【引言】企業實時數據流轉,迎來“集成+計算”新范式
企業 IT 架構的演進,從最初的數據孤島,到集中式數據倉庫,再到如今的實時數據驅動架構。在這一過程中,數據的集成(數據源→目標)與數據的計算(數據變化的處理與應用)成為兩大核心需求。
TapData 和 Kafka,正是在這兩大方向中最具代表性的技術:
- TapData:異構數據的整合、清洗、治理專家
- Kafka:消息傳輸與事件驅動計算的高速通道
企業在數據架構選型時,常將二者對比,甚至被問:“誰替代誰?”
答案是:兩者并非替代,而是最佳拍檔。
一、目標受眾與常見痛點

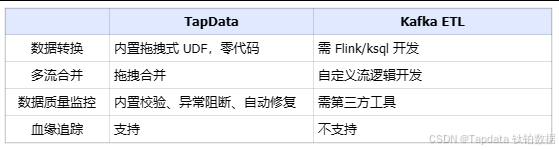
二、TapData vs Kafka ETL Pipeline:全面技術對比
Kafka 是一個分布式高吞吐消息隊列,解決的是消息隊列的性能瓶頸。 上游應用通過 Kafka 程序 API 向 Kafka topic 推送數據,下游應用通過 Kafka API 消費。

后來發現很多企業數據已經在數據庫里需要集成, 于是在幾年后推出了Kafka Connect 框架,可以更方便的在源和目標對接數據庫系統。這個算是一個后來的功能點。

Kafka connect 的用法,恰恰與 TapData 的實時數據管道類似:

二者的關鍵的不同點在以下:

-
產品定位

關鍵區別:
TapData 面向業務系統數據的流轉和治理,Kafka 面向應用事件流的高速傳輸。 -
數據源與 CDC 支持

案例說明:
性能舉例,參考填充模板:某大型金融機構測試結果顯示,TapData 的裸日志 CDC 在 Oracle 實例下對源庫 TPS 影響低于 1%,而 Debezium 方案的 API 拉取方案最高可達 8% 性能下降。 -
數據處理與治理能力
用戶痛點實錄:
“傳統 Kafka ETL,我們寫了一堆 Flink 任務,開發復雜度高,維護代價也高。而 TapData,業務方自己拖拽配置就可以上線流合并與數據清洗了。” —— 某數據平臺負責人 -
開發運維成本

實戰反饋:
一家制造企業采用 Kafka ETL 的復雜鏈路部署后,5 人運維團隊需要每天跟蹤多個流任務狀態,而切換 TapData 后,1 人即可維護全局數據同步與治理。
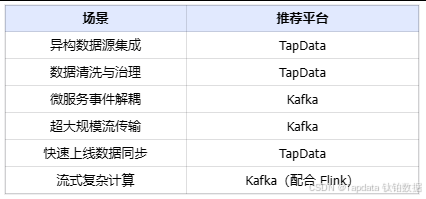
三、選擇建議:你的場景匹配?
TapData 適用場景
- 異構數據庫實時同步
- 數據清洗、治理(去重、轉換、異常阻斷)
- 實時數倉/BI 看板更新
- 低代碼開發、快速上線
Kafka 適用場景
- 高吞吐、超大規模數據傳輸(IoT 日志、點擊流)
- 微服務事件流解耦
- 需要復雜流式計算(Flink、CEP)
- 擁有成熟的大數據工程團隊
經驗法則:
業務數據同步與治理 → TapData
應用事件流傳輸與處理 → Kafka
四、TapData + Kafka:最佳組合架構與應用場景
很多企業并非二選一,而是TapData + Kafka 聯合使用,典型場景如下:
協作模式 1:TapData → Kafka
TapData 擔任 CDC 采集器,監聽數據庫變更,將事件推送至 Kafka Topic
優勢:CDC 零侵入,Kafka 獲得“即席”事件流
案例:某金融機構,TapData 監聽核心賬戶變更,推送到 Kafka,供風控系統消費。
協作模式 2:Kafka → TapData
Kafka 收集來自微服務的事件流,TapData 消費數據并同步入目標數據庫或數倉
優勢:TapData 提供靈活的數據格式轉換與錯誤處理
案例:一家保險公司,將用戶行為事件通過 Kafka 收集,TapData 自動轉換后寫入實時分析平臺(Doris)。
協作模式 3:混合部署,分工協作
- TapData:數據庫間同步、數據治理
- Kafka:應用事件流傳輸與高吞吐消息管理
案例:
某大型電商,使用 TapData 實現訂單系統與財務系統的數據同步,Kafka 用于用戶行為日志的實時處理。
五、TapData + Kafka 架構示意
雖然 TapData 作為一個專門的實時數據管道工具,有其明顯的優勢。但是Kafka 作為一個極為流行的開源消息隊列,很多企業已經部署了。在這樣的情況下,TapData 可以作為 Kafka 的producer,以CDC 采集器角色,幫助把數據庫的事件自動發送到Kafka Topic.

另外一個場景就是 從Kafka Topic 自動把事件消費入到數倉或者目標庫內,這里Tapdata解決的更多的是數據格式自動轉化,避免手工代碼的方式

最后總結一下, TapData 和 Kafka,有多種方式協作:
1) TapData 作為 Kafka 的數據庫CDC 采集器
2) TapData 作為 Kafka 的消費者自動寫入到目標庫
3) TapData 負責數據庫之間的數據同步場景,Kafka 負責應用之間的數據交換場景,各司其職。
六、總結:TapData vs Kafka,不是替代,而是未來企業數據流的“分工協作”
最佳實踐:
越來越多的企業,尤其是金融、電商、制造等行業,正在采用“TapData 數據集成治理 + Kafka 高效分發 + Flink 流計算”的復合架構,以實現真正的實時數據驅動業務。
七、行業視角:為什么現在必須考慮 TapData + Kafka 架構?
- 開發人力緊缺:企業不再愿意投入大量工程師開發/運維復雜的數據流。
- 異構數據激增:數據來源和格式多樣化,治理需求上升。
- 決策時效要求提升:從日級、小時級提升至秒級響應。
- 國產替代趨勢:特別是對國產數據庫與消息系統的兼容能力提出更高要求。
八、下一步:如何快速評估你的場景?
企業可以做一個快速評估(PoC):
- 列出你的數據源與目標(數據庫、消息隊列、文件存儲等)
- 明確需要的數據處理能力(CDC、清洗、轉換、質量保障)
- 估算實時性與吞吐需求
- 確定你的團隊可承擔的開發/運維復雜度
如需進一步的架構建議或 PoC 咨詢,可以聯系我們的專家團隊(team@tapdata.io)。
結語
TapData 與 Kafka,不是競爭者,而是時代共舞的伙伴。
在實時數據的世界里,“集成+傳輸+計算”的新范式正成為企業數據策略的主流,TapData 和 Kafka 的組合,是這個范式的最佳實踐。


)




:數據庫技術的發展、數據模型、數據庫管理系統、數據庫三級模式)





)


)


