背景意義
研究背景與意義
隨著智能家居和自動化技術的快速發展,室內場景理解在計算機視覺領域中變得愈發重要。室內場景分割不僅是計算機視覺的基礎任務之一,也是實現智能家居、機器人導航、增強現實等應用的關鍵技術。傳統的圖像分割方法在處理復雜的室內環境時往往面臨諸多挑戰,如光照變化、物體遮擋和背景復雜性等。因此,開發一種高效且準確的室內場景分割系統顯得尤為重要。
YOLO(You Only Look Once)系列模型因其快速和高效的特性,已成為目標檢測和分割領域的熱門選擇。YOLOv11作為該系列的最新版本,進一步提升了模型的準確性和實時性。然而,針對室內場景的特定需求,YOLOv11的標準配置可能并不足以滿足所有應用場景的要求。因此,改進YOLOv11以適應室內場景分割,尤其是在對天花板、墻壁等特定類別進行精準識別和分割,將為智能家居系統的實現提供強有力的支持。
本研究基于ADE20K數據集,該數據集包含2500幅經過精確標注的室內場景圖像,涵蓋了天花板、墻壁等關鍵類別。通過對這些圖像進行深度學習訓練,模型能夠有效學習到室內環境的特征,從而實現高效的場景分割。研究的意義在于,不僅為室內場景分割提供了一種新的技術方案,也為相關領域的研究提供了數據支持和理論基礎。通過改進YOLOv11模型,期望能夠提升室內場景分割的準確性和實時性,為未來的智能家居、機器人導航等應用奠定堅實的基礎。
圖片效果
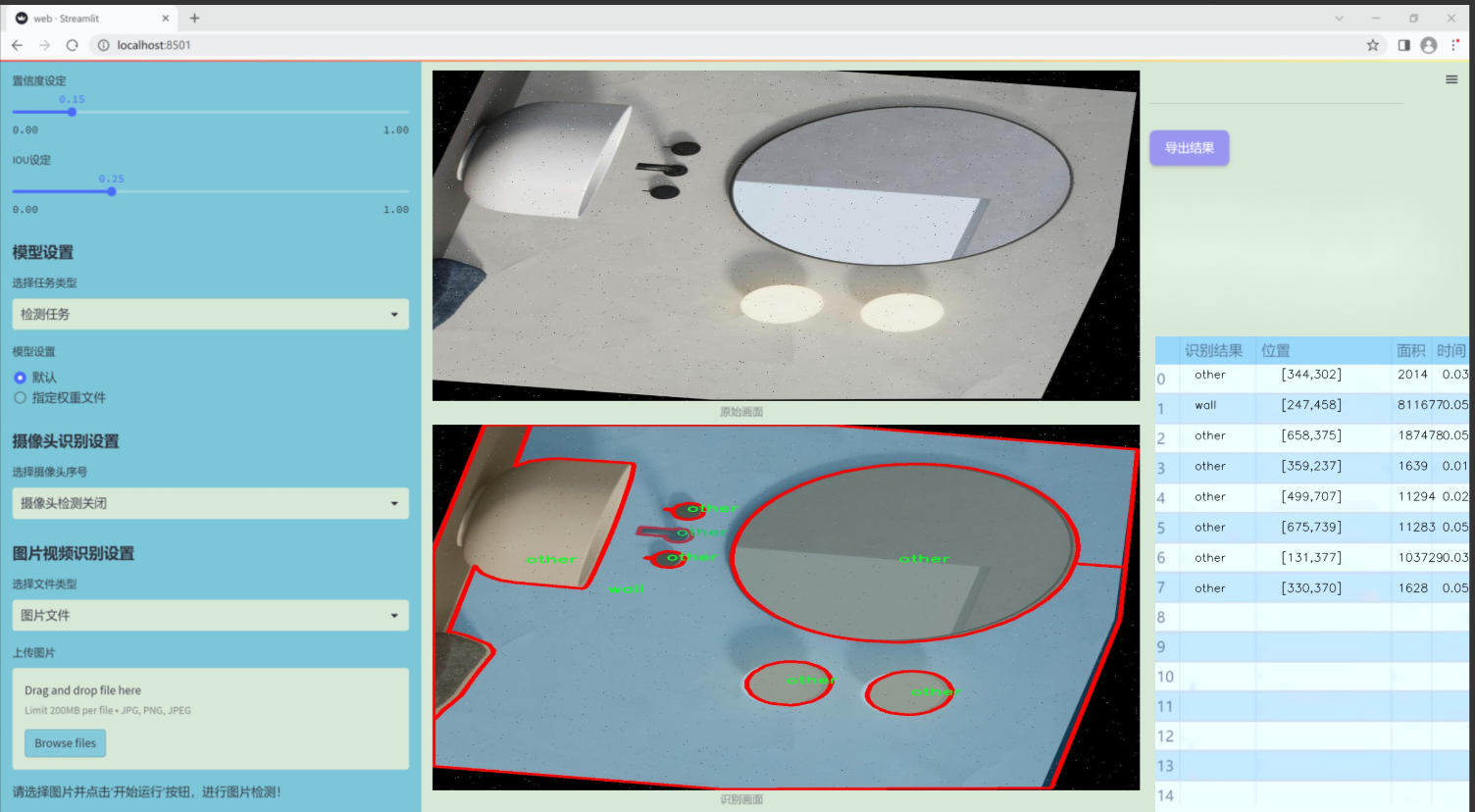
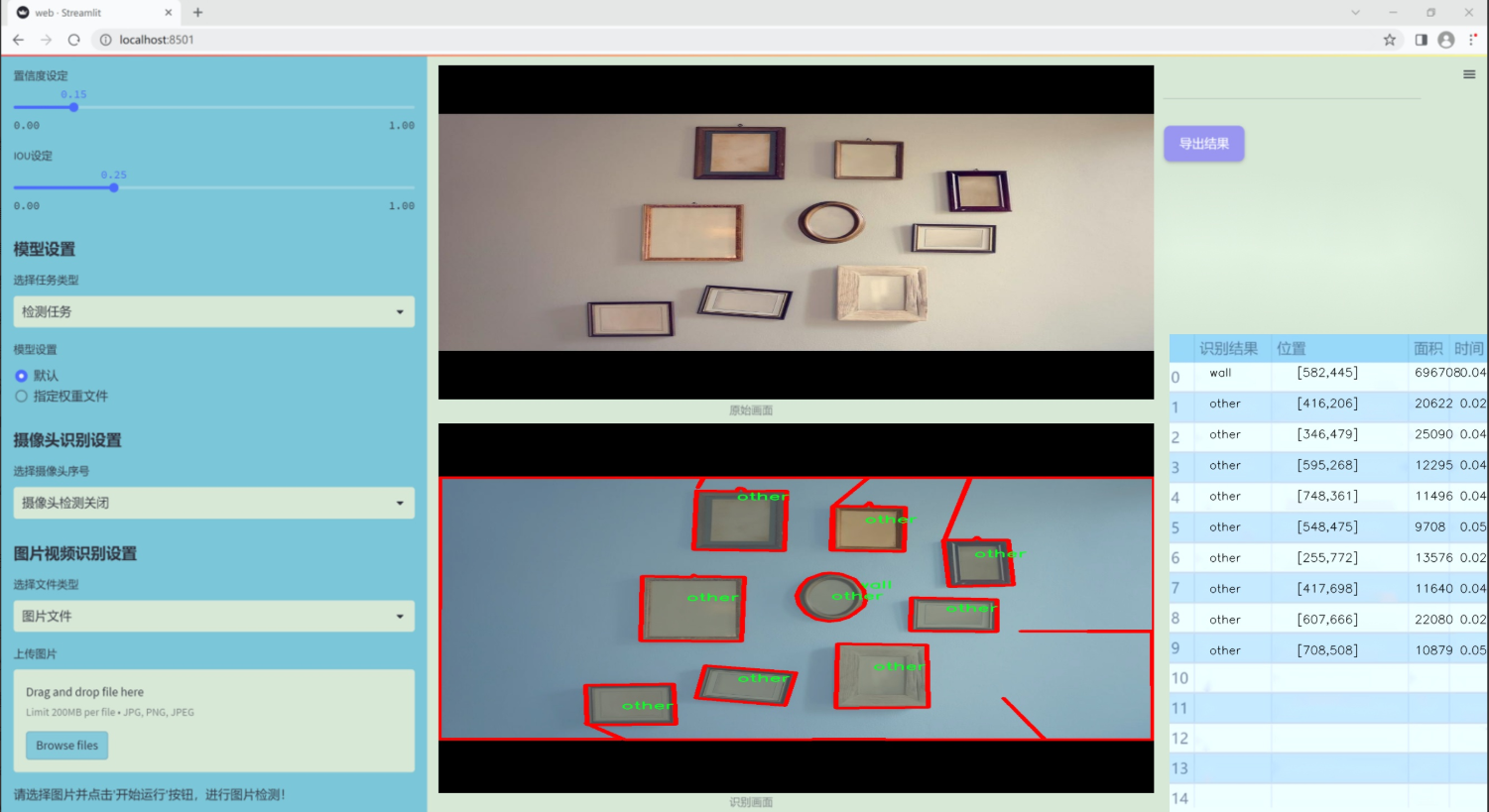
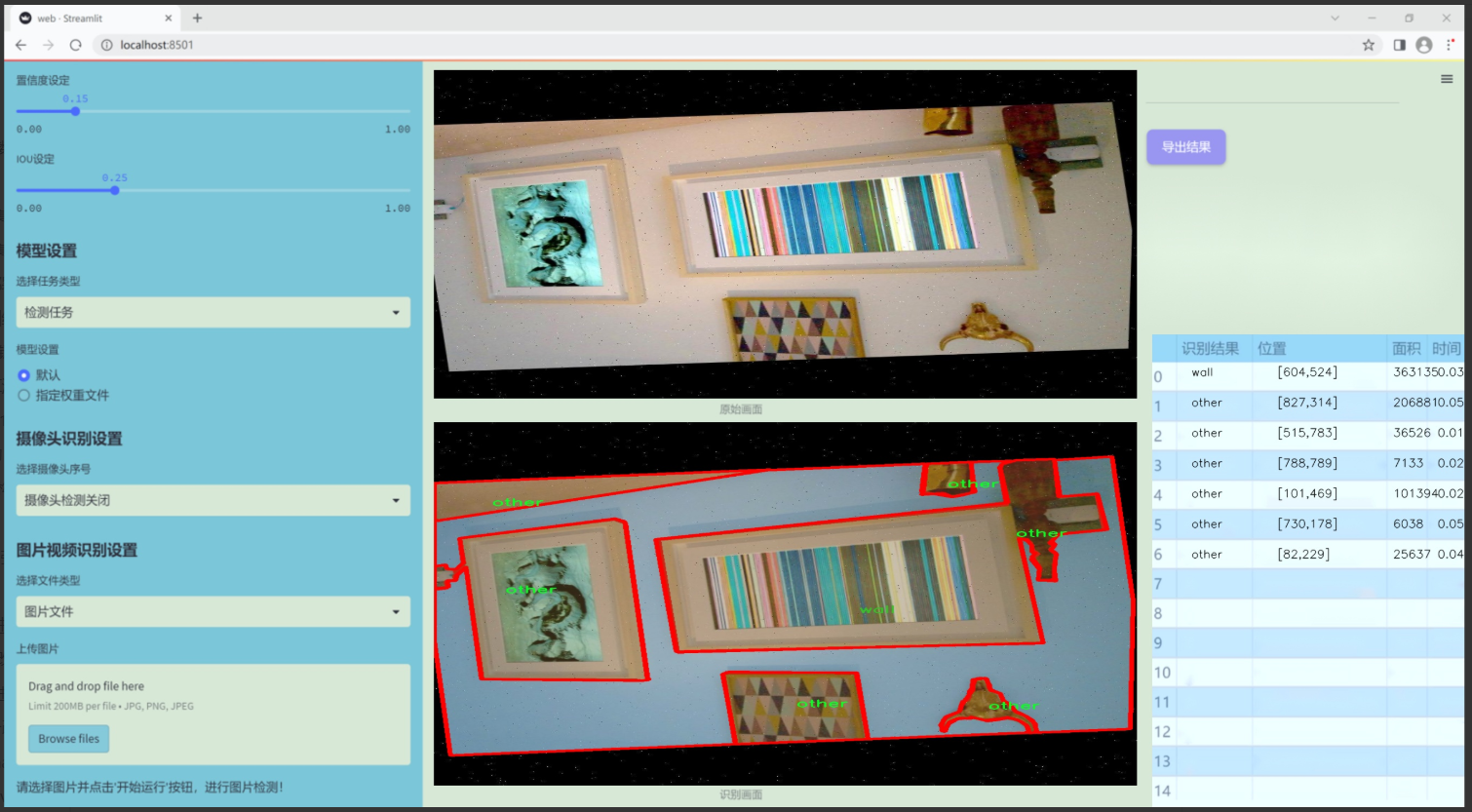
數據集信息
本項目數據集信息介紹
本項目所使用的數據集為“ade20k-dataset-v4.0.1”,該數據集專注于室內場景的分割任務,旨在為改進YOLOv11的室內場景分割系統提供豐富的訓練素材。該數據集包含三種主要類別,分別是“ceiling”(天花板)、“other”(其他)和“wall”(墻壁),共計三個類別。這些類別的選擇反映了室內環境中常見的結構元素,為模型的訓練提供了必要的多樣性和代表性。
在數據集的構建過程中,研究團隊對每一類進行了精細的標注,以確保在訓練過程中,模型能夠準確識別和分割出不同的室內元素。天花板作為室內空間的重要組成部分,其形狀、顏色和材質的多樣性為模型的學習提供了豐富的特征信息。墻壁則是室內環境的基礎構件,其位置和設計風格直接影響空間的視覺效果和功能性。而“其他”類別則涵蓋了各種可能出現的室內物體和結構,確保模型在面對復雜場景時能夠具備更強的適應能力。
通過對這些類別的深度學習,改進后的YOLOv11模型將能夠在多種室內環境中實現更高效的分割,提升其在實際應用中的表現。這一數據集不僅為模型提供了必要的訓練基礎,也為后續的測試和驗證提供了可靠的數據支持。隨著對室內場景理解的不斷深入,模型的分割精度和實時性將得到顯著提升,為智能家居、室內導航等應用場景的實現奠定堅實的基礎。
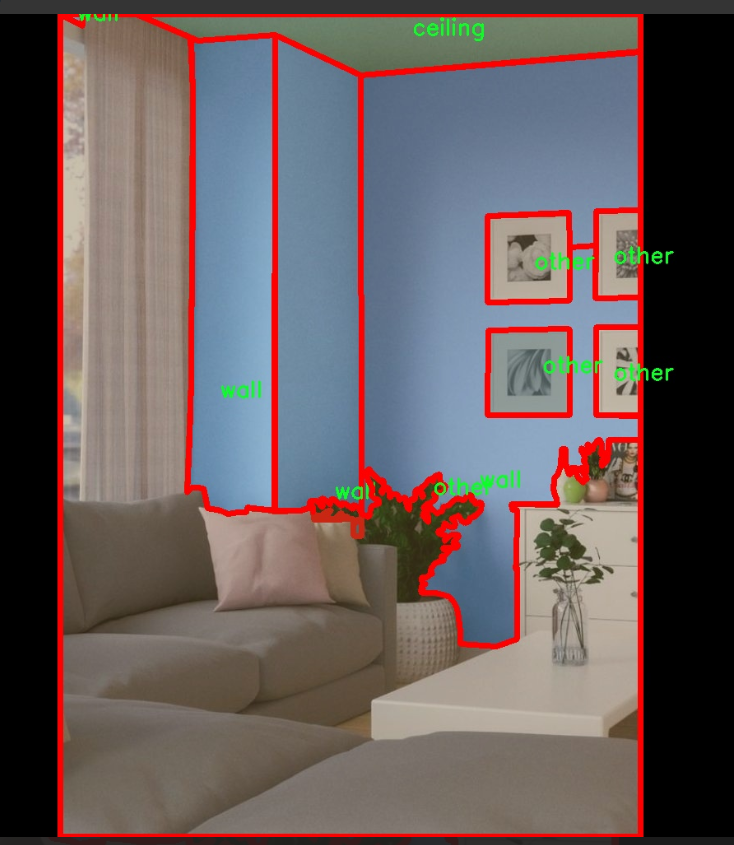




核心代碼
以下是經過簡化并添加詳細中文注釋的核心代碼部分:
import torch
import torch.nn as nn
class KACNConvNDLayer(nn.Module):
def init(self, conv_class, norm_class, input_dim, output_dim, degree, kernel_size,
groups=1, padding=0, stride=1, dilation=1,
ndim: int = 2, dropout=0.0):
super(KACNConvNDLayer, self).init()
# 初始化參數self.inputdim = input_dim # 輸入維度self.outdim = output_dim # 輸出維度self.degree = degree # 多項式的階數self.kernel_size = kernel_size # 卷積核大小self.padding = padding # 填充self.stride = stride # 步幅self.dilation = dilation # 膨脹self.groups = groups # 分組卷積的組數self.ndim = ndim # 數據的維度(1D, 2D, 3D)# 初始化 dropout 層self.dropout = Noneif dropout > 0:if ndim == 1:self.dropout = nn.Dropout1d(p=dropout)elif ndim == 2:self.dropout = nn.Dropout2d(p=dropout)elif ndim == 3:self.dropout = nn.Dropout3d(p=dropout)# 檢查 groups 參數的有效性if groups <= 0:raise ValueError('groups must be a positive integer')if input_dim % groups != 0:raise ValueError('input_dim must be divisible by groups')if output_dim % groups != 0:raise ValueError('output_dim must be divisible by groups')# 初始化歸一化層self.layer_norm = nn.ModuleList([norm_class(output_dim // groups) for _ in range(groups)])# 初始化多項式卷積層self.poly_conv = nn.ModuleList([conv_class((degree + 1) * input_dim // groups,output_dim // groups,kernel_size,stride,padding,dilation,groups=1,bias=False) for _ in range(groups)])# 注冊緩沖區,用于存儲多項式的階數arange_buffer_size = (1, 1, -1,) + tuple(1 for _ in range(ndim))self.register_buffer("arange", torch.arange(0, degree + 1, 1).view(*arange_buffer_size))# 使用 Kaiming 正態分布初始化卷積層的權重for conv_layer in self.poly_conv:nn.init.normal_(conv_layer.weight, mean=0.0, std=1 / (input_dim * (degree + 1) * kernel_size ** ndim))def forward_kacn(self, x, group_index):# 對輸入進行前向傳播x = torch.tanh(x) # 應用tanh激活函數x = x.acos().unsqueeze(2) # 計算反余弦并增加維度x = (x * self.arange).flatten(1, 2) # 乘以階數并展平x = x.cos() # 計算余弦x = self.poly_conv[group_index](x) # 通過對應的卷積層x = self.layer_norm[group_index](x) # 歸一化if self.dropout is not None:x = self.dropout(x) # 應用dropoutreturn xdef forward(self, x):# 前向傳播的主函數split_x = torch.split(x, self.inputdim // self.groups, dim=1) # 按組分割輸入output = []for group_ind, _x in enumerate(split_x):y = self.forward_kacn(_x.clone(), group_ind) # 對每組進行前向傳播output.append(y.clone()) # 存儲輸出y = torch.cat(output, dim=1) # 合并所有組的輸出return y
代碼說明:
KACNConvNDLayer: 這是一個自定義的卷積層,支持多維卷積(1D, 2D, 3D)。它使用多項式卷積和歸一化層。
初始化方法: 在初始化中,設置了輸入輸出維度、卷積參數、分組數、dropout等,并進行了必要的參數檢查。
前向傳播: forward_kacn 方法實現了對輸入的具體處理,包括激活、卷積和歸一化等操作。
分組處理: forward 方法將輸入分成多個組,分別通過 forward_kacn 進行處理,然后將結果合并。
這個程序文件定義了一個名為 kacn_conv.py 的模塊,主要實現了一個自定義的卷積層,名為 KACNConvNDLayer,以及它的三個特化版本:KACNConv3DLayer、KACNConv2DLayer 和 KACNConv1DLayer。這些類是基于 PyTorch 框架構建的,利用了深度學習中的卷積操作。
首先,KACNConvNDLayer 類是一個通用的多維卷積層,它接受多個參數,包括卷積類型、歸一化類型、輸入和輸出維度、卷積核大小、組數、填充、步幅、擴張、維度數量和 dropout 比例。構造函數中,首先調用父類的構造函數,然后初始化了多個屬性,包括輸入和輸出維度、卷積核的相關參數等。特別地,dropout 只在指定的維度下被創建。
在參數驗證方面,類確保了組數是正整數,并且輸入和輸出維度能夠被組數整除。接著,類創建了一個歸一化層的列表和一個多項式卷積層的列表,后者的數量與組數相同。多項式卷積層的權重使用 Kaiming 正態分布初始化,以便于訓練的開始。
forward_kacn 方法是這個類的核心,定義了前向傳播的具體操作。輸入首先經過一個激活函數(雙曲正切),然后進行一系列的數學變換,最后通過對應的卷積層和歸一化層處理,并在必要時應用 dropout。
forward 方法則負責將輸入張量按組進行分割,并對每個組調用 forward_kacn 方法,最后將所有組的輸出拼接在一起,形成最終的輸出。
接下來的三個類 KACNConv3DLayer、KACNConv2DLayer 和 KACNConv1DLayer 是對 KACNConvNDLayer 的特化,分別用于三維、二維和一維卷積操作。它們在構造函數中調用父類的構造函數,并傳入相應的卷積和歸一化層類型。
總體而言,這個文件實現了一個靈活且可擴展的卷積層結構,能夠處理不同維度的輸入數據,并通過多項式卷積和歸一化操作來增強模型的表達能力。
10.4 RFAConv.py
以下是代碼中最核心的部分,并附上詳細的中文注釋:
import torch
import torch.nn as nn
from einops import rearrange
class RFAConv(nn.Module):
def init(self, in_channel, out_channel, kernel_size, stride=1):
super().init()
self.kernel_size = kernel_size
# 通過平均池化和卷積生成權重self.get_weight = nn.Sequential(nn.AvgPool2d(kernel_size=kernel_size, padding=kernel_size // 2, stride=stride),nn.Conv2d(in_channel, in_channel * (kernel_size ** 2), kernel_size=1, groups=in_channel, bias=False))# 生成特征的卷積層self.generate_feature = nn.Sequential(nn.Conv2d(in_channel, in_channel * (kernel_size ** 2), kernel_size=kernel_size, padding=kernel_size // 2, stride=stride, groups=in_channel, bias=False),nn.BatchNorm2d(in_channel * (kernel_size ** 2)),nn.ReLU())# 最終的卷積層self.conv = nn.Conv2d(in_channel, out_channel, kernel_size=kernel_size, stride=kernel_size)def forward(self, x):b, c = x.shape[0:2] # 獲取輸入的批量大小和通道數weight = self.get_weight(x) # 計算權重h, w = weight.shape[2:] # 獲取特征圖的高度和寬度# 對權重進行softmax歸一化weighted = weight.view(b, c, self.kernel_size ** 2, h, w).softmax(2) # b c*k**2, h, w# 生成特征并調整形狀feature = self.generate_feature(x).view(b, c, self.kernel_size ** 2, h, w) # b c*k**2, h, w# 加權特征weighted_data = feature * weighted# 重新排列特征圖conv_data = rearrange(weighted_data, 'b c (n1 n2) h w -> b c (h n1) (w n2)', n1=self.kernel_size, n2=self.kernel_size)return self.conv(conv_data) # 通過卷積層輸出結果
class SE(nn.Module):
def init(self, in_channel, ratio=16):
super(SE, self).init()
self.gap = nn.AdaptiveAvgPool2d((1, 1)) # 全局平均池化
self.fc = nn.Sequential(
nn.Linear(in_channel, ratio, bias=False), # 通道壓縮
nn.ReLU(),
nn.Linear(ratio, in_channel, bias=False), # 通道恢復
nn.Sigmoid() # 激活函數
)
def forward(self, x):b, c = x.shape[0:2] # 獲取輸入的批量大小和通道數y = self.gap(x).view(b, c) # 全局平均池化并調整形狀y = self.fc(y).view(b, c, 1, 1) # 通過全連接層并調整形狀return y # 返回通道注意力
class RFCBAMConv(nn.Module):
def init(self, in_channel, out_channel, kernel_size=3, stride=1):
super().init()
self.kernel_size = kernel_size
# 生成特征的卷積層self.generate = nn.Sequential(nn.Conv2d(in_channel, in_channel * (kernel_size ** 2), kernel_size, padding=kernel_size // 2, stride=stride, groups=in_channel, bias=False),nn.BatchNorm2d(in_channel * (kernel_size ** 2)),nn.ReLU())# 計算通道注意力的卷積層self.get_weight = nn.Sequential(nn.Conv2d(2, 1, kernel_size=3, padding=1, bias=False), nn.Sigmoid())self.se = SE(in_channel) # 通道注意力模塊# 最終的卷積層self.conv = nn.Conv2d(in_channel, out_channel, kernel_size=kernel_size, stride=kernel_size)def forward(self, x):b, c = x.shape[0:2] # 獲取輸入的批量大小和通道數channel_attention = self.se(x) # 計算通道注意力generate_feature = self.generate(x) # 生成特征h, w = generate_feature.shape[2:] # 獲取特征圖的高度和寬度generate_feature = generate_feature.view(b, c, self.kernel_size ** 2, h, w) # 調整形狀# 重新排列特征圖generate_feature = rearrange(generate_feature, 'b c (n1 n2) h w -> b c (h n1) (w n2)', n1=self.kernel_size, n2=self.kernel_size)# 計算加權特征unfold_feature = generate_feature * channel_attention# 計算最大和平均特征max_feature, _ = torch.max(generate_feature, dim=1, keepdim=True)mean_feature = torch.mean(generate_feature, dim=1, keepdim=True)# 計算感受野注意力receptive_field_attention = self.get_weight(torch.cat((max_feature, mean_feature), dim=1))# 加權特征與感受野注意力相乘conv_data = unfold_feature * receptive_field_attentionreturn self.conv(conv_data) # 通過卷積層輸出結果
代碼核心部分解釋:
RFAConv:該類實現了一種卷積操作,使用自適應權重來加權特征圖。它首先通過平均池化和卷積生成權重,然后生成特征并通過softmax進行歸一化,最后將加權特征輸入到卷積層中。
SE:通道注意力模塊,通過全局平均池化和全連接層來生成通道注意力權重,幫助模型關注重要的通道。
RFCBAMConv:結合了特征生成和通道注意力的卷積模塊。它首先生成特征,然后計算通道注意力和感受野注意力,最后將這些信息結合起來進行卷積操作。
這些模塊的設計旨在增強卷積神經網絡的特征提取能力,通過注意力機制使模型能夠更好地關注重要的特征。
這個程序文件 RFAConv.py 定義了一些基于卷積神經網絡的模塊,主要包括 RFAConv、RFCBAMConv 和 RFCAConv。這些模塊使用了自定義的激活函數和注意力機制,旨在增強卷積操作的特征提取能力。
首先,文件中引入了必要的庫,包括 PyTorch 和 einops。h_sigmoid 和 h_swish 是自定義的激活函數,分別實現了 h-sigmoid 和 h-swish。這些激活函數在前向傳播中使用,提供了非線性變換的能力。
RFAConv 類是一個卷積模塊,構造函數中定義了幾個子模塊。get_weight 模塊通過平均池化和卷積操作生成權重,用于后續的特征加權。generate_feature 模塊則通過卷積、批歸一化和 ReLU 激活生成特征。conv 模塊是最終的卷積操作。前向傳播中,輸入數據經過權重計算和特征生成后,進行加權和重排,最后通過卷積層輸出結果。
SE 類實現了 Squeeze-and-Excitation (SE) 機制,用于通道注意力的計算。它通過全局平均池化和全連接層生成通道權重,并在前向傳播中應用于輸入特征。
RFCBAMConv 類結合了 RFAConv 和 SE 機制。它在構造函數中定義了生成特征和獲取權重的模塊。前向傳播中,首先計算通道注意力,然后生成特征并進行重排,接著通過最大池化和平均池化獲取特征的統計信息,最后結合通道注意力和接收場注意力進行卷積操作。
RFCAConv 類是另一個卷積模塊,增加了對輸入特征的高度和寬度的自適應池化。它通過生成特征、池化和卷積操作,計算出注意力權重,并將其應用于特征上。最終,輸出通過卷積層生成。
整體來看,這個文件實現了一些先進的卷積模塊,結合了特征生成、注意力機制和自適應操作,旨在提高模型的表現和特征提取能力。
源碼文件

源碼獲取
歡迎大家點贊、收藏、關注、評論啦 、查看👇🏻獲取聯系方式


















