6.1 數據介紹
直接打開集算器運行 createEventsAndUsers.splx 文件,就可以得到如下兩張表(也可以根據代碼中的注釋,修改起止日期以及每天的數據量):
電商數據表 events.csv
| 字段名 | 含義 |
|---|---|
| eventID | 事件編號, 從 1 開始流水號 |
| userID | 用戶編號 |
| eTime | 事件的發生時間 |
| eType | 事件類型,取值 login,viewProduct,placeOrder,completePayment |
數據同時按 eTime 和 eventID 分別有序,因為數據是按發生時間追加的,所以始終按 eTime 有序,又 eventID 是流水號,所以也是天然有序
用戶表 user.csv
| 字段名 | 含義 |
|---|---|
| userID | 用戶編號,從 1 開始流水號 |
| userName | 用戶姓名 |
| city | 所在城市 |
表間關系:
6.2 選出 24 年國慶假期發生的所有記錄
由于事件表很大,全內存無法放下,所以采用游標的方式,SPL 提供了文件游標,可以對著游標進行過濾、分組、匯總等各種運算。
| A | |
|---|---|
| 1 | =file(“events.csv”).iselect@tc(date("2024-10-01"):datetime("2024-10-07 23:59:59"),eTime ; userID,eTime,eType) |
A1 由于事件表按時間有序,所以采用 iselect 函數,直接對著數據文件按時間過濾,這樣可以采用二分法,提高讀數的效率,不滿足過濾條件的數據直接跳過不讀了。
分號前面的參數date("2024-10-01"):datetime("2024-10-07 23:59:59"),eTime表示選出 eTime 的值位于區間date("2024-10-01"):datetime("2024-10-07 23:59:59")之間的數據,兩端均是閉區間。
分號后面的參數userID,eTime,eType表示選出字段,不需要用到的字段不選出,可以節約內存。iselect 函數返回結果是游標,可以直接進行下一步的運算,如果需要輸出數據,可以 fetch 操作。
A1 的運行結果:

從上圖可以看出,A1 返回的結果是個游標。
6.3 統計 24 年國慶假期發生的記錄數、用戶數
| A | |
|---|---|
| 1 | =file(“events.csv”).iselect@tc(date(“2024-10-01”):datetime(“2024-10-07 23:59:59”),eTime ; userID,eTime,eType) |
| 2 | =A1.groups(; count(1):records,icount(userID):userNum) |
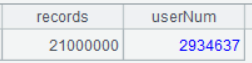
A2 分組匯總,groups 函數可以直接對著游標操作,返回統計結果。特別注意:分號前面不寫分組表達式,表示全集匯總。
A2 的運行結果如下:
6.4 按事件類型分組統計 24 年國慶假期的發生次數和用戶數
| A | |
|---|---|
| 1 | =file(“events.csv”).iselect@tc(date(“2024-10-01”):datetime(“2024-10-07 23:59:59”),eTime;userID,eTime,eType) |
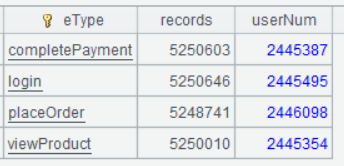
| 2 | =A1.groups(eType;count(1):records,icount(userID):userNum) |
A2 的運行結果如下:
6.5 統計 24 年國慶假期每天的總用戶數、下單用戶數、付款用戶數
| A | |
|---|---|
| 1 | =file(“events.csv”).iselect@tc(date(“2024-10-01”):datetime(“2024-10-07 23:59:59”),eTime;userID,eTime,eType) |
| 2 | =A1.group(date(eTime):Date; ~.icount(userID):TotalNum, ~.select(eType==“placeOrder”).icount(userID):OrderNum, ~.select(eType==“completePayment”).icount(userID):PayNum) |
| 3 | =A2.fetch() |
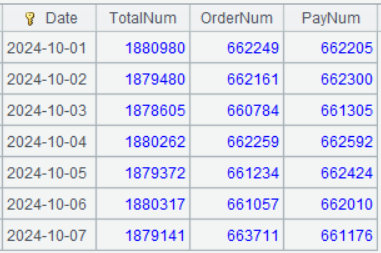
A2 對著游標 A1 進行分組,group 函數表示分組過程中保留分組的組集;~.icount(userID) 表達式中的 ~ 表示當前的組集,整個表達式意思是對著當前組集統計 userID 的去重個數;~.select(eType==“placeOrder”).icount(userID) 表示對著當前組集先過濾出 eType 為 placeOrder 的記錄,再對其統計 userID 的去重個數。
cs.group 函數的返回結果依舊是游標,A2 的運行結果如下:

A3 從游標 A2 中讀出結果數據。
A3 的運行結果如下:
6.6 按天統計 24 年國慶假期北京地區的下單用戶數
| A | |
|---|---|
| 1 | =file(“events.csv”).iselect@tc(date(“2024-10-01”):datetime(“2024-10-07 23:59:59”),eTime;userID,eTime,eType) |
| 2 | =file(“user.csv”).cursor@tc(userID,city).select(city==“Beijing”).fetch() |
| 3 | =A1.select(eType==“placeOrder”).join@i(userID,A2:userID) |
| 4 | =A3.groups(date(eTime):Date;icount(userID):userNum) |
A2 用戶表數據量也非常大,本例只需要讀取北京地區的用戶,因此可以用游標的方式過濾后再 fetch(),這樣非北京地區的用戶數據就不會占用內存了。
A3 將 A1 先過濾出下單的數據,然后和 A2 關聯,@i選項表示只保留關聯上的記錄,關聯不上的記錄直接刪除(如果希望只保留關聯不上的記錄,刪除關聯上的記錄,比如統計非北京地區的用戶,那么可以把@i選項換成@d選項,其余不變即可)。因為 A1 是游標,所以 A3 的返回結果依舊是游標。
A4 將 A3 進行分組匯總。
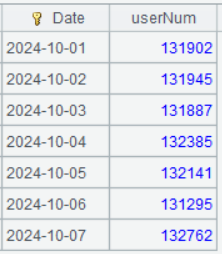
A4 的運行結果:
知識點:先過濾后關聯
上例的 A3 中關聯的兩個對象都是先分別進行了過濾,然后才進行關聯,這樣可以減少關聯的次數,提升關聯效率。
6.7 將事件表拆成一個月一張表,表內按 userID 排序
由于事件表數據量大,無法全內存放下,因此需要用游標排序:
| A | |
|---|---|
| 1 | =file(“events.csv”).iselect@tc(date(“2024-10-01”):datetime(“2024-10-31 23:59:59”),eTime).sortx(userID) |
| 2 | =file(“events202410.csv”).export@tc(A1) |
| 3 | =file(“events.csv”).iselect@tc(date(“2024-11-01”):datetime(“2024-11-30 23:59:59”),eTime).sortx(userID) |
| 4 | =file(“events202411.csv”).export@tc(A3) |
| 5 | =file(“events.csv”).iselect@tc(date(“2024-12-01”):datetime(“2024-12-31 23:59:59”),eTime).sortx(userID) |
| 6 | =file(“events202412.csv”).export@tc(A5) |
A1 sortx 函數專門用于游標排序,參數 userID 是排序字段。sortx 返回值依舊是游標。
A2 將游標 A1 中的數據讀出直接寫入文件 events202410.csv。export 和 import 的選項規則一致,是 import 函數的逆操作。
知識點:sort 函數和 sortx 函數的區別
1.sort 函數
特點:
- 立即執行:調用sort時會直接對當前序表(或排列)進行排序,生成一個新的有序結果。
- 內存排序:數據在內存中完成排序,適合處理中小規模數據。
- 返回新序列:原序列不變,返回排序后的新序列。
適用場景:
數據量較小(可完全裝入內存),且需要直接獲取排序結果的場景。
2.sortx 函數
特點:
- 立即執行:排序結果存入一個或多個臨時文件,返回這些文件的歸并游標。
- 外存排序:支持大數據量的排序,通過臨時外存文件處理超出內存的數據。
- 返回游標:返回排序結果的游標,適合下一步的輸出或運算。
適用場景:
數據量較大(無法完全裝入內存),或需要與其他延遲計算操作(如流式處理)結合時。
6.8 按用戶統計每月的下單個數
需完成如下統計:
10 月下單的用戶,10 月、11 月下單的個數
10 月 11 月均下單的用戶,10 月、11 月下單的個數
按用戶統計 10 月 11 月下單個數
第一步:產生游標
| A | |
|---|---|
| 1 | =file(“events202410.csv”).cursor@tc() |
| 2 | =file(“events202411.csv”).cursor@tc() |
第二步:分別匯總統計訂單數
| A | |
|---|---|
| 3 | =A1.select(eType==“placeOrder”).group(userID;~.count(1):10Num) |
| 4 | =A2.select(eType==“placeOrder”).group(userID;~.count(1):11Num) |
A3 由于 A1 是游標,因此,select 函數返回的是游標,group 函數返回的依舊是游標。
第三步:關聯
1. 10 月下單的用戶,10 月、11 月下單的個數
| A | |
|---|---|
| 5 | =joinx@1(A3:oct,userID;A4:nov,userID) |
| 6 | =A5.new(oct.userID,oct.10Num,nov.11Num) |
| 7 | =file(“result.csv”).export@tc(A6) |
A5 joinx@1 為左連接,joinx 函數專門用于兩個或多個游標之間的關聯,要求參與關聯的游標數據均按關聯字段有序。參數規則和 join() 一致。
A6 因為 joinx 和 join 一樣,關聯的結果是指引字段,所以需要再次 new,產生結果序表,此時 A6 依舊是游標
A7 將結果輸出到文件,由于結果集太大內存依舊放不下,因此可以直接將游標中的數據輸出到文件。
2. 10 月 11 月均下單的用戶,10 月、11 月下單的個數
| A | |
|---|---|
| 5 | =joinx(A3:oct,userID;A4:nov,userID) |
| 6 | =A5.new(oct.userID,oct.10Num,nov.11Num) |
| 7 | =file(“result.csv”).export@tc(A6) |
A5 joinx 為內連接。
3. 按用戶統計 10 月 11 月下單個數
| A | |
|---|---|
| 5 | =joinx@f(A3:oct,userID;A4:nov,userID) |
| 6 | =A5.new(oct.userID,oct.10Num,nov.11Num) |
| 7 | =file(“result.csv”).export@tc(A6) |
A5 joinx@f 為全連接。
知識點: join()函數和 joinx() 函數的區別
1.join() 函數
特點
- 立即執行: 調用 join() 時會直接執行連接操作,生成一個新的結果序表。
- 內存連接: 數據在內存中完成連接,適合中小規模數據。
- 返回完整結果: 連接后的數據會完全加載到內存中。
- 語法靈活: 支持多種連接類型(如內連接、左連接、全連接等)。
- 數據可以無序: 不要求數據按關聯字段有序。
適用場景
- 數據量較小(可完全裝入內存)。
- 需要立即獲取連接結果的場景。
2.joinx() 函數
特點
- 延遲執行: joinx() 僅生成一個連接游標,不會立即計算,實際連接操作會延遲到后續遍歷或聚合時觸發。
- 外存連接: 支持大數據量的連接,可處理超出內存的數據。
- 惰性求值: 適合流式處理,可與其他函數(如 groups、select)結合使用。
- 返回游標: 不直接返回完整數據,而是返回一個可迭代的游標對象。
- 數據有序: 要求數據按關聯字段有序。
適用場景
- 數據量較大(無法完全裝入內存)。
- 需要與其他延遲計算操作(如流式處理)結合時。






)
)




】)
)


)


