前言
筆記的內容主要參考與《Rust 程序設計語言》,一些也參考了《通過例子學 Rust》和《Rust語言圣經》。
Rust學習筆記分為上中下,其它兩個地址在Rust學習筆記(上)和Rust學習筆記(下)。
錯誤處理
panic! 與不可恢復的錯誤
當執行這個宏時,程序會打印出一個錯誤信息,展開并清理棧數據(也可以不清理數據就退出程序),然后接著退出。
panic! 和和其他語言不一樣的地方,像下面的代碼,這種情況下其他像 C 這樣語言會嘗試直接提供所要求的值,即便這可能不是你期望的:你會得到任何對應 vector 中這個元素的內存位置的值,甚至是這些內存并不屬于 vector 的情況。這被稱為 緩沖區溢出(buffer overread),并可能會導致安全漏洞,比如攻擊者可以像這樣操作索引來讀取儲存在數組后面不被允許的數據。為了使程序遠離這類漏洞,如果嘗試讀取一個索引不存在的元素,Rust 會停止執行并拒絕繼續。
fn main() {let v = vec![1, 2, 3];v[99];
}
遇到錯誤 Rust 還可以使用 backtrace ,得到一個詳細的錯誤,通過 RUST_BACKTRACE=1 cargo run 啟用。
Result 與可恢復的錯誤
大部分錯誤并沒有嚴重到需要程序完全停止執行。有時,一個函數會因為一個容易理解并做出反應的原因失敗。例如,如果因為打開一個并不存在的文件而失敗,此時我們可能想要創建這個文件,而不是終止進程。
enum Result<T, E> {Ok(T),Err(E),
}
現在你需要知道的就是 T 代表成功時返回的 Ok 成員中的數據的類型,而 E 代表失敗時返回的 Err 成員中的錯誤的類型。
fn main() {let f = File::open("hello.txt");let f = match f {Ok(file) => file,Err(error) => {panic!("Problem opening the file: {:?}", error)},};
}// 還可以匹配不同的錯誤
use std::fs::File;
use std::io::ErrorKind;fn main() {let f = File::open("hello.txt");let f = match f {Ok(file) => file,Err(error) => match error.kind() {ErrorKind::NotFound => match File::create("hello.txt") {Ok(fc) => fc,Err(e) => panic!("Problem creating the file: {:?}", e),},other_error => panic!("Problem opening the file: {:?}", other_error),},};
}
unwrap 和 expect
match 能夠勝任它的工作,不過它可能有點冗長并且不總是能很好的表明其意圖。Result<T, E> 類型定義了很多輔助方法來處理各種情況。其中之一叫做 unwrap,它的實現就類似于示例 9-4 中的 match 語句。如果 Result 值是成員 Ok,unwrap 會返回 Ok 中的值。如果 Result 是成員 Err,unwrap 會為我們調用 panic!。這里是一個實踐 unwrap 的例子:
use std::fs::File;fn main() {let f = File::open("hello.txt").unwrap();
}
還有另一個類似于 unwrap 的方法叫做 expect,不過它允許自定義錯誤。
use std::fs::File;fn main() {let f = File::open("hello.txt").expect("Failed to open hello.txt");
}
傳播錯誤
Result<String, io::Error>,這意味著函數返回一個 Result<T, E> 類型的值,其中泛型參數 T 的具體類型是 String,而 E 的具體類型是 io::Error。如果這個函數沒有出任何錯誤成功返回,函數的調用者會收到一個包含 String 的 Ok 值 。如果函數遇到任何錯誤,函數的調用者會收到一個 Err 值,它儲存了一個包含更多這個問題相關信息的 io::Error 實例。
fn read_username_from_file() -> Result<String, io::Error> {let f = File::open("hello.txt");let mut f = match f {Ok(file) => file,Err(e) => return Err(e),};let mut s = String::new();match f.read_to_string(&mut s) {Ok(_) => Ok(s),Err(e) => Err(e),}
}
?簡寫
// 等同于上面代碼,如果是ok會繼續執行,Err的話結束程序
fn read_username_from_file() -> Result<String, io::Error> {// 文章中提到,?會自動匹配你想要的返回錯我類型let mut f = File::open("hello.txt")?;let mut s = String::new();f.read_to_string(&mut s)?;Ok(s)
}// 更簡潔的方式
fn read_username_from_file() -> Result<String, io::Error> {let mut s = String::new();File::open("hello.txt")?.read_to_string(&mut s)?;Ok(s)
}
main函數返回錯誤
main 函數是特殊的,其必須返回什么類型是有限制的。main 函數的一個有效的返回值是 (),同時出于方便,另一個有效的返回值是 Result<T, E>,如下所示。Box<dyn Error> 被稱為 “trait 對象”(“trait object”),目前可以理解 Box<dyn Error> 為使用 ? 時 main 允許返回的 “任何類型的錯誤”。
use std::error::Error;
use std::fs::File;fn main() -> Result<(), Box<dyn Error>> {let f = File::open("hello.txt")?;Ok(())
}
panic還是不panic
該如何決定何時應該 panic! 以及何時應該返回 Result 呢?如果代碼 panic,就沒有恢復的可能。選擇返回 Result 值的話,就將選擇權交給了調用者,而不是代替他們做出決定。調用者可能會選擇以符合他們場景的方式嘗試恢復,或者也可能干脆就認為 Err 是不可恢復的,所以他們也可能會調用 panic! 并將可恢復的錯誤變成了不可恢復的錯誤。因此返回 Result 是定義可能會失敗的函數的一個好的默認選擇。
有一些情況 panic 比返回 Result 更為合適,不過他們并不常見。
- 示例、代碼原型和測試都非常適合 panic
- 當我們比編譯器知道更多的情況
- 錯誤處理指導原則(有害狀態并不包含預期會偶爾發生的錯誤;在此之后代碼的運行依賴于不處于這種有害狀態;當沒有可行的手段來將有害狀態信息編碼進所使用的類型中的情況)
- 創建自定義類型進行有效性驗證
泛型、trait與生命周期
泛型
在函數定義中使用泛型
我們可以使用泛型為像函數簽名或結構體這樣的項創建定義,這樣它們就可以用于多種不同的具體數據類型。如下圖,兩個只在名稱和簽名中類型有所不同的函數,可以利用泛型優化它們。
fn largest_i32(list: &[i32]) -> i32 {let mut largest = list[0];for &item in list.iter() {if item > largest {largest = item;}}largest
}fn largest_char(list: &[char]) -> char {let mut largest = list[0];for &item in list.iter() {if item > largest {largest = item;}}largest
}fn main() {let number_list = vec![34, 50, 25, 100, 65];let result = largest_i32(&number_list);println!("The largest number is {}", result);let char_list = vec!['y', 'm', 'a', 'q'];let result = largest_char(&char_list);println!("The largest char is {}", result);
}
fn largest<T>(list: &[T]) -> T {let mut largest = list[0];for &item in list.iter() {// 這里會報錯if item > largest {largest = item;}}largest
}fn main() {let number_list = vec![34, 50, 25, 100, 65];let result = largest(&number_list);println!("The largest number is {}", result);let char_list = vec!['y', 'm', 'a', 'q'];let result = largest(&char_list);println!("The largest char is {}", result);
}
選擇 T 是因為 Rust 的習慣是讓變量名盡量短,通常就只有一個字母,同時 Rust 類型命名規范是駱駝命名法(CamelCase)。T 作為 “type” 的縮寫是大部分 Rust 程序員的首選。
那里會報錯是因為,注釋中提到了 std::cmp::PartialOrd,這是一個 trait,這個錯誤表明 largest 的函數體不能適用于 T 的所有可能的類型。因為在函數體需要比較 T 類型的值,不過它只能用于我們知道如何排序的類型。為了開啟比較功能,標準庫中定義的 std::cmp::PartialOrd trait 可以實現類型的比較功能。
結構體定義中的泛型
這個定義表明結構體 Point<T> 對于一些類型 T 是泛型的,而且字段 x 和 y 都是相同類型的,無論它具體是何類型。
struct Point<T> {x: T,y: T,
}fn main() {let integer = Point { x: 5, y: 10 };let float = Point { x: 1.0, y: 4.0 };
}
不同類型的
struct Point<T, U> {x: T,y: U,
}fn main() {let both_integer = Point { x: 5, y: 10 };let both_float = Point { x: 1.0, y: 4.0 };let integer_and_float = Point { x: 5, y: 4.0 };
}
枚舉定義中的泛型
enum Option<T> {Some(T),None,
}enum Result<T, E> {Ok(T),Err(E),
}
方法定義中的泛型
在 impl 之后聲明泛型 T ,這樣 Rust 就知道 Point 的尖括號中的類型是泛型而不是具體類型。(不用糾結這里了,為什么 impl 后要加 T,就按它的理解)
struct Point<T> {x: T,y: T,
}impl<T> Point<T> {fn x(&self) -> &T {&self.x}
}fn main() {let p = Point { x: 5, y: 10 };println!("p.x = {}", p.x());
}
泛型代碼的性能
Rust 實現了泛型,使得使用泛型類型參數的代碼相比使用具體類型并沒有任何速度上的損失。Rust 通過在編譯時進行泛型代碼的單態化(monomorphization)來保證效率。單態化是一個通過填充編譯時使用的具體類型,將通用代碼轉換為特定代碼的過程。
trait 定義共享的行為
一個類型的行為由其可供調用的方法構成。如果可以對不同類型調用相同的方法的話,這些類型就可以共享相同的行為了。trait 定義是一種將方法簽名組合起來的方法,目的是定義一個實現某些目的所必需的行為的集合。
為類實現trait
// 大寫
pub trait Summary {fn summarize(&self) -> String;
}pub struct NewsArticle {pub headline: String,pub location: String,pub author: String,pub content: String,
}impl Summary for NewsArticle {fn summarize(&self) -> String {format!("{}, by {} ({})", self.headline, self.author, self.location)}
}pub struct Tweet {pub username: String,pub content: String,pub reply: bool,pub retweet: bool,
}impl Summary for Tweet {fn summarize(&self) -> String {format!("{}: {}", self.username, self.content)}
}let tweet = Tweet {username: String::from("horse_ebooks"),content: String::from("of course, as you probably already know, people"),reply: false,retweet: false,
};println!("1 new tweet: {}", tweet.summarize());
如果這個 lib.rs 是對應 aggregator crate 的,而別人想要利用我們 crate 的功能為其自己的庫作用域中的結構體實現 Summary trait。首先他們需要將 trait 引入作用域。這可以通過指定 use aggregator::Summary; 實現,這樣就可以為其類型實現 Summary trait 了。Summary 還必須是公有 trait 使得其他 crate 可以實現它,
實現 trait 時需要注意的一個限制是,只有當 trait 或者要實現 trait 的類型位于 crate 的本地作用域時,才能為該類型實現 trait。例如,可以為 aggregator crate 的自定義類型 Tweet 實現如標準庫中的 Display trait,這是因為 Tweet 類型位于 aggregator crate 本地的作用域中。類似地,也可以在 aggregator crate 中為 Vec<T> 實現 Summary,這是因為 Summary trait 位于 aggregator crate 本地作用域中。
但是不能為外部類型實現外部 trait。例如,不能在 aggregator crate 中為 Vec<T> 實現 Display trait。這是因為 Display 和 Vec<T> 都定義于標準庫中,它們并不位于 aggregator crate 本地作用域中。這個限制是被稱為 相干性(coherence) 的程序屬性的一部分,或者更具體的說是 孤兒規則(orphan rule),其得名于不存在父類型。這條規則確保了其他人編寫的代碼不會破壞你代碼,反之亦然。沒有這條規則的話,兩個 crate 可以分別對相同類型實現相同的 trait,而 Rust 將無從得知應該使用哪一個實現。
(這段代碼沒有違反孤兒規則(orphan rule),因為至少有一方(trait 或類型)是在本地 crate 中定義的。孤兒規則防止你為不在你的 crate 中定義的類型實現不在你的 crate 中定義的 trait。在這個例子中,CommandError是在你的 crate 中定義的,而fmt::Display trait 是標準庫提供的。這樣的實現是被允許的,因為它滿足了孤兒規則的條件之一:要實現的類型(CommandError)是本地定義的。)
默認實現
pub trait Summary {fn summarize(&self) -> String {String::from("(Read more...)")}// 可以有多個fn summarize(&self) -> String {format!("(Read more from {}...)", self.summarize_author())}
}pub struct NewsArticle {pub headline: String,pub location: String,pub author: String,pub content: String,
}// 指定一個空的impl,也可只實現個別trait
impl Summary for NewsArticle {}fn main() {let article = NewsArticle {headline: String::from("Penguins win the Stanley Cup Championship!"),location: String::from("Pittsburgh, PA, USA"),author: String::from("Iceburgh"),content: String::from("The Pittsburgh Penguins once again are the besthockey team in the NHL."),};println!("New article available! {}", article.summarize());
}
trait作為參數
可以將傳遞 NewsArticle 或 Tweet 的實例來調用 notify。
外面可以直接用,為什么要套個函數?方便代碼重用,這樣限制了只有實現trait的類才能用。
pub fn notify(item: impl Summary) {println!("Breaking news! {}", item.summarize());
}
Trait Bound 語法
上面的代碼可以變成這樣。
pub fn notify<T: Summary>(item: T) {println!("Breaking news! {}", item.summarize());
}pub fn notify(item1: impl Summary, item2: impl Summary) {
pub fn notify<T: Summary>(item1: T, item2: T) {
通過 + 指定多個 trait bound
pub fn notify(item: impl Summary + Display) {
pub fn notify<T: Summary + Display>(item: T) {
通過 where 簡化 trait bound
fn some_function<T: Display + Clone, U: Clone + Debug>(t: T, u: U) -> i32 {
fn some_function<T, U>(t: T, u: U) -> i32where T: Display + Clone,U: Clone + Debug
{
返回實現了 trait 的類型
通過使用 impl Summary 作為返回值類型,在不確定其具體的類型的情況下。
fn returns_summarizable() -> impl Summary {Tweet {username: String::from("horse_ebooks"),content: String::from("of course, as you probably already know, people"),reply: false,retweet: false,}
}// 這樣無法運行,不能返回兩種
fn returns_summarizable(switch: bool) -> impl Summary {if switch {NewsArticle {headline: String::from("Penguins win the Stanley Cup Championship!"),location: String::from("Pittsburgh, PA, USA"),author: String::from("Iceburgh"),content: String::from("The Pittsburgh Penguins once again are the besthockey team in the NHL."),}} else {Tweet {username: String::from("horse_ebooks"),content: String::from("of course, as you probably already know, people"),reply: false,retweet: false,}}
}
使用 trait bounds 來修復 largest 函數
// 過濾掉沒有PartialOrd和Copy trait的T
fn largest<T: PartialOrd + Copy>(list: &[T]) -> T {let mut largest = list[0];for &item in list.iter() {if item > largest {largest = item;}}largest
}使用 trait bound 有條件地實現方法
更高級的那 impl 控制
use std::fmt::Display;struct Pair<T> {x: T,y: T,
}impl<T> Pair<T> {fn new(x: T, y: T) -> Self {Self {x,y,}}
}impl<T: Display + PartialOrd> Pair<T> {fn cmp_display(&self) {if self.x >= self.y {println!("The largest member is x = {}", self.x);} else {println!("The largest member is y = {}", self.y);}}
}
也可以對任何實現了特定 trait 的類型有條件地實現 trait。對任何滿足特定 trait bound 的類型實現 trait 被稱為 blanket implementations,他們被廣泛的用于 Rust 標準庫中。例如,標準庫為任何實現了 Display trait 的類型實現了 ToString trait。這個 impl 塊看起來像這樣:
impl<T: Display> ToString for T {// --snip--
}
生命周期
生命周期避免了懸垂引用(指向已經被釋放或無效內存的引用)。
下圖為借用檢查器
{let r; // ---------+-- 'a// |{ // |let x = 5; // -+-- 'b |r = &x; // | |} // -+ |// |println!("r: {}", r); // |
} // ---------+// 正確的例子#![allow(unused_variables)]
{let x = 5; // ----------+-- 'b// |let r = &x; // --+-- 'a |// | |println!("r: {}", r); // | |// --+ |
} // ----------+
函數的生命周期
下面這個會報錯,因為編譯器不知道到底返回的是x還是y,也就是無法確定生命周期。
fn main() {let string1 = String::from("abcd");let string2 = "xyz";let result = longest(string1.as_str(), string2);println!("The longest string is {}", result);
}fn longest(x: &str, y: &str) -> &str {if x.len() > y.len() {x} else {y}
}借用檢查器自身同樣也無法確定,因為它不知道 x 和 y 的生命周期是如何與返回值的生命周期相關聯的。
要解決這個問題需要用到生命周期注解,生命周期注解并不改變任何引用的生命周期的長短,它用于描述多個引用生命周期相互的關系。
// 這里我們想要告訴Rust關于參數中的引用和返回值之間的限制是他們都必須擁有相同的生命周期
fn longest<'a>(x: &'a str, y: &'a str) -> &'a str {if x.len() > y.len() {x} else {y}
}// 就算是這樣也必須加注解,不過可以只加一個
fn longest<'a>(x: &'a str, y: &str) -> &'a str {x
}
當具體的引用被傳遞給 longest 時,被 'a 所替代的具體生命周期是 x 的作用域與 y 的作用域相重疊的那一部分。換一種說法就是泛型生命周期 'a 的具體生命周期等同于 x 和 y 的生命周期中較小的那一個。因為我們用相同的生命周期參數 'a 標注了返回的引用值,所以返回的引用值就能保證在 x 和 y 中較短的那個生命周期結束之前保持有效。
另一個問題,當從函數返回一個引用,返回值的生命周期參數需要與一個參數的生命周期參數相匹配。如果返回的引用 沒有 指向任何一個參數,那么唯一的可能就是它指向一個函數內部創建的值,它將會是一個懸垂引用,因為它將會在函數結束時離開作用域。像下面的代碼會報錯。
這是因為返回值的生命周期與參數完全沒有關聯。 result 在 longest 函數的結尾將離開作用域并被清理,而我們嘗試從函數返回一個 result 的引用。解決方案是返回一個有所有權的數據類型而不是一個引用,這樣函數調用者就需要負責清理這個值了。
fn longest<'a>(x: &str, y: &str) -> &'a str {let result = String::from("really long string");result.as_str()
}
結構體中的生命周期
比如下面的結構體,用到了&str,就需要加聲明周期。為什么?因為&str是一個引用,也就是這個struct拿不到它的所有權,所以很有肯能,在這個struct使用的過程中,&str失效了,造成錯誤。所有必須讓這個結構體的生命周期和&str一樣。
struct ImportantExcerpt<'a> {part: &'a str,
}
聲明周期的省略(lifetime elision)
編譯器采用三條規則來判斷引用何時不需要明確的注解。
第一條,每一個是引用的參數都有它自己的生命周期參數。
第二條,如果只有一個輸入生命周期參數,那么它被賦予所有輸出生命周期參數。
第三條,如果方法有多個輸入生命周期參數并且其中一個參數是 &self 或 &mut self,說明是個對象的方法, 那么所有輸出生命周期參數被賦予 self 的生命周期。為什么這么規定呢?我覺得記住就行,就是這么設計的,那難道聲明周期高于這個對象嗎?
fn first_word(s: &str) -> &str
// 根據第一條規則變為
fn first_word<'a>(s: &'a str) -> &str
// 根據第二條規則變為
fn first_word<'a>(s: &'a str) -> &'a str// 根據第一條規則變為
fn longest(x: &str, y: &str) -> &str
// 根據第一條規則變為
fn longest<'a, 'b>(x: &'a str, y: &'b str) -> &str
// 根據第二條規則不成立
方法中的聲明周期
struct Book<'a> {name: &'a str,
}
impl<'a> Book<'a> {// 更具第三規則省略聲明周期的標注fn get_prefix(&self) -> &str {&self.name[..3]}
}
靜態生命周期
(這塊我有些困惑,暫時不思考了,有機會讀一讀關于String和&str的文章)
'static,其生命周期能夠存活于整個程序期間。所有的字符串字面值都擁有 'static 生命周期。這是因為字符串的文本被直接儲存在程序的二進制文件中而這個文件總是可用的,因此所有的字符串字面值都是 'static 的。
let s: &'static str = "I have a static lifetime.";
// 這兩句是等效的
let s: &str = "I have a static lifetime.";
為什么?既然所有的字符串字面值都擁有 'static 生命周期,那么下面的代碼為什么報錯?
fn main() {{let s: &'static str = "hello world";}println!("s={}", s);
}
這里 str 的 lifetime 確實是 'static,但是它被 scope 所限制,也就是“變小”了。
還有個疑問,既然 &str 默認'static,呢么這里為什么編譯不通過呢?為什么必須加 'static。
fn get_static_message() -> &str {"Hello, I have a static lifetime."
}
具體原因不懂,我覺得可能是 'static 是一個上限,是可能被別的值所影響的,所以還是得標出來。
至于為什么 &str 都是 'static,因為它直接存儲在二進制文件內,而不是在運行時動態地存儲在堆或棧上。那為什么直接存儲在二進制文件內?因為這樣可以減少運行時的內存使用,而且字符串字面值是不變的等一些原因吧。
另外,需要注意的,只有引用有聲明周期,像下面的例子,都是直接把值 copy 出去,不存在什么聲明周期。
fn main() {let r;{let x = 5;r = x;}println!("r: {}", r);
}fn get_static_message() -> i32 {1
}
結合泛型的生命周期
fn longest_with_an_announcement<'a, T>(x: &'a str, y: &'a str, ann: T) -> &'a strwhere T: Display
{println!("Announcement! {}", ann);if x.len() > y.len() {x} else {y}
}
迭代器與閉包
閉包
閉包(closures)是可以保存進變量或作為參數傳遞給其他函數的匿名函數,并且可以使用在其所在的作用域的值
// simulated_expensive_calculation(intensity)這個函數是非常耗時的,在下面三個地方出現
// 我們其實只需要它的運行結果,所以第一種方式就是把它提出來,賦給變量
// 但這樣帶來一個問題是有些地方并不執行,比如else的if,也必須執行
// 所以第二種方式就是用閉包,它只在調用它時運行
// 但是使用了這種,在第一個if里它仍然會執行兩次
// 解決辦法為可以搞個變量在第一個if里接一下值(那直接在函數呢個辦法里,在第一個if接一下不就行了?呵呵,例子不好),另一種用srtuct(后面會寫)
fn generate_workout(intensity: u32, random_number: u32) {let expensive_closure = |num| {println!("calculating slowly...");thread::sleep(Duration::from_secs(2));num};if intensity < 25 {println!("Today, do {} pushups!",// simulated_expensive_calculation(intensity)expensive_closure(intensity));println!("Next, do {} situps!",// simulated_expensive_calculation(intensity)expensive_closure(intensity));} else {if random_number == 3 {println!("Take a break today! Remember to stay hydrated!");} else {println!("Today, run for {} minutes!",// // simulated_expensive_calculation(intensity)expensive_closure(intensity));}}
}
閉包的類型
閉包不要求像 fn 函數那樣在參數和返回值上注明類型。函數中需要類型注解是因為他們是暴露給用戶的顯式接口的一部分,如果不定義用戶無法使用。但是閉包并不用于這樣暴露給外面,只供自己使用。當然,你也可以標出來。
像下面,會報錯,這是因為每個閉包都有自己的唯一類型,不能像下面呢樣。
let example_closure = |x| x;let s = example_closure(String::from("hello"));
let n = example_closure(5);
存儲閉包的結果
可以創建一個存放閉包和調用閉包結果的結構體。該結構體只會在需要結果時執行閉包,并會緩存結果值,這樣余下的代碼就不必再負責保存結果并可以復用該值。這種模式被稱 memoization 或 lazy evaluation。
struct Cacher<T>where T: Fn(u32) -> u32
{calculation: T,value: Option<u32>,
}impl<T> Cacher<T>where T: Fn(u32) -> u32
{fn new(calculation: T) -> Cacher<T> {Cacher {// 省略的寫法calculation,value: None,}}fn value(&mut self, arg: u32) -> u32 {match self.value {// 當然這里的邏輯,當arg改變時,還是返回原來的v。可以自行設定邏輯Some(v) => v,None => {let v = (self.calculation)(arg);self.value = Some(v);v},}}
}
上面的目標將變為:
fn generate_workout(intensity: u32, random_number: u32) {let mut expensive_result = Cacher::new(|num| {println!("calculating slowly...");thread::sleep(Duration::from_secs(2));num});if intensity < 25 {println!("Today, do {} pushups!",expensive_result.value(intensity));println!("Next, do {} situps!",expensive_result.value(intensity));} else {if random_number == 3 {println!("Take a break today! Remember to stay hydrated!");} else {println!("Today, run for {} minutes!",expensive_result.value(intensity));}}
}
捕獲環境變量
像這樣,可以直接拿到 x 的值。
fn main() {let x = 4;let equal_to_x = |z| z == x;let y = 4;assert!(equal_to_x(y));
}
閉包可以通過三種方式捕獲其環境,他們直接對應函數的三種獲取參數的方式:獲取所有權,可變借用和不可變借用。這三種捕獲值的方式被編碼為如下三個 Fn trait:
FnOnce消費從周圍作用域捕獲的變量,閉包周圍的作用域被稱為其環境,environment。為了消費捕獲到的變量,閉包必須獲取其所有權并在定義閉包時將其移動進閉包。其名稱的Once部分代表了閉包不能多次獲取相同變量的所有權的事實,所以它只能被調用一次。FnMut獲取可變的借用值所以可以改變其環境Fn從其環境獲取不可變的借用值
這個要在where里寫,如果只是在函數里用,Rust會自動判斷。
另外也可以用 move 將所有權移到閉包里。
let equal_to_x = move |z| z == x;
迭代器
迭代器(iterator)負責遍歷序列中的每一項,像下面 iter() 會返回一個迭代器,然后遍歷。直接遍歷也行,因為 for 循環會幫你調用迭代器 。
let v1 = vec![1, 2, 3];
let v1_iter = v1.iter();
for val in v1_iter {println!("Got: {}", val);
}
迭代器會實現了一個叫做 Iterator 的定義于標準庫的 trait,里面都會有一個 next 方法。比如下面這樣,要注意的是聲明的迭代器需要為 mut,在迭代器上調用 next 方法改變了迭代器中用來記錄序列位置的狀態。
#[test]
fn iterator_demonstration() {let v1 = vec![1, 2, 3];let mut v1_iter = v1.iter();assert_eq!(v1_iter.next(), Some(&1));assert_eq!(v1_iter.next(), Some(&2));assert_eq!(v1_iter.next(), Some(&3));assert_eq!(v1_iter.next(), None);
}
另外iter 方法生成一個不可變引用的迭代器。如果我們需要一個獲取 v1 所有權并返回擁有所有權的迭代器,則可以調用 into_iter。類似的,如果我們希望迭代可變引用,則可以調用 iter_mut。
消費迭代器的方法
這些調用 next 方法的方法被稱為 消費適配器(consuming adaptors),因為調用他們會消耗迭代器。一個消費適配器的例子是 sum 方法。這個方法獲取迭代器的所有權并反復調用 next 來遍歷迭代器,因而會消費迭代器。調用 sum 之后不再允許使用 v1_iter 因為調用 sum 時它會獲取迭代器的所有權。
fn iterator_sum() {let v1 = vec![1, 2, 3];let v1_iter = v1.iter();let total: i32 = v1_iter.sum();assert_eq!(total, 6);
}
迭代器適配器
迭代器適配器(iterator adaptors),他們允許我們將當前迭代器變為不同類型的迭代器,還可以鏈式調用多個迭代器適配器。
map:將迭代器中的每個元素轉換為另一種形式或值。
let v1: Vec<i32> = vec![1, 2, 3];
let v2: Vec<_> = v1.iter().map(|x| x + 1).collect();
filter:用于從迭代器中篩選出滿足某個條件的元素。
shoes.into_iter().filter(|s| s.size == shoe_size).collect()
自定義迭代器
大概就是下面這樣,重點就是實現 next 方法。
struct Counter {count: u32,
}impl Counter {fn new() -> Counter {Counter { count: 0 }}
}impl Iterator for Counter {type Item = u32;// 只會從 1 數到 5 的迭代器fn next(&mut self) -> Option<Self::Item> {self.count += 1;if self.count < 6 {Some(self.count)} else {None}}
}fn calling_next_directly() {let mut counter = Counter::new();assert_eq!(counter.next(), Some(1));assert_eq!(counter.next(), Some(2));assert_eq!(counter.next(), Some(3));assert_eq!(counter.next(), Some(4));assert_eq!(counter.next(), Some(5));assert_eq!(counter.next(), None);
}
智能指針
智能指針是一類數據結構,他們的表現類似指針,但是也擁有額外的元數據和功能。而且引用是一類只借用數據的指針;相反,在大部分情況下,智能指針擁有他們指向的數據,比如String,Vec。智能指針通常使用結構體實現,區別于常規結構體的顯著特性在于其實現了 Deref 和 Drop trait。Deref trait 允許智能指針結構體實例表現的像引用一樣,這樣就可以編寫既用于引用、又用于智能指針的代碼。Drop trait 允許我們自定義當智能指針離開作用域時運行的代碼。
Box
Box<T>允許你將一個值放在堆上而不是棧上,留在棧上的則是指向堆數據的指針。除了數據被儲存在堆上而不是棧上之外,box 沒有性能損失。不過也沒有很多額外的功能。用于像是編譯時未知大小,而又想要在需要確切大小的上下文中使用這個類型值的時候;當有大量數據并希望在確保數據不被拷貝的情況下轉移所有權的時候(普通呢些i32都實現了copy trait);當希望擁有一個值并只關心它的類型是否實現了特定 trait 而不是其具體類型的時候。
它的一個應用像是可以存儲遞歸。如果正常寫的話Rust會因為不知道這個變量的大小而報錯。對于 Box<T>,因為它是一個指針,我們總是知道它需要多少空間,指針的大小并不會根據其指向的數據量而改變。意味著不同于直接儲存一個值,我們將間接的儲存一個指向值的指針。
enum List {Cons(i32, Box<List>),Nil,
}use crate::List::{Cons, Nil};fn main() {let list = Cons(1,Box::new(Cons(2,Box::new(Cons(3,Box::new(Nil))))));
}
Deref trait
Box<T> 類型是一個智能指針,因為它實現了 Deref trait,它允許 Box<T> 值被當作引用對待。當 Box<T> 值離開作用域時,由于 Box<T> 類型 Drop trait 的實現,box 所指向的堆數據也會被清除。
以下是一個簡單的解引用:
fn main() {let x = 5;let y = &x;assert_eq!(5, x);assert_eq!(5, *y);
}fn main() {let x = 5;let y = Box::new(x);assert_eq!(5, x);assert_eq!(5, *y);
}
自定義智能指針
實現 Deref trait 允許我們重載 解引用運算符(dereference operator)*(與乘法運算符或通配符相區別)。通過這種方式實現 Deref trait 的智能指針可以被當作常規引用來對待,可以編寫操作引用的代碼并用于智能指針。
use std::ops::Deref;struct MyBox<T>(T);impl<T> MyBox<T> {fn new(x: T) -> MyBox<T> {MyBox(x)}
}// 為什么這么寫,不用想呢么多了
impl<T> Deref for MyBox<T> {type Target = T;fn deref(&self) -> &T {&self.0}
}
實現之后,像下面解引用代碼就可以運行了,實際輸入*y,運行邏輯為*(y.deref())(外面還有個*是因為deref里是&self.0)
fn main() {let x = 5;let y = MyBox::new(x);assert_eq!(5, x);assert_eq!(5, *y);
}
解引用強制多態
它是 Rust 在函數或方法傳參上的一種便利。其將實現了 Deref 的類型的引用轉換為原始類型通過 Deref 所能夠轉換的類型的引用。當這種特定類型的引用作為實參傳遞給和形參類型不同的函數或方法時,解引用強制多態將自動發生。這時會有一系列的 deref 方法被調用,把我們提供的類型轉換成了參數所需的類型。
比如下面這個例子,MyBox<T> 上實現了 Deref trait,Rust 可以通過 deref 調用將 &MyBox<String> 變為 &String。標準庫中提供了 String 上的 Deref 實現,其會返回字符串 slice,這可以在 Deref 的 API 文檔中看到。Rust 再次調用 deref 將 &String 變為 &str,這就符合 hello 函數的定義了。
解引用強制多態(deref coercions)的加入使得 Rust 程序員編寫函數和方法調用時無需增加過多顯式使用 & 和 * 的引用和解引用。
fn hello(name: &str) {println!("Hello, {}!", name);
}
fn main() {let m = MyBox::new(String::from("Rust"));hello(&m);// 如果沒有deref coercionshello(&(*m)[..]);
}
如果是要處理可變引用,會用到DerefMut,具體不說了。
Drop trait
其允許我們在值要離開作用域時執行一些代碼,像是這樣
struct CustomSmartPointer {data: String,
}impl Drop for CustomSmartPointer {fn drop(&mut self) {println!("Dropping CustomSmartPointer with data `{}`!", self.data);}
}
然而,有時你可能需要提早清理某個值。一個例子是當使用智能指針管理鎖時,你可能希望強制運行 drop 方法來釋放鎖以便作用域中的其他代碼可以獲取鎖。Rust 并不允許我們主動調用 Drop trait 的 drop 方法;當我們希望在作用域結束之前就強制釋放變量的話,我們應該使用的是由標準庫提供的 std::mem::drop。類似這樣:
let c = CustomSmartPointer { data: String::from("some data") };
drop(c);
Rc<T>
Rust 有一個叫做 Rc<T> 的類型。其名稱為 引用計數(reference counting)的縮寫。引用計數意味著記錄一個值引用的數量來知曉這個值是否仍在被使用。如果某個值有零個引用,就代表沒有任何有效引用并可以被清理。Rc<T> 只能用于單線程場景;第十六章并發會涉及到如何在多線程程序中進行引用計數。
Rc<T> 用于當我們希望在堆上分配一些內存供程序的多個部分讀取,而且無法在編譯時確定程序的哪一部分會最后結束使用它的時候。
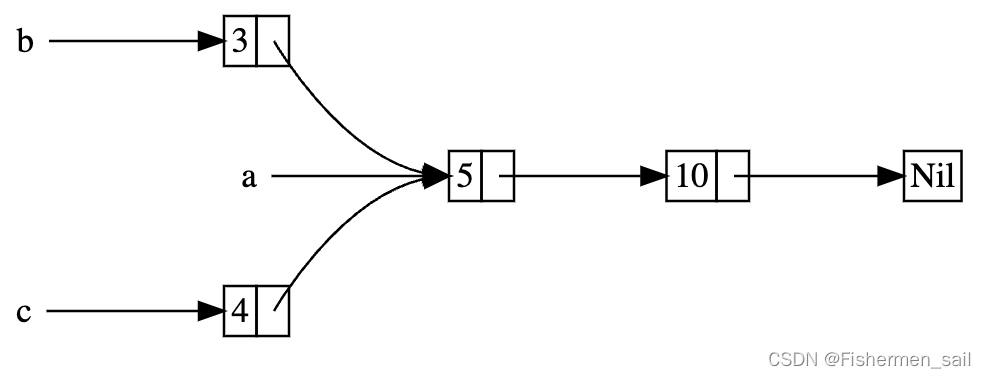
如何使用它共享數據呢,想要b和c共享5、10是難以完成的,看下面的代碼
enum List {Cons(i32, Box<List>),Nil,
}use crate::List::{Cons, Nil};fn main() {let a = Cons(5,Box::new(Cons(10,Box::new(Nil))));let b = Cons(3, Box::new(a));let c = Cons(4, Box::new(a));
}
可以改變 Cons 的定義來存放一個引用,不過接著必須指定生命周期參數。通過指定生命周期參數,表明列表中的每一個元素都至少與列表本身存在的一樣久。
也可以修改 List 的定義為使用 Rc<T> 代替 Box<T>。當創建 b 時,不同于獲取 a 的所有權,這里會克隆 a 所包含的 Rc,這會將引用計數從 1 增加到 2 并允許 a 和 b 共享 Rc 中數據的所有權。創建 c 時也會克隆 a,這會將引用計數從 2 增加為 3。每次調用 Rc::clone,Rc 中數據的引用計數都會增加,直到有零個引用之前其數據都不會被清理。當 c 離開作用域時,計數減1。
enum List {Cons(i32, Rc<List>),Nil,
}use crate::List::{Cons, Nil};
use std::rc::Rc;fn main() {let a = Rc::new(Cons(5, Rc::new(Cons(10, Rc::new(Nil)))));let b = Cons(3, Rc::clone(&a));let c = Cons(4, Rc::clone(&a));
}
當然也可以使用 a.clone() 而不是 Rc::clone(&a),Rc::clone 的實現并不像大部分類型的 clone 實現那樣對所有數據進行深拷貝。Rc::clone 只會增加引用計數,這并不會花費多少時間。深拷貝可能會花費很長時間。
查看數量是可以調用Rc::strong_count(&a)獲得
RefCell<T>
內部可變性(Interior mutability)允許你即使在有不可變引用時也可以改變數據,這通常是借用規則所不允許的。為了改變數據,該模式在數據結構中使用 unsafe 代碼來模糊 Rust 通常的可變性和借用規則。
為什么用它呢(用到再說吧)?因為一些分析是不可能的,如果 Rust 編譯器不能通過所有權規則編譯,它可能會拒絕一個正確的程序;從這種角度考慮它是保守的。RefCell<T> 正是用于當你確信代碼遵守借用規則,而編譯器不能理解和確定的時候。類似于 Rc<T>,RefCell<T> 只能用于單線程場景。在需要繞過Rust靜態借用規則(編譯時借用檢查)的情況,允許在運行時進行動態借用檢查。這樣的設計允許在特定條件下安全地進行內部可變性
Rc<T>允許相同數據有多個所有者;Box<T>和RefCell<T>有單一所有者。Box<T>允許在編譯時執行不可變或可變借用檢查;Rc<T>僅允許在編譯時執行不可變借用檢查;RefCell<T>允許在運行時執行不可變或可變借用檢查。- 因為
RefCell<T>允許在運行時執行可變借用檢查,所以我們可以在即便RefCell<T>自身是不可變的情況下修改其內部的值。
#[derive(Debug)]
enum List {Cons(Rc<RefCell<i32>>, Rc<List>),Nil,
}use crate::List::{Cons, Nil};
use std::rc::Rc;
use std::cell::RefCell;fn main() {let value = Rc::new(RefCell::new(5));let a = Rc::new(Cons(Rc::clone(&value), Rc::new(Nil)));let b = Cons(Rc::new(RefCell::new(6)), Rc::clone(&a));let c = Cons(Rc::new(RefCell::new(10)), Rc::clone(&a));*value.borrow_mut() += 10;println!("a after = {:?}", a);println!("b after = {:?}", b);println!("c after = {:?}", c);
}
引用循環與內存泄漏
可以理解為,比如a依賴b,b依賴a,在作用域結束時,Rust要先確定刪誰,這種情況,誰都刪不了。
可以用Rc::downgrade,代替Rc::clone。后者strong_count不為0就不能清理,前者weak_count不為0也能清理

















)

