1 一道算法題引發的思考及其實現
1.1 算法題
- 問:如何充分利用多核 CPU 的性能,快速對一個2千萬大小的數組進行排序?
- 這道題可以通過歸并排序來解決;
1.2 什么是歸并排序?
-
歸并排序(Merge Sort)是基于分治思想的排序算法,基本思想是把一個大數組分成兩個等大的子數組,對每個子數組分別排序,再將排好序的兩個子數組合并成一個有序大數組,常通過遞歸實現,步驟為分(拆分數組為子數組)、治(子數組排序)、合(合并有序子數組)。它的時間復雜度是 (O(n\log n)),空間復雜度是 (O(n))((n) 為數組長度)。
-
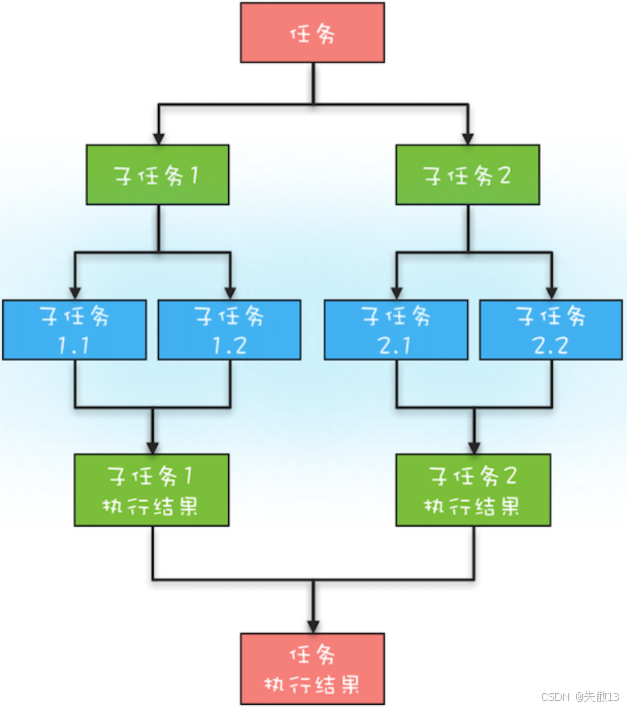
分治思想是把規模為 (N) 的問題分解成 (K) 個規模更小、相互獨立且與原問題性質相同的子問題,解決子問題后,合并子問題的解得到原問題的解。步驟分為分解(拆分原問題為子問題)、求解(子問題足夠小時用簡單方法解決)、合并(合并子問題的解得到原問題解)。像歸并排序、快速排序、二分查找這些計算機經典算法都基于分治思想。分治任務模型圖:
-
動圖演示:Comparison Sorting Visualization。
1.3 使用歸并排序解決算法題
1.3.1 單線程實現歸并排序
-
單線程歸并算法的實現,它的基本思路是將序列分成兩個部分,分別進行遞歸排序,然后將排序好的子序列合并起來;
public class MergeSort {private final int[] arrayToSort; // 待排序的原始數組private final int threshold; // 遞歸拆分的最小閾值,當子數組長度小于此值時將直接使用Arrays.sort()排序/*** 構造函數,初始化待排序數組和閾值* @param arrayToSort 待排序數組* @param threshold 拆分閾值*/public MergeSort(final int[] arrayToSort, final int threshold) {this.arrayToSort = arrayToSort;this.threshold = threshold;}/*** 對類內數組進行順序歸并排序的入口方法* @return 排序后的數組*/public int[] sequentialSort() {return sequentialSort(arrayToSort, threshold);}/*** 靜態方法:遞歸實現歸并排序* @param arrayToSort 待排序數組* @param threshold 拆分閾值* @return 排序后的數組*/public static int[] sequentialSort(final int[] arrayToSort, int threshold) {// 如果當前數組長度小于閾值,則直接使用JDK內置排序(通常是快速排序優化)if (arrayToSort.length < threshold) {Arrays.sort(arrayToSort);return arrayToSort;}// 計算中點,拆分數組為左右兩部分int midpoint = arrayToSort.length / 2;int[] leftArray = Arrays.copyOfRange(arrayToSort, 0, midpoint); // 左半部分 [0, midpoint)int[] rightArray = Arrays.copyOfRange(arrayToSort, midpoint, arrayToSort.length); // 右半部分 [midpoint, end)// 遞歸排序左右子數組leftArray = sequentialSort(leftArray, threshold);rightArray = sequentialSort(rightArray, threshold);// 合并兩個已排序的子數組return merge(leftArray, rightArray);}/*** 合并兩個已排序的數組* @param leftArray 已排序的左數組* @param rightArray 已排序的右數組* @return 合并后的有序數組*/public static int[] merge(final int[] leftArray, final int[] rightArray) {// 創建合并后的數組,長度為兩數組之和int[] mergedArray = new int[leftArray.length + rightArray.length];int mergedArrayPos = 0; // 合并數組的當前位置int leftArrayPos = 0; // 左數組的當前指針int rightArrayPos = 0; // 右數組的當前指針// 同時遍歷左右數組,按升序選擇較小的元素放入合并數組while (leftArrayPos < leftArray.length && rightArrayPos < rightArray.length) {if (leftArray[leftArrayPos] <= rightArray[rightArrayPos]) {mergedArray[mergedArrayPos] = leftArray[leftArrayPos];leftArrayPos++;} else {mergedArray[mergedArrayPos] = rightArray[rightArrayPos];rightArrayPos++;}mergedArrayPos++;}// 如果左數組還有剩余元素,全部追加到合并數組while (leftArrayPos < leftArray.length) {mergedArray[mergedArrayPos] = leftArray[leftArrayPos];leftArrayPos++;mergedArrayPos++;}// 如果右數組還有剩余元素,全部追加到合并數組while (rightArrayPos < rightArray.length) {mergedArray[mergedArrayPos] = rightArray[rightArrayPos];rightArrayPos++;mergedArrayPos++;}return mergedArray;} }
1.3.2 Fork/Join實現并行歸并排序
-
并行歸并排序是一種利用多線程實現的歸并排序算法。它的基本思路是將數據分成若干部分,然后在不同線程上對這些部分進行歸并排序,最后將排好序的部分合并成有序數組。在多核 CPU 上,這種算法也能夠有效提高排序速度;
-
可以使用 Java 的 Fork/Join 框架來實現歸并排序的并行化:
public class MergeSortTask extends RecursiveAction {private final int threshold; // 任務拆分的最小閾值,當子數組長度小于等于此值時將直接進行排序private int[] arrayToSort; // 當前任務需要排序的數組/*** 構造函數,初始化待排序數組和閾值* @param arrayToSort 待排序數組* @param threshold 拆分閾值*/public MergeSortTask(final int[] arrayToSort, final int threshold) {this.arrayToSort = arrayToSort;this.threshold = threshold;}/*** Fork/Join框架的核心方法,實現任務的分解與執行*/@Overrideprotected void compute() {// 如果數組長度小于等于閾值,直接進行排序(基準情況)if (arrayToSort.length <= threshold) {Arrays.sort(arrayToSort); // 使用JDK優化排序算法return;}// 計算中點,將數組拆分為左右兩個子數組int midpoint = arrayToSort.length / 2;int[] leftArray = Arrays.copyOfRange(arrayToSort, 0, midpoint); // 左半部分 [0, midpoint)int[] rightArray = Arrays.copyOfRange(arrayToSort, midpoint, arrayToSort.length); // 右半部分 [midpoint, end)// 創建左右子任務MergeSortTask leftTask = new MergeSortTask(leftArray, threshold);MergeSortTask rightTask = new MergeSortTask(rightArray, threshold);// 將左右任務提交到Fork/Join線程池異步執行(fork操作)leftTask.fork(); // 將左任務提交到工作隊列,由其他工作線程執行rightTask.fork(); // 將右任務提交到工作隊列,由其他工作線程執行// 等待左右子任務執行完成(join操作)leftTask.join(); // 阻塞當前線程直到左任務完成rightTask.join(); // 阻塞當前線程直到右任務完成// 合并兩個已排序的子數組結果arrayToSort = MergeSort.merge(leftTask.getSortedArray(), rightTask.getSortedArray());}/*** 獲取排序后的數組* @return 排序完成的數組*/public int[] getSortedArray() {return arrayToSort;} } -
在這個示例中,使用 Fork/Join 框架實現了歸并排序算法,并通過遞歸調用實現了并行化;
-
使用 Fork/Join 框架實現歸并排序算法的關鍵在于將排序任務分解成小的任務,使用 Fork/Join 框架將這些小任務提交給線程池中的不同線程并行執行,并在最后將排序后的結果進行合并。這樣可以充分利用多核CPU的并行處理能力,提高程序的執行效率。
1.3.3 測試結果對比
-
測試代碼:
public class Utils {/*** 生成指定大小的隨機整數數組* @param size 數組的大小* @return 包含隨機整數的數組*/public static int[] buildRandomIntArray(final int size) {int[] arrayToCalculateSumOf = new int[size];Random generator = new Random();// 生成0-100,000,000范圍內的隨機整數填充數組for (int i = 0; i < arrayToCalculateSumOf.length; i++) {arrayToCalculateSumOf[i] = generator.nextInt(100000000);}return arrayToCalculateSumOf;} }public class ArrayToSortMain {public static void main(String[] args) {// 生成包含2000萬個隨機整數的測試數組int[] arrayToSortByMergeSort = Utils.buildRandomIntArray(20000000);// 創建數組副本,確保兩種排序方法使用相同的數據進行公平比較int[] arrayToSortByForkJoin = Arrays.copyOf(arrayToSortByMergeSort, arrayToSortByMergeSort.length);// 獲取當前系統的處理器核心數,用于優化并行計算int processors = Runtime.getRuntime().availableProcessors();// 創建單線程歸并排序實例,使用處理器數量作為拆分閾值MergeSort mergeSort = new MergeSort(arrayToSortByMergeSort, processors);long startTime = System.nanoTime(); // 記錄開始時間(納秒級精度)// 執行單線程歸并排序mergeSort.mergeSort();long duration = System.nanoTime()-startTime; // 計算耗時// 將納秒轉換為毫秒并輸出結果System.out.println("單線程歸并排序時間: "+(duration/(1000f*1000f))+"毫秒");// 創建Fork/Join并行排序任務,同樣使用處理器數量作為閾值MergeSortTask mergeSortTask = new MergeSortTask(arrayToSortByForkJoin, processors);// 構建Fork/Join線程池,線程數設置為處理器核心數ForkJoinPool forkJoinPool = new ForkJoinPool(processors);startTime = System.nanoTime(); // 重新記錄開始時間// 在線程池中執行并行排序任務(invoke會阻塞直到任務完成)forkJoinPool.invoke(mergeSortTask);duration = System.nanoTime()-startTime; // 計算并行排序耗時// 輸出并行排序時間System.out.println("fork/join排序時間: "+(duration/(1000f*1000f))+"毫秒");} } -
測試結果:數組越大,利用 Fork/Join 框架實現的并行化歸并排序比單線程歸并排序的效率更高

1.4 并行實現歸并排序的優化和注意事項
-
在實際應用里,為充分利用多核CPU,同時保障算法的正確性與效率,得考量數據分布均勻性、內存使用、線程切換開銷等因素;
-
具體而言:
-
任務大小:它的選擇會影響并行算法的效率與負載均衡。任務太小,任務劃分和合并的開銷就會過大;任務太大,又難以充分利用多核 CPU 的并行處理能力。所以要結合數據量、CPU 核心數等,選合適的任務大小;
-
負載均衡:并行算法得保證各線程執行的任務大小和時間盡可能相等,不然有的線程會負載過重,有的則過輕。歸并排序可通過遞歸調用來實現負載均衡,但遞歸層數不能太深,否則會增加線程創建和合并的開銷;
-
數據分布:數據分布均勻與否會影響并行算法效率和負載均衡。若數據分布不均,會出現有的線程處理數據量過大,有的過小的情況。實際應用要考慮數據分布,盡量把數據分成大小相等的子數組;
-
內存使用:處理大規模數據時,內存使用情況對算法執行效率至關重要。歸并排序可通過原地歸并節約內存,但要注意歸并的實現方式,避免數據覆蓋和不穩定排序等問題;
-
線程切換:線程切換是并行算法的一大開銷,要盡量減少切換次數以提升效率。歸并排序可通過設置線程池大小和調整任務大小來控制線程數量和切換開銷,實現最優性能。
-
2 Fork/Join框架
2.1 簡介
-
Fork/Join 是一個支持分治任務模型的并行計算框架,其中:
- Fork:對應分治任務模型里的任務分解,就是把一個大任務拆分成許多小任務;
- Join:對應結果合并,即等小任務并行執行完后,將它們的結果合并成一個大結果;
-
它適用于可采用分治策略的計算密集型任務,像大規模數組排序、圖形渲染、復雜算法求解等場景;
-
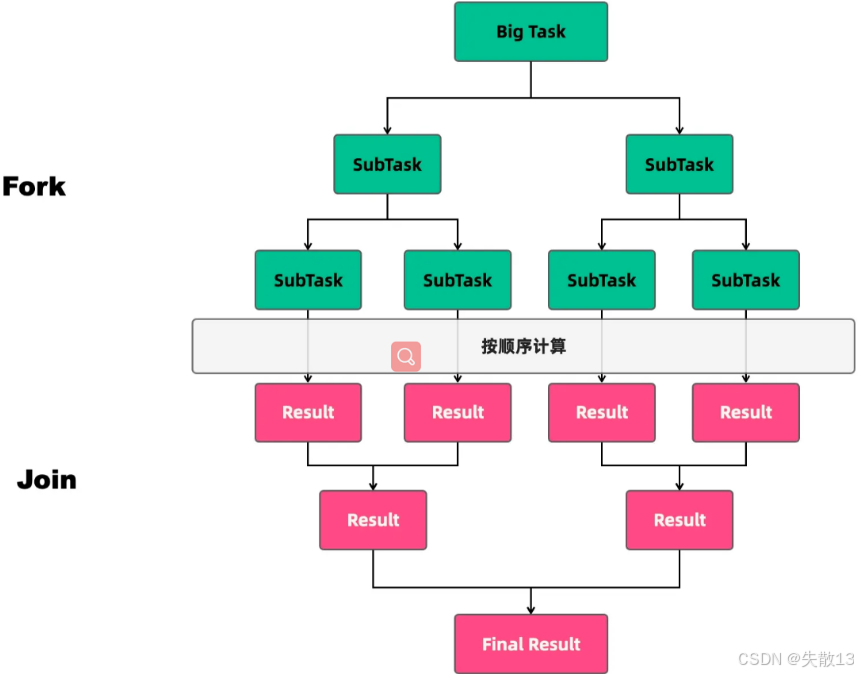
下圖清晰展示了其工作流程:大任務(Big Task)先通過 Fork 不斷分解為更小的子任務(SubTask),子任務按順序計算得到各自結果(Result),之后通過 Join 逐步合并這些結果,最終得到大任務的最終結果(Final Result);
2.2 應用場景
- 并行計算:能便捷執行大規模計算任務,把大任務分解為小任務,借助工作竊取算法并行執行,充分利用多核處理器優勢,提升計算效率;
- 遞歸任務處理:適合遞歸式的任務分解與執行,可遞歸地將大任務拆成諸多小任務,再通過工作竊取算法動態分配給工作線程執行;
- 并行流操作:Java 8 引入的 Stream API 用于集合的函數式編程操作,
ForkJoinPool常用來執行并行流操作里的并行計算部分,比如對元素進行過濾、映射、聚合等; - 高性能任務執行:提供高性能的任務執行機制,通過動態調度任務和管理線程池,有效利用系統資源,在多核處理器上實現任務并行執行。
2.3 使用
- Fork/Join 框架的主要組成部分是 ForkJoinPool、ForkJoinTask;
- ForkJoinPool 是一個線程池,它用于管理 Fork/Join 中任務的執行;
- ForkJoinTask 是一個抽象類,用于表示可以被分割成更小部分的任務。
2.3.1 ForkJoinPool
- ForkJoinPool 是 Fork/Join 框架中的線程池類,它用于管理 Fork/Join 任務的線程;
- ForkJoinPool 類包括一些重要的方法,例如
submit()、invoke()、shutdown()、awaitTermination()等,用于提交任務、執行任務、關閉線程池和等待任務的執行結果; - ForkJoinPool 類中還包括一些參數,例如線程池的大小、工作線程的優先級、任務隊列的容量等,可以根據具體的應用場景進行設置。
2.3.2 構造器
-
ForkJoinPool有四個核心參數,用于控制線程池的并行數、工作線程創建、異常處理和模式指定:-
int parallelism:指定并行級別(parallelism level),ForkJoinPool會據此決定工作線程數量。若未設置,會用Runtime.getRuntime().availableProcessors()獲取可用處理器數量來設置并行級別; -
ForkJoinWorkerThreadFactory factory:ForkJoinPool創建線程時,通過該工廠創建。需實現ForkJoinWorkerThreadFactory接口,若不指定,由默認的DefaultForkJoinWorkerThreadFactory負責線程創建; -
UncaughtExceptionHandler handler:指定異常處理器,當任務運行出錯時,由該處理器處理異常; -
boolean asyncMode:設置隊列工作模式。asyncMode為true時,使用先進先出隊列;為false時,使用后進先出模式;
-
-
代碼示例:
// 獲取處理器數量 int processors = Runtime.getRuntime().availableProcessors(); // 構建forkjoin線程池,用獲取到的處理器數量作為并行級別參數 ForkJoinPool forkJoinPool = new ForkJoinPool(processors);
2.3.3 任務提交方式
| 返回值 | 方法 | |
|---|---|---|
| 提交異步執行 | void | execute(ForkJoinTask)<?> task):提交一個ForkJoinTask類型的任務進行異步執行execute(Runnable task):提交一個 Runnable類型的任務進行異步執行 |
| 等待并獲取結果 | T | invoke(ForkJoinTask task):提交ForkJoinTask類型的任務,等待任務執行完畢后獲取結果 |
| 提交執行獲取Future結果 | ForkJoinTask | submit(ForkJoinTask task):提交ForkJoinTask類型的任務,返回對應的 ForkJoinTask submit(Callable task):提交 Callable類型的任務(Callable 有返回值),返回對應的ForkJoinTasksubmit(Runnable task):提交 Runnable類型的任務(Runnable 無返回值),返回對應的ForkJoinTasksubmit(Runnable task, T result):提交 Runnable類型的任務,同時指定一個結果,返回對應的ForkJoinTask |
2.3.4 調用方法
-
ForkJoinTask 最核心的是
fork()方法和join()方法,承載著主要的任務協調作用,一個用于任務提交,一個用于結果獲取; -
fork():用于向當前任務所運行的線程池中提交任務。如果當前線程是 ForkJoinWorkerThread 類型,將會放入該線程的工作隊列,否則放入 common 線程池的工作隊列中;在 Fork/Join 框架中,“該線程的工作隊列”指的是當前執行任務的
ForkJoinWorkerThread所擁有的工作隊列:ForkJoinWorkerThread是ForkJoinPool中用于執行任務的工作線程。每個ForkJoinWorkerThread內部都維護了一個雙端隊列(Deque),這個隊列就是“該線程的工作隊列”;- 當通過
fork()方法提交任務時,如果當前線程是ForkJoinWorkerThread類型,任務會被放入當前ForkJoinWorkerThread自己的雙端隊列中,后續該線程會從自己的隊列里取出任務執行; - 這樣的設計是為了配合“工作竊取(Work - Stealing)”算法:當一個線程的隊列中沒有任務時,它可以去其他線程的隊列中“竊取”任務來執行,從而提高線程的利用率和整體并行效率;
-
join():用于獲取任務的執行結果。調用join()時,將阻塞當前線程直到對應的子任務完成運行并返回結果。
2.3.5 處理遞歸任務
-
比如計算斐波那契數列:
public class Fibonacci extends RecursiveTask<Integer> {final int n; // 要計算斐波那契數列的第n項Fibonacci(int n) {this.n = n;}/*** 重寫RecursiveTask的compute()方法,實現斐波那契數列的遞歸計算* @return 斐波那契數列的第n項值*/protected Integer compute() {// 基準情況:斐波那契數列的前兩項直接返回if (n <= 1)return n;// 創建計算F(n-1)的子任務Fibonacci f1 = new Fibonacci(n - 1);// 將子任務提交到ForkJoinPool異步執行(fork操作)f1.fork();// 創建計算F(n-2)的子任務,并在當前線程同步執行Fibonacci f2 = new Fibonacci(n - 2);// 合并結果:F(n) = F(n-1) + F(n-2)return f2.compute() + f1.join(); // f2.compute()同步計算,f1.join()等待異步任務完成}public static void main(String[] args) {// 構建forkjoin線程池(使用默認并行級別,通常是處理器核心數)ForkJoinPool pool = new ForkJoinPool();// 創建計算斐波那契數列第10項的任務Fibonacci task = new Fibonacci(10);// 提交任務到線程池并阻塞等待執行完成,返回最終結果int result = pool.invoke(task);System.out.println(result); // 輸出結果:55} }繼承RecursiveTask:表示這是一個有返回值的遞歸任務,返回Integer類型結果
斐波那契數列定義:F(0)=0,F(1)=1,F(n)=F(n?1)+F(n?2)F(0)=0, F(1)=1, F(n)=F(n-1)+F(n-2)F(0)=0,F(1)=1,F(n)=F(n?1)+F(n?2)
任務分解策略:
- 將F(n)F(n)F(n)分解為F(n?1)F(n-1)F(n?1)和F(n?2)F(n-2)F(n?2)兩個子問題
- F(n?1)F(n-1)F(n?1)通過
fork()異步執行 - F(n?2)F(n-2)F(n?2)通過
compute()在當前線程同步執行
結果合并:使用
f1.join()等待異步任務完成,然后與同步計算結果相加Fork/Join工作流程:
fork():將任務推入工作隊列,供其他工作線程竊取執行join():阻塞當前線程直到任務完成并返回結果
性能問題:這種實現方式存在大量重復計算,時間復雜度為O(2n)O(2^n)O(2n),實際應用中應使用動態規劃等優化方法
線程池使用:
pool.invoke(task)同步提交任務并等待結果,適合計算密集型遞歸任務 -
如果 n 為100000,執行上面的代碼會發生什么問題?在上面的例子中,由于遞歸計算 Fibonacci 數列的任務數量呈指數級增長,當 n 較大時,就容易出現 StackOverflowError 錯誤。這個錯誤通常發生在遞歸過程中,由于遞歸過程中每次調用函數都會在棧中創建一個新的棧幀,當遞歸深度過大時,棧空間就會被耗盡,導致 StackOverflowError 錯誤;
-
那么如何解決棧溢出呢?可以使用迭代的方式計算 Fibonacci 數列,以避免遞歸過程中占用大量的棧空間。示例代碼:
public class Fibonacci {public static void main(String[] args) {int n = 100000; // 要計算斐波那契數列的第100000項// 創建數組用于存儲斐波那契數列值,長度為n+1(包含0到n項)long[] fib = new long[n + 1];// 初始化斐波那契數列的前兩項fib[0] = 0; // 第0項為0fib[1] = 1; // 第1項為1// 使用動態規劃(自底向上)方法計算斐波那契數列for (int i = 2; i <= n; i++) {// 遞推公式:F(n) = F(n-1) + F(n-2)fib[i] = fib[i - 1] + fib[i - 2];}// 輸出斐波那契數列的第100000項System.out.println(fib[n]);} } -
對于一些遞歸深度較大的任務,使用 Fork/Join 框架可能會出現任務調度和內存消耗的問題;
- 當遞歸深度較大時,會產生大量的子任務,這些子任務可能被調度到不同的線程中執行,而線程的創建和銷毀以及任務調度的開銷都會占用大量的資源,從而導致性能下降;
- 此外,對于遞歸深度較大的任務,由于每個子任務所占用的棧空間較大,可能會導致內存消耗過大,從而引起內存溢出的問題;
- 因此,在使用 Fork/Join 框架處理遞歸任務時,需要根據實際情況來評估遞歸深度和任務粒度,以避免任務調度和內存消耗的問題。如果遞歸深度較大,可以嘗試采用其他方法來優化算法,如使用迭代方式替代遞歸,或者限制遞歸深度來減少任務數量,以避免 Fork/Join 框架的缺點。
2.3.6 處理阻塞任務
-
在 ForkJoinPool 中使用阻塞型任務時需要注意以下幾點:
- 防止線程饑餓:
- 當一個線程在執行一個阻塞型任務時,它將會一直等待任務完成,這時如果沒有其他線程可以竊取任務,那么該線程將一直被阻塞,直到任務完成為止;
- 為了避免這種情況,應該避免在 ForkJoinPool 中提交大量的阻塞型任務;
- 使用特定的線程池:
- 為了最大程度地利用 ForkJoinPool 的性能,可以使用專門的線程池來處理阻塞型任務,這些線程不會被 ForkJoinPool 的竊取機制所影響;
- 例如,可以使用 ThreadPoolExecutor 來創建一個線程池,然后將這個線程池作為 ForkJoinPool 的執行器,這樣就可以使用 ThreadPoolExecutor 來處理阻塞型任務,而使用 ForkJoinPool 來處理非阻塞型任務;
- 不要阻塞工作線程:
- 如果在 ForkJoinPool 中使用阻塞型任務,那么需要確保這些任務不會阻塞工作線程,否則會導致整個線程池的性能下降;
- 為了避免這種情況,可以將阻塞型任務提交到一個專門的線程池中,或者使用 CompletableFuture 等異步編程工具來處理阻塞型任務;
- 防止線程饑餓:
-
下面是一個使用阻塞型任務的例子,這個例子展示了如何使用 CompletableFuture 來處理阻塞型任務:
public class BlockingTaskDemo {public static void main(String[] args) {// 構建一個forkjoin線程池(使用默認配置,通常為核心數)ForkJoinPool pool = new ForkJoinPool();// 創建一個異步任務,使用CompletableFuture并將其提交到ForkJoinPool中執行CompletableFuture<String> future = CompletableFuture.supplyAsync(() -> {try {// 模擬一個耗時的任務(阻塞5秒鐘)TimeUnit.SECONDS.sleep(5);return "Hello, world!"; // 任務完成后的返回值} catch (InterruptedException e) {e.printStackTrace();return null; // 發生中斷異常時返回null}}, pool); // 指定使用ForkJoinPool作為執行器try {// 阻塞等待任務完成,并獲取結果(get()方法會阻塞當前線程直到任務完成)String result = future.get();System.out.println(result); // 輸出結果:"Hello, world!"} catch (InterruptedException e) {// 處理線程中斷異常e.printStackTrace();} catch (ExecutionException e) {// 處理任務執行過程中拋出的異常e.printStackTrace();} finally {// 關閉ForkJoinPool,釋放線程資源(優雅關閉,等待已提交任務完成)pool.shutdown();}} }- 在這個例子中,使用了 CompletableFuture 來處理阻塞型任務,因為它可以避免阻塞 ForkJoinPool 中的工作線程;
- 另外,我們也可以使用專門的線程池來處理阻塞型任務,例如 ThreadPoolExecutor 等。不管是哪種方式,都需要避免在 ForkJoinPool 中提交大量的阻塞型任務,以免影響整個線程池的性能。
2.4 ForkJoinPool 工作原理
2.4.1 原理概述
-
當通過 ForkJoinPool 的
invoke()或submit()方法提交任務時,ForkJoinPool 會依據路由規則將任務提交到某個任務隊列。若任務執行過程中創建子任務,子任務會被提交到工作線程對應的任務隊列; -
若工作線程對應的任務隊列空了,ForkJoinPool 支持任務竊取機制,空閑的工作線程可“竊取”其他工作任務隊列里的任務,確保所有工作線程都能有效利用,不閑置;
-
核心設計
-
ForkJoinPool 內部存儲有 WorkQueue 數組,提交給它的任務會被分配到指定的 WorkQueue 上執行;
-
每個 WorkQueue 內部維護一個 ForkJoinTask 數組來存儲待執行任務,還配有一個獨立的 ForkJoinWorkerThread 來真正執行任務;

-
2.4.2 工作線程 ForkJoinWorkerThread
-
ForkJoinWorkerThread 是 ForkJoinPool 里專門執行任務的線程。創建它時,會自動向 ForkJoinPool 注冊一個 WorkQueue,這個 WorkQueue 是該線程專屬的任務存儲隊列,且只能出現在
workqueues[]的奇數位; -
ForkJoinWorkerThread 工作線程啟動后,會掃描并 “竊取” 任務執行。另外,當它在
ForkJoinTask#join()等待返回結果時,若被 ForkJoinPool 線程池發現其任務隊列為空,或者當前任務已執行完畢,也會通過工作竊取算法從其他任務隊列獲取任務,分配到自己的任務隊列中執行;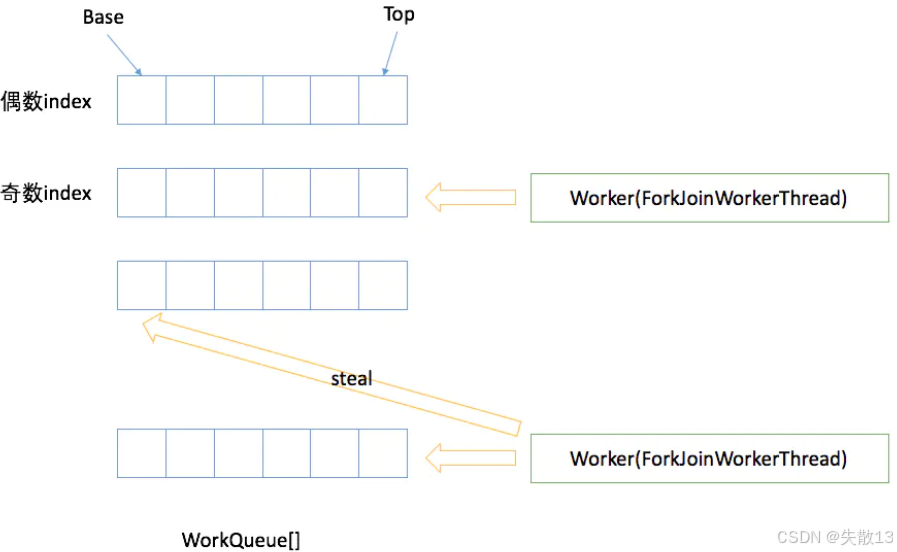
2.4.3 工作隊列 WorkQueue
-
WorkQueue 一個是雙端隊列,用于存儲工作線程自己的任務。每個工作線程都維護一個本地 WorkQueue,優先執行本地隊列中的任務。當本地隊列任務執行完,工作線程會嘗試從其他線程的 WorkQueue 中竊取任務;
-
WorkQueue 任務隊列分兩種類型:一種是外部提交任務所用隊列,在任務隊列數組中數組下標為偶數;另一種是工作線程私有的任務隊列,存儲大任務
fork分解出的任務,在任務隊列數組中數組下標為奇數; -
下圖展示了 WorkQueue 的操作,如
externalSubmit(task)外部提交任務、subtask(fork)子任務提交,還有push、pop等操作,以及根據async是true還是false,分別對應FIFO_QUEUE(先進先出隊列)和LIFO_QUEUE(后進先出隊列)的工作模式;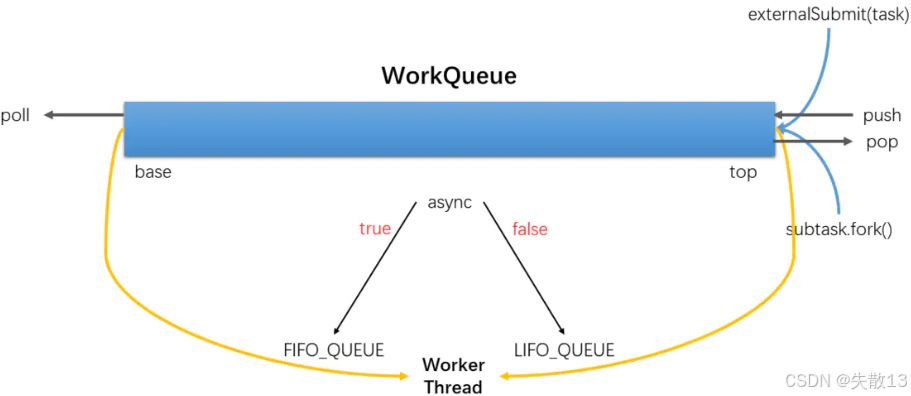
2.4.4 工作竊取機制
-
ForkJoinPool 和 ThreadPoolExecutor 有很大不同,ForkJoinPool 引入了工作竊取設計,這是其性能保障的關鍵之一;
-
工作竊取指的是允許空閑線程從繁忙線程的雙端隊列中竊取任務。默認情況下,工作線程從自己雙端隊列的頭部獲取任務;當自己的任務為空時,線程會從其他繁忙線程雙端隊列的尾部獲取任務,這種方式能最大限度減少線程競爭任務的可能性;
-
下圖展示了主線程提交任務到 ForkJoinPool 后,任務被推入工作隊列(workQueue),
ForkJoinWorkerThread - 1和ForkJoinWorkerThread - 2不僅會處理自身隊列中的任務(如通過fork分解任務),當自身任務不足時,還會通過“steal 工作竊取”從其他工作隊列獲取任務;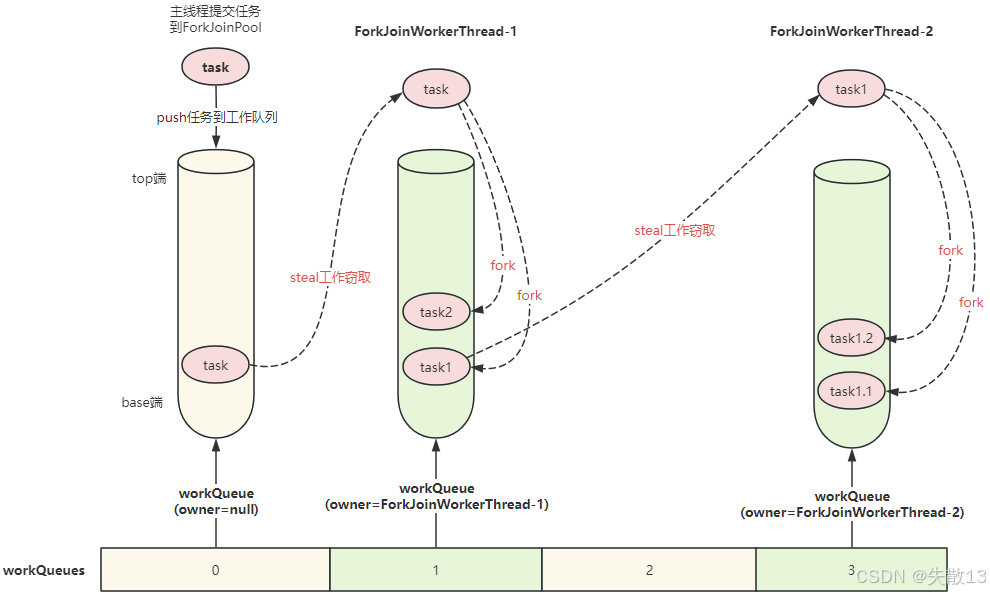
-
通過工作竊取,Fork/Join 框架能實現任務的自動負載均衡,充分利用多核 CPU 的計算能力,同時避免線程饑餓和延遲問題;
-
如果想了解更多關于 ForkJoinPool 的內容,可以參考Doug Lea 的論文。
2.5 ForkJoinPool 執行流程
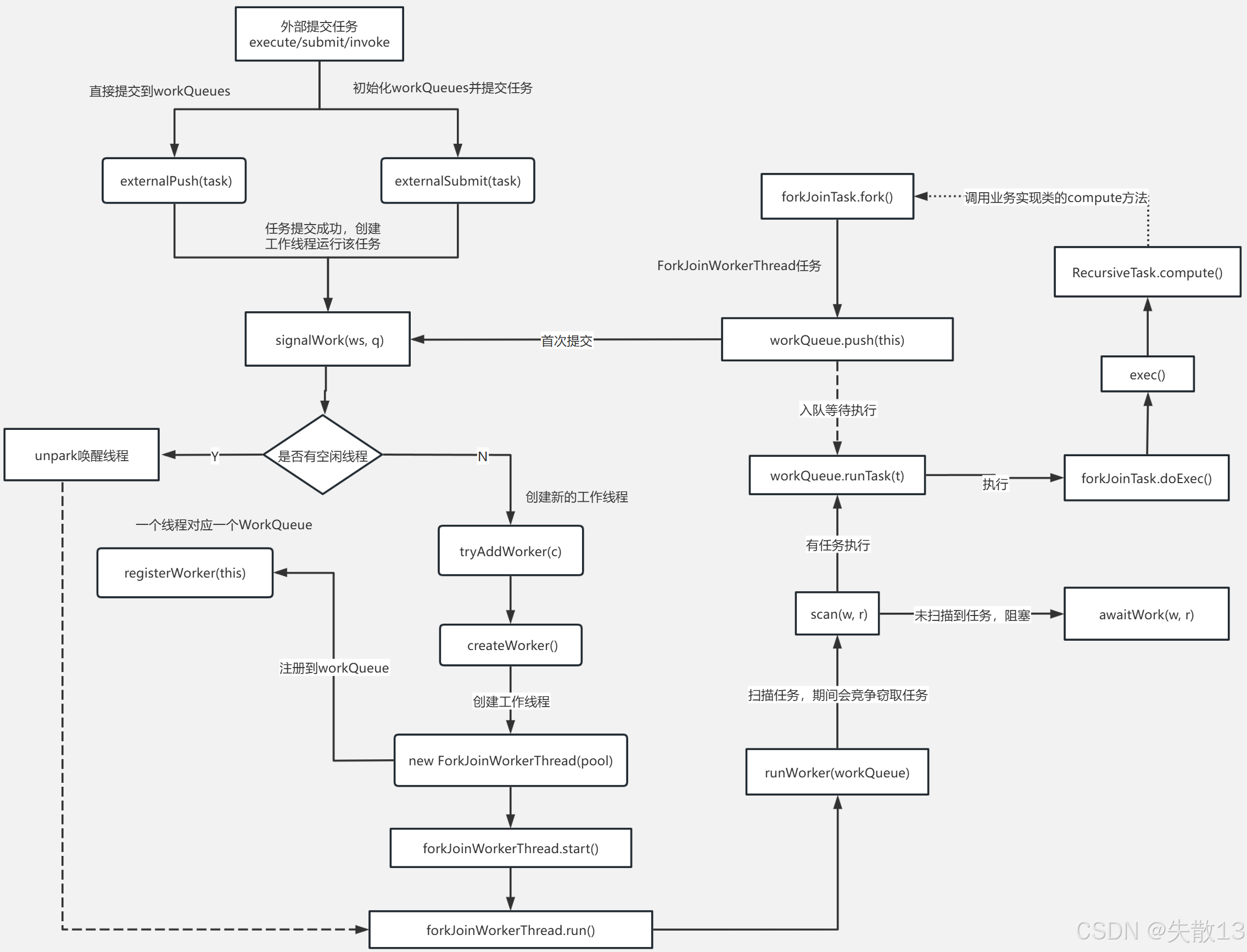
-
應用程序外部向Fork/Join框架提交任務(通過
execute/submit/invoke)。此時有兩種處理路徑:-
路徑1:直接提交到workQueues。調用
externalPush(task),將任務直接放入工作隊列(workQueues)。若提交成功,會觸發signalWork(w, q),嘗試用工作線程執行任務; -
路徑2:初始化workQueues并提交任務。調用
externalSubmit(task),先初始化工作隊列,再將任務提交到隊列,后續邏輯與“路徑1”類似,最終也會觸發signalWork(w, q);
-
-
signalWork(w, q)執行后,會判斷是否有空閑線程:-
有空閑線程(Y分支):直接從空閑線程中選一個,執行任務(進入下面的任務執行階段);
-
無空閑線程(N分支):需要創建新的工作線程,流程如下:
tryAddWorker(c):嘗試添加新工作線程createWorker():創建工作線程實例new ForkJoinWorkerThread(pool):實例化ForkJoinWorkerThread;forkJoinWorkerThread.start():啟動工作線程,觸發線程的run()方法forkJoinWorkerThread.run():線程啟動后,執行run()方法,此時會先執行registerWorker(this),將新線程注冊到workQueues,完成線程與隊列的綁定;
-
-
工作線程就緒后,進入任務執行的核心邏輯:
-
任務入隊等待執行。若任務是通過
ForkJoinTask.fork()提交的,會調用workQueue.push(this),將任務放入隊列等待執行; -
工作線程執行任務。調用
workQueue.runTask(),從隊列中取出任務執行。執行時調用forkJoinTask.doExec(),而doExec()最終會觸發任務的核心邏輯:- 若任務是
RecursiveTask(有返回值的分治任務),會調用RecursiveTask.compute()(用戶自定義的“任務拆分與計算邏輯”就在這里實現); - 執行的入口也可通過
exec()方法觸發,最終導向compute();
- 若任務是
-
任務掃描與等待
-
若當前隊列“有任務執行”,則持續執行;
-
若“未掃描到任務”,則調用
scan(w, r)掃描其他隊列的任務(Fork/Join的工作竊取(Work-Stealing)機制:空閑線程會從其他線程的隊列“偷”任務執行,提升資源利用率); -
若掃描后仍無任務,調用
awaitWork(w, r)讓線程進入“等待任務”狀態;
-
-
持續運行工作線程。整個執行過程由
runWorker(workQueue)驅動,持續從隊列中獲取并執行任務。
-
2.6總結
-
Fork/Join是基于分治思想(把大任務拆成小任務,并行執行后合并結果)的編程模型,適合計算密集型任務(大量CPU運算的場景),效率提升源于兩點:
-
任務切分:將大任務拆成更小的子任務,讓更多線程同時參與計算,充分利用多核CPU的并行能力;
-
任務竊取:空閑的線程會“竊取”其他線程隊列中未執行的任務,減少線程閑置,同時降低線程間的競爭(因為每個線程優先處理自己隊列的任務,竊取是“補充性”的);
-
-
使用
ForkJoinPool(Fork/Join框架的線程池)時,要關注任務類型:-
最適合的是純函數計算型任務:任務不依賴外部狀態、不修改共享變量(無副作用),這樣并行執行時更安全,不會因“狀態不一致”出問題;
-
若要處理阻塞型任務(如I/O操作、等待鎖),需謹慎評估:雖然
ForkJoinPool能處理,但會導致線程被長時間占用(阻塞),破壞“任務竊取”的高效性,增加線程管理成本;
-
-
普通線程池(如
ThreadPoolExecutor)更適合IO密集型(如網絡請求、文件讀寫)或“短小任務”,而Fork/Join針對大規模并行計算,核心區別有四點:-
工作竊取算法:
ForkJoinPool:線程空閑時,會從其他線程的任務隊列中“偷取”任務執行,最大化線程利用率;- 普通線程池:任務存在公共隊列,線程直接從公共隊列取任務,無“竊取”邏輯,空閑線程只能等新任務入隊;
-
任務的分解與合并:
ForkJoinPool:支持分治——大任務拆成小任務并行執行,最終合并小任務結果得到大任務結果;- 普通線程池:任務是“獨立的”,不支持“自動拆分-合并”,需手動處理任務依賴和結果聚合;
-
工作線程的數量:
ForkJoinPool:會自動根據CPU核心數設置工作線程數量,避免線程過多(減少上下文切換開銷),最大化CPU性能;- 普通線程池:需手動指定線程數,若設置不合理(如線程過多導致切換頻繁,或過少導致CPU閑置),會影響性能;
-
任務類型適配:
ForkJoinPool:適合大規模并行計算任務(如大數據排序、矩陣運算);- 普通線程池:適合短小的、IO密集型任務(如Web服務器處理請求、數據庫操作)。
-

)
)







)
:運行x86Demo示例)



![[光學原理與應用-353]:ZEMAX - 設置 - 可視化工具:2D視圖、3D視圖、實體模型三者的區別,以及如何設置光線的數量](http://pic.xiahunao.cn/[光學原理與應用-353]:ZEMAX - 設置 - 可視化工具:2D視圖、3D視圖、實體模型三者的區別,以及如何設置光線的數量)



