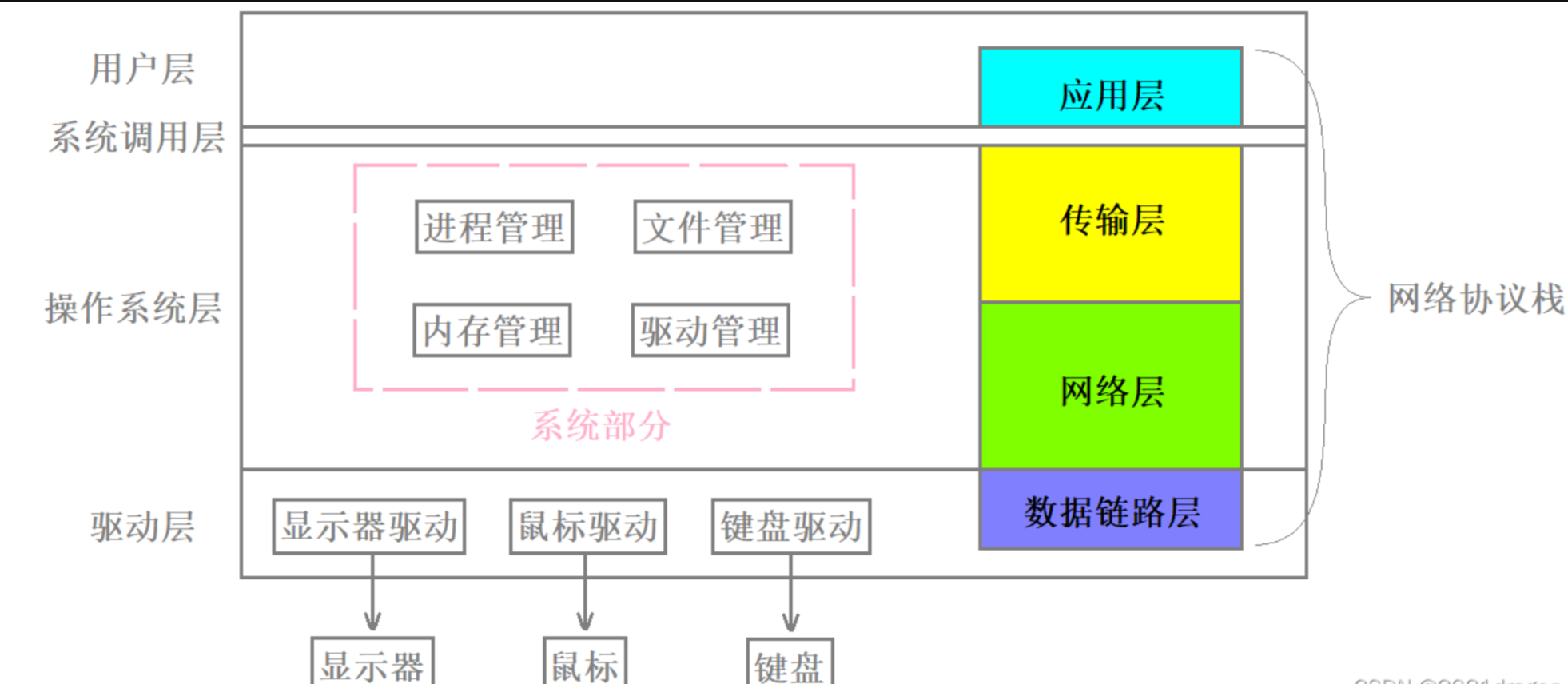
1.網絡協議棧
一般一個主機內的應用(進程)進行通信,直接在操作系統層面進行 進程交互即可。而不同位置兩臺主機進行通信需要通過網線傳輸信號,因此 這些通信的數據為網絡數據,而網絡數據進程傳輸必須從應用層依次向下包裝一直到物理層。
操作系統中的進程管理、文件管理、內存管理、驅動管理是隸屬于系統部分的,系統部分的核心工作就是管理好各種軟硬件資源,對上提供一個良好穩定的運行環境。現代操作系統由系統和網絡兩部分組成。
操作系統中除了有這四大管理模塊,還有與網絡協議棧有著密切的關系。網絡協議棧主要負責數據的通信,其自頂向下可分為四層,分別是應用層、傳輸層、網絡層、數據鏈路層。
網絡協議棧各部分所處位置:
- 應用層是位于用戶層的。?這部分代碼是由網絡協議的開發人員來編寫的,比如HTTP協議、HTTPS協議以及SSH協議等。他通過各種系統調用 處理tcp層接收的數據
- 傳輸層和網絡層是位于操作系統層的。?其中傳輸層最經典的協議叫做TCP協議,網絡層最經典的協議叫做IP協議,這就是我們平常所說的TCP/IP協議。
- 數據鏈路層是位于驅動層的。?其負責真正的數據傳輸。
Linux內核包含的代碼:TCP處理 → IP處理 → 網卡驅動
協議分層
協議分層的好處
網絡協議棧設計成層狀結構,其目的就是為了將層與層之間進行解耦,保證代碼的可維護性和可擴展性。每一層都有自己的功能。看上去就像是層與層通信。
OSI七層模型
上面我們說的是TCP/IP四層協議,而實際當初那個站出來的人定的協議叫做OSI七層協議:
- OSI(Open System Interconnection,開放系統互聯)七層網絡模型稱為開方式系統互聯參考模型,是一個邏輯上的定義和規范。
- SI把網絡從邏輯上分為了七層,每一層都有相關的、相對應的物理設備,比如路由器,交換機。
- OSI七層模型是一種框架性的設計方法,其最主要的功能就是幫助不同類型的主機實現數據傳輸,比如手機和電視之間數據的傳輸。
- OSI七層模型最大的優點是將服務、接口和協議這三個概念明確地區分開來,概念清楚,理論也比較完整,通過七個層次化的結構模型使不同的系統不同的網絡之間實現可靠的通訊。
但是,OSI七層模型既復雜又不實用,所以后來在具體實現的時候就對其進行了調整,于是就有了我們現在看到的TCP/IP四層協議。
TCP/IP五層(或四層)模型
TCP/IP是一組協議的代名詞,它還包括許多協議,共同組成了TCP/IP協議簇。TCP/IP通訊協議采用了五層的層級結構,每一層都呼叫它的下一層所提供的網絡來完成自己的需求。
- 物理層:?負責光/電信號的傳遞方式。比如現在以太網通用的網線(雙絞線)、早期以太網采用的同軸電纜(現在主要用于有線電視)、光纖,現在的WiFi無線網使用的電磁波等都屬于物理層的概念。物理層的能力決定了最大傳輸速率、傳輸距離、抗干擾性等。集線器(Hub)就是工作在物理層的。
- 數據鏈路層:?負責設備之間的數據幀的傳送和識別。例如網卡設備的驅動、幀同步、沖突檢測(如果檢測到沖突就自動重發)、數據差錯校驗等工作。數據鏈路層底層的網絡通信標準有很多,如以太網、令牌環網、無線LAN等。交換機(Switch)就是工作在數據鏈路層的。
- 網絡層:?負責地址管理和路由選擇。例如在IP協議中,通過IP地址來標識一臺主機,并通過路由表的方式規劃出兩臺主機之間數據傳輸的線路(路由)。路由器(Router)就是工作在網絡層的。
- 傳輸層:?負責兩臺主機之間的數據傳輸。例如傳輸控制協議(TCP),能夠確保數據可靠的從源主機發送到目標主機。
- 應用層:?負責應用程序間溝通。比如簡單電子郵件傳輸(SMTP)、文件傳輸協議(FTP)、網絡遠程訪問協議(Telnet)等。我們的網絡編程主要就是針對應用層的。
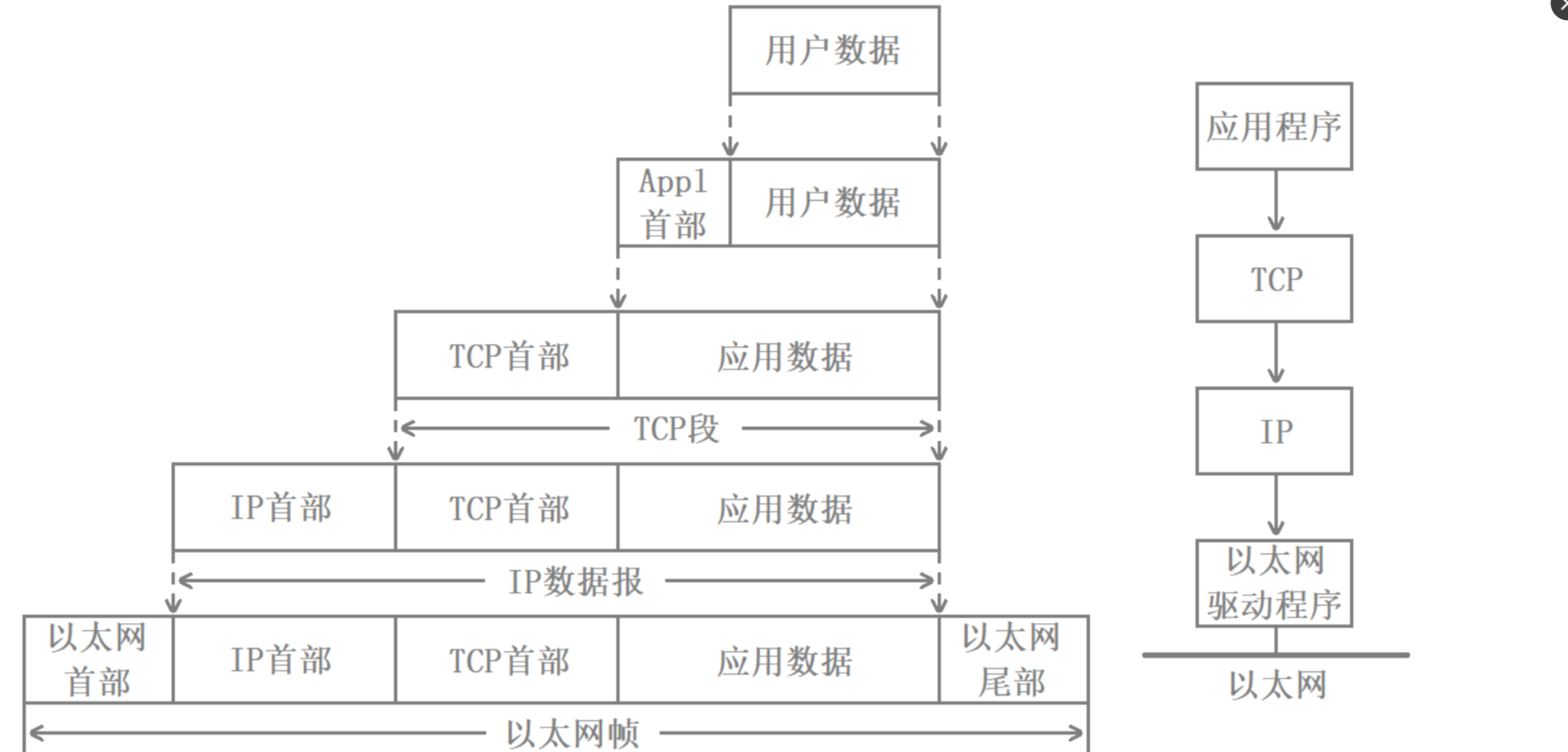
數據包封裝和分用
- 不同協議層對數據包有不同的稱謂,在傳輸層叫做段(segment),在網絡層叫做數據報(datagram),在鏈路層叫做幀(frame)。
- 應用層數據通過協議棧發到網絡上,每層協議都要加上一個數據首部(header),稱為封裝(Encapsulation)。
下圖為數據封裝的過程:
如何將報頭與有效載荷進行分離?
協議棧的每一層都要從數據中提取對應的報頭信息,而要將數據中的報頭提取出來,首先就需要明確報頭與有效載荷之間的界限,這樣才能將它們進行分離。而每一層添加報頭時都是將報頭添加到數據的首部的,因此我們只要知道了報頭的大小,就能夠講報頭和有效載荷進行分離。
獲取報頭大小的方法通常有兩種:
- 定長報頭。顧名思義就是報頭的大小是固定的。
- 自描述字段。報頭當中提供了一個字段,用來表示報頭的長度。
實際上每個協議都要提供一種方法,讓我們獲取到報頭的大小,這樣我們才能在解包時將報頭與有效載荷進行分離。
如何判斷發送出去的數據是否發生了碰撞?
因為發送到局域網當中的數據是所有主機都能夠收到的,因此當一個主機將數據發送出去后,該主機本身也是能夠收到這個數據的。當該主機收到該數據后就可以將其與之前發送出去的數據進行對比,如果發現收到的數據與之前發送出去的數據不相同,則說明在發送過程中發生了碰撞。
發生碰撞后是如何處理的?
當一個主機發現自己發送出去的數據產生了碰撞,此時該主機就要執行“碰撞避免”算法。“碰撞避免”算法實際很簡單:當一個主機發送出去的數據產生了碰撞,那么該主機可以選擇等一段時間后,再重新發送該數據。
每個主機如何判斷該數據是否是發送給自己的?
在局域網中發送的數據實際叫做MAC數據幀,在這個MAC數據幀的報頭當中會包含兩個字段,分別叫做源MAC地址和目的MAC地址。
每一臺計算機都至少配有一張網卡,而每一張網卡在出廠時就已經內置了一個48位的序列號,我們將這個序列號稱之為“MAC地址”,這個MAC地址是全球唯一的。
跨網絡的兩臺主機通信
局域網之間都是通過路由器連接起來的,因此一個路由器至少能夠橫跨兩個局域網。而這些被路由器級聯局域網都認為,該路由器就是本局域網內的一臺主機,因此路由器可以和這些局域網內的任意一臺主機進行直接通信。
比如局域網1當中的主機A想要和局域網2當中的主機H進行通信,那么主機A可以先將數據發送給路由器,然后路由器再將數據轉發給局域網2當中的主機H。
路由器為什么能夠“認路”?
根據路由表和 目的ip字段
以太網
局域網技術
不同局域網所采用的通信技術可能是不同的,常見的局域網技術有以下三種:
- 以太網:以太網是一種計算機局域網技術,一種應用最普遍的局域網技術。
- 令牌環網:令牌環網常用于IBM系統中,在這種網絡中有一種專門的幀稱為“令牌”,在環路上持續地傳輸來確定一個節點何時可以發送包。
- 無線LAN/WAN:無線局域網是有線網絡的補充和擴展,現在已經是計算機網絡的一個重要組織部分。
以太網幀格式如下:

- 源地址和目的地址是指網卡的硬件地址(也叫MAC地址),長度是48位,是在網卡出廠時固化的。
- 幀協議類型字段有三種值,分別對應IP協議、ARP協議和RARP協議。
- 幀末尾是CRC校驗碼。
舉個例子
假設局域網當中的主機A想要將IP數據報發送給同一局域網當中的主機B,那么主機A封裝MAC幀當中的目的地址就是主機B的MAC地址,源地址就是主機A的MAC地址,而幀協議的類型對應就是0800,緊接著就是要發送的IP數據報,幀尾部分對應就是CRC校驗。
當主機A將該MAC幀發送到局域網當中后,局域網當中的所有主機都可以收到這個MAC幀,包括主機A自己。
- 主機A收到該MAC幀后,可以對收到的MAC幀進行CRC校驗,如果校驗失敗則說明數據發送過程中產生了碰撞,此時主機A就會執行碰撞避免算法,后續進行MAC幀重發。
- 主機B收到該MAC幀后,提取出MAC幀當中的目的地址,發現該目的地址與自己的MAC地址相同,于是在CRC校驗成功后就會將有效載荷交付給上層IP層進行進一步處理。
認識MTU
MTU(Maximum Transmission Unit,最大傳輸單元)描述的是底層數據幀一次最多可以發送的數據量,這個限制是不同的數據鏈路層對應的物理層產生的。
- 以太網對應MTU的值一般是1500字節,不同的網絡類型有不同的MTU,如果一次要發送的數據超過了MTU,則需要在IP層對數據進行分片(fragmentation)。
- 此外,以太網規定MAC幀中數據的最小長度為46字節,如果發送數據量小于46字節,則需要在數據后面補填充位,比如ARP數據包的長度就是不夠46字節的。
MUT對IP協議的影響
因為數據鏈路層規定了最大傳輸單元MTU,所以如果IP層一次要發送的數據量超過了MTU,此時IP層就需要先對該數據進行分片,然后才能將分片后的數據向下交付。
- IP層會將較大的數據進行分片,并給每個分片數據包進行標記,具體就是通過設置IP報頭當中的16位標識、3位標志和13位片偏移來完成的。
- 由同一個數據分片得到的各個分片報文,所對應的IP報頭當中的16位標識(id)都是相同的。
- 每一個分片報文的IP報頭當中的3位標志字段中,第2位設置為0,表示允許分片,第3位用作結束標記(最后一個分片報文設置為0,其余分片報文設置為1)。
MTU對TCP協議的影響
對于TCP來說,分片也會增加TCP報文丟包的概率,但與UDP不同的是TCP丟包后還需要進行重傳,因此TCP應該盡量減少因為分片導致的數據重傳。
- TCP發送的數據報不能無限大,還是應該受制于MTU,我們將TCP的單個數據報的最大報文長度,稱為MSS(Max Segment Size)。
- TCP通信雙方在建立連接的過程中,就會進行MSS協商,最終選取雙方支持的MSS值當中的較小值作為最終MSS。
ARP協議
地址解析協議(Address?Resolution Protocol,ARP)協議,是根據IP地址獲取MAC地址的一個TCP/IP協議。

ARP數據的格式

ARP請求的過程
首先路由器D需要先構建ARP請求。
- 首先,因為路由器D構建的是ARP請求,因此ARP請求當中的op字段設置為1。
- ARP請求當中的硬件類型字段設置為1,因為當前使用的是以太網通信。
- ARP請求當中的協議類型設置為0800,因為路由器是要根據主機B的IP地址來獲取主機B的MAC地址。
- ARP請求當中的硬件地址長度和協議地址長度分別設置為6和4,因為MAC地址的長度是48位,IP地址的長度是32位。
- ARP請求當中的發送端以太網地址和發送端IP地址,對應就是路由器D的MAC地址和IP地址。
- ARP請求當中的目的以太網地址和目的IP地址,對應就是主機B的MAC地址和IP地址,但由于路由器D不知道主機B的MAC地址,因此將目的以太網地址的二進制序列設置為全1,表示在局域網中進行廣播。
總結:
發起方構建ARP請求,以廣播的方式發送給每一個主機。
每臺主機都能識別接收,然后根據MAC幀的幀類型字段將有效載荷交付給每個主機的ARP層。
其他不相關主機立馬根據目的IP,在自己的ARP協議內部丟棄ARP請求,只有目標主機會處理請求。
ARP緩存表
實際不是每次要獲取對方的MAC地址時都需要發起ARP請求,每次發起ARP請求后都會建立對應主機IP地址和MAC地址的映射關系,每臺主機都維護了一個ARP緩存表,我們可以用arp -a命令進行查看。
網絡編程套接字
理解源端口號和目的端口號
首先我們需要明確的是,兩臺主機之間通信的目的不僅僅是為了將數據發送給對端主機,而是為了訪問對端主機上的某個服務。比如我們在用百度搜索引擎進行搜索時,不僅僅是想將我們的請求發送給對端服務器,而是想訪問對端服務器上部署的百度相關的搜索服務。
socket通信的本質
現在通過IP地址和MAC地址已經能夠將數據發送到對端主機了,但實際我們是想將數據發送給對端主機上的某個服務進程,此外,數據的發送者也不是主機,而是主機上的某個進程,比如當我們用瀏覽器訪問數據時,實際就是瀏覽器進程向對端服務進程發起的請求。
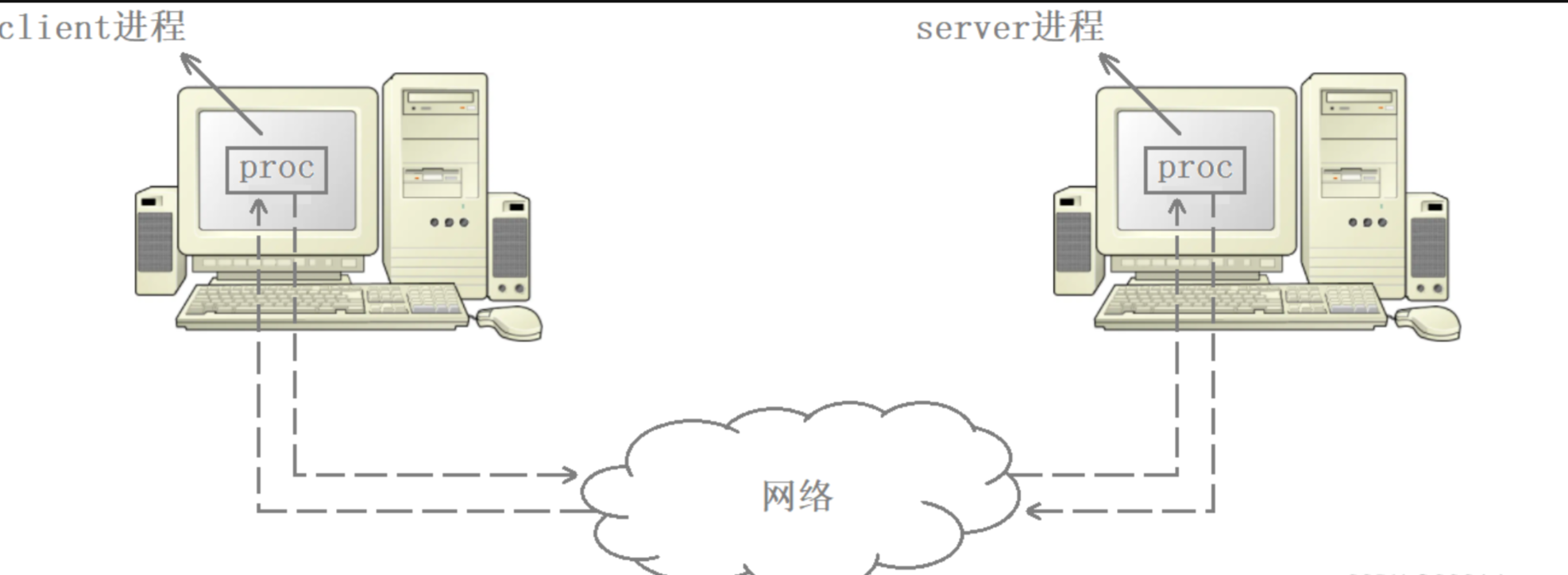
socket通信本質上就是兩個進程之間在進行通信,只不過這里是跨網絡的進程間通信。比如逛淘寶和刷抖音的動作,實際就是手機上的淘寶進程和抖音進程在和對端服務器主機上的淘寶服務進程和抖音服務進程之間在進行通信。
因此進程間通信的方式除了管道、消息隊列、信號量、共享內存等方式外,還有套接字,只不過前者是不跨網絡的,而后者是跨網絡的。
端口號
實際在兩臺主機上,可能會同時存在多個正在進行跨網絡通信的進程,因此當數據到達對端主機后,必須要通過某種方法找到該主機上對應的服務進程,然后將數據交給該進程處理。
端口號(port)的作用實際就是標識一臺主機上的一個進程。
- 端口號是傳輸層協議的內容。
- 端口號是一個2字節16位的整數。
- 端口號用來標識一個進程,告訴操作系統,當前的這個數據要交給哪一個進程來處理。
- 一個端口號只能被一個進程占用。
由于IP地址能夠唯一標識公網內的一臺主機,而端口號能夠唯一標識一臺主機上的一個進程,因此用IP地址+端口號就能夠唯一標識網絡上的某一臺主機的某一個進程。
底層如何通過port找到對應進程的?
實際底層采用哈希的方式建立了端口號和進程PID或PCB之間的映射關系,當底層拿到端口號時就可以直接執行對應的哈希算法,然后就能夠找到該端口號對應的進程。
網絡字節序
網絡中的大小端問題
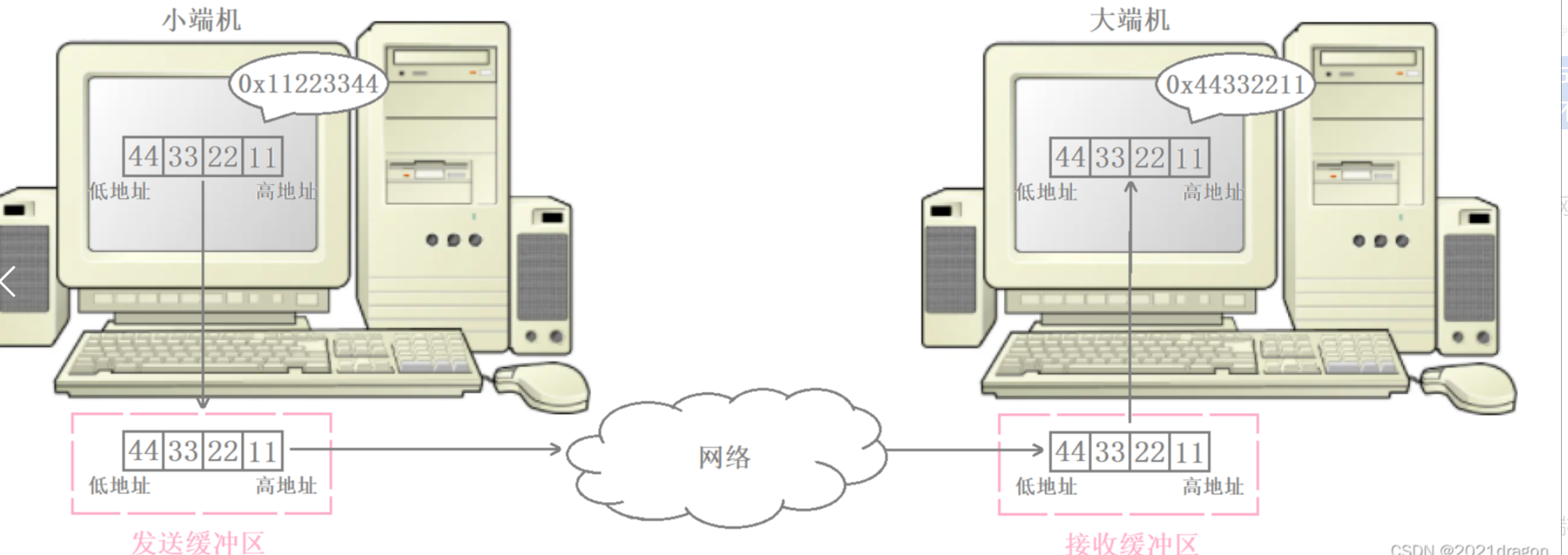
由于發送端和接收端采用的分別是小端存儲和大端存儲,此時對于內存地址從低到高為44332211的序列,發送端按小端的方式識別出來是0x11223344,而接收端按大端的方式識別出來是0x44332211,此時接收端識別到的數據與發送端原本想要發送的數據就不一樣了,這就是由于大小端的偏差導致數據識別出現了錯誤。
socket編程接口
socket常見API
創建套接字:(TCP/UDP,客戶端+服務器)
int socket(int domain, int type, int protocol);綁定端口號:(TCP/UDP,服務器)
int bind(int sockfd, const struct sockaddr *addr, socklen_t addrlen);sockaddr結構
sockaddr結構的出現
套接字不僅支持跨網絡的進程間通信,還支持本地的進程間通信(域間套接字)。
在進行跨網絡通信時我們需要傳遞的端口號和IP地址,而本地通信則不需要,因此套接字提供了sockaddr_in結構體和sockaddr_un結構體,其中sockaddr_in結構體是用于跨網絡通信的,而sockaddr_un結構體是用于本地通信的。
簡單的UDP網絡程序
服務端創建套接字
我們把服務器封裝成一個類,當我們定義出一個服務器對象后需要馬上初始化服務器,而初始化服務器需要做的第一件事就是創建套接字。
socket函數
創建套接字的函數叫做socket,該函數的函數原型如下:
int socket(int domain, int type, int protocol);參數說明:
- domain:創建套接字的域或者叫做協議家族,也就是創建套接字的類型。該參數就相當于
struct sockaddr結構的前16個位。如果是本地通信就設置為AF_UNIX,如果是網絡通信就設置為AF_INET(IPv4)或AF_INET6(IPv6)。 - type:創建套接字時所需的服務類型。其中最常見的服務類型是SOCK_STREAM和SOCK_DGRAM,如果是基于UDP的網絡通信,我們采用的就是SOCK_DGRAM,叫做用戶數據報服務,如果是基于TCP的網絡通信,我們采用的就是SOCK_STREAM,叫做流式套接字,提供的是流式服務。
- protocol:創建套接字的協議類別。你可以指明為TCP或UDP,但該字段一般直接設置為0就可以了,設置為0表示的就是默認,此時會根據傳入的前兩個參數自動推導出你最終需要使用的是哪種協議。
返回值說明:
- 套接字創建成功返回一個文件描述符,創建失敗返回-1,同時錯誤碼會被設置。
socket函數底層做了什么?
socket函數是被進程所調用的,而每一個進程在系統層面上都有一個進程地址空間PCB(task_struct)、文件描述符表(files_struct)以及對應打開的各種文件。而文件描述符表里面包含了一個數組fd_array,其中數組中的0、1、2下標依次對應的就是標準輸入、標準輸出以及標準錯誤。
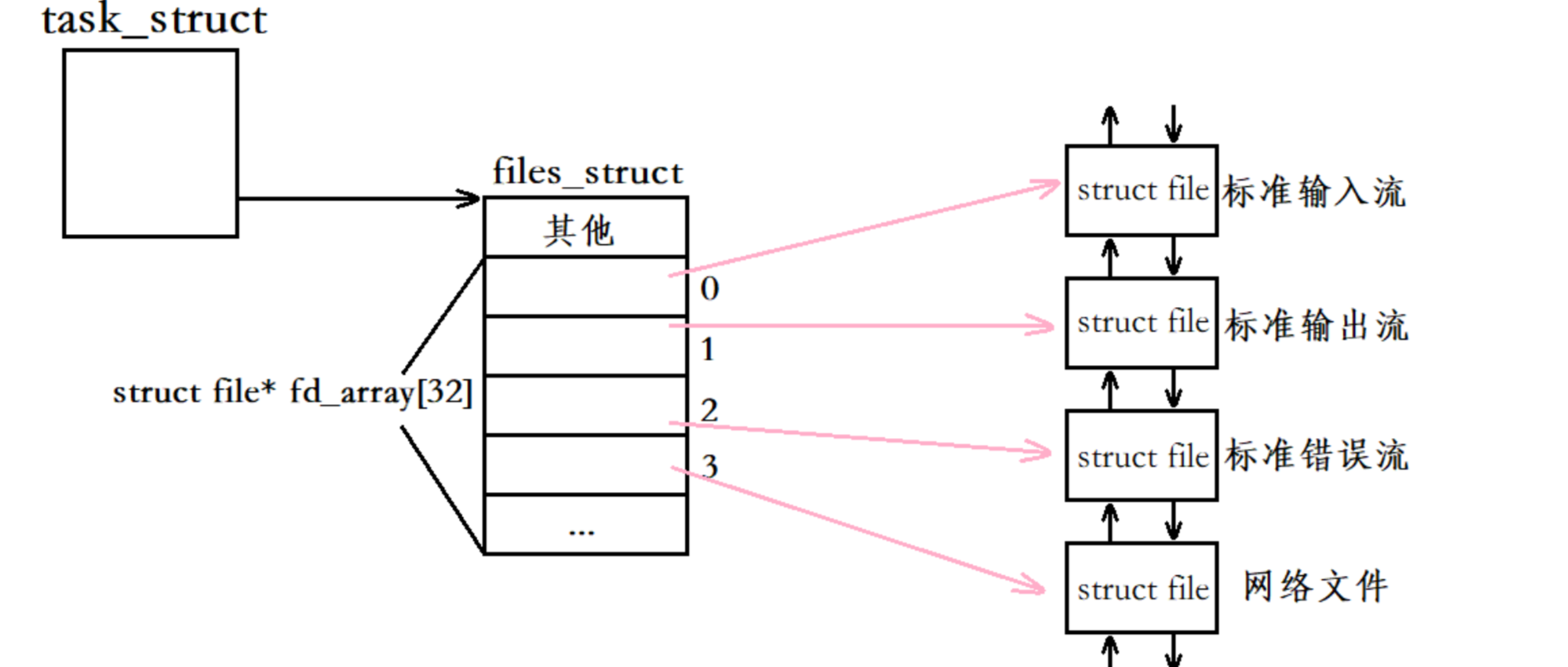
當我們調用socket函數創建套接字時,實際相當于我們打開了一個“網絡文件”,打開后在內核層面上就形成了一個對應的struct file結構體,同時該結構體被連入到了該進程對應的文件雙鏈表,并將該結構體的首地址填入到了fd_array數組當中下標為3的位置,此時fd_array數組中下標為3的指針就指向了這個打開的“網絡文件”,最后3號文件描述符作為socket函數的返回值返回給了用戶。
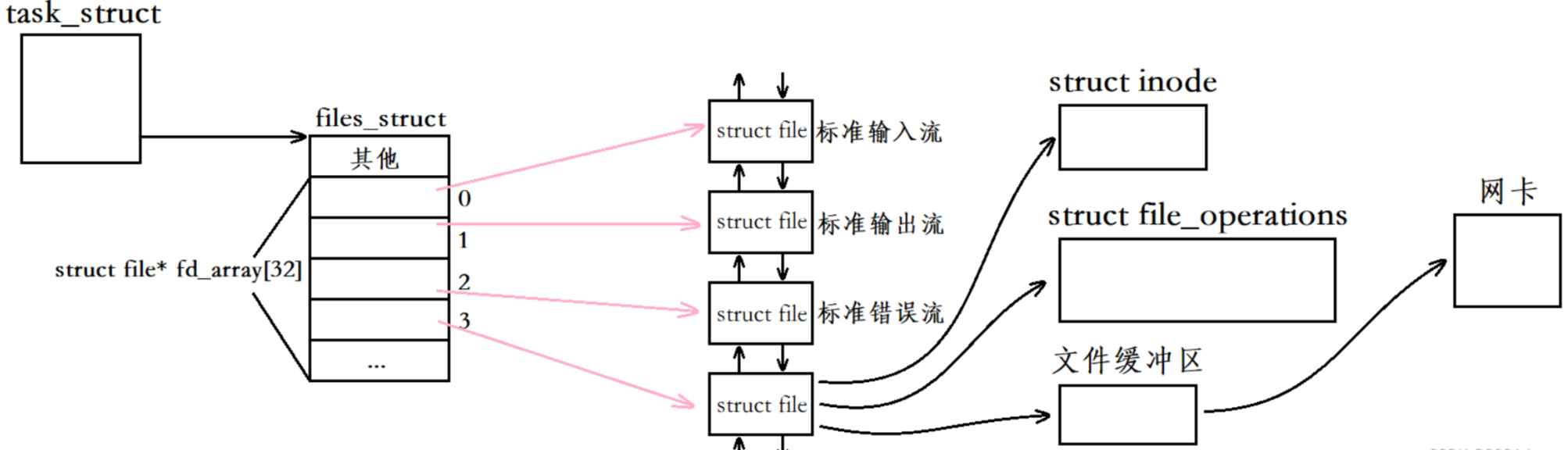
對于一般的普通文件來說,當用戶通過文件描述符將數據寫到文件緩沖區,然后再把數據刷到磁盤上就完成了數據的寫入操作。而對于現在socket函數打開的“網絡文件”來說,當用戶將數據寫到文件緩沖區后,操作系統會定期將數據刷到網卡里面,而網卡則是負責數據發送的,因此數據最終就發送到了網絡當中。
服務端綁定
現在套接字已經創建成功了,但作為一款服務器來講,如果只是把套接字創建好了,那我們也只是在系統層面上打開了一個文件,操作系統將來并不知道是要將數據寫入到磁盤還是刷到網卡,此時該文件還沒有與網絡關聯起來。
bind函數
綁定的函數叫做bind,該函數的函數原型如下:
int bind(int sockfd, const struct sockaddr *addr, socklen_t addrlen);
struct sockaddr_in結構體
在綁定時需要將網絡相關的屬性信息填充到一個結構體當中,然后將該結構體作為bind函數的第二個參數進行傳入,這實際就是struct sockaddr_in結構體。
可以看到,struct sockaddr_in當中的成員如下:
- sin_family:表示協議家族。
- sin_port:表示端口號,是一個16位的整數。
- sin_addr:表示IP地址,是一個32位的整數。
class UdpServer
{
public:UdpServer(std::string ip, int port):_sockfd(-1),_port(port),_ip(ip){};bool InitServer(){//創建套接字_sockfd = socket(AF_INET, SOCK_DGRAM, 0);if (_sockfd < 0){ //創建套接字失敗std::cerr << "socket error" << std::endl;return false;}std::cout << "socket create success, sockfd: " << _sockfd << std::endl;//填充網絡通信相關信息struct sockaddr_in local;memset(&local, '\0', sizeof(local));local.sin_family = AF_INET;local.sin_port = htons(_port);local.sin_addr.s_addr = inet_addr(_ip.c_str()); //綁定if (bind(_sockfd, (struct sockaddr*)&local, sizeof(sockaddr)) < 0){ //綁定失敗std::cerr << "bind error" << std::endl;return false;}std::cout << "bind success" << std::endl;return true;}~UdpServer(){if (_sockfd >= 0){close(_sockfd);}};
private:int _sockfd; //文件描述符int _port; //端口號std::string _ip; //IP地址
};
整數IP存在的意義
網絡傳輸數據時是寸土寸金的,如果我們在網絡傳輸時直接以基于字符串的點分十進制IP的形式進行IP地址的傳送,那么此時一個IP地址至少就需要15個字節,但實際并不需要耗費這么多字節。
IP地址實際可以劃分為四個區域,其中每一個區域的取值都是0~255,而這個范圍的數字只需要用8個比特位就能表示,因此我們實際只需要32個比特位就能夠表示一個IP地址。
字符串IP和整數IP相互轉換的方式
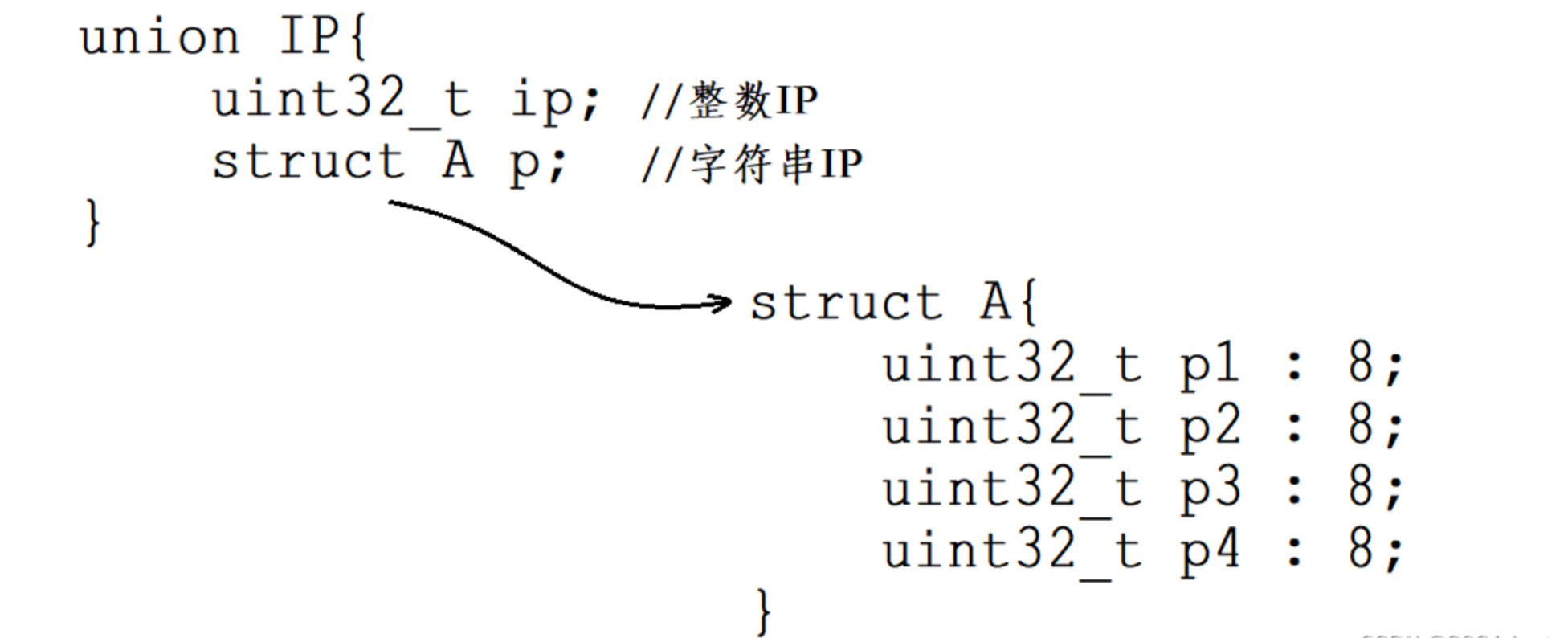
inet_addr函數
實際在進行字符串IP和整數IP的轉換時,我們不需要自己編寫轉換邏輯,系統已經為我們提供了相應的轉換函數,我們直接調用即可。
將字符串IP轉換成整數IP的函數叫做inet_addr,該函數的函數原型如下:
in_addr_t inet_addr(const char *cp);inet_ntoa函數
將整數IP轉換成字符串IP的函數叫做inet_ntoa,該函數的函數原型如下:
char *inet_ntoa(struct in_addr in);運行服務器
UDP服務器的初始化就只需要創建套接字和綁定就行了,當服務器初始化完畢后我們就可以啟動服務器了。
服務器實際上就是在周而復始的為我們提供某種服務,服務器之所以稱為服務器,是因為服務器運行起來后就永遠不會退出,因此服務器實際執行的是一個死循環代碼。由于UDP服務器是不面向連接的,因此只要UDP服務器啟動后,就可以直接讀取客戶端發來的數據。
recvfrom函數
UDP服務器讀取數據的函數叫做recvfrom,該函數的函數原型如下:
ssize_t recvfrom(int sockfd, void *buf, size_t len, int flags, struct sockaddr *src_addr, socklen_t *addrlen)啟動服務器函數
現在服務端通過recvfrom函數讀取客戶端數據,我們可以先將讀取到的數據當作字符串看待,將讀取到的數據的最后一個位置設置為'\0',此時我們就可以將讀取到的數據進行輸出,同時我們也可以將獲取到的客戶端的IP地址和端口號也一并進行輸出。
void Start(){
#define SIZE 128char buffer[SIZE];for (;;){struct sockaddr_in peer;socklen_t len = sizeof(peer);ssize_t size = recvfrom(_sockfd, buffer, sizeof(buffer)-1, 0, (struct sockaddr*)&peer, &len);if (size > 0){buffer[size] = '\0';int port = ntohs(peer.sin_port);std::string ip = inet_ntoa(peer.sin_addr);std::cout << ip << ":" << port << "# " << buffer << std::endl;}else{std::cerr << "recvfrom error" << std::endl;}}}
sendto函數
UDP客戶端發送數據的函數叫做sendto,該函數的函數原型如下:
ssize_t sendto(int sockfd, const void *buf, size_t len, int flags, const struct sockaddr *dest_addr, socklen)簡單的TCP網絡程序
服務端監聽
UDP服務器的初始化操作只有兩步,第一步就是創建套接字,第二步就是綁定。而TCP服務器是面向連接的,客戶端在正式向TCP服務器發送數據之前,需要先與TCP服務器建立連接,然后才能與服務器進行通信。
因此TCP服務器需要時刻注意是否有客戶端發來連接請求,此時就需要將TCP服務器創建的套接字設置為監聽狀態。
listen函數
設置套接字為監聽狀態的函數叫做listen,該函數的函數原型如下:
int listen(int sockfd, int backlog);參數說明:
- sockfd:需要設置為監聽狀態的套接字對應的文件描述符。
- backlog:全連接隊列的最大長度。如果有多個客戶端同時發來連接請求,此時未被服務器處理的連接就會放入連接隊列,該參數代表的就是這個全連接隊列的最大長度,一般不要設置太大,設置為5或10即可。
服務端獲取連接
TCP服務器初始化后就可以開始運行了,但TCP服務器在與客戶端進行網絡通信之前,服務器需要先獲取到客戶端的連接請求。
accept函數
獲取連接的函數叫做accept,該函數的函數原型如下:
int accept(int sockfd, struct sockaddr *addr, socklen_t *addrlen);
accept函數返回的套接字是什么?
調用accept函數獲取連接時,是從監聽套接字當中獲取的。如果accept函數獲取連接成功,此時會返回接收到的套接字對應的文件描述符。
監聽套接字與accept函數返回的套接字的作用:
- 監聽套接字:用于獲取客戶端發來的連接請求。accept函數會不斷從監聽套接字當中獲取新連接。
- accept函數返回的套接字:用于為本次accept獲取到的連接提供服務。監聽套接字的任務只是不斷獲取新連接,而真正為這些連接提供服務的套接字是accept函數返回的套接字,而不是監聽套接字。
class TcpServer
{
public:void Start(){for (;;){//獲取連接struct sockaddr_in peer;memset(&peer, '\0', sizeof(peer));socklen_t len = sizeof(peer);int sock = accept(_listen_sock, (struct sockaddr*)&peer, &len);if (sock < 0){std::cerr << "accept error, continue next" << std::endl;continue;}std::string client_ip = inet_ntoa(peer.sin_addr);int client_port = ntohs(peer.sin_port);std::cout<<"get a new link->"<<sock<<" ["<<client_ip<<"]:"<<client_port<<std::endl;}}
private:int _listen_sock; //監聽套接字int _port; //端口號
};
客戶端連接服務器
由于客戶端不需要綁定,也不需要監聽,因此當客戶端創建完套接字后就可以向服務端發起連接請求。
connect函數
發起連接請求的函數叫做connect,該函數的函數原型如下:
int connect(int sockfd, const struct sockaddr *addr, socklen_t addrlen);
單執行流服務器的弊端
單執行流的服務器
通過實驗現象可以看到,這服務端只有服務完一個客戶端后才會服務另一個客戶端。因為我們目前所寫的是一個單執行流版的服務器,這個服務器一次只能為一個客戶端提供服務。
當服務端調用accept函數獲取到連接后就給該客戶端提供服務,但在服務端提供服務期間可能會有其他客戶端發起連接請求,但由于當前服務器是單執行流的,只能服務完當前客戶端后才能繼續服務下一個客戶端。
客戶端為什么會顯示連接成功?
當服務端在給第一個客戶端提供服務期間,第二個客戶端向服務端發起的連接請求時是成功的,只不過服務端沒有調用accept函數將該連接獲取上來罷了。
實際在底層會為我們維護一個連接隊列,服務端沒有accept的新連接就會放到這個連接隊列當中,而這個連接隊列的最大長度就是通過listen函數的第二個參數來指定的,因此服務端雖然沒有獲取第二個客戶端發來的連接請求,但是在第二個客戶端那里顯示是連接成功的。
多進程版的TCP網絡程序
我們可以將當前的單執行流服務器改為多進程版的服務器。
當服務端調用accept函數獲取到新連接后不是由當前執行流為該連接提供服務,而是當前執行流調用fork函數創建子進程,然后讓子進程為父進程獲取到的連接提供服務。
捕捉SIGCHLD信號
實際當子進程退出時會給父進程發送SIGCHLD信號,如果父進程將SIGCHLD信號進行捕捉,并將該信號的處理動作設置為忽略,此時父進程就只需專心處理自己的工作,不必關心子進程了。
該方式實現起來非常簡單,也是比較推薦的一種做法。
class TcpServer
{
public:void Start(){signal(SIGCHLD, SIG_IGN); //忽略SIGCHLD信號for (;;){//獲取連接struct sockaddr_in peer;memset(&peer, '\0', sizeof(peer));socklen_t len = sizeof(peer);int sock = accept(_listen_sock, (struct sockaddr*)&peer, &len);if (sock < 0){std::cerr << "accept error, continue next" << std::endl;continue;}std::string client_ip = inet_ntoa(peer.sin_addr);int client_port = ntohs(peer.sin_port);std::cout << "get a new link->" << sock << " [" << client_ip << "]:" << client_port << std::endl;pid_t id = fork();if (id == 0){ //child//處理請求Service(sock, client_ip, client_port);exit(0); //子進程提供完服務退出}}}
private:int _listen_sock; //監聽套接字int _port; //端口號
};
讓孫子進程提供服務
我們也可以讓服務端創建出來的子進程再次進行fork,讓孫子進程為客戶端提供服務, 此時我們就不用等待孫子進程退出了。
class TcpServer
{
public:void Start(){for (;;){//獲取連接struct sockaddr_in peer;memset(&peer, '\0', sizeof(peer));socklen_t len = sizeof(peer);int sock = accept(_listen_sock, (struct sockaddr*)&peer, &len);if (sock < 0){std::cerr << "accept error, continue next" << std::endl;continue;}std::string client_ip = inet_ntoa(peer.sin_addr);int client_port = ntohs(peer.sin_port);std::cout << "get a new link->" << sock << " [" << client_ip << "]:" << client_port << std::endl;pid_t id = fork();if (id == 0){ //childclose(_listen_sock); //child關閉監聽套接字if (fork() > 0){exit(0); //爸爸進程直接退出}//處理請求Service(sock, client_ip, client_port); //孫子進程提供服務exit(0); //孫子進程提供完服務退出}close(sock); //father關閉為連接提供服務的套接字waitpid(id, nullptr, 0); //等待爸爸進程(會立刻等待成功)}}
private:int _listen_sock; //監聽套接字int _port; //端口號
};
多線程版的TCP網絡程序
創建進程的成本是很高的,創建進程時需要創建該進程對應的進程控制塊(task_struct)、進程地址空間(mm_struct)、頁表等數據結構。而創建線程的成本比創建進程的成本會小得多,因為線程本質是在進程地址空間內運行,創建出來的線程會共享該進程的大部分資源,因此在實現多執行流的服務器時最好采用多線程進行實現。
class TcpServer
{
public:static void* HandlerRequest(void* arg){pthread_detach(pthread_self()); //分離線程//int sock = *(int*)arg;Param* p = (Param*)arg;Service(p->_sock, p->_ip, p->_port); //線程為客戶端提供服務delete p; //釋放參數占用的堆空間return nullptr;}void Start(){for (;;){//獲取連接struct sockaddr_in peer;memset(&peer, '\0', sizeof(peer));socklen_t len = sizeof(peer);int sock = accept(_listen_sock, (struct sockaddr*)&peer, &len);if (sock < 0){std::cerr << "accept error, continue next" << std::endl;continue;}std::string client_ip = inet_ntoa(peer.sin_addr);int client_port = ntohs(peer.sin_port);std::cout << "get a new link->" << sock << " [" << client_ip << "]:" << client_port << std::endl;Param* p = new Param(sock, client_ip, client_port);pthread_t tid;pthread_create(&tid, nullptr, HandlerRequest, p);}}
private:int _listen_sock; //監聽套接字int _port; //端口號
};
線程池版的TCP網絡程序
引入線程池
實際要解決這里的問題我們就需要在服務端引入線程池,因為線程池的存在就是為了避免處理短時間任務時創建與銷毀線程的代價,此外,線程池還能夠保證內核充分利用,防止過分調度。
其中在線程池里面有一個任務隊列,當有新的任務到來的時候,就可以將任務Push到線程池當中,在線程池當中我們默認創建了5個線程,這些線程不斷檢測任務隊列當中是否有任務,如果有任務就拿出任務,然后調用該任務對應的Run函數對該任務進行處理,如果線程池當中沒有任務那么當前線程就會進入休眠狀態。 tcp網絡服務器中就包含線程池,監聽文件描述符和端口號。
class TcpServer
{
public:TcpServer(int port): _listen_sock(-1), _port(port), _tp(nullptr){}void InitServer(){//創建套接字_listen_sock = socket(AF_INET, SOCK_STREAM, 0);if (_listen_sock < 0){std::cerr << "socket error" << std::endl;exit(2);}//綁定struct sockaddr_in local;memset(&local, '\0', sizeof(local));local.sin_family = AF_INET;local.sin_port = htons(_port);local.sin_addr.s_addr = INADDR_ANY;if (bind(_listen_sock, (struct sockaddr*)&local, sizeof(local)) < 0){std::cerr << "bind error" << std::endl;exit(3);}//監聽if (listen(_listen_sock, BACKLOG) < 0){std::cerr << "listen error" << std::endl;exit(4);}_tp = new ThreadPool<Task>(); //構造線程池對象}void Start(){_tp->ThreadPoolInit(); //初始化線程池for (;;){//獲取連接struct sockaddr_in peer;memset(&peer, '\0', sizeof(peer));socklen_t len = sizeof(peer);int sock = accept(_listen_sock, (struct sockaddr*)&peer, &len);if (sock < 0){std::cerr << "accept error, continue next" << std::endl;continue;}std::string client_ip = inet_ntoa(peer.sin_addr);int client_port = ntohs(peer.sin_port);std::cout << "get a new link->" << sock << " [" << client_ip << "]:" << client_port << std::endl;Task task(sock, client_ip, client_port); //構造任務_tp->Push(task); //將任務Push進任務隊列}}
private:int _listen_sock; //監聽套接字int _port; //端口號ThreadPool<Task>* _tp; //線程池
};
TCP協議通訊流程
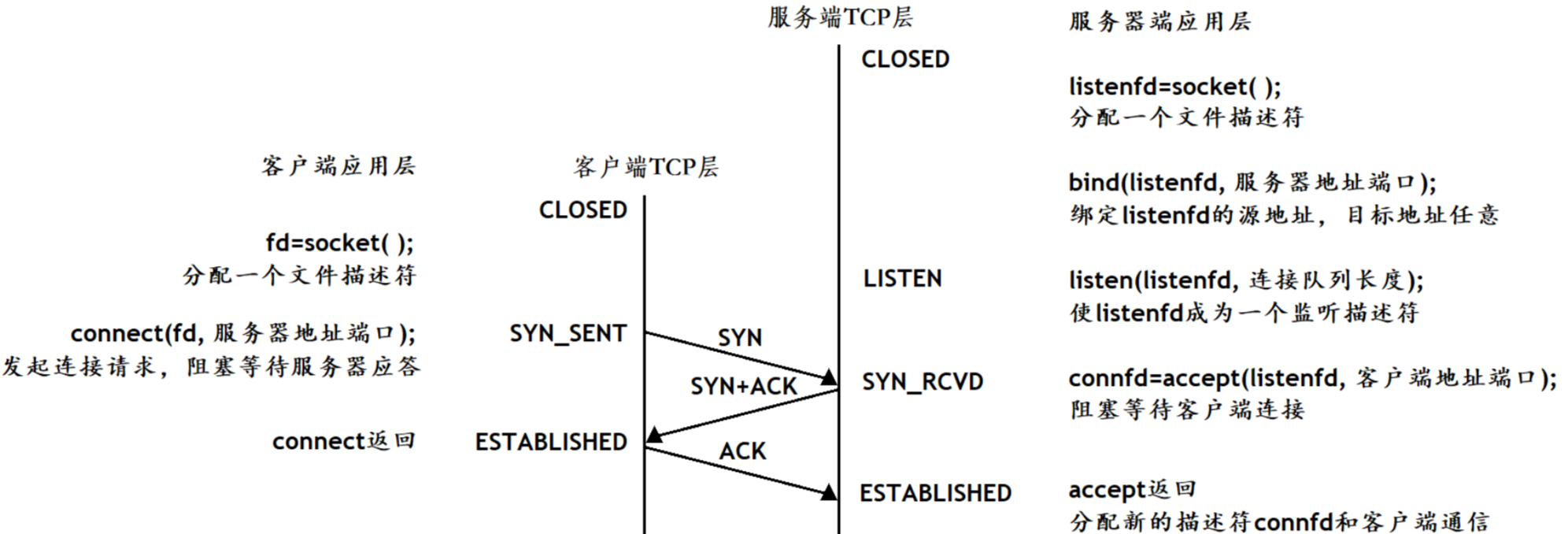
三次握手的過程
四次揮手的過程
HTTP協議
HTTP(Hyper Text Transfer Protocol)協議又叫做超文本傳輸協議,是一個簡單的請求-響應協議,HTTP通常運行在TCP之上。
認識URL
URL(Uniform Resource Lacator)叫做統一資源定位符,也就是我們通常所說的網址,是因特網的萬維網服務程序上用于指定信息位置的表示方法。
一個URL大致由如下幾部分構成:

三、服務器地址
www.example.jp表示的是服務器地址,也叫做域名,比如www.alibaba.com,www.qq.com,www.baidu.com。
需要注意的是,我們用IP地址標識公網內的一臺主機,但IP地址本身并不適合給用戶看。
四、服務器端口號
80表示的是服務器端口號。HTTP協議和套接字編程一樣都是位于應用層的,在進行套接字編程時我們需要給服務器綁定對應的IP和端口,而這里的應用層協議也同樣需要有明確的端口號。
常見協議對應的端口號:
| 協議名稱 | 對應端口號 |
|---|---|
| HTTP | 80 |
| HTTPS | 443 |
| SSH | 22 |
當我們使用某種協議時,該協議實際就是在為我們提供服務,現在這些常用的服務與端口號之間的對應關系都是明確的,所以我們在使用某種協議時實際是不需要指明該協議對應的端口號的,因此在URL當中,服務器的端口號一般也是被省略的。
五、帶層次的文件路徑
/dir/index.htm表示的是要訪問的資源所在的路徑。訪問服務器的目的是獲取服務器上的某種資源,通過前面的域名和端口已經能夠找到對應的服務器進程了,此時要做的就是指明該資源所在的路徑。
HTTP協議格式
HTTP是基于請求和響應的應用層服務,作為客戶端,你可以向服務器發起request,服務器收到這個request后,會對這個request做數據分析,得出你想要訪問什么資源,然后服務器再構建response,完成這一次HTTP的請求。這種基于request&response這樣的工作方式,我們稱之為cs或bs模式,其中c表示client,s表示server,b表示browser。
HTTP請求協議格式
HTTP請求協議格式如下:
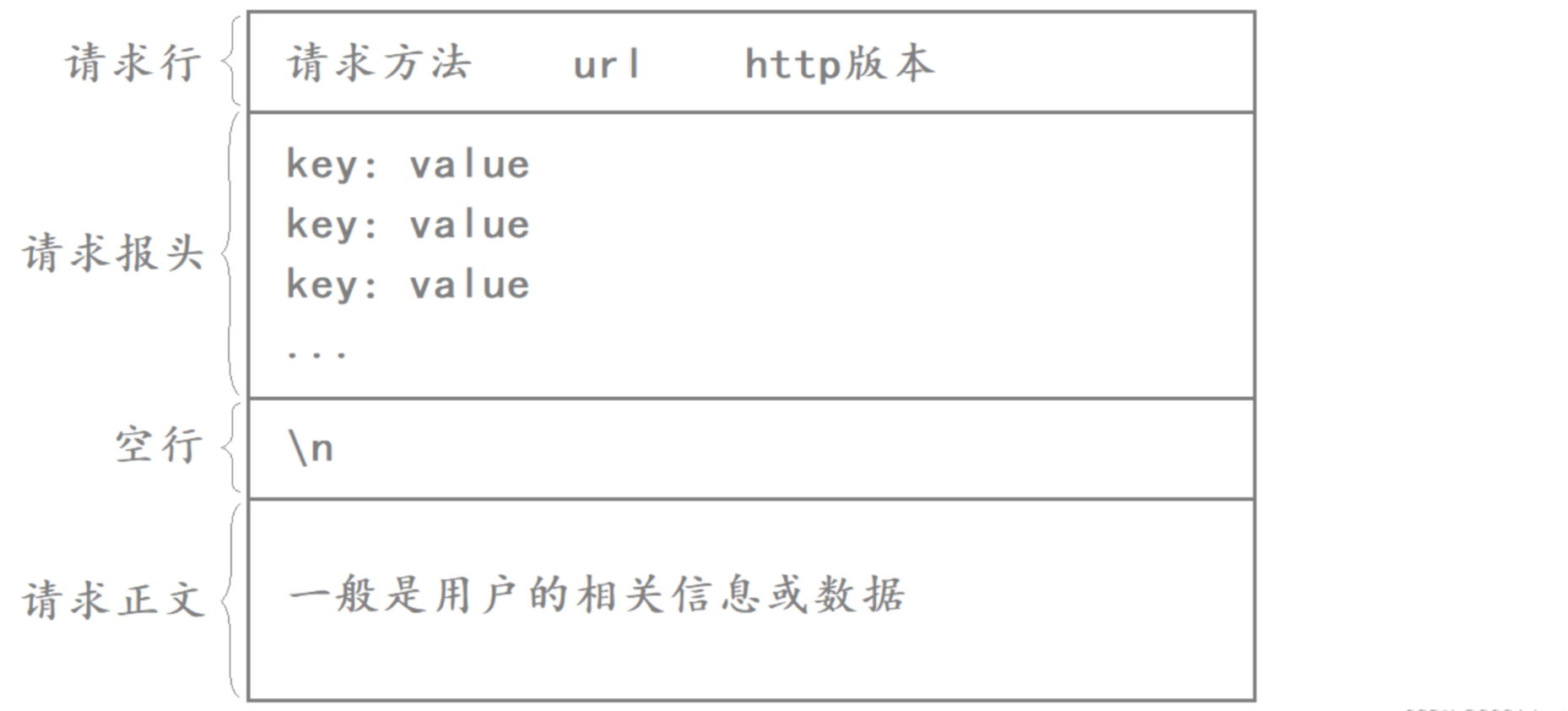
HTTP請求由以下四部分組成:
- 請求行:[請求方法]+[url]+[http版本]
- 請求報頭:請求的屬性,這些屬性都是以
key: value的形式按行陳列的。 - 空行:遇到空行表示請求報頭結束。
- 請求正文:請求正文允許為空字符串,如果請求正文存在,則在請求報頭中會有一個Content-Length屬性來標識請求正文的長度。
其中,前面三部分是一般是HTTP協議自帶的,是由HTTP協議自行設置的,而請求正文一般是用戶的相關信息或數據,如果用戶在請求時沒有信息要上傳給服務器,此時請求正文就為空字符串。
HTTP響應協議格式
HTTP響應協議格式如下:
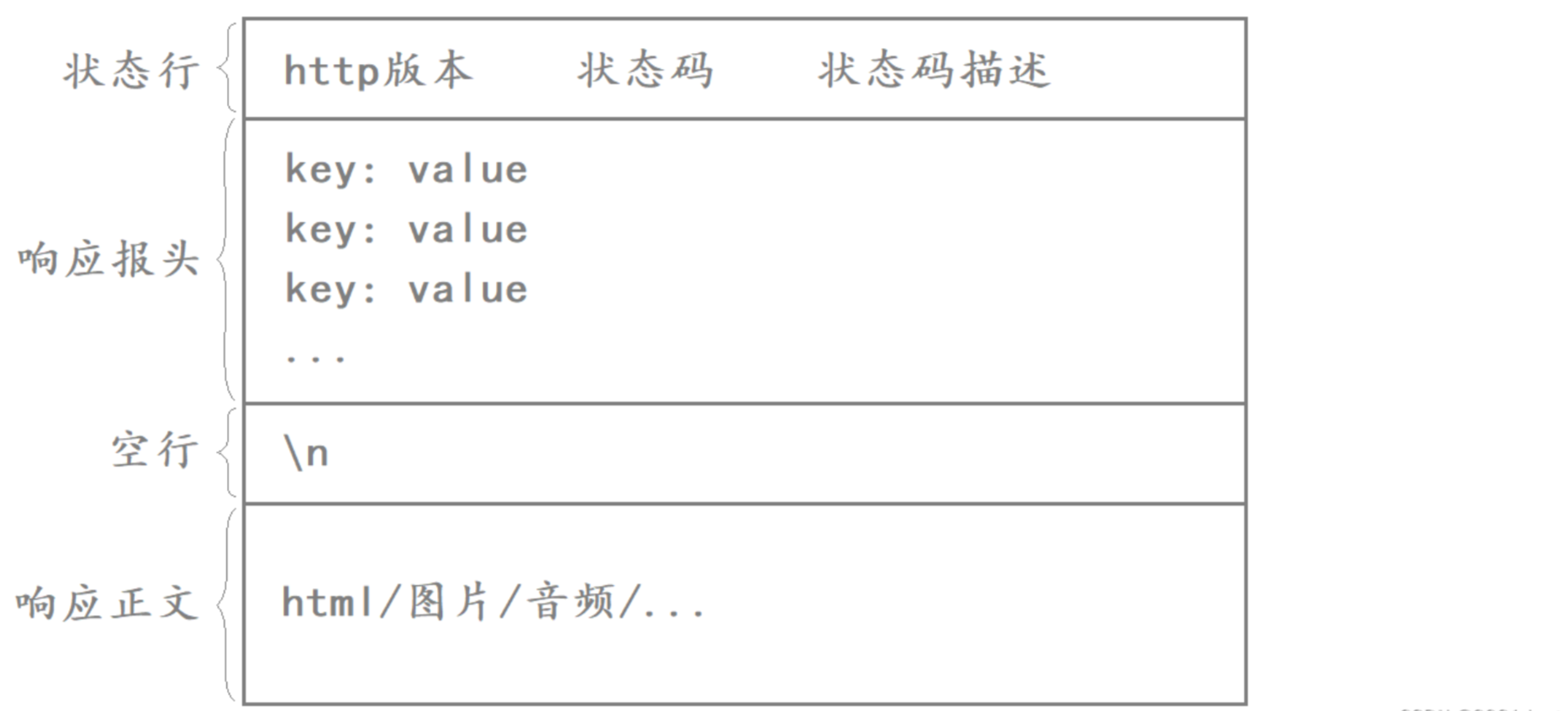
當瀏覽器向服務器發起HTTP請求時,不管瀏覽器發來的是什么請求,我們都將這個網頁響應給瀏覽器,此時這個html文件的內容就應該放在響應正文當中,我們只需讀取該文件當中的內容,然后將其作為響應正文即可。
#include <iostream>
#include <fstream>
#include <string>
#include <cstring>
#include <unistd.h>
#include <sys/wait.h>
#include <sys/socket.h>
#include <sys/types.h>
#include <netinet/in.h>
#include <arpa/inet.h>
using namespace std;int main()
{//創建套接字int listen_sock = socket(AF_INET, SOCK_STREAM, 0);if (listen_sock < 0){cerr << "socket error!" << endl;return 1;}//綁定struct sockaddr_in local;memset(&local, 0, sizeof(local));local.sin_family = AF_INET;local.sin_port = htons(8081);local.sin_addr.s_addr = htonl(INADDR_ANY);if (bind(listen_sock, (struct sockaddr*)&local, sizeof(local)) < 0){cerr << "bind error!" << endl;return 2;}//監聽if (listen(listen_sock, 5) < 0){cerr << "listen error!" << endl;return 3;}//啟動服務器struct sockaddr peer;memset(&peer, 0, sizeof(peer));socklen_t len = sizeof(peer);for (;;){int sock = accept(listen_sock, (struct sockaddr*)&peer, &len);if (sock < 0){cerr << "accept error!" << endl;continue;}if (fork() == 0){ //爸爸進程close(listen_sock);if (fork() > 0){ //爸爸進程exit(0);}//孫子進程char buffer[1024];recv(sock, buffer, sizeof(buffer), 0); //讀取HTTP請求cout << "--------------------------http request begin--------------------------" << endl;cout << buffer << endl;cout << "---------------------------http request end---------------------------" << endl;#define PAGE "index.html" //網站首頁//讀取index.html文件ifstream in(PAGE);if (in.is_open()){in.seekg(0, in.end);int len = in.tellg();in.seekg(0, in.beg);char* file = new char[len];in.read(file, len);in.close();//構建HTTP響應string status_line = "http/1.1 200 OK\n"; //狀態行string response_header = "Content-Length: " + to_string(len) + "\n"; //響應報頭string blank = "\n"; //空行string response_text = file; //響應正文string response = status_line + response_header + blank + response_text; //響應報文//響應HTTP請求send(sock, response.c_str(), response.size(), 0);delete[] file;}close(sock);exit(0);}//爺爺進程close(sock);waitpid(-1, nullptr, 0); //等待爸爸進程}return 0;
}
說明一下:
- 實際我們在進行網絡請求的時候,如果不指明請求資源的路徑,此時默認你想訪問的就是目標網站的首頁,也就是web根目錄下的index.html文件。
- 由于只是作為示例,我們在構建HTTP響應時,在響應報頭當中只添加了一個屬性信息Content-Length,表示響應正文的長度,實際HTTP響應報頭當中的屬性信息還有很多。
HTTP的方法
HTTP常見的方法如下:
| 方法 | 說明 | 支持的HTTP協議版本 |
|---|---|---|
| GET | 獲取資源 | 1.0、1.1 |
| POST | 傳輸實體主體 | 1.0、1.1 |
| PUT | 傳輸文件 | 1.0、1.1 |
| HEAD | 獲得報文首部 | 1.0、1.1 |
其中最常用的就是GET方法和POST方法。
GET方法和POST方法
GET方法一般用于獲取某種資源信息,而POST方法一般用于將數據上傳給服務器。但實際我們上傳數據時也有可能使用GET方法,比如百度提交數據時實際使用的就是GET方法。
GET方法和POST方法都可以帶參:
- GET方法是通過url傳參的。
- POST方法是通過正文傳參的。
HTTP的狀態碼
HTTP的狀態碼如下:
| 類別 | 原因短語 | |
|---|---|---|
| 1XX | Informational(信息性狀態碼) | 接收的請求正在處理 |
| 2XX | Success(成功狀態碼) | 請求正常處理完畢 |
| 3XX | Redirection(重定向狀態碼) | 需要進行附加操作以完成請求 |
| 4XX | Client Error(客戶端錯誤狀態碼) | 服務器無法處理請求 |
| 5XX | Server Error(服務器錯誤狀態碼) | 服務器處理請求出錯 |
最常見的狀態碼,比如200(OK),404(Not Found),403(Forbidden請求權限不夠),302(Redirect),504(Bad Gateway)。
Redirection(重定向狀態碼)
重定向就是通過各種方法將各種網絡請求重新定個方向轉到其它位置,此時這個服務器相當于提供了一個引路的服務。
重定向又可分為臨時重定向和永久重定向,其中狀態碼301表示的就是永久重定向,而狀態碼302和307表示的是臨時重定向。
//構建HTTP響應string status_line = "http/1.1 307 Temporary Redirect\n"; //狀態行string response_header = "Location: https://www.csdn.net/\n"; //響應報頭string blank = "\n"; //空行string response = status_line + response_header + blank; //響應報文
HTTP常見的Header
HTTP常見的Header如下:
- Content-Type:數據類型(text/html等)。
- Content-Length:正文的長度。
- Host:客戶端告知服務器,所請求的資源是在哪個主機的哪個端口上。
- User-Agent:聲明用戶的操作系統和瀏覽器的版本信息。
- Referer:當前頁面是哪個頁面跳轉過來的。
- Location:搭配3XX狀態碼使用,告訴客戶端接下來要去哪里訪問。
- Cookie:用于在客戶端存儲少量信息,通常用于實現會話(session)的功能。
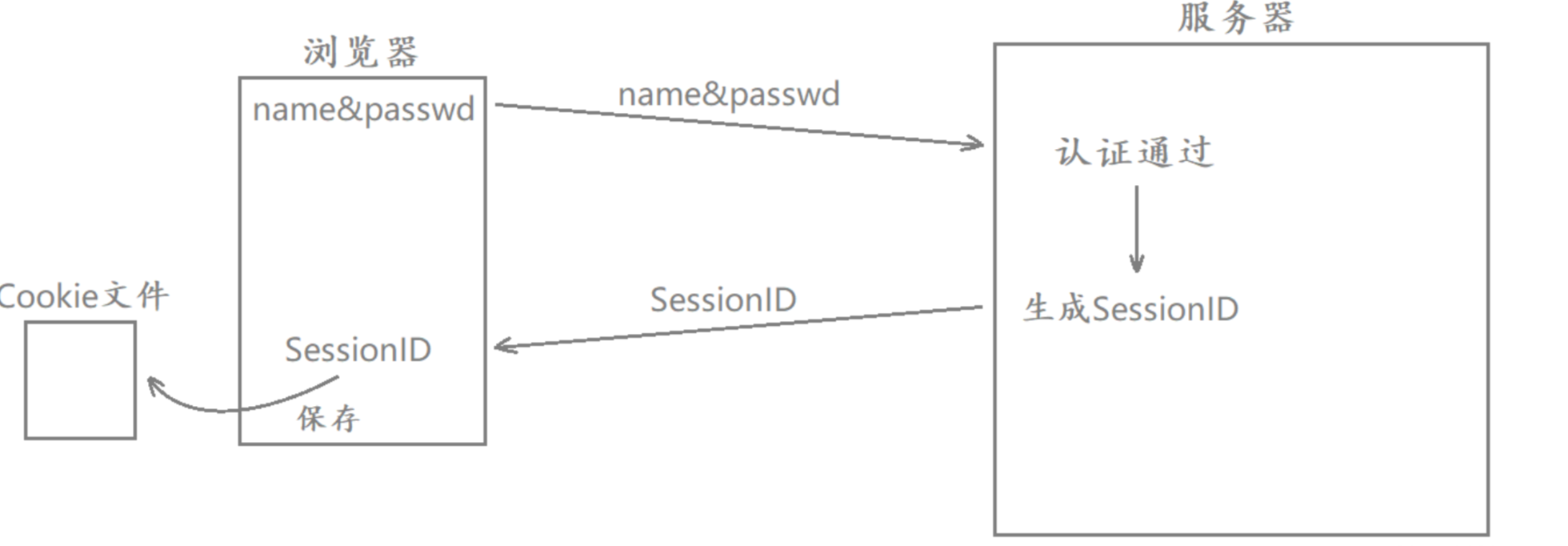
Cookie和Session
HTTP實際上是一種無狀態協議,HTTP的每次請求/響應之間是沒有任何關系的,但你在使用瀏覽器的時候發現并不是這樣的。
cookie是什么呢?而瀏覽器收到響應后會自動提取出Set-Cookie的值,將其保存在瀏覽器的cookie文件當中,此時就相當于我的賬號和密碼信息保存在本地瀏覽器的cookie文件當中。
因為HTTP是一種無狀態協議,如果沒有cookie的存在,那么每當我們要進行頁面請求時都需要重新輸入賬號和密碼進行認證,這樣太麻煩了。
當認證通過并在服務端進行Set-Cookie設置后,服務器在對瀏覽器進行HTTP響應時就會將這個Set-Cookie響應給瀏覽器.而瀏覽器收到響應后會自動提取出Set-Cookie的值,將其保存在瀏覽器的cookie文件當中,此時就相當于我的賬號和密碼信息保存在本地瀏覽器的cookie文件當中。
現在主流做法是把sessionId保存在Cookie文件中。
HTTPS VS HTTP
早期很多公司剛起步的時候,使用的應用層協議都是HTTP,而HTTP無論是用GET方法還是POST方法傳參,都是沒有經過任何加密的,因此早期很多的信息都是可以通過抓包工具抓到的。

UDP協議
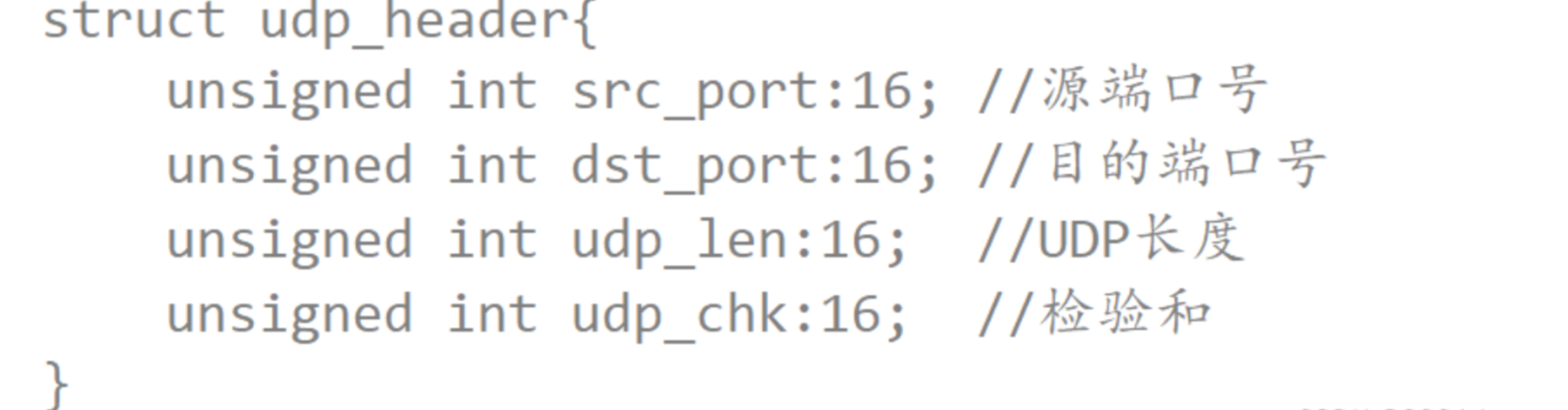
面向數據報
應用層交給UDP多長的報文,UDP就原樣發送,既不會拆分,也不會合并,這就叫做面向數據報。
比如用UDP傳輸100個字節的數據:
- 如果發送端調用一次sendto,發送100字節,那么接收端也必須調用對應的一次recvfrom,接收100個字節;而不能循環調用10次recvfrom,每次接收10個字節。
UDP的緩沖區
- UDP沒有真正意義上的發送緩沖區,其內核"發送緩沖區" 僅暫存待發送的單個數據報。我們調用sendto會直接交給內核,由內核將數據傳給網絡層協議進行后續的傳輸動作。
- UDP具有接收緩沖區。但是這個接收緩沖區不能保證收到的UDP報的順序和發送UDP報的順序一致;如果緩沖區滿了,再到達的UDP數據就會被丟棄。
- UDP的socket既能讀,也能寫,因此UDP是全雙工的。
當應用程序調用?sendto()?或?sendmsg()?時,內核會立即嘗試將整個UDP數據報發送出去。
DP協議報頭當中的UDP最大長度是16位的,因此一個UDP報文的最大長度是64K(包含UDP報頭的大小)。
然而64K在當今的互聯網環境下,是一個非常小的數字。如果需要傳輸的數據超過64K,就需要在應用層 sendto()?之前進行手動分包,多次發送,并在接收端進行手動拼裝。
TCP協議
協議格式
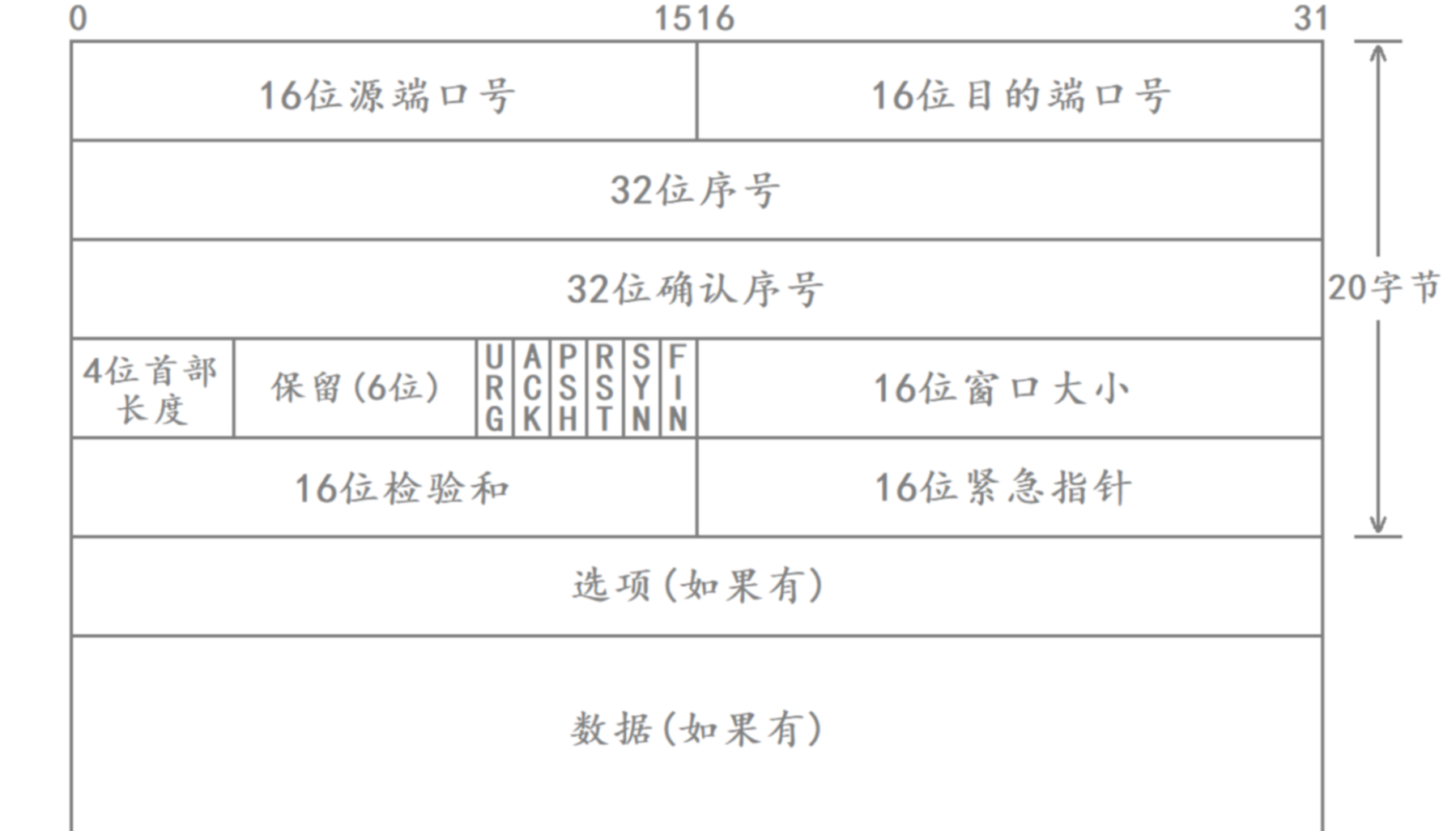
TCP報頭當中各個字段的含義如下:
- 源/目的端口號:表示數據是從哪個進程來,到發送到對端主機上的哪個進程。
- 32位序號/32位確認序號:分別代表TCP報文當中每個字節數據的編號以及對對方的確認,是TCP保證可靠性的重要字段。
- 4位TCP報頭長度:表示該TCP報頭的長度,以4字節為單位。
- 6位保留字段:TCP報頭中暫時未使用的6個比特位。
- 16位窗口大小:保證TCP可靠性機制和效率提升機制的重要字段。
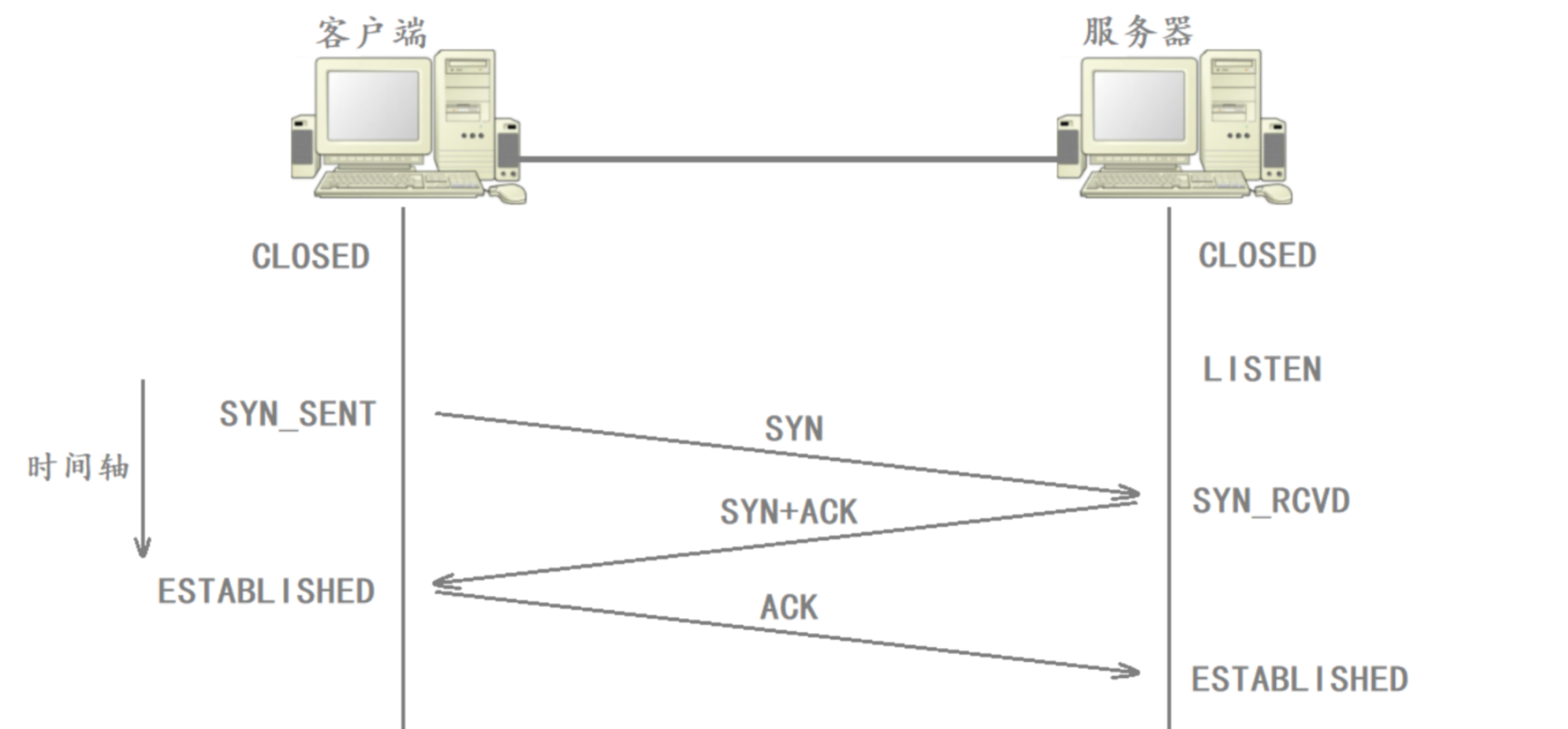
三次握手時的狀態變化
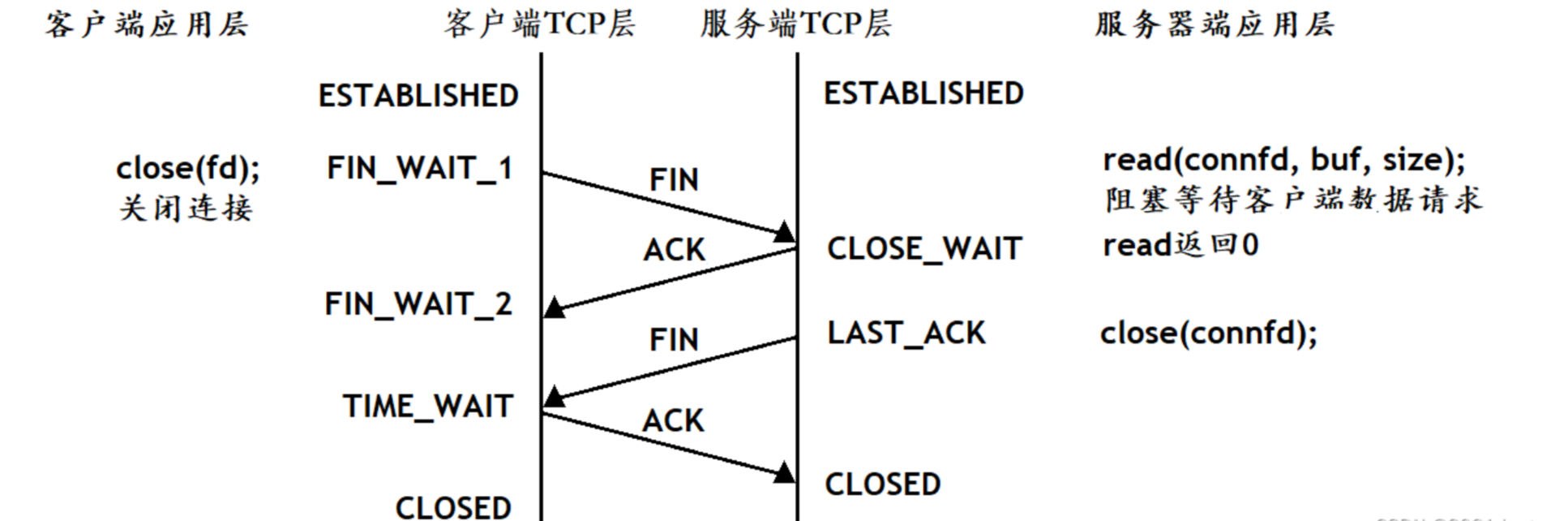
四次揮手的過程
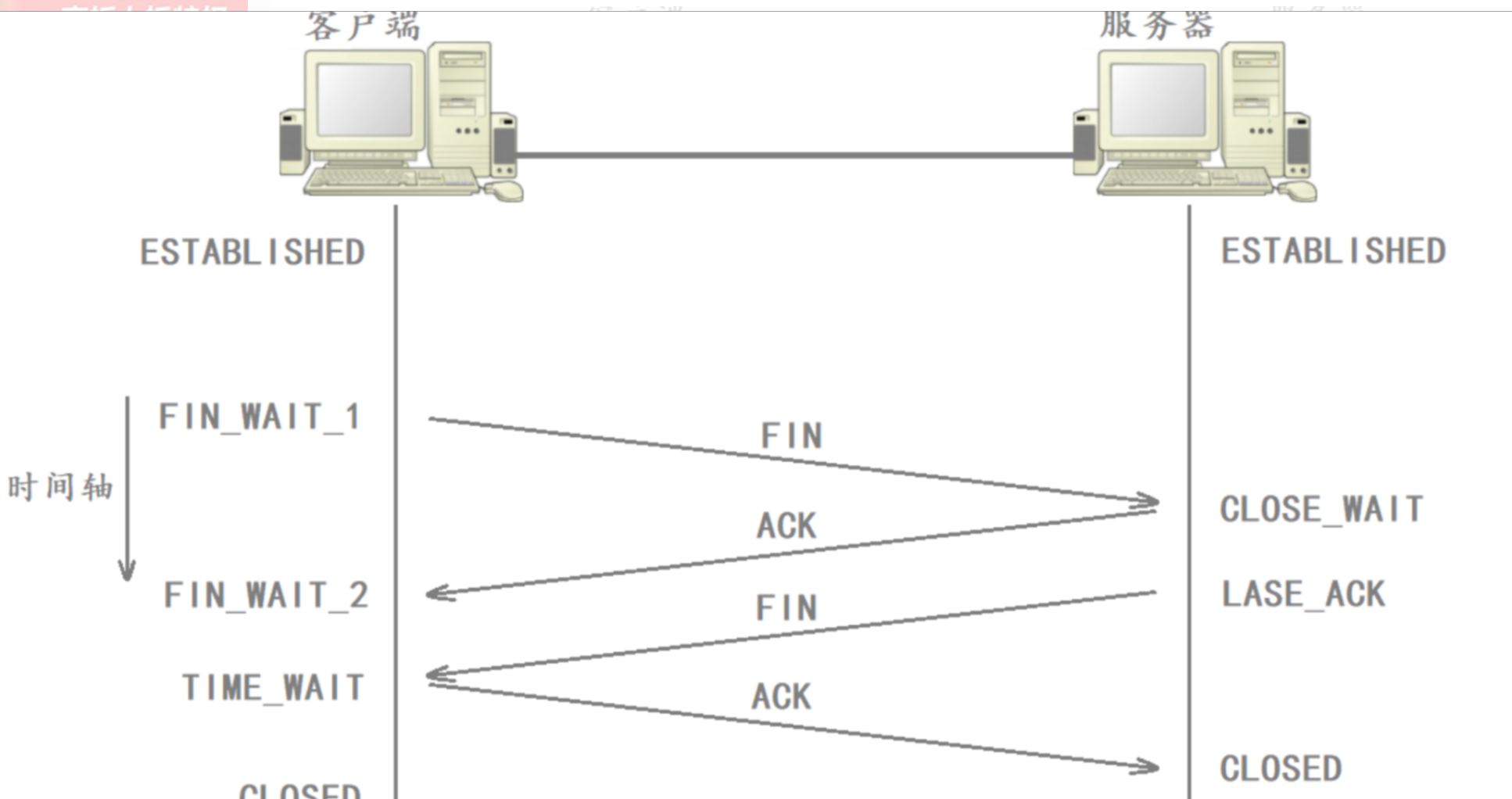
CLOSE_WAIT
- 雙方在進行四次揮手時,如果只有客戶端調用了close函數,而服務器不調用close函數,此時服務器就會進入CLOSE_WAIT狀態,而客戶端則會進入到FIN_WAIT_2狀態。
- 但只有完成四次揮手后連接才算真正斷開,此時雙方才會釋放對應的連接資源。如果服務器沒有主動關閉不需要的文件描述符,此時在服務器端就會存在大量處于CLOSE_WAIT狀態的連接,而每個連接都會占用服務器的資源,最終就會導致服務器可用資源越來越少。
TIME_WAIT狀態存在的必要性:
- 客戶端在進行四次揮手后進入TIME_WAIT狀態,如果第四次揮手的報文丟包了,客戶端在一段時間內仍然能夠接收服務器重發的FIN報文并對其進行響應,能夠較大概率保證最后一個ACK被服務器收到。
- 客戶端發出最后一次揮手時,雙方歷史通信的數據可能還沒有發送到對方。因此客戶端四次揮手后進入TIME_WAIT狀態,還可以保證雙方通信信道上的數據在網絡中盡可能的消散。
TCP協議規定,主動關閉連接的一方在四次揮手后要處于TIME_WAIT狀態,等待兩個MSL(Maximum Segment Lifetime,報文最大生存時間)的時間才能進入CLOSED狀態。
滑動窗口
發送方可以一次發送多個報文給對方,此時也就意味著發送出去的這部分報文當中有相當一部分數據是暫時沒有收到應答的。發送緩沖區的第二部分就叫做滑動窗口,滑動窗口除了限定不收到ACK而可以直接發送的數據之外,滑動窗口也可以支持TCP的重傳機制。

滑動窗口存在的最大意義就是可以提高發送數據的效率:
- 滑動窗口的大小等于對方窗口大小與自身擁塞窗口大小的較小值,因為發送數據時不僅要考慮對方的接收能力,還要考慮當前網絡的狀況。
- 我們這里先不考慮擁塞窗口,并且假設對方的窗口大小一直固定為4000,此時發送方不用等待ACK一次所能發送的數據就是4000字節,因此滑動窗口的大小就是4000字節。(四個段)
如何解決粘包問題
要解決粘包問題,本質就是要明確報文和報文之間的邊界,由應用層讀取。這個是該由應用層解決的問題。
- 對于UDP,如果還沒有上層交付數據,UDP的報文長度仍然在,同時,UDP是一個一個把數據交付給應用層的,有很明確的數據邊界。
- 對于定長的包,保證每次都按固定大小讀取即可。
解決TIME_WAIT狀態引起的bind失敗的方法
當服務器崩潰后最重要實際是讓服務器立馬重新啟動,如果想要讓服務器崩潰后在TIME_WAIT期間也能立馬重新啟動,需要讓服務器在調用socket函數創建套接字后,繼續調用setsockopt函數設置端口復用,這也是編寫服務器代碼時的推薦做法。
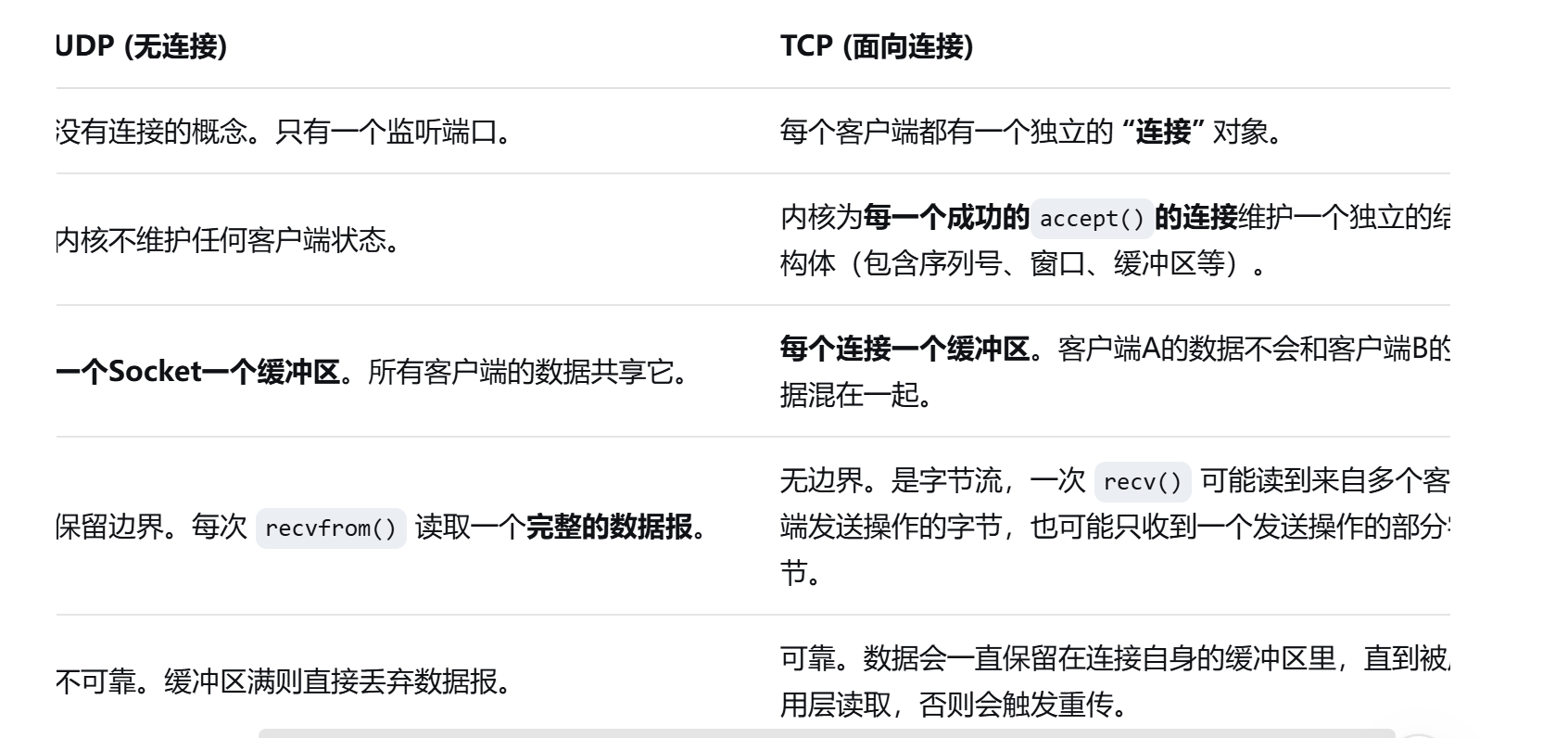
IP協議
- 網絡層解決的問題是,將數據從一臺主機送到另一臺主機,因此網絡層解決的是主機到主機的問題。
- 一方傳輸層從上方進程拿到數據后,該數據貫穿網絡協議棧進行封裝和解包,最終到達對方傳輸層,此時對方傳輸層也會將數據向上交給對應的進程,因此傳輸層解決的是進程到進程的問題。
IP如何將報頭與有效載荷進行分離?
IP分離報頭與有效載荷的方法與TCP是一模一樣的,當IP從底層獲取到一個報文后,雖然IP不知道報頭的具體長度,但IP報文的前20個字節是IP的基本報頭,并且這20字節當中涵蓋4位首部長度。
DHCP協議
實際手動管理IP地址是一個非常麻煩的事情,當子網中新增主機時需要給其分配一個IP地址,當子網當中有主機斷開網絡時又需要將其IP地址進行回收,便于分配給后續新增的主機使用。
- DHCP是一個基于UDP的應用層協議,一般的路由器都帶有DHCP功能,因此路由器也可以看作一個DHCP服務器。
- 當我們連接WiFi時需要輸入密碼,本質就是因為路由器需要驗證你的賬號和密碼,如果驗證通過,那么路由器就會給你動態分配了一個IP地址,然后你就可以基于這個IP地址進行各種上網動作了。
Linux高級IO
- 對文件進行的讀寫操作本質就是一種IO,文件IO對應的外設就是磁盤。
- 對網絡進行的讀寫操作本質也是一種IO,網絡IO對應的外設就是網卡。
輸入就是操作系統將數據從外設拷貝到內存的過程,操作系統一定要通過某種方法得知特定外設上是否有數據就緒。
- 操作系統實際采用的是中斷的方式來得知外設上是否有數據就緒的,當某個外設上面有數據就緒時,該外設就會向CPU當中的中斷控制器發送中斷信號,中斷控制器再根據產生的中斷信號的優先級按順序發送給CPU。
- 每一個中斷信號都有一個對應的中斷處理程序,存儲中斷信號和中斷處理程序映射關系的表叫做中斷向量表,當CPU收到某個中斷信號時就會自動停止正在運行的程序,然后根據該中斷向量表執行該中斷信號對應的中斷處理程序,處理完畢后再返回原被暫停的程序繼續運行。
OS如何處理從網卡中讀取到的數據包?
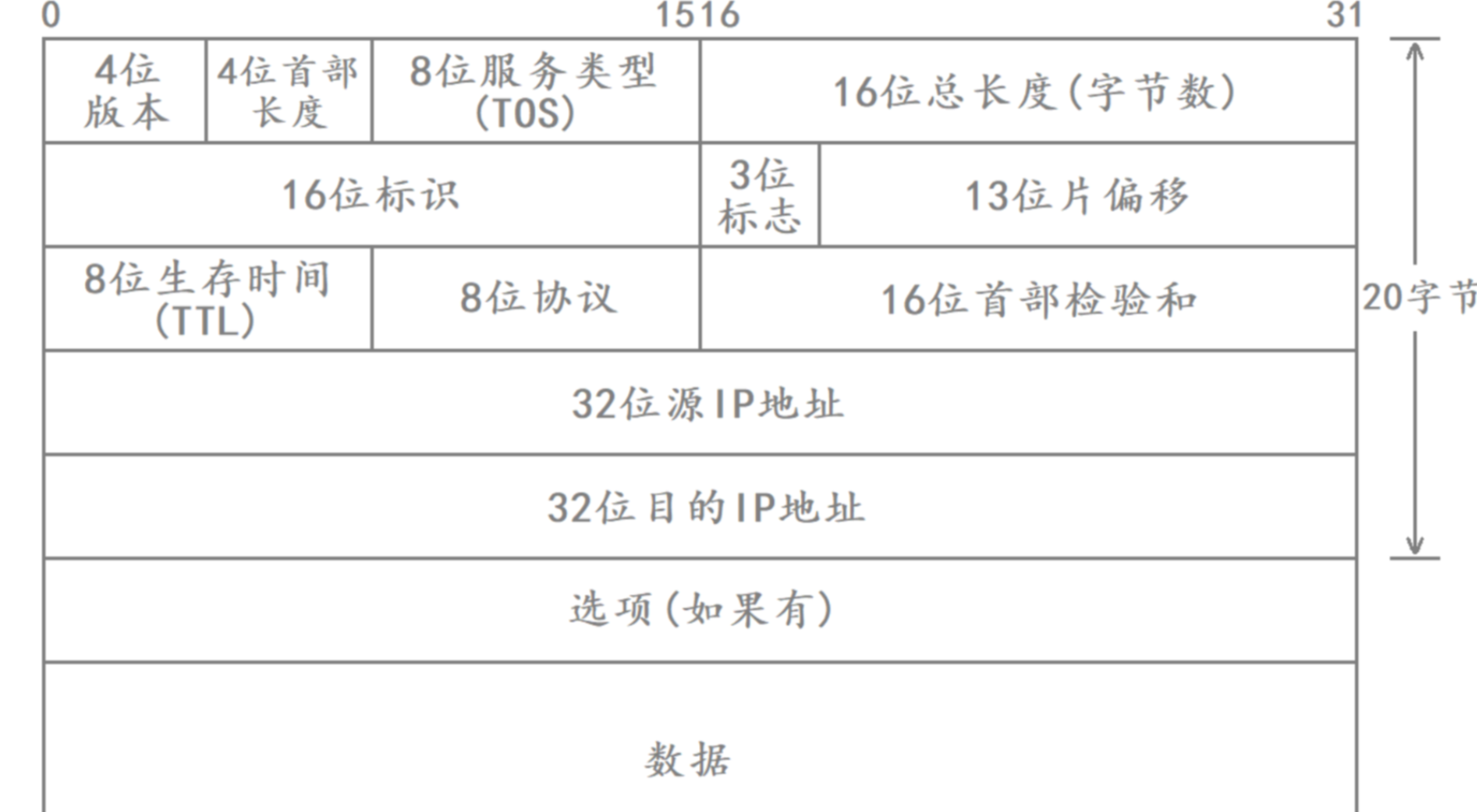
操作系統任何時刻都可能會收到大量的數據包,因此操作系統必須將這些數據包管理起來。操作系統從網卡當中讀取到一個數據包后,會將該數據依次交給鏈路層、網絡層、傳輸層、應用層進行解包和分用。最后將剩余數據交給 操作系統的接收緩沖區。
五種IO模型
實際這五個人的釣魚方式分別對應的就是五種IO模型。
張三、李四、王五他們三個人的釣魚的效率是一樣的,他們只是等魚上鉤的方式不同而已,張三是死等,李四是定期檢測浮漂,而王五是通過鈴鐺來判斷是否有魚上鉤,他們單位時間會釣上來的魚是一樣多的。通過這里的釣魚例子我們可以看到,阻塞IO、非阻塞IO和信號驅動IO本質上是不能提高IO的效率的,但非阻塞IO和信號驅動IO能提高整體做事的效率。
?
信號驅動IO
信號驅動IO就是當內核將數據準備好的時候,使用SIGIO信號通知應用程序進行IO操作。當底層數據就緒的時候會向當前進程或線程遞交SIGIO信號,因此可以通過signal或sigaction函數將SIGIO的信號處理程序自定義為需要進行的IO操作,當底層數據就緒時就會自動執行對應的IO操作。
IO多路轉接
IO多路轉接也叫做IO多路復用,能夠同時等待多個文件描述符的就緒狀態。
select實現
阻塞式等待所有設置進fd_set的文件描述符。
int select(int nfds, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout);select的優點
- 可以同時等待多個文件描述符,并且只負責等待,實際的IO操作由accept、read、write等接口來完成,這些接口在進行IO操作時不會被阻塞。
- select同時等待多個文件描述符,因此可以將“等”的時間重疊,提高了IO的效率。
select的缺點
- 每次調用select,都需要手動設置fd集合,從接口使用角度來說也非常不便。
- 每次調用select,都需要把fd集合從用戶態拷貝到內核態,這個開銷在fd很多時會很大。
- 同時每次調用select都需要在內核遍歷傳遞進來的所有fd,這個開銷在fd很多時也很大。
- select可監控的文件描述符數量有限。
I/O多路轉接之epoll
epoll有三個相關的系統調用,分別是epoll_create、epoll_ctl和epoll_wait。
int epoll_create(int size);返回值說明:
- epoll模型創建成功返回其對應的文件描述符,否則返回-1,同時錯誤碼會被設置。
當不再使用時,必須調用close函數關閉epoll模型對應的文件描述符,當所有引用epoll實例的文件描述符都已關閉時,內核將銷毀該實例并釋放相關資源。
epoll_ctl函數用于向指定的epoll模型中注冊事件,該函數的函數原型如下:
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
epoll_wait函數
epoll_ctl函數用于收集監視的事件中已經就緒的事件,該函數的函數原型如下:
int epoll_wait(int epfd, struct epoll_event *events, int maxevents, int timeout);epoll工作原理
紅黑樹和就緒隊列
當某一進程調用epoll_create函數時,Linux內核會創建一個eventpoll結構體,也就是我們所說的epoll模型,eventpoll結構體當中包含 成員rbr和rdlist,一顆紅黑樹和一個就緒隊列。
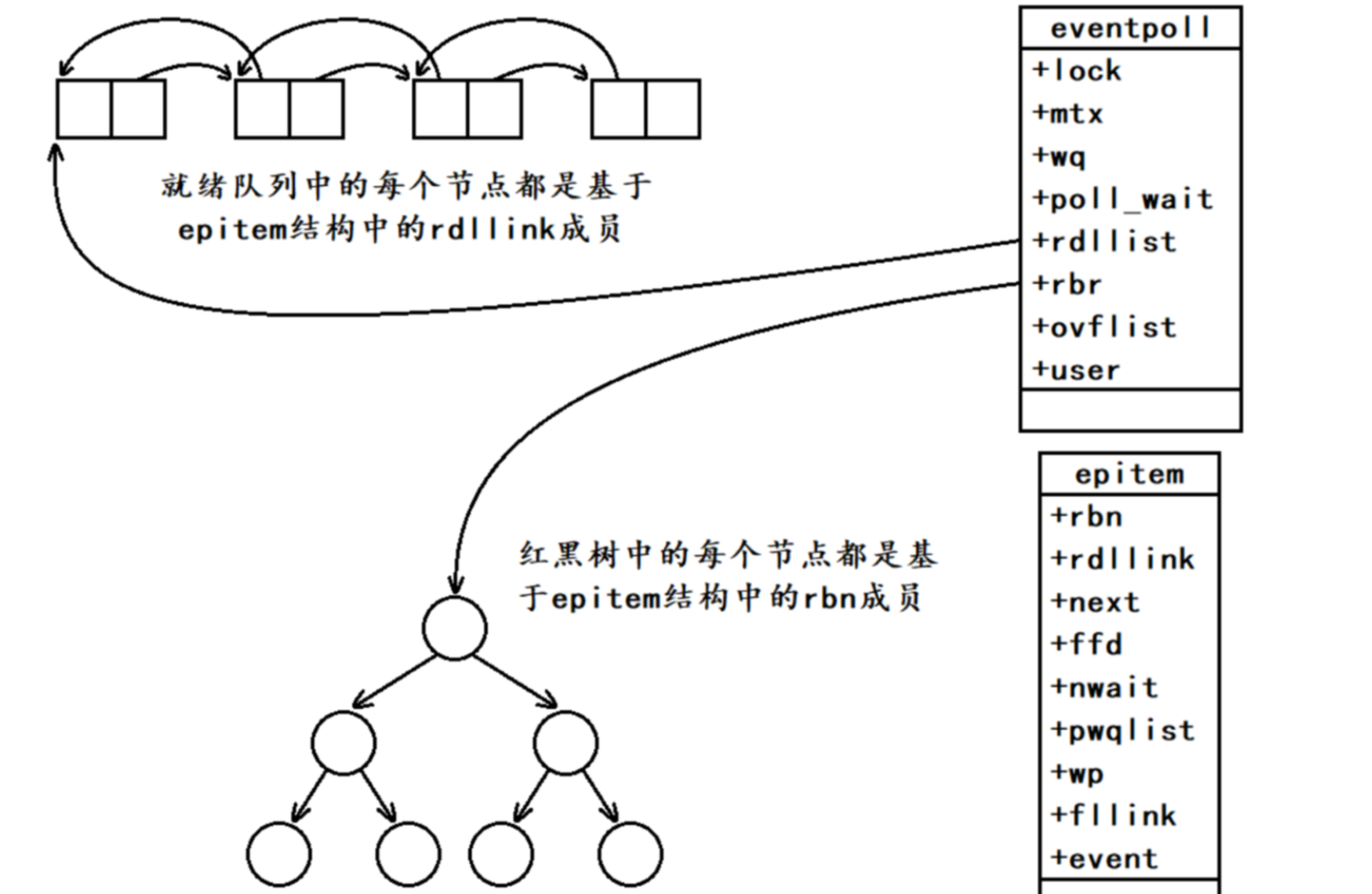
- epoll模型當中的紅黑樹本質就是告訴內核,需要監視哪些文件描述符上的哪些事件,調用epll_ctl函數實際就是在對這顆紅黑樹進行對應的增刪改操作。
- epoll模型當中的就緒隊列本質就是告訴內核,哪些文件描述符上的哪些事件已經就緒了,調用epoll_wait函數實際就是在從就緒隊列當中獲取已經就緒的事件。
回調機制
所有添加到紅黑樹當中的事件,都會與設備(網卡)驅動程序建立回調方法,這個回調方法在內核中叫ep_poll_callback。
- 對于select和poll來說,操作系統在監視多個文件描述符上的事件是否就緒時,需要讓操作系統主動對這多個文件描述符進行輪詢檢測,這一定會增加操作系統的負擔。
- 而對于epoll來說,操作系統不需要主動進行事件的檢測,當紅黑樹中監視的事件就緒時,會自動調用對應的回調方法,將就緒的事件添加到就緒隊列當中。
- 當用戶調用epoll_wait函數獲取就緒事件時,只需要關注底層就緒隊列是否為空,如果不為空則將就緒隊列當中的就緒事件拷貝給用戶即可。
- 由于就緒隊列可能會被多個執行流同時訪問,因此必須要使用互斥鎖對其進行保護,eventpoll結構當中的lock和mtx就是用于保護臨界資源的,因此epoll本身是線程安全的。
epoll工作方式LT和ET
epoll有兩種工作方式,分別是水平觸發工作模式和邊緣觸發工作模式。
水平觸發(LT,Level Triggered)
- 只要底層有事件就緒,epoll就會一直通知用戶。
- 就像數字電路當中的高電平觸發一樣,只要一直處于高電平,則會一直觸發。
epoll默認狀態下就是LT工作模式。
- 由于在LT工作模式下,只要底層有事件就緒就會一直通知用戶,因此當epoll檢測到底層讀事件就緒時,可以不立即進行處理,或者只處理一部分,因為只要底層數據沒有處理完,下一次epoll還會通知用戶事件就緒。
- select和poll其實就是工作是LT模式下的。
- 支持阻塞讀寫和非阻塞讀寫。
邊緣觸發(ET,Edge?Triggered)
- 只有底層就緒事件數量由無到有或由有到多發生變化的時候,epoll才會通知用戶。
- 就像數字電路當中的上升沿觸發一樣,只有當電平由低變高的那一瞬間才會觸發。
如果要將epoll改為ET工作模式,則需要在添加事件時設置EPOLLET選項。
- 由于在ET工作模式下,只有底層就緒事件無到有或由有到多發生變化的時候才會通知用戶,因此當epoll檢測到底層讀事件就緒時,必須立即進行處理,而且必須全部處理完畢,因為有可能此后底層再也沒有事件就緒,那么epoll就再也不會通知用戶進行事件處理,此時沒有處理完的數據就相當于丟失了。
- ET工作模式下epoll通知用戶的次數一般比LT少,因此ET的性能一般比LT性能更高,Nginx就是默認采用ET模式使用epoll的。
- 只支持非阻塞的讀寫。
ET工作模式下應該如何進行讀寫
因為在ET工作模式下,只有底層就緒事件無到有或由有到多發生變化的時候才會通知用戶,這就倒逼用戶當讀事件就緒時必須一次性將數據全部讀取完畢,當寫事件就緒時必須一次性將發送緩沖區寫滿,否則可能再也沒有機會進行讀寫了。
因此讀數據時必須循環調用recv函數進行讀取,寫數據時必須循環調用send函數進行寫入。
- 當底層讀事件就緒時,循環調用recv函數進行讀取,直到某次調用recv讀取時,實際讀取到的字節數小于期望讀取的字節數,則說明本次底層數據已經讀取完畢了。
- 但有可能最后一次調用recv讀取時,剛好實際讀取的字節數和期望讀取的字節數相等,但此時底層數據也恰好讀取完畢了,如果我們再調用recv函數進行讀取,那么recv就會因為底層沒有數據而被阻塞住。? 因此需要非阻塞讀寫。
對比LT和ET
- 在ET模式下,一個文件描述符就緒之后,用戶不會反復收到通知,看起來比LT更高效,但如果在LT模式下能夠做到每次都將就緒的文件描述符立即全部處理,不讓操作系統反復通知用戶的話,其實LT和ET的性能也是一樣的。
- 此外,ET的編程難度比LT更高。ET模式一定會以最快的速度把TCP緩沖區的數據讀走。這樣會給對方一個更大的ACK窗口,更高效。LT也可以實現ET的效果。
poll?ET服務器(Reactor模式)
Reactor反應器模式,也叫做分發者模式或通知者模式,是一種將就緒事件派發給對應服務處理程序的事件設計模式。
Reactor模式的五個角色
在這個epoll ET服務器中,Reactor模式中的五個角色對應如下:
- 句柄:文件描述符。
- 同步事件分離器:I/O多路復用epoll。
- 事件處理器:包括讀回調、寫回調和異常回調。
- 具體事件處理器:讀回調、寫回調和異常回調的具體實現。
- 初始分發器:Reactor類當中的Dispatcher函數。


 規范深度解析)
![[硬件電路-179]:集成運放,虛短的是電壓,虛斷的是電流](http://pic.xiahunao.cn/[硬件電路-179]:集成運放,虛短的是電壓,虛斷的是電流)

結合子陣列算法,創建基于區塊鏈的動態信任管理模型)








——事件監聽(用戶交互))



)
