交叉注意力
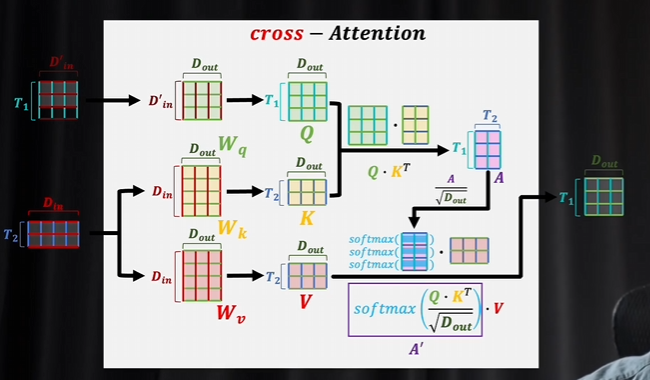
交叉注意力里面q和KV生成的數據不一樣
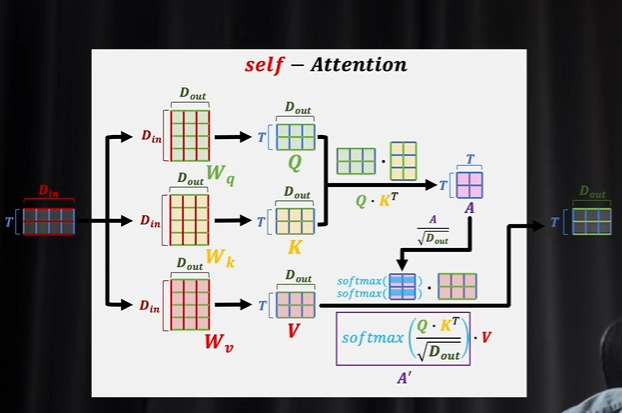
自注意力機制就是悶頭自學
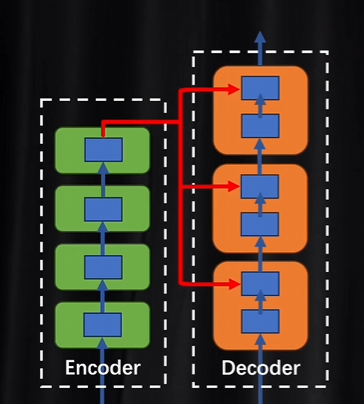
解碼器里面的每一層都會拿著編碼器結果進行參考,然后比較相互之間的差異。每做一次注意力計算都需要校準一次
編碼器和解碼器是可以并行進行訓練的
訓練過程
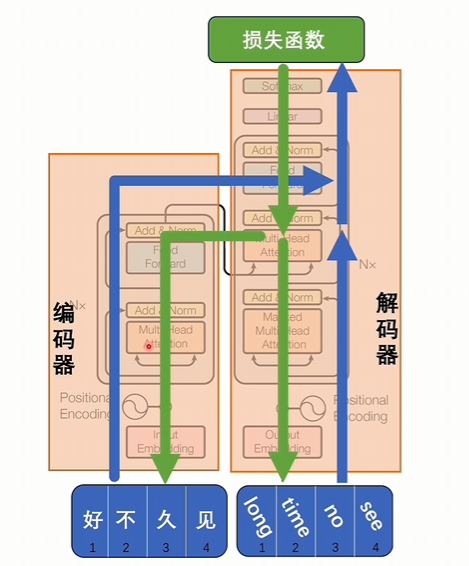
好久不見輸入到編碼器,long time no see輸入到解碼器,按照transformer的編碼和解碼這個過程逐漸往上進行計算。
有交叉注意力進行互相匹配,看是不是一樣,最后得到損失函數,這個損失函數就是判斷編碼器和解碼器部分分別得到的潛空間詞向量是不是匹配,經過反向傳播再修改模型里的參數,最后達到編碼器和解碼器他們在潛空間里詞向量里表達的詞意是能對應起來的
推理過程
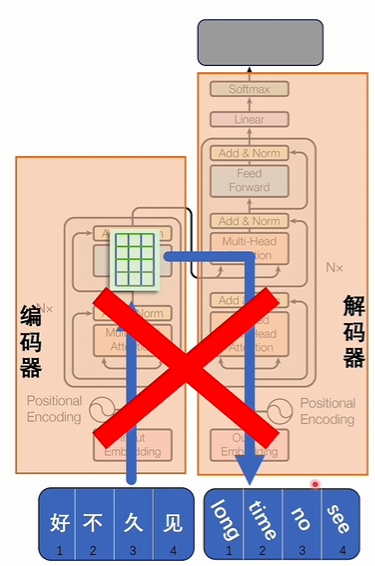
直接把輸入變成詞向量,詞向量翻譯成對應的目標的語言是不行的
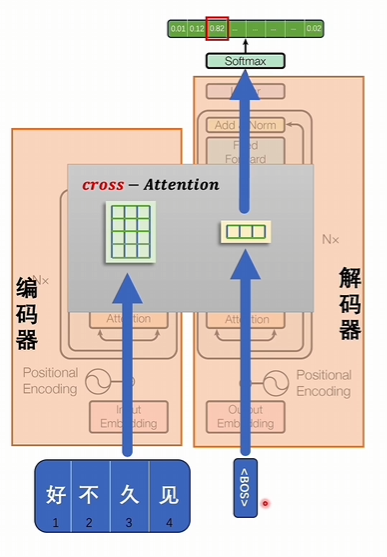
編碼器部分:輸入好久不見,生成一組潛空間里的詞向量
解碼器部分:輸入一個特殊符號, 代表開始
經過交叉注意力進行計算得到一個結果,結果經過升維和softmax計算后,會將詞匯表的所有token都計算一個數值,拿出概率最大的值作為結果,結果代表下一個token將會是什么。
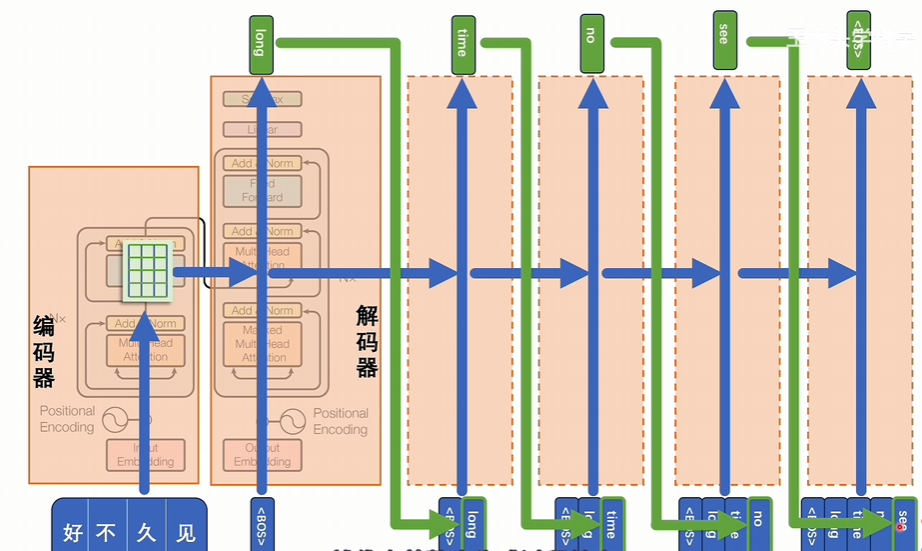
以此類推直到得到的結果是結束符號為止,代表整個生成過程結束,生成的結果就是好久不見的翻譯。相當于是逐步挨個對潛空間里的詞向量進行解壓,一個一個的還原成token,從而解決seq2seq
位置編碼
多頭注意力機制其實就是能力更強的CNN,詞向量的維度就是CNN里面的通道,多頭對應的就是卷積核
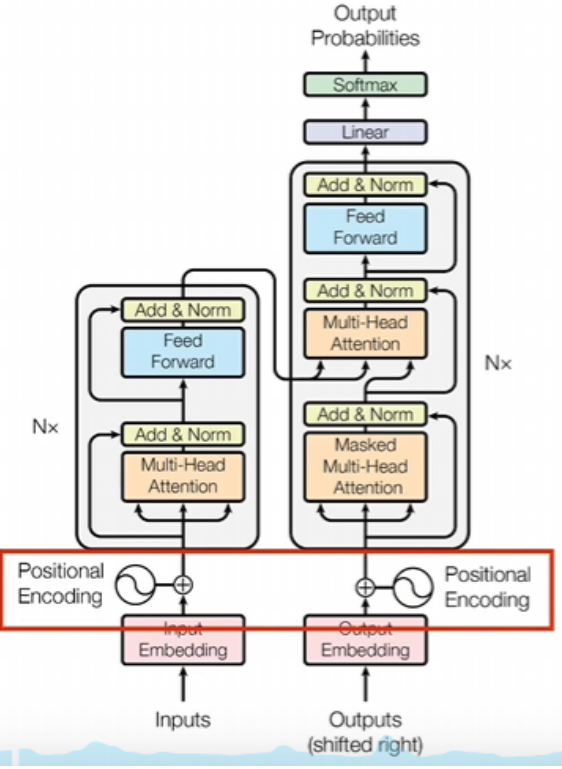
如果沒有位置編碼,transfomer會把所有token一起放到模型并行運算,這樣的話詞語的前后順序所攜帶的信息沒辦法體現
有兩種選擇增加位置信息:
- 通過權重增加位置信息(乘法)
- 通過偏置系數進行區分(加法)
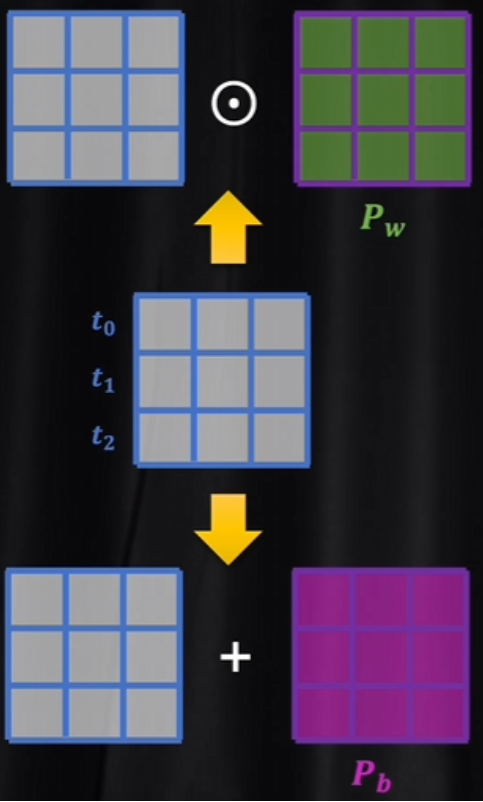
transformer用的是加法,因為如果用乘法,位置對詞向量影響就太大。而LLama模型用到的旋轉位置編碼,就是用乘法的方式實現
絕對位置編碼
針對數據進行修飾,直接讓數據攜帶了位置信息
把位置下標,一維的自然數集投射到與詞向量維度相同的連續空間,這樣詞向量矩陣就可以和位置編碼矩陣直接相加了。
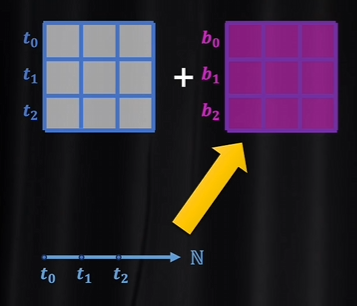
投射過程
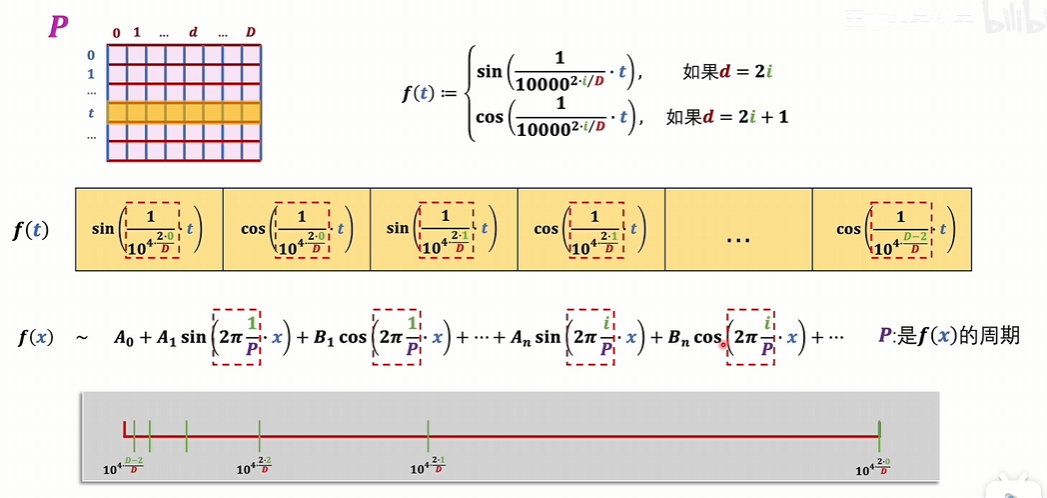
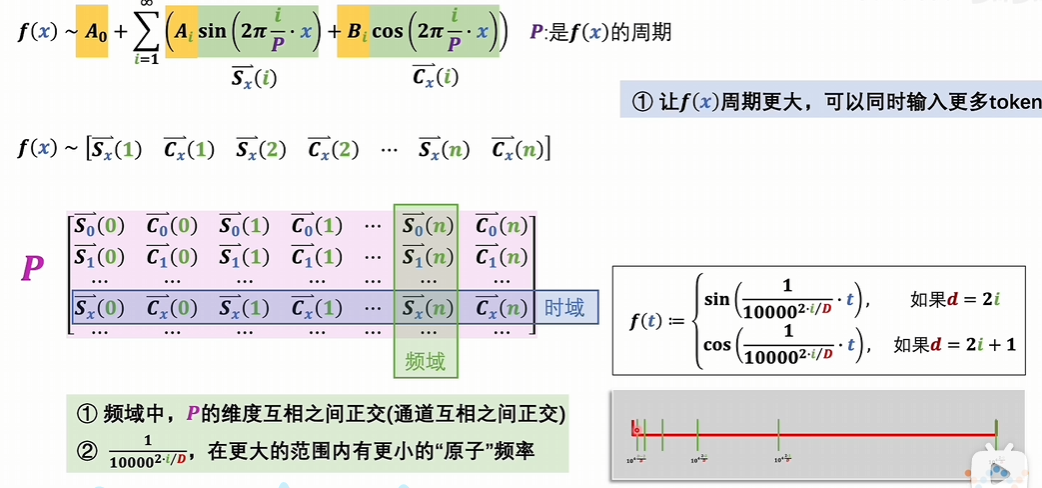
值域中

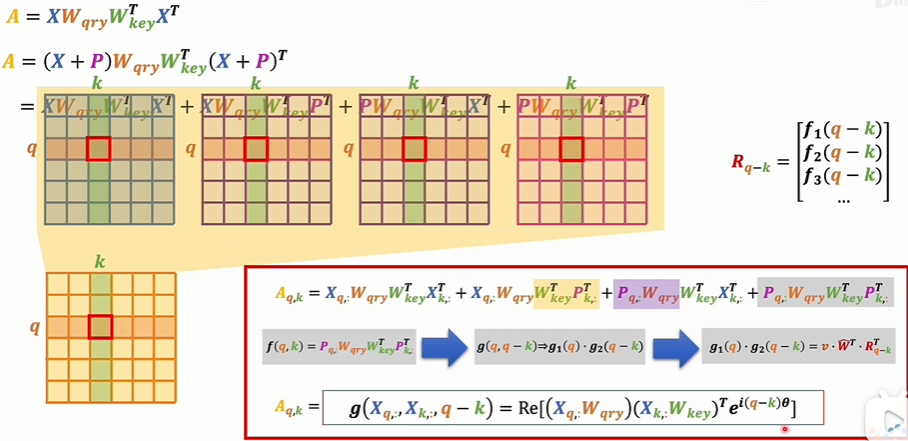
相對位置編碼
會更多的考慮一個詞向量和另一個詞向量之間的相對位置,一個詞向量和另一個詞向量進行對比。這個過程是在注意力機制里面發生的.
絕對位置編碼是對數據進行修飾的話,那相對位置編碼就是對注意力得分的那個A矩陣進行修飾,讓它具備相對位置的信息。這個矩陣考慮的是Q和K的相對關系.
對于這個注意力得分矩陣,用乘法的方式為每一項增加一個系數。這個系數是和相對位置有關的。
多頭注意力機制
形式
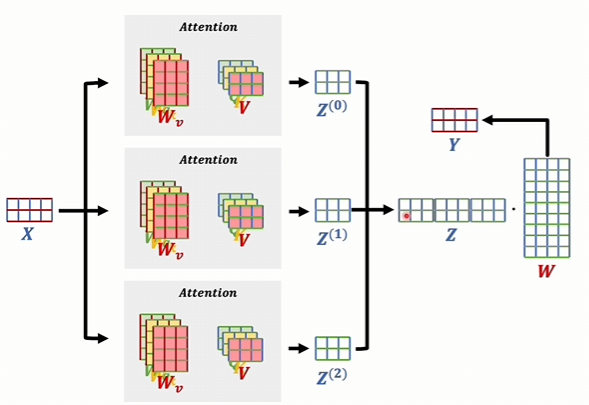
輸入的數據。假如說有兩詞向量,我們之前只是把這個數據進行一次注意力機制,然后得到一個新的詞向量。現在我們是多頭了,假如說我有三頭,分別去計算三次,這三個注意力機制里面系數是各自獨立的。
也就是說這里的三個矩陣是不一樣的。最后學到了什么可能會各不相同。最后得到的這三個結果也可能不一樣。而多頭對立就是把他們給拼起來
這個矩陣的行數和輸入數據的這個矩陣的行數是一樣的。因為行代表的是詞向量的個數,行是一樣的,維度就不同了。維度它是每一個輸出的維度,再乘以頭的個數,然后最后得到這個結果以后,還會再和一個W矩陣相乘,再得出一個輸出的詞向量
有什么意義
為什么要分別去計算,然后再拼在一起,而不是直接就用一個9維的W矩陣去進行訓練。
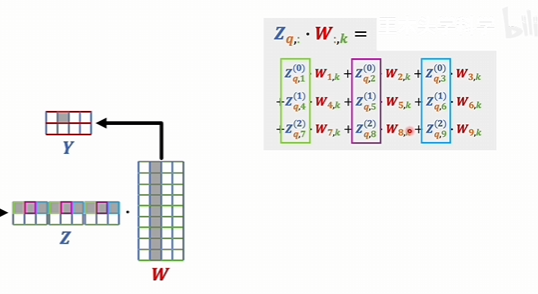
詞向量的維度某種程度上是可以理解成是通道的。就是和圖片的RGB的通道是相同的。如果就是一個大的注意力機制,那最后得到的結果是九維,那就是相當于九個通道。
現在是多頭的,每個頭計算出來都有三個維度。這三個計算結果的第一位,如果定性的去想的話,他們在語義上都是比較接近的,把這些語義接近的組成一組是更合理。那這三個通道經過一個系數相乘,然后再相加得到一個具體的值
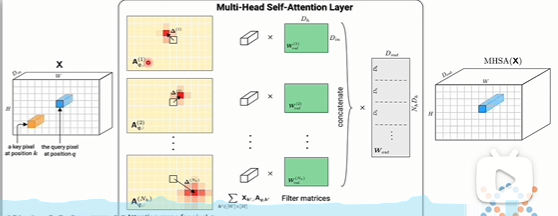
多頭注意力機制比卷積神經網絡它有更大的可能性,它不再局限于卷積核,必須是圍繞一個中心的,是可以中間可以跨越很多個頭頭,對很遠的地方去產生聯系,所以這個可能性就要更多,也可能會比卷積神經網絡更靈活。
在卷積神經網絡里面,它通過卷積操作,它可以疊加不同的層去識別出不同尺度的模式,或者說不同尺度的規律。就比如說這里這個圖最開始的卷積層可能是只能識別出非常簡單的一些模式。再往上去疊加更多的層,就能識別出復雜的模式來了。比如說眼睛、鼻子、嘴,再往上就可以把眼睛、鼻子、嘴再拼成人的臉。

transformer它疊加了很多層,它其實也有類似的作用,不同層的疊加,最底層它很可能只能識別出一個單詞,跨越幾個單詞它們之間的關系。隨著層數越高,那可能就能識別出跨越段的語義關系,代表就識別出跨越文章的語義關系。
其他
1.掩碼
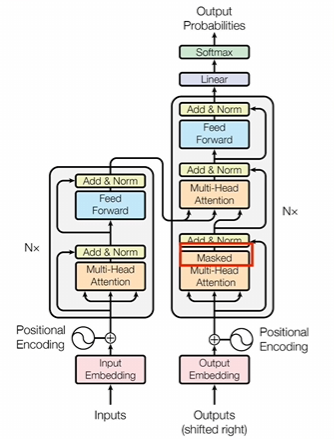
第一個是在解碼器里面,這個注意力上會加一個掩碼,就是因為在推理的時候,解碼器部分是一個詞一個詞生成的這就代表了你生成到某個詞的時候,這個詞它只能受到它之前詞的影響,不應該被未來生成的詞所決定。我們前面說了,注意力機制里面那個助力得分矩陣A它可以表示一個詞和所有上下文之間的關系的,既包含了它之前的,也包含了它之后的。所以說這個時候就需要把矩陣A中的這部分詞給屏蔽掉。
屏蔽的方法就是在這些位置上分別加上一個無窮小這樣子。

2.計算殘差和進行normal運算
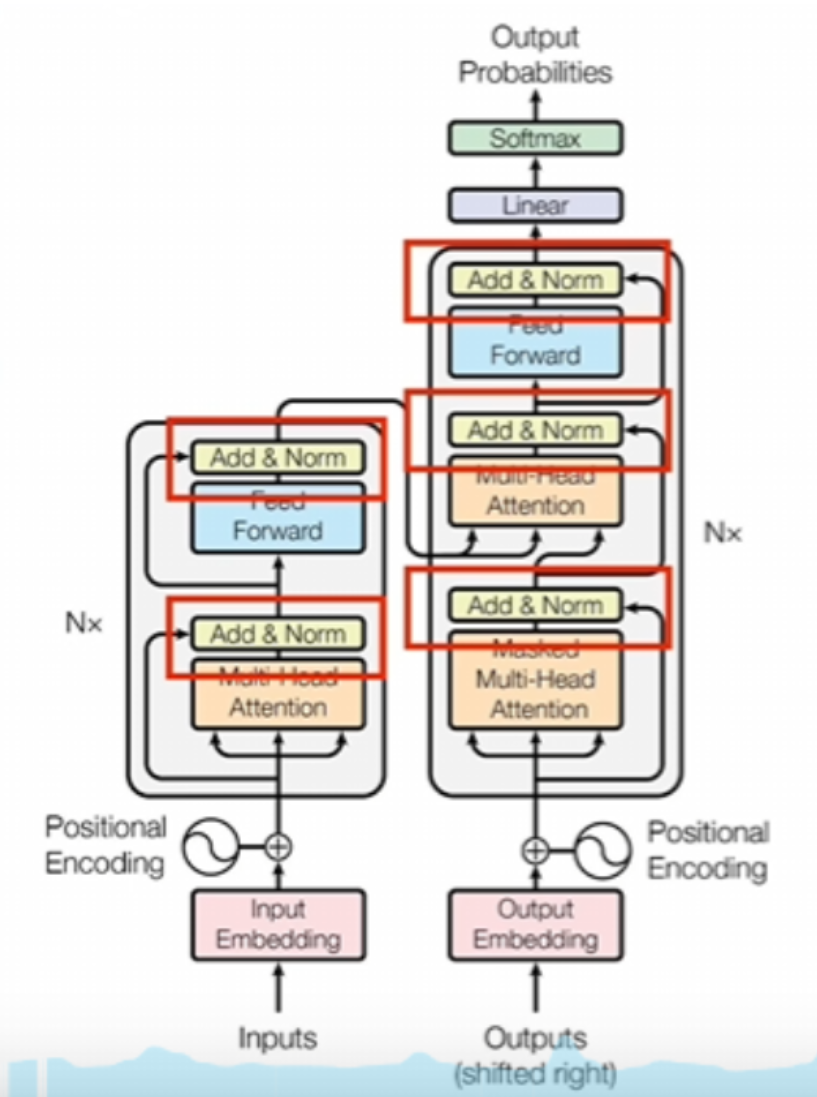 這部分它會完成兩個操作,一個是實現殘差網絡的功能,另一個是對上一層數據進行normal運算,也就是進行歸一化。反正它的計算很簡單,就是把輸入和輸出直接加起來,這么簡單一加之后就會讓注意力機制里面學習到的東西發生變化了。如果沒有做殘差,那注意力機制里面學到的是變化后的結果。而做了殘差注意力機制里面學到的就是變化的程度了。
這部分它會完成兩個操作,一個是實現殘差網絡的功能,另一個是對上一層數據進行normal運算,也就是進行歸一化。反正它的計算很簡單,就是把輸入和輸出直接加起來,這么簡單一加之后就會讓注意力機制里面學習到的東西發生變化了。如果沒有做殘差,那注意力機制里面學到的是變化后的結果。而做了殘差注意力機制里面學到的就是變化的程度了。
這兩種情況的區別,做個類比的話,大概就是這樣一種情況,沒有做殘差,就相當于是你蒙著眼開車,你只能通過控制手的不來回晃動,讓自己車盡量走直線。理論上是可以做到的,但是對操作要求那就非常高了。做了殘差,就相當于是你可以看到路上的標線,你控制的其實是車子和標線的偏差。就算手再抖,這個偏差也不會太大,你還是能調整回來的。
至于norm,Transformer里面用到的是layer Normal, 簡單來說就是給模型里面輸入的是一個batch數據。如果簡單理解的話,你可以這么去想,你給模型說說一段話,一段話里面有不同的句子,每個句子都是一個句子的長短不一樣。所以說這個句子的行數也不一樣,那樣的話要做的就是你一個句子里面,不管你的這個行數是多少,反正是這個句子里的所有元素放在一起進行歸一,那就是layer Normal.
3.前饋神經網絡
其實也就是一個全連接神經網絡。CNN也有類似的東西,就是前面是一堆卷積層。卷積層計算完了之后還會把結果輸入到神經網絡里面。
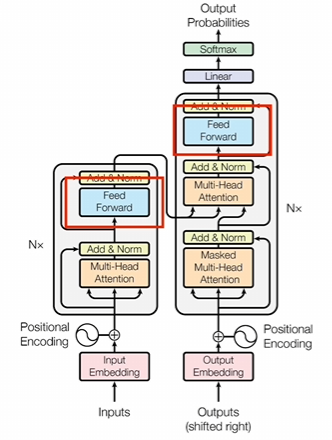
全連接神經網絡到底和前面的數據怎么連,按照詞向量的維度去排列,作為輸入一個維度。對應一個輸入,因為只想讓你的維度某種程度上來說就是這個詞對應的詞義特征,把特征輸入到神經網絡,這應該算是標準操作了。神經網絡最后要做的就是各種特征的組合和抽象。
4.線性層
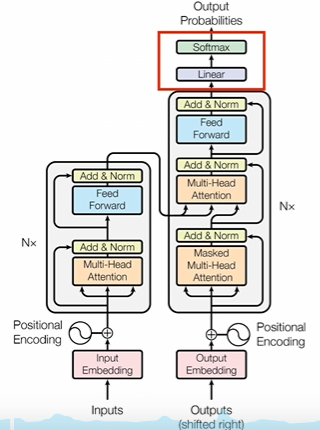
線性層其實就是一個線性變化,也就是做一個矩陣運算。其實這部分我也沒有去仔細研究,我的理解是這里加入這一層是為了將前面潛空間里的子向量再進行一次維度變換訓練的時候,你就要把維度變換成可以計算損失值的形式。在推理的時候,你需要把詞向量變成讀熱編碼去判斷到底哪個token的概率最大。所以這部分應該也不是特別復雜。








![YOLOv8訓練流程-原理解析[目標檢測理論篇]](http://pic.xiahunao.cn/YOLOv8訓練流程-原理解析[目標檢測理論篇])


)





函數基于FP棧回溯)

