Adobe Research和特拉維夫大學的研究人員聯合開發了一種名為LazyDiffusion的新型擴散變換器,它能夠高效地生成部分圖像更新,特別適用于交互式圖像編輯。該模型通過創新的編碼器-解碼器架構,顯著提升了圖像編輯的效率,同時保持了與全尺寸圖像生成相媲美的質量。
技術突破:
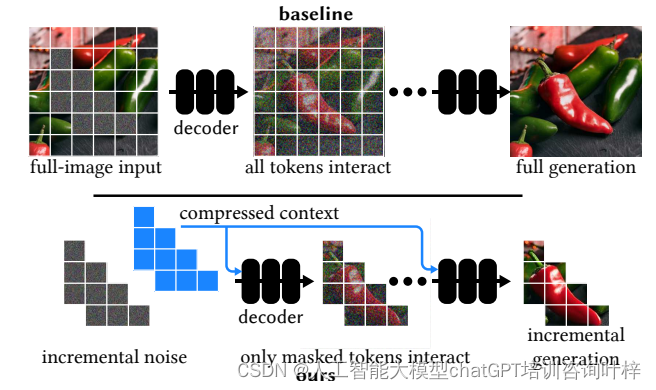
LazyDiffusion的核心在于兩個階段的工作流程:首先,上下文編碼器處理當前畫布和用戶遮罩,生成一個緊湊的全局上下文;其次,擴散解碼器基于這個上下文“懶惰”地合成遮罩像素,即僅生成遮罩區域的像素。這種方法避免了傳統擴散模型在每次迭代中處理整個圖像的需要,從而顯著減少了計算量和時間。
上下文編碼器(Context Encoder)
全局上下文生成:
- 上下文編碼器的目的是將當前畫布的全局信息和用戶的編輯意圖(通過遮罩定義)整合起來。
- 輸入包括兩部分:一是用戶希望修改的圖像區域(通過遮罩表示),二是遮罩外的背景或上下文區域。
- 編碼器處理這兩部分信息,生成一個包含整個圖像上下文的緊湊表示,但重點是為遮罩區域生成內容。
信息壓縮:
- 為了減少計算量,上下文編碼器將豐富的圖像信息壓縮成一個較小的上下文碼。
- 這個上下文碼是編碼器輸出的一組特征或“tokens”,它們高效地編碼了遮罩區域需要的全局信息。
- 通過這種方式,上下文編碼器確保了后續的解碼器只需要關注小范圍的遮罩區域,而不是整個大尺寸的圖像。
擴散解碼器(Diffusion Decoder)
遮罩區域生成:
- 擴散解碼器的任務是根據上下文編碼器提供的全局上下文碼來生成遮罩區域內的像素。
- 與傳統的擴散模型不同,解碼器不需要對整個圖像進行迭代處理,而是只關注用戶指定的遮罩區域。
- 這種“懶惰”的生成方式顯著減少了不必要的計算,從而加快了圖像編輯的速度。
迭代去噪:
- 擴散解碼器采用迭代去噪的方法,逐步精細化遮罩區域的像素。
- 在每次迭代中,解碼器都會使用當前的上下文碼來指導遮罩區域內像素的生成,確保新生成的像素與整體圖像風格一致。
- 這個過程從一個噪聲圖像開始,逐步去除噪聲,直到生成高質量的圖像內容。
LazyDiffusion模型在計算效率方面的顯著提升,主要得益于其對遮罩大小的依賴性以及上下文編碼器的一次性編碼特性。在傳統的擴散模型中,每次迭代都需要處理整個圖像,這不僅增加了計算負擔,也延長了處理時間。與之相對,LazyDiffusion的解碼器僅針對用戶定義的遮罩區域進行像素生成,這意味著運行時間與遮罩區域的大小成正比,而非整個圖像的尺寸。對于局部編輯任務,這種設計大幅減少了不必要的計算,使得模型能夠快速響應用戶的編輯需求。
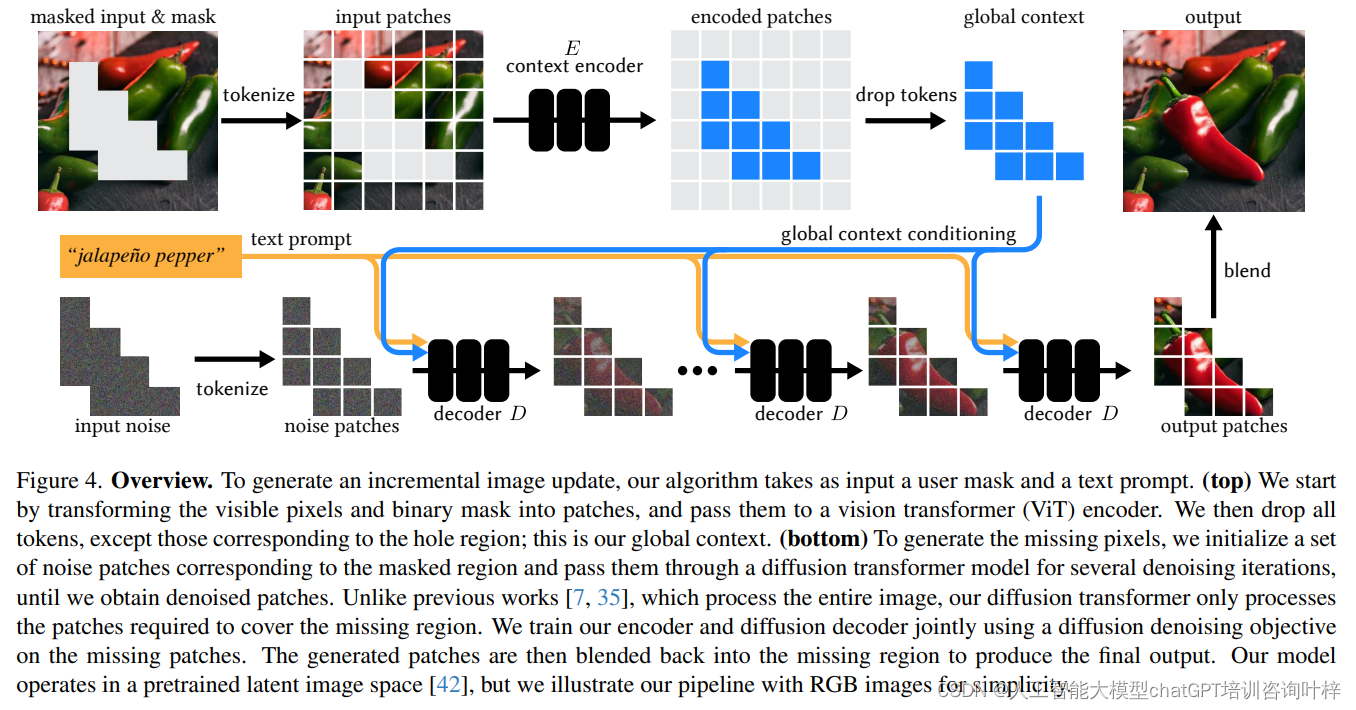
上下文編碼器的設計也極大優化了計算過程。該編碼器一次性處理整個圖像和遮罩,生成一個緊湊的全局上下文,之后在多次迭代中復用這一上下文,避免了對同一圖像重復編碼的需要。這種設計不僅提高了計算效率,還減少了內存占用和整體的計算延遲。
LazyDiffusion通過智能地壓縮和利用圖像上下文信息,以及僅對圖像的特定區域進行迭代處理,實現了計算效率的大幅提升。這使得模型特別適合于交互式圖像編輯,為用戶提供了接近實時的反饋和高度靈活的編輯體驗。在圖像編輯領域,尤其是在需要快速迭代和精細調整的場景中,LazyDiffusion展現了其巨大的潛力和應用價值。
實驗與結果
實驗設置 (Experimental Setup)
-
數據集: 研究人員使用了一個內部數據集,包含2.2億張高質量的1024×1024分辨率的圖像。這些圖像涵蓋了多種對象和場景,為模型提供了豐富的訓練材料。
-
掩碼和文本提示生成: 采用實體分割模型對圖像中的每個對象進行分割,并使用BLIP-2為每個實體生成描述性文本。為了模擬用戶創建的粗糙和不準確的掩碼,研究人員對實體掩碼進行了隨機膨脹處理。
-
基線比較: 將LazyDiffusion與兩種圖像修復基線方法進行比較,分別是RegenerateImage和RegenerateCrop。RegenerateImage處理整個圖像,而RegenerateCrop僅處理掩碼周圍的緊湊區域。
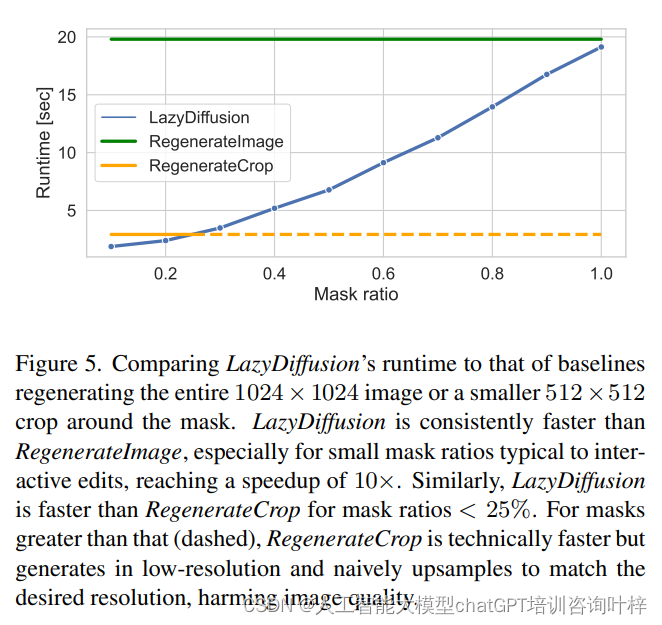
推理時間 (Inference Time)
-
性能對比: 研究人員展示了LazyDiffusion與基線方法在推理時間上的性能對比。LazyDiffusion的運行時間與掩碼的大小成比例,而基線方法則在固定大小的張量上運行,導致LazyDiffusion在處理小掩碼時具有顯著的速度優勢。
-
速度提升: 在掩碼覆蓋圖像10%的情況下,LazyDiffusion實現了比RegenerateImage快10倍的速度提升。
逐步生成 (Progressive Generation)
-
交互式編輯: LazyDiffusion顯著加快了局部圖像編輯的速度,使得擴散模型更適合于用戶參與其中的交互式應用。
-
生成示例: 論文中展示了LazyDiffusion在圖像編輯和生成中的迭代過程,從空白畫布開始,逐步添加圖像內容。
圖像修復質量 (Inpainting Quality)
-
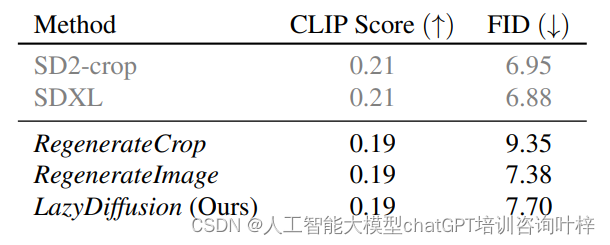
定量評估: 使用零樣本FID(Fréchet Inception Distance)和CLIPScore進行定量評估,這些指標估計了圖像與真實圖像的相似度以及文本-圖像對齊的質量。
-
用戶研究: 通過用戶研究評估模型在生成高度上下文相關的圖像修復任務中的性能。用戶在給定的掩碼輸入圖像、文本提示和兩種結果(LazyDiffusion和基線)中選擇整體看起來最好的圖像。
-
質量比較: LazyDiffusion在保持圖像全局一致性的同時,即使在壓縮上下文的情況下,也能產生與RegenerateImage和SDXL相當的修復結果。
草圖引導的圖像修復 (Sketch-guided Inpainting)
-
多樣化條件: LazyDiffusion不僅依賴掩碼和文本提示,還能適應其他形式的條件,如草圖和邊緣圖。
-
靈活性展示: 論文中通過使用用戶提供的粗略彩色草圖來引導圖像生成,展示了模型的靈活性。
實驗結果證明了LazyDiffusion在交互式圖像編輯任務中的有效性和效率,為未來的圖像編輯工具和應用提供了新的可能性。
盡管LazyDiffusion在交互式圖像編輯領域展現出巨大潛力,但研究人員也指出了一些局限性,例如在處理極高分辨率圖像時可能遇到的挑戰。未來的工作將致力于解決這些挑戰,進一步提升模型的可擴展性和適用性。
論文鏈接:https://arxiv.org/abs/2404.12382
GitHub 地址:https://lazydiffusion.github.io/
)





)


)









