人工智能和多模態學習領域,視頻理解技術的突破為各類應用提供了強大的支持。快手近期開源了其創新性的大型多模態推理模型——Keye-VL 1.5,該模型具備超長的上下文窗口、0.1秒級的視頻時序定位能力,并支持視頻與文本之間的跨模態推理。這一技術的發布,標志著視頻理解和智能推理能力的新高峰。
Keye-VL 1.5:全面提升視頻理解與推理能力
Keye-VL 1.5的優勢主要體現在三個方面:
- 128K上下文窗口:?Keye-VL 1.5通過創新的Slow-Fast雙路編碼機制,支持128K超長的上下文窗口,使得模型能夠在處理視頻內容時考慮到更多的歷史信息,從而提高視頻理解的深度和準確性。
- 0.1秒級視頻時序定位:?該模型能夠精確到0.1秒的粒度識別視頻中物品或場景的出現時刻。這一時序能力極大提升了視頻內容的精確度,尤其適用于帶貨視頻等短視頻場景,能夠準確判斷關鍵事件發生的具體時刻。
- 跨模態推理:?除了基本的視頻理解,Keye-VL 1.5還能夠進行跨模態推理,結合視頻內容和文本信息推斷出可能的后續事件,提供更加完整的事件鏈分析。例如,在視頻中,模型能夠根據寵物之間的互動推測出行為背后的原因。
技術創新:快慢編碼與多階段預訓練
Keye-VL 1.5不僅僅是在視頻理解上做出了突破,還通過以下技術創新提升了模型的整體性能:
- 快慢編碼機制:?Keye-VL 1.5采用了“快幀”和“慢幀”兩種處理策略。快幀用于靜態場景的高幀率處理,慢幀則保留高分辨率細節,確保在高效運算的同時保留關鍵圖像信息。這一策略讓模型在不犧牲速度的情況下,提高了計算效率。
- 四階段漸進式預訓練:?Keye-VL 1.5的訓練過程經歷了四個階段,從視覺編碼器的預訓練到跨模態對齊,再到多任務優化和退火訓練,最終使得模型能夠在多個視頻理解基準測試中超越同類模型。
在多個基準測試中領先,開創視頻理解新標準
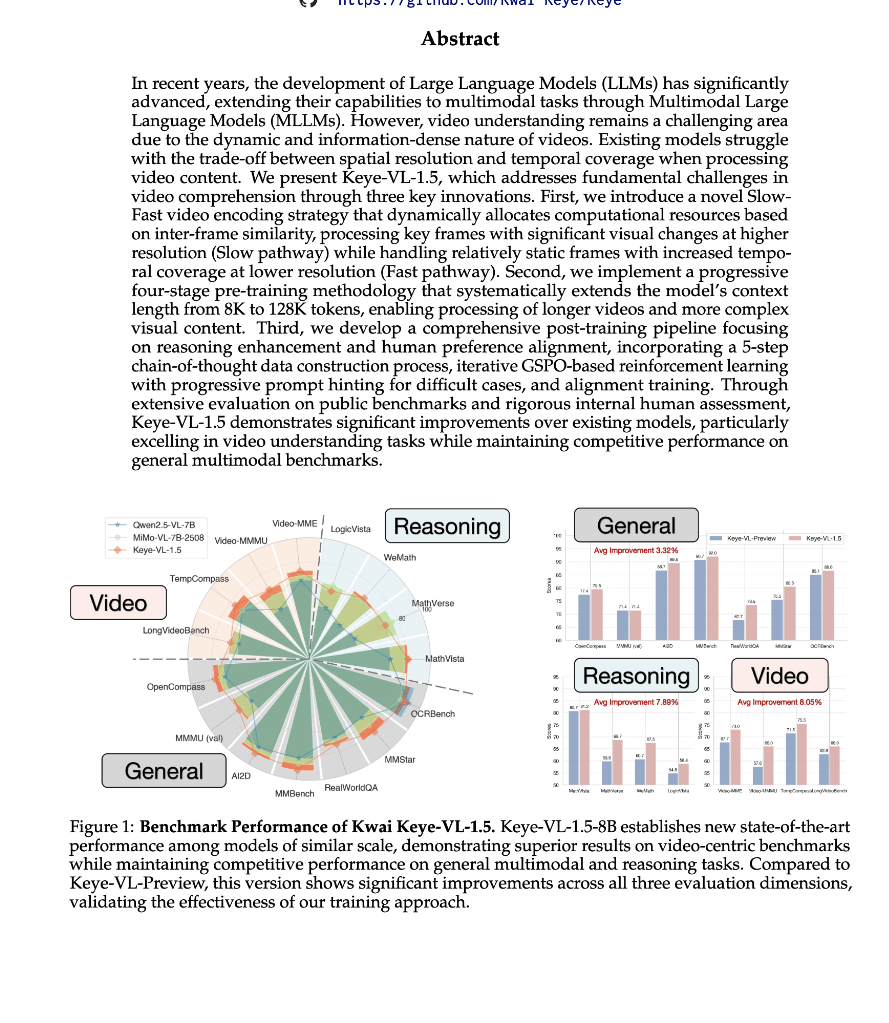
Keye-VL 1.5在多個公開基準測試中表現出色,獲得了視頻理解領域的多個SOTA(state-of-the-art)成績。在Video-MME、TempCompass和LongVideoBench等測試中,Keye-VL 1.5均表現超越Qwen2.5-VL 7B等同類模型。特別是在MMBench和OpenCompass等基準中,Keye-VL 1.5的成績在同尺寸模型中遙遙領先。
此外,Keye-VL 1.5也在AI2D、OCRBench等視覺推理強相關的數據集中表現突出,充分展示了其在圖像和視頻理解方面的強大能力。
如何實現這些突破:Keye團隊的技術積淀
Keye-VL 1.5的突破離不開Keye團隊在多模態學習和視頻理解方面的深厚積累。團隊利用ViT(視覺Transformer)結合語言解碼器的架構,并引入了3DRoPE和Slow-Fast編碼等技術,使得模型能夠同時處理高分辨率和高幀率的視頻內容,確保信息的完整性和時序的精準度。
模型權重與在線演示
快手已經將Keye-VL 1.5的模型權重公開,并提供了基于Hugging Face平臺的在線演示。研究人員和開發者可以輕松訪問和測試該模型,以驗證其在實際應用中的表現。
- 模型權重:?Keye-VL 1.5-8B模型權重
- 在線演示:?Keye-VL 1.5在線DEMO
總結
隨著快手Keye-VL 1.5的開源,視頻理解和跨模態推理技術邁上了新的臺階。憑借其強大的時序定位、跨模態推理和創新性編碼策略,Keye-VL 1.5為智能視頻分析提供了新的技術框架,并為各類短視頻應用場景,如電商帶貨、智能剪輯、視頻搜索等,提供了強有力的技術支撐。





)
![[源力覺醒 創作者計劃]_文心一言 4.5開源深度解析:性能狂飆 + 中文專精](http://pic.xiahunao.cn/[源力覺醒 創作者計劃]_文心一言 4.5開源深度解析:性能狂飆 + 中文專精)


![[GYCTF2020]Ezsqli](http://pic.xiahunao.cn/[GYCTF2020]Ezsqli)









