在Linux服務器運維工作中,磁盤I/O瓶頸是導致系統性能下降的常見原因之一。當服務器出現響應緩慢、應用卡頓等問題時,及時定位并解決高I/O占用進程就顯得尤為重要。本文將從核心思路出發,通過“確認問題-定位磁盤-鎖定進程-深入分析”四個步驟,詳細介紹Linux下磁盤I/O高占用進程的排查方法,幫助運維人員高效解決磁盤I/O相關問題。
一、排查核心思路
磁盤I/O排查需遵循“由全局到局部、由表面到深層”的邏輯,避免盲目定位。核心流程可分為四步:
- 確認問題:先判斷性能瓶頸是否真的在磁盤I/O,而非CPU或內存。
- 全局視角:找到壓力過大的磁盤或分區,縮小排查范圍。
- 進程視角:定位對目標磁盤進行大量讀寫操作的具體進程。
- 深入分析:挖掘高I/O進程的具體行為(如讀寫文件、系統調用等),為后續優化提供依據。
二、第1步:確認全局磁盤I/O狀況
首先需要通過工具確認是否存在磁盤I/O瓶頸,并定位壓力最高的磁盤。這里首選iostat工具(來自sysstat包),它能直觀展示磁盤的讀寫速率、利用率等關鍵指標。
1.1 安裝sysstat(含iostat工具)
不同Linux發行版的安裝命令略有差異:
- Ubuntu/Debian系統:
sudo apt update && sudo apt install sysstat - CentOS/RHEL/Fedora系統:
sudo yum install sysstat # 或 sudo dnf install sysstat(Fedora新版本)
1.2 運行iostat查看磁盤狀態
使用以下命令實時監控磁盤I/O,每2秒刷新一次(間隔可自定義):
iostat -dx 2
-d:僅顯示磁盤相關統計信息,排除CPU信息。-x:顯示擴展統計信息(如等待時間、利用率),比默認輸出更詳細。
1.3 關鍵指標解讀
iostat輸出結果中,以下指標是判斷磁盤I/O瓶頸的核心:
| 指標 | 含義 | 參考標準 |
|---|---|---|
Device | 磁盤設備名(如sda、vda、nvme0n1,NVMe硬盤通常以nvme開頭) | - |
r/s/w/s | 每秒讀/寫請求數量(IOPS) | 無固定標準,需結合業務判斷 |
rkB/s/wkB/s | 每秒讀/寫數據量(吞吐量,單位KB) | 無固定標準,需結合業務判斷 |
await | 每個I/O請求的平均等待時間(毫秒),包含隊列等待時間和設備處理時間 | 正常應<10ms,>50ms說明排隊嚴重 |
%util | 磁盤設備利用率(百分比),表示磁盤忙時占比 | 持續>80%說明磁盤飽和,存在瓶頸 |
1.4 示例分析
假設iostat輸出如下:
Device r/s w/s rkB/s wkB/s await %util
sda 0.00 485.00 0.00 59420.00 120.33 98.20
vda 2.00 10.00 16.00 80.00 2.10 3.50
從結果可見:
sda磁盤的%util高達98.2%(接近飽和),await達120.33ms(排隊嚴重),wkB/s為59420KB/s(約58MB/s),說明sda是高壓力磁盤,且主要壓力來自寫入操作。vda磁盤各項指標正常,無I/O瓶頸。
三、第2步:定位高I/O占用進程
確認高壓力磁盤(如上文的sda)后,下一步需鎖定對該磁盤進行大量讀寫的進程。常用工具包括iotop(直觀實時)和pidstat(詳細統計)。
方法1:使用iotop(首選,實時監控)
iotop類似top工具,但專門針對磁盤I/O,能按進程/線程顯示實時讀寫速率,且支持交互操作。
1.1 安裝iotop
- Ubuntu/Debian系統:
sudo apt install iotop - CentOS/RHEL/Fedora系統:
sudo yum install iotop # 或 sudo dnf install iotop
1.2 運行iotop(需root權限)
sudo iotop
1.3 實用操作技巧
- 只顯示有I/O活動的進程:按下鍵盤
o鍵(或啟動時加--only參數,如sudo iotop --only),避免無關進程干擾。 - 自定義刷新間隔:通過
-d參數設置,如sudo iotop -d 3表示每3秒刷新一次。 - 按列排序:按左右箭頭鍵切換排序列(如按“DISK WRITE”排序,快速找到寫入量最大的進程)。
- 查看累計I/O:加
-a參數顯示進程累計讀寫量,而非實時速率(適合長期監控)。
1.4 輸出解讀
假設iotop輸出如下:
Total DISK READ: 0.00 B/s | Total DISK WRITE: 59.42 M/sTID PRIO USER DISK READ DISK WRITE SWAPIN IO> COMMAND4560 be/4 mysql 0.00 B/s 59.42 M/s 0.00 % 99.99 % mysqld1230 be/4 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % bash
關鍵信息:
COMMAND列顯示進程名,此處mysqld(MySQL服務進程)是主要 culprit。DISK WRITE列顯示mysqld每秒寫入59.42MB,與前文sda磁盤的寫入量匹配。IO>列顯示mysqld的I/O占用時間達99.99%,說明該進程幾乎完全占用磁盤I/O資源。
方法2:使用pidstat(詳細統計,支持歷史記錄)
pidstat是sysstat套件的一部分,不僅能顯示進程的實時I/O統計,還能記錄歷史數據,適合需要長期跟蹤的場景。
2.1 運行pidstat監控I/O
- 監控所有進程的I/O(每2秒刷新):
sudo pidstat -d 2 - 監控特定進程(已知PID后):若已通過
iotop找到可疑進程PID(如4560),可針對性監控:sudo pidstat -d -p 4560 2
2.2 輸出解讀
假設pidstat輸出如下:
Linux 5.4.0-xxx-generic 2024-05-20 _x86_64_ (4 CPU)03:15:20 PM UID PID kB_rd/s kB_wr/s kB_ccwr/s Command
03:15:22 PM 112 4560 0.00 59420.00 0.00 mysqld
03:15:24 PM 112 4560 0.00 58980.00 0.00 mysqld
關鍵指標:
kB_rd/s:進程每秒從磁盤讀取的字節數(KB),此處mysqld無讀取操作(0.00)。kB_wr/s:進程每秒向磁盤寫入的字節數(KB),mysqld穩定在約59000KB/s(58MB/s),與iotop結果一致。kB_ccwr/s:進程每秒取消寫入的字節數(KB,如文件刪除后的回寫),此處為0,無異常。
四、第3步:深入分析高I/O進程
找到高I/O進程(如mysqld,PID=4560)后,需進一步分析其具體行為,例如“讀寫哪些文件”“發起哪些系統調用”,為優化提供方向。常用工具包括lsof、strace和/proc文件系統。
方法1:用lsof查看進程打開的文件
lsof(List Open Files)可列出進程當前打開的所有文件(包括普通文件、設備文件、日志文件等),幫助定位進程讀寫的具體文件。
1.1 基礎用法(列出進程打開的所有文件)
sudo lsof -p 4560
-p 4560:指定進程PID為4560(mysqld)。
1.2 過濾關鍵文件(重點關注寫入/刪除的文件)
實際場景中,進程打開的文件可能很多,可通過grep過濾核心文件(如正在寫入的文件、已刪除但仍被占用的日志文件):
# 過濾“可寫入的普通文件”(REG類型+W權限)和“已刪除的文件”(DEL狀態)
sudo lsof -p 4560 | grep -E "REG.*W|DEL"
1.3 示例輸出與解讀
mysqld 4560 mysql 4u REG 8,1 10485760 123456 /var/lib/mysql/ib_logfile0 (deleted)
mysqld 4560 mysql 5u REG 8,1 10485760 123457 /var/lib/mysql/ib_logfile1
mysqld 4560 mysql 6u REG 8,1 524288000 123458 /var/lib/mysql/testdb.ibd
關鍵信息:
ib_logfile0(已刪除,DEL狀態)和ib_logfile1是MySQL的redo日志文件,用于崩潰恢復,mysqld正在寫入這些文件。testdb.ibd是MySQL的表空間文件,可能因大量寫入操作(如批量插入)導致高I/O。
方法2:用strace跟蹤進程的系統調用(高級調試)
strace可實時跟蹤進程發起的系統調用(如read、write、open、sync等),能精確到“進程向哪個文件寫入了多少數據”,但開銷較大,不建議在生產環境長時間運行。
2.1 基礎用法(跟蹤文件讀寫相關調用)
sudo strace -ff -p 4560 -e trace=file,write,read -s 1024 -o /tmp/mysqld_strace.txt
參數解讀:
-ff:跟蹤進程的所有子線程(如mysqld的工作線程),并為每個線程生成獨立日志文件。-p 4560:指定目標進程PID。-e trace=file,write,read:只跟蹤與“文件操作”(file)、“寫入”(write)、“讀取”(read)相關的系統調用,減少冗余日志。-s 1024:顯示字符串(如文件名)的前1024個字符,避免文件名被截斷。-o /tmp/mysqld_strace.txt:將日志輸出到指定文件(子線程日志會以mysqld_strace.txt.123形式命名)。
2.2 日志解讀示例
查看/tmp/mysqld_strace.txt,可找到類似記錄:
write(4, "\x01\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00", 16) = 16
open("/var/lib/mysql/testdb.ibd", O_RDWR|O_DIRECT|O_DSYNC) = 7
write(7, "\x08\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00", 16384) = 16384
write(4, ...):向文件描述符4(對應ib_logfile1)寫入數據。open(...):打開testdb.ibd文件,權限為“讀寫”(O_RDWR)+“直接I/O”(O_DIRECT)。write(7, ...):向testdb.ibd(文件描述符7)寫入16384字節(16KB)數據,驗證了mysqld對該表空間文件的寫入操作。
方法3:用/proc文件系統查看進程累計I/O
Linux的/proc文件系統是內核與用戶空間的接口,其中/proc/<PID>/io文件存儲了進程的累計I/O統計信息,適合手動計算進程的實時I/O速率。
3.1 查看累計I/O
sudo cat /proc/4560/io
3.2 輸出解讀與速率計算
示例輸出:
rchar: 12345678 # 進程從內核讀取的總字節數(含緩存,非物理磁盤)
wchar: 987654321 # 進程向內核寫入的總字節數(含緩存,非物理磁盤)
syscr: 120 # 進程發起的讀系統調用次數
syscw: 450 # 進程發起的寫系統調用次數
read_bytes: 4096000 # 進程從物理磁盤讀取的總字節數(KB)
write_bytes: 20480000 # 進程向物理磁盤寫入的總字節數(KB)
cancelled_write_bytes: 0 # 取消寫入的總字節數
- 實時速率計算:間隔10秒讀取兩次
write_bytes,計算差值除以時間:- 第一次讀取:
write_bytes=20480000 - 10秒后第二次讀取:
write_bytes=26480000 - 寫入速率 = (26480000 - 20480000) / 10 = 600000 KB/s = 600 MB/s(此處為示例,實際需根據真實數據計算)。
- 第一次讀取:
五、常見高I/O進程場景與優化方向
排查出高I/O進程后,需結合業務場景制定優化方案。以下是常見高I/O進程及對應的優化思路:
| 進程類型 | 常見場景 | 優化方向 |
|---|---|---|
| 數據庫(MySQL/PostgreSQL) | 1. 大量寫入(如批量插入、日志刷盤);2. 全表掃描導致的大量讀取;3. 臟頁頻繁刷新。 | 1. 調整數據庫參數(如MySQL的innodb_flush_log_at_trx_commit);2. 優化SQL(加索引避免全表掃描);3. 升級磁盤(如機械硬盤換SSD)。 |
| 日志服務(rsyslog/journald) | 應用日志輸出過多(如 debug 級別日志未關閉),導致日志文件頻繁寫入。 | 1. 調整日志級別(如改為 info/warn);2. 配置日志輪轉(logrotate),避免單個日志文件過大;3. 日志歸檔到遠程存儲(如ELK)。 |
| 備份工具(rsync/tar/cp) | 全量備份時大量讀取源文件,寫入目標存儲,占用磁盤I/O。 | 1. 改為增量備份(如rsync --link-dest);2. 在業務低峰期執行備份;3. 使用多線程工具(如pigz替代gzip壓縮)。 |
| 包管理器(apt/yum) | 批量安裝/更新軟件時,大量下載包并解壓寫入磁盤。 | 1. 選擇業務低峰期執行更新;2. 配置本地yum/apt源(如阿里云鏡像),減少下載耗時。 |
| 虛擬機/容器(KVM/Docker) | 虛擬機磁盤鏡像(qcow2/raw)或容器數據卷的頻繁讀寫。 | 1. 使用SSD存儲鏡像/數據卷;2. 配置磁盤緩存策略(如KVM的cache=writeback);3. 限制容器I/O速率(如Docker的–device-read-bps)。 |
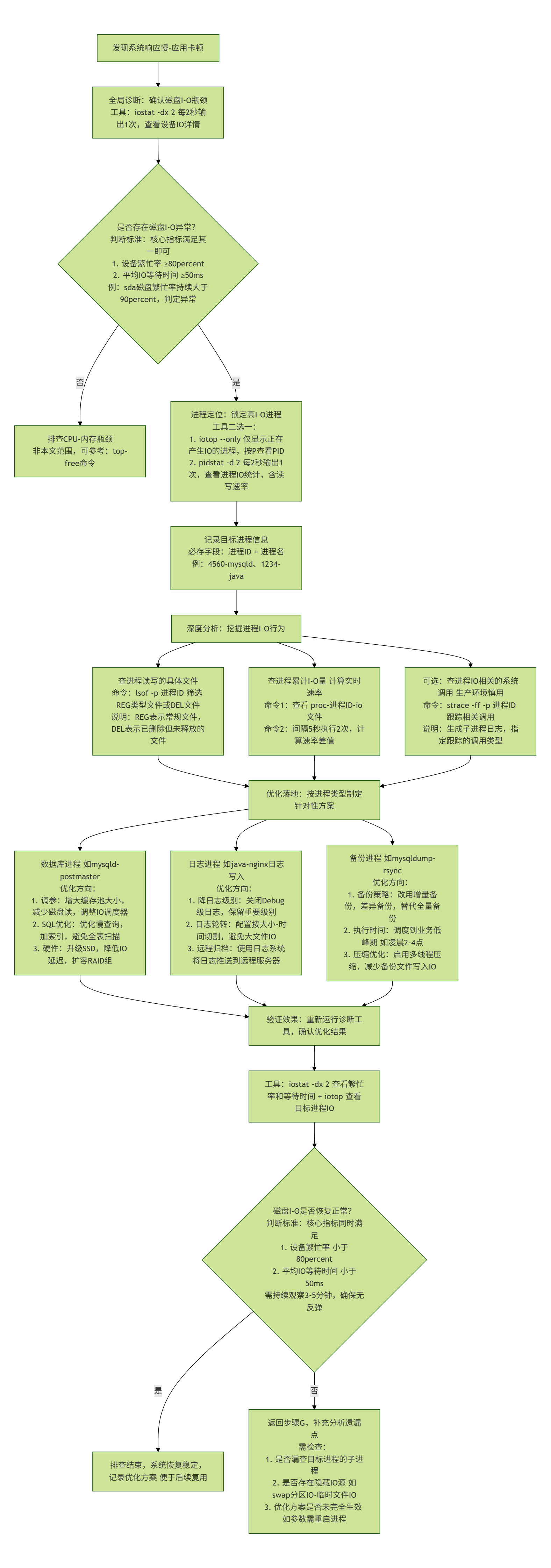
六、排查流程總結(附流程圖)
Linux 磁盤 I/O 高占用進程的排查需遵循“從全局到局部、從現象到本質”的邏輯,通過標準化流程可高效定位問題并落地解決方案。以下為完整排查流程拆解及可視化流程圖。
1. 排查流程分步拆解
步驟 1:全局診斷 - 確認磁盤 I/O 瓶頸
- 核心目標:判斷性能問題是否源于磁盤 I/O(排除 CPU、內存瓶頸干擾),定位高壓力磁盤。
- 執行工具:
iostat(需提前安裝sysstat套件)。 - 關鍵操作:
- 運行命令
sudo iostat -dx 2(每 2 秒刷新一次,-d僅顯磁盤、-x顯擴展指標)。 - 重點關注指標:
%util(磁盤利用率,持續 >80% 為飽和)、await(I/O 等待時間,>50ms 為排隊嚴重)、wkB/s/rkB/s(讀寫吞吐量)。 - 輸出結果中,篩選出
%util和await異常的磁盤(如sda),作為后續排查焦點。
- 運行命令
步驟 2:進程定位 - 鎖定高 I/O 進程
- 核心目標:找到對“高壓力磁盤”進行大量讀寫的具體進程(獲取 PID 和進程名)。
- 執行工具:優先用
iotop(實時直觀),備選pidstat(統計詳細)。 - 關鍵操作(以
iotop為例):- 運行命令
sudo iotop --only(--only僅顯有 I/O 活動的進程,減少干擾)。 - 按“DISK WRITE”或“DISK READ”列排序(左右箭頭鍵切換),定位讀寫量最大的進程。
- 記錄目標進程的 PID(如 4560)和 進程名(如
mysqld),用于下一步分析。
- 運行命令
步驟 3:深度分析 - 挖掘進程 I/O 行為
- 核心目標:明確高 I/O 進程的具體操作(如讀寫哪些文件、發起哪些系統調用),為優化提供依據。
- 執行工具:
lsof(查打開的文件)、/proc/<PID>/io(查累計 I/O 統計)、strace(查系統調用,謹慎使用)。 - 關鍵操作:
- 查讀寫文件:運行
sudo lsof -p 4560 | grep -E "REG.*W|DEL",篩選進程寫入的普通文件(REG.*W)或已刪除但仍占用的文件(DEL,如未釋放的日志),定位核心讀寫文件(如/var/lib/mysql/testdb.ibd)。 - 查累計 I/O:運行
sudo cat /proc/4560/io,通過對比不同時間的write_bytes/read_bytes,計算進程實時 I/O 速率(如間隔 10 秒差值 ÷10 得每秒寫入量)。 - 查系統調用(可選):若需精準跟蹤操作,運行
sudo strace -ff -p 4560 -e trace=file,write -o /tmp/strace.log(-ff跟蹤子線程,-e過濾關鍵調用),但需注意:strace性能開銷較大,生產環境避免長時間運行。
- 查讀寫文件:運行
步驟 4:優化落地 - 解決 I/O 瓶頸
- 核心目標:結合進程類型和業務場景,制定針對性優化方案,降低磁盤 I/O 壓力。
- 優化方向(按進程類型匹配):
- 數據庫進程(如
mysqld):調整參數(如 MySQL 的innodb_flush_log_at_trx_commit降低刷盤頻率)、優化 SQL(加索引避免全表掃描)、升級磁盤(機械硬盤換 SSD)。 - 日志進程(如
rsyslog):降低日志級別(debug → info)、配置logrotate日志輪轉、將日志歸檔至遠程存儲(如 ELK 集群)。 - 備份進程(如
rsync):改為增量備份(rsync --link-dest)、在業務低峰期執行、用多線程工具(如pigz替代gzip壓縮)。
- 數據庫進程(如
- 驗證效果:優化后重新運行
iostat和iotop,確認磁盤%util、await恢復正常,高 I/O 進程讀寫量下降。
2. 排查流程可視化流程圖
通過上述流程,可標準化解決 Linux 磁盤 I/O 高占用問題。實際運維中需注意:優先使用 iostat、iotop 等低開銷工具,避免在生產環境濫用 strace;優化方案需結合業務特性(如數據庫不可中斷,需選擇低風險參數調整),確保穩定性優先。

與LED點陣驅動原理)




——靜態方法)

)
)







評測與實操:5 秒在線摳圖、支持批量與換底(電商/設計團隊提效指南))

