數據庫技術是研究數據庫的結構、存儲、設計、管理和應用的一門軟件學科。
數據庫系統本質上是一個用計算機存儲信息的系統。
數據庫管理系統是位于用戶與操作系統之間的一層數據管理軟件,其基本目標是提供一個可以方便、有效地存取數據庫信息的環境。
數據庫就是信息的集合,它是收集計算機數據的倉庫或容器,系統用戶可以對這些數據執行一系列操作。
設計數據庫系統的目的是為了管理大量信息,給用戶提供數據的抽象視圖,即系統隱藏有關數據存儲和維護的某些細節。
對數據的管理涉及信息存儲結構的定義、信息操作機制的提供、安全性保證,以及多用戶對數據的共享問題。
一、數據庫技術的發展
數據處理是對各種數據進行收集、存儲、加工和傳播的一系列活動。數據管理是對數據進行分類、組織、編碼、存儲、檢索和維護的活動。
數據管理技術的發展經歷了3個階段:人工管理、文件系統和數據庫系統階段。
(一)人工管理階段
早期的數據處理都是通過手工進行的,因為當時的計算機主要用于科學計算。計算機上沒有專門管理數據的軟件,也沒有諸如磁盤之類的設備來存儲數據。
在人工管理階段,數據處理具有以下幾個特點。
1.人工管理階段數據處理的特點
(1)數據量較少且“綁定”程序
數據和程序一一對應,即一組數據對應一個程序,數據面向應用,獨立性很差。
數據和程序幾乎是一一對應的“捆綁銷售”。一組特定的數據只為解決一個特定的計算任務(應用)而生。這就好比每本菜譜(程序)都必須自帶獨一無二的食材清單(數據),想換個菜譜?對不起,清單也得重寫。 數據完全服務于單一應用,毫無獨立性可言。
(2)數據不保存
該階段計算機主要用于科學計算(比如彈道計算、物理模擬),一般不需要將數據長期保存,只在計算一個題目時,將數據輸入計算機,計算完成得到計算結果即可。
計算任務像“快餐”——數據是臨時買來的食材,計算過程是烹飪,得到結果(菜肴)后,食材(數據)就被丟棄了。 一般沒有長期保存數據的需要和意識。
(3)沒有軟件系統對數據進行管理
程序員需要“身兼數職”,沒有專門的軟件來管理數據這個“倉庫”。
程序員不僅要設計數據的邏輯結構(數據代表什么),還得在程序里操心數據的物理存儲細節(存在哪、怎么存、怎么取、怎么輸入輸出)。
這相當于建筑師不僅要設計房屋藍圖,還得親自燒磚砌墻、鋪設水電管道。
2.手工處理數據的缺點
(1)緊耦合的噩夢: 應用程序與數據深度綁定。
想修改一下數據結構(比如在員工信息里加個“電話號碼”字段)?抱歉,所有用到這份數據的程序都得跟著大改,牽一發而動全身。 程序和數據完全無法獨立演化。
(2)冗余的“信息孤島”
不同部門或不同程序處理的數據常常重復。
銷售部門有自己的客戶地址卡片,財務部門也建了一套客戶地址卡片用于開發票。
這不僅浪費存儲空間(雖然當時存儲空間極其珍貴),更可怕的是,一旦客戶搬家,更新任何一處都可能遺漏其他地方,導致數據不一致,引發混亂。
3.人工管理的存儲方式:物理世界的局限
數據主要棲身于物理介質。
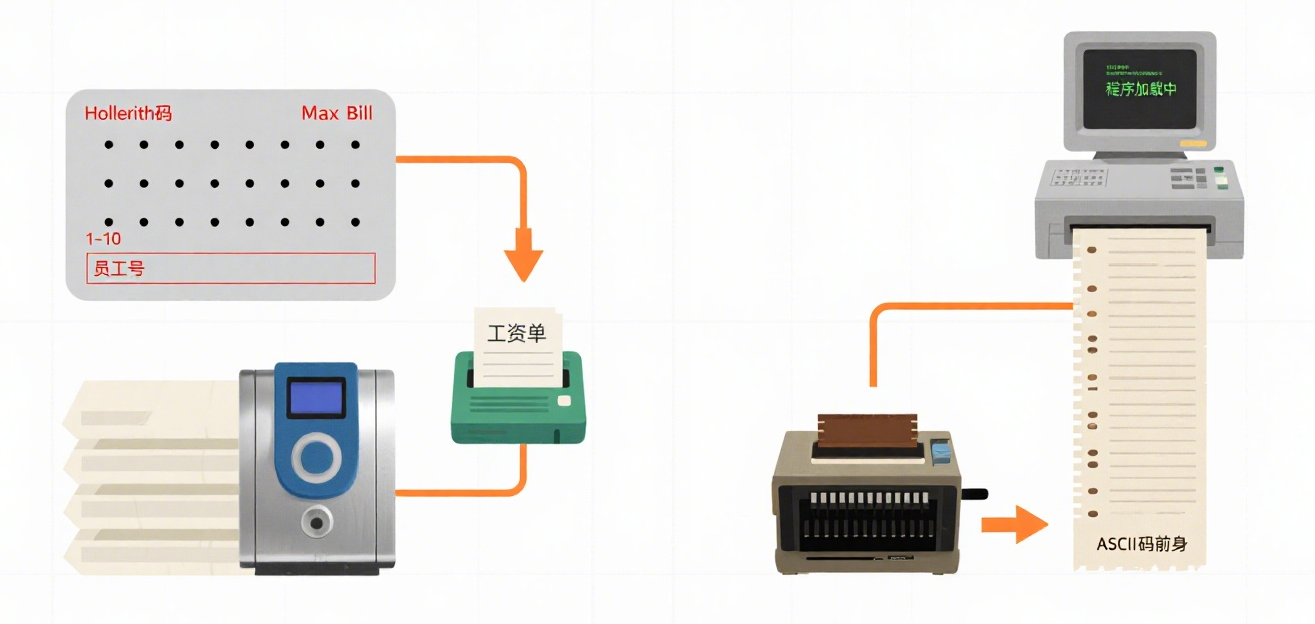
(1)打孔卡片:
在特制的硬紙卡片上,按照特定的編碼規則(如Hollerith碼,用孔的位置代表數字、字母或符號)打孔來表示數據和程序指令。
使用打卡機將數據和程序指令制作成卡片疊。每張卡片通常代表一條記錄或一條指令。 計算機通過讀卡器逐張讀取卡片上的孔洞信息,將其轉換成電信號輸入內存進行計算。計算結果可通過打卡機輸出到新的卡片上,或通過打印機輸出到紙上。
例如,一家工廠的工資系統:每張卡片代表一個員工,記錄其員工號、工作時長、工資率等。程序卡片疊規定了如何計算工資。處理時,讀卡器依次讀入員工卡片和程序卡片進行計算,結果輸出到新的工資卡片或打印出來。
程序員在編寫程序時,必須精確指定:數據在卡片上的哪幾列(Column)代表什么字段(如1-10列是員工號)。
(2)紙帶:
在長條紙帶上打孔(通常一排孔代表一個字符,如ASCII碼的前身)來表示數據和程序。
使用紙帶穿孔機制作紙帶。 計算機通過紙帶閱讀機連續讀取紙帶上的孔信息。 可通過紙帶穿孔機輸出結果紙帶。
常用于在計算機之間或從終端向主機傳輸程序和數據。例如,一個分時系統的用戶終端可能通過紙帶閱讀機將程序加載到主機運行。
(3)總結
打孔卡片是絕對主流,紙帶次之,紙質文檔是外圍輔助。
人工管理階段的核心矛盾: 日益增長的數據處理需求 與 原始、低效、脆弱、緊耦合的物理介質存儲及管理方式 之間的矛盾。正是這個矛盾的激化,加上大容量磁盤的出現,才催生了文件系統這一革命性的解決方案。
(二)文件系統階段
隨著企業規模擴大、業務復雜度增加,以及——最關鍵的是——大容量磁盤等輔助存儲設備的出現,數據的“洪流”開始涌現,人工管理和物理卡片系統徹底不堪重負。
數據量激增、需要長期保存和反復使用的需求日益迫切(比如工資計算每月都要用到員工數據)。
那種“用完即棄”和“翻箱倒柜”的方式走到了盡頭。
技術終于迎來了突破點:專門用于管理輔助存儲設備(主要是磁盤)上數據的軟件——文件系統誕生了! 這就像是為數據修建了第一條“高速公路”。
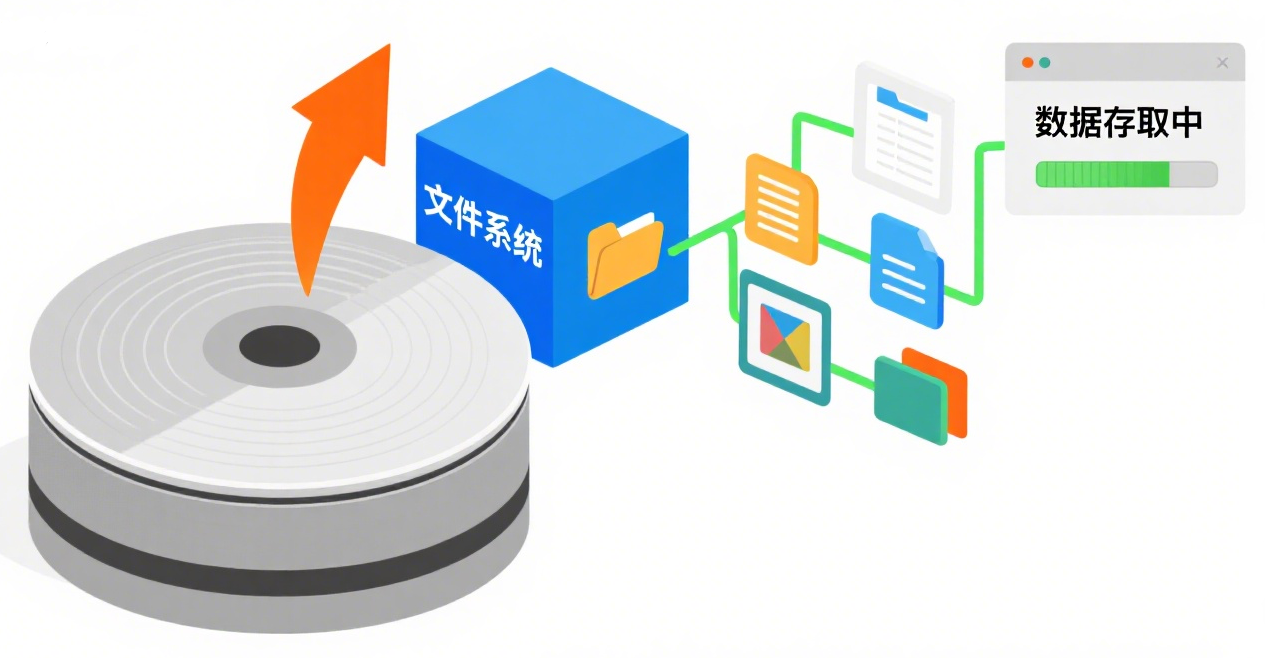
文件系統帶來的核心變革是: 數據可以按一定的邏輯規則(比如按記錄結構)組織成一個文件(如 employees.dat, books.txt)。
應用程序不再需要直接操作物理存儲設備上的復雜細節(扇區、磁道等),而是**通過文件系統提供的統一接口(如打開、讀取、寫入、關閉文件)來訪問和操作文件中的數據。**程序員終于可以從繁瑣的物理存儲管理中解放出來一部分精力。
1.在文件系統階段中數據管理的特點
(1)數據可以長期保留
數據可以長期保存在磁盤上,不再是臨時工。文件系統抽象了磁盤的復雜物理結構(磁道、扇區),程序只需要知道文件名和存取方法(讀、寫),就能找到并操作數據,不用管它具體藏在倉庫的哪個角落(物理位置)。
(2)數據不屬于某個特定的應用
數據不再死死綁定一個程序。同一個數據文件(如員工信息.txt)可以被工資計算程序、考勤統計程序甚至部門通訊錄程序重復使用。數據有了一定的獨立性。
(3)文件組織形式的多樣化
文件系統提供了多種組織文件內部數據的方式:索引文件(像帶目錄的書,快速定位章節)、順序文件/鏈接文件(像串珠,一個接一個找)、Hash文件(像分門別類的抽屜,按關鍵字直接定位)。
但是! 這些文件之間是完全獨立、沒有聯系的。員工信息.txt 和 部門預算.xls 之間沒有任何關聯。想知道某個部門的員工總工資?得寫個程序分別讀兩個文件,自己手動匹配部門ID。
2.文件系統的缺點
(1)數據冗余 (Data Redundancy)
因為文件是圍繞應用建立的,不同應用需要相似數據時,往往各自建一個文件。比如銷售系統有自己的客戶地址.csv,財務系統也有自己的客戶開票地址.txt。相同的數據(客戶地址)被重復存儲多次。
(2)數據不一致性 (Data Inconsistency)
正是由于冗余,當數據發生變化時(如客戶地址更新),如果只修改了部分文件(如只改了銷售部的文件),而其他文件(如財務部的)沒改,就導致了同一個事實在系統中有多個版本,數據不一致。
(3)數據孤立 (Data Isolation)
數據分散在無數格式各異、互不關聯的文件中。文件系統沒有提供機制來描述和建立文件之間、數據之間的聯系(如“員工屬于部門”、“訂單關聯客戶”)。要獲得全局視圖或復雜信息,需要編寫極其復雜的程序去“拼圖”。
3.文件系統的存儲方式
文件:所有數據都被塞進一個個命名好的“檔案袋”(文件)里,扔進倉庫(磁盤)。人事檔案袋(hr.dat),財務賬本袋(finance.xls),各自為政。
索引:為了更快找到袋里某張特定紙(如“員工ID=10086”的記錄),可以單獨建一個“目錄小冊子”(索引文件)。小冊子按ID排序,記錄著每個ID對應的紙在檔案袋里的位置(偏移量)。想找10086?先查小冊子,再直奔檔案袋指定位置!效率大大提升
4.總結
文件系統是數據管理史上的一次巨大飛躍。它讓數據持久化、初步共享,并提供了基礎的組織工具(文件、目錄、索引)。它就像給混亂的數據世界建立了無數個有序的小檔案室。
然而,它的本質局限在于:它只管理“檔案袋”(文件),卻不理解也不管理“檔案袋里的內容”(數據本身)以及“檔案袋之間的關系”(數據語義和聯系)。
它解決了“存哪里、怎么找袋”的問題,但沒解決“袋里裝的是什么?袋子之間有什么關系?”的問題。
它實現了程序與數據的初步解耦(通過文件名),但數據與數據的耦合(聯系)依然要靠程序硬編碼,脆弱且低效。
這就引出了一個核心問題:我們能否建立一個系統,不僅能管理‘檔案袋’(存儲),更能理解‘檔案袋里的內容’(數據含義)和它們之間的‘血緣關系’(數據聯系),并提供統一、高效、安全的方式來操作和利用這些知識?
這個強烈的需求,正是數據庫技術誕生的原動力!
(三)數據庫系統階段
數據庫系統是由計算機軟件、硬件資源組成的系統,它有組織地、動態地存儲大量關聯數據,方便多用戶訪問,它與文件系統重要的區別是數據的充分共享、交叉訪問、與應用程序的高度獨立性。
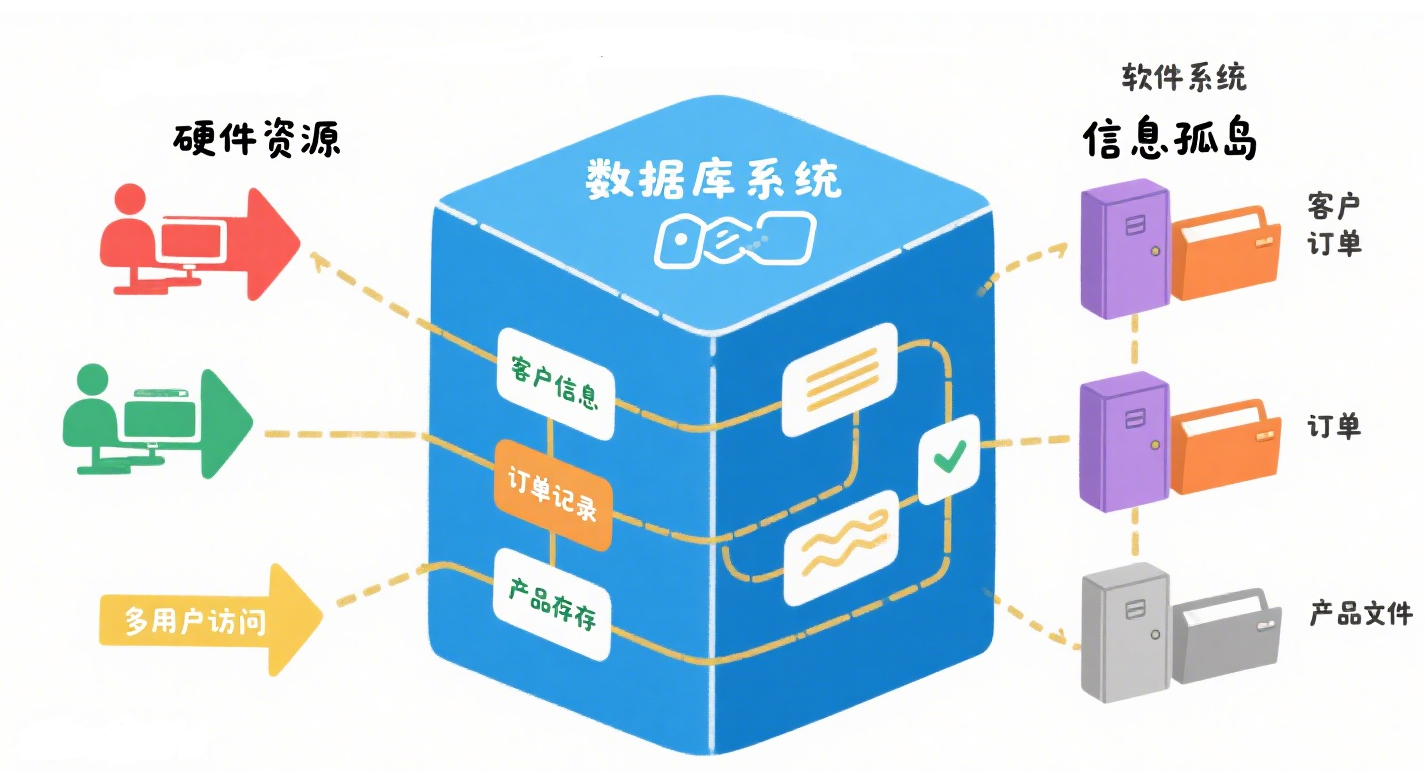
1.數據庫系統階段數據管理的特點
(1)從“孤島”到“大陸”:數據模型與共享
數據模型不僅描述數據本身的特點,還描述數據之間的聯系。數據不再面向某個應用,而是面向整個應用系統。數據冗余明顯減少,實現了數據共享。
想象一下,以前每個部門(應用)都有自己的小倉庫(文件),里面堆滿了重復的貨物(數據冗余),比如財務有員工名單,人事也有員工名單,但格式還不同!數據庫系統就像建造了一個超級智能的中央大倉庫(大陸)。
它用一張精密的“關系地圖”(關系模型)或“對象藍圖”(對象模型)來組織所有貨物(數據),清晰地標出貨物之間的聯系(如“員工”屬于“部門”)。
現在,所有部門都來這個同一個大倉庫取貨,倉庫管理員(DBMS)保證大家看到的是唯一、最新、正確的貨物信息。冗余大大減少,協作效率飆升!
(2)程序與數據的“離婚協議”:數據獨立性
數據庫也是以文件方式存儲數據的,但是它是數據的一種更高級的組織形式,在應用程序和數據庫之間由DBMS 負責數據的存取。 DBMS 對數據的處理方式和文件系統不同,它把所有應用程序中使用的數據以及數據間的聯系匯集在一起,以便于應用程序查詢和使用。
數據庫系統與文件系統的區別是:數據庫對數據的存儲是按照同一種數據結構進行的,不同的應用程序都可以直接操作這些數據(即對應用程序的高度獨立性)。
文件系統時代,程序和數據就像一對“連體嬰”,程序嚴重依賴數據的存放格式和位置。換個硬盤位置或者改個文件結構?程序就得動大手術!
數據庫系統引入了專業的“中介”——DBMS。它制定了一份完美的“離婚協議”(數據獨立性):程序只需要告訴中介“我要什么”(如:查詢所有銷售部的員工),完全不用管數據具體存在哪個硬盤角落、是用表格還是對象存的(物理獨立性),甚至倉庫內部調整了貨架結構(邏輯結構微調,如增加字段),只要程序要的信息不變,程序本身也完全不用改(邏輯獨立性)。
(3)從“混亂集市”到“法治城市”:數據管理與控制
數據庫系統對數據的完整性、一致性和安全性都提供了一套有效的管理手段(即數據的充分共享性)。數據庫系統還提供管理和控制數據的各種簡單操作命令,容易掌握,使用戶編寫程序簡單(即操作方便性)。
文件系統下的數據共享,就像一個混亂的集市:誰都可以隨意改價簽(數據),沒有統一規則,假幣(錯誤數據)可能流通,小偷(未授權訪問)容易得手。數據庫系統則像建立了一個高度法治化的現代城市:
-
統一法典(數據結構): 所有市民(數據)都必須按統一的身份規則(Schema)登記注冊。
-
警察與法官(DBMS): 嚴格執行法律:確保錢貨一致(數據完整性,如年齡不能負數)、全城物價同步(數據一致性,如轉賬時A賬戶扣款和B賬戶加款必須同時成功或失敗)、檢查身份證(安全性,權限控制)。
-
便捷公共服務(SQL): 市民(用戶/程序)只需用簡單通用的語言(SQL)向市政廳(DBMS)提出需求(查詢/更新),就能高效地獲得服務,不用自己滿城跑(操作文件)。
2. 數據庫系統的存儲方式
(1)關系數據庫 (如MySQL, PostgreSQL, Oracle)
想象一個大型電商。Customers表存客戶信息,Orders表存訂單,Products表存商品。它們像精密的齒輪通過ID(主鍵/外鍵)相互咬合。
一個簡單的SQL查詢就能回答:“上海的金牌會員最近一個月買了哪些單價超過500元的電子產品?”——這需要瞬間關聯多個表,精準篩選。體現了結構化數據的強大關聯查詢能力。
(2)NoSQL數據庫 (如MongoDB-文檔, Cassandra-列族, Redis-鍵值):
-
文檔存儲 (MongoDB): 你的整個個人主頁(包含個人信息、發的所有動態、動態下的評論、點贊列表)可以作為一個復雜的JSON文檔直接存儲和讀取。非常適合快速展示個人主頁這種“一次性獲取大量關聯但不太結構化數據”的場景。
-
鍵值存儲 (Redis): 用來存儲用戶的在線狀態(Key: user:12345, Value: online)或者熱門動態的點贊數(Key: post:67890:likes, Value: 1024)。讀寫快到飛起,支撐實時更新。
-
列族存儲 (Cassandra): 存儲海量用戶的行為日志(如瀏覽記錄)。可以按用戶ID快速查詢其所有行為,或者按時間范圍查詢所有用戶的行為(用于大數據分析)。體現了靈活性與處理海量非結構化/半結構化數據、高并發讀寫的優勢。
(3)對象數據庫 (如db4o, ObjectDB - 不如關系/NoSQL主流,但有特定場景):
開發一個復雜的CAD軟件或游戲引擎。一個“3D場景”對象可能包含復雜的幾何網格對象、材質對象、光源對象,它們之間有復雜的繼承和引用關系。
對象數據庫允許程序員直接把內存中的對象“扔”進數據庫持久化,保留其復雜的結構和關系,避免了在關系數據庫中將對象“拆解”成多個表和繁瑣的ORM映射帶來的開銷和復雜性。
體現了與面向對象編程思維的無縫銜接。
(4)索引
就像書本后面的“索引目錄”。沒有目錄,你要找“數據庫”相關內容,得翻遍整本書(全表掃描)。有了目錄(索引),直接翻到第35、89、201頁,瞬間找到!代價是目錄本身要占空間,且增刪書頁時要更新目錄。
(5)視圖
就像一個“定制化的觀察窗”。財務總監需要看公司總營收和各部門成本(一個視圖),HR總監需要看員工薪資分布和績效(另一個視圖)。
他們看到的都是基于底層核心數據(員工表、銷售表、成本表)實時計算組合出來的“虛擬表”,既簡化了他們的操作,又隱藏了不必要的數據細節,保障了核心數據的安全。
二、數據模型
想象一下,你要設計一個圖書館來存放和管理海量的書籍。你需要一個清晰的藍圖來定義:書架如何排列(結構)、讀者如何借閱歸還(操作)、以及借閱規則(約束)。
數據庫管理數據同樣如此,它的核心藍圖就是數據模型——一組用于描述數據如何組織、操作和約束的概念和定義。
數據模型的三要素如同圖書館設計的三個關鍵方面:
(1) 數據結構
數據結構是對象類型的集合,是對系統靜態特性的描述。
這就像圖書館的書架、圖書分類標簽、讀者信息卡的設計。它定義了有哪些“東西”(如“讀者”、“圖書”、“借閱記錄”)以及它們本身的結構(如“讀者”包含姓名、ID、聯系方式)。它關注的是系統在某個時刻的“樣子”或“骨架”。
在關系模型中,數據結構就是“表”的定義(表名、列名、列的數據類型)。
(2) 數據操作
對數據庫中各種對象(型)的實例(值)允許執行的操作集合,包括操作及操作規則。
如操作有檢索、插入、刪除和修改,操作規則有優先級等。數據操作是對系統動態特性的描述。
這規定了讀者能做什么(借書、還書、查詢)、管理員能做什么(上架新書、下架舊書、修改信息)以及這些操作的規則(比如必須先辦卡才能借書)。它關注的是系統如何“動”起來,數據如何被“使用”和“改變”。
SQL語言中的 SELECT (檢索), INSERT (插入), UPDATE (修改), DELETE (刪除) 就是最核心的數據操作。
(3) 數據的約束條件
數據的約束條件是一組完整性規則的集合。也就是說,對于具體的應用數據必須遵循特定的語義約束條件,以保證數據的正確、有效和相容。
這就像圖書館的規則:一本書不能同時被兩個人借走(唯一性約束)、借書證必須有效才能借書(參照完整性)、還書日期不能早于借書日期(業務規則約束)。這些規則確保了圖書館運作的有序和數據的真實可靠。
在數據庫中,約束可以是“員工年齡不能小于18歲”(域約束)、“訂單必須關聯一個存在的客戶”(外鍵約束)、“員工的工號必須唯一”(主鍵約束)。
理解數據模型的演變: 隨著信息需求越來越復雜,圖書館的管理方式也在進化(從簡單卡片柜到電腦系統)。數據庫的發展歷程也類似,按照不同的數據模型,可以分為3個主要階段:
(一)層次和網狀數據庫系統:早期的“樹形”與“蛛網”組織法
最早的數據庫需要高效地管理具有明確父子或復雜關聯的數據,比如組織結構圖(公司-部門-員工)或復雜的設備零件清單。它們像早期的圖書館分類法,要么像一棵樹(層次),要么像一張網(網狀)。
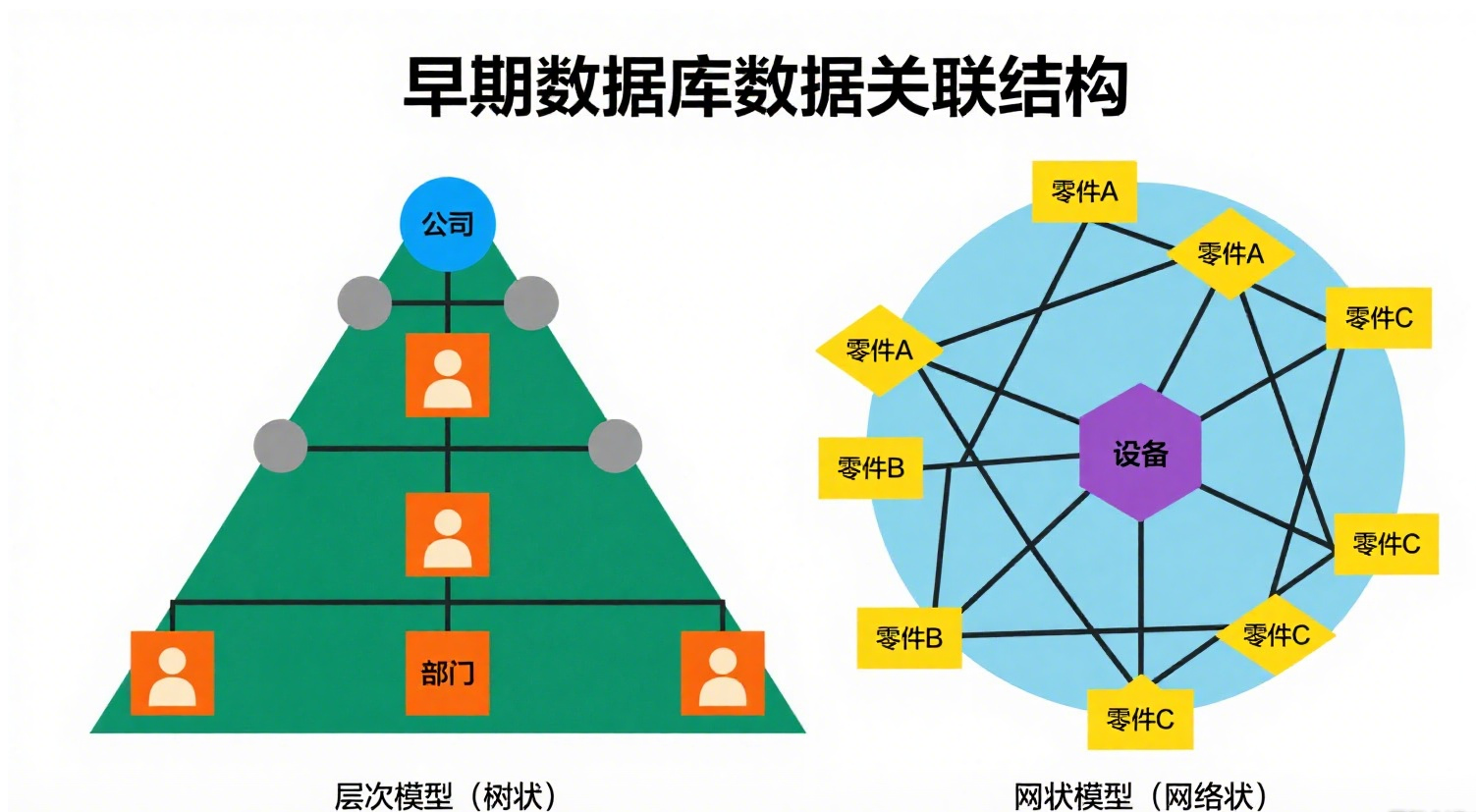
1.層次模型: 采用樹形結構表示數據與數據間的聯系。
每個結點(除根結點)有且僅有一個雙親結點。聯系是嚴格的 1:n (包括 1:1)。
想象一個嚴格的公司架構圖:一個部門(子節點)只能屬于一個公司(父節點),但一個公司可以有多個部門。查詢數據就像沿著這棵樹的固定分支(存取路徑)走。
IBM Information Management System (IMS) - 廣泛應用于早期大型企業(金融、電信),處理如銀行賬戶(賬戶是根,交易記錄是子節點)這類結構清晰的數據。
2.網狀模型: 采用網絡結構表示數據間聯系。
允許一個以上結點無雙親,或一個結點有多個雙親。能更直接描述現實世界(如“復合聯系”)。
不能直接表示多對多(m:n)聯系,需要引入額外的“聯結記錄”(如“選課”表連接“學生”和“課程”)。
想象一個城市交通圖:一個交叉路口(節點)可以連接多條道路(父節點)。查詢數據需要“導航”這張網,路徑可能有多條,但也更復雜。
示例:
CODASYL DBTG Model - 定義了網狀數據庫的標準。
IDMS - 經典網狀系統,用于大型主機環境,如管理復雜的制造業物料清單(一個零件可能被用在多個產品中,一個產品由多個零件組成)。
3.共同特點與局限
都支持三級模式、用存取路徑顯式表示聯系、有獨立的數據定義語言。
導航式數據操縱語言 - 程序員必須像地圖導航一樣,明確指定從一條記錄到另一條記錄的存取路徑(“先找到A,再通過鏈接找到B”)。這增加了編程的復雜性。
想象在層次或網狀圖書館里找一本書,你需要知道它具體在哪個房間的哪個書架的第幾層(依賴物理路徑),而不是像現代圖書館那樣通過書名或作者名(邏輯查詢)直接查找。
| 特性 | 層次數據庫 | 網狀數據庫 |
|---|---|---|
| 數據模型 | 樹形結構 | 網絡結構 |
| 父節點 | 每個子節點有且僅有一個父節點 | 子節點可以有多個父節點 |
| 關系類型 | 1:N (或 1:1) | 支持更復雜關系 (但仍需聯結記錄處理 M:N) |
| 靈活性 | 較低 | 較高 |
| 復雜性 | 較低 | 較高 |
| 查詢路徑 | 固定路徑 | 多路徑 |
| 代表系統 | IBM IMS | IDMS (基于 CODASYL DBTG) |
(二)關系數據庫系統
有沒有一種更簡單、更直觀的方法來組織數據,擺脫復雜的指針和導航?就像用統一的Excel表格來管理圖書館信息,讀者一張表、圖書一張表、借閱記錄一張表,表之間通過ID關聯。
關系模型 (Relation Model) 是目前最常用的數據模型之一。關系數據庫系統采用關系模型作為數據的組織方式,在關系模型中用表格結構表達實體集以及實體集之間的聯系,其最大特色是描述的一致性。
關系模型是由若干個關系模式組成的集合。一個關系模式相當于一個記錄型,對應于程序設計語言中類型定義的概念。
關系是一個實例,也是一張表,對應于程序設計語言中變量的概念。變量的值隨時間可能會發生變化,類似地,當關系被更新時,關系實例的內容也發生了變化。
由于關系模型比網狀、層次模型更為簡單靈活,因此,數據處理領域中,關系數據庫的使用已相當普遍。
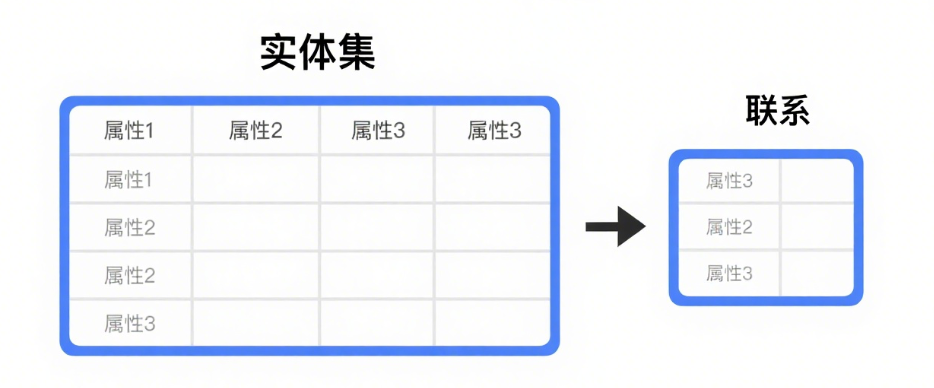
1.關系模型
關系模型用表格結構(關系) 表達實體集及實體集間的聯系,最大特色是描述的一致性(都用表)。
-
關系模式 (Relation Schema): 相當于記錄型的“類型定義”(表頭:列名+數據類型)。定義結構。
-
關系 (Relation): 是關系模式的一個具體實例,是一張有數據的表。內容是動態的(可增刪改)。
為何成功? 關系模型比網狀、層次模型更為簡單靈活。它隱藏了復雜的物理存儲細節和存取路徑,用戶只需關心數據本身及其邏輯關系(通過表連接)。
核心語言:SQL (Structured Query Language) - 強大的聲明式語言,用戶只需說“要什么”(What),而不需指定“怎么取”(How)。
例如,查詢“借了《數據庫導論》這本書的所有讀者姓名”,在關系數據庫中,你只需用SQL描述這個邏輯需求(關聯讀者表、借閱表、圖書表),DBMS會自動找到最優的存取路徑執行。這大大降低了使用和開發的難度。
2.關系數據庫特點:
- 數據獨立性高(邏輯與物理分離)。
- 支持復雜的查詢和強大的事務處理 (ACID)。
- 易于理解和使用(二維表直觀)。
- 提供標準化的SQL語言。
- 能有效處理各種關系(1:1, 1:n, m:n 通過關聯表)。
3.數據庫示例 (驗證其普及性):
Oracle Database - 企業級旗艦,功能全面強大。
MySQL - 開源、輕量、高性能,Web應用最愛。
Microsoft SQL Server - 深度集成Windows生態的企業級方案。
PostgreSQL - 開源、高度可靠、擴展性強,支持高級特性。
4.關系模型的優勢
| 優勢 | 說明 |
|---|---|
| 結構簡單 | 使用直觀的二維表格表示數據 |
| 數據獨立性 | 物理數據存儲與邏輯結構分離 |
| 強大的查詢能力 | 通過SQL實現復雜查詢 |
| 標準化 | SQL成為行業標準查詢語言 |
| 完整性約束 | 提供豐富的數據完整性保障機制 |
| 事務支持 | 支持ACID事務,保證數據一致性 |
(三)第三代數據庫系統
互聯網、物聯網、社交媒體的爆炸式增長帶來了新挑戰:數據量巨大(Volume)、類型繁多(Variety - 文本、圖片、視頻、日志)、產生速度極快(Velocity)、價值密度低(Value)——即大數據。
傳統的關系數據庫,為處理規整的事務型數據設計,在面對這些新型應用(如海量用戶動態、實時傳感器流、復雜對象關系圖)時,開始顯得力不從心。
從20世紀80年代開始,出現了許多新型應用,數據管理出現了許多新的數據模型,如面向對象模型、語義數據模型、 XML 數據模型、半結構化數據模型等。數據模型的發展,需要數據庫系統支持日益復雜的數據類型。其中最典型的是No SQL(Not Only of SQL)運動。
1.NoSQL運動的興起:
名稱演變: 最初(1998)指“無SQL”的關系庫 -> 后來(2009)主要指非關系型、分布式、不嚴格遵循ACID的設計模式。普遍解釋為 “Not Only SQL” 或 “非關聯型”。
驅動力: Web 2.0/社交網絡(SNS)的超大規模、高并發、動態、半/非結構化數據需求。關系數據庫的擴展性(尤其是水平擴展)、寫入性能、靈活模式成為瓶頸。
核心理念: “select fun, profit from real_world where relational=false;” - 在關系模型不適用或低效的現實場景中選擇合適的工具。
目標: 解決大規模數據集合和多重數據種類帶來的挑戰,特別是大數據應用難題。通常優先考慮可擴展性、性能和靈活性,在一致性上可能妥協(最終一致性)。
第三代數據庫主要類型:
2.對象數據庫
數據模型:對象數據庫將數據存儲為對象,類似于面向對象編程中的對象。每個對象包含數據和方法。
特點:
- 支持復雜的數據類型和面向對象的特性。
- 與面向對象編程語言集成度高,便于開發。
- 適合需要復雜數據結構和行為的應用。
示例:
ObjectDB:開源的對象數據庫管理系統,支持Java持久化API (JPA) 和 Java Data Objects (JDO)。
db4o (database for objects):開源的對象數據庫,支持多種編程語言,如Java和.NET。
3.NoSQL數據庫 (多種模型):
數據模型:NoSQL數據庫不使用傳統的表格形式,而是采用更加靈活的數據模型,如鍵值對、文檔、列族或圖形。
特點:
- 高可擴展性,適合大規模分布式環境。
- 靈活的數據模型,支持非結構化和半結構化數據。
- 通常不支持完整的ACID事務,但提供最終一致性。
示例:
MongoDB:文檔型NoSQL數據庫,使用BSON格式存儲數據,支持動態模式和豐富的查詢功能。
Cassandra:列族存儲的NoSQL數據庫,設計用于處理大規模數據集,具有高可用性和水平擴展性。
Redis:內存數據存儲,可以用作數據庫、緩存和消息中間件,支持多種數據結構如字符串、哈希、列表等。
Neo4j:圖形數據庫,專門用于處理復雜的圖形數據和關系,適用于社交網絡、推薦系統等領域。
4.為什么NOSQL數據庫比關系型數據庫更適合大型分布式系統?
| 特性 | NoSQL數據庫 | 關系型數據庫 (RDBMS) | 為什么NoSQL更優 (在特定場景下) |
|---|---|---|---|
| 數據模型 | 靈活 (鍵值、文檔、列、圖) | 固定/嚴格 (表格,需預定義Schema) | 適應快速變化、非/半結構化數據,無需昂貴Schema變更。 |
| 擴展方式 | 水平擴展 (添加節點) 為主,天然分布式設計 | 垂直擴展 (升級單機) 為主,水平擴展 (分庫分表) 復雜 | 輕松應對海量數據和高流量,成本更低廉。 |
| 一致性模型 | 通常最終一致性 (優先保證可用性和分區容忍性) | 強一致性 (ACID事務) | 在分布式環境下,強一致性會嚴重限制性能和可用性。 |
| 讀寫性能 | 極高 (尤其特定模式,如Key訪問、批量寫) | 高 (但復雜Join、事務會成瓶頸) | 滿足高并發、低延遲需求,尤其寫入密集型場景。 |
| 管理與運維 | 更簡單 (自動化分片、復制、恢復) | 更復雜 (尤其大規模集群的分片、復制、備份) | 降低大規模分布式系統的運維成本和復雜性。 |
(1)數據模型的靈活性
NoSQL數據庫通常支持靈活的數據模型,如鍵值對、文檔、列族或圖形。關系型數據庫使用固定的數據模型(表格形式),并且需要預先定義好表結構(模式)。這種嚴格的模式要求在擴展時可能會變得復雜。
(2)水平擴展能力
NoSQL數據庫通常設計為可以輕松進行水平擴展,即通過增加更多的服務器節點來提高系統的處理能力和存儲容量。傳統的關系型數據庫通常是垂直擴展的,即通過增加單個服務器的硬件資源(如CPU、內存、磁盤)來提高性能。
(3)一致性和容錯性
NoSQL數據庫通常采用最終一致性模型,這意味著在某些情況下,系統可以在一段時間內容忍不一致的狀態,以換取更高的可用性和性能。關系型數據庫通常遵循ACID(原子性、一致性、隔離性、持久性)事務原則,保證了強一致性。強一致性要求在分布式環境中實現起來更加復雜,特別是在跨多個節點的情況下。
(4)寫入和讀取性能。
NoSQL數據庫通常優化了寫入和讀取性能,尤其是在高并發環境下。例如,Redis作為一個內存數據庫,提供了極高的讀寫速度。關系型數據庫在處理大量并發寫入和讀取時可能會遇到瓶頸,尤其是在需要執行復雜的聯接操作時。雖然關系型數據庫也有優化措施(如索引、緩存等),但在大規模分布式環境中,這些優化可能不足以滿足高性能需求。
(5)管理和運維
NoSQL數據庫通常設計為易于管理和運維,自動化的數據分布和故障恢復機制減少了手動干預的需求。關系型數據庫在大規模分布式環境中可能需要更多的手動配置和管理,特別是在數據復制、備份、恢復等方面。
(四)核心術語解析
理解了數據模型和數據庫類型,讓我們明確幾個最基礎但至關重要的術語,它們是理解整個數據庫領域的基石。
1.數據 (Data):
描述事物的符號記錄。形式多樣:文字、數字、圖形、圖像、聲音等。
案例: “25℃", “張三”, “https://example.com/photo.jpg” 都是數據。
2.信息 (Information)
信息是數據經過處理后得到的、對接收者具有特定意義和價值的結果。它是現實世界事物存在方式或狀態的反映。
今天氣溫25℃” 是數據,結合“人體舒適溫度是22-26℃”這個知識,你就得到了“今天天氣舒適”這個信息。信息能減少不確定性、輔助決策。
數據是信息的載體和表現形式,信息是數據的含義和價值體現。
3.數據庫 (DB, DataBase)
長期儲存在計算機內、有組織的、可共享的、統一管理的相關數據的集合。
數據間聯系密切、冗余度小、獨立性較高、易擴展、可共享。
存儲數據的物理介質(硬盤、SSD)及其上按模型組織的數據本身。
4.數據庫管理系統 (DBMS, DataBase Management System)
位于用戶和操作系統之間的一層數據管理軟件。它是數據庫系統的核心。
科學組織存儲數據、高效獲取維護數據。核心功能包括:
- 數據定義 (DDL): 定義數據庫結構 (創建/修改表等)。
- 數據操縱 (DML): 查詢、插入、刪除、修改數據 (SQL的核心)。
- 數據庫運行管理: 并發控制、安全性檢查、完整性檢查、故障恢復等。
- 數據庫維護: 備份、恢復、性能監控、重組等。
5.數據庫系統 (DBS, DataBase System):
采用數據庫技術存儲和管理數據的計算機系統。廣義上,它包括:
- 數據庫 (DB)
- 數據庫管理系統 (DBMS)
- 應用系統
- 數據庫管理員 (DBA)
- 用戶
簡單理解: DBS = DB + DBMS + 相關的軟硬件和人。
關鍵關系比喻:
-
DB 是圖書館的藏書庫(書+書架)。
-
DBMS 是圖書館的管理系統(借還書流程、管理員、編目規則)。
-
DBS 是整個圖書館實體(書庫+管理系統+管理員+讀者+借閱規則)。
三、數據庫管理系統
想象一下,如果一個公司沒有統一的倉庫,每個部門都用自己的Excel表存放數據:銷售部存一份客戶信息,財務部存另一份,兩邊的數據還經常對不上。這簡直就是一場數據災難!
而數據庫管理系統(DBMS)就是這個混亂世界的救星。
DBMS 實現了對共享數據有效地組織、管理和存取,因此DBMS應具有如下幾個方面的功能及特征。
(一)DBMS功能
DBMS功能主要包括數據定義、數據庫操作、數據庫運行管理、數據組織、存儲和管理、數據庫的建立和維護。
1.數據定義(DDL)
DBMS提供數據定義語言 (Data Definition Language,DDL), 可以對數據庫的結構進行描述,包括外模式、模式和內模式的定義;數據庫的完整性定義;安全保密定義,如口令、級別和存取權限等。
DDL不是操作數據本身,而是定義數據的“形狀”和“規則”。
-- 1.創建表 (定義結構)
-- 請你準備一個表格,規定好:
-- 必須有三列:ID(數字,主鍵)、名字(字符串,非空)、郵箱(字符串,唯一)
-- 這就是規矩,以后所有數據都得按這個來”
CREATE TABLE users (id INT PRIMARY KEY,name VARCHAR(100) NOT NULL,email VARCHAR(100) UNIQUE
);
-- 2. 修改表結構
-- “還得記錄用戶的手機號,在表格里加一列”
ALTER TABLE users ADD COLUMN phone VARCHAR(20);-- 3. 刪除表
-- “整個`users`表我不要了,連規矩帶數據全扔掉”
DROP TABLE users;
這些定義存儲在數據字典中,是 DBMS 運行的基本依據。
DDL就是你用來設計和建造倉庫貨架(數據庫結構)的工具,而不是往貨架上放貨物(數據)。
2.數據庫操作(DML)
DBMS 向用戶提供數據操縱語言 (Data Manipulation Language,DML), 實現對數據庫中數據的基本操作,如檢索、插入、修改和刪除。
-- 1. 檢索 (Retrieve) - SELECT
SELECT * FROM users WHERE name = '小王';-- 2. 插入 (Insert) - INSERT
INSERT INTO users (name, email) VALUES ('小李', 'lw@example.com');-- 3. 修改 (Update) - UPDATE
UPDATE users SET email = 'wang.new@example.com' WHERE name = '小王';-- 4. 刪除 (Delete) - DELETE
DELETE FROM users WHERE name = '小李';
3.數據庫運行管理。
數據庫在運行期間,多用戶環境下的并發控制、安全性檢查和存取控制、完整性檢查和執行、運行日志的組織管理、事務管理和自動恢復等都是DBMS 的重要組成部分。這些功能可以保證數據庫系統的正常運行。
防止“超賣”的經典案例:假設有兩個用戶同時試圖購買最后一件商品。
-- 事務 (Transaction) 開始
BEGIN TRANSACTION;-- 1. 用戶A的會話執行:查詢庫存,結果是1
SELECT stock FROM products WHERE id = 123; -- stock = 1-- 2. 幾乎同時,用戶B的會話也執行了同樣的查詢,看到的stock也是1
SELECT stock FROM products WHERE id = 123; -- stock = 1-- 3. 用戶A下單,庫存減1
UPDATE products SET stock = stock - 1 WHERE id = 123;
COMMIT; -- 提交事務,庫存變為0-- 4. 用戶B也下單,試圖庫存減1
UPDATE products SET stock = stock - 1 WHERE id = 123; -- 此時庫存已經是0了!
COMMIT;
-- 如果沒有并發控制,庫存就會變成-1,這就是“超賣”
4.數據組織、存儲和管理。
DBMS 分類組織、存儲和管理各種數據,包括數據字典、用戶數據和存取路徑等。
要確定以何種文件結構和存取方式在存儲級別上組織這些數據,以提高存取效率。
實現數據間的聯系、數據組織和存儲的基本目標是提高存儲空間的利用率。
例如,baidu要索引整個互聯網的數據。它不可能每次搜索都去掃描幾十億個網頁。DBMS(或類似系統)會以極其高效的方式(如倒排索引)組織和存儲數據,讓你在毫秒級內得到結果。
5.數據庫的建立和維護。
數據庫的建立和維護,包括數據庫的初始建立、數據的轉換、數據庫的轉儲和恢復、數據
庫的重組和重構、性能監測和分析等。
6.其他功能。
如DBMS 與網絡中其他軟件系統的通信功能,一個DBMS 與另一個 DBMS或文件系統的數據轉換功能等。
(二) DBMS 的特點
通過 DBMS來管理數據具有如下特點:
1.數據結構化且統一管理。
數據庫中的數據由DBMS統一管理。由于數據庫系統采用數據模型表示數據結構,數據模型不僅描述數據本身的特點,還描述數據之間的聯系。
數據不再面向某個應用,而是面向整個企業內的所有應用。數據易維護、易擴展,數據冗余明顯減少,真正實現了數據的共享。
(1)無DBMS(文件系統)的問題:
假設一個公司,銷售部用 sales.txt 文件管理客戶,客服部用 support.csv 文件管理客戶。
- 數據冗余:兩個文件都存了客戶的姓名、電話,造成重復。
- 數據不一致:銷售部更新了客戶的電話,但客服部的文件還是舊號碼。
- 孤立數據:銷售部的文件里有客戶的購買記錄,客服部無法直接獲取和使用這個信息。
- 程序依賴數據存儲方式:如果
sales.txt的格式從逗號分隔改成制表符分隔,所有讀取這個文件的程序都需要重寫。
(2)有DBMS的解決方案:
DBMS讓我們可以建立結構化的、互相關聯的表。
-- 1. 數據定義:建立結構化的、有關聯的表
-- “客戶”表,存儲所有客戶的核心信息
CREATE TABLE customers (customer_id INT PRIMARY KEY, -- 主鍵,唯一標識一個客戶name VARCHAR(100) NOT NULL,phone VARCHAR(20) NOT NULL
);-- “訂單”表,存儲客戶的購買記錄
CREATE TABLE orders (order_id INT PRIMARY KEY,order_date DATE NOT NULL,amount DECIMAL(10, 2) NOT NULL,customer_id INT NOT NULL, -- 外鍵,指向 customers 表的 customer_idFOREIGN KEY (customer_id) REFERENCES customers(customer_id) -- 建立外鍵關系
);-- “服務工單”表,存儲客戶的支持請求
CREATE TABLE support_tickets (ticket_id INT PRIMARY KEY,issue_description TEXT,status VARCHAR(20),customer_id INT NOT NULL, -- 外鍵,同樣指向 customers 表FOREIGN KEY (customer_id) REFERENCES customers(customer_id) -- 建立外鍵關系
);
-
統一管理,共享數據:銷售部和客服部都通過DBMS操作唯一的 customers 表。客戶的電話在這里只存一份,任何部門修改,其他部門看到的就是最新數據。
-
數據關聯:我們可以輕松地查詢出“所有下過訂單但從未提交過服務工單的優質客戶”:
-
易維護和擴展:如果需要給客戶增加一個“會員等級”屬性,只需一條SQL,所有程序都能立即使用這個新字段,而無需改變程序讀取數據的方式。
2.有較高的數據獨立性。
數據的獨立性是指數據與程序獨立,將數據的定義從程序中分離出去,由 DBMS負責數據的存儲,應用程序關心的只是數據的邏輯結構,無須了解數據在磁盤上的存儲形式,從而簡化應用程序,大大減少應用程序編制的工作量。
數據的獨立性包括數據的物理獨立性和數據的邏輯獨立性。
(1)物理獨立性:改變存儲結構,不影響應用程序
指數據的物理存儲結構(如硬盤上的文件格式、索引類型、存儲路徑)的改變,不需要修改應用程序。
假設我們一開始的數據沒有索引,查詢很慢。
-- 應用程序的查詢語句
SELECT * FROM orders WHERE customer_id = 123;
-- DBA 在后臺執行的優化操作,應用程序完全無感知
CREATE INDEX idx_orders_customer_id ON orders (customer_id);
之后同樣的 SELECT 查詢語句,速度得到了巨大提升,但應用程序的代碼一行都不用改。DBMS自動選擇了更高效的存取路徑(使用新索引)來執行這條查詢。
反之亦然,DBA甚至可以決定把 orders 表從一個硬盤遷移到另一個更快的SSD硬盤上,應用程序也完全感覺不到變化。
(2)邏輯獨立性:改變邏輯結構,盡可能不影響應用程序
指數據庫的邏輯結構(如表結構、視圖)發生改變,理論上可能影響應用程序,但DBMS提供了機制(如視圖)來盡量減少這種影響。
假設我們最初的 customers 表有很多字段,但某個應用程序只需要 name 和 phone。
-- 應用程序的查詢語句
SELECT name, phone FROM customers;
后來,業務需求變化,我們需要將 customers 表拆分成 customer_details 和 customer_contacts 兩個表。
-- 數據庫結構變更
CREATE TABLE customer_details (customer_id INT PRIMARY KEY,name VARCHAR(100)-- ... 其他字段
);
CREATE TABLE customer_contacts (customer_id INT PRIMARY KEY,phone VARCHAR(20)-- ... 其他字段
);
如果我們直接刪除舊的 customers 表,那么之前那個應用程序的查詢就會報錯,因為它依賴的表不存在了。這就是邏輯依賴。
DBMS如何提供邏輯獨立性?—— 使用視圖(View)。
我們可以創建一個名為 customers 的視圖,它模擬出原來表的結構。
CREATE VIEW customers AS
SELECT d.customer_id, d.name, c.phone
FROM customer_details d
JOIN customer_contacts c ON d.customer_id = c.customer_id;
之后,應用程序依然執行 SELECT name, phone FROM customers;,它甚至不知道自己查詢的不再是一張真實的表,而是一個視圖。DBMS會自動將查詢轉換成對底層 customer_details 和 customer_contacts 表的連接操作。
這樣,雖然數據庫的邏輯結構發生了巨大變化(表被拆分),但通過視圖這個抽象層,保護了上層的應用程序免受影響,這就是邏輯獨立性。
3.數據控制功能。
DBMS提供了數據控制功能,以適應共享數據的環境。數據控制功能包括對數據庫中數據的安全性、完整性、并發和恢復的控制。
(1)安全性
數據庫的安全性 (Security) 是指保護數據庫以防止不合法的使用所造成的數據泄露、更改或破壞。這樣,用戶只能按規定對數據進行處理,例如,劃分了不同的權限,有的用戶只有讀數據的權限,有的用戶有修改數據的權限,用戶只能在規定的權限范圍內操縱數據庫。
-- 1. 管理員給不同用戶授權
-- “管家,讓實習生`intern01`只有讀`users`表的權限”
GRANT SELECT ON users TO intern01;-- “管家,讓經理`manager01`可以讀、可以改`users`表”
GRANT SELECT, INSERT, UPDATE ON users TO manager01;-- 2. 實習生`intern01`試圖刪表,會直接被管家拒絕
DELETE FROM users; -- 執行錯誤: Access denied (權限不足)
(2)完整性 (Integrality)
數據的完整性是指數據庫正確性和相容性,是防止合法用戶使用數據庫時向數據庫加入不符合語義的數據。保證數據庫中數據是正確的,避免非法的更新。
-- 1. 非空約束 (NOT NULL)
-- 試圖插入一個沒有名字的用戶,管家會拒絕
INSERT INTO users (id, email) VALUES (1, 'test@example.com'); -- 錯誤!-- 2. 唯一約束 (UNIQUE)
-- 試圖插入一個重復的郵箱,管家會拒絕
INSERT INTO users (id, name, email) VALUES (2, '小張', 'wang.new@example.com'); -- 錯誤!郵箱和‘小王’的一樣了
(3)并發控制 (concurrency control)
并發控制是指在多用戶共享的系統中,許多用戶可能同時對同一數據進行操作。 DBMS的并發控制子系統負責協調并發事務的執行,保證數據庫的完整性不受破壞,避免用戶得到不正確的數據。
DBMS管家會使用鎖(Locking) 或多版本并發控制(MVCC) 等機制。比如,在用戶A開始修改庫存時,DBMS會自動給這條數據加上鎖,用戶B的更新操作必須等待,直到用戶A的鎖釋放(事務提交)后才會繼續。此時用戶B看到庫存已是0,更新就會失敗,從而保證了數據的一致性。
(4)故障恢復 (recovery from failure)
數據庫中的常見故障是事務內部故障、系統故障、介質故障及計算機病毒等。故障恢復主要是指恢復數據庫本身,即在故障導致數據庫狀態不一致時,將數據庫恢復到某個正確狀態或一致狀態。
-- 一個銀行轉賬事務:從A賬戶轉100元到B賬戶
BEGIN TRANSACTION; -- 事務開始UPDATE accounts SET balance = balance - 100 WHERE name = 'A';
UPDATE accounts SET balance = balance + 100 WHERE name = 'B';-- 此時,系統突然斷電!
- 沒有DBMS的情況:A的錢扣了,B的錢沒收到,100元不翼而飛。
- 有DBMS的情況:DBMS管家在做事務時,會先把要做的操作(“A-100”, “B+100”)記錄到日志文件中。斷電重啟后,管家檢查日志,發現這個事務沒有完成(COMMIT記錄)。它會自動利用日志回滾(ROLLBACK) 這個未完成的事務,將A的賬戶余額加回100元,就像這個轉賬從來沒發生過一樣。這就保證了交易的原子性——要么完全發生,要么完全不影響系統。
恢復的原理非常簡單,就是要建立冗余 (redundancy) 數據。
換句話說,確定數據庫是否可恢復的方法就是其包含的每一條信息是否都可以利用冗余的存儲在別處的信息重構。
四、數據庫三級模式
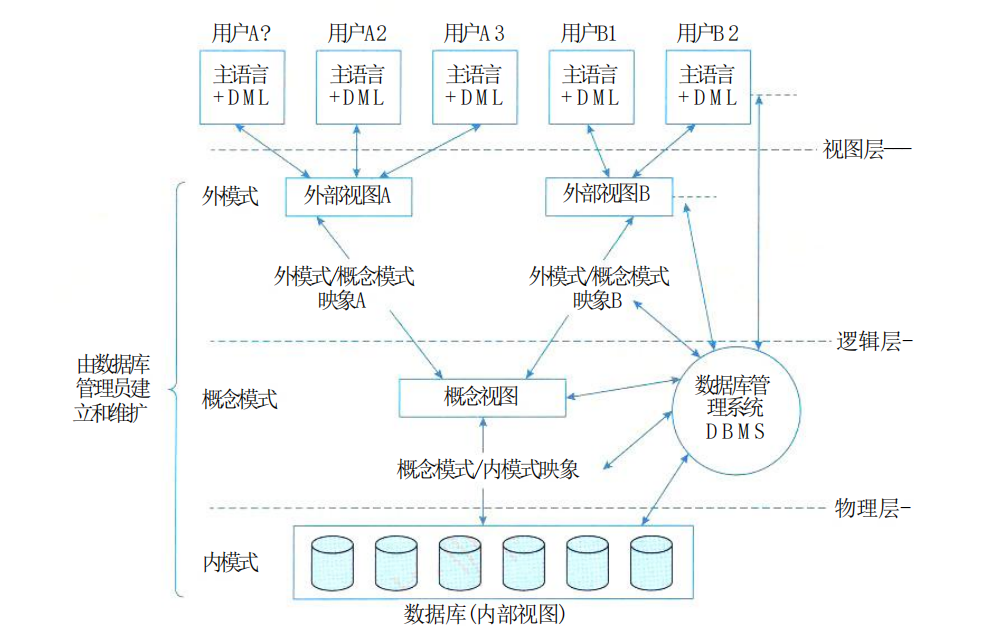
站在數據庫管理系統的角度看,數據庫系統一般采用三級模式結構,其體系結構如圖所示。
事實上,一個可用的數據庫系統必須能夠高效地檢索數據。這種高效性的需求促使數據庫設計者使用復雜的數據結構來表示數據。
可以把一個數據庫想象成一座繁華的城市。城市規劃局需要管理這座城市的方方面面,但不同的人需要看到城市的不同視圖:
-
游客:只關心景點、餐廳和酒店(外模式)。
-
市長/城市規劃師:關心城市的整體布局、功能區劃分和建筑規范(概念模式)。
-
市政工程師:關心地下管線、地基結構、建筑材料(內模式)。
數據庫的三級模式結構正是為了高效、安全地管理這座“數據城市”而設計的藍圖。
(二)三級模式結構
數據庫系統采用三級模式結構,這是數據庫管理系統內部的系統結構。
數據庫有“型”和“值”的概念,“型”是指對某一數據的結構和屬性的說明,“值”是型的一個具體賦值。
從數據庫管理系統的角度,數據庫也分為三級模式,分別是外模式、概念模式和內模式。
1.概念模式
概念模式也稱模式,是數據庫中全部數據的邏輯結構和特征的描述,它由若干個概念記錄類型組成,只涉及“型”的描述,不涉及具體的值。
概念模式的一個具體值稱為模式的一個實例,同一個模式可以有很多實例。
概念模式反映的是數據庫的結構及其聯系,所以是相對穩定的;而實例反映的是數據庫某一時刻的狀態,是相對變動的。
數據庫管理員 (DBA) 使用 DDL 來定義概念模式。
-- 定義訂單表的結構
CREATE TABLE Orders (OrderID INT PRIMARY KEY,OrderDate DATE NOT NULL,TotalAmount DECIMAL(10, 2),UserID INT NOT NULL, -- 這條“路”連接回Users區FOREIGN KEY (UserID) REFERENCES Users(UserID) -- 外鍵約束,定義“聯系”
);
這個模式定義了數據的結構和規則。任何應用程序如果想在這個城市里“建房”或“修路”(操作數據),都必須遵守這些規劃。它是系統中最穩定、最核心的一層。
需要說明的是,概念模式不僅要描述概念記錄類型,還要描述記錄間的聯系、操作、數據的完整性和安全性等要求。
但是,概念模式不涉及存儲結構、訪問技術等細節。只有這樣,概念模式才算做到了“物理數據獨立性”。
2.外模式
外模式也稱用戶模式或子模式,是用戶與數據庫系統的接口,是用戶需要使用的部分數據的描述。它由若干個外部記錄類型組成。
用戶使用數據操縱語言對數據庫進行操作,實際上是對外模式的外部記錄進行操作。
使用 VIEW 來創建外模式。
-- 為銷售人員創建一個視圖(外模式)
-- 他們只需要看到客戶姓名和訂單金額,不需要看到客戶的郵箱等敏感信息
CREATE VIEW SalesView AS
SELECT u.UserName AS CustomerName,o.OrderDate,o.TotalAmount
FROM Users u
INNER JOIN Orders o ON u.UserID = o.UserID;-- 銷售人員可以像查詢普通表一樣使用這個視圖,完全不知道底層復雜的連接
SELECT * FROM SalesView WHERE TotalAmount > 1000;
每個視圖都是從總體規劃(概念模式)中派生出來的子集或轉換,它屏蔽了不需要的細節,并保證了安全性。
通過外模式,你可以輕松地創建一個視圖,其中自動過濾掉了所有未明確同意營銷條款的用戶數據。應用程序無需修改任何代碼,只需查詢這個視圖,就能天然地遵守數據隱私法規。這就是邏輯數據獨立性的威力——修改邏輯結構(增加隱私控制)而不影響應用程序。
3.內模式
內模式也稱存儲模式,是數據物理結構和存儲方式的描述,是數據在數據庫內部的表示方式。定義所有的內部記錄類型、索引和文件的組織方式,以及數據控制方面的細節。
內模式通常由 DBA 通過特定的 SQL 擴展來定義和優化。
-- 在‘Users’表的‘UserName’列上創建一個索引,就像為城市制作一個姓名目錄
-- 這樣按名字查找用戶的速度會極大提高
CREATE INDEX idx_users_username ON Users (UserName);-- 為‘Orders’表選擇一種特定的存儲引擎(MySQL示例)
-- 這決定了數據在磁盤上如何被組織、索引和緩存
ALTER TABLE Orders ENGINE = InnoDB;-- 配置數據庫的物理文件布局(通常在生產環境初始化時設定)
-- 例如:將頻繁訪問的‘Orders’表的數據文件放在更快的SSD硬盤上,
-- 而將歸檔的日志表放在更大的機械硬盤上。
-- (這通常是數據庫配置文件的設置,而非標準SQL)
應用程序和普通用戶完全看不到也不需要關心內模式。無論工程師是把數據從HDD遷移到SSD,還是改變索引類型,只要概念模式不變,上層應用就毫無感知。這就是物理數據獨立性。
總之,數據按外模式的描述提供給用戶,按內模式的描述存儲在磁盤上,而概念模式提供了連接這兩極模式的相對穩定的中間觀點,并使得兩級的任意一級的改變都不受另一級的牽制。
(二)三層架構
由于大多數數據庫系統用戶并未受過計算機的專業訓練,因此系統開發人員需要通過視圖層、邏輯層和物理層三個層次上的抽象來對用戶屏蔽系統的復雜性,簡化用戶與系統的交互。
1.視圖層 (View Level)
視圖層是最高層次的抽象,描述整個數據庫的某個部分的數據。
因為數據庫系統的很多用戶并不關心數據庫中的所有信息,而只關心所需要的那部分數據。可以通過構建視圖層來實現用戶的數據需求,這樣做不僅使用戶與系統交互簡化,而且還可以保證數據的保密性和安全性。
例子:
- 普通顧客看到的商品列表(只包含商品名、圖片、售價、評分)。
- 商家后臺看到的則是另一個視圖(包含成本、庫存、月銷量)。
- 物流人員看到的又是另一個視圖(僅包含訂單號、收貨地址、配送狀態)。
每個用戶只能看到和理解他們需要的數據,界面簡單友好,同時也保證了數據安全(顧客看不到商品的成本,物流看不到商品的價格)。
2.邏輯層 (Logical Level)
邏輯層是比物理層更高一層的抽象,描述數據庫中存儲的數據以及這些數據間存在的關系。
邏輯層通過相對簡單的結構描述了整個數據庫。盡管邏輯層簡單結構的實現涉及了復雜的物理層結構,但邏輯層的用戶不必知道這些復雜性。因為,邏輯層抽象是數據庫管理員的職責,管理員確定數據庫應保存哪些信息。
例如:數據庫中的表結構(Schema)。
-- 這就是在定義邏輯層的結構
CREATE TABLE Users (user_id INT PRIMARY KEY,username VARCHAR(50),email VARCHAR(100)
);
CREATE TABLE Products (product_id INT PRIMARY KEY,product_name VARCHAR(100),price DECIMAL(10, 2)
);
CREATE TABLE Orders (order_id INT PRIMARY KEY,user_id INT,order_date DATE,FOREIGN KEY (user_id) REFERENCES Users(user_id) -- 定義了“關系”
);
數據庫管理員(DBA)和應用程序開發者關心這一層。他們用SQL語句(如 SELECT * FROM Orders WHERE user_id = 123;)來操作數據,而無需關心數據是存在SSD硬盤還是機械硬盤上。
3.物理層 (Physical Level)
物理層是最低層次的抽象,描述數據在存儲器中是如何存儲的。物理層詳細地描述復雜的底層結構。
例子:
- 數據是以堆文件形式存儲,還是B+樹索引形式組織?
- 數據文件在磁盤的哪個塊(Block)上?
- 是否使用了數據壓縮或加密技術?
數據庫系統本身負責這一層,目標是實現最高效的存儲和檢索。用戶和開發者完全感知不到它的存在。
比如,你執行一條查詢語句,數據庫引擎會自動決定是走全表掃描還是使用索引,這個過程對你是透明的。而像excel表或txt文件,比如改下從ASCII到Unicode的編碼,程序就需要重新讀取文件了。
實際上,數據庫的產品很多,它們支持不同的數據模型,使用不同的數據庫語言,建立在不同的操作系統上,而且數據的存儲結構也各不相同,但基本上都支持三級模式。
| 三層架構 (為用戶抽象) | 三級模式 (在DBMS內實現) | 比喻 | 主要操作者 |
|---|---|---|---|
| 視圖層 | 外模式 (Views) | 房間的窗戶 | 最終用戶 |
| 邏輯層 | 概念模式 (Tables, Schema) | 建筑藍圖 | 開發者、DBA |
| 物理層 | 內模式 (Indexes, Storage) | 建材與地基 | DBMS自身、資深DBA |





)


)




)





