項目的源碼地址
Spring Cloud Alibaba 工程搭建(1)
Spring Cloud Alibaba 工程搭建連接數據庫(2)
Spring Cloud Alibaba 集成 nacos 以及整合 Ribbon 與 Feign 實現負載調用(3)
Spring Cloud Alibaba Ribbon 負載調用說明(4)
Spring Cloud Alibaba 核心理論 CAP與BASE理論簡單理解(5)
Spring Cloud Alibaba Sentinel 集成與限流實戰(6)
Spring Cloud Alibaba 網關 Gateway 集成(7)
前面我們已經搭建了好幾個組件了,會發現,其實就是各個組件的引入,以及相關的配置,其實如果是簡單使用的話,這塊不算復雜,我們先從簡單入手嘛,后面有個基礎或者概念了,就可以深入去學習了。但是在基礎上面我們會遇到一個問題,就是分布式的環境下面,怎么能快速定位問題呢?
問題的復雜性
這里我們先拋出兩個常見問題
- 微服務調用鏈路出現了問題怎么快速排查?
- 微服務調用鏈路耗時長怎么定位是哪個服務?
鏈路追蹤系統
分布式應用架構雖然滿足了應用橫向擴展的需求,但是運維和診斷的過程變得越來越復雜,例如會遇到接口診斷困難、應用性能診斷復雜、架構分析復雜等難題,傳統的監控工具并無法滿足,分布式鏈路系統由此誕生。
核心在于將一次請求分布式調用,使用GPS定位串起來,記錄每個調用的耗時、性能等日志,并通過可視化工具展示出來。
AlibabaCloud全家桶還沒對應的鏈路追蹤系統,我們使用Sleuth和zipking搭建先。
Sleuth 鏈路追蹤
Spring Cloud Sleuth 為 Spring Cloud 實現了分布式跟蹤解決方案。兼容 Zipkin,HTrace 和其他基于日志的追蹤系統,例如 ELK(Elasticsearch 、Logstash、 Kibana)。
Spring Cloud Sleuth 提供了以下功能:
- 鏈路追蹤:通過 Sleuth 可以很清楚的看出一個請求都經過了那些服務,可以很方便的理清服務間的調用關系等。
- 性能分析:通過 Sleuth 可以很方便的看出每個采樣請求的耗時,分析哪些服務調用比較耗時,當服務調用的耗時隨著請求量的增大而增大時, 可以對服務的擴容提供一定的提醒。
- 數據分析:優化鏈路:對于頻繁調用一個服務,或并行調用等,可以針對業務做一些優化措施。
- 可視化錯誤:對于程序未捕獲的異常,可以配合 Zipkin 查看。
項目集成
先把網關的部分測試功能屏蔽掉
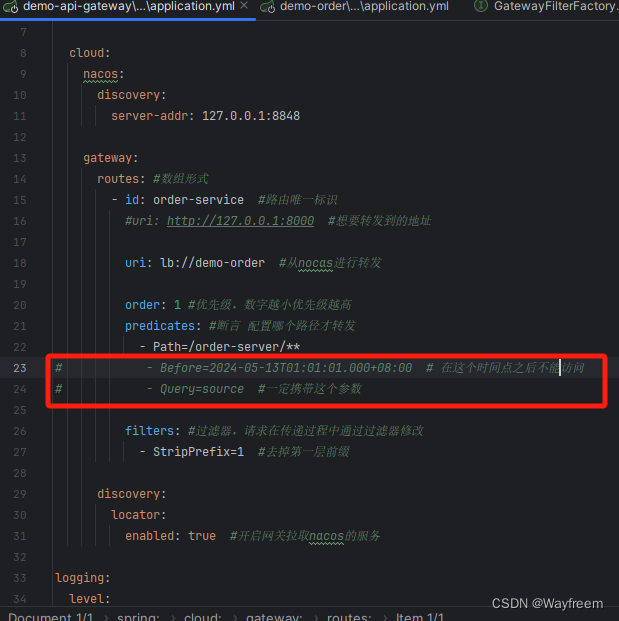
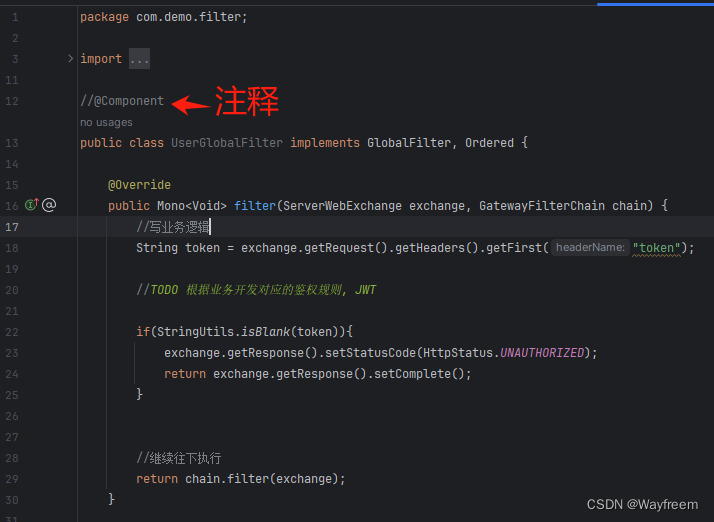
全局的過濾器注釋掉 @Component,這樣子就不會起作用了
在每個模塊的Pom 文件下面都加上 sleuth 的依賴包
<!--添加 sleuth -->
<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>
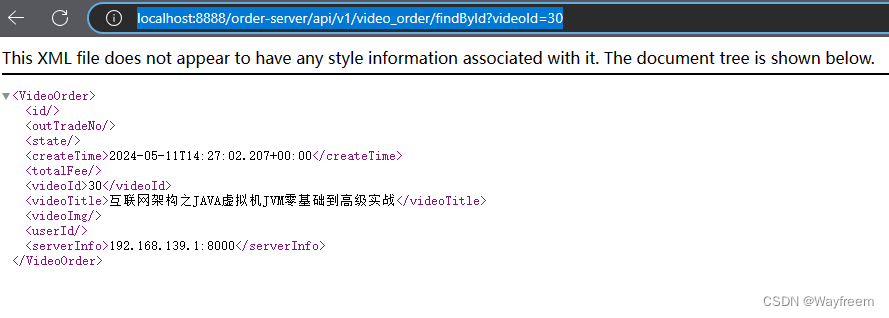
現在訪問下:http://localhost:8888/order-server/api/v1/video_order/findById?videoId=30
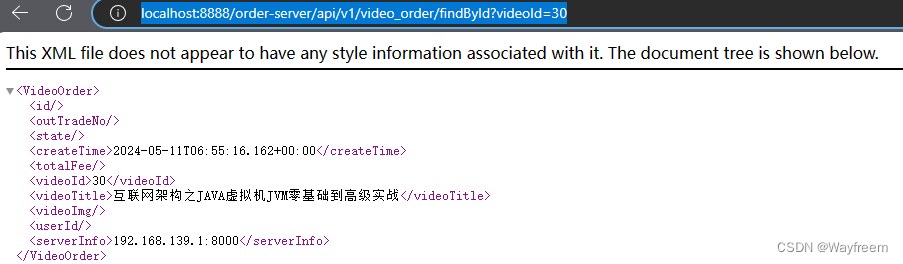
接下來我們分別看下對應服務的日志輸出
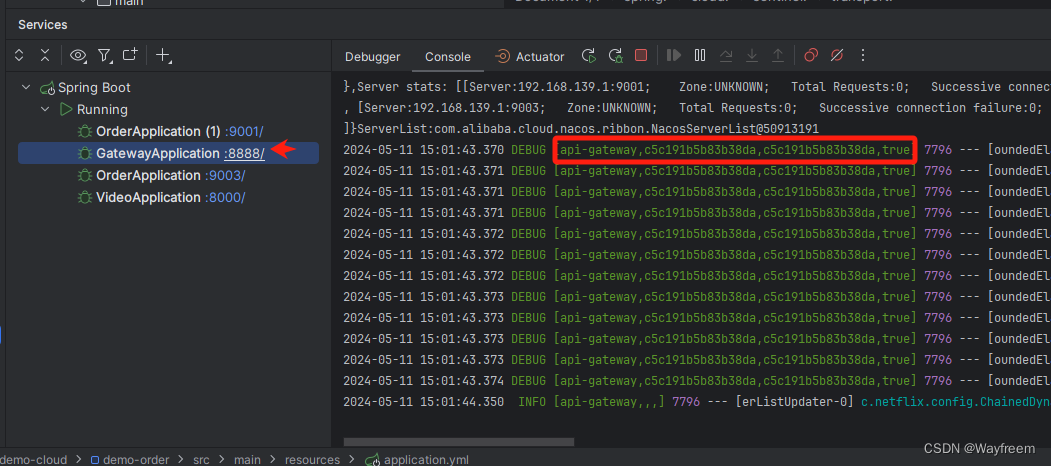
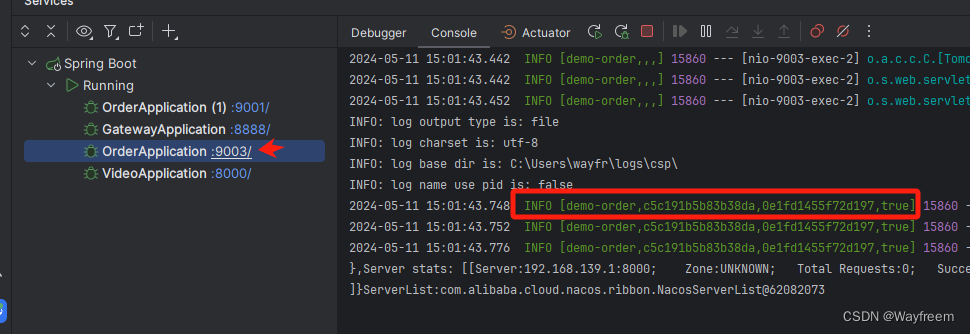
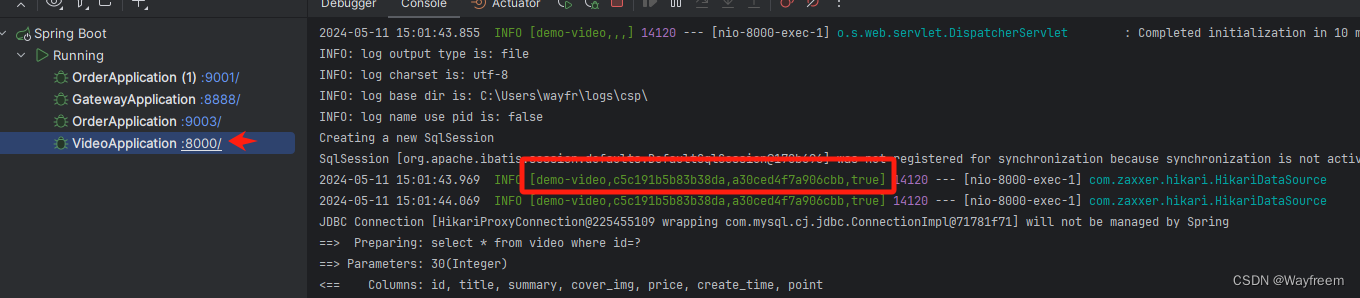
這里我們將三個日志都貼出來:
## gateway 網關
[api-gateway,c5c191b5b83b38da,c5c191b5b83b38da,true]## 訂單服務
[demo-order,c5c191b5b83b38da,0e1fd1455f72d197,true]## 視頻服務
[demo-video,c5c191b5b83b38da,a30ced4f7a906cbb,true]
參數說明
第一個值,spring.application.name 的值第二個值,c5c191b5b83b38da,sleuth 生成的一個ID,叫Trace ID,用來標識一條請求鏈路,一條請求鏈路中包含一個Trace ID,多個Span ID第三個值,c5c191b5b83b38da、span id 基本的工作單元,獲取元數據,如發送一個http第四個值:false,是否要將該信息輸出到 zipkin 服務中來收集和展示。
相關術語
-
Trace (一條完整鏈路–包含很多span(微服務接口))
由一組Trace Id(貫穿整個鏈路)相同的Span串聯形成一個樹狀結構。為了實現請求跟蹤,當請求到達分布式系統的入口端點時,只需要服務跟蹤框架為該請求創建一個唯一的標識(即TraceId),同時在分布式系統內部流轉的時候,框架始終保持傳遞該唯一值,直到整個請求的返回。那么我們就可以使用該唯一標識將所有的請求串聯起來,形成一條完整的請求鏈路。 -
Span
代表了一組基本的工作單元。為了統計各處理單元的延遲,當請求到達各個服務組件的時候,也通過一個唯一標識(SpanId)來標記它的開始、具體過程和結束。通過SpanId的開始和結束時間戳,就能統計該span的調用時間,除此之外,我們還可以獲取如事件的名稱。請求信息等元數據。 -
Annotation
用它記錄一段時間內的事件,內部使用的重要注釋:- cs(Client Send)客戶端發出請求,開始一個請求的生命
- sr(Server Received)服務端接受到請求開始進行處理, sr-cs = 網絡延遲(服務調用的時間)
- ss(Server Send)服務端處理完畢準備發送到客戶端,ss - sr = 服務器上的請求處理時間
- cr(Client Reveived)客戶端接受到服務端的響應,請求結束。 cr - sr = 請求的總時間
Zipkin
什么是zipkin?
Zipkin 是 Twitter 的一個開源項目,它基于Google Dapper實現,它致力于收集服務的定時數據,以解決微服務架構中的延遲問題,包括數據的收集、存儲展現、查找和我們可以使用它來收集各個服務器上請求鏈路的跟蹤數據,并通過它提供的REST API接口來輔助我們查詢跟蹤數據以實現對分布式系統的監控程序。
也提供了方便的UI組件來幫助我們直觀的搜索跟蹤信息和分析請求鏈路明細,比如:可以查詢某段時間內各用戶請求的處理時間等。
下載
我這邊使用的是這個這個版本 zipkin-server-2.12.9-exec.jar
java -jar zipkin-server-2.12.9-exec.jar
訪問:http://127.0.0.1:9411/zipkin/
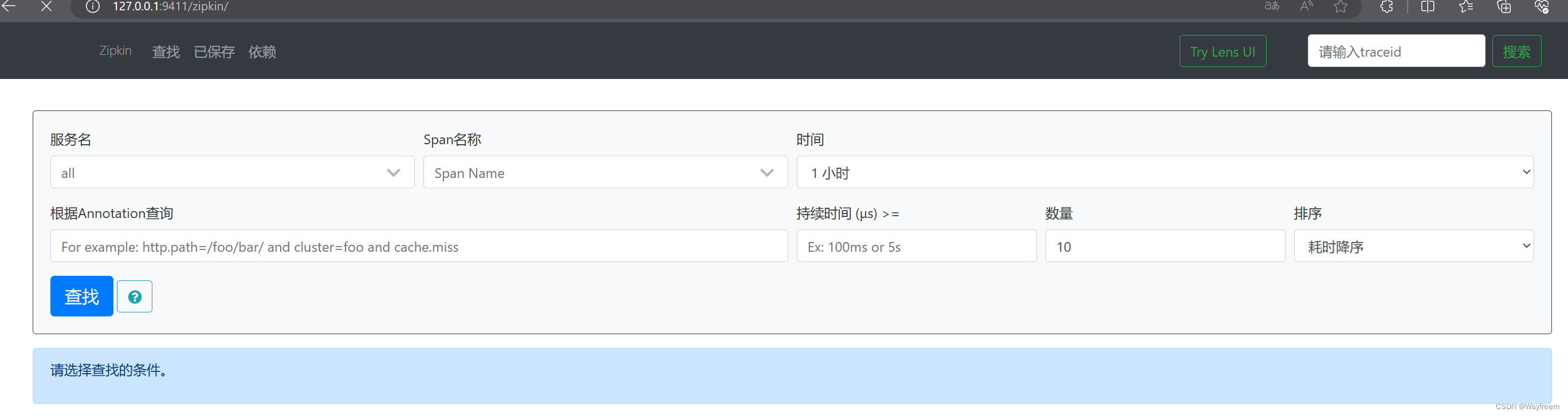
zipkin組成:Collector、Storage、Restful API、WebUI組成
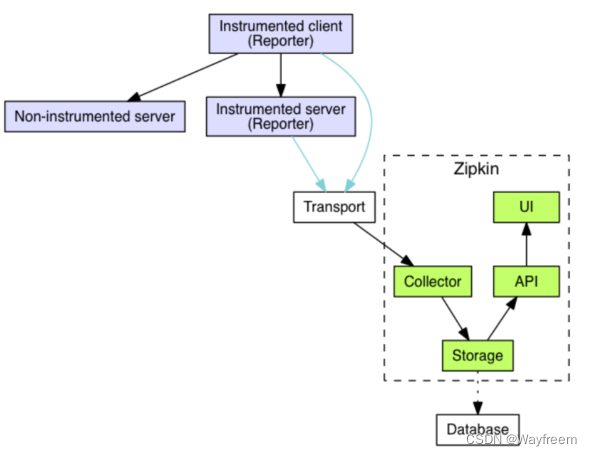
關于整個鏈路的時序圖如下,其實通過時序圖可以看到后面在返回給 User 的時候,有一個異步的操作將數據給到了 Collector 了,可以點擊下這里,看下官方的說明
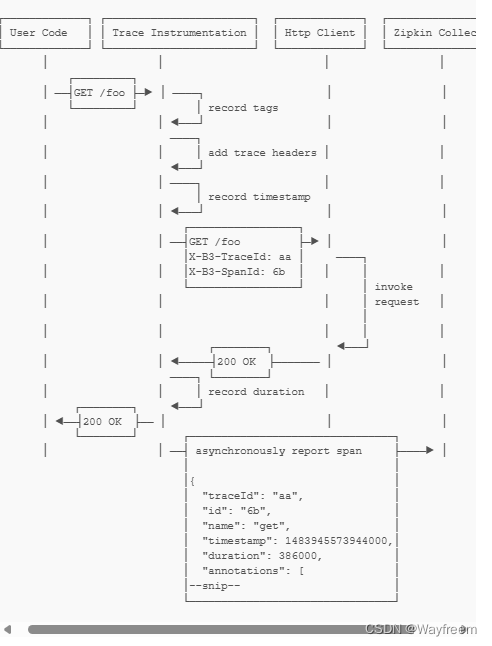
Zipkin+Sleuth整合實戰
流程說明
這里我們來重復地說下這個過程:
- Sleuth 收集跟蹤信息通過 http 請求發送給zipkin server
- Zipkin server進行跟蹤信息的存儲以及提供 Rest API 即可
- Zipkin UI調用其API接口進行數據展示默認存儲是內存,可也用 mysql 或者 elasticsearch 等存儲
項目集成
在每個模塊的POM文件上面都增加依賴
<!--添加 zipkin -->
<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
配置地址和采樣百分比配置
spring:application:name: api-gatewayzipkin:base-url: http://127.0.0.1:9411/ #zipkin地址discovery-client-enabled: false #不用開啟服務發現
?sleuth:sampler:probability: 1.0 #采樣百分
默認為0.1,即10%,這里配置1,是記錄全部的sleuth信息,是為了收集到更多的數據(僅供測試用)。
在分布式系統中,過于頻繁的采樣會影響系統性能,所以這里配置需要采用一個合適的值。
啟動服務
訪問下:http://localhost:8888/order-server/api/v1/video_order/findById?videoId=30
這個時候控制臺,也會有對應的日志出來
這里我們訪問下zipkin 的面板,刷新下就可以看到相關的信息了
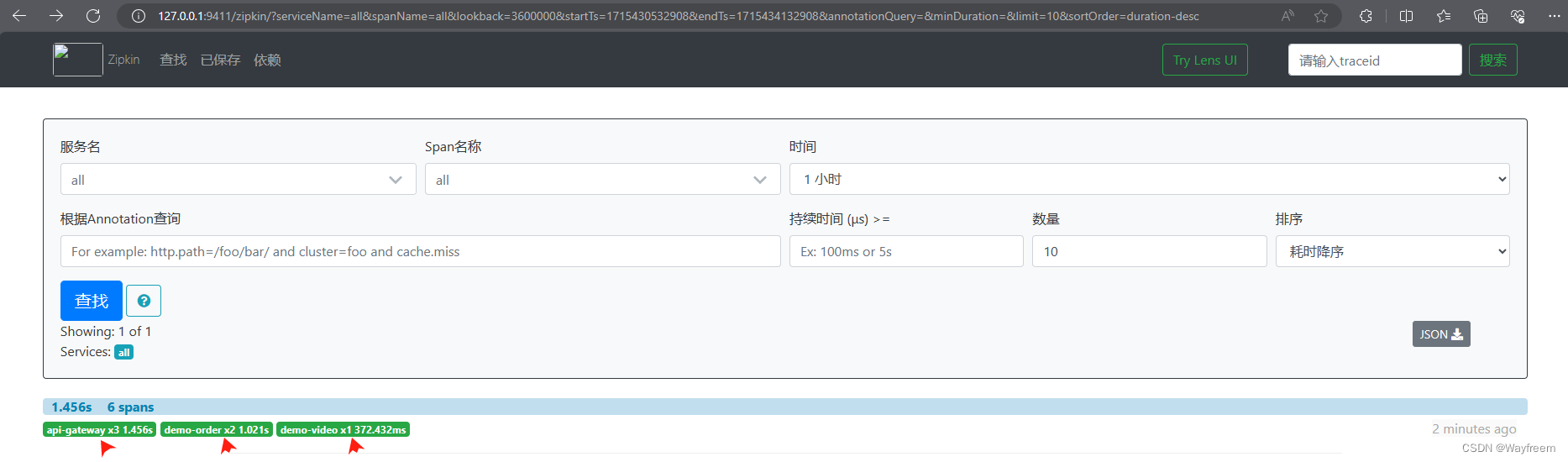
點擊上面的請求信息,這里我們可以看到,整個請求耗時是:1.456s,經過了 3 個服務(所以深度為3)

- 第一個 api-gateway:就是整個請求的記錄耗時
- 第二個 api-gateway:就是從網關開始到返回給前端的耗時
- 第三個 demo-order: 是從訂單服務進入,然后返回給 api-gateway 的耗時
- 第四個 demo-video:是在視頻服務中的耗時
這里點擊具體的一塊,可以看到明細信息
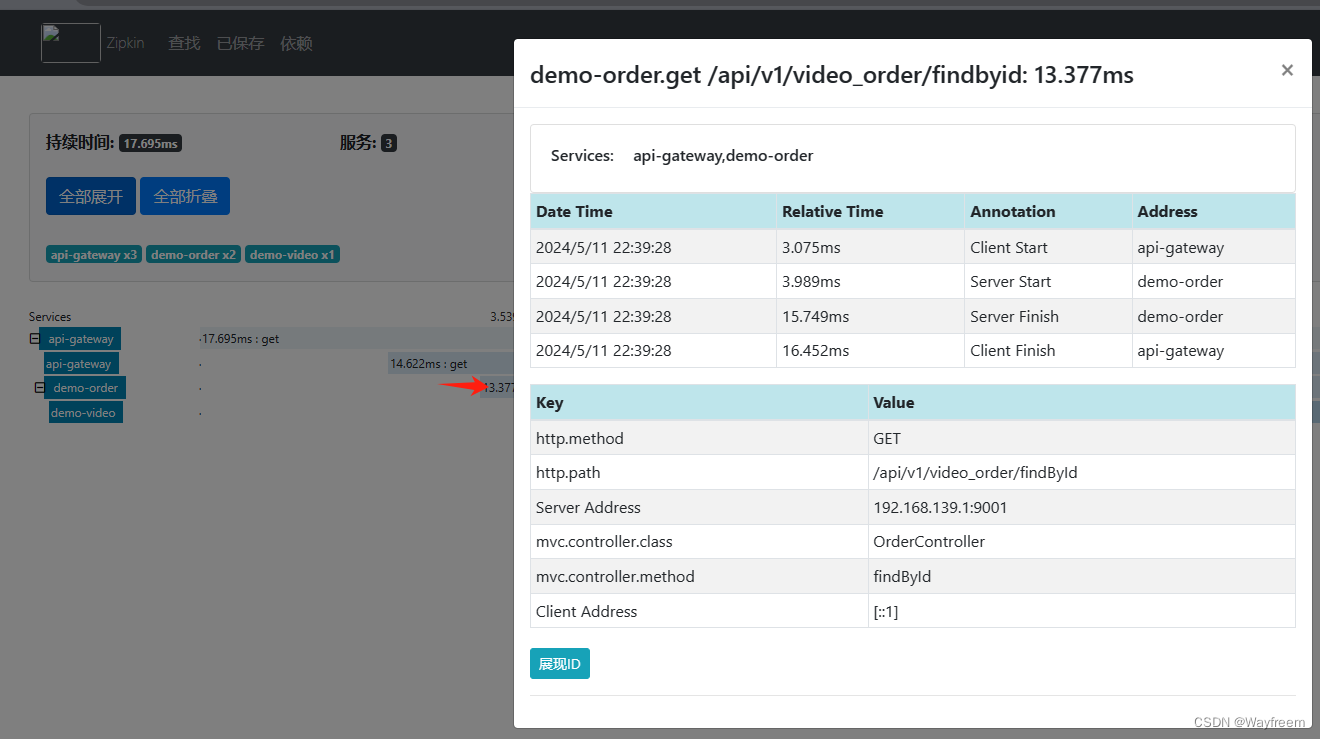
那我多請求幾次看看,會發現下面請求時長就變化了,由于第一次請求會有一個預熱的過程,所以第一次會慢一點
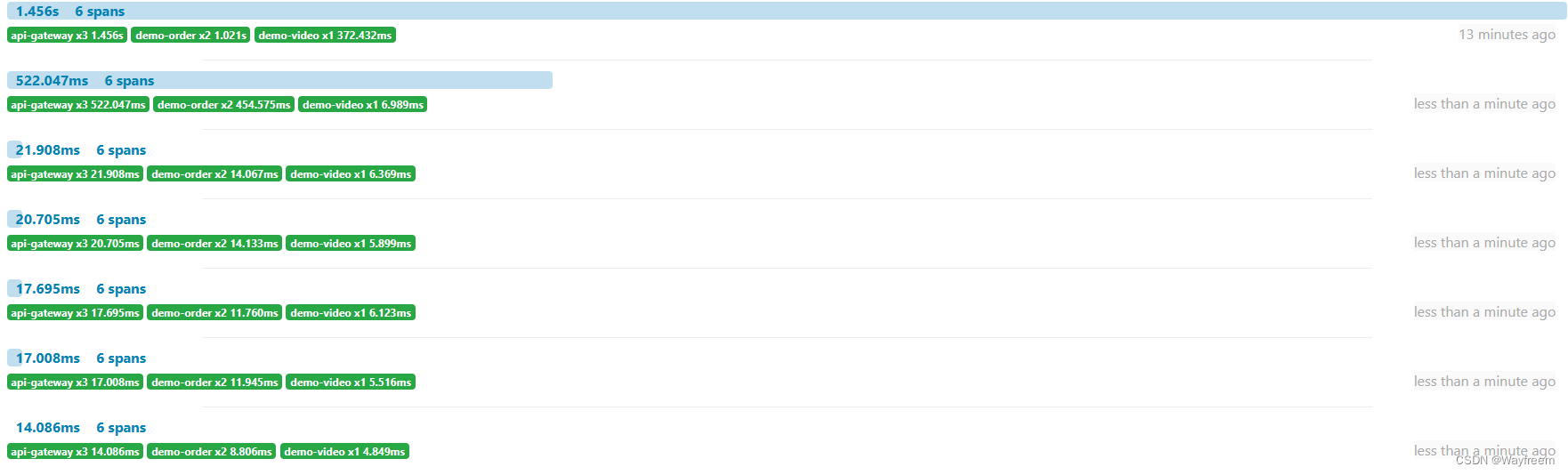
當我請求多次list接口:http://localhost:8888/order-server/api/v1/video_order/list,會發現報錯的請求是這樣子的
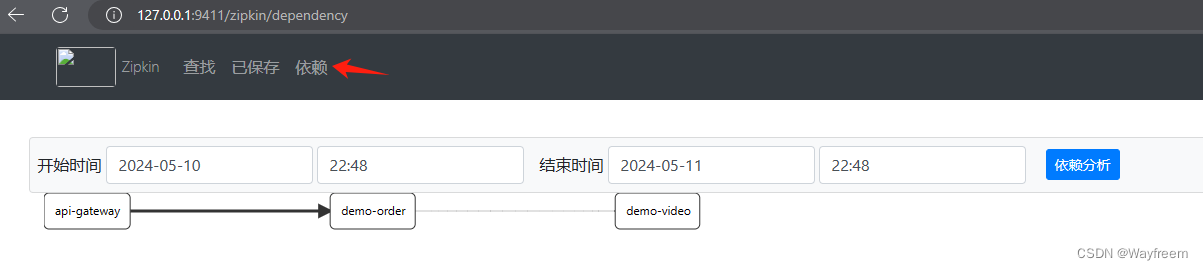
 點擊這里可以看到依賴分析
點擊這里可以看到依賴分析
Zipkin持久化配置
首先,我們先看下官網地址,點擊這里看看,我們可以放到 MongoDB,或者 ES,MYSQL 上面,都是可以的。
Zipkin 持久化
需要在我們的數據庫增加下面的表
CREATE TABLE IF NOT EXISTS zipkin_spans (`trace_id_high` BIGINT NOT NULL DEFAULT 0 COMMENT 'If non zero, this means the trace uses 128 bit traceIds instead of 64 bit',`trace_id` BIGINT NOT NULL,`id` BIGINT NOT NULL,`name` VARCHAR(255) NOT NULL,`remote_service_name` VARCHAR(255),`parent_id` BIGINT,`debug` BIT(1),`start_ts` BIGINT COMMENT 'Span.timestamp(): epoch micros used for endTs query and to implement TTL',`duration` BIGINT COMMENT 'Span.duration(): micros used for minDuration and maxDuration query',PRIMARY KEY (`trace_id_high`, `trace_id`, `id`)
) ENGINE=InnoDB ROW_FORMAT=COMPRESSED CHARACTER SET=utf8 COLLATE utf8_general_ci;ALTER TABLE zipkin_spans ADD INDEX(`trace_id_high`, `trace_id`) COMMENT 'for getTracesByIds';
ALTER TABLE zipkin_spans ADD INDEX(`name`) COMMENT 'for getTraces and getSpanNames';
ALTER TABLE zipkin_spans ADD INDEX(`remote_service_name`) COMMENT 'for getTraces and getRemoteServiceNames';
ALTER TABLE zipkin_spans ADD INDEX(`start_ts`) COMMENT 'for getTraces ordering and range';CREATE TABLE IF NOT EXISTS zipkin_annotations (`trace_id_high` BIGINT NOT NULL DEFAULT 0 COMMENT 'If non zero, this means the trace uses 128 bit traceIds instead of 64 bit',`trace_id` BIGINT NOT NULL COMMENT 'coincides with zipkin_spans.trace_id',`span_id` BIGINT NOT NULL COMMENT 'coincides with zipkin_spans.id',`a_key` VARCHAR(255) NOT NULL COMMENT 'BinaryAnnotation.key or Annotation.value if type == -1',`a_value` BLOB COMMENT 'BinaryAnnotation.value(), which must be smaller than 64KB',`a_type` INT NOT NULL COMMENT 'BinaryAnnotation.type() or -1 if Annotation',`a_timestamp` BIGINT COMMENT 'Used to implement TTL; Annotation.timestamp or zipkin_spans.timestamp',`endpoint_ipv4` INT COMMENT 'Null when Binary/Annotation.endpoint is null',`endpoint_ipv6` BINARY(16) COMMENT 'Null when Binary/Annotation.endpoint is null, or no IPv6 address',`endpoint_port` SMALLINT COMMENT 'Null when Binary/Annotation.endpoint is null',`endpoint_service_name` VARCHAR(255) COMMENT 'Null when Binary/Annotation.endpoint is null'
) ENGINE=InnoDB ROW_FORMAT=COMPRESSED CHARACTER SET=utf8 COLLATE utf8_general_ci;ALTER TABLE zipkin_annotations ADD UNIQUE KEY(`trace_id_high`, `trace_id`, `span_id`, `a_key`, `a_timestamp`) COMMENT 'Ignore insert on duplicate';
ALTER TABLE zipkin_annotations ADD INDEX(`trace_id_high`, `trace_id`, `span_id`) COMMENT 'for joining with zipkin_spans';
ALTER TABLE zipkin_annotations ADD INDEX(`trace_id_high`, `trace_id`) COMMENT 'for getTraces/ByIds';
ALTER TABLE zipkin_annotations ADD INDEX(`endpoint_service_name`) COMMENT 'for getTraces and getServiceNames';
ALTER TABLE zipkin_annotations ADD INDEX(`a_type`) COMMENT 'for getTraces and autocomplete values';
ALTER TABLE zipkin_annotations ADD INDEX(`a_key`) COMMENT 'for getTraces and autocomplete values';
ALTER TABLE zipkin_annotations ADD INDEX(`trace_id`, `span_id`, `a_key`) COMMENT 'for dependencies job';CREATE TABLE IF NOT EXISTS zipkin_dependencies (`day` DATE NOT NULL,`parent` VARCHAR(255) NOT NULL,`child` VARCHAR(255) NOT NULL,`call_count` BIGINT,`error_count` BIGINT,PRIMARY KEY (`day`, `parent`, `child`)
) ENGINE=InnoDB ROW_FORMAT=COMPRESSED CHARACTER SET=utf8 COLLATE utf8_general_ci;
Zipkin 啟動的時候,需要自定數據源就好
java -jar zipkin-server-2.12.9-exec.jar --STORAGE_TYPE=mysql --MYSQL_HOST=127.0.0.1 --MYSQL_TCP_PORT=3306 --MYSQL_DB=zipkin_log --MYSQL_USER=admin --MYSQL_PASS=123456

![BUUCTF[PWN]](http://pic.xiahunao.cn/BUUCTF[PWN])
![[Cmake Qt]找不到文件ui_xx.h的問題?有關Qt工程的問題,看這篇文章就行了。](http://pic.xiahunao.cn/[Cmake Qt]找不到文件ui_xx.h的問題?有關Qt工程的問題,看這篇文章就行了。)







)




函數和stoll函數)
-百變屏幕無壓力,這才是Android屏幕適配的終極解決方案)
----單級放大器(共源極))

