
論文:https://arxiv.org/pdf/2404.17571
主頁:https://mengtingchen.github.io/tunnel-try-on-page/
一、摘要總結
????????隨著虛擬試衣技術的發展,消費者和時尚行業對于能夠在視頻中實現高質量虛擬試衣的需求日益增長。這項技術允許用戶在不實際穿上衣物的情況下,通過視頻序列體驗穿著不同服裝的效果。盡管基于圖像的虛擬試衣方法已經得到了廣泛的研究,但視頻虛擬試衣面臨著保持服裝細節和模擬連貫動作的雙重挑戰,這在以往的研究中并未得到很好的解決。
????????本文介紹了一種名為“Tunnel Try-on”的新型視頻虛擬試衣框架,旨在解決以往方法在處理復雜場景時的不足。該框架的核心思想是在輸入視頻中挖掘一個“聚焦隧道”(focus tunnel),以便近距離拍攝服裝區域,從而更好地保留服裝的細微細節。為了生成連貫的動作,研究者們首先利用卡爾曼濾波器(Kalman filter)構建平滑的裁剪框,并注入隧道的位置嵌入到注意力層中,以提高生成視頻的連貫性。此外,還開發了一個環境編碼器來提取隧道外的上下文信息,作為輔助線索。通過這些技術,Tunnel Try-on不僅保持了服裝的精細細節,還合成了穩定和平滑的視頻。該方法在視頻虛擬試衣領域取得了突破性進展,為電商/時尚行業的實際應用提供了新的可能性,并為未來虛擬試衣應用的研究提供了新的方向。
二、網絡結構
a.)核心創新
本文的核心創新主要體現在以下幾個方面:
-
聚焦隧道(Focus Tunnel):提出了一種新的視頻處理策略,通過在視頻中創建一個聚焦隧道來放大服裝區域,從而更好地捕捉和保留服裝的細微特征。
-
隧道平滑和嵌入(Tunnel Smoothing and Embedding):使用卡爾曼濾波器對隧道坐標進行平滑處理,并引入隧道嵌入機制,以增強視頻幀之間的連貫性和一致性。
-
環境編碼器(Environment Encoder):開發了一種新的編碼器,用于提取并融合視頻中隧道區域外的全局上下文信息,以改善背景生成的質量。
-
擴散模型應用:將擴散模型應用于視頻虛擬試衣,利用其在圖像生成中的優勢,提高了視頻試衣結果的質量和真實感。
b.)核心網絡
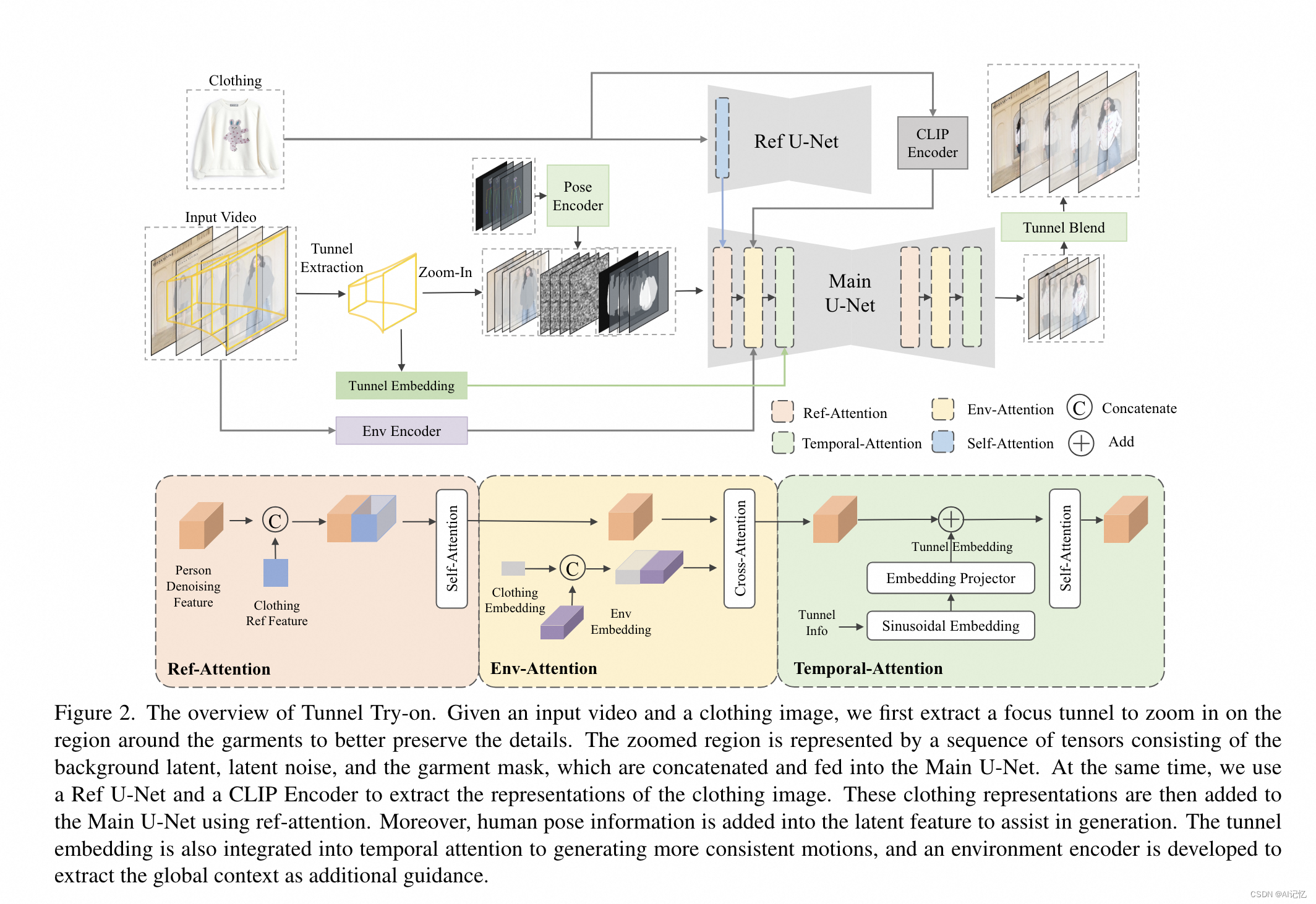
Tunnel Try-on的網絡結構包括以下幾個關鍵組件:
-
主網絡(Main U-Net):作為基礎的圖像試衣模型,使用掩碼視頻幀、潛在噪聲和衣物無關掩碼作為輸入。
-
參考網絡(Ref U-Net):用于編碼參考服裝的細粒度特征。
-
CLIP圖像編碼器:捕獲目標服裝圖像的高級語義信息。
-
姿態編碼器:將人體姿態信息編碼為特征,用于輔助視頻生成。
-
時間注意力模塊(Temporal-Attention):在Main U-Net的每個階段后插入,用于確保幀之間的平滑過渡。
-
環境編碼器(Environment Encoder):由一個凍結的CLIP圖像編碼器和一個可學習的線性映射層組成,用于提取和融合環境上下文信息。
-
隧道嵌入(Tunnel Embedding):將隧道的位置和大小信息編碼為嵌入,注入到時間注意力模塊中。
-
訓練和測試流程:訓練分為兩個階段,第一階段專注于圖像級別的試衣生成,第二階段整合所有策略和模塊,訓練視頻試衣數據集。
-
后處理:使用高斯模糊技術將生成的試衣視頻與原始視頻融合,以獲得最終的試衣效果。
通過這些創新點和詳細的算法流程,Tunnel Try-on能夠處理復雜的背景和多樣的人體動作,生成高保真的虛擬試衣視頻。
三、實驗結果
a.)總體指標
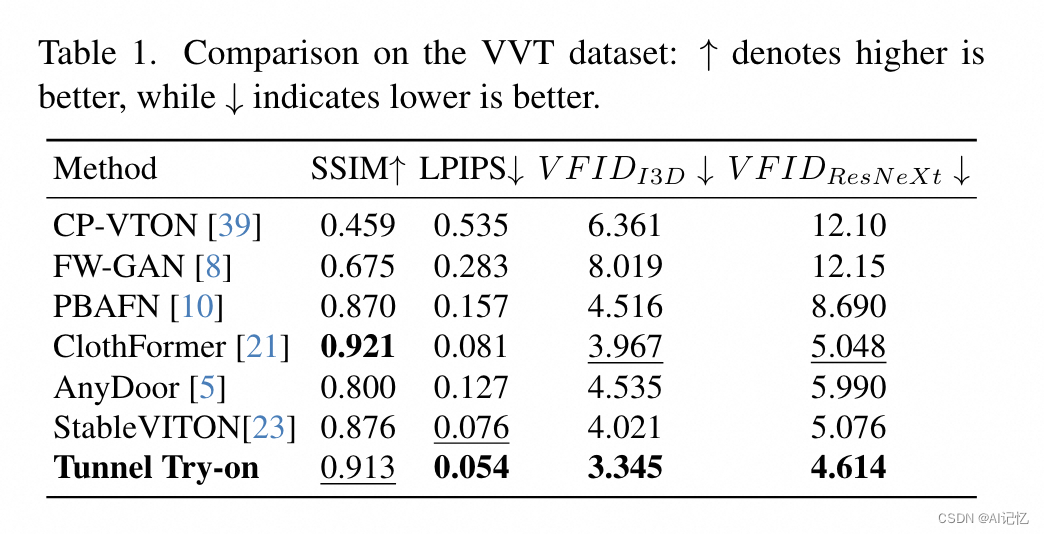
b.)ablation study
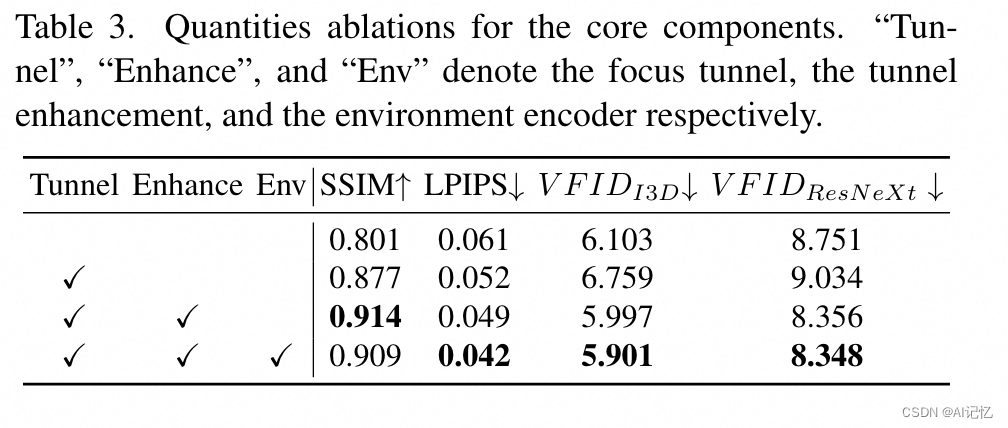
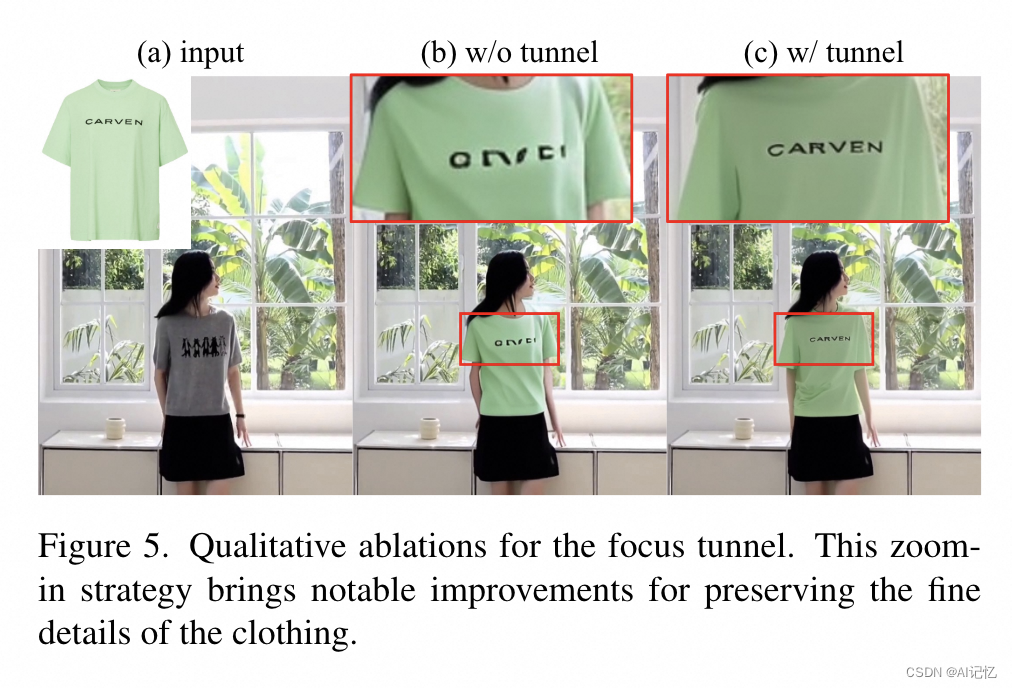

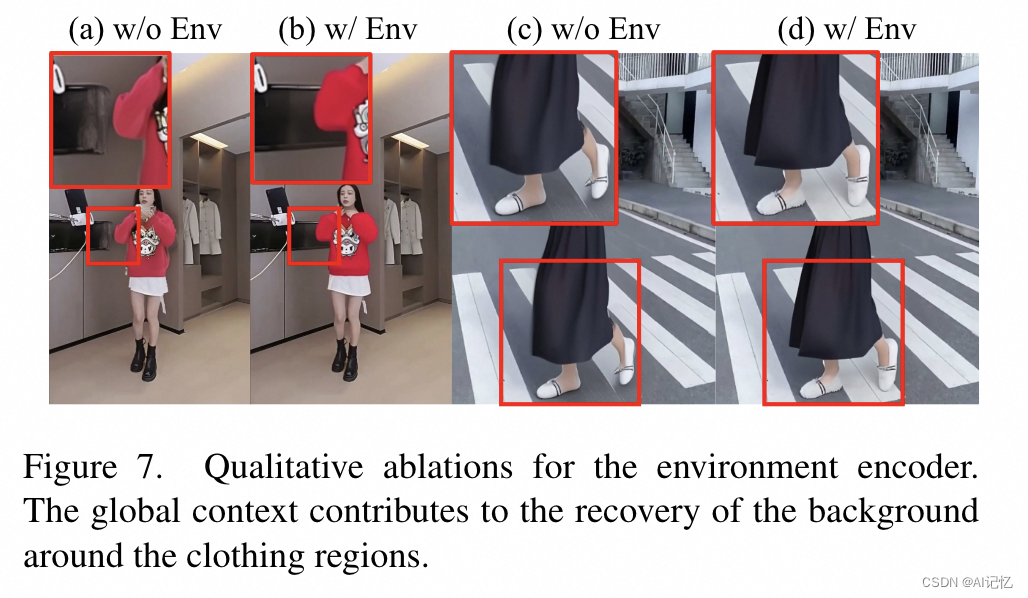









)
(200分))








