本文為大模型&存內計算融合專題的首篇文章,我們將以這篇名為《REM-CiM: Attentional RGB-Event Fusion Multi-modal Analog CiM for Area/Energy-efficient Edge Object Detection during both Day and Night》為例[1],探討其在文中提到的多模態大模型與存內計算技術的融合等信息。
一.基礎概念
為了更好的理解文章的主要創新點和涉及到的知識,我們先對文章中涉及的重要基本概念、文章背景等進行介紹。
(1)存內計算
存內計算技術是指將數據存儲和處理單元集成在一起的技術,目的是減少數據在處理過程中的移動距離,從而降低能耗并提高處理速度。在REM-CIM中,CIM可以針對多模態數據的卷積計算(如RGB圖像和事件數據)進行高效處理。

圖1 REM-CiM存內計算單元、陣列示意圖
(2)RGB-Event融合
RGB是指紅(Red)、綠(Green)、藍(Blue)三種顏色的光信號組合,是最常見的顏色模式,廣泛應用于圖像處理和顯示技術中。通過調整三種顏色的強度,可以合成出幾乎所有可見光譜的顏色,傳統RGB相機能夠捕捉全彩圖像,提供豐富的色彩與細節,適用于廣泛的視覺應用;其以固定幀率捕獲圖像,每幀捕捉一個時間點的完整視覺場景;其動態范圍也較低,通常在60dB左右。
而Event相機(事件相機)不是按固定時間間隔捕捉整個場景的圖像,而是響應像素級的亮度變化。每個像素獨立工作,只在檢測到亮度變化時生成數據(稱為“事件”)。Event相機具有非常高的動態范圍(如140dB),使其能夠在光線變化極大的環境下工作,如直射日光下或夜間。由于事件的記錄幾乎實時發生,時間分辨率可以達到微秒級,這使得Event相機非常適合捕捉快速移動的對象或高速發生的場景變化,具有超低的延遲與高時間分辨率。
文章背景中的challenge部分對這兩種傳感器(相機)的優劣做出了對比,文中提出事件傳感器的數據量少,可以在夜景下正常工作,但是其不足是數據稀疏性較高,只在亮度變化時生成數據:RGB相機具有豐富的色彩信息,但也導致其在夜晚無法正常工作,因此引出了將RGB與Event兩種傳感器融合的操作。
將RGB相機與事件相機融合使用可以實現高精度的視覺感知,因為它們各自彌補了對方的不足。RGB提供了豐富的顏色信息,而事件傳感器提供了高時間分辨率的動態信息。這種融合使系統能夠在各種光照條件下捕捉到更加細致和準確的場景信息,增強了整體系統對復雜環境的適應性和反應能力。這種多模態融合在視覺系統中開辟了新的應用可能,特別是在動態和極端光照條件下的性能提升上。圖2展示了對來自RGB和event二者的張量進行拼接的三種操作。
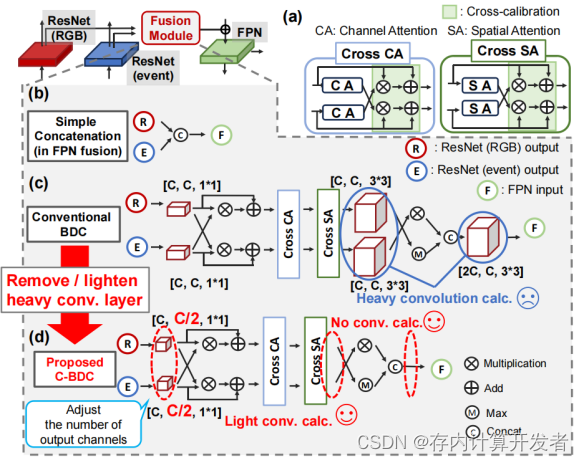
圖2 REM-CiM存內計算單元、陣列示意圖
(3)多模態
首先,模態指的是信息、數據或傳感器輸入的類型,而多模態方式可以通過結合來自不同傳感器或信息源的信息,提供比單一模態更為全面、精確的數據解析信息與能力。在REM-CIM的上下文中,多模態主要指的是同時處理來自RGB圖像和事件傳感器數據的能力,這對于理解復雜的視覺場景非常重要;但這樣也會導致計算資源需求的提高,二者數據不同(多模態)也會引入統一格式的處理步驟。多模態通常可以給系統帶來更好的信息互補性、系統魯棒性并提升系統解析信息或數據的能力。
以現階段大熱的自動駕駛汽車為例,該種車輛通常裝備多種傳感器:
- 視覺傳感器(如相機):捕捉道路、行人、標志等的視覺圖像。
- 雷達(無線電波):用于檢測遠距離的對象和測量它們的速度。
- 激光雷達(光學雷達):提供環境的精確3D映射。
- 超聲波傳感器:在低速時幫助檢測近距離的障礙物。
通過融合這些傳感器的數據,自動駕駛系統能夠在各種天氣和光照條件下準確地感知周圍環境,即使在某些傳感器由于環境因素(如霧、雨、直射陽光)受到影響時也能保持高性能。這種多模態集成提高了系統的安全性和可靠性,是實現有效自動駕駛的關鍵。
二、文章創新點
(一)MEA-FPN架構
(1)從FPN到MEA-FPN
MEA-FPN(Memory capacity-Efficient Attentional Feature Pyramid Network)是一種針對RGB-事件融合的模擬存內計算(CiM)設計的創新模型架構。它基于傳統的FPN(Feature Pyramid Network)進行改進,FPN通過結合自頂向下的架構和橫向連接,構建了一個多層次的特征金字塔[2]。這種設計使得每個層級既擁有豐富的語義信息,又維持高分辨率,從而有效改善對不同尺度對象的檢測能力。與依賴單一深層語義特征的傳統神經網絡相比,FPN提供了一種更為復雜且有效的多尺度信息處理方式。
FPN fusion技術則進一步利用注意力機制,有效獲取并整合來自不同數據源(如RGB圖像與事件相機數據)的特征,極大增強了模型的感知能力和準確性。在需要處理多模態輸入的復雜視覺任務中,FPN fusion表現出其獨特的優勢。

圖3 本文提出的MEA-FPN對比其他網絡架構
本文提出的MEA-FPN顯著降低了模型的參數數量,這一優化主要通過移除傳統雙向校正(Bi-Directional Calibration,BDC)中的大型卷積操作實現。特別是,通過構建C-BDC模塊(Convolution-less Bi-Directional Calibration),它去除了除第一層外的所有大卷積計算。與傳統的注意力特征金字塔網絡(Attentional FPN fusion, A-FPN)相比,MEA-FPN實現了76%的參數減少,同時將平均精度(mean Average Precision, mAP)的降低控制在2.3%以內。這種設計不僅優化了參數效率,還降低了內存需求。
(2)C-BDC模塊
BDC模塊通過利用注意力機制加強不同模態數據之間的特征融合,特別強調在RGB與事件數據融合中的效果。該模塊的核心是跨模態注意力機制,包括通道注意力(Channel Attention, CA)和空間注意力(Spatial Attention, SA)。這些機制幫助模型聚焦于最關鍵的特征,并通過模態間的特征映射增強整體的檢測性能。
C-BDC進一步優化了這一過程,去除了不必要的復雜卷積計算,僅關注注意力機制獲取的關鍵信息,從而在保證性能的同時,簡化了模型結構,減輕了計算負擔。
(二)低比特量化與裁剪
除了MEA-FPN模型架構方面的創新,低比特量化與裁剪(Low-bit Quantization with Clipping, LQC)也是本文的主要創新點之一,下面將從該技術的概念出發,詳細介紹本文LQC的作用以及相關數據。
(1)LQC技術概念
LQC是一種針對深度神經網絡優化的技術,旨在減少模型的存儲需求和計算成本,同時盡量保持模型的性能。這項技術主要包含兩個核心步驟:低比特量化和裁剪:
低比特量化是指將神經網絡中的權重和激活值從高精度浮點數轉換為低精度整數表示,常見的如從32位浮點數轉換為8位、4位乃至更低的比特寬度。量化通過映射函數實現,該函數將連續的浮點數值范圍映射到離散的整數集合上。這樣做可以顯著減少模型的存儲占用并加速計算過程。
裁剪是預量化過程中的一個重要步驟,用于限制網絡中的數值范圍,以避免量化后的信息損失。在量化前,通過設定合適的裁剪閾值(即裁剪范圍),將超出此范圍的權重或激活值強制限制在閾值內,這樣可以減少量化過程中的誤差。裁剪有助于保持網絡的動態范圍,并確保量化后數據的分布更加集中,進而提高量化后的模型精度。
LQC綜合了以上兩步,旨在找到一個平衡點,在減少模型大小和計算需求的同時,通過精細調整裁剪參數來最小化量化引起的精度損失。通過這種方法,LQC技術能夠幫助設計出既節能又具有較高準確率的多模態AI系統,如REM-CIM所示。
(2)LQC技術在REM-CIM中的創新
在REM-CIM中,作者對LQC技術進行了諸多方面的創新和優化:
1.考慮CIM特性量身定制:現有的量化方法往往不直接適用于CIM的特性,如差分對的零中心對稱權重分布。本文作者特別針對這些特性,探索了適合CIM的權重裁剪范圍,確保量化過程更加精準有效。
2.全鏈路量化考慮:與僅關注激活函數裁剪范圍的自動優化方法不同,LQC還考慮了輸出量化,即在考慮模數轉換器(ADC)影響下的輸入和輸出量化,使得整個信號處理流程的量化更為全面。
3.模塊級敏感度分析:通過對MEA-FPN中各模塊的權重位精度敏感性進行分析,確定了在保持平均精度的同時實現低比特量化所需的最優配置,從而最大化效率與性能的平衡。
- LQC技術減小面積和功耗
得益于LQC技術的使用,MEA-CIM大大減少了面積和能耗:
1.面積和能耗正比關系利用:LQC基于面積和能耗與激活比特精度成正比的假設,通過減小權重和激活的比特精度來直接減少所需硬件資源,尤其是模數轉換器的面積和能耗。
2.ADC面積與能耗減少:如表1所示,與沒有LQC的FPN CIM相比,REM-CIM通過應用LQC,實現了21%的ADC面積和24%的ADC能耗降低;與沒有LQC的MEA-FPN CIM相比,REM-CIM實現了25%的ADC面積和能耗降低;與沒有LQC的A-FPN CIM相比,REM-CIM實現了55%的ADC面積和34%的ADC能耗降低;
3.參數數量與內存容量減少:如表1所示,A-FPN CIM在所有錯誤模式下都能實現最佳平均精度,但是,它需要最多的存儲單元(542Mb)和ADC面積/能量,難以在邊緣計算上實現。在本研究中,結合LQC的使用,REM-CIM實現了131Mb 左右的內存容量(與A-FPN?CIM相比減少76%的參數,與FPN CIM和MEA-FPN CIM相同),從而降低內存容量需求。
4.保持高準確率下的低比特量化:通過LQC技術探索合適的權重和激活裁剪范圍,使得模型能在較低比特精度下運行而不犧牲太多準確率。即便在加入寫入變化誤差和數據保持錯誤的情況下,REM-CIM依然能保持較高的平均精度,與FPN CIM相比提高了0.7%(如表1所示),顯示了對硬件誤差的良好容忍性和長期穩定性能。
5.算法與電路的協同優化:LQC與MEA-FPN的聯合設計體現了算法與硬件實現的協同優化策略,既提升了平均精度,又降低了面積和能耗。這種協同設計確保了在模擬CIM上實現準確的多模態AI,同時滿足邊緣計算的嚴格資源限制。
表1 LQC技術使用前后模型參數對比
| CIM(without LQC) | REM-CIM(with LQC) | |||
| 模型種類 | FPN | A-FPN | MEA-FPN | MEA-FPN |
| 平均精度 | 0.437 | 0.495 | 0.475 | 0.454 |
| 存儲單元數量 | 131M | 542M | 131M | 131M |
| ADC面積 | 0.95 | 1.65 | 1 | 0.75 |
| ADC功耗 | 0.99 | 1.14 | 1 | 0.75 |
綜上所述,LQC技術是REM-CIM設計中實現面積/能源效率提升的關鍵因素,它通過量化與裁剪策略,有效地在保持高檢測性能的同時,降低了硬件資源的需求,使得多模態邊緣AI在實際應用中更加可行。
三.拓展知識與應用
在此篇文章的基礎上,我們將對對深度學習的量化知識進行一些拓展,并討論REM-CiM技術在自動駕駛、機器人視覺、增強現實等領域的潛在應用。
(1)深度學習量化
在深度學習中,量化是一種減少模型大小和計算需求的技術,通過降低數值精度來實現。這一技術對于在資源受限的設備上部署深度學習模型特別有用,如移動設備和邊緣計算設備。量化能顯著減少模型在內存中的占用空間,同時還能減少計算的復雜性,從而提高推理速度并降低能耗。
用最簡單的話說,量化的本質是將值從大集合“四舍五入”映射至小集合的過程,這一過程也會帶來一定的精度損失。在信號處理時,量化過程主要發生在模數轉換器(ADC)中,將連續的模擬信號采樣、四舍五入到最接近的可表示量化值,在深度學習中,量化也是類似的原理,只不過這時候是用將較高精度的數據類型映射為較低精度的數據類型(例如從FP32映射到INT8)。

圖4 信號處理中的量化
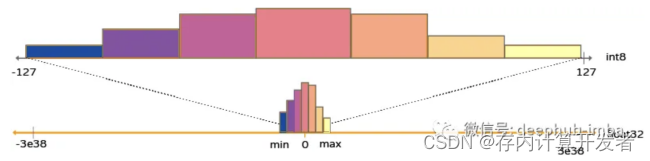
圖5 從FP32到INT8的代表性映射[3]
深度學習中的量化可以分為均勻量化和非均勻量化。均勻量化是最簡單的形式,其中每個數值都被等距地映射到新的數值范圍內;非均勻量化則允許不同的輸入值映射到不同的輸出范圍,這通常用于更復雜的映射關系,以減少誤差。因此,在量化過程中,我們通常需要根據具體需求選擇均勻量化or非均勻量化,并根據模型大小、硬件資源等條件的權衡確定量化精度。在量化完成后也需要使用校對數據集來調整量化參數,以最小化模型性能損失,并在模型部署前做后量化處理,進一步優化性能和資源消耗。
現階段,多個深度學習框架如TensorFlow、PyTorch和TensorRT提供了量化工具和API,使得開發者可以輕松地對模型進行量化處理。這些工具通常包括自動化的量化流程,以及對不同類型量化策略的支持[4]。
1.TensorFlow:
TensorFlow Lite支持訓練后動態范圍量化,可以將權重轉換為8位精度,從而使模型大小縮減至原來的四分之一。
TensorFlow還提供了訓練后量化和動態范圍量化,這些技術可以提供更快的計算速度并減少內存使用量。
2.PyTorch:
PyTorch 2引入了全圖模式量化工作流,這是一種新的自動量化框架,相比之前的FX圖模式量化,它能夠捕獲更高比例(88.8%)的模型信息。
PyTorch還提供了Eager模式量化和FX圖模式量化兩種不同的量化模式,其中Eager模式量化是beta特性,而FX圖模式量化是原型特性。
PyTorch的Quanto工具包支持多種模型量化方案,包括靜態量化和動態量化,并且可以將量化模型序列化為state_dict格式。
3.TensorRT:
TensorRT支持兩種量化方式:QAT(Quantization-Aware Training)和PTQ(Post-Training Quantization)。這些技術允許在訓練或推理階段應用量化,以優化模型性能和減小模型大小。
從TensorRT 7.2版本開始,引入了set dynamic range API,用于QAT,這進一步增強了其量化能力。
此外,近些年的低比特量化技術為大模型在端側的部署提供了更多可能性,清華提出的OneBit方法將大模型參數壓縮到1比特大小[5]、微軟在2024年2月提出將所有大模型量化為1.58[6]、自動化所提出的SpQR量化方案將大模型量化至3~4比特等[7],都將大幅壓縮大模型大小,優化模型在端側部署的內存占用與計算資源調用,同時也使存算技術在端側賦能大模型部署成為可能。
(2)REM-CiM技術的應用
REM-CiM(RGB-Event融合多模態模擬存算一體)技術通過結合RGB和Event傳感器的數據,并使用存算一體(CiM)技術,提供了一個高效的解決方案來處理視覺數據。這種技術在自動駕駛、機器人視覺和增強現實等領域具有廣泛的潛在應用,特別是在需要快速且精確處理大量視覺數據的情景中。
自動駕駛:
自動駕駛車輛需要能夠快速準確地理解周圍環境,以做出安全的駕駛決策。REM-CiM技術可以極大地增強車輛的夜間和逆光駕駛能力,因為:
1.改善低光和高對比度環境下的性能:Event相機的高動態范圍能夠在極端光照條件下提供清晰的視覺信息,而RGB相機則提供詳細的色彩和紋理信息。
2.快速響應:Event相機能夠捕捉到快速移動對象的細微變化,有助于自動駕駛系統更快地響應緊急情況,如忽然出現的行人或車輛。
機器人視覺:
在機器人領域,尤其是在復雜或動態環境中工作的機器人(如工業自動化、服務機器人等),對視覺系統的要求極高。
1.環境適應性:機器人操作通常涉及多種光照和視覺條件,REM-CiM可以提供更好的環境適應性,使機器人在不同光照條件下都能有效工作。
2.實時處理:CiM技術能夠在內存中直接進行數據處理,大大減少了數據傳輸時間,提高了處理速度,這對于需要實時決策的機器人應用尤為重要。
增強現實(AR):
在增強現實應用中,將虛擬信息無縫融合到用戶的實際視野中是一大挑戰,尤其是在外部環境光線變化大的情況下。
1.環境感知與交互:通過利用Event相機的高動態范圍和快速響應特性,REM-CiM技術可以改進增強現實設備對真實世界環境的感知能力,如在室外陽光直射或室內暗光條件下都能穩定工作。
2.性能優化:存算一體技術使得數據處理更加高效,有助于減輕AR設備的能耗和處理負擔,使設備更輕便,延長電池壽命。
總體來看,REM-CiM技術通過其在速度、精度和能效方面的優勢,為各種視覺依賴的應用提供了強大的支持。這些應用領域通常要求高速、高精度的視覺處理能力,以及在多變環境中的魯棒性,REM-CiM通過提供一種有效的多模態融合和處理方案,能夠滿足這些要求。
參考資料
[1]Ichikawa Y, Yamada A, Misawa N, et al. REM-CiM: Attentional RGB-Event Fusion Multi-modal Analog CiM for Area/Energy-efficient Edge Object Detection during both Day and Night[J]. IEICE Transactions on Electronics, 2024: 2023CTP0001.
[2]?Lin T Y, Dollár P, Girshick R, et al. Feature pyramid networks for object detection[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2017: 2117-2125.
[3] 神經網絡壓縮方法:模型量化的概念簡介,數據派THU,2024.
[4] Dive into cheap deep learning(aieye-top.github.io)
[5] Xu Y, Han X, Yang Z, et al. OneBit: Towards Extremely Low-bit Large Language Models[J]. arXiv preprint arXiv:2402.11295, 2024.
[6] Ma S, Wang H, Ma L, et al. The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits[J]. arXiv preprint arXiv:2402.17764, 2024.
[7] Dettmers T, Svirschevski R, Egiazarian V, et al. Spqr: A sparse-quantized representation for near-lossless llm weight compression[J]. arXiv preprint arXiv:2306.03078, 2023.




)





)


)





