一、安裝Kafka
1.執行以下命令完成Kafka的安裝:
cd ~ //默認壓縮包放在根目錄
sudo tar -zxf kafka_2.12-2.6.0.tgz -C /usr/local
cd /usr/local
sudo mv kafka_2.12-2.6.0 kafka-2.6.0
sudo chown -R qiangzi ./kafka-2.6.0二、啟動Kafaka
1.首先需要啟動Kafka,打開一個終端,輸入下面命令啟動Zookeeper服務:
cd /usr/local/kafka-2.6.0
./bin/zookeeper-server-start.sh config/zookeeper.properties
注意:以上現象是Zookeeper服務器已經啟動,正在處于服務狀態。不要關閉!
2.打開第二個終端,輸入下面命令啟動Kafka服務:
cd /usr/local/kafka-2.6.0
./bin/kafka-server-start.sh config/server.properties//加了“&”的命令,Kafka就會在后臺運行,即使關閉了這個終端,Kafka也會一直在后臺運行。
bin/kafka-server-start.sh config/server.properties &
注意:同樣不要誤以為死機了,而是Kafka服務器已經啟動,正在處于服務狀態。
三、創建Topic
1.再打開第三個終端,然后輸入下面命令創建一個自定義名稱為“wordsender”的Topic:
cd /usr/local/kafka-2.6.0
./bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic wordsender2.然后,可以執行如下命令,查看名稱為“wordsender”的Topic是否已經成功創建:
./bin/kafka-topics.sh --list --zookeeper localhost:2181
3.再新開一個終端(記作“監控輸入終端”),執行如下命令監控Kafka收到的文本:
cd /usr/local/kafka-2.6.0
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic wordsender注意,所有這些終端窗口都不要關閉,要繼續留著后面使用。
四、Spark準備工作
Kafka和Flume等高級輸入源,需要依賴獨立的庫(jar文件),因此,需要為Spark添加相關jar包。訪問MVNREPOSITORY官網(http://mvnrepository.com),下載spark-streaming-kafka-0-10_2.12-3.5.1.jar和spark-token-provider-kafka-0-10_2.12-3.5.1.jar文件,其中,2.12表示Scala的版本號,3.5.1表示Spark版本號。然后,把這兩個文件復制到Spark目錄的jars目錄下(即“/usr/local/spark-3.5.1/jars”目錄)。此外,還需要把“/usr/local/kafka-2.6.0/libs”目錄下的kafka-clients-2.6.0.jar文件復制到Spark目錄的jars目錄下。
cd ~ .jar文件默認放在根目錄
sudo mv ./spark-streaming-kafka-0-10_2.12-3.5.1.jar /usr/local/spark-3.5.1/jars/
sudo mv ./spark-token-provider-kafka-0-10_2.12-3.5.1.jar /usr/local/spark-3.5.1/jars/
sudo cp /usr/local/kafka-2.6.0/libs/kafka-clients-2.6.0.jar /usr/local/spark-3.5.1/jars/spark-streaming-kafka-0-10_2.12-3.5.1.jar的下載頁面:
Maven Repository: org.apache.spark ? spark-streaming-kafka-0-10_2.12 ? 3.5.1 (mvnrepository.com)
spark-streaming-kafka-0-10_2.12-3.5.1.jar的下載頁面:
Maven Repository: org.apache.spark ? spark-token-provider-kafka-0-10_2.12 ? 3.5.1 (mvnrepository.com)
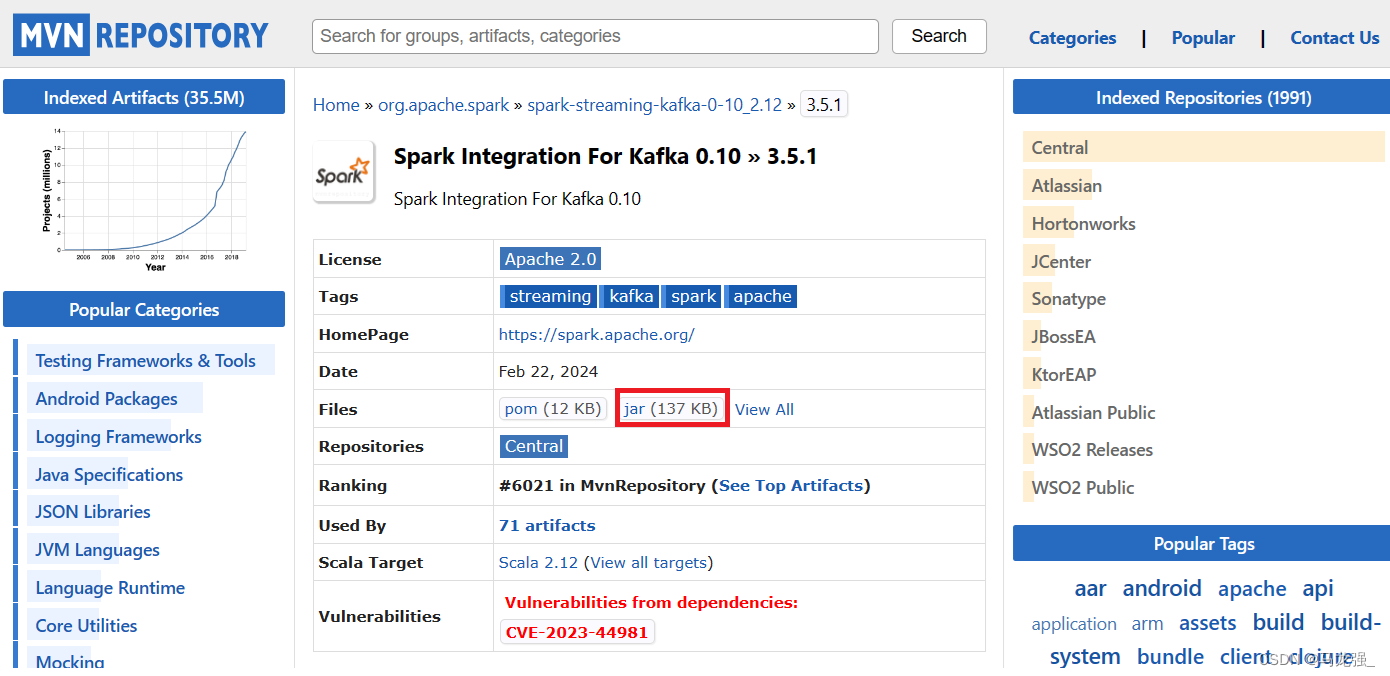
進入下載頁面以后,如下圖所示,點擊紅色方框內的“jar”,就可以下載JAR包了。
五、編寫Spark Streaming程序使用Kafka數據源
1.編寫生產者(Producer)程序
(1)新打開一個終端,然后,執行如下命令創建代碼目錄和代碼文件:
cd /usr/local/spark-3.5.1
mkdir mycode
cd ./mycode
mkdir kafka
mkdir -p kafka/src/main/scala
vi kafka/src/main/scala/KafkaWordProducer.scala(2)使用vi編輯器新建了KafkaWordProducer.scala
它是用來產生一系列字符串的程序,會產生隨機的整數序列,每個整數被當作一個單詞,提供給KafkaWordCount程序去進行詞頻統計。請在KafkaWordProducer.scala中輸入以下代碼:
import java.util.HashMap
import org.apache.kafka.clients.producer.{KafkaProducer, ProducerConfig, ProducerRecord}
import org.apache.spark.SparkConf
import org.apache.spark.streaming._
import org.apache.spark.streaming.kafka010._
object KafkaWordProducer {def main(args: Array[String]) {if (args.length < 4) {System.err.println("Usage: KafkaWordProducer <metadataBrokerList> <topic> " +"<messagesPerSec> <wordsPerMessage>")System.exit(1)}val Array(brokers, topic, messagesPerSec, wordsPerMessage) = args// Zookeeper connection propertiesval props = new HashMap[String, Object]()props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, brokers)props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer")props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer")val producer = new KafkaProducer[String, String](props)// Send some messageswhile(true) {(1 to messagesPerSec.toInt).foreach { messageNum =>val str = (1 to wordsPerMessage.toInt).map(x => scala.util.Random.nextInt(10).
toString).mkString(" ")print(str)println()val message = new ProducerRecord[String, String](topic, null, str)producer.send(message)}Thread.sleep(1000)}}
}2.編寫消費者(Consumer)程序
在“/usr/local/spark-3.5.1/mycode/kafka/src/main/scala”目錄下創建文件KafkaWordCount.scala,用于單詞詞頻統計,它會把KafkaWordProducer發送過來的單詞進行詞頻統計,代碼內容如下:
cd /usr/local/spark-3.5.1/mycode
vi kafka/src/main/scala/KafkaWordCount.scalaimport org.apache.spark._
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.streaming._
import org.apache.spark.streaming.kafka010._
import org.apache.spark.streaming.StreamingContext._
import org.apache.spark.streaming.kafka010.KafkaUtils
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.streaming.kafka010.LocationStrategies.PreferConsistent
import org.apache.spark.streaming.kafka010.ConsumerStrategies.Subscribeobject KafkaWordCount{def main(args:Array[String]){val sparkConf = new SparkConf().setAppName("KafkaWordCount").setMaster("local[2]")val sc = new SparkContext(sparkConf)sc.setLogLevel("ERROR")val ssc = new StreamingContext(sc,Seconds(10))ssc.checkpoint("file:///usr/local/spark-3.5.1/mycode/kafka/checkpoint") //設置檢查點,如果存放在HDFS上面,則寫成類似ssc.checkpoint("/user/hadoop/checkpoint")這種形式,但是,要啟動Hadoopval kafkaParams = Map[String, Object]("bootstrap.servers" -> "localhost:9092","key.deserializer" -> classOf[StringDeserializer],"value.deserializer" -> classOf[StringDeserializer],"group.id" -> "use_a_separate_group_id_for_each_stream","auto.offset.reset" -> "latest","enable.auto.commit" -> (true: java.lang.Boolean))val topics = Array("wordsender")val stream = KafkaUtils.createDirectStream[String, String](ssc,PreferConsistent,Subscribe[String, String](topics, kafkaParams))stream.foreachRDD(rdd => {val offsetRange = rdd.asInstanceOf[HasOffsetRanges].offsetRangesval maped: RDD[(String, String)] = rdd.map(record => (record.key,record.value))val lines = maped.map(_._2)val words = lines.flatMap(_.split(" "))val pair = words.map(x => (x,1))val wordCounts = pair.reduceByKey(_+_)wordCounts.foreach(println)})ssc.startssc.awaitTermination}
}3.在路徑“file:///usr/local/spark/mycode/kafka/”下創建“checkpoint”目錄作為預寫式日志的存放路徑。
cd ./kafka
mkdir checkpoint4.繼續在當前目錄下創建StreamingExamples.scala代碼文件,用于設置log4j:
cd /usr/local/spark-3.5.1/mycode/
vi kafka/src/main/scala/StreamingExamples.scala/*StreamingExamples.scala*/
package org.apache.spark.examples.streaming
import org.apache.spark.internal.Logging
import org.apache.log4j.{Level, Logger} /** Utility functions for Spark Streaming examples. */
object StreamingExamples extends Logging {/** Set reasonable logging levels for streaming if the user has not configured log4j. */def setStreamingLogLevels() {val log4jInitialized = Logger.getRootLogger.getAllAppenders.hasMoreElementsif (!log4jInitialized) {// We first log something to initialize Spark's default logging, then we override the// logging level.logInfo("Setting log level to [WARN] for streaming example." +" To override add a custom log4j.properties to the classpath.")Logger.getRootLogger.setLevel(Level.WARN)} } } 5.編譯打包程序
現在在“/usr/local/spark-3.5.1/mycode/kafka/src/main/scala”目錄下,就有了如下3個scala文件:

然后,執行下面命令新建一個simple.sbt文件:
cd /usr/local/spark-3.5.1/mycode/kafka/
vim simple.sbt在simple.sbt中輸入以下代碼:
name := "Simple Project"
version := "1.0"
scalaVersion := "2.12.18"
libraryDependencies += "org.apache.spark" %% "spark-core" % "3.5.1"
libraryDependencies += "org.apache.spark" %% "spark-streaming" % "3.5.1" % "provided"
libraryDependencies += "org.apache.spark" %% "spark-streaming-kafka-0-10" % "3.5.1"
libraryDependencies += "org.apache.kafka" % "kafka-clients" % "2.6.0"然后執行下面命令,進行編譯打包:
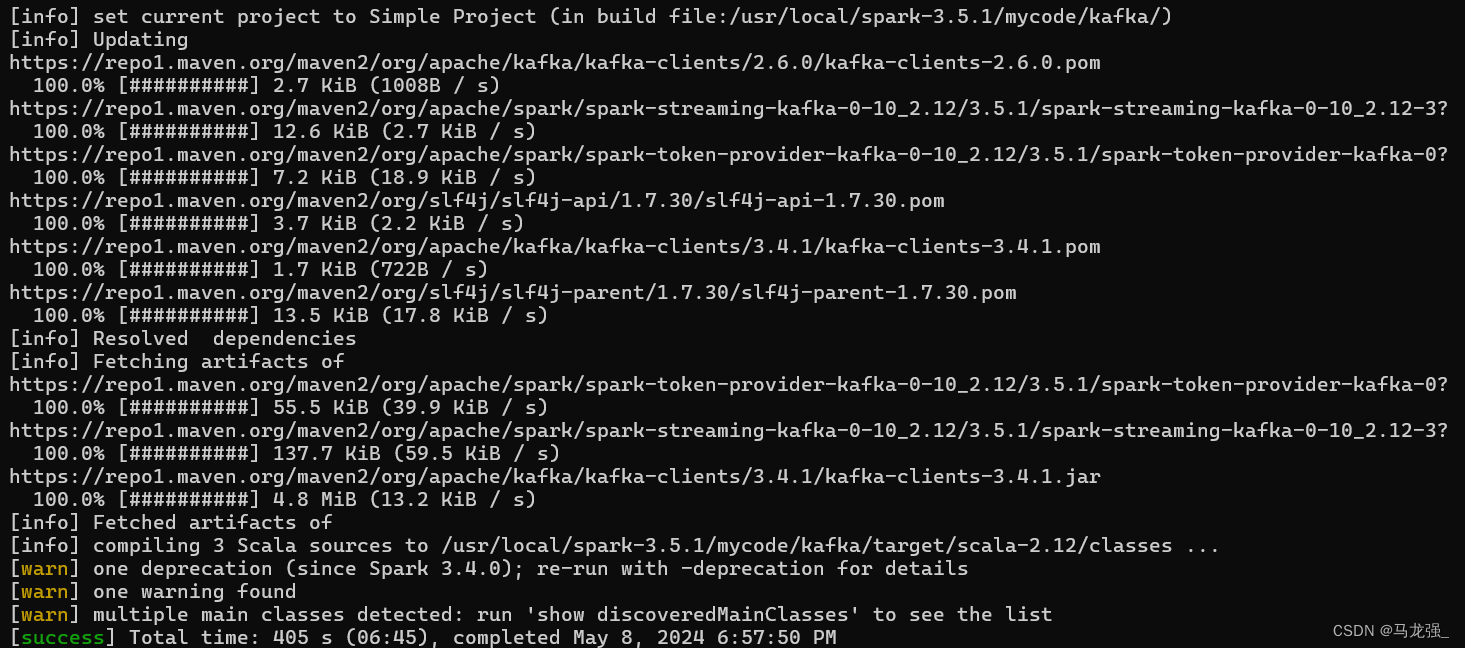
cd /usr/local/spark-3.5.1/mycode/kafka/
/usr/local/sbt-1.9.0/sbt/sbt package打包成功界面
6. 運行程序
首先,啟動Hadoop,因為如果前面KafkaWordCount.scala代碼文件中采用了ssc.checkpoint
("/user/hadoop/checkpoint")這種形式,這時的檢查點是被寫入HDFS,因此需要啟動Hadoop。啟動Hadoop的命令如下:
cd /usr/local/hadoop-2.10.1
./sbin/start-dfs.sh
或者
start-dfs.sh
start-yarn.sh啟動Hadoop成功以后,就可以測試剛才生成的詞頻統計程序了。
要注意,之前已經啟動了Zookeeper服務和Kafka服務,因為之前那些終端窗口都沒有關閉,所以,這些服務一直都在運行。如果不小心關閉了之前的終端窗口,那就參照前面的內容,再次啟動Zookeeper服務,啟動Kafka服務。
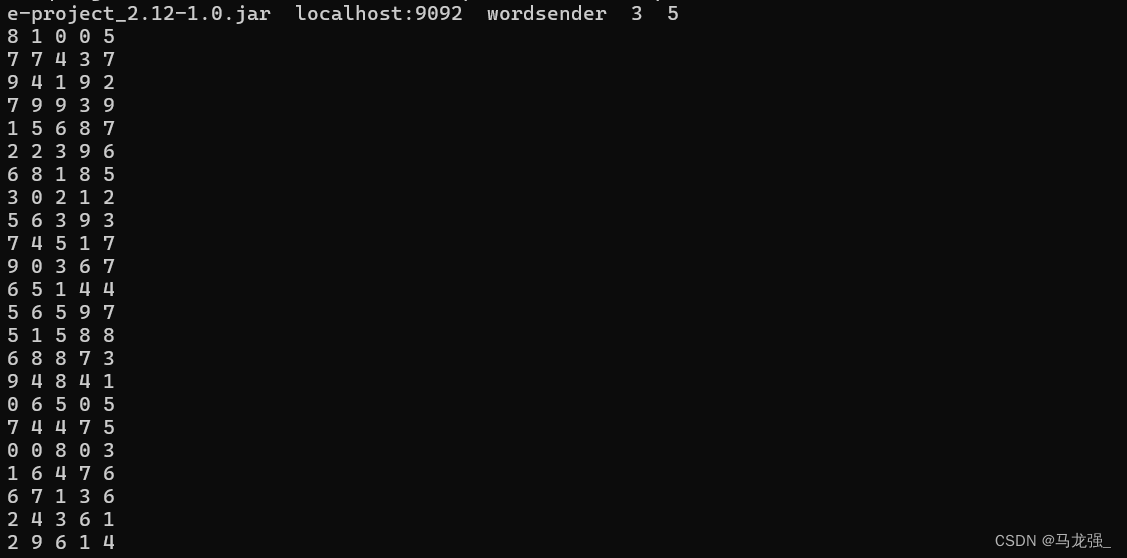
然后,新打開一個終端,執行如下命令,運行“KafkaWordProducer”程序,生成一些單詞(是一堆整數形式的單詞):
cd /usr/local/spark-3.5.1/mycode/kafka/
/usr/local/spark-3.5.1/bin/spark-submit --class "KafkaWordProducer" ./target/scala-2.12/sime-project_2.12-1.0.jar localhost:9092 wordsender 3 5注意,上面命令中,“localhost:9092 wordsender 3 5”是提供給KafkaWordProducer程序的4個輸入參數,第1個參數“localhost:9092”是Kafka的Broker的地址,第2個參數“wordsender”是Topic的名稱,我們在KafkaWordCount.scala代碼中已經把Topic名稱寫死掉,所以,KafkaWordCount程序只能接收名稱為“wordsender”的Topic。第3個參數“3”表示每秒發送3條消息,第4個參數“5”表示每條消息包含5個單詞(實際上就是5個整數)。
執行上面命令后,屏幕上會不斷滾動出現類似如下的新單詞:
不要關閉這個終端窗口,讓它一直不斷發送單詞。然后,再打開一個終端,執行下面命令,運行KafkaWordCount程序,執行詞頻統計:
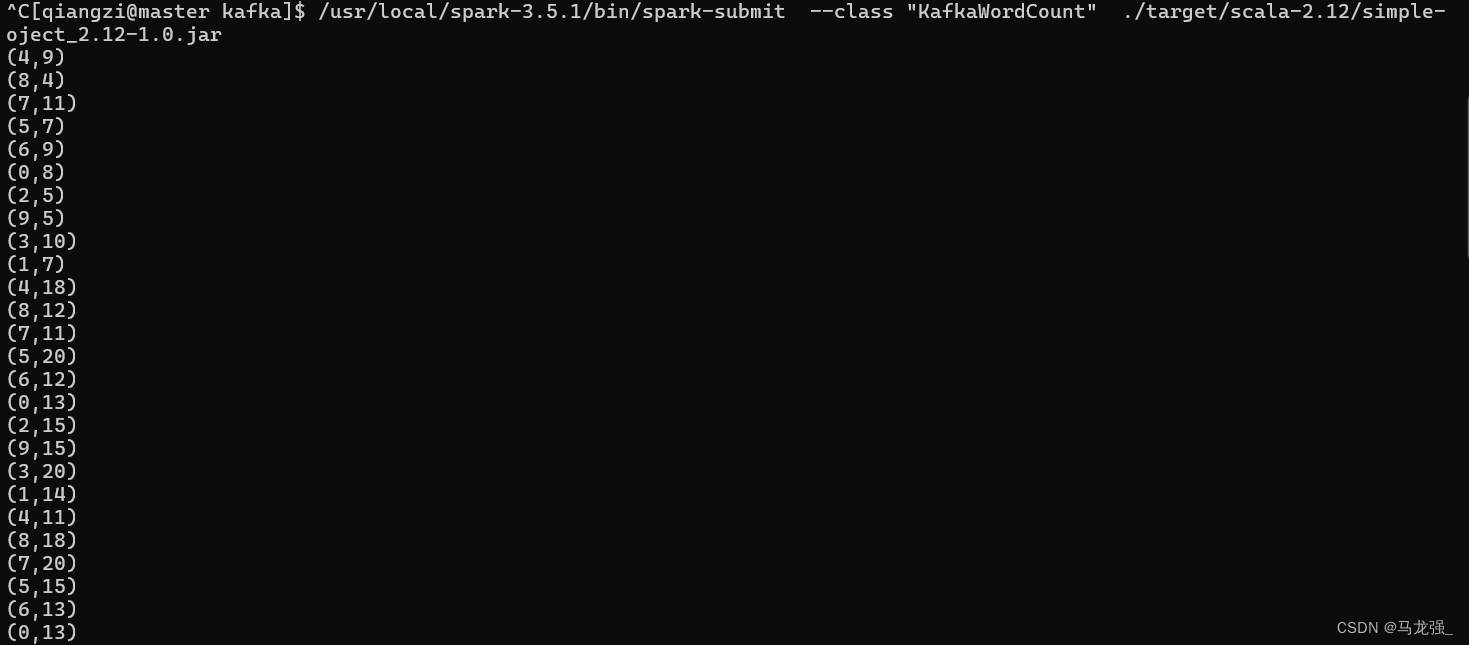
cd /usr/local/spark-3.5.1/mycode/kafka/
/usr/local/spark-3.5.1/bin/spark-submit --class "KafkaWordCount" ./target/scala-2.12/simple-oject_2.12-1.0.jar運行上面命令以后,就啟動了詞頻統計功能,屏幕上就會顯示如下類似信息:


)


)







)

——object進階)



