昨天我們講了深度學習的大致框架,下面我們用深度學習網絡來實現一個小項目——手寫數字識別。
完整代碼
import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision.transforms import ToTensortraining_data=datasets.MNIST(root='./data',train=True,download=True,transform=ToTensor())test_data=datasets.MNIST(root='./data',train=False,download=True,transform=ToTensor())from matplotlib import pyplot as plt, figurefigure = plt.figure()
for i in range(9):image,label = training_data[i+59000]figure.add_subplot(3,3,i+1)plt.title(label)plt.axis('off')plt.imshow(image.squeeze(),cmap='gray')a=image.squeeze()
plt.show()train_dataloader=DataLoader(training_data,32)
test_dataloader=DataLoader(test_data,32)device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(device)for X, y in test_dataloader:print(f"Shape of X [N, C, H, W]: {X.shape}") # 批次大小、通道、高度、寬度print(f"Shape of y: {y.shape}, Type of y: {y.dtype}")breakclass Net(nn.Module):def __init__(self):super().__init__()self.flatten = nn.Flatten()self.hidden1 = nn.Linear(28*28,128)self.hidden2 = nn.Linear(128,400)self.output = nn.Linear(400,10)def forward(self, x):x = self.flatten(x)x = self.hidden1(x)x = nn.ReLU()(x)# x = nn.functional.sigmoid(x)x = self.hidden2(x)x = nn.ReLU()(x)# x = nn.functional.sigmoid(x)x = self.output(x)return xmodel = Net()
model.to(device)
loss_fn = nn.CrossEntropyLoss()
# optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)def train(train_dataloader,model,loss_fn,optimizer):model.train()batch_size_num=1for X, y in train_dataloader:X,y=X.to(device),y.to(device)output = model.forward(X)loss = loss_fn(output,y)optimizer.zero_grad()loss.backward()optimizer.step()a=loss.item()if batch_size_num %100 ==0:print(f"Batch size: {batch_size_num}, Loss: {a}")batch_size_num+=1# print(model)def test(dataloader,model,loss_fn):size = len(dataloader.dataset)num_batches = len(dataloader)model.eval()batch_size_num=1loss,correct=0,0with torch.no_grad():for X, y in test_dataloader:X,y=X.to(device),y.to(device)pred = model(X)loss = loss_fn(pred,y)+losscorrect += (pred.argmax(1) == y).type(torch.float).sum().item()loss/=num_batchescorrect/=sizeprint(f'Test result: \n Accuracy: {(100*correct)}%,Avg loss: {loss}')# train(train_dataloader,model,loss_fn,optimizer)
# test(test_dataloader,model,loss_fn)epochs=10
for i in range(epochs):print(f"Epoch {i+1}")train(train_dataloader,model,loss_fn,optimizer)test(test_dataloader,model,loss_fn)
結果展示
下面我來進行拆解,
?1 導入庫
import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision.transforms import ToTensor前面就是導入庫,沒什么多說的。
2 導入數據
training_data=datasets.MNIST(root='./data',train=True,download=True,transform=ToTensor())test_data=datasets.MNIST(root='./data',train=False,download=True,transform=ToTensor())首先我們從datasets.MINST()這個庫中導入數據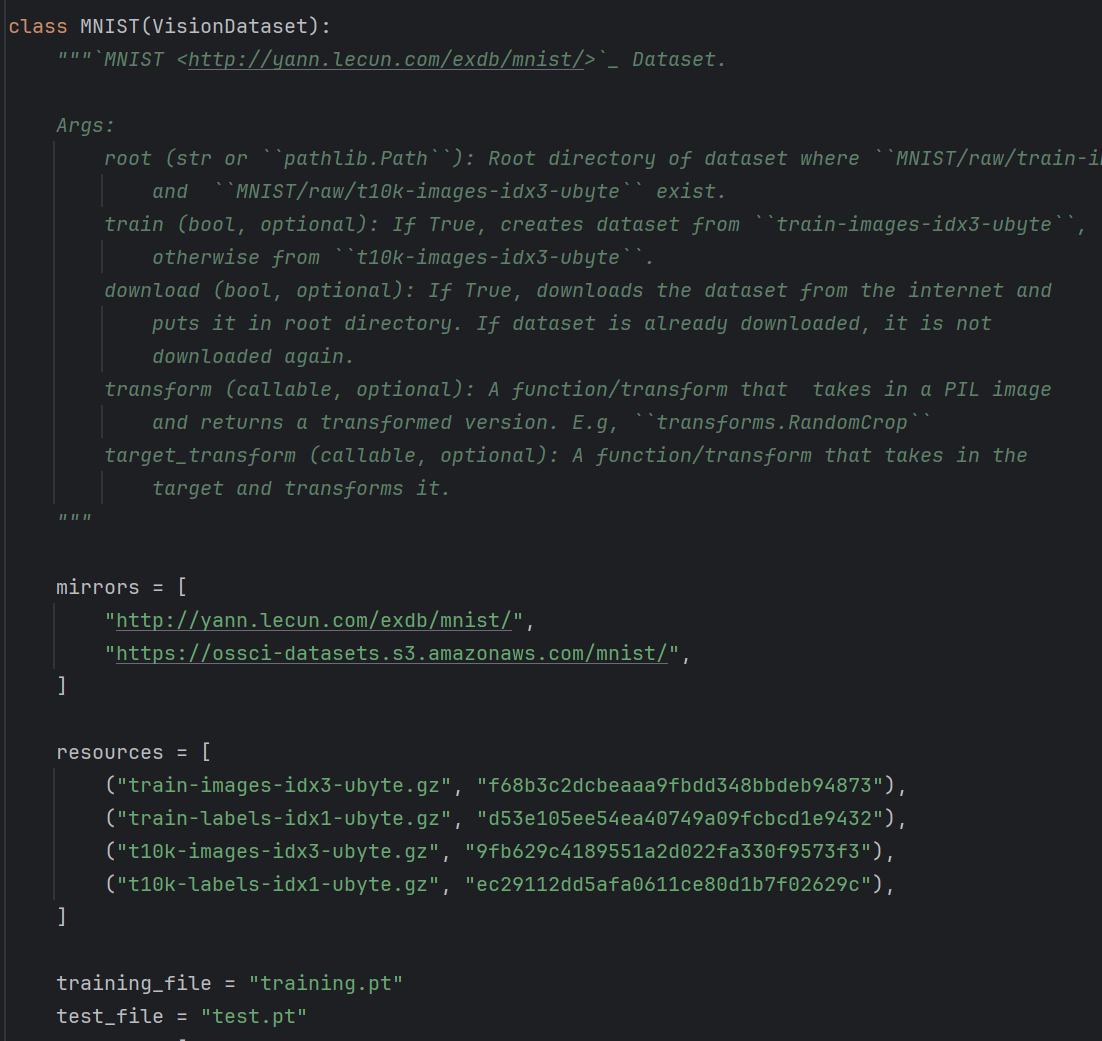
從上面我們可以看出,這個庫中包含一些網址,然后可以從其中下載一些數據。
root='./data',? ? ? ? 這個表示把數據存儲在這樣一個文件夾中
train=False,? ? ? ? 這個表示下載的是訓練集還是測試集,True為訓練集,False為測試集
download=True,? ? ? ? 下載
transform=ToTensor())? ? ? ? 轉化為Tensor數據,將圖像數據轉換為PyTorch張量(像素值歸一化到[0,1])。
3 數據展示
from matplotlib import pyplot as plt, figurefigure = plt.figure()
for i in range(9):image,label = training_data[i+59000]figure.add_subplot(3,3,i+1)plt.title(label)plt.axis('off')plt.imshow(image.squeeze(),cmap='gray')a=image.squeeze()
plt.show()- 創建一個3x3的子圖,顯示訓練集中最后9個樣本(索引59000到59008)的圖像和標簽。
image.squeeze()將形狀從[1,28,28]變為[28,28],因為matplotlib要求單通道圖像為二維。
結果展示

4 創建數據加載器
train_dataloader=DataLoader(training_data,32)
test_dataloader=DataLoader(test_data,32)- 訓練和測試數據加載器,每次迭代返回一個批次(32張圖片和對應的標簽)。
5??設置設備
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(device)- 檢查是否有可用的GPU,如果有則使用第一個GPU,否則用CPU。
6?打印一批測試數據的形狀
for X, y in test_dataloader:print(f"Shape of X [N, C, H, W]: {X.shape}") # 批次大小、通道、高度、寬度print(f"Shape of y: {y.shape}, Type of y: {y.dtype}")break- 從測試數據加載器中取一個批次,打印輸入圖像和標簽的形狀。
- X的形狀:[32, 1, 28, 28](32個樣本,1個通道,28x28像素)
- y的形狀:[32](32個標簽)
7 ?定義神經網絡模型
class Net(nn.Module):def __init__(self):super().__init__()self.flatten = nn.Flatten()self.hidden1 = nn.Linear(28 * 28, 128) # 第一層全連接self.hidden2 = nn.Linear(128, 400) # 第二層全連接self.output = nn.Linear(400, 10) # 輸出層(10個數字)def forward(self, x):x = self.flatten(x) # 將圖像展平為向量:[batch, 28 * 28]x = self.hidden1(x) # [batch, 128]#x = nn.functional.sigmoid(x)x = nn.ReLU()(x) # ReLU激活x = self.hidden2(x) # [batch, 400]#x = nn.functional.sigmoid(x)x = nn.ReLU()(x) # ReLU激活x = self.output(x) # [batch, 10]return x
- 一個簡單的多層感知機(MLP)模型:
- 輸入:28x28=784維
- 兩個隱藏層:128和400個神經元,使用ReLU激活。
- 輸出層:10個神經元(對應0-9),無激活(后面用交叉熵損失包含Softmax)。
forward為前向傳播
? ? ? ? 第一步先用flatten(x)把數據拉成一維的,例如原本28*28的二維數據,變成了28*28的一維數據
? ? ? ? 第二步傳入到隱含層
? ? ? ? 第三步使用激活函數進行激活(這里初開始使用sigmod函數進行激活,但使用ReLU激活比較好)
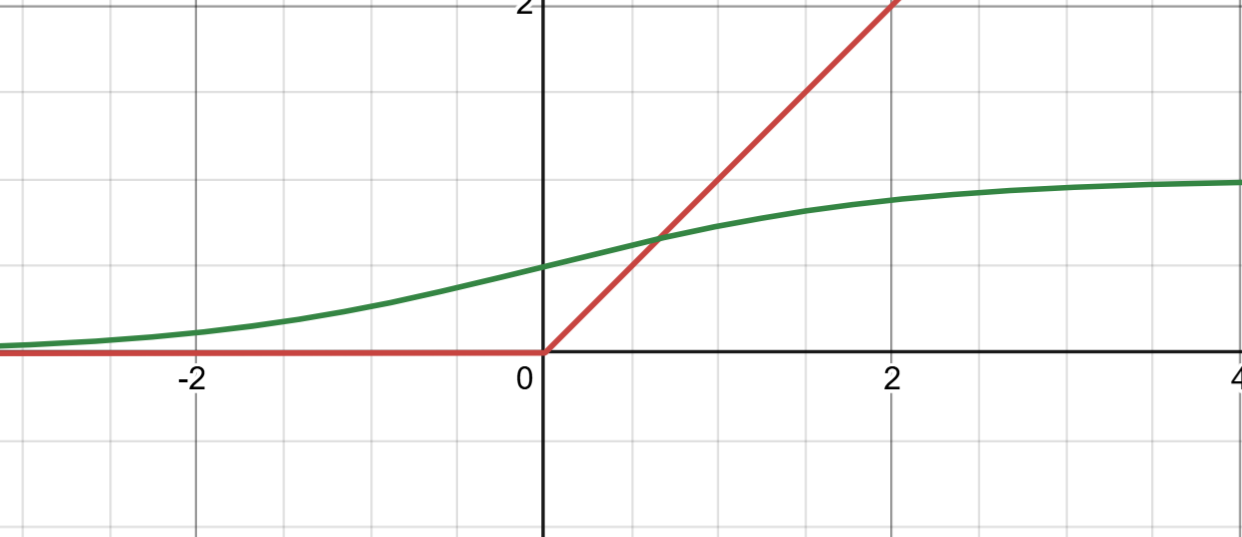
sigmod和ReLU函數對比
Sigmoid 激活函數的公式為:?f(x) = 1 / (1 + e^(-x))?它將輸入值映射到 (0, 1) 區間,常用于二分類問題的輸出層。Sigmoid 的優點是可以提供概率分布,但存在以下問題:
梯度消失問題:當輸入值過大或過小時,梯度趨近于 0,導致深層網絡訓練困難。
非零中心輸出:輸出值始終為正,可能導致權重更新不穩定。
計算復雜度高:涉及指數運算,計算效率較低。
ReLU 激活函數的公式為:?f(x) = max(0, x)?ReLU 是深度學習中廣泛使用的激活函數,具有以下優點:
計算效率高:只需簡單的比較操作,計算速度快。
避免梯度消失:在正值范圍內梯度為常數,有助于深層網絡的訓練。
稀疏激活性:部分神經元輸出為 0,減少參數依賴,緩解過擬合問題。
然而,ReLU 也存在死亡 ReLU問題,即當神經元進入負值區域時,梯度為 0,可能導致神經元永不激活。為此,改進版本如 Leaky ReLU 和 Parametric ReLU 被提出。
對比總結:
計算效率:ReLU 優于 Sigmoid,適合處理大規模數據。
梯度問題:Sigmoid 易出現梯度消失,而 ReLU 在正值范圍內表現更優。
適用場景:Sigmoid 常用于二分類問題的輸出層,而 ReLU 更適合深度網絡,如圖像識別和自然語言處理任務
8 創建模型對象
model = Net()
model.to(device)
這里創建了一個模型對象,并把模型傳入到我們的device也就是GPU中
9 初始化損失函數
loss_fn = nn.CrossEntropyLoss()
然后定義損失函數,這里為交叉熵損失函數。因為分類算法一般都是用交叉熵損失函數,找最優參數。還有許多損失函數的介紹看我主頁。
10 建立優化器
# optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)這里最初建立的是SGD優化器,這個是梯度下降優化器,lr步長為0.01,后面優化成了Adam優化器,這個比較實用。適用幾乎所有哦網絡。
11 創建訓練函數
def train(train_dataloader,model,loss_fn,optimizer):model.train()batch_size_num=1for X, y in train_dataloader:X,y=X.to(device),y.to(device)output = model.forward(X)loss = loss_fn(output,y)optimizer.zero_grad()loss.backward()optimizer.step()a=loss.item()if batch_size_num %100 ==0:print(f"Batch size: {batch_size_num}, Loss: {a}")batch_size_num+=1# print(model)第一步model.train(),這里設置為訓練模式(影響 Dropout、BatchNorm 等層),也就是說允許讀寫w。
第二部 分批次對訓練集進行導入,前行傳播,計算損失值,清空之前的梯度,反向計算梯度,更新梯度,下面就是訓練100批次就打印一下損失值。
12 創建測試函數
def test(dataloader, model, loss_fn):size = len(dataloader.dataset) # 總樣本數num_batches = len(dataloader) # batch 數量model.eval() # 設置為評估模式batch_size_num = 1loss, correct = 0, 0with torch.no_grad(): # 不計算梯度,節省內存和計算for X, y in dataloader:X, y = X.to(device), y.to(device)pred = model(X)loss += loss_fn(pred, y) # 累積損失correct += (pred.argmax(1) == y).type(torch.float).sum().item() # 統計正確預測的數量loss /= num_batches # 平均損失correct /= size # 正確率print(f'Test result: \n Accuracy: {(100*correct):.2f}%, Avg loss: {loss:.4f}')我們先把總樣本數求出來是因為后面要用預測對的樣本數/總樣本數就可以得到準確率了
model.eval()就是把w的模式改為僅讀模式
初始化損失值和準確率
在不對梯度進行改變的情況下,對訓練集中每一個值進行循環,得到預測值,然后用預測值和真實值作對比,然后得出的是一個列表,其中全是True和False.然后轉化為float也就是轉化為數值型0/1,然后再sum求綜合再取item()。
然后計算平均損失和正確率(其實這里損失值沒啥用了)
13 訓練和測試
train(train_dataloader,model,loss_fn,optimizer)
test(test_dataloader,model,loss_fn)
這里進行了訓練和測試,結果并不是很理想,但是我們可以疊加訓練,也就是說,在優化的時候次數太少,w權重并沒有更新到最優狀態。然后我們疊加train,這也是深度學習的一個優點,可以在前一層的基礎上繼續訓練。
epochs=10
for i in range(epochs):print(f"Epoch {i+1}")train(train_dataloader,model,loss_fn,optimizer)test(test_dataloader,model,loss_fn)如上,我們進行了十次訓練,準確率從0.87訓練到了95











:下一代Wi-Fi性能提升的關鍵技術)





?(58))


