二叉搜索樹
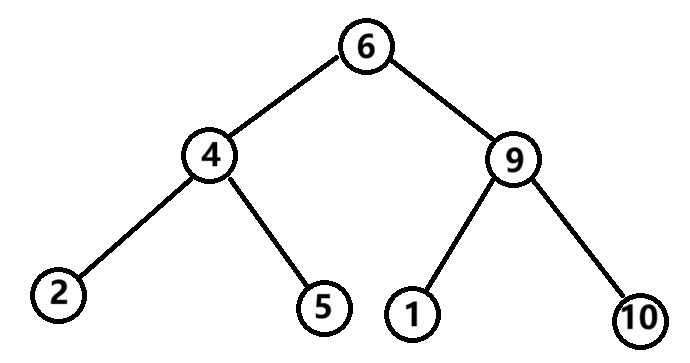
像上圖這樣滿足,任意一棵子樹的左子樹小于該子樹的根結點,右子樹大于該子樹的根結點,滿足這樣的條件,則這種樹就被稱為二叉搜索樹。
public class BinarySearchTree {static class TreeNode {public int val;public TreeNode left;public TreeNode right;public TreeNode(int val) {this.val = val;}}public TreeNode root = null;public boolean search(int val) {TreeNode cur = root;while(cur!=null){if(cur.val > val){cur = cur.left;}else if(cur.val < val) {cur = cur.right;}else{return true ;}}return false;}public void insert(int val) {TreeNode node = new TreeNode(val);if(root==null){root=node;return;}TreeNode cur = root;TreeNode parent = null;while(cur!=null){parent = cur;if(cur.val>val){cur=cur.left;}else if(cur.val<val){cur=cur.right;}else{return;}}if(parent.val>val){parent.left = node;}else if(parent.val<val) {parent.right = node;}}public void remove(int val){if(root==null){return;}TreeNode cur = root;TreeNode parent = null;while(cur!=null) {if(cur.val>val){parent=cur;cur=cur.left;}else if(cur.val<val){parent=cur;cur=cur.right;}else{removeNode(parent,cur);}}}private void removeNode(TreeNode parent,TreeNode cur) {if(cur.left == null) {//以cur為根左樹為空的情況if(cur==root){//parent和cur在一起(頂根為要刪除的節點時)root=cur.right;}else if(cur==parent.left){//cur為要刪除元素并且走到了parent左邊,cur左邊為空,把parent的左邊接上cur的右邊parent.left=cur.right;}else{//cur為要刪除元素并且走到了parent右邊,cur左邊為空,把parent的右邊接上cur的右邊parent.right=cur.right;}} else if (cur.right == null) {//以cur為根右樹為空的情況if(cur==root){root=cur.left;}else if(cur==parent.left){parent.left=cur.left;}else{parent.right=cur.left;}}else{//cur左右都不為空的情況************TreeNode targetParent = cur;TreeNode target = cur.left;while(target.right!=null){targetParent = target;target = target.right;}cur.val=target.val;if(target==targetParent.right){targetParent.right=target.left;}else{targetParent.left=target.left;}}}
}二叉搜索樹的模擬只要遵循二叉搜索樹的特性即可。
單支的二叉搜索樹
如果插入的順序不恰當,二叉搜索樹就會出現只有單支的情況
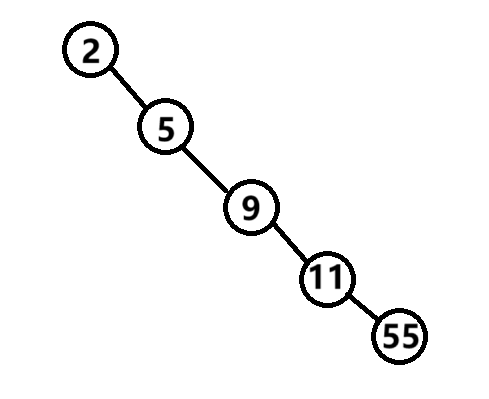
這樣也屬于二叉搜索樹,但是由于另一半枝沒有放入元素,我們對該種搜索樹進行操作時,效率必然會有所下降。
Map和Set
先了解一下Map和Set的概念,以及兩者的區別。
首先這兩種集合是高效的搜索容器,很適合動態查找,不同于我們以前學過的其他數據結構,那些數據結構進行動態查找都需要不小的時間復雜度。
Map是一種Key-Value模型,kv模型的意思就是,如果你往里面存放數據,那就需要提供key 和 value的值,我們也稱這種模型為鍵值對模型。例如我們要統計某單詞在英語試卷中出現的次數,
<單詞,單詞出現的次數>對應的就是 Key 和 Value
Set是一種Key模型,如果你往里面存放數據,只需要提供一個數據Key,但是Set不允許有重復的數據,所以Set更偏向于去重,查找是否存在目標數據
TreeMap
TreeMap就是結合了剛剛提到的KeyValue模型和搜索樹,實際上TreeMap底層是紅黑樹,現階段還沒學到紅黑樹,這里不細說它的結構
Map<String,Integer> map = new TreeMap<>();
TreeMap<String,Integer> map2 = new TreeMap<>();創建一個TreeMap有以上兩種格式,推薦使用第一種
Map有幾個核心的方法
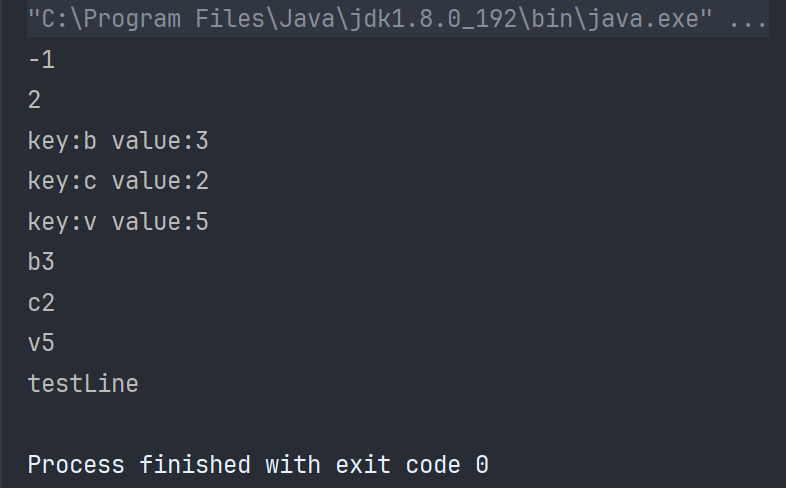
public static void main(String[] args) {Map<String,Integer> map = new TreeMap<>();//key value typeTreeMap<String,Integer> map2 = new TreeMap<>();map.put("b",3);map.put("c",2);map.put("v",5);int val = map.getOrDefault("d",-1);//如果存在key就返回key的value,不存在就返回Default(-1)System.out.println(val);val = map.get("c");System.out.println(val);Set<String> set = map.keySet();//收集keyCollection<Integer> collection=map.values();//收集valueSet<Map.Entry<String,Integer>> entries = map.entrySet();//搜索樹上每一個節點放的都是Map.Entryfor (Map.Entry<String,Integer> entry :entries) {System.out.println("key:"+entry.getKey()+" value:"+entry.getValue());}for (Map.Entry<String,Integer> entry :map.entrySet()) {System.out.println(entry.getKey()+entry.getValue());}
}
TreeSet
Set是純Key模型,適合查找存在
public static void main(String[] args) {Set<String> set = new TreeSet<>();set.add("a");set.add("g");set.add("tq");set.remove("a");boolean flag =set.contains("g");System.out.println(flag);System.out.println(set);}
public static void main(String[] args) {Set<String> set = new TreeSet<>();set.add("a");set.add("g");set.add("tq");set.add("a");
// set.remove("a");boolean flag =set.contains("g");System.out.println(flag);System.out.println(set);}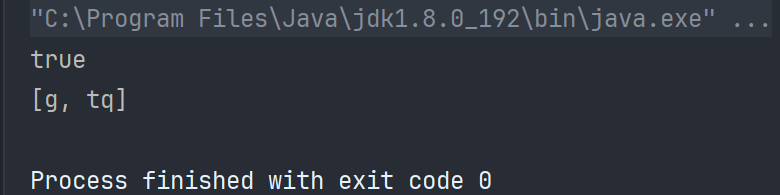
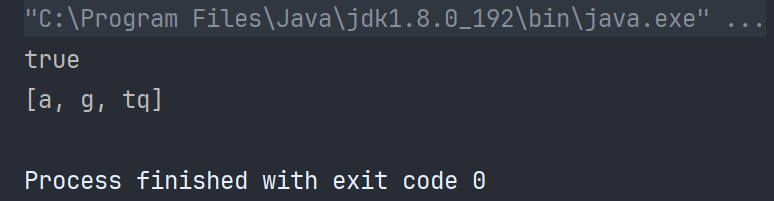
TreeSet的底層也是紅黑樹
哈希表
順序結構以及平衡樹中,元素關鍵碼與其存儲位置之間沒有對應的關系,因此在查找一個元素時,必須要經過關鍵 碼的多次比較。
順序查找時間復雜度為O(N),平衡樹中為樹的高度,即O(log2(N)?),搜索的效率取決于搜索過程中 元素的比較次數。
但是哈希表不一樣,哈希表可以不經過任何比較,一次直接從表中得到要搜索的元素。
沖突
要明白什么是哈希表的沖突之前,不防這樣設想一下,假若有5個數據,他的范圍在1到10之間

這個時候我們不難發現,如果創建一個帶有1到10下標的表格把對應數據存放起來,這樣一來我們將來要找目標數據的時候就會很方便,只需要對應下標就可以找到。
但是如果保持5個數據數量不變的情況下,但是把范圍改變至1到20,并且這個時候我們不能把表進行擴容
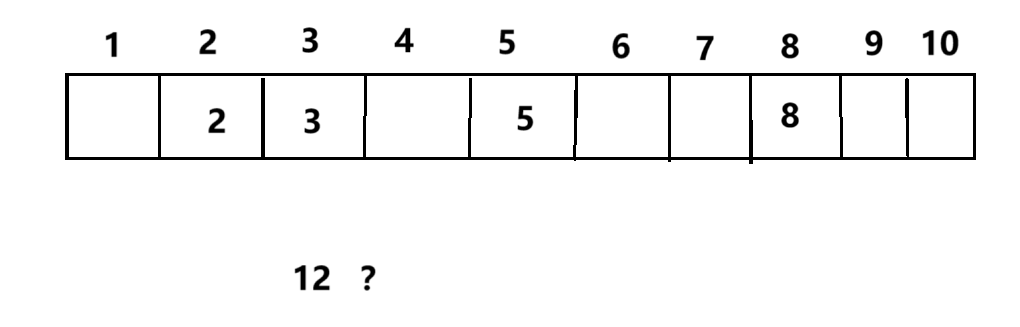
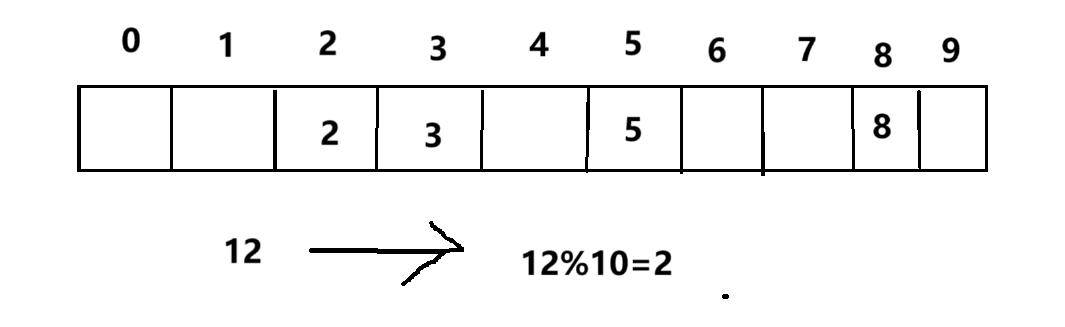
假若這個時候指定規則,不管目標數據為個位數還是十位數,數據的個位數是什么我們就放到什么位置,這個時候我們把12放到2下標的位置,表的內容就產生了沖突。
哈希函數
針對沖突的發生,又引出了一個概念,哈希函數可以有很多種,舉個常見的,線性函數,比如:? ? ? ? Hash(Key)= A*Key + B ,但是大多數情況下,我們使用除留余數法,函數為:? ? ? ? ? ? ? ? ? ?? ? ? ? Hash(Key)= Key % 表長
負載因子
散列表的負載因子=元素個數/表長,通常來說負載因子越小,沖突的概率越低,就像馬路一樣,如果馬路越寬,那么堵車的可能性也會變低。我們通常擴展列表的長度來使得負載因子擴展,通常情況下,如果負載因子達到了0.75,我們就要對散列表進行擴容
解決沖突
既然有了哈希函數,并且產生了沖突,那我們就要解決沖突,解決沖突可以分為兩種方式,開散列和閉散列。
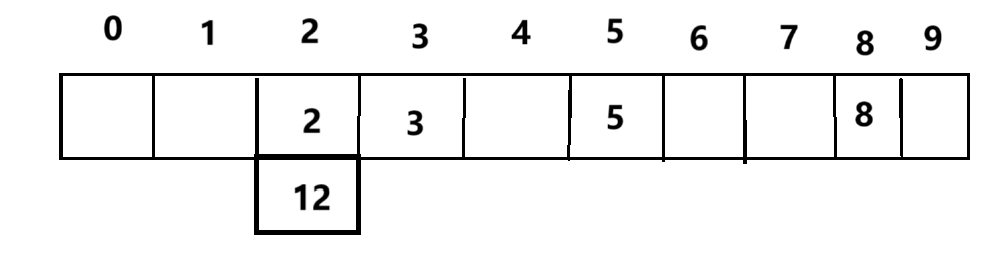
首先來說說閉散列,閉散列我們通常采用線性探測的方式來解決沖突,按上面的例子來簡單說就是,12得到的結果是2要放在2的位置,但是2已經有了數據,這個時候我們就把12放到下一個為空的位置

這種解決方式雖然簡單粗暴,但是必然會影響查找的時間復雜度,以為增加后續可能發生的沖突
所以我們就要用開散列的方法
哈希桶
哈希表的底層就是哈希桶,哈希桶是什么呢?哈希桶就是在前面我們畫的表格的基礎上,每一個表格都寬展出一個鏈表,使得一個下標能存放更多的數據
public class HashBucket {//哈系桶是哈希查找的關鍵static class Node{public int key;public int value;public Node next;public Node(int key,int value){this.key = key;this.value = value;}}public Node[] array;public int usedSize;public HashBucket() {array = new Node[10];}public void putLast (int key,int value){//尾插法,這里的尾差指的是,在表對應的位置上,對鏈表結構進行尾插int index = key % array.length;Node node = new Node(key,value);if(array[index] == null){//第一次插入array[index] = node;usedSize++;if(loadFactor() >=0.75){resize();}return;}Node cur = array[index];//若不是第一次插入,則進行尾插while(cur.next!=null){//尾插cur = cur.next;}cur.next = node;usedSize++;if(loadFactor() >= 0.75){resize();}}public void putFirst (int key , int value) {int index = key % array.length;Node node = new Node(key,value);Node cur = array[index];//先遍歷一遍鏈表結構,檢查是否存在當前的keywhile(cur!=null){if(cur.key==key){cur.value = value;//若存在當前key,則把當前的value更新掉return;}}node.next = array[index];array[index] = node;usedSize++;if(loadFactor() >= 0.75){resize();}}private double loadFactor() {//算負載因子return usedSize*1.0/array.length;}private void resize(){//如果負載因子大于0.75就對表進行擴容Node[] tempArray = new Node[array.length*2];for (int i = 0; i < array.length; i++) {//遍歷原來的表Node cur = array[i];while(cur != null) {//找到非空的表位Node curNext = cur.next;//先記錄下表位的next,后續會對next進行修改,所以要進行next的備份int newIndex = cur.key % tempArray.length;//算出表位鏈表上的key對應新表的位置,如13%20=13,就找到13位置cur.next = tempArray[newIndex];//頭插到新表里,這樣就把key:13從鏈表中分離出來了tempArray[newIndex] = cur;cur = curNext;//遍歷表位的鏈表}}array=tempArray;//覆蓋舊表}public int get(int key) {int index = key % array.length;Node cur = array[index];while(cur!=null){if(cur.key == key){return cur.value;}cur = cur.next;}return -1;}
}HashMap
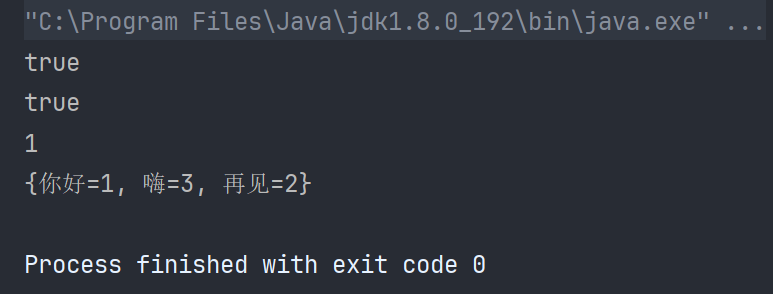
public class TestHashMap {public static void main(String[] args) {Map<String,Integer> map = new HashMap<>();map.put("你好",1);map.put("再見",2);map.put("嗨",3);System.out.println(map.containsKey("你好"));System.out.println(map.containsValue(3));System.out.println(map.get("你好"));System.out.println(map);}
}
和TreeMap的方法種類沒有區別,但是底層結構上有所區別,HashMap的底層是哈希桶(HashBucket),TreeMap的底層是紅黑樹。從先階段的簡單層面來說,可以把HashMap理解成一個兩行的列表
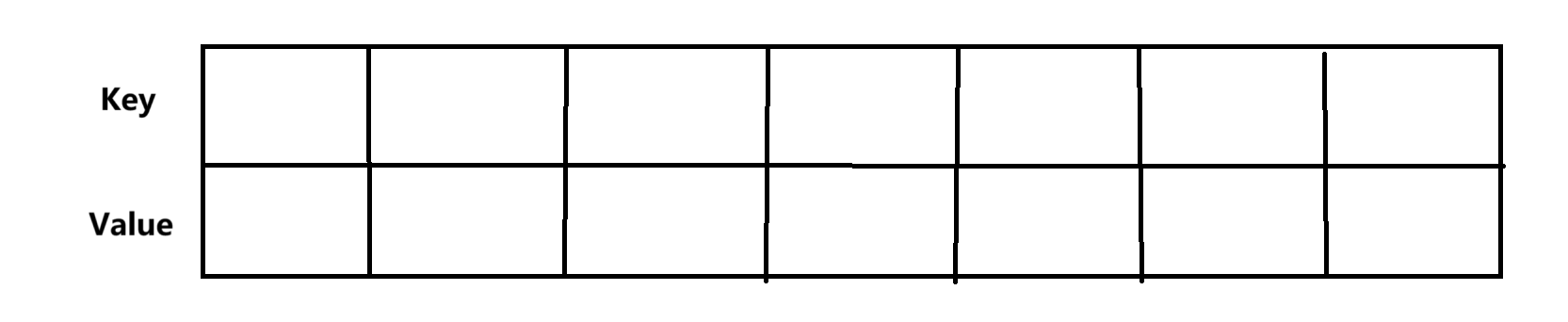
Key和Value的類型可以自己定義,可以是<String,Integer>,也可以是<String,String>,這一點在某些算法中有所體現。
HashSet
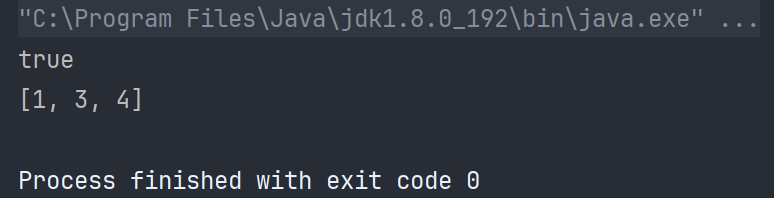
public class TestHashSet {public static void main(String[] args) {Set<Integer> set = new HashSet<>();set.add(1);set.add(2);set.add(3);set.add(4);System.out.println(set.contains(2));set.remove(2);System.out.println(set);}
}
相比于TreeSet,HashSet的效率更高,因為HashSet不需要進行額外的數據對比操作,在其他方面基本于TreeSet無異。具體要TreeSet還是HashSet需要結合實際來考慮。








)




:數據庫技術的發展、數據模型、數據庫管理系統、數據庫三級模式)





)