1.整體流程
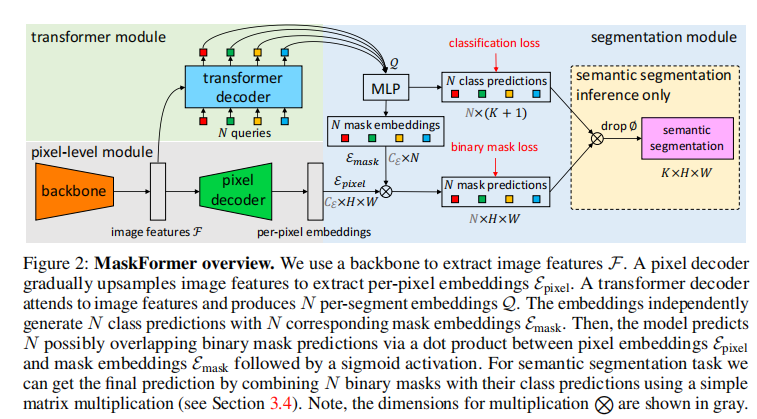
? ? ? ? Mask2former流程如圖所示,對于輸入圖片,首先經過Resnet等骨干網絡獲得多層級特征,對于獲得的多層級特征,一個方向經過pixel decoder(基于DetrTransformerEncoderLayer)得到per-pixel embedding,另外一個方向經過transformer decoder,得到mask embedding,矩陣乘法得到mask pediction,對于語義分割任務使用class prediction和mask prediction做矩陣乘法得到預測結果。
2.backbone
? ? ? ? 可以使用resnet等作為backbone,獲得多層級特征。
3.pixel decoder
? ? ? ? 這個模塊進行解碼階段的特征提取,在Mask2former中,為了減少計算量和加速收斂,采用了deformable detr的transformer的設計。具體包括:
- 多層級特征的預處理,包括維度變換、采樣點和位置編碼
- 使用deformable transformer進行特征提取
- 對特征圖進行上采樣,并進行特征融合,并根據最后一層特征圖學習一個mask
整體代碼如下:
class MSDeformAttnPixelDecoder(BaseModule):"""Pixel decoder with multi-scale deformable attention.Args:in_channels (list[int] | tuple[int]): Number of channels in theinput feature maps.strides (list[int] | tuple[int]): Output strides of feature frombackbone.feat_channels (int): Number of channels for feature.out_channels (int): Number of channels for output.num_outs (int): Number of output scales.norm_cfg (:obj:`ConfigDict` or dict): Config for normalization.Defaults to dict(type='GN', num_groups=32).act_cfg (:obj:`ConfigDict` or dict): Config for activation.Defaults to dict(type='ReLU').encoder (:obj:`ConfigDict` or dict): Config for transformerencoder. Defaults to None.positional_encoding (:obj:`ConfigDict` or dict): Config fortransformer encoder position encoding. Defaults todict(num_feats=128, normalize=True).init_cfg (:obj:`ConfigDict` or dict or list[:obj:`ConfigDict` or \dict], optional): Initialization config dict. Defaults to None."""def __init__(self,in_channels: Union[List[int],Tuple[int]] = [256, 512, 1024, 2048],strides: Union[List[int], Tuple[int]] = [4, 8, 16, 32],feat_channels: int = 256,out_channels: int = 256,num_outs: int = 3,norm_cfg: ConfigType = dict(type='GN', num_groups=32),act_cfg: ConfigType = dict(type='ReLU'),encoder: ConfigType = None,positional_encoding: ConfigType = dict(num_feats=128, normalize=True),init_cfg: OptMultiConfig = None) -> None:super().__init__(init_cfg=init_cfg)self.strides = stridesself.num_input_levels = len(in_channels)self.num_encoder_levels = \encoder.layer_cfg.self_attn_cfg.num_levelsassert self.num_encoder_levels >= 1, \'num_levels in attn_cfgs must be at least one'input_conv_list = []# from top to down (low to high resolution)for i in range(self.num_input_levels - 1,self.num_input_levels - self.num_encoder_levels - 1,-1):input_conv = ConvModule(in_channels[i],feat_channels,kernel_size=1,norm_cfg=norm_cfg,act_cfg=None,bias=True)input_conv_list.append(input_conv)self.input_convs = ModuleList(input_conv_list)self.encoder = Mask2FormerTransformerEncoder(**encoder)self.postional_encoding = SinePositionalEncoding(**positional_encoding)# high resolution to low resolutionself.level_encoding = nn.Embedding(self.num_encoder_levels,feat_channels)# fpn-like structureself.lateral_convs = ModuleList()self.output_convs = ModuleList()self.use_bias = norm_cfg is None# from top to down (low to high resolution)# fpn for the rest features that didn't pass in encoderfor i in range(self.num_input_levels - self.num_encoder_levels - 1, -1,-1):lateral_conv = ConvModule(in_channels[i],feat_channels,kernel_size=1,bias=self.use_bias,norm_cfg=norm_cfg,act_cfg=None)output_conv = ConvModule(feat_channels,feat_channels,kernel_size=3,stride=1,padding=1,bias=self.use_bias,norm_cfg=norm_cfg,act_cfg=act_cfg)self.lateral_convs.append(lateral_conv)self.output_convs.append(output_conv)self.mask_feature = Conv2d(feat_channels, out_channels, kernel_size=1, stride=1, padding=0)self.num_outs = num_outsself.point_generator = MlvlPointGenerator(strides)def init_weights(self) -> None:"""Initialize weights."""for i in range(0, self.num_encoder_levels):xavier_init(self.input_convs[i].conv,gain=1,bias=0,distribution='uniform')for i in range(0, self.num_input_levels - self.num_encoder_levels):caffe2_xavier_init(self.lateral_convs[i].conv, bias=0)caffe2_xavier_init(self.output_convs[i].conv, bias=0)caffe2_xavier_init(self.mask_feature, bias=0)normal_init(self.level_encoding, mean=0, std=1)for p in self.encoder.parameters():if p.dim() > 1:nn.init.xavier_normal_(p)# init_weights defined in MultiScaleDeformableAttentionfor m in self.encoder.layers.modules():if isinstance(m, MultiScaleDeformableAttention):m.init_weights()def forward(self, feats: List[Tensor]) -> Tuple[Tensor, Tensor]:"""Args:feats (list[Tensor]): Feature maps of each level. Each hasshape of (batch_size, c, h, w).Returns:tuple: A tuple containing the following:- mask_feature (Tensor): shape (batch_size, c, h, w).- multi_scale_features (list[Tensor]): Multi scale \features, each in shape (batch_size, c, h, w)."""# generate padding mask for each level, for each imagebatch_size = feats[0].shape[0]encoder_input_list = []padding_mask_list = []level_positional_encoding_list = []spatial_shapes = []reference_points_list = []for i in range(self.num_encoder_levels):level_idx = self.num_input_levels - i - 1feat = feats[level_idx]feat_projected = self.input_convs[i](feat)feat_hw = torch._shape_as_tensor(feat)[2:].to(feat.device)# no padding padding部分mask掉padding_mask_resized = feat.new_zeros((batch_size, ) + feat.shape[-2:], dtype=torch.bool)pos_embed = self.postional_encoding(padding_mask_resized) # 正弦位置編碼,與特征圖大小對應level_embed = self.level_encoding.weight[i] # 層級位置編碼,就是256維向量level_pos_embed = level_embed.view(1, -1, 1, 1) + pos_embed# (h_i * w_i, 2) 采樣點reference_points = self.point_generator.single_level_grid_priors(feat.shape[-2:], level_idx, device=feat.device)# normalizefeat_wh = feat_hw.unsqueeze(0).flip(dims=[0, 1])factor = feat_wh * self.strides[level_idx]reference_points = reference_points / factor# shape (batch_size, c, h_i, w_i) -> (h_i * w_i, batch_size, c) 維度轉換feat_projected = feat_projected.flatten(2).permute(0, 2, 1)level_pos_embed = level_pos_embed.flatten(2).permute(0, 2, 1)padding_mask_resized = padding_mask_resized.flatten(1)# 各個層級加入列表encoder_input_list.append(feat_projected)padding_mask_list.append(padding_mask_resized)level_positional_encoding_list.append(level_pos_embed)spatial_shapes.append(feat_hw)reference_points_list.append(reference_points)# shape (batch_size, total_num_queries),# total_num_queries=sum([., h_i * w_i,.])padding_masks = torch.cat(padding_mask_list, dim=1)# shape (total_num_queries, batch_size, c) 拼接各個層級encoder_inputs = torch.cat(encoder_input_list, dim=1)level_positional_encodings = torch.cat(level_positional_encoding_list, dim=1)# shape (num_encoder_levels, 2), from low# resolution to high resolution 各個層級的分界num_queries_per_level = [e[0] * e[1] for e in spatial_shapes]spatial_shapes = torch.cat(spatial_shapes).view(-1, 2) # 各個層級特征圖大小# shape (0, h_0*w_0, h_0*w_0+h_1*w_1, ...)level_start_index = torch.cat((spatial_shapes.new_zeros((1, )), spatial_shapes.prod(1).cumsum(0)[:-1]))reference_points = torch.cat(reference_points_list, dim=0) # 采樣參考點reference_points = reference_points[None, :, None].repeat(batch_size, 1, self.num_encoder_levels, 1)valid_radios = reference_points.new_ones( # 哪一個層級不用(batch_size, self.num_encoder_levels, 2))# shape (num_total_queries, batch_size, c) deformable transformer進行特征提取memory = self.encoder(query=encoder_inputs,query_pos=level_positional_encodings,key_padding_mask=padding_masks,spatial_shapes=spatial_shapes,reference_points=reference_points,level_start_index=level_start_index,valid_ratios=valid_radios)# (batch_size, c, num_total_queries)memory = memory.permute(0, 2, 1)# from low resolution to high resolutionouts = torch.split(memory, num_queries_per_level, dim=-1) # 將各個層級分開outs = [x.reshape(batch_size, -1, spatial_shapes[i][0],spatial_shapes[i][1]) for i, x in enumerate(outs)]# 上采樣與特征融合for i in range(self.num_input_levels - self.num_encoder_levels - 1, -1,-1):x = feats[i]cur_feat = self.lateral_convs[i](x)y = cur_feat + F.interpolate(outs[-1],size=cur_feat.shape[-2:],mode='bilinear',align_corners=False)y = self.output_convs[i](y)outs.append(y)multi_scale_features = outs[:self.num_outs]mask_feature = self.mask_feature(outs[-1]) # 根據最后一層特征圖學習一個maskreturn mask_feature, multi_scale_features?deformable transformer
? ? ? ? 在deformerable transformer中,需要根據query預測一個偏移量和注意力權重,然后根據采樣點和偏移量完成對V的采樣,并完成attention_score*v。
class MultiScaleDeformableAttention(BaseModule):"""An attention module used in Deformable-Detr.`Deformable DETR: Deformable Transformers for End-to-End Object Detection.<https://arxiv.org/pdf/2010.04159.pdf>`_.Args:embed_dims (int): The embedding dimension of Attention.Default: 256.num_heads (int): Parallel attention heads. Default: 8.num_levels (int): The number of feature map used inAttention. Default: 4.num_points (int): The number of sampling points foreach query in each head. Default: 4.im2col_step (int): The step used in image_to_column.Default: 64.dropout (float): A Dropout layer on `inp_identity`.Default: 0.1.batch_first (bool): Key, Query and Value are shape of(batch, n, embed_dim)or (n, batch, embed_dim). Default to False.norm_cfg (dict): Config dict for normalization layer.Default: None.init_cfg (obj:`mmcv.ConfigDict`): The Config for initialization.Default: None.value_proj_ratio (float): The expansion ratio of value_proj.Default: 1.0."""def __init__(self,embed_dims: int = 256,num_heads: int = 8,num_levels: int = 4,num_points: int = 4,im2col_step: int = 64,dropout: float = 0.1,batch_first: bool = False,norm_cfg: Optional[dict] = None,init_cfg: Optional[mmengine.ConfigDict] = None,value_proj_ratio: float = 1.0):super().__init__(init_cfg)if embed_dims % num_heads != 0:raise ValueError(f'embed_dims must be divisible by num_heads, 'f'but got {embed_dims} and {num_heads}')dim_per_head = embed_dims // num_headsself.norm_cfg = norm_cfgself.dropout = nn.Dropout(dropout)self.batch_first = batch_first# you'd better set dim_per_head to a power of 2# which is more efficient in the CUDA implementationdef _is_power_of_2(n):if (not isinstance(n, int)) or (n < 0):raise ValueError('invalid input for _is_power_of_2: {} (type: {})'.format(n, type(n)))return (n & (n - 1) == 0) and n != 0if not _is_power_of_2(dim_per_head):warnings.warn("You'd better set embed_dims in "'MultiScaleDeformAttention to make ''the dimension of each attention head a power of 2 ''which is more efficient in our CUDA implementation.')self.im2col_step = im2col_stepself.embed_dims = embed_dimsself.num_levels = num_levelsself.num_heads = num_headsself.num_points = num_pointsself.sampling_offsets = nn.Linear(embed_dims, num_heads * num_levels * num_points * 2)self.attention_weights = nn.Linear(embed_dims,num_heads * num_levels * num_points)value_proj_size = int(embed_dims * value_proj_ratio)self.value_proj = nn.Linear(embed_dims, value_proj_size)self.output_proj = nn.Linear(value_proj_size, embed_dims)self.init_weights()def init_weights(self) -> None:"""Default initialization for Parameters of Module."""constant_init(self.sampling_offsets, 0.)device = next(self.parameters()).devicethetas = torch.arange(self.num_heads, dtype=torch.float32,device=device) * (2.0 * math.pi / self.num_heads)grid_init = torch.stack([thetas.cos(), thetas.sin()], -1)grid_init = (grid_init /grid_init.abs().max(-1, keepdim=True)[0]).view(self.num_heads, 1, 1,2).repeat(1, self.num_levels, self.num_points, 1)for i in range(self.num_points):grid_init[:, :, i, :] *= i + 1self.sampling_offsets.bias.data = grid_init.view(-1)constant_init(self.attention_weights, val=0., bias=0.)xavier_init(self.value_proj, distribution='uniform', bias=0.)xavier_init(self.output_proj, distribution='uniform', bias=0.)self._is_init = True@no_type_check@deprecated_api_warning({'residual': 'identity'},cls_name='MultiScaleDeformableAttention')def forward(self,query: torch.Tensor,key: Optional[torch.Tensor] = None,value: Optional[torch.Tensor] = None,identity: Optional[torch.Tensor] = None,query_pos: Optional[torch.Tensor] = None,key_padding_mask: Optional[torch.Tensor] = None,reference_points: Optional[torch.Tensor] = None,spatial_shapes: Optional[torch.Tensor] = None,level_start_index: Optional[torch.Tensor] = None,**kwargs) -> torch.Tensor:"""Forward Function of MultiScaleDeformAttention.Args:query (torch.Tensor): Query of Transformer with shape(num_query, bs, embed_dims).key (torch.Tensor): The key tensor with shape`(num_key, bs, embed_dims)`.value (torch.Tensor): The value tensor with shape`(num_key, bs, embed_dims)`.identity (torch.Tensor): The tensor used for addition, with thesame shape as `query`. Default None. If None,`query` will be used.query_pos (torch.Tensor): The positional encoding for `query`.Default: None.key_padding_mask (torch.Tensor): ByteTensor for `query`, withshape [bs, num_key].reference_points (torch.Tensor): The normalized referencepoints with shape (bs, num_query, num_levels, 2),all elements is range in [0, 1], top-left (0,0),bottom-right (1, 1), including padding area.or (N, Length_{query}, num_levels, 4), addadditional two dimensions is (w, h) toform reference boxes.spatial_shapes (torch.Tensor): Spatial shape of features indifferent levels. With shape (num_levels, 2),last dimension represents (h, w).level_start_index (torch.Tensor): The start index of each level.A tensor has shape ``(num_levels, )`` and can be representedas [0, h_0*w_0, h_0*w_0+h_1*w_1, ...].Returns:torch.Tensor: forwarded results with shape[num_query, bs, embed_dims]."""if value is None:value = queryif identity is None:identity = queryif query_pos is not None:query = query + query_posif not self.batch_first:# change to (bs, num_query ,embed_dims)query = query.permute(1, 0, 2)value = value.permute(1, 0, 2)bs, num_query, _ = query.shapebs, num_value, _ = value.shapeassert (spatial_shapes[:, 0] * spatial_shapes[:, 1]).sum() == num_valuevalue = self.value_proj(value) # 全連接層,得到vif key_padding_mask is not None: # mask,可能有維度不對應的情況value = value.masked_fill(key_padding_mask[..., None], 0.0)value = value.view(bs, num_value, self.num_heads, -1)sampling_offsets = self.sampling_offsets(query).view( # 通過query預測一個偏移量,MLP層輸出通道數滿足:nem_heads*num_levels*num_points*2bs, num_query, self.num_heads, self.num_levels, self.num_points, 2)attention_weights = self.attention_weights(query).view( # 通過query預測注意力權重,num_heads*num_levels*num_pointsbs, num_query, self.num_heads, self.num_levels * self.num_points)attention_weights = attention_weights.softmax(-1)attention_weights = attention_weights.view(bs, num_query,self.num_heads,self.num_levels,self.num_points)if reference_points.shape[-1] == 2: # 進一步得到偏移后點的坐標[-1,+1]offset_normalizer = torch.stack([spatial_shapes[..., 1], spatial_shapes[..., 0]], -1)sampling_locations = reference_points[:, :, None, :, None, :] \+ sampling_offsets \/ offset_normalizer[None, None, None, :, None, :]elif reference_points.shape[-1] == 4:sampling_locations = reference_points[:, :, None, :, None, :2] \+ sampling_offsets / self.num_points \* reference_points[:, :, None, :, None, 2:] \* 0.5else:raise ValueError(f'Last dim of reference_points must be'f' 2 or 4, but get {reference_points.shape[-1]} instead.')if ((IS_CUDA_AVAILABLE and value.is_cuda)or (IS_MLU_AVAILABLE and value.is_mlu)):output = MultiScaleDeformableAttnFunction.apply( # 完成采樣和attention*vvalue, spatial_shapes, level_start_index, sampling_locations,attention_weights, self.im2col_step)else:output = multi_scale_deformable_attn_pytorch(value, spatial_shapes, sampling_locations, attention_weights)output = self.output_proj(output) # 輸出的全連接層if not self.batch_first:# (num_query, bs ,embed_dims)output = output.permute(1, 0, 2)return self.dropout(output) + identity # dropout和殘差def multi_scale_deformable_attn_pytorch(value: torch.Tensor, value_spatial_shapes: torch.Tensor,sampling_locations: torch.Tensor,attention_weights: torch.Tensor) -> torch.Tensor:"""CPU version of multi-scale deformable attention.Args:value (torch.Tensor): The value has shape(bs, num_keys, num_heads, embed_dims//num_heads)value_spatial_shapes (torch.Tensor): Spatial shape ofeach feature map, has shape (num_levels, 2),last dimension 2 represent (h, w)sampling_locations (torch.Tensor): The location of sampling points,has shape(bs ,num_queries, num_heads, num_levels, num_points, 2),the last dimension 2 represent (x, y).attention_weights (torch.Tensor): The weight of sampling points usedwhen calculate the attention, has shape(bs ,num_queries, num_heads, num_levels, num_points),Returns:torch.Tensor: has shape (bs, num_queries, embed_dims)"""bs, _, num_heads, embed_dims = value.shape_, num_queries, num_heads, num_levels, num_points, _ =\sampling_locations.shapevalue_list = value.split([H_ * W_ for H_, W_ in value_spatial_shapes],dim=1) # 分離各個層級sampling_grids = 2 * sampling_locations - 1sampling_value_list = [] # 對各個層級進行采樣for level, (H_, W_) in enumerate(value_spatial_shapes):# bs, H_*W_, num_heads, embed_dims -># bs, H_*W_, num_heads*embed_dims -># bs, num_heads*embed_dims, H_*W_ -># bs*num_heads, embed_dims, H_, W_value_l_ = value_list[level].flatten(2).transpose(1, 2).reshape(bs * num_heads, embed_dims, H_, W_)# bs, num_queries, num_heads, num_points, 2 -># bs, num_heads, num_queries, num_points, 2 -># bs*num_heads, num_queries, num_points, 2sampling_grid_l_ = sampling_grids[:, :, :,level].transpose(1, 2).flatten(0, 1)# bs*num_heads, embed_dims, num_queries, num_pointssampling_value_l_ = F.grid_sample(value_l_,sampling_grid_l_,mode='bilinear',padding_mode='zeros',align_corners=False)sampling_value_list.append(sampling_value_l_)# (bs, num_queries, num_heads, num_levels, num_points) -># (bs, num_heads, num_queries, num_levels, num_points) -># (bs, num_heads, 1, num_queries, num_levels*num_points)attention_weights = attention_weights.transpose(1, 2).reshape(bs * num_heads, 1, num_queries, num_levels * num_points) # attention*Voutput = (torch.stack(sampling_value_list, dim=-2).flatten(-2) *attention_weights).sum(-1).view(bs, num_heads * embed_dims,num_queries)return output.transpose(1, 2).contiguous()4.transformer decoder
? ? ? ? transformer decoder預測一組mask,每個mask包含了預測的實例對象相關的信息。具體流程為:
- 首先,初始化一組query
- ?得到query的類別預測,mask預測,同時得到cross attention的attention mask
- 經過交叉注意力和自注意力進行特征提取與特征融合
交叉注意力與自注意力:
class Mask2FormerTransformerDecoderLayer(DetrTransformerDecoderLayer):"""Implements decoder layer in Mask2Former transformer."""def forward(self,query: Tensor,key: Tensor = None,value: Tensor = None,query_pos: Tensor = None,key_pos: Tensor = None,self_attn_mask: Tensor = None,cross_attn_mask: Tensor = None,key_padding_mask: Tensor = None,**kwargs) -> Tensor:"""Args:query (Tensor): The input query, has shape (bs, num_queries, dim).key (Tensor, optional): The input key, has shape (bs, num_keys,dim). If `None`, the `query` will be used. Defaults to `None`.value (Tensor, optional): The input value, has the same shape as`key`, as in `nn.MultiheadAttention.forward`. If `None`, the`key` will be used. Defaults to `None`.query_pos (Tensor, optional): The positional encoding for `query`,has the same shape as `query`. If not `None`, it will be addedto `query` before forward function. Defaults to `None`.key_pos (Tensor, optional): The positional encoding for `key`, hasthe same shape as `key`. If not `None`, it will be added to`key` before forward function. If None, and `query_pos` has thesame shape as `key`, then `query_pos` will be used for`key_pos`. Defaults to None.self_attn_mask (Tensor, optional): ByteTensor mask, has shape(num_queries, num_keys), as in `nn.MultiheadAttention.forward`.Defaults to None.cross_attn_mask (Tensor, optional): ByteTensor mask, has shape(num_queries, num_keys), as in `nn.MultiheadAttention.forward`.Defaults to None.key_padding_mask (Tensor, optional): The `key_padding_mask` of`self_attn` input. ByteTensor, has shape (bs, num_value).Defaults to None.Returns:Tensor: forwarded results, has shape (bs, num_queries, dim)."""query = self.cross_attn(query=query,key=key,value=value,query_pos=query_pos,key_pos=key_pos,attn_mask=cross_attn_mask,key_padding_mask=key_padding_mask,**kwargs)query = self.norms[0](query)query = self.self_attn(query=query,key=query,value=query,query_pos=query_pos,key_pos=query_pos,attn_mask=self_attn_mask,**kwargs)query = self.norms[1](query)query = self.ffn(query)query = self.norms[2](query)return querypixel decoder和transformer decoder網絡流程:
class Mask2FormerHead(MaskFormerHead):"""Implements the Mask2Former head.See `Masked-attention Mask Transformer for Universal ImageSegmentation <https://arxiv.org/pdf/2112.01527>`_ for details.Args:in_channels (list[int]): Number of channels in the input feature map.feat_channels (int): Number of channels for features.out_channels (int): Number of channels for output.num_things_classes (int): Number of things.num_stuff_classes (int): Number of stuff.num_queries (int): Number of query in Transformer decoder.pixel_decoder (:obj:`ConfigDict` or dict): Config for pixeldecoder. Defaults to None.enforce_decoder_input_project (bool, optional): Whether to adda layer to change the embed_dim of tranformer encoder inpixel decoder to the embed_dim of transformer decoder.Defaults to False.transformer_decoder (:obj:`ConfigDict` or dict): Config fortransformer decoder. Defaults to None.positional_encoding (:obj:`ConfigDict` or dict): Config fortransformer decoder position encoding. Defaults todict(num_feats=128, normalize=True).loss_cls (:obj:`ConfigDict` or dict): Config of the classificationloss. Defaults to None.loss_mask (:obj:`ConfigDict` or dict): Config of the mask loss.Defaults to None.loss_dice (:obj:`ConfigDict` or dict): Config of the dice loss.Defaults to None.train_cfg (:obj:`ConfigDict` or dict, optional): Training config ofMask2Former head.test_cfg (:obj:`ConfigDict` or dict, optional): Testing config ofMask2Former head.init_cfg (:obj:`ConfigDict` or dict or list[:obj:`ConfigDict` or \dict], optional): Initialization config dict. Defaults to None."""def __init__(self,in_channels: List[int],feat_channels: int,out_channels: int,num_things_classes: int = 80,num_stuff_classes: int = 53,num_queries: int = 100,num_transformer_feat_level: int = 3,pixel_decoder: ConfigType = ...,enforce_decoder_input_project: bool = False,transformer_decoder: ConfigType = ...,positional_encoding: ConfigType = dict(num_feats=128, normalize=True),loss_cls: ConfigType = dict(type='CrossEntropyLoss',use_sigmoid=False,loss_weight=2.0,reduction='mean',class_weight=[1.0] * 133 + [0.1]),loss_mask: ConfigType = dict(type='CrossEntropyLoss',use_sigmoid=True,reduction='mean',loss_weight=5.0),loss_dice: ConfigType = dict(type='DiceLoss',use_sigmoid=True,activate=True,reduction='mean',naive_dice=True,eps=1.0,loss_weight=5.0),train_cfg: OptConfigType = None,test_cfg: OptConfigType = None,init_cfg: OptMultiConfig = None,**kwargs) -> None:super(AnchorFreeHead, self).__init__(init_cfg=init_cfg)self.num_things_classes = num_things_classesself.num_stuff_classes = num_stuff_classesself.num_classes = self.num_things_classes + self.num_stuff_classesself.num_queries = num_queriesself.num_transformer_feat_level = num_transformer_feat_levelself.num_heads = transformer_decoder.layer_cfg.cross_attn_cfg.num_headsself.num_transformer_decoder_layers = transformer_decoder.num_layersassert pixel_decoder.encoder.layer_cfg. \self_attn_cfg.num_levels == num_transformer_feat_levelpixel_decoder_ = copy.deepcopy(pixel_decoder)pixel_decoder_.update(in_channels=in_channels,feat_channels=feat_channels,out_channels=out_channels)self.pixel_decoder = MODELS.build(pixel_decoder_)self.transformer_decoder = Mask2FormerTransformerDecoder(**transformer_decoder)self.decoder_embed_dims = self.transformer_decoder.embed_dimsself.decoder_input_projs = ModuleList()# from low resolution to high resolutionfor _ in range(num_transformer_feat_level):if (self.decoder_embed_dims != feat_channelsor enforce_decoder_input_project):self.decoder_input_projs.append(Conv2d(feat_channels, self.decoder_embed_dims, kernel_size=1))else:self.decoder_input_projs.append(nn.Identity())self.decoder_positional_encoding = SinePositionalEncoding(**positional_encoding)self.query_embed = nn.Embedding(self.num_queries, feat_channels)self.query_feat = nn.Embedding(self.num_queries, feat_channels)# from low resolution to high resolutionself.level_embed = nn.Embedding(self.num_transformer_feat_level,feat_channels)self.cls_embed = nn.Linear(feat_channels, self.num_classes + 1)self.mask_embed = nn.Sequential(nn.Linear(feat_channels, feat_channels), nn.ReLU(inplace=True),nn.Linear(feat_channels, feat_channels), nn.ReLU(inplace=True),nn.Linear(feat_channels, out_channels))self.test_cfg = test_cfgself.train_cfg = train_cfgif train_cfg:self.assigner = TASK_UTILS.build(self.train_cfg['assigner'])self.sampler = TASK_UTILS.build(self.train_cfg['sampler'], default_args=dict(context=self))self.num_points = self.train_cfg.get('num_points', 12544)self.oversample_ratio = self.train_cfg.get('oversample_ratio', 3.0)self.importance_sample_ratio = self.train_cfg.get('importance_sample_ratio', 0.75)self.class_weight = loss_cls.class_weightself.loss_cls = MODELS.build(loss_cls)self.loss_mask = MODELS.build(loss_mask)self.loss_dice = MODELS.build(loss_dice)def init_weights(self) -> None:for m in self.decoder_input_projs:if isinstance(m, Conv2d):caffe2_xavier_init(m, bias=0)self.pixel_decoder.init_weights()for p in self.transformer_decoder.parameters():if p.dim() > 1:nn.init.xavier_normal_(p)def _get_targets_single(self, cls_score: Tensor, mask_pred: Tensor,gt_instances: InstanceData,img_meta: dict) -> Tuple[Tensor]:"""Compute classification and mask targets for one image.Args:cls_score (Tensor): Mask score logits from a single decoder layerfor one image. Shape (num_queries, cls_out_channels).mask_pred (Tensor): Mask logits for a single decoder layer for oneimage. Shape (num_queries, h, w).gt_instances (:obj:`InstanceData`): It contains ``labels`` and``masks``.img_meta (dict): Image informtation.Returns:tuple[Tensor]: A tuple containing the following for one image.- labels (Tensor): Labels of each image. \shape (num_queries, ).- label_weights (Tensor): Label weights of each image. \shape (num_queries, ).- mask_targets (Tensor): Mask targets of each image. \shape (num_queries, h, w).- mask_weights (Tensor): Mask weights of each image. \shape (num_queries, ).- pos_inds (Tensor): Sampled positive indices for each \image.- neg_inds (Tensor): Sampled negative indices for each \image.- sampling_result (:obj:`SamplingResult`): Sampling results."""gt_labels = gt_instances.labelsgt_masks = gt_instances.masks# sample pointsnum_queries = cls_score.shape[0]num_gts = gt_labels.shape[0]point_coords = torch.rand((1, self.num_points, 2),device=cls_score.device)# shape (num_queries, num_points)mask_points_pred = point_sample(mask_pred.unsqueeze(1), point_coords.repeat(num_queries, 1,1)).squeeze(1)# shape (num_gts, num_points)gt_points_masks = point_sample(gt_masks.unsqueeze(1).float(), point_coords.repeat(num_gts, 1,1)).squeeze(1)sampled_gt_instances = InstanceData(labels=gt_labels, masks=gt_points_masks)sampled_pred_instances = InstanceData(scores=cls_score, masks=mask_points_pred)# assign and sampleassign_result = self.assigner.assign(pred_instances=sampled_pred_instances,gt_instances=sampled_gt_instances,img_meta=img_meta)pred_instances = InstanceData(scores=cls_score, masks=mask_pred)sampling_result = self.sampler.sample(assign_result=assign_result,pred_instances=pred_instances,gt_instances=gt_instances)pos_inds = sampling_result.pos_indsneg_inds = sampling_result.neg_inds# label targetlabels = gt_labels.new_full((self.num_queries, ),self.num_classes,dtype=torch.long)labels[pos_inds] = gt_labels[sampling_result.pos_assigned_gt_inds]label_weights = gt_labels.new_ones((self.num_queries, ))# mask targetmask_targets = gt_masks[sampling_result.pos_assigned_gt_inds]mask_weights = mask_pred.new_zeros((self.num_queries, ))mask_weights[pos_inds] = 1.0return (labels, label_weights, mask_targets, mask_weights, pos_inds,neg_inds, sampling_result)def _loss_by_feat_single(self, cls_scores: Tensor, mask_preds: Tensor,batch_gt_instances: List[InstanceData],batch_img_metas: List[dict]) -> Tuple[Tensor]:"""Loss function for outputs from a single decoder layer.Args:cls_scores (Tensor): Mask score logits from a single decoder layerfor all images. Shape (batch_size, num_queries,cls_out_channels). Note `cls_out_channels` should includesbackground.mask_preds (Tensor): Mask logits for a pixel decoder for allimages. Shape (batch_size, num_queries, h, w).batch_gt_instances (list[obj:`InstanceData`]): each contains``labels`` and ``masks``.batch_img_metas (list[dict]): List of image meta information.Returns:tuple[Tensor]: Loss components for outputs from a single \decoder layer."""num_imgs = cls_scores.size(0)cls_scores_list = [cls_scores[i] for i in range(num_imgs)]mask_preds_list = [mask_preds[i] for i in range(num_imgs)](labels_list, label_weights_list, mask_targets_list, mask_weights_list,avg_factor) = self.get_targets(cls_scores_list, mask_preds_list,batch_gt_instances, batch_img_metas)# shape (batch_size, num_queries)labels = torch.stack(labels_list, dim=0)# shape (batch_size, num_queries)label_weights = torch.stack(label_weights_list, dim=0)# shape (num_total_gts, h, w)mask_targets = torch.cat(mask_targets_list, dim=0)# shape (batch_size, num_queries)mask_weights = torch.stack(mask_weights_list, dim=0)# classfication loss# shape (batch_size * num_queries, )cls_scores = cls_scores.flatten(0, 1)labels = labels.flatten(0, 1)label_weights = label_weights.flatten(0, 1)class_weight = cls_scores.new_tensor(self.class_weight)loss_cls = self.loss_cls(cls_scores,labels,label_weights,avg_factor=class_weight[labels].sum())num_total_masks = reduce_mean(cls_scores.new_tensor([avg_factor]))num_total_masks = max(num_total_masks, 1)# extract positive ones# shape (batch_size, num_queries, h, w) -> (num_total_gts, h, w)mask_preds = mask_preds[mask_weights > 0]if mask_targets.shape[0] == 0:# zero matchloss_dice = mask_preds.sum()loss_mask = mask_preds.sum()return loss_cls, loss_mask, loss_dicewith torch.no_grad():points_coords = get_uncertain_point_coords_with_randomness(mask_preds.unsqueeze(1), None, self.num_points,self.oversample_ratio, self.importance_sample_ratio)# shape (num_total_gts, h, w) -> (num_total_gts, num_points)mask_point_targets = point_sample(mask_targets.unsqueeze(1).float(), points_coords).squeeze(1)# shape (num_queries, h, w) -> (num_queries, num_points)mask_point_preds = point_sample(mask_preds.unsqueeze(1), points_coords).squeeze(1)# dice lossloss_dice = self.loss_dice(mask_point_preds, mask_point_targets, avg_factor=num_total_masks)# mask loss# shape (num_queries, num_points) -> (num_queries * num_points, )mask_point_preds = mask_point_preds.reshape(-1)# shape (num_total_gts, num_points) -> (num_total_gts * num_points, )mask_point_targets = mask_point_targets.reshape(-1)loss_mask = self.loss_mask(mask_point_preds,mask_point_targets,avg_factor=num_total_masks * self.num_points)return loss_cls, loss_mask, loss_dicedef _forward_head(self, decoder_out: Tensor, mask_feature: Tensor,attn_mask_target_size: Tuple[int, int]) -> Tuple[Tensor]:"""Forward for head part which is called after every decoder layer.Args:decoder_out (Tensor): in shape (batch_size, num_queries, c).mask_feature (Tensor): in shape (batch_size, c, h, w).attn_mask_target_size (tuple[int, int]): target attentionmask size.Returns:tuple: A tuple contain three elements.- cls_pred (Tensor): Classification scores in shape \(batch_size, num_queries, cls_out_channels). \Note `cls_out_channels` should includes background.- mask_pred (Tensor): Mask scores in shape \(batch_size, num_queries,h, w).- attn_mask (Tensor): Attention mask in shape \(batch_size * num_heads, num_queries, h, w)."""decoder_out = self.transformer_decoder.post_norm(decoder_out) # layernorm# shape (num_queries, batch_size, c)cls_pred = self.cls_embed(decoder_out) # 類別預測# shape (num_queries, batch_size, c)mask_embed = self.mask_embed(decoder_out)# shape (num_queries, batch_size, h, w) 相當于將query映射到區域mask_pred = torch.einsum('bqc,bchw->bqhw', mask_embed, mask_feature)attn_mask = F.interpolate(mask_pred,attn_mask_target_size,mode='bilinear',align_corners=False) # 下采樣到16*16大小# shape (num_queries, batch_size, h, w) -># (batch_size * num_head, num_queries, h, w) repeat為多頭attn_mask = attn_mask.flatten(2).unsqueeze(1).repeat((1, self.num_heads, 1, 1)).flatten(0, 1)attn_mask = attn_mask.sigmoid() < 0.5 # 注意力mask的定義attn_mask = attn_mask.detach()return cls_pred, mask_pred, attn_maskdef forward(self, x: List[Tensor],batch_data_samples: SampleList) -> Tuple[List[Tensor]]:"""Forward function.Args:x (list[Tensor]): Multi scale Features from theupstream network, each is a 4D-tensor.batch_data_samples (List[:obj:`DetDataSample`]): The DataSamples. It usually includes information such as`gt_instance`, `gt_panoptic_seg` and `gt_sem_seg`.Returns:tuple[list[Tensor]]: A tuple contains two elements.- cls_pred_list (list[Tensor)]: Classification logits \for each decoder layer. Each is a 3D-tensor with shape \(batch_size, num_queries, cls_out_channels). \Note `cls_out_channels` should includes background.- mask_pred_list (list[Tensor]): Mask logits for each \decoder layer. Each with shape (batch_size, num_queries, \h, w)."""batch_size = x[0].shape[0]mask_features, multi_scale_memorys = self.pixel_decoder(x)# multi_scale_memorys (from low resolution to high resolution)decoder_inputs = []decoder_positional_encodings = []for i in range(self.num_transformer_feat_level):decoder_input = self.decoder_input_projs[i](multi_scale_memorys[i]) # decoder的輸入# shape (batch_size, c, h, w) -> (batch_size, h*w, c)decoder_input = decoder_input.flatten(2).permute(0, 2, 1)level_embed = self.level_embed.weight[i].view(1, 1, -1) # 層級編碼decoder_input = decoder_input + level_embed# shape (batch_size, c, h, w) -> (batch_size, h*w, c)mask = decoder_input.new_zeros( # 初始化mask(batch_size, ) + multi_scale_memorys[i].shape[-2:],dtype=torch.bool)decoder_positional_encoding = self.decoder_positional_encoding(mask) # 位置編碼維度與mask一致decoder_positional_encoding = decoder_positional_encoding.flatten(2).permute(0, 2, 1)decoder_inputs.append(decoder_input)decoder_positional_encodings.append(decoder_positional_encoding)# shape (num_queries, c) -> (batch_size, num_queries, c)query_feat = self.query_feat.weight.unsqueeze(0).repeat( # query的特征(batch_size, 1, 1))query_embed = self.query_embed.weight.unsqueeze(0).repeat( # query的位置編碼(batch_size, 1, 1))cls_pred_list = []mask_pred_list = []# 獲得類別預測,mask預測,注意力maskcls_pred, mask_pred, attn_mask = self._forward_head(query_feat, mask_features, multi_scale_memorys[0].shape[-2:])cls_pred_list.append(cls_pred)mask_pred_list.append(mask_pred)for i in range(self.num_transformer_decoder_layers):level_idx = i % self.num_transformer_feat_level# if a mask is all True(all background), then set it all False.全為True,cross attn就失效了mask_sum = (attn_mask.sum(-1) != attn_mask.shape[-1]).unsqueeze(-1)attn_mask = attn_mask & mask_sum# cross_attn + self_attnlayer = self.transformer_decoder.layers[i]query_feat = layer( # cross attnquery=query_feat,key=decoder_inputs[level_idx],value=decoder_inputs[level_idx],query_pos=query_embed,key_pos=decoder_positional_encodings[level_idx],cross_attn_mask=attn_mask,query_key_padding_mask=None,# here we do not apply masking on padded regionkey_padding_mask=None)cls_pred, mask_pred, attn_mask = self._forward_head( # 輸出層,更新cls_pred,mask_pred,attn_maskquery_feat, mask_features, multi_scale_memorys[(i + 1) % self.num_transformer_feat_level].shape[-2:])cls_pred_list.append(cls_pred)mask_pred_list.append(mask_pred)return cls_pred_list, mask_pred_list5.標簽分配策略
? ? ? ? 標簽分配采用的是匈牙利二分圖匹配,對于匈牙利匹配,首先需要構建一個維度為num_query*num_labels的成本矩陣,成本矩陣主要由3種損失構成,即分類損失、mask損失,diceloss損失,分類損失是query預測每個label概率的負值,mask損失是一個二元交叉熵損失,dice loss是重疊度損失。然后使用匈牙利匹配方法進行匹配。
class HungarianAssigner(BaseAssigner):"""Computes one-to-one matching between predictions and ground truth.This class computes an assignment between the targets and the predictionsbased on the costs. The costs are weighted sum of some components.For DETR the costs are weighted sum of classification cost, regression L1cost and regression iou cost. The targets don't include the no_object, sogenerally there are more predictions than targets. After the one-to-onematching, the un-matched are treated as backgrounds. Thus each queryprediction will be assigned with `0` or a positive integer indicating theground truth index:- 0: negative sample, no assigned gt- positive integer: positive sample, index (1-based) of assigned gtArgs:match_costs (:obj:`ConfigDict` or dict or \List[Union[:obj:`ConfigDict`, dict]]): Match cost configs."""def __init__(self, match_costs: Union[List[Union[dict, ConfigDict]], dict,ConfigDict]) -> None:if isinstance(match_costs, dict):match_costs = [match_costs]elif isinstance(match_costs, list):assert len(match_costs) > 0, \'match_costs must not be a empty list.'self.match_costs = [TASK_UTILS.build(match_cost) for match_cost in match_costs]def assign(self,pred_instances: InstanceData,gt_instances: InstanceData,img_meta: Optional[dict] = None,**kwargs) -> AssignResult:"""Computes one-to-one matching based on the weighted costs.This method assign each query prediction to a ground truth orbackground. The `assigned_gt_inds` with -1 means don't care,0 means negative sample, and positive number is the index (1-based)of assigned gt.The assignment is done in the following steps, the order matters.1. assign every prediction to -12. compute the weighted costs3. do Hungarian matching on CPU based on the costs4. assign all to 0 (background) first, then for each matched pairbetween predictions and gts, treat this prediction as foregroundand assign the corresponding gt index (plus 1) to it.Args:pred_instances (:obj:`InstanceData`): Instances of modelpredictions. It includes ``priors``, and the priors canbe anchors or points, or the bboxes predicted by theprevious stage, has shape (n, 4). The bboxes predicted bythe current model or stage will be named ``bboxes``,``labels``, and ``scores``, the same as the ``InstanceData``in other places. It may includes ``masks``, with shape(n, h, w) or (n, l).gt_instances (:obj:`InstanceData`): Ground truth of instanceannotations. It usually includes ``bboxes``, with shape (k, 4),``labels``, with shape (k, ) and ``masks``, with shape(k, h, w) or (k, l).img_meta (dict): Image information.Returns::obj:`AssignResult`: The assigned result."""assert isinstance(gt_instances.labels, Tensor)num_gts, num_preds = len(gt_instances), len(pred_instances)gt_labels = gt_instances.labelsdevice = gt_labels.device# 1. assign -1 by default 初始化為-1assigned_gt_inds = torch.full((num_preds, ),-1,dtype=torch.long,device=device)assigned_labels = torch.full((num_preds, ),-1,dtype=torch.long,device=device)if num_gts == 0 or num_preds == 0:# No ground truth or boxes, return empty assignmentif num_gts == 0:# No ground truth, assign all to backgroundassigned_gt_inds[:] = 0return AssignResult(num_gts=num_gts,gt_inds=assigned_gt_inds,max_overlaps=None,labels=assigned_labels)# 2. compute weighted costcost_list = [] # 分類損失是query預測每個label概率的負值for match_cost in self.match_costs: # 分類損失,mask損失,diceloss(重合比例)cost = match_cost(pred_instances=pred_instances,gt_instances=gt_instances,img_meta=img_meta)cost_list.append(cost)cost = torch.stack(cost_list).sum(dim=0)# 3. do Hungarian matching on CPU using linear_sum_assignmentcost = cost.detach().cpu()if linear_sum_assignment is None:raise ImportError('Please run "pip install scipy" ''to install scipy first.')matched_row_inds, matched_col_inds = linear_sum_assignment(cost) # num_query*num_lables的cost矩陣做二分圖最大匹配matched_row_inds = torch.from_numpy(matched_row_inds).to(device)matched_col_inds = torch.from_numpy(matched_col_inds).to(device)# 4. assign backgrounds and foregrounds# assign all indices to backgrounds firstassigned_gt_inds[:] = 0# assign foregrounds based on matching results 匹配的標簽assigned_gt_inds[matched_row_inds] = matched_col_inds + 1assigned_labels[matched_row_inds] = gt_labels[matched_col_inds]return AssignResult( # 字典num_gts=num_gts,gt_inds=assigned_gt_inds,max_overlaps=None,labels=assigned_labels)?整體代碼:
class MaskFormerHead(AnchorFreeHead):"""Implements the MaskFormer head.See `Per-Pixel Classification is Not All You Need for SemanticSegmentation <https://arxiv.org/pdf/2107.06278>`_ for details.Args:in_channels (list[int]): Number of channels in the input feature map.feat_channels (int): Number of channels for feature.out_channels (int): Number of channels for output.num_things_classes (int): Number of things.num_stuff_classes (int): Number of stuff.num_queries (int): Number of query in Transformer.pixel_decoder (:obj:`ConfigDict` or dict): Config for pixeldecoder.enforce_decoder_input_project (bool): Whether to add a layerto change the embed_dim of transformer encoder in pixel decoder tothe embed_dim of transformer decoder. Defaults to False.transformer_decoder (:obj:`ConfigDict` or dict): Config fortransformer decoder.positional_encoding (:obj:`ConfigDict` or dict): Config fortransformer decoder position encoding.loss_cls (:obj:`ConfigDict` or dict): Config of the classificationloss. Defaults to `CrossEntropyLoss`.loss_mask (:obj:`ConfigDict` or dict): Config of the mask loss.Defaults to `FocalLoss`.loss_dice (:obj:`ConfigDict` or dict): Config of the dice loss.Defaults to `DiceLoss`.train_cfg (:obj:`ConfigDict` or dict, optional): Training config ofMaskFormer head.test_cfg (:obj:`ConfigDict` or dict, optional): Testing config ofMaskFormer head.init_cfg (:obj:`ConfigDict` or dict or list[:obj:`ConfigDict` or \dict], optional): Initialization config dict. Defaults to None."""def __init__(self,in_channels: List[int],feat_channels: int,out_channels: int,num_things_classes: int = 80,num_stuff_classes: int = 53,num_queries: int = 100,pixel_decoder: ConfigType = ...,enforce_decoder_input_project: bool = False,transformer_decoder: ConfigType = ...,positional_encoding: ConfigType = dict(num_feats=128, normalize=True),loss_cls: ConfigType = dict(type='CrossEntropyLoss',use_sigmoid=False,loss_weight=1.0,class_weight=[1.0] * 133 + [0.1]),loss_mask: ConfigType = dict(type='FocalLoss',use_sigmoid=True,gamma=2.0,alpha=0.25,loss_weight=20.0),loss_dice: ConfigType = dict(type='DiceLoss',use_sigmoid=True,activate=True,naive_dice=True,loss_weight=1.0),train_cfg: OptConfigType = None,test_cfg: OptConfigType = None,init_cfg: OptMultiConfig = None,**kwargs) -> None:super(AnchorFreeHead, self).__init__(init_cfg=init_cfg)self.num_things_classes = num_things_classesself.num_stuff_classes = num_stuff_classesself.num_classes = self.num_things_classes + self.num_stuff_classesself.num_queries = num_queriespixel_decoder.update(in_channels=in_channels,feat_channels=feat_channels,out_channels=out_channels)self.pixel_decoder = MODELS.build(pixel_decoder)self.transformer_decoder = DetrTransformerDecoder(**transformer_decoder)self.decoder_embed_dims = self.transformer_decoder.embed_dimsif type(self.pixel_decoder) == PixelDecoder and (self.decoder_embed_dims != in_channels[-1]or enforce_decoder_input_project):self.decoder_input_proj = Conv2d(in_channels[-1], self.decoder_embed_dims, kernel_size=1)else:self.decoder_input_proj = nn.Identity()self.decoder_pe = SinePositionalEncoding(**positional_encoding)self.query_embed = nn.Embedding(self.num_queries, out_channels)self.cls_embed = nn.Linear(feat_channels, self.num_classes + 1)self.mask_embed = nn.Sequential(nn.Linear(feat_channels, feat_channels), nn.ReLU(inplace=True),nn.Linear(feat_channels, feat_channels), nn.ReLU(inplace=True),nn.Linear(feat_channels, out_channels))self.test_cfg = test_cfgself.train_cfg = train_cfgif train_cfg:self.assigner = TASK_UTILS.build(train_cfg['assigner'])self.sampler = TASK_UTILS.build(train_cfg['sampler'], default_args=dict(context=self))self.class_weight = loss_cls.class_weightself.loss_cls = MODELS.build(loss_cls)self.loss_mask = MODELS.build(loss_mask)self.loss_dice = MODELS.build(loss_dice)def init_weights(self) -> None:if isinstance(self.decoder_input_proj, Conv2d):caffe2_xavier_init(self.decoder_input_proj, bias=0)self.pixel_decoder.init_weights()for p in self.transformer_decoder.parameters():if p.dim() > 1:nn.init.xavier_uniform_(p)def preprocess_gt(self, batch_gt_instances: InstanceList,batch_gt_semantic_segs: List[Optional[PixelData]]) -> InstanceList:"""Preprocess the ground truth for all images.Args:batch_gt_instances (list[:obj:`InstanceData`]): Batch ofgt_instance. It usually includes ``labels``, each isground truth labels of each bbox, with shape (num_gts, )and ``masks``, each is ground truth masks of each instancesof a image, shape (num_gts, h, w).gt_semantic_seg (list[Optional[PixelData]]): Ground truth ofsemantic segmentation, each with the shape (1, h, w).[0, num_thing_class - 1] means things,[num_thing_class, num_class-1] means stuff,255 means VOID. It's None when training instance segmentation.Returns:list[obj:`InstanceData`]: each contains the following keys- labels (Tensor): Ground truth class indices\for a image, with shape (n, ), n is the sum of\number of stuff type and number of instance in a image.- masks (Tensor): Ground truth mask for a\image, with shape (n, h, w)."""num_things_list = [self.num_things_classes] * len(batch_gt_instances)num_stuff_list = [self.num_stuff_classes] * len(batch_gt_instances)gt_labels_list = [gt_instances['labels'] for gt_instances in batch_gt_instances]gt_masks_list = [gt_instances['masks'] for gt_instances in batch_gt_instances]gt_semantic_segs = [None if gt_semantic_seg is None else gt_semantic_seg.sem_segfor gt_semantic_seg in batch_gt_semantic_segs]targets = multi_apply(preprocess_panoptic_gt, gt_labels_list,gt_masks_list, gt_semantic_segs, num_things_list,num_stuff_list)labels, masks = targetsbatch_gt_instances = [InstanceData(labels=label, masks=mask)for label, mask in zip(labels, masks)]return batch_gt_instancesdef get_targets(self,cls_scores_list: List[Tensor],mask_preds_list: List[Tensor],batch_gt_instances: InstanceList,batch_img_metas: List[dict],return_sampling_results: bool = False) -> Tuple[List[Union[Tensor, int]]]:"""Compute classification and mask targets for all images for a decoderlayer.Args:cls_scores_list (list[Tensor]): Mask score logits from a singledecoder layer for all images. Each with shape (num_queries,cls_out_channels).mask_preds_list (list[Tensor]): Mask logits from a single decoderlayer for all images. Each with shape (num_queries, h, w).batch_gt_instances (list[obj:`InstanceData`]): each contains``labels`` and ``masks``.batch_img_metas (list[dict]): List of image meta information.return_sampling_results (bool): Whether to return the samplingresults. Defaults to False.Returns:tuple: a tuple containing the following targets.- labels_list (list[Tensor]): Labels of all images.\Each with shape (num_queries, ).- label_weights_list (list[Tensor]): Label weights\of all images. Each with shape (num_queries, ).- mask_targets_list (list[Tensor]): Mask targets of\all images. Each with shape (num_queries, h, w).- mask_weights_list (list[Tensor]): Mask weights of\all images. Each with shape (num_queries, ).- avg_factor (int): Average factor that is used to average\the loss. When using sampling method, avg_factor isusually the sum of positive and negative priors. Whenusing `MaskPseudoSampler`, `avg_factor` is usually equalto the number of positive priors.additional_returns: This function enables user-defined returns from`self._get_targets_single`. These returns are currently refinedto properties at each feature map (i.e. having HxW dimension).The results will be concatenated after the end."""results = multi_apply(self._get_targets_single, cls_scores_list,mask_preds_list, batch_gt_instances,batch_img_metas)(labels_list, label_weights_list, mask_targets_list, mask_weights_list,pos_inds_list, neg_inds_list, sampling_results_list) = results[:7]rest_results = list(results[7:])avg_factor = sum([results.avg_factor for results in sampling_results_list])res = (labels_list, label_weights_list, mask_targets_list,mask_weights_list, avg_factor)if return_sampling_results:res = res + (sampling_results_list)return res + tuple(rest_results)def _get_targets_single(self, cls_score: Tensor, mask_pred: Tensor,gt_instances: InstanceData,img_meta: dict) -> Tuple[Tensor]:"""Compute classification and mask targets for one image.Args:cls_score (Tensor): Mask score logits from a single decoder layerfor one image. Shape (num_queries, cls_out_channels).mask_pred (Tensor): Mask logits for a single decoder layer for oneimage. Shape (num_queries, h, w).gt_instances (:obj:`InstanceData`): It contains ``labels`` and``masks``.img_meta (dict): Image informtation.Returns:tuple: a tuple containing the following for one image.- labels (Tensor): Labels of each image.shape (num_queries, ).- label_weights (Tensor): Label weights of each image.shape (num_queries, ).- mask_targets (Tensor): Mask targets of each image.shape (num_queries, h, w).- mask_weights (Tensor): Mask weights of each image.shape (num_queries, ).- pos_inds (Tensor): Sampled positive indices for each image.- neg_inds (Tensor): Sampled negative indices for each image.- sampling_result (:obj:`SamplingResult`): Sampling results."""gt_masks = gt_instances.masksgt_labels = gt_instances.labelstarget_shape = mask_pred.shape[-2:]if gt_masks.shape[0] > 0:gt_masks_downsampled = F.interpolate(gt_masks.unsqueeze(1).float(), target_shape,mode='nearest').squeeze(1).long()else:gt_masks_downsampled = gt_maskspred_instances = InstanceData(scores=cls_score, masks=mask_pred)downsampled_gt_instances = InstanceData(labels=gt_labels, masks=gt_masks_downsampled)# assign and sampleassign_result = self.assigner.assign( # 標簽分配pred_instances=pred_instances,gt_instances=downsampled_gt_instances,img_meta=img_meta)sampling_result = self.sampler.sample(assign_result=assign_result,pred_instances=pred_instances,gt_instances=gt_instances)pos_inds = sampling_result.pos_indsneg_inds = sampling_result.neg_inds# label targetlabels = gt_labels.new_full((self.num_queries, ),self.num_classes,dtype=torch.long)labels[pos_inds] = gt_labels[sampling_result.pos_assigned_gt_inds]label_weights = gt_labels.new_ones(self.num_queries)# mask targetmask_targets = gt_masks[sampling_result.pos_assigned_gt_inds]mask_weights = mask_pred.new_zeros((self.num_queries, ))mask_weights[pos_inds] = 1.0return (labels, label_weights, mask_targets, mask_weights, pos_inds,neg_inds, sampling_result)def loss_by_feat(self, all_cls_scores: Tensor, all_mask_preds: Tensor,batch_gt_instances: List[InstanceData],batch_img_metas: List[dict]) -> Dict[str, Tensor]:"""Loss function.Args:all_cls_scores (Tensor): Classification scores for all decoderlayers with shape (num_decoder, batch_size, num_queries,cls_out_channels). Note `cls_out_channels` should includesbackground.all_mask_preds (Tensor): Mask scores for all decoder layers withshape (num_decoder, batch_size, num_queries, h, w).batch_gt_instances (list[obj:`InstanceData`]): each contains``labels`` and ``masks``.batch_img_metas (list[dict]): List of image meta information.Returns:dict[str, Tensor]: A dictionary of loss components."""num_dec_layers = len(all_cls_scores)batch_gt_instances_list = [batch_gt_instances for _ in range(num_dec_layers)]img_metas_list = [batch_img_metas for _ in range(num_dec_layers)] # 每一層做處理losses_cls, losses_mask, losses_dice = multi_apply( # 計算損失self._loss_by_feat_single, all_cls_scores, all_mask_preds,batch_gt_instances_list, img_metas_list)loss_dict = dict()# loss from the last decoder layerloss_dict['loss_cls'] = losses_cls[-1]loss_dict['loss_mask'] = losses_mask[-1]loss_dict['loss_dice'] = losses_dice[-1]# loss from other decoder layersnum_dec_layer = 0for loss_cls_i, loss_mask_i, loss_dice_i in zip(losses_cls[:-1], losses_mask[:-1], losses_dice[:-1]):loss_dict[f'd{num_dec_layer}.loss_cls'] = loss_cls_iloss_dict[f'd{num_dec_layer}.loss_mask'] = loss_mask_iloss_dict[f'd{num_dec_layer}.loss_dice'] = loss_dice_inum_dec_layer += 1return loss_dictdef _loss_by_feat_single(self, cls_scores: Tensor, mask_preds: Tensor,batch_gt_instances: List[InstanceData],batch_img_metas: List[dict]) -> Tuple[Tensor]:"""Loss function for outputs from a single decoder layer.Args:cls_scores (Tensor): Mask score logits from a single decoder layerfor all images. Shape (batch_size, num_queries,cls_out_channels). Note `cls_out_channels` should includesbackground.mask_preds (Tensor): Mask logits for a pixel decoder for allimages. Shape (batch_size, num_queries, h, w).batch_gt_instances (list[obj:`InstanceData`]): each contains``labels`` and ``masks``.batch_img_metas (list[dict]): List of image meta information.Returns:tuple[Tensor]: Loss components for outputs from a single decoder\layer."""num_imgs = cls_scores.size(0)cls_scores_list = [cls_scores[i] for i in range(num_imgs)] # 取出每一個cls score和mask predsmask_preds_list = [mask_preds[i] for i in range(num_imgs)]# 分配標簽(labels_list, label_weights_list, mask_targets_list, mask_weights_list,avg_factor) = self.get_targets(cls_scores_list, mask_preds_list,batch_gt_instances, batch_img_metas)# shape (batch_size, num_queries)labels = torch.stack(labels_list, dim=0)# shape (batch_size, num_queries)label_weights = torch.stack(label_weights_list, dim=0)# shape (num_total_gts, h, w)mask_targets = torch.cat(mask_targets_list, dim=0)# shape (batch_size, num_queries)mask_weights = torch.stack(mask_weights_list, dim=0)# classfication loss 分配標簽后實際計算損失# shape (batch_size * num_queries, )cls_scores = cls_scores.flatten(0, 1)labels = labels.flatten(0, 1)label_weights = label_weights.flatten(0, 1)class_weight = cls_scores.new_tensor(self.class_weight)loss_cls = self.loss_cls(cls_scores,labels,label_weights,avg_factor=class_weight[labels].sum())num_total_masks = reduce_mean(cls_scores.new_tensor([avg_factor]))num_total_masks = max(num_total_masks, 1)# extract positive ones# shape (batch_size, num_queries, h, w) -> (num_total_gts, h, w)mask_preds = mask_preds[mask_weights > 0] # 取出有實例的位置target_shape = mask_targets.shape[-2:]if mask_targets.shape[0] == 0:# zero matchloss_dice = mask_preds.sum()loss_mask = mask_preds.sum()return loss_cls, loss_mask, loss_dice# upsample to shape of target# shape (num_total_gts, h, w)mask_preds = F.interpolate(mask_preds.unsqueeze(1),target_shape,mode='bilinear',align_corners=False).squeeze(1)# dice lossloss_dice = self.loss_dice(mask_preds, mask_targets, avg_factor=num_total_masks)# mask loss# FocalLoss support input of shape (n, num_class)h, w = mask_preds.shape[-2:]# shape (num_total_gts, h, w) -> (num_total_gts * h * w, 1)mask_preds = mask_preds.reshape(-1, 1)# shape (num_total_gts, h, w) -> (num_total_gts * h * w)mask_targets = mask_targets.reshape(-1)# target is (1 - mask_targets) !!!loss_mask = self.loss_mask(mask_preds, 1 - mask_targets, avg_factor=num_total_masks * h * w)return loss_cls, loss_mask, loss_dicedef forward(self, x: Tuple[Tensor],batch_data_samples: SampleList) -> Tuple[Tensor]:"""Forward function.Args:x (tuple[Tensor]): Features from the upstream network, eachis a 4D-tensor.batch_data_samples (List[:obj:`DetDataSample`]): The DataSamples. It usually includes information such as`gt_instance`, `gt_panoptic_seg` and `gt_sem_seg`.Returns:tuple[Tensor]: a tuple contains two elements.- all_cls_scores (Tensor): Classification scores for each\scale level. Each is a 4D-tensor with shape\(num_decoder, batch_size, num_queries, cls_out_channels).\Note `cls_out_channels` should includes background.- all_mask_preds (Tensor): Mask scores for each decoder\layer. Each with shape (num_decoder, batch_size,\num_queries, h, w)."""batch_img_metas = [data_sample.metainfo for data_sample in batch_data_samples]batch_size = x[0].shape[0]input_img_h, input_img_w = batch_img_metas[0]['batch_input_shape']padding_mask = x[-1].new_ones((batch_size, input_img_h, input_img_w),dtype=torch.float32)for i in range(batch_size):img_h, img_w = batch_img_metas[i]['img_shape']padding_mask[i, :img_h, :img_w] = 0padding_mask = F.interpolate(padding_mask.unsqueeze(1), size=x[-1].shape[-2:],mode='nearest').to(torch.bool).squeeze(1)# when backbone is swin, memory is output of last stage of swin.# when backbone is r50, memory is output of tranformer encoder.mask_features, memory = self.pixel_decoder(x, batch_img_metas)pos_embed = self.decoder_pe(padding_mask)memory = self.decoder_input_proj(memory)# shape (batch_size, c, h, w) -> (batch_size, h*w, c)memory = memory.flatten(2).permute(0, 2, 1)pos_embed = pos_embed.flatten(2).permute(0, 2, 1)# shape (batch_size, h * w)padding_mask = padding_mask.flatten(1)# shape = (num_queries, embed_dims)query_embed = self.query_embed.weight# shape = (batch_size, num_queries, embed_dims)query_embed = query_embed.unsqueeze(0).repeat(batch_size, 1, 1)target = torch.zeros_like(query_embed)# shape (num_decoder, num_queries, batch_size, embed_dims)out_dec = self.transformer_decoder(query=target,key=memory,value=memory,query_pos=query_embed,key_pos=pos_embed,key_padding_mask=padding_mask)# cls_scoresall_cls_scores = self.cls_embed(out_dec)# mask_predsmask_embed = self.mask_embed(out_dec)all_mask_preds = torch.einsum('lbqc,bchw->lbqhw', mask_embed,mask_features)return all_cls_scores, all_mask_predsdef loss(self,x: Tuple[Tensor],batch_data_samples: SampleList,) -> Dict[str, Tensor]:"""Perform forward propagation and loss calculation of the panoptichead on the features of the upstream network.Args:x (tuple[Tensor]): Multi-level features from the upstreamnetwork, each is a 4D-tensor.batch_data_samples (List[:obj:`DetDataSample`]): The DataSamples. It usually includes information such as`gt_instance`, `gt_panoptic_seg` and `gt_sem_seg`.Returns:dict[str, Tensor]: a dictionary of loss components"""batch_img_metas = []batch_gt_instances = []batch_gt_semantic_segs = []for data_sample in batch_data_samples:batch_img_metas.append(data_sample.metainfo)batch_gt_instances.append(data_sample.gt_instances)if 'gt_sem_seg' in data_sample:batch_gt_semantic_segs.append(data_sample.gt_sem_seg)else:batch_gt_semantic_segs.append(None)# forwardall_cls_scores, all_mask_preds = self(x, batch_data_samples)# preprocess ground truthbatch_gt_instances = self.preprocess_gt(batch_gt_instances,batch_gt_semantic_segs)# losslosses = self.loss_by_feat(all_cls_scores, all_mask_preds,batch_gt_instances, batch_img_metas)return lossesdef predict(self, x: Tuple[Tensor],batch_data_samples: SampleList) -> Tuple[Tensor]:"""Test without augmentaton.Args:x (tuple[Tensor]): Multi-level features from theupstream network, each is a 4D-tensor.batch_data_samples (List[:obj:`DetDataSample`]): The DataSamples. It usually includes information such as`gt_instance`, `gt_panoptic_seg` and `gt_sem_seg`.Returns:tuple[Tensor]: A tuple contains two tensors.- mask_cls_results (Tensor): Mask classification logits,\shape (batch_size, num_queries, cls_out_channels).Note `cls_out_channels` should includes background.- mask_pred_results (Tensor): Mask logits, shape \(batch_size, num_queries, h, w)."""batch_img_metas = [data_sample.metainfo for data_sample in batch_data_samples]all_cls_scores, all_mask_preds = self(x, batch_data_samples)mask_cls_results = all_cls_scores[-1]mask_pred_results = all_mask_preds[-1]# upsample masksimg_shape = batch_img_metas[0]['batch_input_shape']mask_pred_results = F.interpolate(mask_pred_results,size=(img_shape[0], img_shape[1]),mode='bilinear',align_corners=False)return mask_cls_results, mask_pred_results詳解)
)
)

![BUUCTF[PWN]](http://pic.xiahunao.cn/BUUCTF[PWN])
![[Cmake Qt]找不到文件ui_xx.h的問題?有關Qt工程的問題,看這篇文章就行了。](http://pic.xiahunao.cn/[Cmake Qt]找不到文件ui_xx.h的問題?有關Qt工程的問題,看這篇文章就行了。)







)




函數和stoll函數)
-百變屏幕無壓力,這才是Android屏幕適配的終極解決方案)