目錄
一、前言
二、Dify介紹
2.1 Dify 是什么
2.2 Dify 核心特性
2.2.1 Dify特點
2.2.2 Dify 多模型支持
2.2.3 Dify 適應場景
2.2.4 基于Dify 搭建發票識別應用優勢
三、Dify 搭建業務單據核對助手實戰過程
3.1 前置準備
3.1.1 安裝必要的插件
3.2 完整操作步驟
3.2.1 創建一個應用
3.2.2 開始節點增加一個參數
3.2.3 增加第一個大模型節點
3.2.4 增加第二個大模型節點
3.2.5 增加第三個大模型節點
3.2.6 配置結束節點
3.2.7 效果驗證
四、寫在文末
一、前言
隨著AI智能體在很多領域使用的越來越廣泛,并逐漸產生商業價值之后。人們驚訝的發現,一個可以實現商用的業務系統或應用,只需短短幾天,甚至幾小時就可以做出來。有個傳統業務系統開發經驗的同學應該了解,開發一個功能,從產品經理識別需求到最終開發完成上線使用,這個過程是很長的,而且中間可能還涉及到來來回回的反復溝通,會拉長業務最終交付和使用的時間。比如像票據核對這種工作,往往是需要人工參與校對的,比較大程度上需要依賴人力去完成。有了AI大模型+AI智能體之后,即便不是開發工程師,也能基于AI智能體平臺,快速搭建一個簡單的AI應用來驗證效果,從而快速實現業務價值的驗證。本篇以Dify智能體平臺為例進行說明,使用Dify快速搭建一個業務單據自動核對智能助手應用。
二、Dify介紹
2.1 Dify 是什么
Dify 是一個開源大模型應用開發平臺,旨在幫助開發者(智能體應用愛好者)快速構建、部署和管理基于大型語言模型(LLM)的 AI 應用。它提供了一套完整的工具鏈,支持從提示詞工程(Prompt Engineering)到應用發布的全流程,適用于企業級 AI 解決方案和個人開發者項目。
官網入口:Dify: Production-Ready AI Agent Builder
中文站入口:Dify:企業級 AI Agent 開發平臺
2.2 Dify 核心特性
2.2.1 Dify特點
Dify 具備如下核心特點:
-
可視化編排工作流
-
通過低代碼界面設計 AI 應用流程,無需深入編程即可構建復雜的 LLM 應用。
-
支持 對話型(Chat App) 和 文本生成型(Completion App) 應用。
-
-
多模型支持
-
兼容主流大模型 API,如 OpenAI GPT、Anthropic Claude、Cohere、Hugging Face 等。
-
支持私有化部署的 Llama 2、ChatGLM、通義千問 等開源模型。
-
-
靈活的提示詞工程
-
提供 Prompt 模板、變量插值、上下文管理等功能,優化 AI 輸出效果。
-
支持 RAG(檢索增強生成),可結合外部知識庫提升回答準確性。
-
-
數據管理與持續優化
-
記錄用戶與 AI 的交互日志,用于分析和迭代改進模型效果。
-
支持 A/B 測試,對比不同提示詞或模型版本的表現。
-
-
企業級功能
-
支持 多租戶、權限管理,適合團隊協作開發。
-
可私有化部署,保障數據安全。
-
2.2.2 Dify 多模型支持
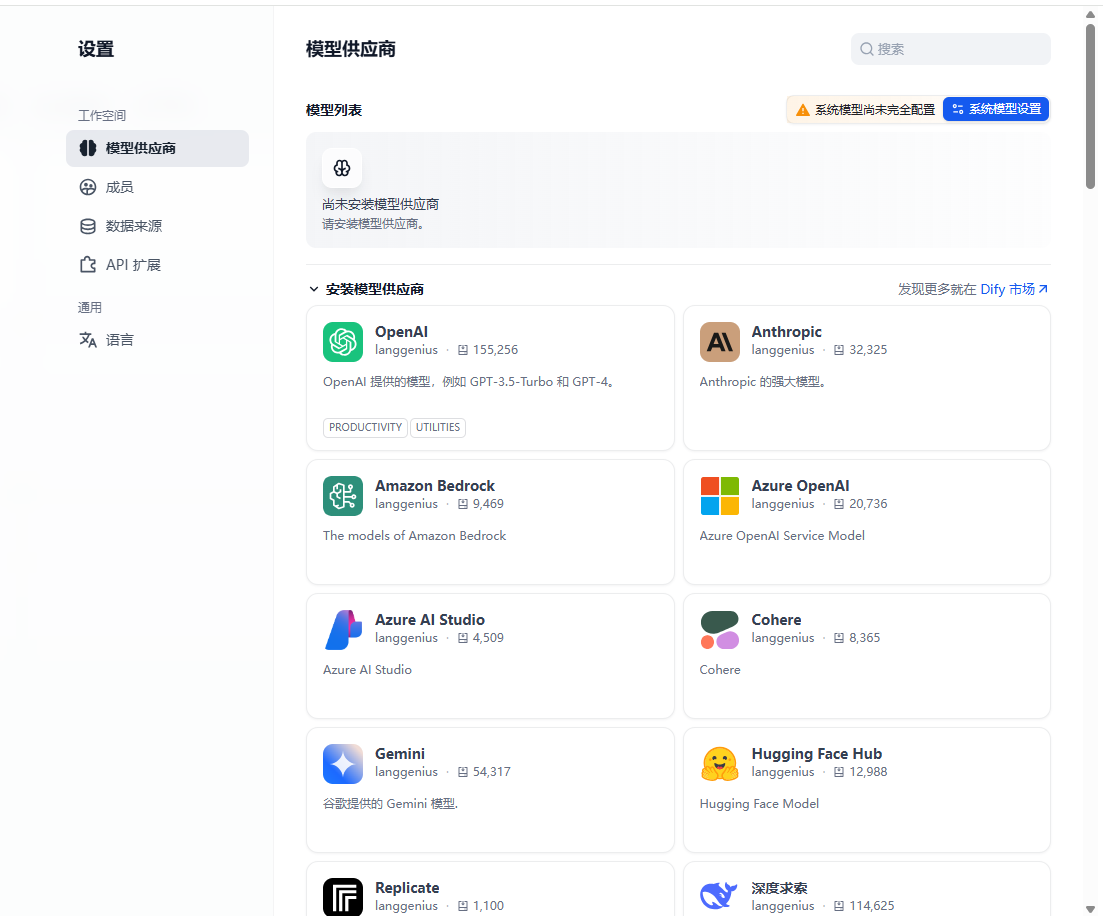
在dify控制臺,內置了非常多大模型可供用戶選擇使用,比如GPT系列,DeepSeek模型、千問系列模型等,基于這些模型,應用開發者可以自由靈活的選擇并使用。
2.2.3 Dify 適應場景
Dify 適用于多種生成式 AI 應用開發場景:
-
內容創作與生成
-
自動化生成文章、報告、營銷文案等
-
結合知識庫實現專業領域內容生成(如法律、醫療文檔)
-
-
智能對話系統
-
構建多輪對話客服機器人、虛擬助手
-
通過 Agent 框架實現任務分解與工具調用(如搜索、圖像生成)
-
-
數據分析與自動化
-
解讀復雜數據并生成可視化報告
-
自動化業務流程(如工單處理、郵件回復)
-
-
個性化推薦與營銷
-
基于用戶畫像生成個性化推薦內容。
-
結合RAG實現精準信息檢索與推送。
-
2.2.4 基于Dify 搭建發票識別應用優勢
Dify作為領先的AI應用開發平臺,為零代碼/低代碼構建發票識別應用提供了強大支持。Dify通過可視化工作流編排和多模型集成能力,使開發者無需編寫復雜代碼即可構建專業級發票處理應用。
1)Dify構建的發票識別應用為企業解決了以下痛點:
-
效率瓶頸:傳統人工錄入方式處理一張發票平均需3-5分鐘,而AI方案可縮短至秒級2
-
錯誤率高:手工錄入錯誤率約2-5%,AI識別準確率可達99%以上17
-
版式適應差:傳統OCR依賴固定模板,而AI方案能自適應多種發票版式變化4
-
成本壓力:企業財務部門50%以上時間耗費在票據處理上,AI自動化可釋放這部分人力7
2)基于Dify 實現一個發票識別應用搭建的關鍵技術流程如下:
-
多模態模型集成:
-
支持視覺-語言大模型(VLM)如Qwen-VL、DeepSeek-V2等,能同時處理圖像和文本信息
-
-
可視化工作流編排:
-
通過拖拽節點方式構建復雜處理流程,如"文檔提取→OCR識別→數據驗證→結果輸出"的全自動化流水線
-
-
條件分支與邏輯控制:
-
支持基于發票類型的智能路由,如自動區分增值稅發票、火車票等不同類型并調用相應處理模塊
-
-
多模型協同驗證:
-
可采用多個VLM模型并行識別后比對結果,顯著提升準確率
-
3)從實際落地案例看,Dify發票識別應用為企業帶來多維度的價值提升:
-
效率提升
-
單張發票處理時間從人工3-5分鐘縮短至2-10秒
-
華為云方案用戶實現"財務審核效率提升90%以上"
-
支持批量處理,某電商企業日處理能力從200張提升至10,000+張
-
-
成本節約
-
減少70%以上人工審核崗位
-
某服裝電商年節省開票成本23.6萬元(人力+稅損)
-
按需使用的云資源模式避免硬件過度投資
-
-
風險控制
-
自動識別異常發票(如頻繁紅沖、大額整數票)
-
稅務合規率從約85%提升至近100%
-
避免如"某電商因紅沖率超15%被罰款87萬元"的案例
-
-
業務賦能
-
結構化票據數據賦能財務分析(如供應商集中度分析)
-
API集成能力支持與ERP、報銷系統的深度對接
-
某制造企業實現"從識別到入賬全流程自動化"
-
三、Dify 搭建業務單據核對助手實戰過程
接下來通過一個實際案例應用來演示下如何基于Dify 搭建業務單據核對助手的操作過程。
3.1 前置準備
3.1.1 安裝必要的插件
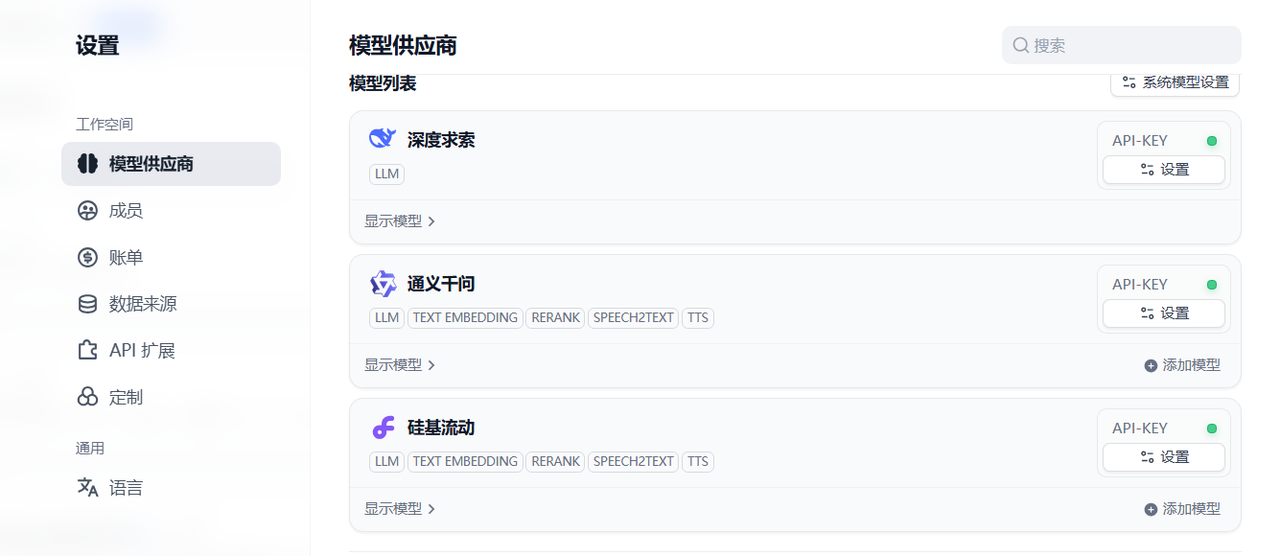
Dify提為應用開發者提供了眾多大模型可供集成使用,但需要使用者以插件方式安裝并集成進去。在賬戶那里右鍵設置,進入模型供應商設置那里,可以看到有很多大模型可供集成,入口:插件 - Dify

你可以選擇合適的模型供應商進行安裝,比如我這里選擇了DeepSeek ,通義千問大模型,以及國內的硅基流動大模型集成平臺,主要是把對應的模型供應商的apikey配置進去即可。
3.2 完整操作步驟
3.2.1 創建一個應用
如下,創建一個ChatFlow類型的空白應用,填寫應用名稱和描述之后點擊創建
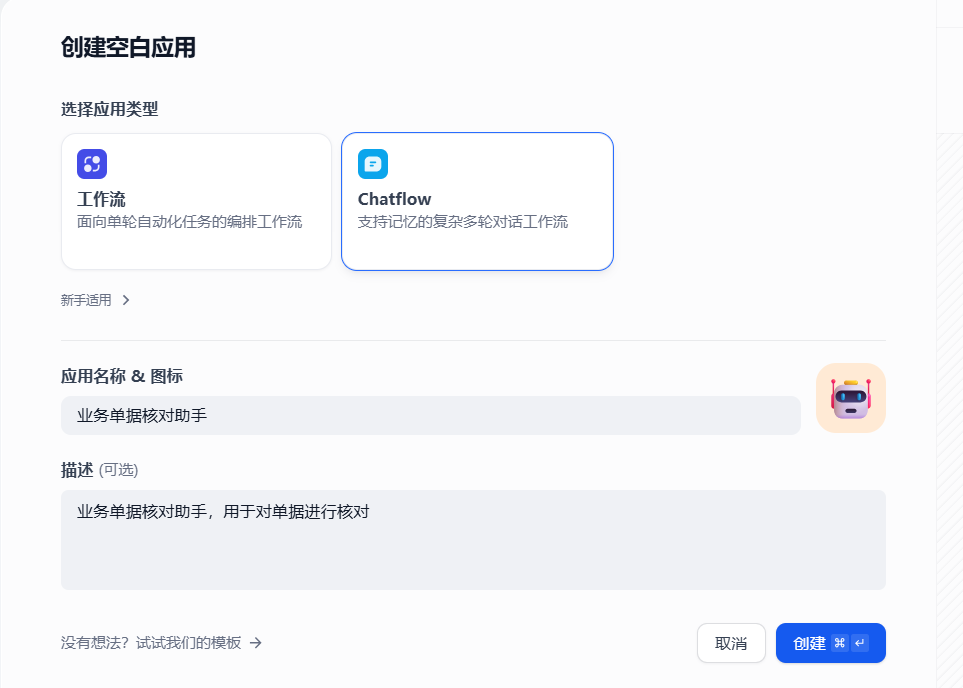
創建完成后,跳轉到下面的流程配置頁面
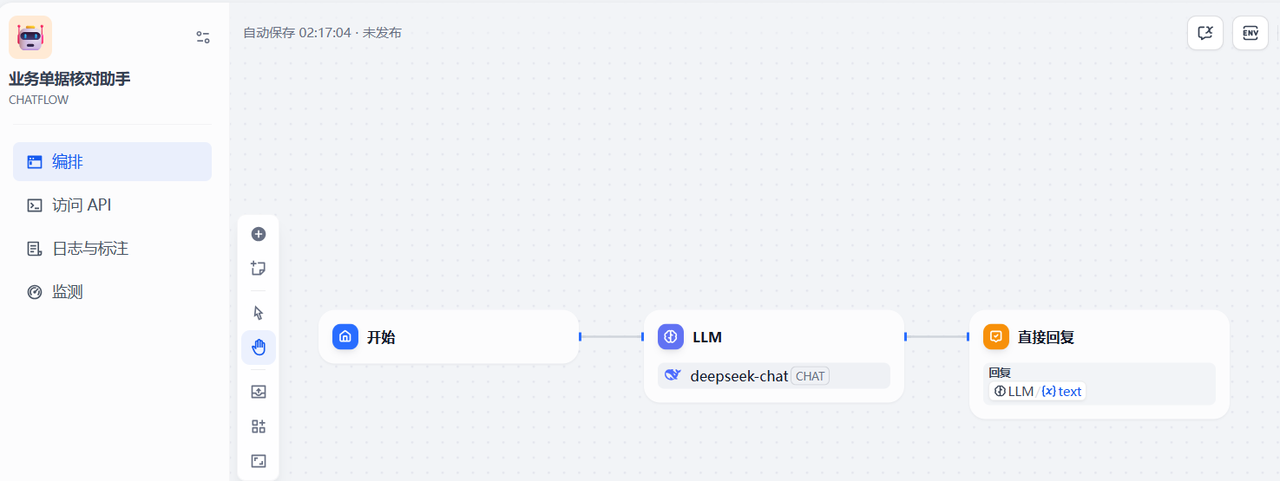
3.2.2 開始節點增加一個參數
在開始節點增加一個文件類型的變量參數,用于用戶上傳票據文件使用,如下:
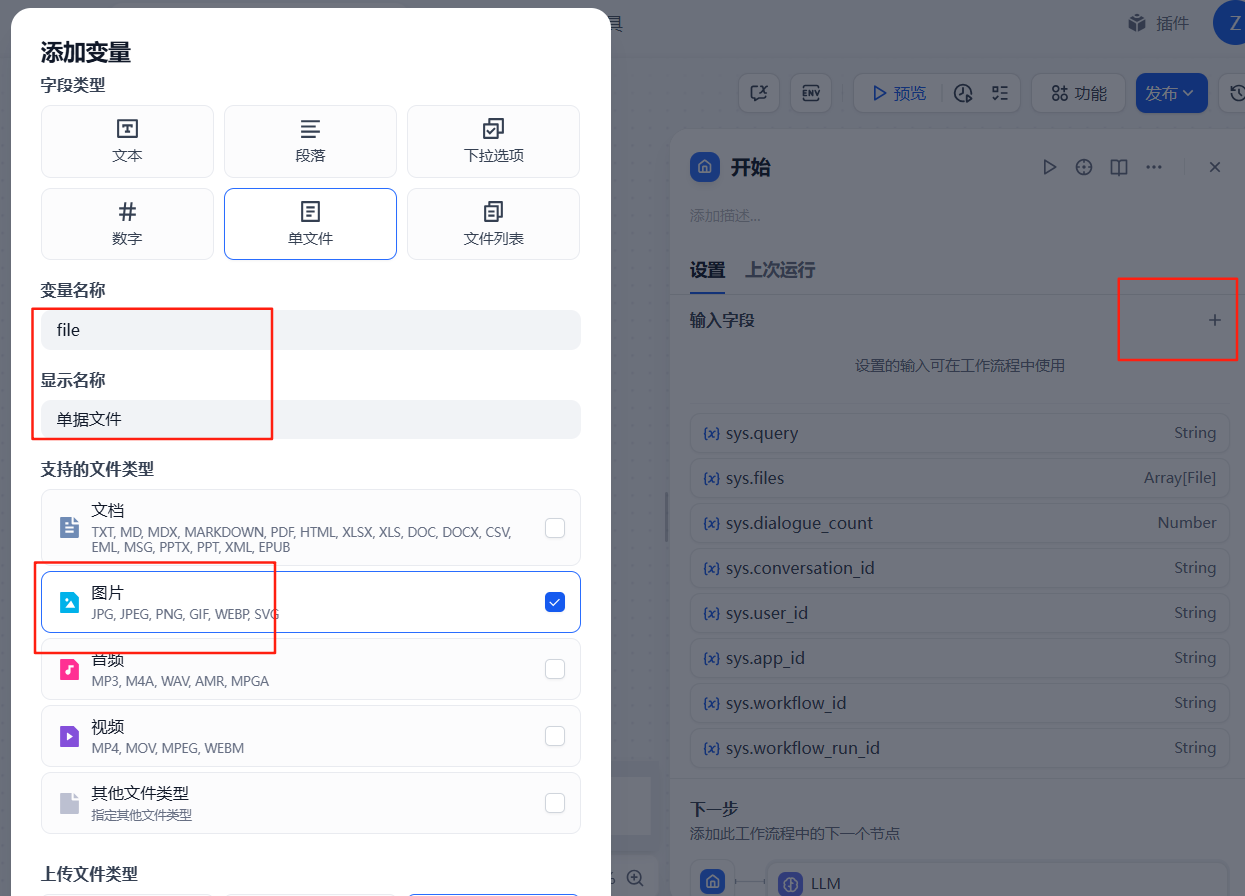
添加完成之后,在右側開始節點配置中可以看到這個參數
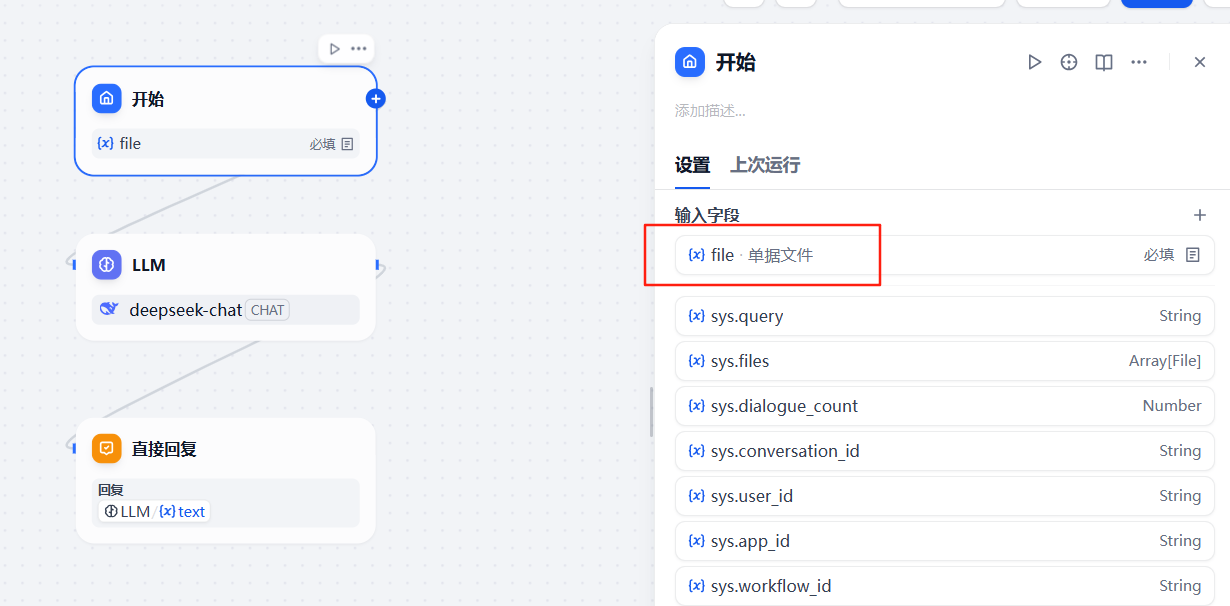
3.2.3 增加第一個大模型節點
第一個大模型節點通過配置提示詞,從而來提取用戶上傳的票據文件中的內容,參考下面的系統提示詞
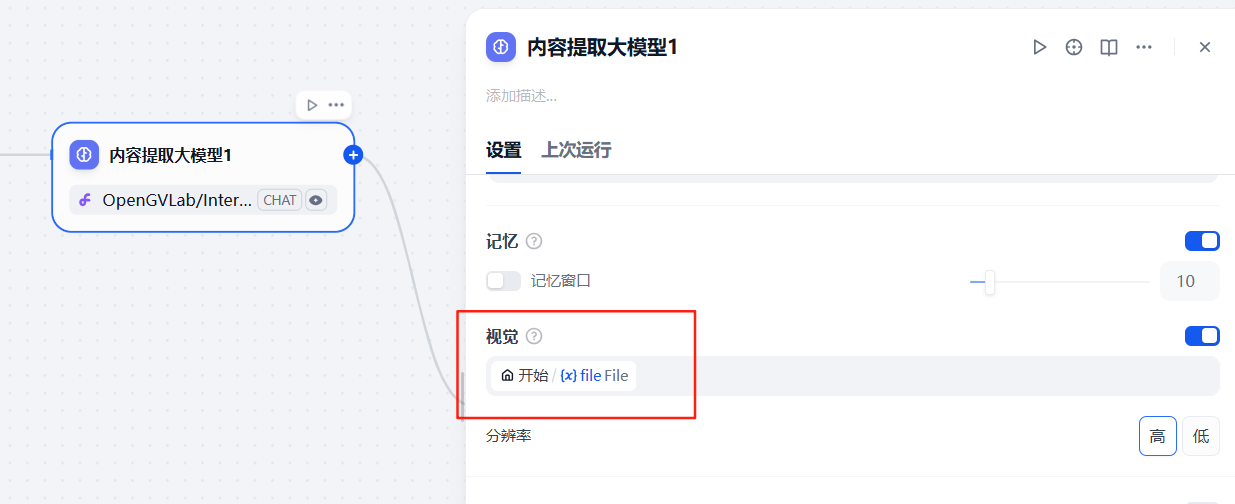
請提取這張照片的內容,其中內容格式'發票號碼'、'開票日期'、'出發時間'、'始發站'、'終點站'、'車次'、'票價'、'身份證號'、'姓名'、'電子客票號'、'購買方名稱'、'統一社會信用代碼'字段返回信息,返回的結果以json格式返回注意這里的大模型選擇具備視覺識別的大模型
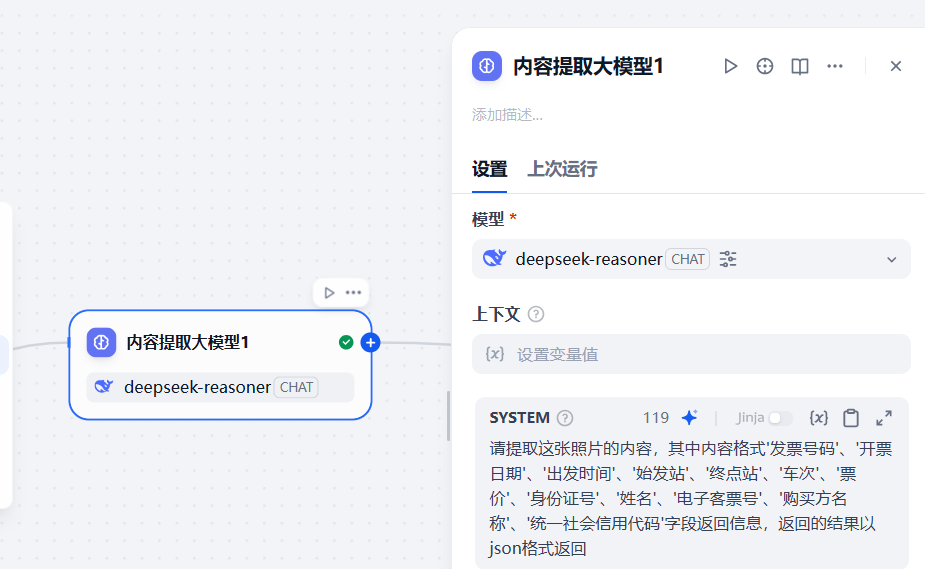
同時,將配置節點中的視覺選項勾選上
3.2.4 增加第二個大模型節點
為了達到最后的票據核對效果,這里我們采用兩個大模型節點,而且兩個大模型節點背后配置不同廠商的大模型,如下,第二個大模型使用千問的大模型,也是選擇帶有VL的,系統提示詞與上一個大模型節點配置相同的內容
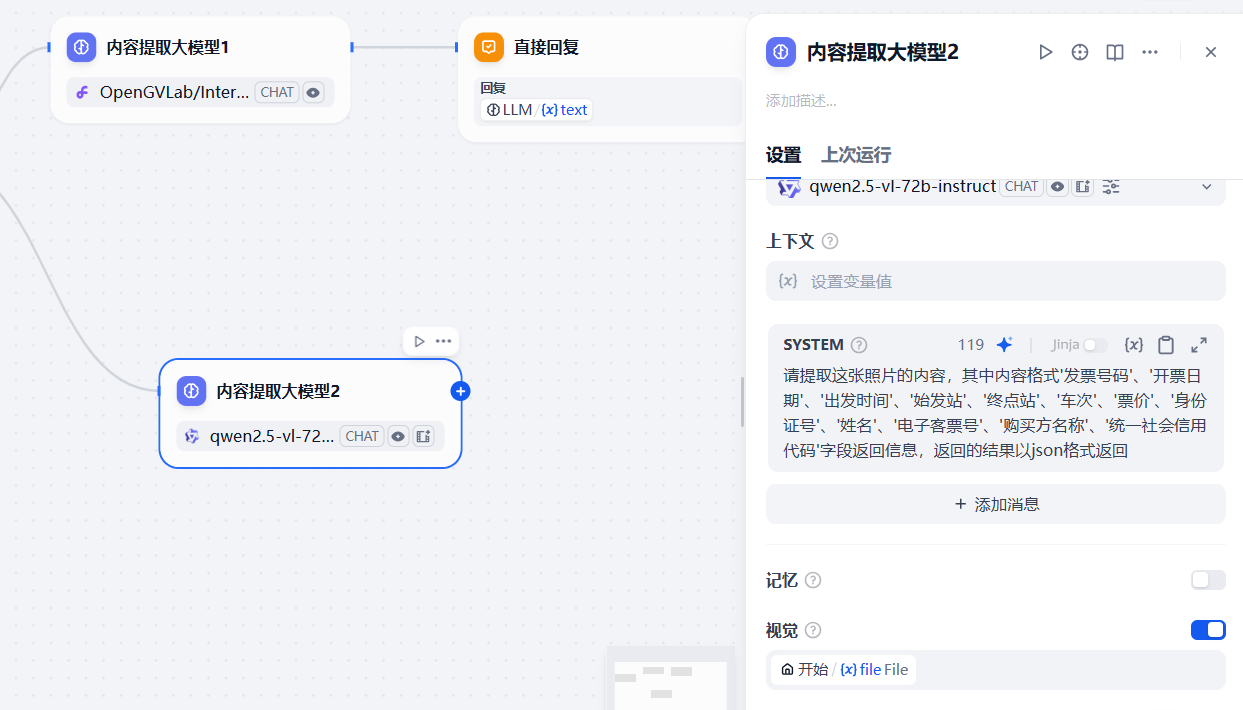
總的來說,通過添加兩個大模型節點,兩個不同廠商的大模型同時對用戶上傳的同一份票據進行提取,如果最終不同的大模型提取的內容相同,可以判斷識別的就沒問題
3.2.5 增加第三個大模型節點
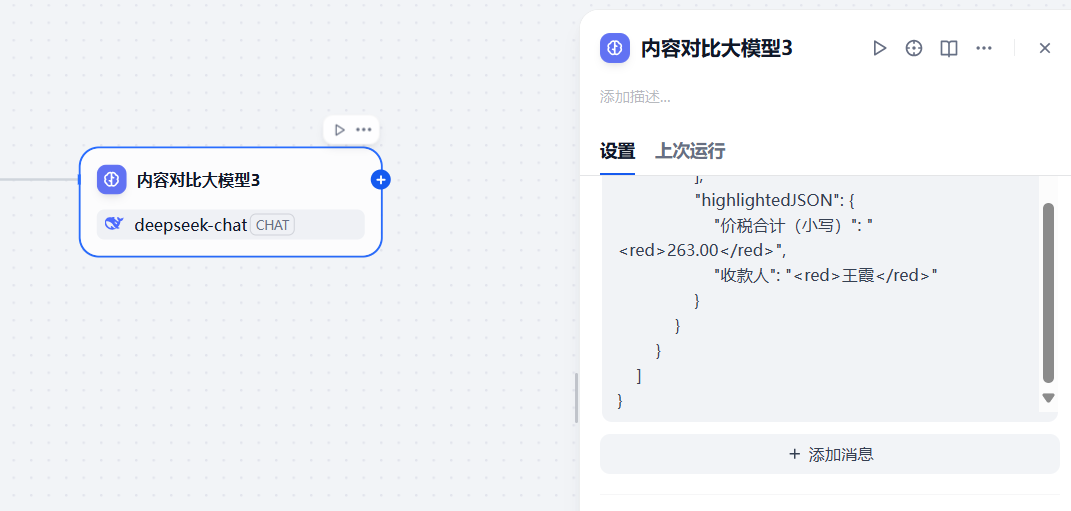
再增加一個大模型節點,該節點用于收集前2個大模型節點提取到的內容,然后進行對比分析,大模型中配置下面的提示詞,該提示詞以json的結構對大模型的回答進行了約束,并且給出了參考案例,從而更好的輸出結果
{"Role": "JSON 數據對比專家","Profile": {"專長": "精確比較和分析 JSON 數據","經驗": "多年處理各種結構化數據的豐富經驗","技能": ["精準識別差異","使用顏色高亮標注","詳細對比報告生成"]},"Goals": ["逐行比較兩個JSON數據的內容","識別并標記所有存在的差異","使用顏色(紅色)高亮顯示不同之處","生成清晰、易讀的比對結果報告"],"Rules": ["必須逐個鍵值對進行比較,不遺漏任何字段","只標注存在差異的部分,相同的部分保持原樣","使用紅色作為差異標注的唯一顏色","對于數值型差異,需要考慮精度問題","對于字符串差異,需要考慮大小寫和空白字符","保持 JSON 的結構完整性,不改變原有的格式和順序"],"Workflows": ["接收并解析兩個待比對的 JSON 數據","確保兩個 JSON 數據結構一致,如果不一致,報告結構差異","逐一對比每個鍵值對"," - 如鍵不同,標記為新增或缺失"," - 如值不同,使用紅色高亮標注","生成詳細的對比報告,包括:"," - 總體差異統計"," - 每個差異項的具體描述"," - 高亮顯示的 JSON 數據"],"OutputFormat": {"type": "json","structure": {"summary": "總體比對結果摘要","differences": [{"key": "差異字段名","value1": "第一個 JSON 中的值","value2": "第二個 JSON 中的值","highlightColor": "red"}],"highlightedJSON": "包含紅色高亮的完整 JSON 數據"}},"Examples": [{"input": {"json1": {"價稅合計(小寫)": "263.00","收款人": "李華"},"json2": {"價稅合計(小寫)": "213.00","收款人": "王霞"}},"output": {"summary": "發現2處差異","differences": [{"key": "價稅合計(小寫)","value1": "263.00","value2": "213.00","highlightColor": "red"},{"key": "收款人","value1": "李華","value2": "王霞","highlightColor": "red"}],"highlightedJSON": {"價稅合計(小寫)": "<red>263.00</red>","收款人": "<red>王霞</red>"}}}]
}
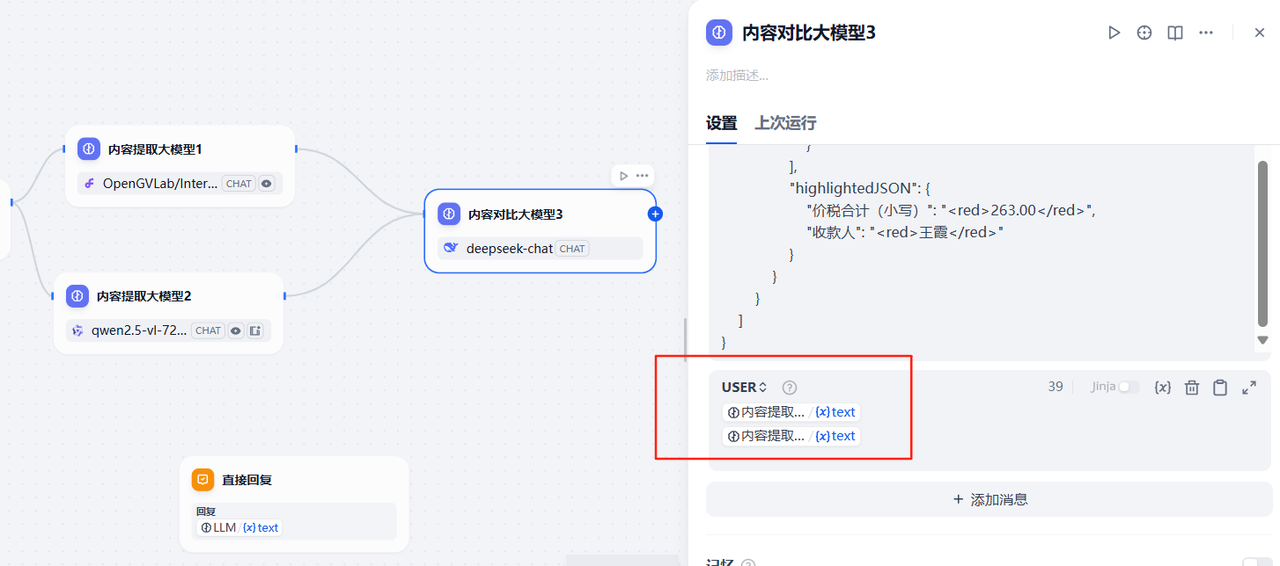
同時在添加消息那里,添加用戶提示詞,將前面2個大模型提取的票據內容進行匯聚,如下,在用戶消息輸入框中,將前面2個大模型節點的輸出結果展示在里面即可
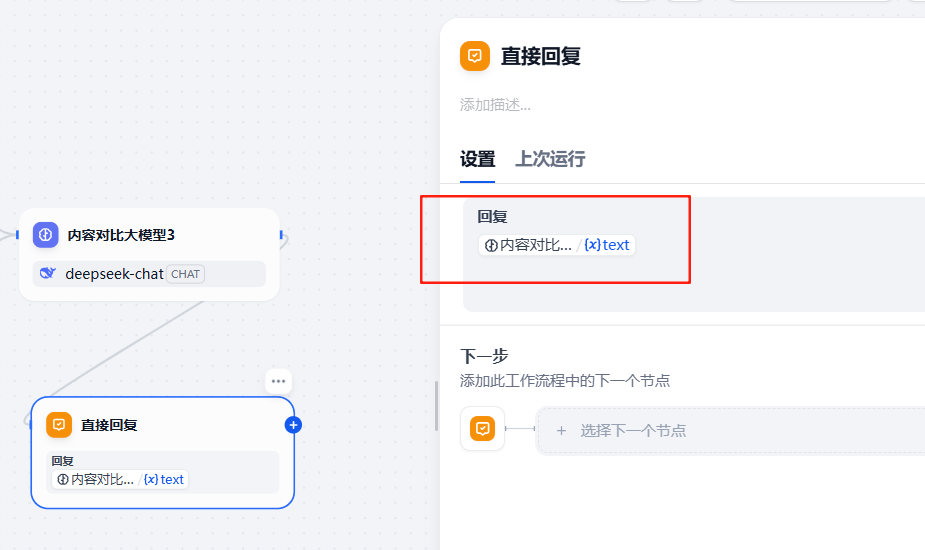
3.2.6 配置結束節點
在大模型節點3后面增加一個回復節點,輸入變量為大模型3的輸出結果,如下:
3.2.7 效果驗證
上述配置完成后,點擊發布更新
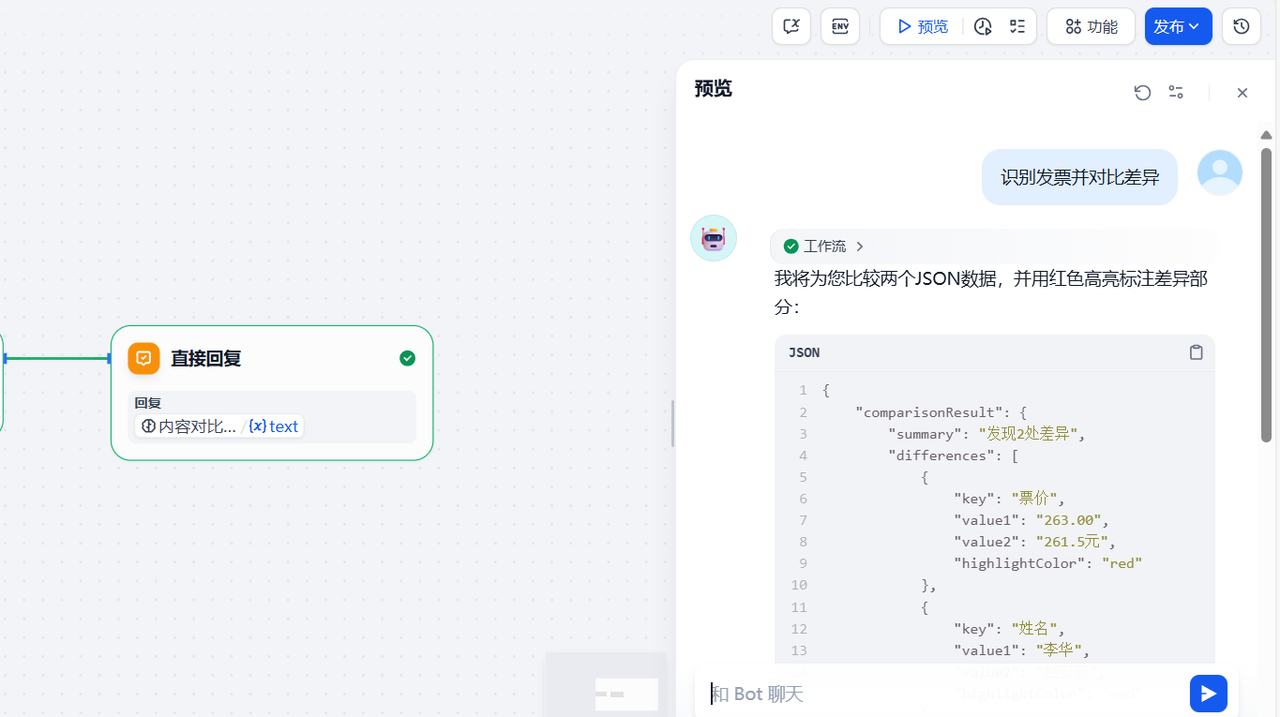
然后點擊預覽,上傳一張本地的票據,這里我選擇本地的一張火車票,然后首先輸入發票識別,可以看到經過執行,發票的信息被提取出來了,同時給出了差異信息的輸出

四、寫在文末
本文通過案例操作演示詳細介紹了如何基于Dify智能體平臺搭建一個業務發票的差異識別助手的詳細過程,希望對看到的同學有用哦,本篇到此結束,感謝觀看!




)
![[創業之路-560]:機械、電氣、自控、電子、軟件、信息、通信、大數據、人工智能,上述技術演進過程](http://pic.xiahunao.cn/[創業之路-560]:機械、電氣、自控、電子、軟件、信息、通信、大數據、人工智能,上述技術演進過程)
)












