標題:Sparse4D v3:Advancing End-to-End 3D Detection and Tracking
作者:Xuewu Lin, Zixiang Pei, Tianwei Lin, Lichao Huang, Zhizhong Su
motivation
作者覺得做自動駕駛,還需要跟蹤。于是更深入的把3D-檢測&跟蹤用sparse的模式做好。 檢測性能的進一步優化及端到端跟蹤實現。
于是將目光聚焦到了兩個問題上:
**收斂困難:**稀疏形式的感知算法,大多數都面臨這個收斂困難的問題,收斂速度相對較慢、訓練不穩定導致最終指標不高;在Sparse4D-V2 中,我們主要采用了額外的深度估計任務來幫助網絡訓練,但由于用上了額外的點云作為監督,這并不是一種理想的形式。
**端到端跟蹤:**在實際業務系統中,在檢測模塊后,我們總是需要在加入跟蹤模塊獲得目標軌跡。因此一個完善的稀疏動態感知框架應該同時具備端到端跟蹤能力。
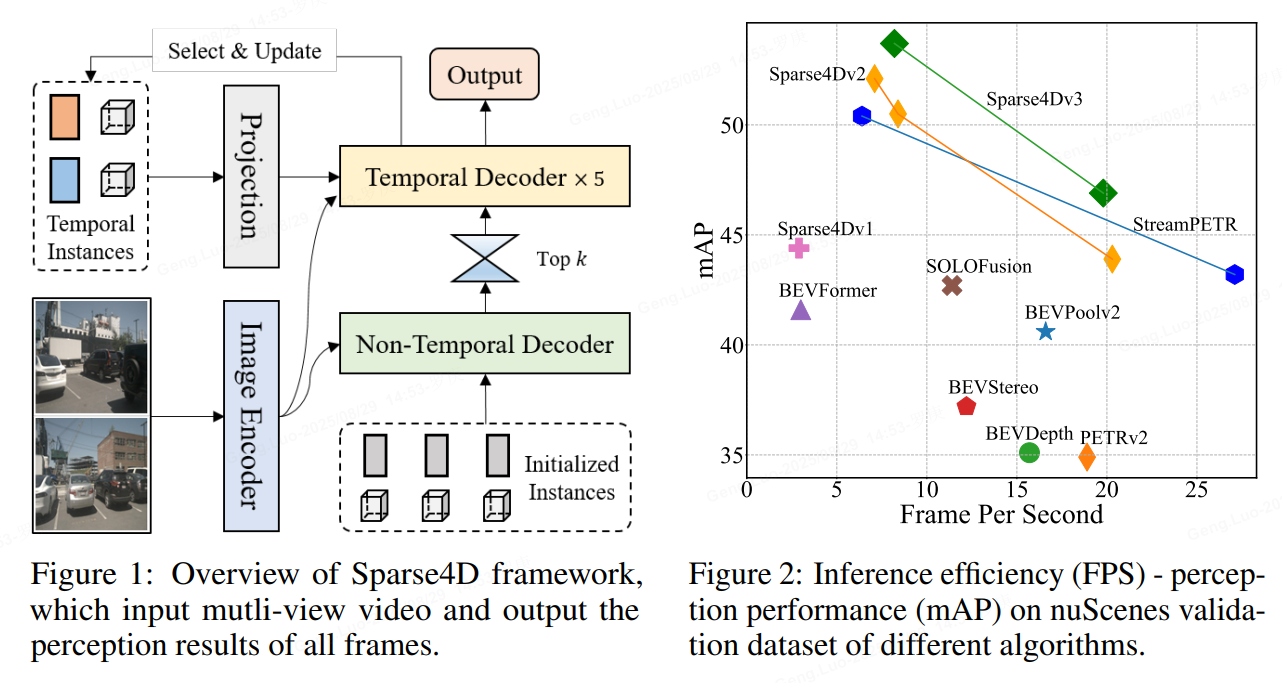
methods
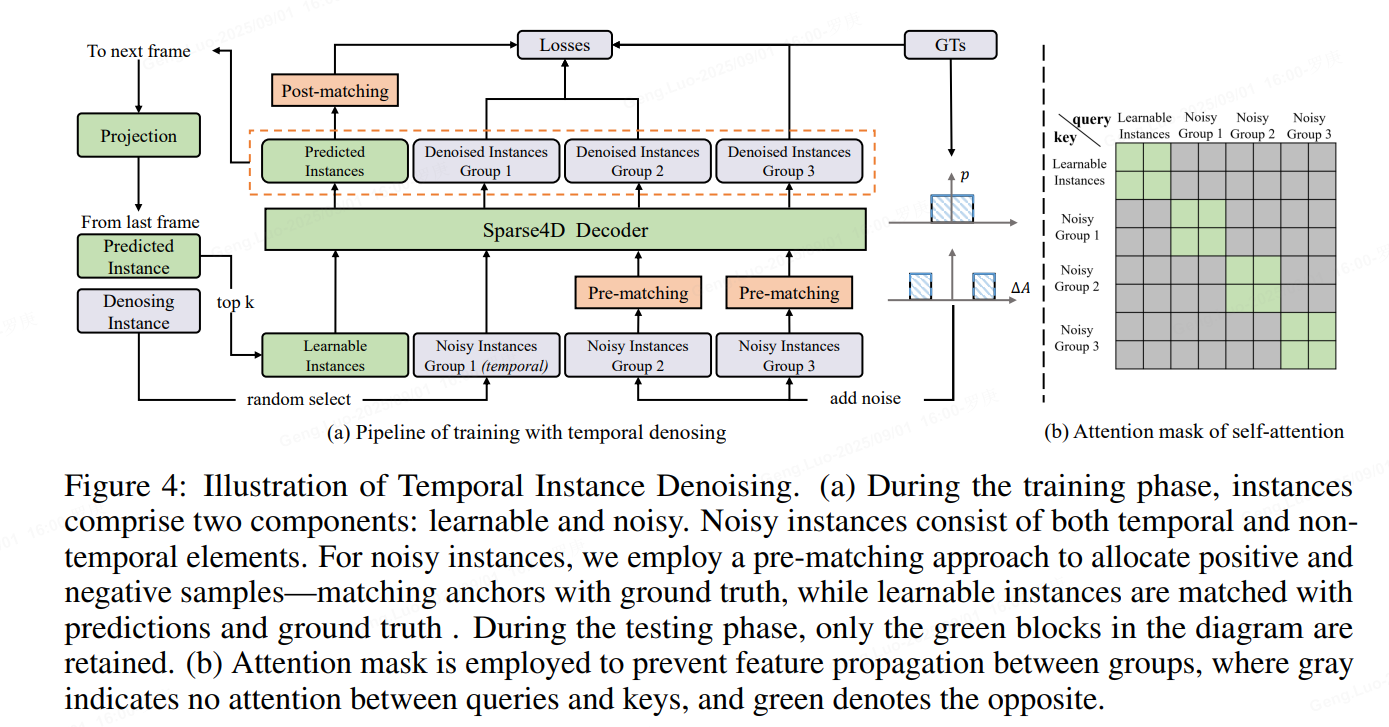
1、Temporal Instance Denoising
在訓練過程中,初始化了兩組錨點。
一組包括均勻分布在檢測空間中的錨點,使用 k 均值方法初始化,這些錨點作為可學習參數。
另一組錨點是通過向地面實況 (GT) 添加噪聲生成的,如公式如下所示,專門為 3D 檢測任務量身定制。對GT加上小規模噪聲來生成noisy instance,用decoder來進行去噪,這樣可以較好的控制instance和gt之間的偏差范圍,decoder 層之間匹配關系穩定,讓訓練更加魯棒,且大幅增加正樣本的數量,讓模型收斂更充分,以得到更好的結果。具體來說,我們設置兩個分布來生產噪聲Delat_A,用于模擬產生正樣本和負樣本,對于3D檢測任務加噪公式如下
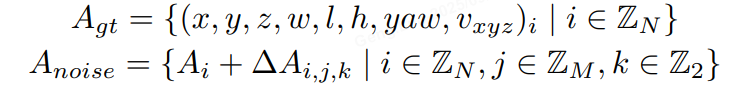
加上噪聲的GT框需要重新和原始GT進行one2one匹配,確定正負樣本,而并不是直接將加了較大擾動的GT作為負樣本,這可以緩解一部分的分配歧義性。噪聲GT需要轉為instance的形式以輸入進網絡中,首先噪聲GT可以直接作為anchor,把噪聲GT編碼成高維特征作為anchor embed,相應的instance feature直接以全0來初始化。
為了模擬時序特征傳遞的過程,讓時序模型能得到denoisy任務更多的收益,將單幀denosing拓展為時序的形式。具體地,在每個訓練step,隨機選擇部分noisy-instance組,將這些instance通過ego pose和velocity投影到當前幀,投影方式與learnable instance一致。
具體實現中,我們設置了5組noisy-instance,每組最大gt數量限制為32,因此會增加5322=320個額外的instance。時序部分,每次隨機選擇2組來投影到下一幀。每組instance使用attention mask完全隔開,與DINO中的實現不一樣的是,我們讓noisy-instance也無法和learnable instance進行特征交互.
2、Quality Estimation
Sparse4D輸出的分類置信度并不適合用來判斷框的準確程度,這主要是因為one2one 匈牙利匹配過程中,正樣本離GT并不能保證一定比負樣本更近,而且正樣本的分類loss并不隨著匹配距離而改變。而對比dense head,如CenterPoint或BEV3D,其分類label為heatmap,隨著離gt距離增大,loss weight會發生變化。
因此,除了一個正負樣本的分類置信度以外,還需要一個描述模型結果與GT匹配程度的置信度,也就是進行Quality Estimation。對于3D檢測來說,我們定義了兩個quality指標,centerness和yawness:
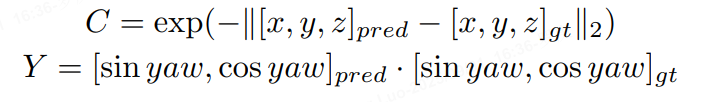
qt = qt.flatten(end_dim=1)[mask] #[n,2]
cns = qt[..., 0]
yns = qt[..., 1].sigmoid()
cns_target = torch.norm(reg_target[..., :3] - reg[..., :3], p=2, dim=-1)
cns_target = torch.exp(-cns_target)
cns_loss = self.loss_cns(cns, cns_target, avg_factor=num_pos)
output[f"loss_cns_{decoder_idx}"] = cns_loss
yns_target = (torch.nn.functional.cosine_similarity(reg_target[..., 6:8],reg[..., 6:8],dim=-1,) > 0
)
yns_target = yns_target.float()
yns_loss = self.loss_yns(yns, yns_target)
output[f"loss_yns_{decoder_idx}"] = yns_loss
對于centerness和yawness,我們分別用cross entropy loss和focal loss來進行訓練
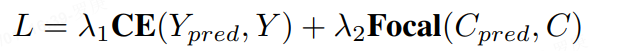
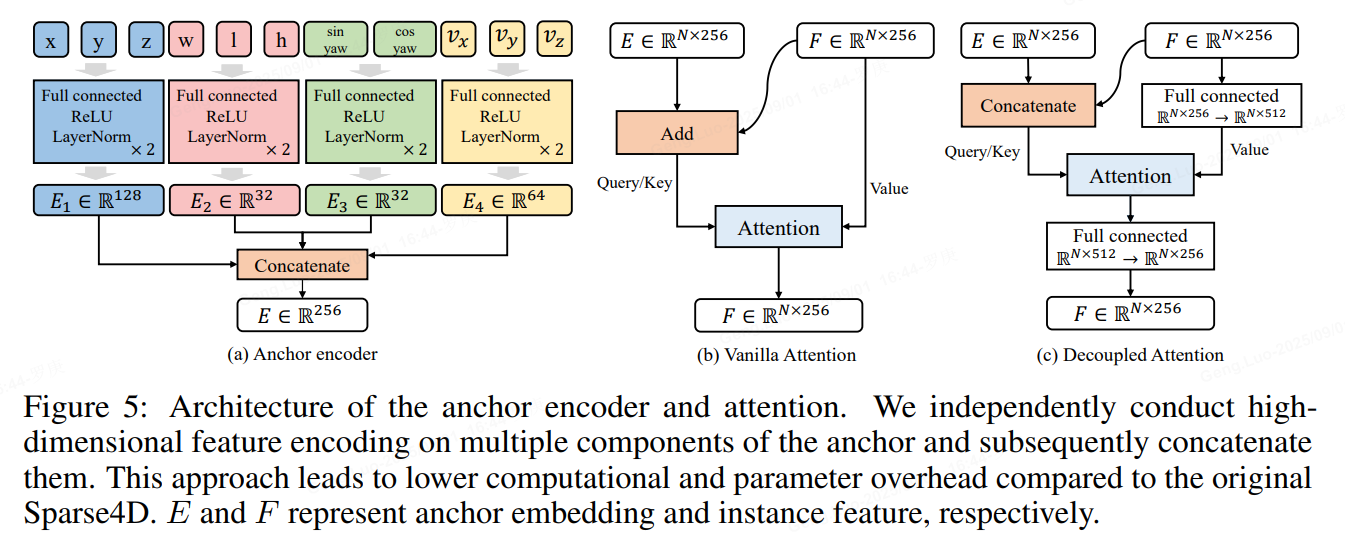
3、Decoupled Attention
Sparse4D中有兩個instance attention模塊,1)instance self-attention和2)temporal instance cross-attention。在這兩個attention模塊中,將instance feature和anchor embed相加作為query與key,在計算attention weights時一定程度上會存在特征混淆的問題,如圖下所示。

為了解決這問題,作者對attention模塊進行了簡單的改進,將所有特征相加操作換成了拼接,提出了decoupled atttention module,結構如下圖所示
def forward(self, box_3d: torch.Tensor) -> torch.Tensor:pos_feat = self.pos_fc(box_3d[..., 0:3])size_feat = self.size_fc(box_3d[..., 3:6])yaw_feat = self.yaw_fc(box_3d[..., 6:8])if self.vel_dims > 0:vel_feat = self.vel_fc(box_3d[..., 8 : 8 + self.vel_dims])output = self.cat.cat([pos_feat, size_feat, yaw_feat, vel_feat], dim=-1)else:output = self.cat.cat([pos_feat, size_feat, yaw_feat], dim=-1)return output4、Extend to Tracking
無需額外訓練策略的端到端多目標跟蹤能力。由于Sparse4D已經實現了目標檢測的端到端(無需dense-to-sparse的解碼),進一步考慮將端到端往檢測的下游任務進行拓展,即多目標跟蹤。發現當Sparse4D經過充分檢測任務的訓練之后,instance在時序上已經具備了目標一致性了,即同一個instance始終檢測同一個目標。因此,無需對訓練流程進行任何修改,只需要在infercence階段對instance進行ID assign即可,infer pipeline如下所示。

對比如MOTR、TransTrack、TrackFormer等一系列端到端跟蹤算法,實現方式具有以下兩點不同: 1)訓練階段,無需進行任何tracking的約束;2)Temporal instance不需要卡高閾值,大部分temporal instance不表示一個歷史幀的檢測目標。
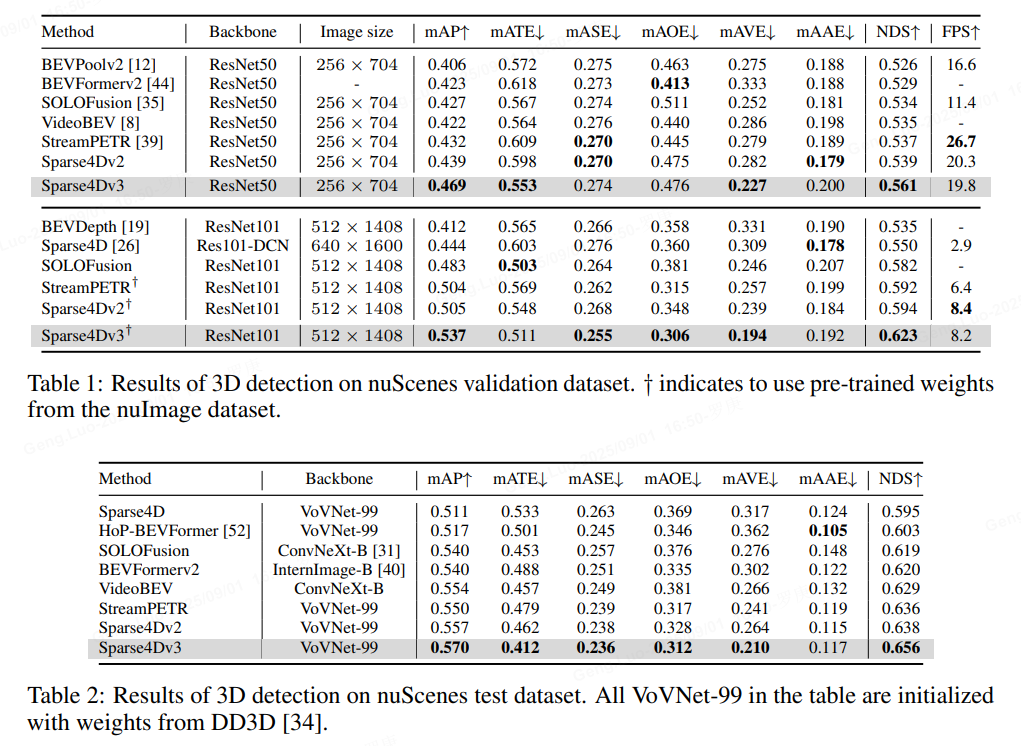
experiments
作者的總結與展望
總的來說,在長時序稀疏化3D 目標檢測的一路探索中,主要有如下的收獲:
顯式的稀疏實例表示方式: 將待檢測的instance 表示為3D anchor 和 instance feature,并不斷進行迭代更新來獲得檢測結果是一種簡潔、有效的方式。同時,這種方式也更容易進行時序的運動補償;
高效的Deformable Aggregation 算子:提出了針對多視角/多尺度圖像特征 + 多關鍵點的層級化特征采樣與融合策略,并進行了大幅的效率優化,能高效獲得高質量的特征表示。同時在稀疏化的形式下,decoder 部分的計算量和計算延時受輸入圖像分辨率的影響不大,能更好處理高分辨率輸入;
Recurrent 的時序稀疏融合框架:基于稀疏實例的時序recurrent 融合框架,使得時序模型基本上具備與單幀模型相同的推理速度,同時在幀間只需要占用少量的帶寬(比起bev 的時序方案)。這樣輕量且有效的時序方案很適合在真實的車端場景處理多攝視頻流數據。
端到端多目標跟蹤:在無需對訓練階段進行任何修改的情況下,實現了從多視角視頻到目標軌跡的端到端感知,進一步減小對后處理的依賴,算法結構和推理流程非常簡潔;
卓越的感知性能:在稀疏感知框架下進行了一系列性能優化,在不增加推理計算量的前提下,讓Sparse4D在檢測和跟蹤任務上都取得了SOTA的水平。
基于稀疏范式的感知算法仍然有很多未解決的問題,也具有很大的發展空間。首先,如何將Sparse的框架應用到更廣泛的感知任務上是下一步需要探索的,例如道路元素的感知任務(HD map construction、 topology等)、預測規控任務(trajectory prediction、end-to-end planning等);其次,需要對稀疏感知算法進行更充足的驗證,保證其具備量產能力,例如遠距離檢測效果、相機內外參泛化能力及多模態融合感知性能等。作者希望Sparse4D(v3)可以作為稀疏感知方向新的baseline,推動該領域的進步。
就是好好好!
【完結】

)










)






