間曲線是實際運行時間,另一個時間增長曲線是理論估計時間,時間增長曲線能描述當N充分大的時候的趨勢。
1.8 查找算法中的“二分法”是這樣定義的:給定N個從小到大排好序的整數序列List[],以及某待查找整數X,我們的目標是找到X在List中的下標,即若有List[i]=X,則返回i;否則返回-1表示沒有找到。二分法是先找到序列的中點List[M],與X進行比較,若下個等則返回中點下標;否則,若List[M]>X,則在左邊的子系列中查找X;若List[M]<X,則在右邊的子系列中查找X。試寫出算法的偽碼描述,并分析最壞,最好情況下的時間、空間復雜度。
【答】二分查找,可以用循環實現也可以用遞歸實現,這里我給出我的文章【代碼隨想錄刷題記錄】LeetCode704二分查找
中左閉右閉情況的代碼進行分析(循環實現,改成了C語言版本重新實現了一下):
int search(int* nums, int numsSize, int target){int low = 0;//low指針int high = numsSize-1;//high指針int mid = 0;//折半點while(low<=high){mid = (low+high)>>1;//右移1位相當于除2if(nums[mid]==target){return mid;}else if(target < nums[mid])//小于在左半側查找{high = mid-1;}else{low = mid+1;//大于在右半側查找}}//沒找到返回-1return -1;
}
先分析最壞時間復雜度,當要找的值在最左側或者最右側的時候,運行時間最多,假設要找的值在最右側,low要不斷地移動直到大于high,設數組長度為M,while循環的代碼執行了n次, l o w ( n ) low(n) low(n)表示第n次low的取值,則 h i g h = M , l o w ( n ) = m i d + 1 = l o w ( n ? 1 ) + h i g h 2 + 1 = l o w ( n ? 1 ) + M + 2 2 high = M,low(n)=mid+1=\frac{low(n-1)+high}{2}+1=\frac{low(n-1)+M+2}{2} high=M,low(n)=mid+1=2low(n?1)+high?+1=2low(n?1)+M+2?即 l o w ( n ) ? 1 2 l o w ( n ? 1 ) = M + 2 2 , l o w ( 1 ) = 0 , l o w ( 2 ) = l o w ( 1 ) + M + 2 2 = M + 2 2 low(n)-\frac{1}{2}low(n-1)=\frac{M+2}{2},low(1)=0,low(2)=\frac{low(1)+M+2}{2}=\frac{M+2}{2} low(n)?21?low(n?1)=2M+2?,low(1)=0,low(2)=2low(1)+M+2?=2M+2?,這是一個一階線性非齊次差分方程,
其特征方程為 x ? 1 2 = 0 x-\frac{1}{2}=0 x?21?=0
即特征根為 x = 1 2 x=\frac{1}{2} x=21?
故齊次通解為 l o w ˉ ( n ) = C ( 1 2 ) n , C 為任意常數 \bar{low}(n)=C\left(\frac{1}{2}\right)^{n},C為任意常數 lowˉ(n)=C(21?)n,C為任意常數
則特解為 l o w ? ( n ) = n 0 p = p , p 為任意常數 low^{*}(n)=n^{0}p=p,p為任意常數 low?(n)=n0p=p,p為任意常數
則 p ? 1 2 p = M + 2 2 p-\frac{1}{2}p=\frac{M+2}{2} p?21?p=2M+2?,所以 p = M + 2 p=M+2 p=M+2
所以非齊次通解為 l o w ( n ) = C ( 1 2 ) n + M + 2 , C 為任意常數 low(n)=C\left(\frac{1}{2}\right)^{n}+M+2,C為任意常數 low(n)=C(21?)n+M+2,C為任意常數
又因為 l o w ( 1 ) = 1 2 C + M + 2 = 0 low(1)=\frac{1}{2}C+M+2=0 low(1)=21?C+M+2=0,所以 C = ? M + 2 2 C=-\frac{M+2}{2} C=?2M+2?
所以 l o w ( n ) = ? M + 2 2 ( 1 2 ) n + M + 2 low(n)=-\frac{M+2}{2}\left(\frac{1}{2}\right)^{n}+M+2 low(n)=?2M+2?(21?)n+M+2
當要找的值在最右側時, l o w ( n ) = M low(n)=M low(n)=M,所以有:
M = ? M + 2 2 ( 1 2 ) n + M + 2 M=-\frac{M+2}{2}\left(\frac{1}{2}\right)^{n}+M+2 M=?2M+2?(21?)n+M+2解得 n = log 2 M + 2 4 n=\text{log}_{2}\frac{M+2}{4} n=log2?4M+2?
M其實就是問題規模N,n是時間復雜度函數 T ( n ) T(n) T(n),則其最壞時間復雜度為 O ( log 2 N + 2 4 ) = O ( log N ) O(\text{log}_{2}\frac{N+2}{4})=O(\text{log}N) O(log2?4N+2?)=O(logN)
最好時間復雜度就是中點對應就是要找的元素,一下子就找到了,所以最好時間復雜度為 O ( 1 ) O(1) O(1)
我們在此算法中就用到了三個變量low,high,mid,所以空間復雜度無論好壞都是常數級的 O ( 1 ) O(1) O(1)
1.9 給定存儲了N個從小到大排好序的整數數組List[],試給出算法將任一給定整數X插入數組中合適的位置,以保持結果依然有序。分析算法在最壞、最好情況下的時間、空間復雜度。
【答】
#include <stdio.h>
#include <stdlib.h>//arr是指向待插入數組的指針,n是待插入的數組的長度,m是待插入的值
//返回的是插入后的新數組的長度
//C語言函數參數默認值傳遞,沒有引用,因此只能傳入指向舊數組的指針(即指向指針的指針)
int InsertArray(int** arr, int n, int m)
{int* old = *arr; //舊的數組指針int* temp = (int*)malloc((sizeof(int)) * (n + 1)); // 開辟比原來數組長度多1的內存空間當作新的數組//判斷開辟的空間是否成功if (temp == NULL){printf("內存不足!\n");return -1;}//將原來數組的元素拷貝到新數組for (int i = 0; i < n; i++){temp[i] = old[i];}int k = n; //記錄應該插入的位置下標,數組中若沒有元素,默認從n=0開始插入,若遍歷到最后都沒有大于等于m的元素,則正好在最后位置插入//因為數組有序,只需要找到首個大于等于m的元素,記錄此時的下標for (int i = 0; i < n; i++){if (old[i] >= m){k = i;break; // 找到后就跳出循環}}//將k所指元素及其后面的元素都向后移動一個空間(在新的temp數組中)for (int i = n; i > k; i--){temp[i] = temp[i - 1];}temp[k] = m; //插入元素位置free(old); //釋放舊數組*arr = temp; //arr指針指向新數組return n + 1;
}int main()
{int* a = (int*)malloc(sizeof(int) * 3); //開辟長度為3的動態數組if (a == NULL){printf("內存不足!\n");return 0;}a[0] = 1;a[1] = 2;a[2] = 3;int **arr = &a; //指向動態數組的指針,便于直接修改值int N = InsertArray(arr, 3, 2);//打印數組結果for (int i = 0; i < N; i++){printf("%d\n", a[i]);}return 0;
}運行結果:

分析時間復雜度,函數中常數級別的復雜度不需要看,在無窮趨向下都被略掉了,現在看循環中的時間復雜度,首先將原來數組的元素拷貝到新數組的循環是 O ( N ) O(N) O(N),找到要插入的下標,有可能要插入的值比數組中的元素都大,此時遍歷了整個數組,時間復雜度為 O ( n ) O(n) O(n),將下標k對應的后面的元素全部向后移動1個位置,假設要插入的值比數組中的元素都小,整個數組后移1位,時間復雜度為 O ( n ) O(n) O(n),最后,總的時間復雜度為 O ( N + N + N ) = O ( N ) O(N+N+N)=O(N) O(N+N+N)=O(N),對于空間復雜度,拋出常數級別的變量,我們創建了一個新的長度為 N + 1 N+1 N+1的數組,則空間復雜度為 O ( N + 1 ) = O ( N ) O(N+1)=O(N) O(N+1)=O(N)
1.10 試給出判斷N是否為質數的 O ( N ) O(\sqrt{N}) O(N?)的算法。
【答】素數一般指質數。質數是指在大于1的自然數中,除了1和它本身以外不再有其他因數的自然數。根據定義,可以從2~n-1依次試除,判斷n是否有約數(約數,又稱因數。整數a除以整數b(b≠0) 除得的商正好是整數而沒有余數,就說a能被b整除,或b能整除a。a稱為b的倍數,b稱為a的約數。記作 b ∣ a b|a b∣a),若有則n不是質數,假設 d d d 可以整除 n n n( n d \frac{n}{d} dn?是整數, d ∣ n d|n d∣n),那么它們的商 n d \frac{n}{d} dn? 也能整除 n n n( n n d = d \frac{n}{\frac{n}{d}}=d dn?n?=d, n d ∣ n \frac{n}{d}|n dn?∣n),若約數是成對(5×7=35,5×5=25)出現的,必定是一大一小或者相等,則假設 d ≤ n d d\le\frac{n}{d} d≤dn?,即 d 2 ≤ n d^{2}\le n d2≤n,亦即 d ≤ n d\le\sqrt{n} d≤n?(因為 d d d是自然數,必然大于0,所以不會出現開根號取負的結果),所以每次判斷只需要判斷到 n \sqrt{n} n? 即可。
實際上,這個引理來自初等數論,引用一下陳景潤版初等數論第一冊第五頁引理6:
【前置知識】
【注】書中給的證明看得不是太明白,尤其是c大于等于0那里,如果評論區有高人請告訴我為什么能推出 c ≥ 0 c\ge0 c≥0(我感覺像是說因為c>0,所以c大于等于0),我只推出>0,我自己證了一下,此處用的反證法,因為 ∣ a ∣ ∣ ∣ b ∣ |a|||b| ∣a∣∣∣b∣,所以有一個整數 c c c,使得 ∣ a ∣ = ∣ b ∣ c |a|=|b|c ∣a∣=∣b∣c,如果 ∣ a ∣ = 0 |a|=0 ∣a∣=0,則有 a = 0 a=0 a=0,假設 ∣ a ∣ > 0 |a|>0 ∣a∣>0,則由于 ∣ a ∣ < ∣ b ∣ |a|<|b| ∣a∣<∣b∣有 0 < ∣ a ∣ < ∣ b ∣ 0<|a|<|b| 0<∣a∣<∣b∣,又由于 ∣ a ∣ = ∣ b ∣ c > 0 , ∣ b ∣ > 0 |a|=|b|c>0,|b|>0 ∣a∣=∣b∣c>0,∣b∣>0則 c > 0 c>0 c>0,且 c = ∣ a ∣ ∣ b ∣ c=\frac{|a|}{|b|} c=∣b∣∣a∣?,又因為 ∣ b ∣ > ∣ a ∣ > 0 |b|>|a|>0 ∣b∣>∣a∣>0,所以 c = ∣ a ∣ ∣ b ∣ < 1 c=\frac{|a|}{|b|}<1 c=∣b∣∣a∣?<1,所以 0 < c < 1 0<c<1 0<c<1這與 c c c是一個整數矛盾,故如果 a , b a,b a,b都是整數,而 ∣ a ∣ < ∣ b ∣ , ∣ b ∣ ∣ ∣ a ∣ |a|<|b|,|b|||a| ∣a∣<∣b∣,∣b∣∣∣a∣,則有 a = 0 a=0 a=0.
【注】一個數的因數都小于等于其本身,且在證明的反證法部分,假設 b b b是復合數, b b b一定有大于1而不等于 b b b的因數 c c c,所以 1 < c < b 1<c<b 1<c<b,后來又證明 c c c是 a a a的因數,結果此處 c c c比 b b b小了,和前面 b b b是 a a a的大于1最小因數矛盾了(因為此時 c c c是最小因數了),故得證。
【引理6】這個引理6是解決本題的關鍵。
【注】由于 a a a被大于1而小于 a \sqrt{a} a?的整數都除不盡,且 a = b c a=bc a=bc, b b b和 c c c是整數且都為 a a a的因數,所以 b > a , c > a b>\sqrt{a},c>\sqrt{a} b>a?,c>a?








由引理6可知,因為 a a a是整數, a a a要是復合數,則一定有大于1即大于等于2而小于根號a的因數,所以只要從2遍歷到根號a,發現能整除,就是復合數,如果過了一遍循環遍歷,沒有能整除的數,就是素數,這樣一看此種算法遍歷到最后,最多是 O ( n ) O(\sqrt{n}) O(n?)的時間復雜度,但是我們要注意,此處判斷條件不能直接寫i<sqrt(a),因為sqrt函數在C語言的math.h頭文件定義,其用牛頓迭代法求解根號,時間復雜度更復雜,我們應該換一下等價形式,循環變量 i ≤ a i\le\sqrt{a} i≤a?等價于 i 2 < a i^{2}<a i2<a,乘法指令要比開根號迭代運行得快,思路明確后,代碼如下:
#include <stdio.h>
#include <stdlib.h>//時間復雜度為$O(\sqrt{n})$的判斷素數的算法
//0代表不是素數,1代表是素數
int isPrime(int a)
{//素數的前提是自然數,不是自然數不行if (a <= 0){return 0;}for (int i = 2; i * i <= a; i++){//這期間有一個能整除的,最后結果都是復合數if (a % i == 0){return 0;}}//最后都沒整除,則是素數return 1;
}//輸出是否是素數的結果
void printIsPrime(int a)
{if (isPrime(a)){printf("%d", a);printf("是素數\n");}else{printf("%d", a);printf("不是素數\n");}
}int main()
{printIsPrime(-1);printIsPrime(0);printIsPrime(4);printIsPrime(5);printIsPrime(10);printIsPrime(23);printIsPrime(1523);printIsPrime(1524);return 0;
}運行結果:
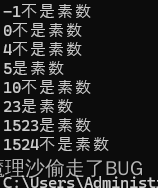
時間復雜度為 O ( N ) O(\sqrt{N}) O(N?)
1.11 試給出計算 x N x^{N} xN的時間復雜度為 O ( log N ) O(\text{log}_{N}) O(logN?)的算法。
【答】此題目對應LeetCode50 Pow(x,n),此處是計算整數次冪
為了能寫出低于 O ( n ) O(n) O(n)時間復雜度的算法,肯定要讓計算機記住中間的一些計算結果,比如 x 8 x^{8} x8,最開始是從 x x x, x 2 x^{2} x2開始計算,如果我們知道了 x 2 x^{2} x2就相當于知道了 x 4 = x 2 x 2 x^{4}=x^{2}x^{2} x4=x2x2,知道了 x 4 x^{4} x4相當于知道了 x 8 = x 4 x 4 x^{8}=x^{4}x^{4} x8=x4x4,于是我們知道,如果我們最開始通過不斷地計算Pow(x,n/2),即乘 x n 2 x^{\frac{n}{2}} x2n?一直遞歸到冪數為0,然后我們再將每次遞歸得到的 x n 2 x^{\frac{n}{2}} x2n?相乘即 x n 2 x n 2 = x n x^{\frac{n}{2}}x^{\frac{n}{2}}=x^{n} x2n?x2n?=xn記作上一次遞歸的計算結果,這是偶數次冪的情況,奇數次冪的情況是,假如計算 x 9 x^{9} x9,最開始是從 x x x, x 2 x^{2} x2開始計算,如果我們知道了 x 2 x^{2} x2就相當于知道了 x 4 = x 2 x 2 x^{4}=x^{2}x^{2} x4=x2x2,知道了 x 4 x^{4} x4相當于知道了 x 8 = x 4 x 4 x^{8}=x^{4}x^{4} x8=x4x4,此時還差乘一個 x x x,那需要判斷冪數是偶數就正常二分,是奇數就乘個 x x x再二分即可,但是我們目前只考慮了冪為自然數的情況,如果為0則返回1,如果為負數,應該按正數(取個負)計算,然后返回其倒數,所以我們只需要先考慮冪為自然數的情況,再根據冪的正負號決定返回倒數還是本身:
遞歸法:
double quickMul(double x, long long n)
{//為0返回其本身if(n == 0){return 1.0;}double y = quickMul(x, n/2); //求x^(n/2)的情況遞歸,一直遞歸到n為0為止//分奇數還是偶數,奇數需要多乘個xif(n % 2 == 0){//偶數直接返回兩個二分的結果相乘return y * y;}else{//奇數需要乘個xreturn y * y * x;}
}
double myPow(double x, int n) {//大于0按冪為自然數情況考慮if(n > 0){return quickMul(x, n);}//小于0取倒數(0的情況已經考慮到,直接返回1)else{return 1.0 / quickMul(x,-n);}
}
證明時間復雜度過程:遞歸法的時間復雜度函數為 T ( n ) T(n) T(n),則它是不斷二分,根據double y = quickMul(x, n/2);的遞歸調用,然后每一次都有一個常數時間復雜度的判斷奇偶的過程,則有 T ( n ) = T ( n 2 ) + O ( 1 ) = T ( n 4 ) + O ( 1 ) + O ( 1 ) = . . . = T ( n 2 k ) + k O ( 1 ) T(n)=T(\frac{n}{2})+O(1)=T(\frac{n}{4})+O(1)+O(1)=...=T(\frac{n}{2^{k}})+kO(1) T(n)=T(2n?)+O(1)=T(4n?)+O(1)+O(1)=...=T(2kn?)+kO(1)
遞歸到最后,問題規模為1,即 n 2 k = 1 \frac{n}{2^{k}}=1 2kn?=1,所以 k = log 2 n k=\text{log}_{2}n k=log2?n,于是
T ( n ) = T ( 1 ) + O ( 1 ) log 2 n = T ( 1 ) + O ( log 2 n ) T(n)=T(1)+O(1)\text{log}_{2}n=T(1)+O(\text{log}_{2}n) T(n)=T(1)+O(1)log2?n=T(1)+O(log2?n),所以時間復雜度為 O ( log 2 n ) O(\text{log}_{2}n) O(log2?n)
循環法:遞歸需要額外的函數調用棧的空間,我們嘗試改成循環求解:
我們知道任何數都能用二進制表示為 b = k i ? 1 2 i ? 1 + k i ? 2 2 i ? 2 + . . . + k 0 2 0 b=k_{i-1}2^{i-1}+k_{i-2}2^{i-2}+...+k_{0}2^{0} b=ki?1?2i?1+ki?2?2i?2+...+k0?20
即每個整數都可以唯一表示為若干指數不重復的2的次冪和,則 a b = a k i ? 1 2 i ? 1 × a k i ? 2 2 i ? 2 × . . . × a k 0 2 0 a^{b}=a^{k_{i-1}2^{i-1}}\times a^{k_{i-2}2^{i-2}}\times ... \times a^{k_{0}2^{0}} ab=aki?1?2i?1×aki?2?2i?2×...×ak0?20
且 a 2 i = ( a 2 i ? 1 ) 2 a^{2i}=(a^{2i-1})^{2} a2i=(a2i?1)2,以LeetCode官方舉的例子為例,求 x 77 x^{77} x77,按照分治的方法,先求 x ? n 2 ? x^{\lfloor \frac{n}{2}\rfloor} x?2n??,即求 x ? 77 2 ? = x 38 x^{\lfloor \frac{77}{2}\rfloor}=x^{38} x?277??=x38,然后求 x ? 38 2 ? = x 19 x^{\lfloor \frac{38}{2}\rfloor}=x^{19} x?238??=x19,然后是 x ? 19 2 ? = x 9 x^{\lfloor \frac{19}{2}\rfloor}=x^{9} x?219??=x9……以此類推,最后得到要計算的順序:
x → x 2 → x 4 → x 9 → x 19 → x 38 → x 77 x \rightarrow x^{2} \rightarrow x^{4} \rightarrow x^{9} \rightarrow x^{19} \rightarrow x^{38} \rightarrow x^{77} x→x2→x4→x9→x19→x38→x77
然后從左向右計算,根據冪的奇偶性判斷是否需要乘 x x x
我們將額外乘 x x x的部分打一個加號:
x → x 2 → x 4 → + x 9 → + x 19 → x 38 → + x 77 x \rightarrow x^{2} \rightarrow x^{4} \rightarrow^{+} x^{9} \rightarrow^{+} x^{19} \rightarrow x^{38} \rightarrow^{+} x^{77} x→x2→x4→+x9→+x19→x38→+x77
{ x 38 → + x 77 中額外乘的? x 在? x 77 中貢獻了? x 因此在 x 77 中貢獻了 x 2 0 ;? x 9 → + x 19 中額外乘的? x 在之后被平方了? 2 次,即 ( x 2 ) 2 = x 4 ,因此在? x 77 中貢獻了? x 2 2 = x 4 ;? x 4 → + x 9 中額外乘的? x 在之后被平方了? 3 次,即? ( ( x 2 ) 2 ) 2 = ( x 4 ) 2 = x 8 ,因此在? x 77 中貢獻了? x 2 3 = x 8 ;? 最初的? x 在之后被平方了? 6 次,因此在? x 77 中??貢獻了? x 2 6 = x 64 。? \left\{\begin{array}{l} x^{38} \rightarrow^{+} x^{77} \text { 中額外乘的 } x \text { 在 } x^{77} \text { 中貢獻了 } x \text{因此在}x^{77}\text{中貢獻了}x^{2^{0}}\text { ; } \\ x^{9} \rightarrow^{+} x^{19} \text { 中額外乘的 } x \text { 在之后被平方了 } 2 \text { 次},\text{即}(x^{2})^{2}=x^{4}\text{,因此在 } x^{77} \text { 中貢獻了 } x^{2^{2}}=x^{4} \text { ; } \\ x^{4} \rightarrow^{+} x^{9} \text { 中額外乘的 } x \text { 在之后被平方了 } 3 \text { 次,即 }\left(\left(x^{2}\right)^{2}\right)^{2}=\left(x^{4}\right)^{2}=x^{8} \text { ,因此在 } x^{77} \text { 中貢獻了 } x^{2^{3}}=x^{8} \text { ; } \\ \text { 最初的 } x \text { 在之后被平方了 } 6 \text { 次,因此在 } x^{77} \text { 中 } \text { 貢獻了 } x^{2^{6}}=x^{64} \text { 。 } \end{array}\right. ? ? ??x38→+x77?中額外乘的?x?在?x77?中貢獻了?x因此在x77中貢獻了x20?;?x9→+x19?中額外乘的?x?在之后被平方了?2?次,即(x2)2=x4,因此在?x77?中貢獻了?x22=x4?;?x4→+x9?中額外乘的?x?在之后被平方了?3?次,即?((x2)2)2=(x4)2=x8?,因此在?x77?中貢獻了?x23=x8?;??最初的?x?在之后被平方了?6?次,因此在?x77?中??貢獻了?x26=x64?。??
77的二進制表示為1001101B,二進制表示中的1的位置從右到左(從下標0開始)恰好和貢獻的 x x x的冪數對應的 2 2 2的次方數相同,因此我們借助整數的二進制拆分,就可以得到迭代計算的方法,代碼如下:
double quickMul(double x, long long n)
{// 只考慮自然數的情況double result = 1.0; // 初始為1,冪數為0時,它為1// 貢獻的初始值為xdouble x_con = x;// 對N進行二進制拆分并計算答案while (n > 0) {//如果當前數的最低位是1,則需要乘貢獻的xif(n % 2 == 1){result *= x_con;}// 將貢獻不斷地平方x_con *= x_con;// 每次除2,相當于找到新的最低位,除2相當于右移1位// 比如1011B除2,就變成了101,右移動1位// 這樣每次都能通過除2取余判斷新的最低位,直到右移不了位置// 我們是按次冪數的二進制求解n = n >> 1;}return result;
}
double myPow(double x, int n)
{//大于0按冪為自然數情況考慮if(n > 0){return quickMul(x, n);}//小于0取倒數(0的情況已經考慮到,直接返回1)else{return 1.0 / quickMul(x, -n);}
}
分析時間復雜度:假設問題規模 n n n,則 T ( n ) T(n) T(n)時, n n n通過不斷除2接近變成規模位1,那么就是 T ( n ) = T ( n 2 ) T(n)=T(\frac{n}{2}) T(n)=T(2n?),和上面的遞推方程一致,所以時間復雜度為 O ( log N ) O(\text{log}N) O(logN)
3. 總結
想讀明白陳姥姥的書,確實需要懂一些離散數學的知識,我也準備重新回顧看一看,順帶再看看數論。














)


)

