- 實驗目的
1. 掌握特征工程,會進行特征提取與特征選擇,會進行缺失值填充。
2.?建立決策樹模型,解決實際問題。
3. 會對模型進行調試,能夠繪制并保存決策樹。
- 實驗環境
Python 3.7.0,Sklearn ,PyCharm
- 實驗原理
1、特征工程
特征工程、降維與超參數調優是機器學習工程應用中的三個重要問題。在優惠券核銷示例中討論過,輸入模型進行訓練的一般不是實例的屬性,而是從實例的屬性數據中提取出的特征。降維技術可以解決因為特征過多而帶來的樣本稀疏、計算量大等問題。
在訓練時,算法參數的設置對算法效果的影響很大,設置合適算法參數的過程稱為“超參數調優”。特征工程的目標是從實例的原始數據中提取出供模型訓練的合適特征。特征的提取與問題的領域知識密切相關。特征工程在機器學習過程中的位置和作用如下圖所示。特征提取是一種創造性的活動,沒有固定的規則可循。一般來說,需要先從總體上理解數據,必要時可通過可視化來幫助理解,然后運用領域知識進行分析和聯想,然后處理數據提取特征。
首先要數據預處理:
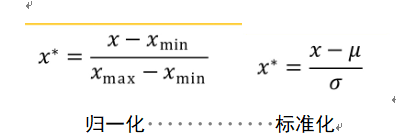

2、決策樹算法
決策樹,可以理解為:從訓練數據中學習得出一個樹狀結構的模型。決策樹屬于判別模型,既可以做分類也可以做回歸。
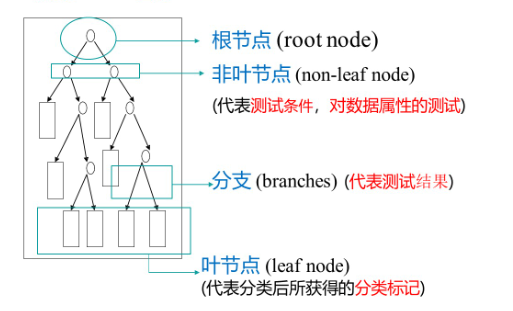
可分為訓練階段和分類階段:
訓練階段:從給定的訓練數據集DB,構造出一棵決策樹:class=DecisionTree(DB)
分類階段:從根開始,按照決策樹的分類屬性逐層往下劃分,直到葉節點,獲得決策結果。y= DecisionTree(x)
基尼指數:1.對于樣本集D,假設有K個分類,則樣本屬于第k類的概率為p;,則此概率分布的基尼指數定義為:
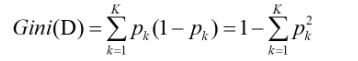
如果樣本集D按照某個屬性被劃分成獨立的兩個子集D,和Dz,其基尼指數為:
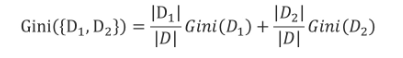
度量樣本集合純度最常用的一種指標。假定當前樣本集合D中第k類樣本所占的比例為p;(k = 1,2.. . , K),則D的信息嫡定義為:
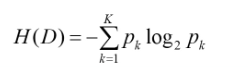
信息增益率:
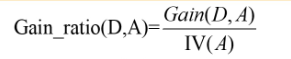
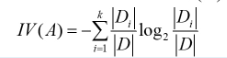
信息增益:
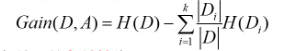
- 實驗內容
泰坦尼克號的沉沒是歷史上最著名的沉船之一。1912年4月15日,在首航期間,泰坦尼克號撞上一座冰山后沉沒,2224名乘客和機組人員中有1502人遇難。這一聳人聽聞的悲劇震撼了國際社會,并導致了更好的船舶安全條例。
沉船導致生命損失的原因之一是乘客和船員沒有足夠的救生艇。雖然幸存下來的運氣有一些因素,但有些人比其他人更有可能生存,比如婦女,兒童和上層階級。
在這個挑戰中,我們要求你完成對什么樣的人可能生存的分析。特別是,我們要求你運用機器學習的工具來預測哪些乘客幸存下來的悲劇。數據描述如下:
特征 | 描述 | 特征描述 |
PassengerId | 序號,乘客編號 | 乘客ID,對結果無影響 |
Survival | 生存,是否獲救 | 1是存活,0是未存活 |
Pclass | 票類別-社會地位 | 船艙等級,1 = Upper,2 = Middle,3= Lower |
Name | 乘客姓名 | 乘客姓名,對結果無影響 |
Sex | 性別 | male,female,女士優先,對結果有影響 |
Age | 年齡 | 年齡,對結果有影響 |
SibSp | 兄弟姐妹/配偶的數量 | 對結果有影響 |
Parch | 父母/孩子的數量 | 對結果有影響 |
Ticket | 票號 | 對結果無影響 |
Fare | 乘客票價 | 和船艙等級一樣,有影響 |
Cabin | 客艙號碼 | 對結果無影響 |
Embarked | 登船港口,上船地點 | C=Cherbourg, Q=Queenstown, S=Southampton 出發地點:S=英國南安普頓Southampton 途徑地點1:C=法國 瑟堡市Cherbourg 途徑地點2:Q=愛爾蘭 昆士敦Queenstown |
數據內容如下:
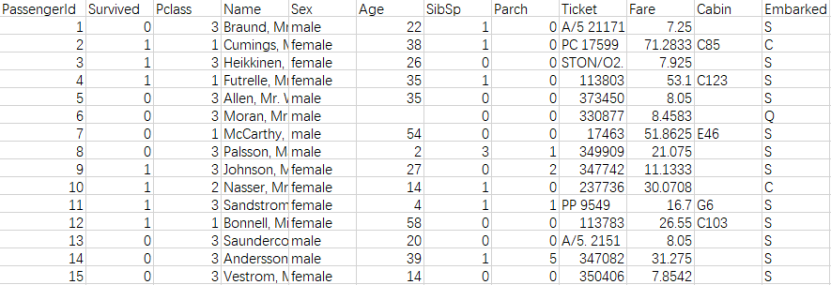
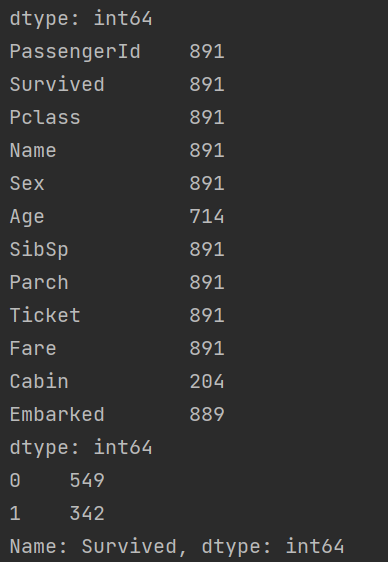
顯然,這次事故中沒有多少乘客幸免于難。在訓練集的891名乘客中,只有342人幸存下來,只有38.4%的機組人員在空難中幸存下來。我們需要從數據中挖掘出更多的信息,看看哪些類別的乘客幸存下來,哪些沒有。
數據特征分為:連續值和離散值。
- 離散值:性別(男,女),登船地點(S,Q,C)
- 連續值:年齡,船票價格
任務一、對數據集進行特征處理
1.1源代碼
- 導入數據
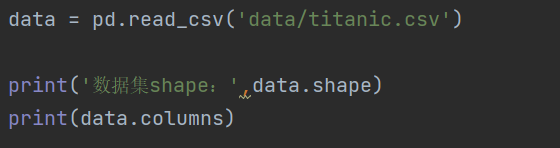
- 獲取數據類型的描述統計信息
print(data.describe())
- 查看數據信息:
?print(data.info())
提取行與列:

提取行列中的數據:

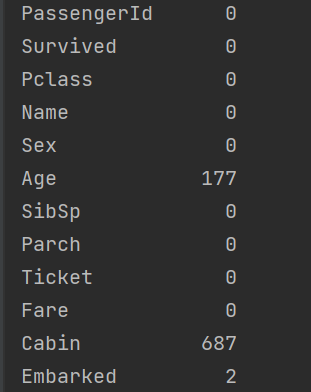
- 查看是否有缺失值:

- 生還情況:
print(data['Survived'].value_counts())
- 正則表達:
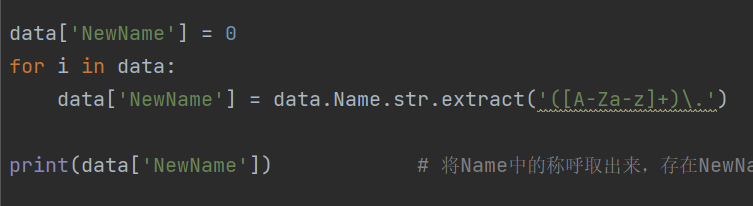
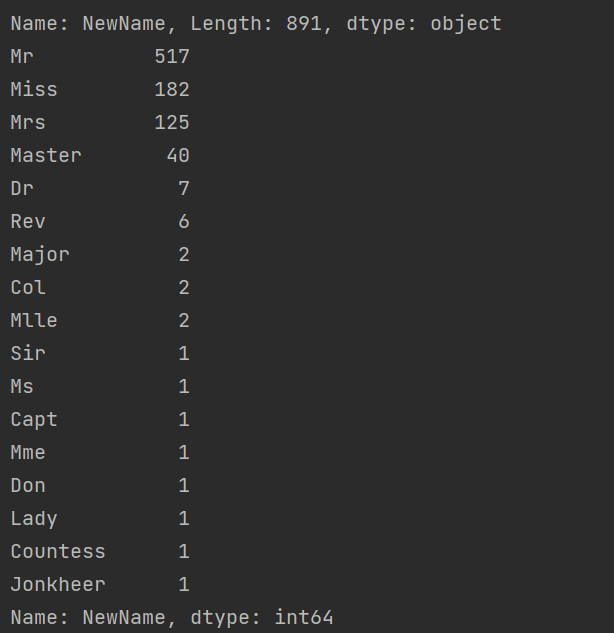
- 對值統計:
?print(data['NewName'].value_counts()) ?
- 替換:
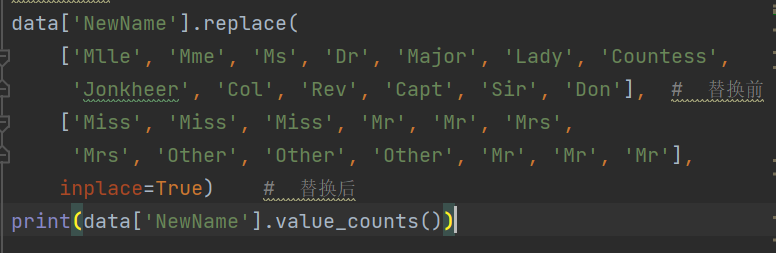
- 求平均年齡:
?print(data.groupby('NewName')['Age'].mean())
- 填充缺失值:
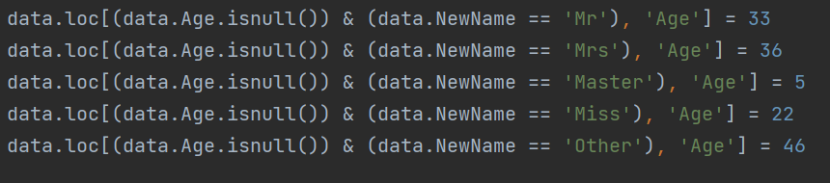
- 再次查看是否有缺失值并進行填充
?print(data.Age.isnull().sum()) ??# 0 表示沒有缺失值了。
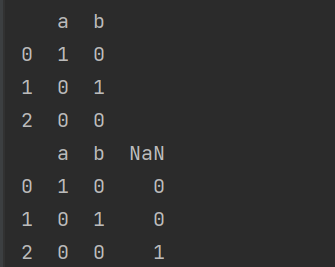
- One-hot編碼:
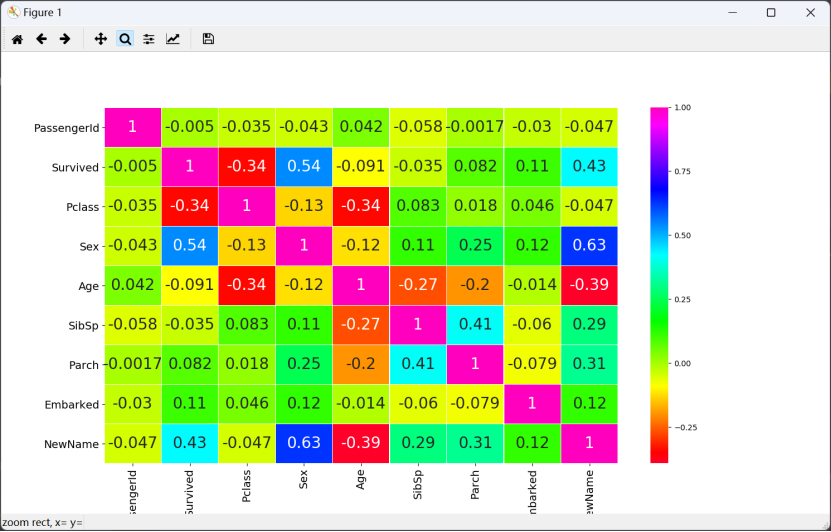
- 特征協方差關系圖:
sns.heatmap(data.corr(), annot=True, cmap='gist_rainbow', linewidths=0.2, annot_kws={'size': 20}) ??
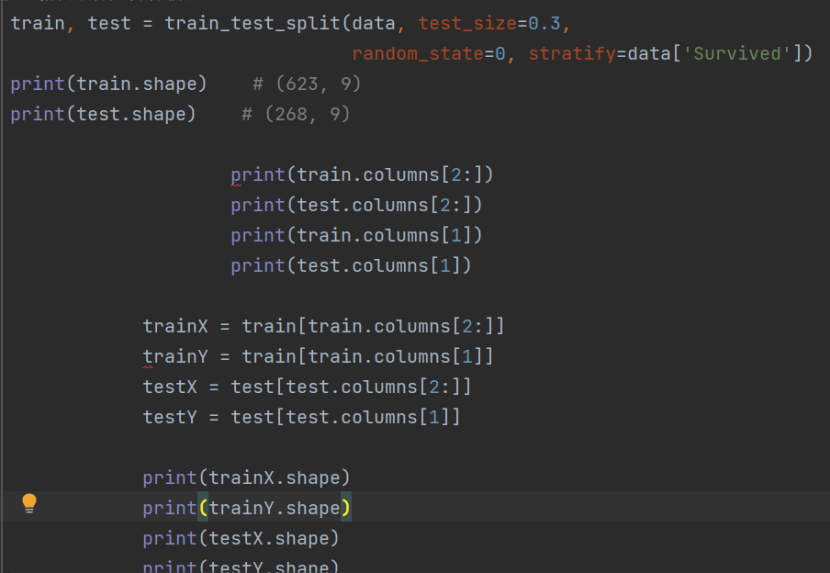
- 構建學習模型:測試集與訓練集
?
- 字符串值轉化為數字:
?

1.2實驗結果與分析
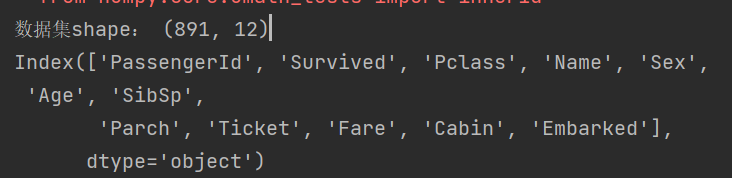
- 數據集詳情:
2.獲取數據類型的描述統計信息:
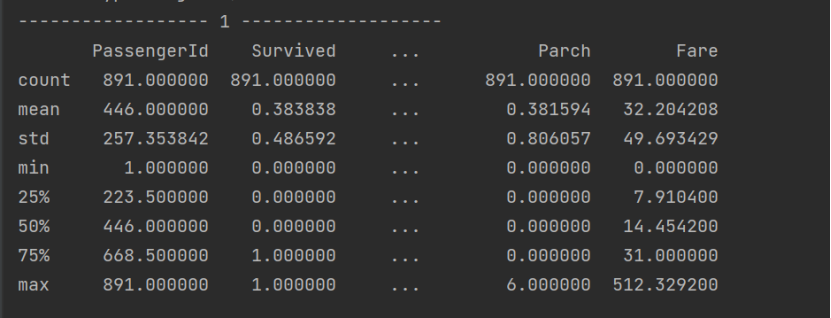
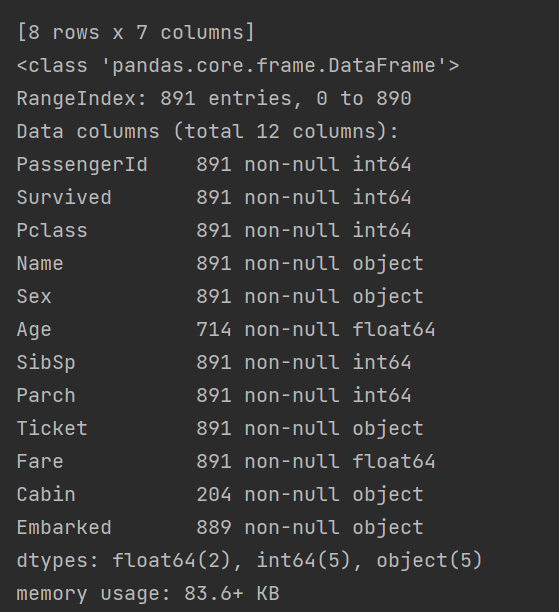
- 數據詳細信息:
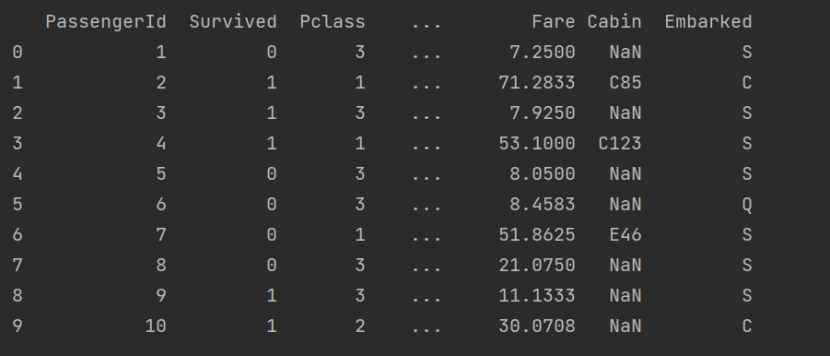
- 前十行數據:
- 第一行第一列:
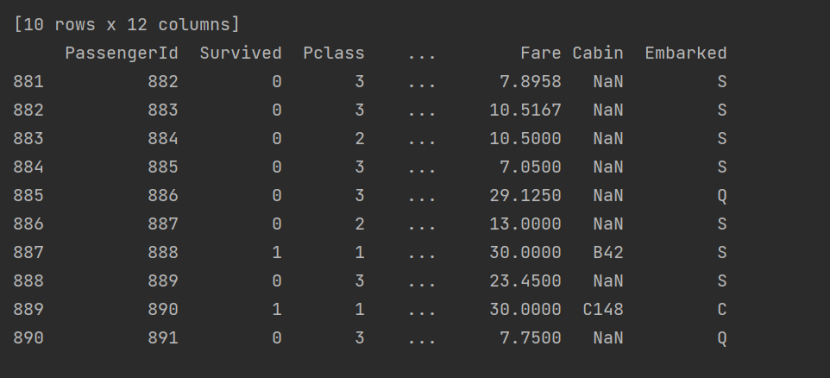
- 更詳細數據:
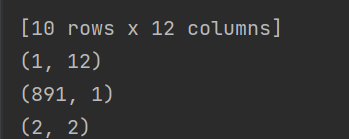
- 缺失值:
- 生還情況:
- 運用正則表達式,對值統計:
- 替換后:
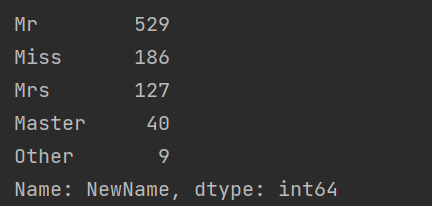
- 平均年齡:
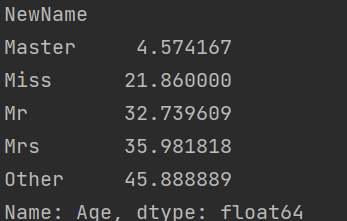
- 填補過程:計算出均值:
 港口確實填充:
港口確實填充: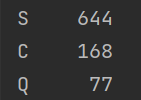
- 編碼輸出:
- 學習模型:
?
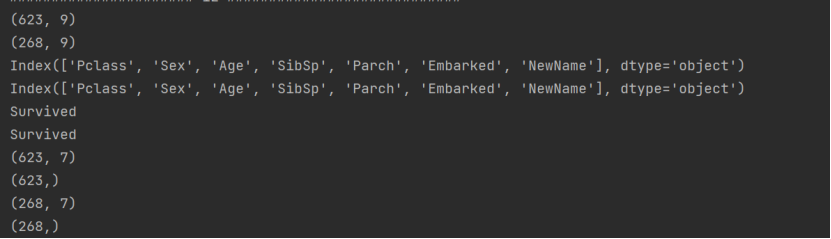
任務二、構建決策模型
2.1源代碼
- 構建決策樹
- 實現決策樹的可視化

2.2實驗結果與分析
決策樹可視化結果:
精確的決策樹信息

- 實驗總結及注意事項
實驗總結:特征工程的處理方法有數據預處理、特征提取,特征選擇和特征降維,最后構建響應模型;特征提取方面,我們的數值類型可直接使用,時間序列需轉成單獨的年月日,分類數據可用數值代替類別one-hot編碼。本次試驗中也可以使用常用的數據挖掘手段對乘客的獲救率進行預測。創建決策樹時,構建模型中需建立和測試數據集,從而進行達到評估模型的結果。
注意事項:導入數據與訓練數據集與前幾次實驗相通,本次的data明顯類型復雜許多,并且在決策樹建模過程,我們也可以通過交叉驗證的方法有待學習,最后,在這次問題的分析方面,也可以通過后面的學習進行數據分析,使用決策函數進行預測。















,上傳文件,后端插入數據,將文件保存到數據庫)
)
——pinctrl GPIO)


