標題: Sparse4D v2:Recurrent Temporal Fusion with Sparse Model
作者: Xuewu Lin, Tianwei Lin, Zixiang Pei, Lichao Huang, Zhizhong Su
motivation
在v1的基礎上,作者發現長時序有更好的效果,但v1的計算量太大,于是又快又好的長時序v2誕生。
稀疏算法為多視圖時間感知任務提供了極大的靈活性。提出了 Sparse4D 的增強版本,其中通過實現多幀特征采樣的遞歸形式來改進時間融合模塊。通過有效地解耦圖像特征和結構化錨點特征,Sparse4D實現了時間特征的高效變換,從而僅通過稀疏特征的逐幀傳輸來促進時間融合。循環時間融合方法有兩個主要好處。首先,它將時間融合的計算復雜度從O(T)降低到O(1),從而顯著提高了推理速度和內存占用。其次,它能夠實現長期信息的融合,從而通過時間融合帶來更明顯的性能提升:Sparse4D v2。
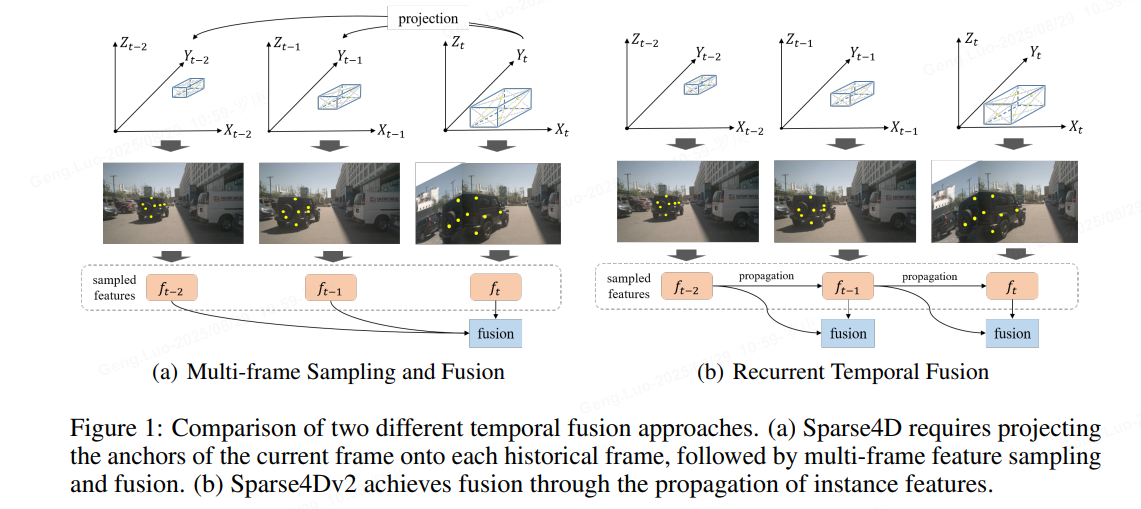
methods
總體Framwork如下:
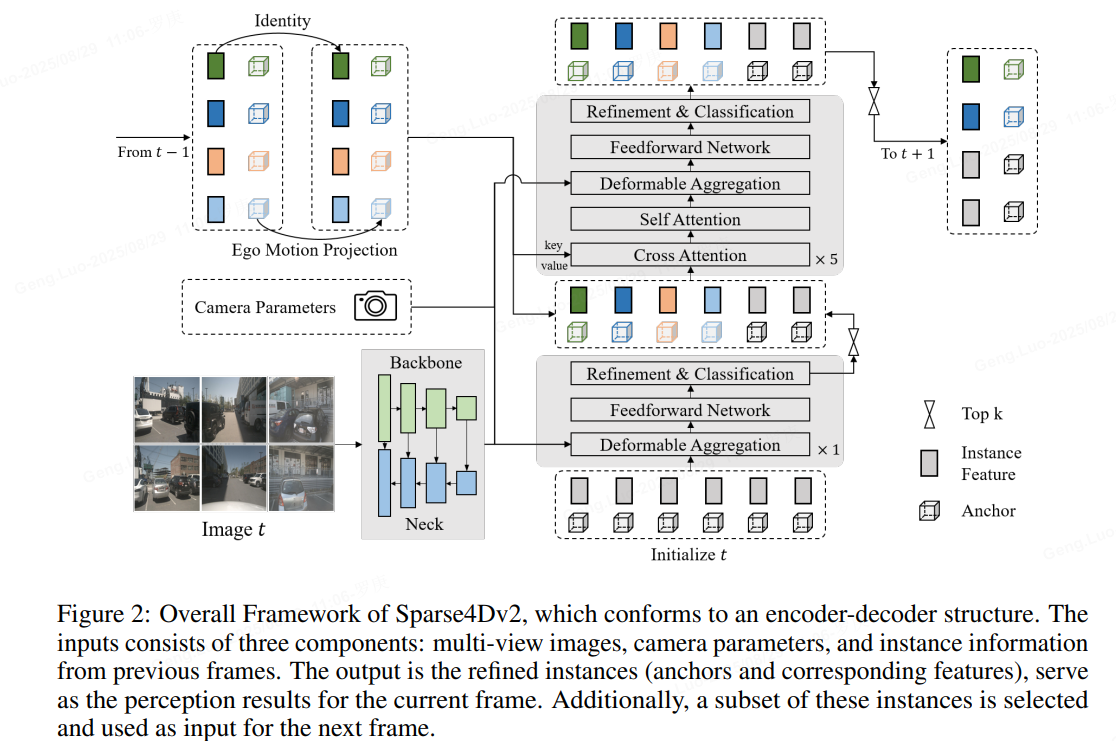
1、Instance Temporal Propagation
實例由三個部分表示,分別是錨點、實例特征和錨點嵌入。錨點是結構化信息,它指示實例的狀態,并具有實際的物理含義。實例特征是從圖像中提取的高階語義特征,主要來自圖像編碼器。錨點嵌入是錨點的特征編碼,利用小型錨點編碼器將錨點的結構化信息映射到高維空間。這種設計完全解耦了實例的圖像特征和結構化狀態,因此我們可以更方便地添加先驗知識。例如時間傳播,我們只需要投影其錨點,并使用錨點編碼器對投影的錨點進行編碼,實例特征可以保持不變。
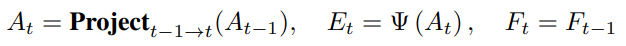
其中投影公式與anchor定義相關,對于3D 檢測任務,使用的投影公式如公式:
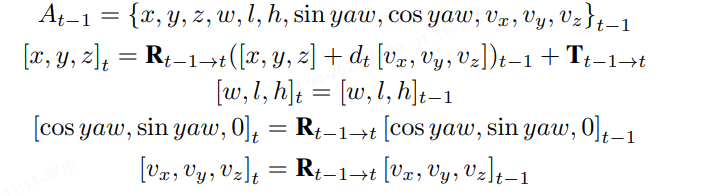
將decoder分為單幀層和時序層。單幀層以新初始化的instance作為輸入,輸出一部分高置信度的instance至時序層;時序層的instance除了來自于單幀層的輸出以外,還來自于歷史幀(上一幀)。將歷史幀的instance投影至當前幀,其中,instance feature保持不變,anchor box通過自車運動和目標速度投影至當前幀,anchor embed通過對投影后的anchor進行編碼得到。
Instance 表示方式:PETR系列中,query instance 采用的是 “Anchor Point -> Query 特征”的方式。即將均勻分布在3D 空間中的anchor point(learnable)用MLP編碼成Query 特征。比起Sparse4D instance 中顯式分離feature (紋理語義信息) 和3D anchor(幾何運動信息) 的方式,PETR的instance 表示方式更加隱式一些。我們認為feature + anchor box的顯式instance表示方式,在稀疏3D檢測任務中更加簡潔有效,也更易于訓練;
時序轉換方式:與instance 表示方法相對應的是稀疏Reccurent 的方式。StreamPETR 中,采用了隱式的query時序轉換方式,即把velocity、ego pose、timestamp都編碼成特征,然后再和query feature做一些乘加操作;Sparse4d-V2 則采用了顯式的時序轉換方式,對于歷史幀的instance,直接將其3D anchor基于自車和instance 運動投影到當前幀,而保持其instance feature不變。
歷史幀數量:StreamPETR 中 cache了歷史N幀的query,再與當前幀進行attention。Sparse4d-v2 則只cache了上一幀的query。當然,StreamPETR 也可以只cache 一幀,只是效果會略略有下降。在實際的業務實踐中,較少的歷史幀cache 有助于減少端上的帶寬占用,進一步提升系統整體性能。
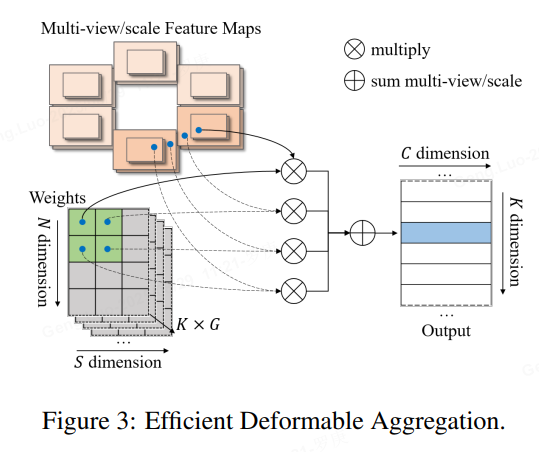
2、Efficient Deformable Aggregation
就是直接在模型里面進行特征采樣及融合,提高中間效率,降低訪問及存儲;
作者對deformable aggregation模塊進行了底層的分析和優化,讓其并行計算效率顯著提升,顯存占用大幅降低。基于pytorch op組合的Basic Deformable Aggregation 計算邏輯實現如下圖所示。

可以發現其會生成多個中間變量,需要對顯存進行多次訪問和存儲,降低了推理速度,且中間變量 尺寸較大,從而導致顯存占用量顯著增加,并且反向傳播過程中的顯存消耗會進一步提升。
Efficient Deformable Aggregation(EDA)的關鍵在于將“先采樣所有特征再融合”的方式變成了“并行地邊采樣邊融合”,其允許在關鍵點維度和特征維度上實現完全的并行化,每個線程的計算復雜度僅與相機數量和特征尺度數量相關,在某些場景中,3D空間中的一個點最多被投影到兩個視圖,使得計算復雜度可以進一步降低 。EDA可以作為一種基礎性的算子操作,可以適用于需要多圖像和多尺度融合的各種應用。
3、Camera Parameter Encoding
camera embedding(Liner層)
作者加入了內外參的編碼,將相機投影矩陣通過全連接網絡映射到高維特征空間得到camera embed。在計算deformable aggregation中的attention weights
時,我們不僅考慮instance feature和anchor embed,還加上了camera embedding。
4、Dense Depth Supervision
在實驗中,發現基于稀疏的方法在早期訓練階段缺乏足夠的收斂能力和速度。為了緩解這一問題,還引入了以點云為監督的多尺度密集深度估計方法作為輔助訓練任務。而在推理過程中,這個分支網絡將不會被激活,不影響推理效率。
Experiment
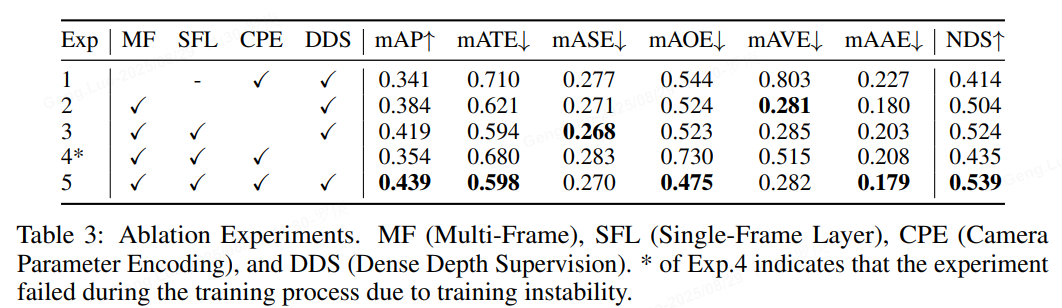
作者首先基于Resnet50 + 256x704 分辨率的配置展開了消融實驗。如下表所示:
對比Exp1 和Exp5可以看出,采用recurrent instance的形式來實現長時序融合,相比單幀提升非常大;
對比Exp4 和Exp5可以看出,深度監督模塊,有效降低了Sparse4D-V2的收斂難度,如果去掉該模塊,模型訓練過程會出現梯度崩潰的現象,從而使得mAP降低了8.5%。(在不具備深度監督條件的情況下,也可以考慮使用2D 的檢測head 作為輔助loss,如FCOS Head,YoloX等)
對比Exp2 和Exp3可以看出,單幀層 + 時序層的組合方式比起只使用時序層的效果要好很多;
對比Exp3 和Exp5可以看出,相機參數編碼也帶來了可觀的提升,mAP和NDSf分別提升了2.0%和1.5%;
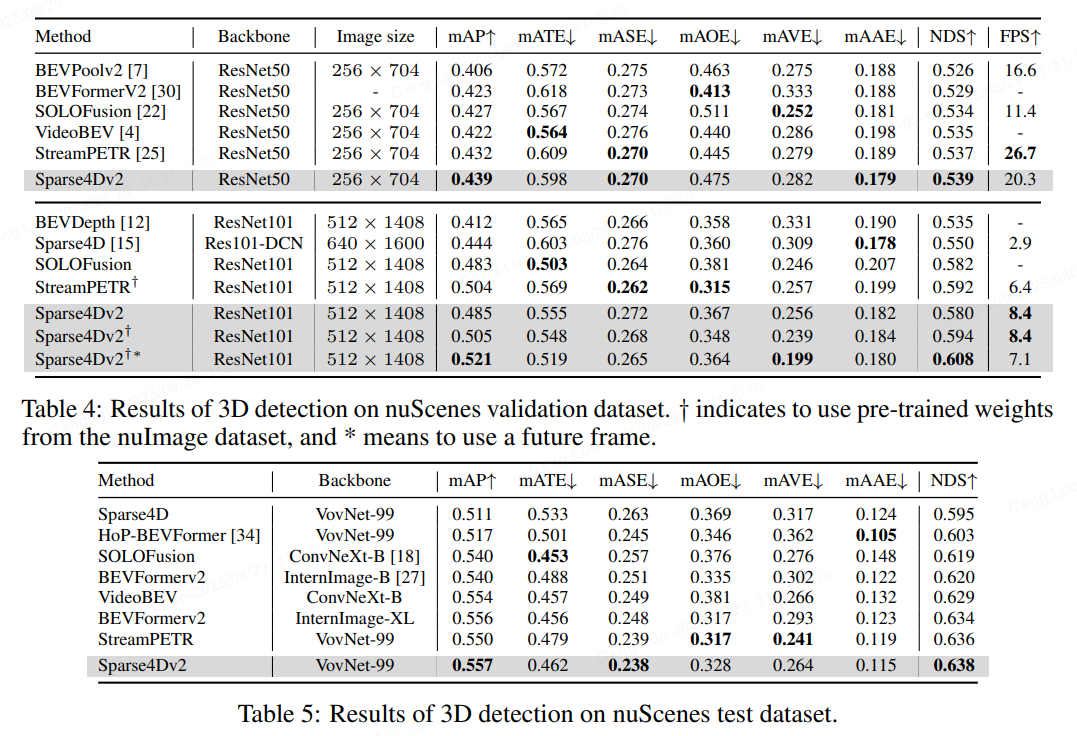
在nuScenes validation數據集上進行了對比,可以無論是在低分辨率+ResNet50還是高分辨率+ResNet101的配置下,Sparse4D v2都取得了SOTA的指標,超過了SOLOFusion、VideoBEV和StreamPETR等算法。
從推理速度來看,在256X704的圖像分辨率下,Sparse4Dv2超過了LSS-Based算法BEVPoolv2,但是低于StreamPETR。但是當圖像分辨率提升至512X1408,Sparse4Dv2的推理速度會反超StreamPETR。這主要是因為在低分辨率下直接做global attention的代價較低,但隨著特征圖尺寸的上升其效率顯著下降。而Sparse4D head理論計算量則和特征圖尺寸無關,這也展示了純稀疏范式算法在效率上的優勢。實際測定中,當圖像分辨率從256x704 提升到512x1408時,Sparse4Dv2 的decoder 部分耗時僅增加15%(從高分辨率特征上進行grid sample,會比從低分辨率特征上進行grid sample 略慢一點)。
以上是作者的全部內容,好,好,好!
【完結】





-> QPushButton)




)


)
)




