目錄
一、關聯式容器
二、鍵值對
三、set
四、set的構造
五、set的iterator
六、set的Operations
七、multiset
一、關聯式容器
序列式容器 :?
- ?在初階階段,我們已經接觸過STL中的部分容器,比如:vector、list、deque、forward_list(C++11)等
- 底層為線性序列的數據結構,里面存儲的是元素本身
關式容器聯 :?
- 也是用來存儲數據的,與序列式容器不同的是,其里面存儲的是<key, value>結構的鍵值對,在數據檢索時比序列式容器效率更高
二、鍵值對
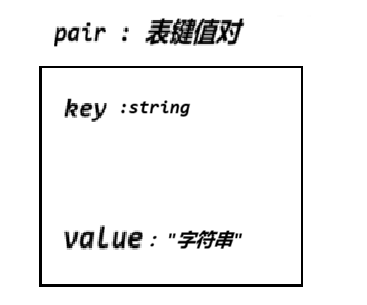
鍵值對 :?用來表示具有一一對應關系的一種結構,該結構中一般只包含兩個成員變量key和value,key代表鍵值,value表示與key對應的信息

使用場景 :
現在要建立一個英漢互譯的字典,那該字典中必然有英文單詞與其對應的中文含義,而且,英文單詞與其中文含義是一一對應的關系,即通過該應該單詞,在詞典中就可以找到與其對應的中文含義
pair的結構
template<class T1,class T2>
struct pair
{
typedef T1 first_type;
typedef T2 second_type;
T1 first;
T2 second;pair()
:first(T1())
,second(T2())
{}pair(const T1& a,const T2& b)
:first(a)
,second(b)
{}
};三、set

- T: set中存放元素的類型,實際在底層存儲<value, value>的鍵值對
- Compare:set中元素默認按照小于來比較
- Alloc:set中元素空間的管理方式,使用STL提供的空間配置器管理
在使用set中,set相當于只存一個值,在set中,元素的value也標識它(value就是key,類型為T),并且每個value必須是唯一的,且set是按照一定次序存儲元素的容器
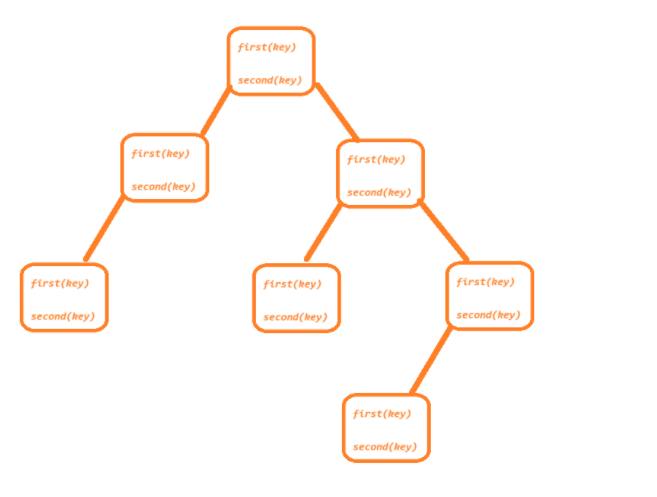
在內部,set中的元素總是按照其內部比較對象(類型比較)所指示的特定嚴格弱排序準則進行排序,set中的元素按一定次序排序,且元素唯一,元素不能在set中被修改 (元素總是const) ,只能被插入或刪除 ,set在底層是用二叉搜索樹(紅黑樹)實現的
注意記憶的點:
- set中只放value,但在底層實際存放的是由<value, value>構成的鍵值對
- set中插入元素時,只需要插入value即可,不需要構造鍵值對pair
- ?set中的元素不可以重復(因此可以使用set進行去重)
- 使用set的迭代器遍歷set中的元素,可以得到有序序列
- set中的元素默認按照小于來比較
- set中查找某個元素,時間復雜度為:log2(N)
四、set的構造
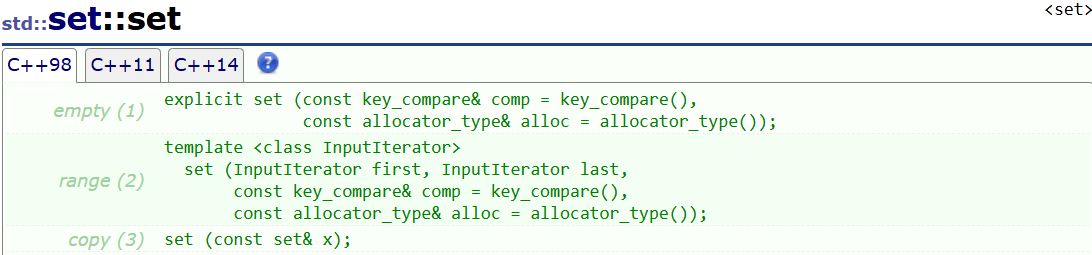
- empty : set的無參的構造?
- range :使用一段迭代器區間構造
- copy :拷貝構造?
operator=

#include <iostream>
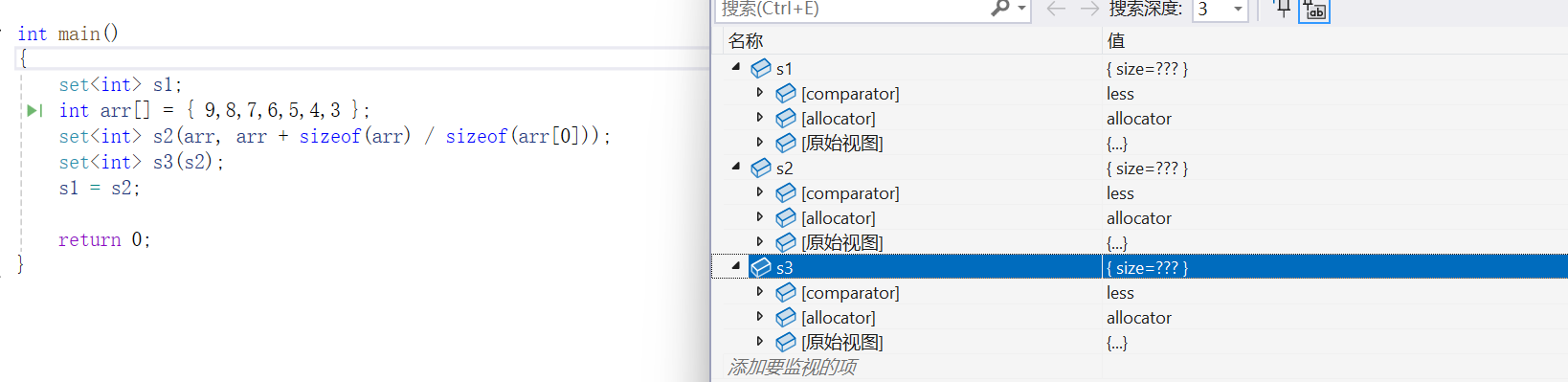
#include <set>using namespace std;int main()
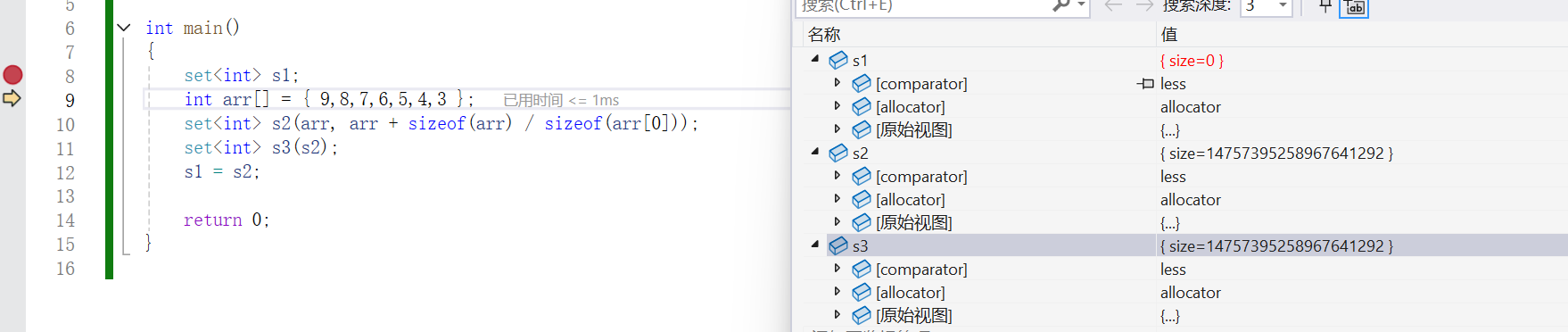
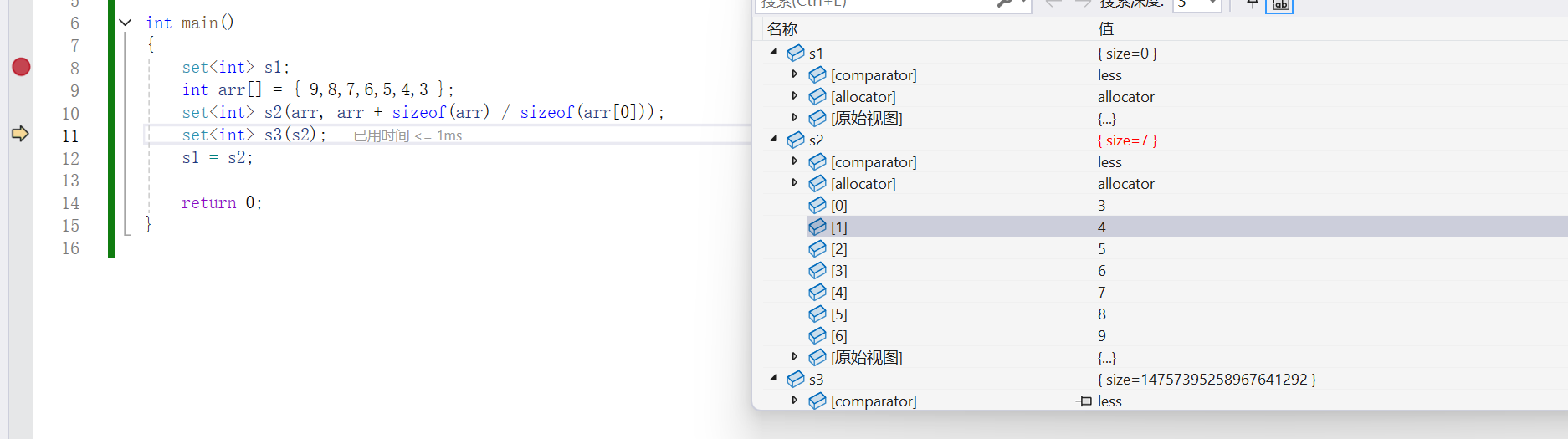
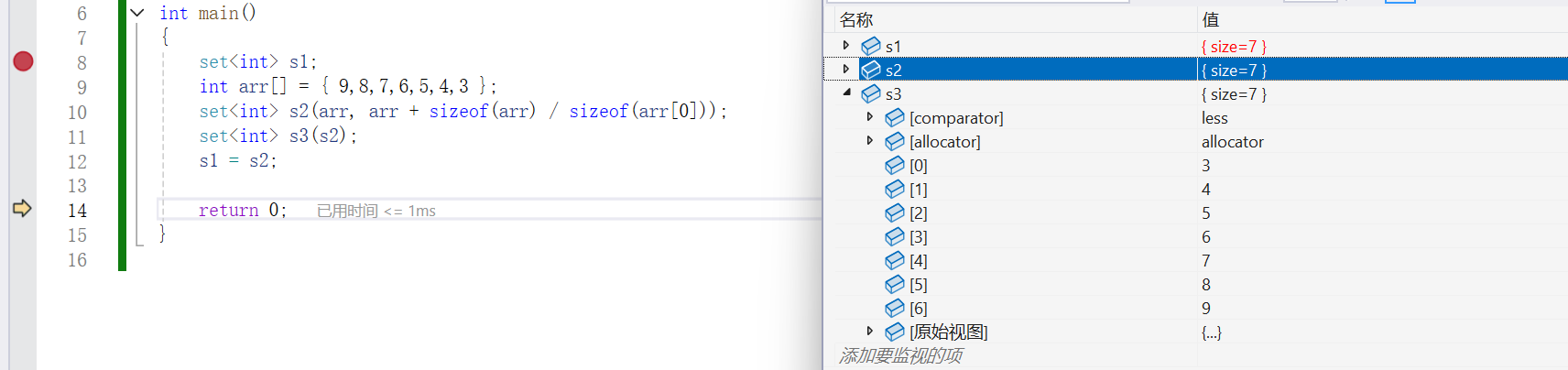
{set<int> s1;int arr[] = { 9,8,7,6,5,4,3 };set<int> s2(arr, arr + sizeof(arr) / sizeof(arr[0]));set<int> s3(s2);s1 = s2;return 0;
}
五、set的iterator

- 返回第一個元素的iterator

- 返回最后一個元素的iterator
#include <iostream>
#include <set>
using namespace std;
int main()
{int arr[] = { 9,8,7,6,5,4,3 };set<int> s2(arr, arr + sizeof(arr) / sizeof(arr[0]));set<int>::iterator it = s2.begin();set<int>::iterator it1 = s2.end();while (it != it1){cout << *it << " ";it++;}return 0;
}


- 判斷set是否為空

- 返回set的元素個數

- single element : 插入一個key(val)返回一個鍵值對pair,在pair中第一個數據first是插入位置的迭代器,第二個位置是->是否插入成功,set中的key值不能重復且只能有一個,如果key值已經有了,那么返回的是原key位置的迭代器以及false,如果key值沒有,那么返回的是新插入key位置的迭代器以及true,由于return不能返回兩個值,所以如果想返回多個值,必須放在一個結構中進行返回,這里是放在了鍵值對pair中進行返回
- with hint :?在一個迭代器位置插入一個key(val),傳入的這個iterator 位置對于編譯器來說只是一個建議位置,實際插入數據還是根據其原有的二叉搜索樹的邏輯 (有序) 進行插入
- range : 是插入一段迭代器區間
#include <iostream>
#include <set>
using namespace std;
int main()
{int arr[] = { 9,8,7,6,5,4,3 };set<int> s2;s2.insert(arr, arr + sizeof(arr) / sizeof(arr[0]));set<int>::iterator it=s2.insert(s2.begin(), 2);cout << *it << endl;pair<set<int>::iterator, bool> pa = s2.insert(9);cout << *(pa.first) << " "<<pa.second << endl;return 0;
}

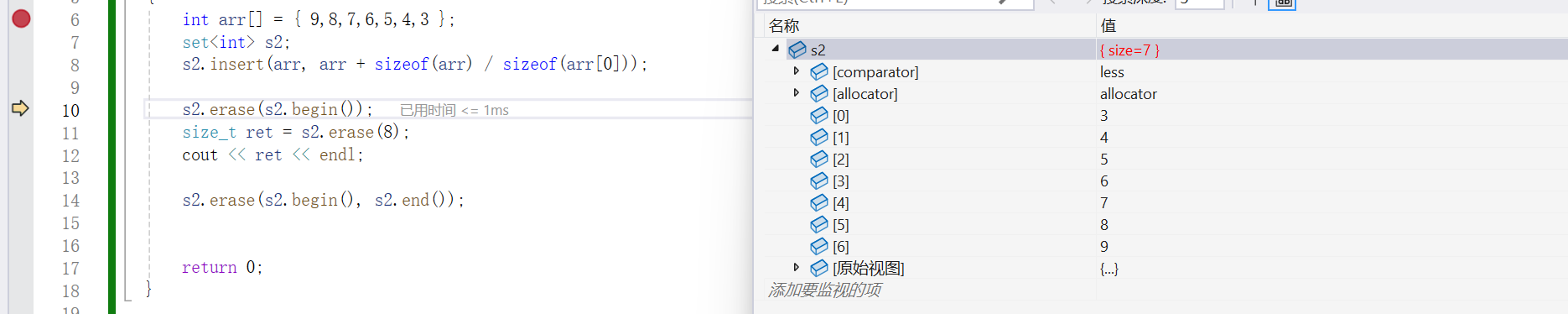
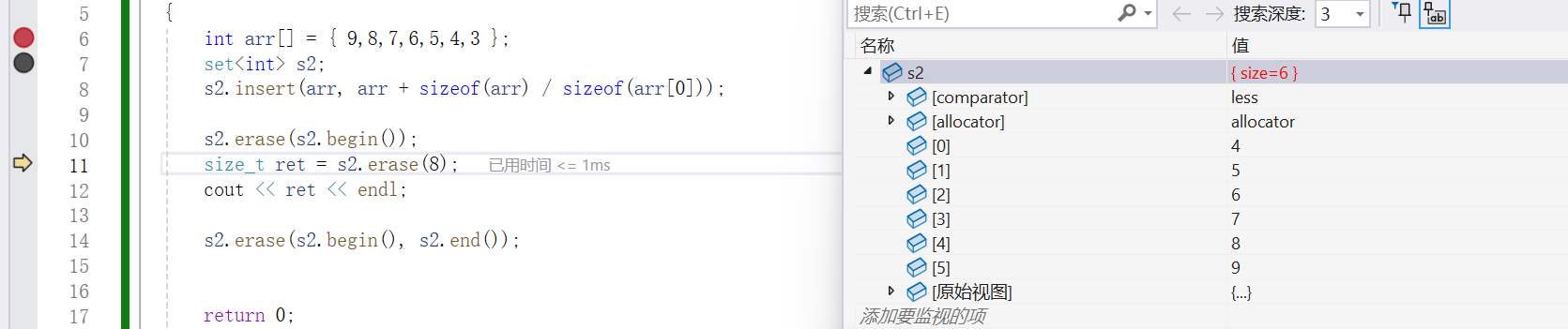
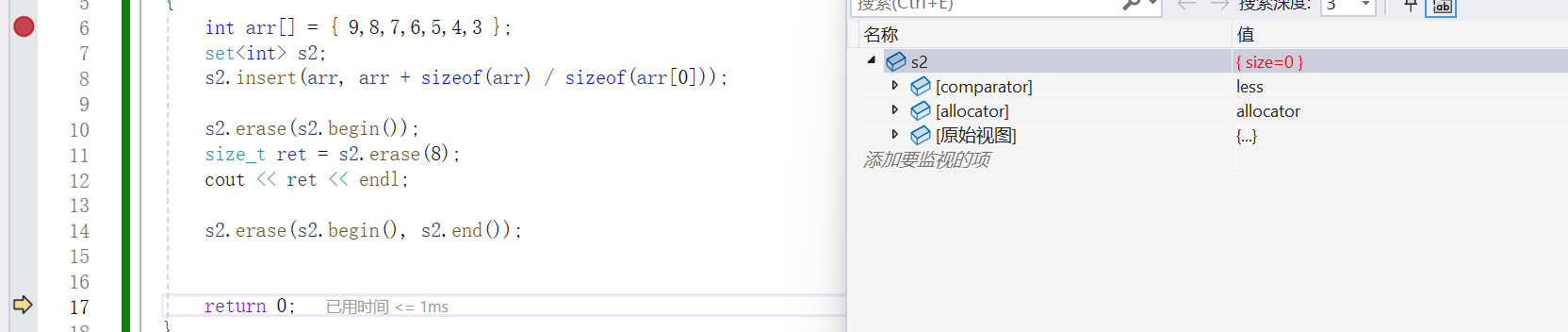
- void erase : 刪除某個 iterator?
- size_ t erase :?刪除某個key值,返回值是刪除的這個key值的個數 , 返回的個數這是為了后面的 multiset 做準備,因為multiset可以允許有多個相同的key值,而set和mulitset的關聯性很大,所以為了接口的統一性將這里的刪除值為key的erase的操作的返回值設置為了返回刪除key值的個數,在set中當有這個key值的 時候刪除對應的節點成功返回1,當沒有這個key值的時候刪除對應節點失敗返回 0
- void erase :?刪除一段迭代器區間
#include <iostream>
#include <set>
using namespace std;
int main()
{int arr[] = { 9,8,7,6,5,4,3 };set<int> s2;s2.insert(arr, arr + sizeof(arr) / sizeof(arr[0]));s2.erase(s2.begin());size_t ret = s2.erase(8);cout << ret << endl;s2.erase(s2.begin(), s2.end());return 0;
}


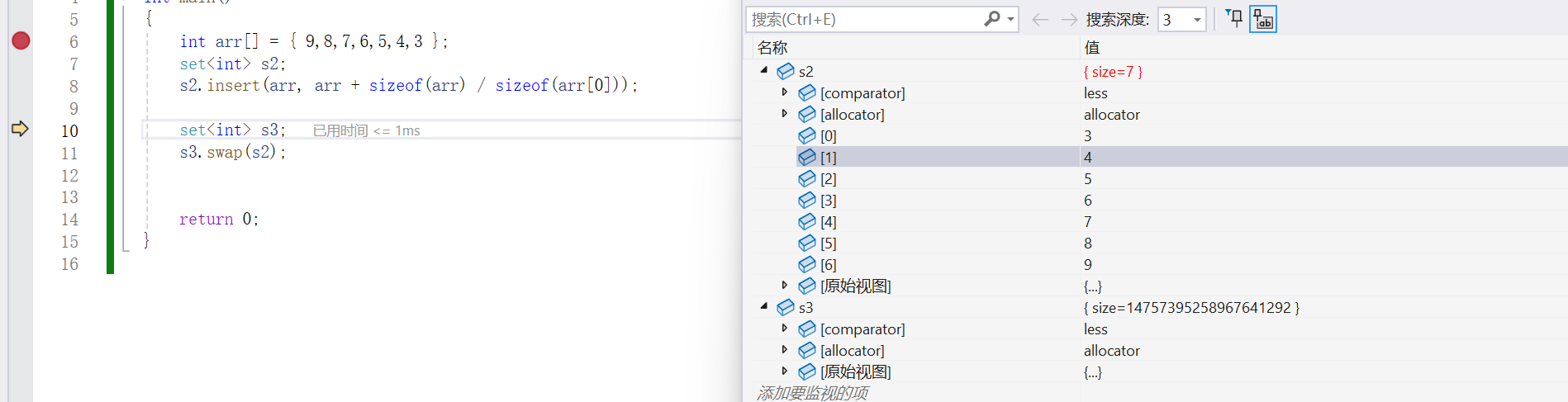
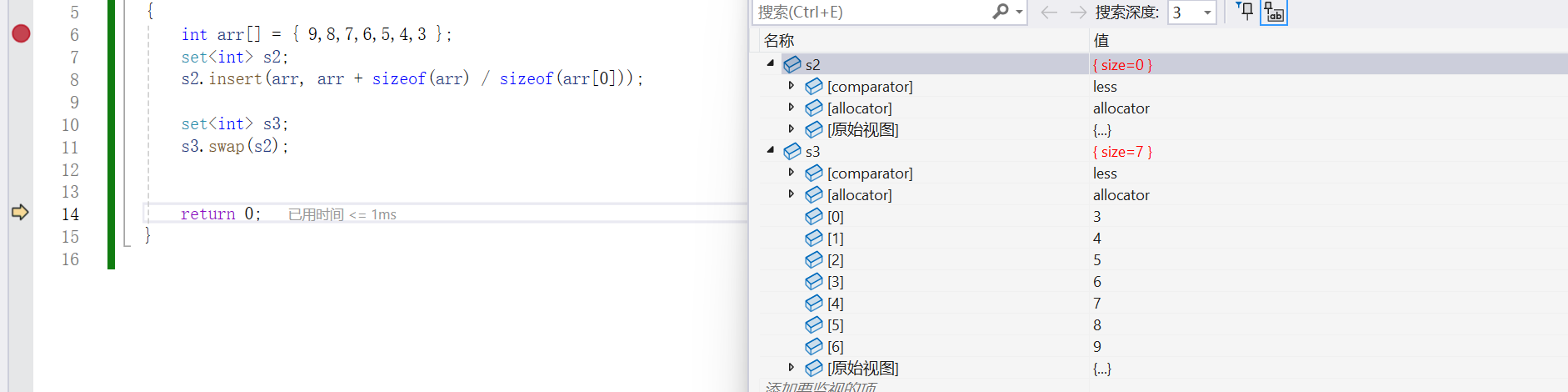
- swap是交換兩個set對象的數據
#include <iostream>
#include <set>
using namespace std;
int main()
{int arr[] = { 9,8,7,6,5,4,3 };set<int> s2;s2.insert(arr, arr + sizeof(arr) / sizeof(arr[0]));set<int> s3;s3.swap(s2);return 0;
}

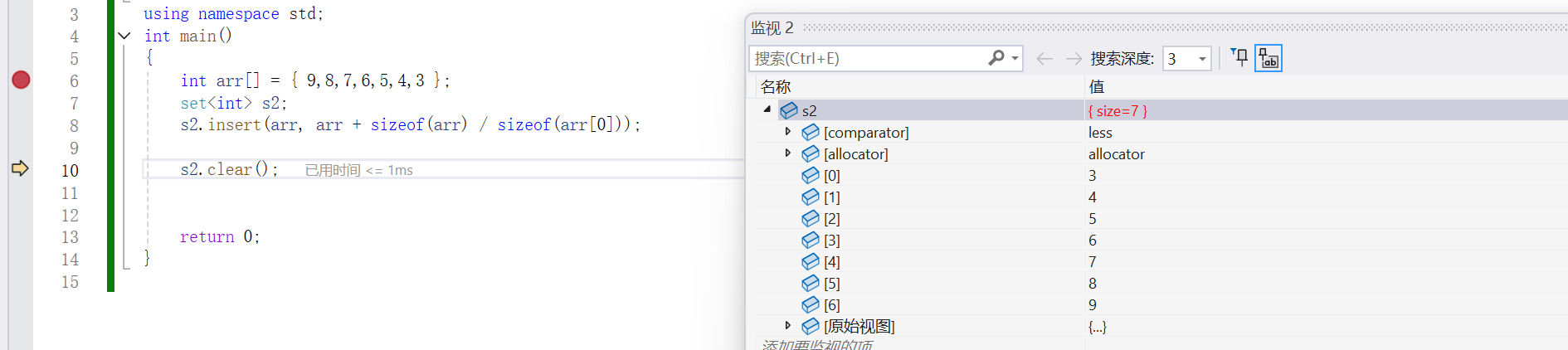
- 清空set的所有元素
#include <iostream>
#include <set>
using namespace std;
int main()
{int arr[] = { 9,8,7,6,5,4,3 };set<int> s2;s2.insert(arr, arr + sizeof(arr) / sizeof(arr[0]));s2.clear();return 0;
}

六、set的Operations

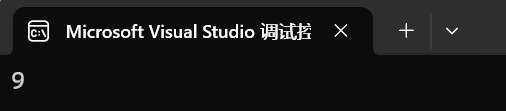
- find是查找一個元素的iterator,如果沒有查找到那么返回end()iterator
- set的底層是紅黑樹,在二叉搜索數的基礎上進行了平衡,所以成員函數find的查找效率高為O(logN),,庫里也有find,由于庫里的是給出區間遍歷查找,時間復雜度為O(N) ,所以單獨提供了find
#include <iostream>
#include <set>
using namespace std;
int main()
{int arr[] = { 9,8,7,6,5,4,3 };set<int> s2;s2.insert(arr, arr + sizeof(arr) / sizeof(arr[0]));cout << *(s2.find(9)) << endl;return 0;
}

- count是返回key值對應的個數 ,同樣是為了和multiset保持接口的一致性,multiset允許多個key值存在,所以當myltiset調用count的時候可能key值對應的個數會有多個,為了set和multiset接口的統一性,我們給set也提供一個count接口,count接口在set中可以用于判空
#include <iostream>
#include <set>
using namespace std;
int main()
{int arr[] = { 9,8,7,6,5,4,3 };set<int> s2;s2.insert(arr, arr + sizeof(arr) / sizeof(arr[0]));cout << s2.count(7) << endl;return 0;
}


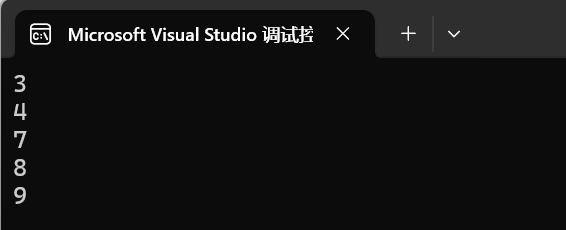
- lower_bound是下界(>=)的意思,即尋找比給定key值等于大于的值的位置的迭代器,有等于優先是等于,其次是大于,如果找不到那么返回end()

- upper_bound(>)是上界的意思,即尋找比給定key值大的值的位置的迭代器,如果找不到那么返回end()
lower_bound和upper_bound通常是搭配使用,用于尋找指定區間的迭代器(前閉區間 ,后開區間),通常要使用erase或insert插入一段區間,對區間進行操作,那么就會用到這兩個函數
erase:
#include <iostream>
#include <set>
using namespace std;
int main()
{int arr[] = { 9,8,7,6,5,4,3 };set<int> s2;s2.insert(arr, arr + sizeof(arr) / sizeof(arr[0]));set<int>::iterator it1 = s2.lower_bound(5);// >=5set<int>::iterator it2 = s2.upper_bound(6);// >6// erase: [5 ,6 ) ,刪除掉 5 和6 s2.erase(it1, it2);for (auto e : s2){cout << e << endl;}return 0;
}

- equal_range的意思是相等的范圍,即去尋找和key值相等序列的開頭和結尾位置的迭代器,同理 ,這里同樣是為了和multiset保持接口的一致性,即multiset中可以有多個相同的key值,即使用equal_range去找key值會找到的是一段序列
- 返回的pair中第一個iterator 是?和key值相等序列的開頭位置的iterator , 第二個是結尾位置的迭代器?
- 如果給equal_range的key值,在set中沒有,那么會返回比key值大的位置的迭代器作為開頭位置的迭代器和結尾位置的迭代器進行返回,舉例set數據序列為1,5,7,那么傳入查找3作為key值進行查找,3沒有,那么就會找比key值3大的值的迭代器即5位置的迭代器作為開頭和結尾位置的迭代器,那么就會返回[5,5),那么由于成員函數對序列區間進行操作是前閉區間后開區間,那么[5,5)這個序列就相當于不存在的區間,如果比key值(key值不存在set的數據序列中)大的位置的值都沒有那么會返回end()作為開頭和結尾的位置的迭代器即[end(),end()),即如果給equal_range的key值不存在,那么equal_range會返回一個不存在的區間
七、multiset

- multiset與set 的唯一不同是multiset中可以有多個相等的key值
- multiset的其它性質和set類似
#include <iostream>
#include <set>
using namespace std;
int main()
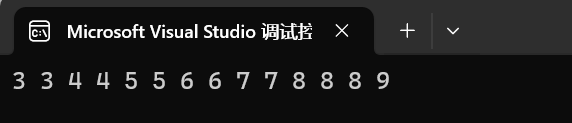
{int arr[] = { 9,8,7,6,5,4,3,8,7,6,5,4,3,8 };multiset<int> s2;s2.insert(arr, arr + sizeof(arr) / sizeof(arr[0]));for (auto e : s2){cout << e <<" ";}cout << endl;return 0;
}
multiset的count
#include <iostream>
#include <set>
using namespace std;
int main()
{int arr[] = { 9,8,7,6,5,4,3,8,7,6,5,4,3,8 };multiset<int> s2;s2.insert(arr, arr + sizeof(arr) / sizeof(arr[0]));cout << s2.count(9);cout << endl;cout << s2.count(7) << endl;return 0;
}

multiset的erase
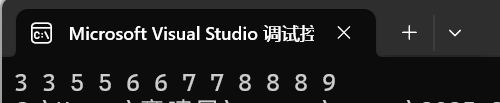
- 與set不同的是,multiset刪除key值,如果key值有多個,那么會將多個相同的key值同時刪除
#include <iostream>
#include <set>
using namespace std;
int main()
{int arr[] = { 9,8,7,6,5,4,3,8,7,6,5,4,3,8 };multiset<int> s2;s2.insert(arr, arr + sizeof(arr) / sizeof(arr[0]));s2.erase(4);for (auto e : s2){cout << e << " ";}return 0;
}
multiset的find
- 與set不同的是,multiset的find的key值可能會有對應的多個相等的key值,那么find會返回迭代器遍歷(中序遍歷)中的第一個key值位置的迭代器
#include <iostream>
#include <set>
using namespace std;
int main()
{int arr[] = { 9,8,7,6,5,4,3,8,7,6,5,4,3,8 };multiset<int> s2;s2.insert(arr, arr + sizeof(arr) / sizeof(arr[0]));set<int>:: iterator it = s2.find(7);//找到第一個7cout << *(it) << endl;it++;cout << *(it) << endl;//是按有序的排列,第一個7后面也是7 ,說明是第一個7return 0;
}









梳理總結)
)


)





