英文名稱:Stock Price Trend Prediction using Emotion Analysis of Financial Headlines with Distilled LLM Model ?
中文名稱:利用蒸餾大型語言模型對財務新聞標題情緒分析以預測股價趨勢 ?
鏈接: https://dl.acm.org/doi/pdf/10.1145/3652037.3652076
作者: Rithesh H. Bhat, Bhanu Jain ?
機構: University of Texas at Arlington ?
日期:2024?06?26?
摘要
目標:探討僅通過財務新聞標題中的情緒分析是否能夠在無財務數據情況下預測股票價格趨勢。
方法:使用輕量蒸餾大型語言模型分析財務新聞標題的情緒,再結合多種機器學習分類算法預測次日股價方向。
結論:基于新聞標題情緒的特征預測準確性可與使用傳統財務數據的模型相當,不依賴抓取公司財務數據亦可有效預測股價走勢。
讀后感
內容簡潔明了,各種具體的實現方法不僅清晰而且易于執行。驚喜的是,這里提到可以從 Kaggle 上下載 2009-2020 年間超過百萬條的股票相關新聞數據(下載鏈接)。
不過這個預測的目標顯得有些單一,僅僅是預測股價是漲是跌,相對而言較為簡單。

1 引言
通過基于 API 的機制檢索財經新聞頭條,并訓練輕量化、計算快速的蒸餾 LLM 模型,以捕捉公司金融新聞頭條的情緒基調和強度。隨后,我們將這些情緒信息與多種機器學習分類算法結合使用,僅通過新聞的情緒分析預測股價走勢。我們證明,利用金融新聞標題中的情緒分析屬性預測股價方向,與僅依賴財務數據運行的算法一樣準確。
1.1 主要貢獻
通過金融聚合器的 API 創建預測股票價格所需的數據集,避免了網絡抓取用于策劃金融數據集的復雜過程。
展示如何微調預訓練的 LLM 模型,以有效預測財經新聞頭條的情緒。
使用蒸餾的 LLM 模型執行文本分類任務,代替傳統 NLP 方法,實現同樣的目標。
針對情緒和財務特性,分別執行分類算法,以預測股價走勢。
對所采用方法的局限性和挑戰進行分析和討論。
2 數據聚合
2.1 股票選擇
本研究選取了來自美國的 32 家市值超過 2000 億美元的大型上市公司。這些公司具有新聞曝光度高、數據豐富等特點,便于獲取高質量的財經新聞,從而有效研究新聞標題所包含的信息與股價趨勢之間的相關性。
我們收集了與這些公司相關的兩個維度的數據:
財經新聞
股票的日常財務指標(開盤價、收盤價、成交量、當日最高價和最低價等)
2.2 財經新聞提取
為確保新聞數據的權威性與一致性,我們未采用網頁爬蟲,而是通過官方新聞聚合平臺 NewsAPI.org 提取新聞內容。NewsAPI 提供免費和付費版本的服務,在免費計劃下,每日可請求最多 100 條新聞數據,覆蓋全球主流媒體。
需要注意的是,NewsAPI 的響應中并不包含完整的文章正文,僅提供新聞的標題、描述、來源、發布時間、圖片鏈接及原文鏈接等元數據。
2.3 財務屬性數據獲取
股票價格及財務屬性數據通過 Alpha Vantage 獲取,該平臺提供包括實時和歷史數據在內的金融市場數據服務。用戶需注冊賬號并獲取 API Key。在免費額度下,每日最多請求 25 次數據,因此無法支持對所有公司進行高頻監控。
獲取的數據包括:
每日股價(開盤、收盤、最高、最低)
成交量
年度與季度收益報告等基本面信息
2.4 數據采集使用的工具庫
我們分別使用?newsapi-python?和?alphavantage?兩個官方 Python 包從上述 API 獲取數據。這些庫封裝了常用請求方法,便于快速集成。
上述信息經清洗后統一存儲至 Postgres 數據庫。
2.5 歷史新聞數據的補充
由于 NewsAPI 的免費套餐僅允許訪問最近 30 天的數據,我們通過 Kaggle 補充了歷史財經新聞數據,獲取了 2009 年至 2020 年期間,涵蓋 6,000 只股票的新聞標題數據,以提升模型的泛化能力與長期預測效果。
2.6 情緒分析
本研究引入情緒分析而非傳統的情感(sentiment)分析,是為了獲得更細致的情緒標簽和更高維度的表達。相比二元(正面 / 負面)或三元(正面 / 中性 / 負面)情感分類,情緒分析提供了對具體情緒類別(如憤怒、喜悅、恐懼等)的識別,更有助于理解金融新聞中對市場潛在影響的細節。
2.7 模型選擇策略
在本地部署了一款輕量級的蒸餾版語言模型:emotion-english-distilroberta-base。這是基于 RoBERTa-base 的變體,專為英文情緒識別任務優化。
該模型支持基于 Ekman 情緒理論的 7 類標簽:
憤怒(anger)
厭惡(disgust)
恐懼(fear)
喜悅(joy)
悲傷(sadness)
驚訝(surprise)
中性(neutral)
該分類粒度適中,適合捕捉財經新聞標題中隱含的心理預期和市場反應傾向。
2.8 模型訓練數據
為了增強模型對財經領域術語和表達的理解,我們采用有監督微調方法對模型進行定制訓練。具體流程如下:
首先人工對一批財經新聞標題進行標注,每條標題分配一個情緒標簽;
然后使用這些帶標簽的數據對基礎模型進行訓練,使其適應金融語境下的情緒識別任務。
訓練的核心目標是提升模型對財經類文本的感知精度,而不僅僅依賴通用語料中的語言特征。
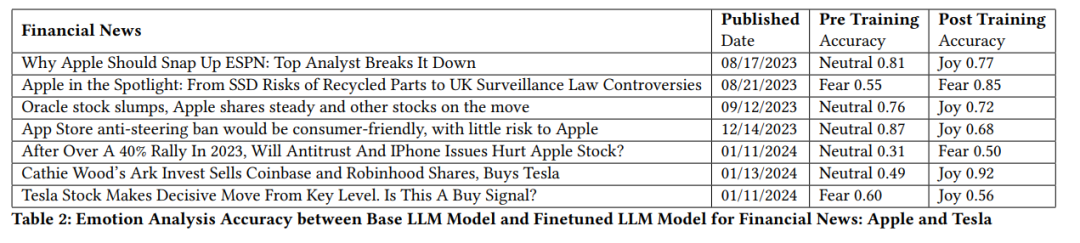
2.9 微調效果
在微調階段,我們僅使用了 76 條具有不同情緒標簽的新聞標題進行訓練,樣本數量雖少,但模型表現有明顯提升。微調后的模型在預測財經新聞的情緒類別上更加敏感,尤其對“恐懼”“驚訝”等高影響力情緒的識別更準確。
表 2 展示了模型微調前后的性能對比,具體指標包括準確率、召回率和 F1 分數,均有實質性改善。
3 實驗
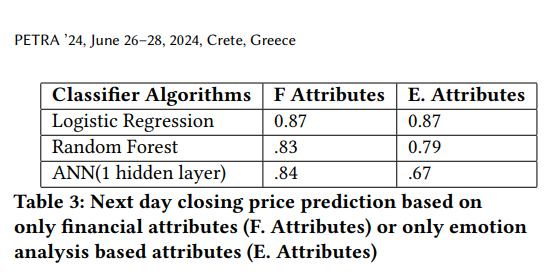
- 實驗一
:通過 SQL 查詢提取指定時間范圍內的情緒標簽、情緒強度(emotion_strength)以及收盤價。對 7 類情緒(憤怒、厭惡、恐懼、喜悅、中性、悲傷、驚訝)進行獨熱編碼,轉化為布爾特征。
- 實驗二
:提取同一時間段內的股價相關數據,包括開盤價、收盤價、最高價、最低價、成交量及收盤價的滾動平均。
為防止過擬合,兩組實驗均移除了公司名稱、日期等非關鍵字段。
標簽設置為二分類:若次日收盤價高于當日,則為 1,否則為 0。
數據按 8:2 比例劃分為訓練集和測試集。
兩個實驗均分別使用三種分類算法進行建模:邏輯回歸、隨機森林、人工神經網絡(ANN)。




 規范深度解析)
![[硬件電路-179]:集成運放,虛短的是電壓,虛斷的是電流](http://pic.xiahunao.cn/[硬件電路-179]:集成運放,虛短的是電壓,虛斷的是電流)

結合子陣列算法,創建基于區塊鏈的動態信任管理模型)








——事件監聽(用戶交互))


