概述
從文本等非結構化數據中提取結構化信息并非新鮮事物,但大語言模型(LLMs)為該領域帶來了重大變革。以往需要機器學習專家團隊策劃數據集并訓練自定義模型,如今只需訪問LLM即可實現,顯著降低了技術門檻,讓曾僅限領域專家使用的技術對非技術人員也更加友好。
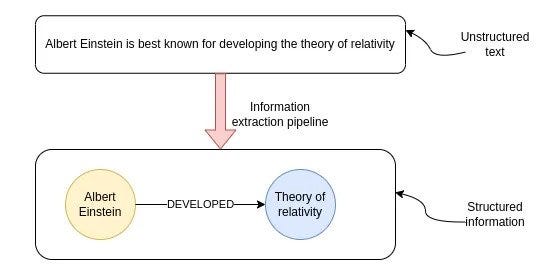
/* 信息提取管道的目標是從非結構化文本中提取結構化信息。*/
上圖展示了非結構化文本轉換為結構化信息的過程,該過程被稱為信息提取管道,最終得到信息的圖形表示。其中,節點代表關鍵實體,連接線表示實體之間的關系。知識圖譜在多跳問答、實時分析,或者需要在單個數據庫中結合結構化和非結構化數據等場景中非常實用。
盡管借助LLMs,從文本中提取結構化信息變得更加容易,但這絕非已解決的問題。在本文中,我們將結合OpenAI函數與LangChain,從示例維基百科頁面構建知識圖譜,同時探討最佳實踐以及當前LLMs的一些局限性。
Neo4j環境設置
要跟隨本文示例操作,需先設置Neo4j環境。最簡單的方法是在Neo4j Aura上啟動免費實例,獲取Neo4j數據庫的云實例;也可下載Neo4j Desktop應用程序,創建本地數據庫實例。
以下代碼用于實例化LangChain包裝器,以連接到Neo4j數據庫:
from langchain.graphs import Neo4jGraphurl = "neo4j+s://databases.neo4j.io"
username = "neo4j"
password = ""
graph = Neo4jGraph(url=url,username=username,password=password
)
信息提取管道
典型的信息提取管道包含以下步驟:
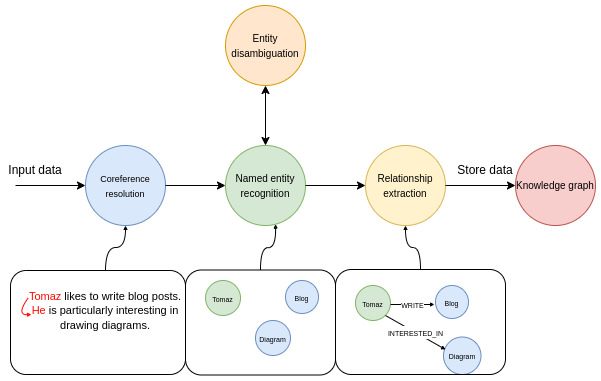
信息提取管道的多個步驟。
第一步,將輸入文本通過共指消解模型處理。共指消解的任務是找出所有指向特定實體的表達式,簡單來說,就是將所有代詞與所指代的實體關聯起來。在管道的命名實體識別部分,我們會嘗試提取所有提及的實體。例如,某個文本中包含Tomaz、Blog和Diagram三個實體。
下一步是實體消歧,這是信息提取管道中重要卻常被忽視的環節。實體消歧是準確識別和區分具有相似名稱或引用的實體的過程,確保在特定上下文中識別出正確的實體。
最后一步,模型會嘗試識別實體之間的各種關系。比如,可確定Tomaz和Blog實體之間存在LIKES關系。
使用OpenAI函數提取結構化信息
OpenAI函數非常適合從自然語言中提取結構化信息。其核心思路是讓LLM輸出一個預定義的JSON對象并填充值,該JSON對象可作為其他函數的輸入(如在所謂的RAG應用程序中),或用于從文本中提取預定義的結構化信息。
在LangChain中,可將Pydantic類作為OpenAI函數特性所需JSON對象的描述傳遞。因此,我們首先定義要從文本中提取的信息的結構。LangChain已提供節點和關系的定義,作為可重用的Pydantic類:
class Node(Serializable):"""表示圖中具有關聯屬性的節點。屬性:id (Union[str, int]): 節點的唯一標識符。type (str): 節點的類型或標簽,默認為"Node"。properties (dict): 與節點關聯的附加屬性和元數據。"""id: Union[str, int]type: str = "Node"properties: dict = Field(default_factory=dict)class Relationship(Serializable):"""表示圖中兩個節點之間的有向關系。屬性:source (Node): 關系的源節點。target (Node): 關系的目標節點。type (str): 關系的類型。properties (dict): 與關系關聯的附加屬性。"""source: Nodetarget: Nodetype: strproperties: dict = Field(default_factory=dict)
但遺憾的是,OpenAI函數目前不支持字典對象作為值,因此我們必須重寫properties的定義以符合函數端點的限制:
from langchain.graphs.graph_document import (Node as BaseNode,Relationship as BaseRelationship
)
from typing import List, Dict, Any, Optional
from langchain.pydantic_v1 import Field, BaseModelclass Property(BaseModel):"""由鍵和值組成的單個屬性"""key: str = Field(..., description="鍵")value: str = Field(..., description="值")class Node(BaseNode):properties: Optional[List[Property]] = Field(None, description="節點屬性列表")class Relationship(BaseRelationship):properties: Optional[List[Property]] = Field(None, description="關系屬性列表")
在這里,我們將properties值重寫為Property類的列表而非字典,以克服API限制。由于只能向API傳遞單個對象,我們需要將節點和關系組合到一個名為KnowledgeGraph的單個類中:
class KnowledgeGraph(BaseModel):"""生成具有實體和關系的知識圖譜。"""nodes: List[Node] = Field(..., description="知識圖譜中的節點列表")rels: List[Relationship] = Field(..., description="知識圖譜中的關系列表")
接下來只需進行一些提示工程即可開始操作。我進行提示工程的通常方式如下:
- 用自然語言迭代提示并改進結果
- 若某些內容未按預期工作,讓ChatGPT使指令更便于LLM理解任務
- 最后,當提示包含所有必要指令時,讓ChatGPT以markdown格式總結指令,以節省令牌并使指令更清晰
我特意選擇markdown格式,是因為曾了解到OpenAI模型對提示中的markdown語法響應更佳,從我的經驗來看,這似乎是合理的。
通過迭代提示工程,我為信息提取管道設計了以下系統提示:
llm = ChatOpenAI(model="gpt-3.5-turbo-16k", temperature=0)def get_extraction_chain(allowed_nodes: Optional[List[str]] = None,allowed_rels: Optional[List[str]] = None):prompt = ChatPromptTemplate.from_messages([("system",f"""# GPT-4的知識圖譜指令
## 1. 概述
你是一個頂級算法,專為以結構化格式提取信息以構建知識圖譜而設計。
- **節點**代表實體和概念。它們類似于維基百科節點。
- 目標是在知識圖譜中實現簡單性和清晰度,使其對廣大受眾可訪問。
## 2. 標記節點
- **一致性**:確保你為節點標簽使用基本或基礎類型。- 例如,當你識別代表人的實體時,始終將其標記為**"person"**。避免使用更具體的術語,如"mathematician"或"scientist"。
- **節點ID**:永遠不要使用整數作為節點ID。節點ID應該是在文本中找到的名稱或人類可讀的標識符。
{'- **允許的節點標簽:**' + ", ".join(allowed_nodes) if allowed_nodes else ""}
{'- **允許的關系類型**:' + ", ".join(allowed_rels) if allowed_rels else ""}
## 3. 處理數值數據和日期
- 數值數據,如年齡或其他相關信息,應作為相應節點的屬性或特性合并。
- **不為日期/數字創建單獨節點**:不要為日期或數值創建單獨的節點。始終將它們作為節點的屬性或特性附加。
- **屬性格式**:屬性必須采用鍵值格式。
- **引號**:在屬性值中永遠不要使用轉義的單引號或雙引號。
- **命名約定**:對屬性鍵使用駝峰命名法,例如`birthDate`。
## 4. 共指消解
- **保持實體一致性**:在提取實體時,確保一致性至關重要。
如果一個實體,如"John Doe",在文本中被多次提及,但被不同的名稱或代詞引用(例如,"Joe","he"),
在整個知識圖譜中始終使用該實體最完整的標識符。在這個例子中,使用"John Doe"作為實體ID。
記住,知識圖譜應該是連貫且易于理解的,因此在實體引用中保持一致性至關重要。
## 5. 嚴格遵守
嚴格遵守規則。不遵守將導致終止。"""),("human", "使用給定格式從以下輸入中提取信息:{input}"),("human", "提示:確保以正確格式回答"),])return create_structured_output_chain(KnowledgeGraph, llm, prompt, verbose=False)
我們使用的是GPT-3.5模型的16k版本,主要原因是OpenAI函數輸出為結構化的JSON對象,而結構化JSON語法會給結果增加大量令牌開銷。本質上,我們是為結構化輸出的便利性付出了增加令牌空間的代價。
除一般指令外,我還添加了限制從文本中提取的節點或關系類型的選項,通過后續示例你會了解其用處。
現在,我們已準備好Neo4j連接和LLM提示,可將信息提取管道定義為單個函數:
def extract_and_store_graph(document: Document,nodes:Optional[List[str]] = None,rels:Optional[List[str]]=None) -> None:# 使用OpenAI函數提取圖數據extract_chain = get_extraction_chain(nodes, rels)data = extract_chain.run(document.page_content)# 構建圖文檔graph_document = GraphDocument(nodes = [map_to_base_node(node) for node in data.nodes],relationships = [map_to_base_relationship(rel) for rel in data.rels],source = document)# 將信息存儲到圖中graph.add_graph_documents([graph_document])
該函數接收LangChain文檔以及可選的節點和關系參數,這些參數用于限制我們希望LLM識別和提取的對象類型。大約一個月前,我們向Neo4j圖對象添加了add_graph_documents方法,可在此處利用該方法無縫導入圖。
評估
我們將從沃爾特·迪士尼的維基百科頁面提取信息并構建知識圖譜,以測試該管道。在此過程中,會利用LangChain提供的維基百科加載器和文本分塊模塊:
from langchain.document_loaders import WikipediaLoader
from langchain.text_splitter import TokenTextSplitter# 讀取維基百科文章
raw_documents = WikipediaLoader(query="Walt Disney").load()
# 定義分塊策略
text_splitter = TokenTextSplitter(chunk_size=2048, chunk_overlap=24)# 只取前三個原始文檔
documents = text_splitter.split_documents(raw_documents[:3])
你可能已注意到我們使用了相對較大的chunk_size值,這是因為我們希望在單個句子周圍提供盡可能多的上下文,以便共指消解部分能更好地發揮作用。請記住,只有當實體及其引用出現在同一塊中時,共指步驟才能正常工作;否則,LLM沒有足夠信息來鏈接兩者。
現在,我們可以繼續讓文檔通過信息提取管道處理:
from tqdm import tqdmfor i, d in tqdm(enumerate(documents), total=len(documents)):extract_and_store_graph(d)
該過程大約需要5分鐘,速度相對較慢。因此,在生產環境中,你可能希望通過并行API調用來處理此問題,以實現一定的可擴展性。
首先,我們來看LLM識別的節點和關系類型:
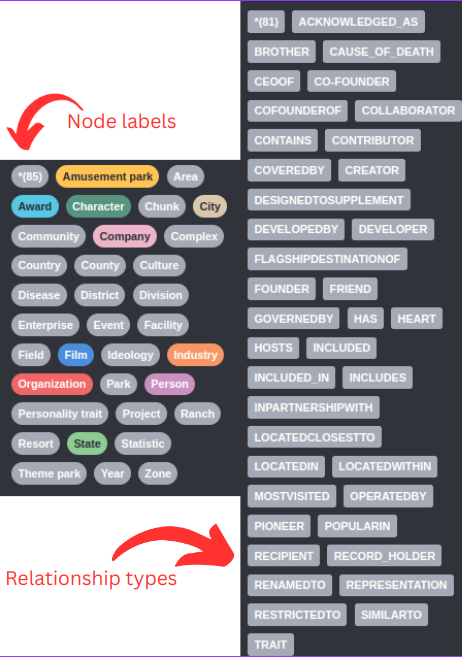
由于未提供圖模式,LLM會即時決定使用的節點標簽和關系類型。例如,我們可以看到存在Company和Organization節點標簽,這兩個在語義上可能相似或相同,所以我們希望只用一個節點標簽來表示兩者。關系類型的問題更為明顯,例如存在CO-FOUNDER和COFOUNDEROF關系,以及DEVELOPER和DEVELOPEDBY關系。
對于任何更嚴謹的項目,你都應該定義LLM應提取的節點標簽和關系類型。幸運的是,我們已經添加了通過傳遞附加參數在提示中限制類型的選項:
# 指定LLM應該提取哪些節點標簽
allowed_nodes = ["Person", "Company", "Location", "Event", "Movie", "Service", "Award"]for i, d in tqdm(enumerate(documents), total=len(documents)):extract_and_store_graph(d, allowed_nodes)
在這個例子中,我僅限制了節點標簽,你也可以通過向extract_and_store_graph函數傳遞另一個參數輕松限制關系類型。
提取的子圖的可視化結構如下:
放大圖像將被顯示
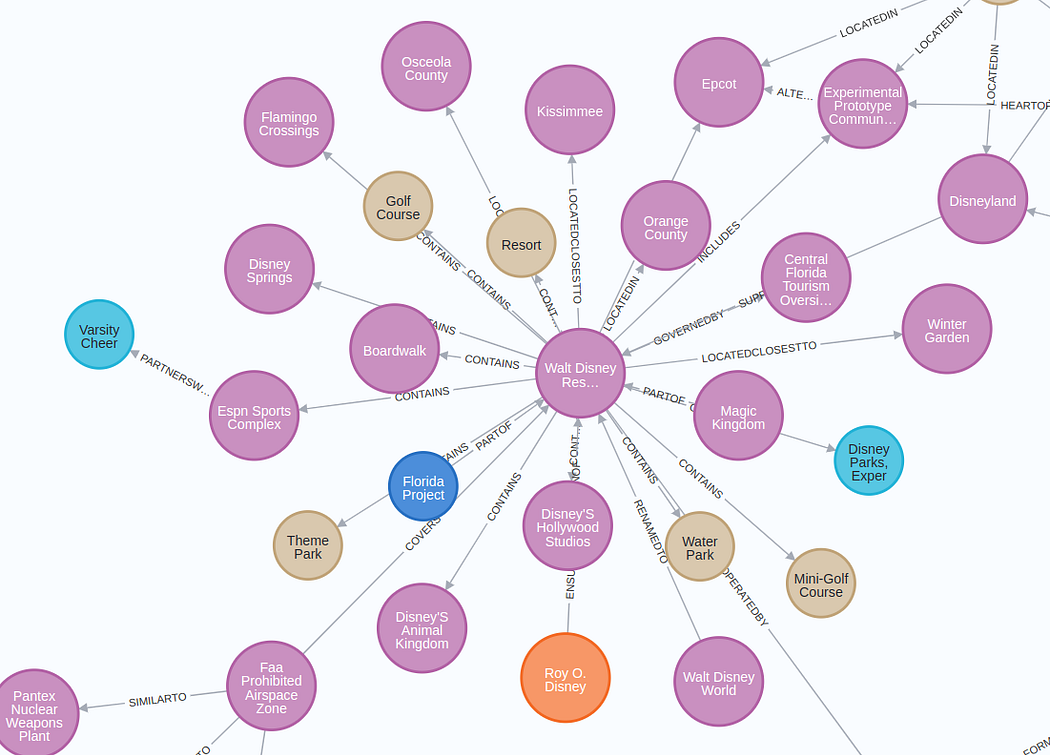
圖表結果比預期的要好(經過五次迭代后 😃 )。我無法在可視化中很好地呈現整個圖,但你可以在Neo4j瀏覽器或其他工具中自行探索。
實體消歧
需要說明的是,我們部分跳過了實體消歧環節。我們使用了較大的塊大小,并在系統提示中添加了共指消解和實體消歧的具體指令。但由于每個塊都是單獨處理的,無法確保不同文本塊之間實體的一致性。例如,可能會出現兩個代表同一個人的節點:
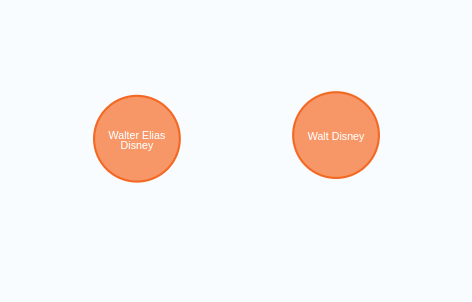
代表同一實體的多個節點。
在這個例子中,Walt Disney和Walter Elias Disney指的是同一個現實世界中的人。實體消歧問題并非新問題,已有多種解決方案:
- 使用實體鏈接或實體消歧 NLP模型
- 通過LLM進行第二次傳遞,要求其執行實體消歧
- 基于圖的方法
你應根據所在領域和具體用例選擇合適的解決方案。但請記住,實體消歧步驟不容忽視,因為它可能對RAG應用程序的準確性和有效性產生重大影響。
RAG應用程序
最后,我們將展示如何通過構建Cypher語句在知識圖譜中瀏覽信息。Cypher是用于處理圖數據庫的結構化查詢語言,類似于關系數據庫中的SQL。LangChain有一個GraphCypherQAChain,它能讀取圖的模式,并根據用戶輸入構建相應的Cypher語句:
# 在RAG應用程序中查詢知識圖譜
from langchain.chains import GraphCypherQAChaingraph.refresh_schema()
cypher_chain = GraphCypherQAChain.from_llm(graph=graph,cypher_llm=ChatOpenAI(temperature=0, model="gpt-4"),qa_llm=ChatOpenAI(temperature=0, model="gpt-3.5-turbo"),validate_cypher=True, # 驗證關系方向verbose=True
)
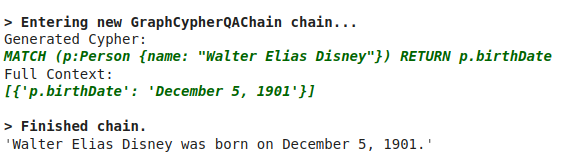
cypher_chain.run("Walter Elias Disney是什么時候出生的?")
結果如下:
總結
當需要結合結構化和非結構化數據來支持RAG應用程序時,知識圖譜是一個不錯的選擇。在本文中,你學習了如何使用OpenAI函數在任意文本上在Neo4j中構建知識圖譜。OpenAI函數提供了整潔的結構化輸出,使其成為提取結構化信息的理想選擇。為了在使用LLMs構建圖時獲得良好效果,請確保盡可能詳細地定義圖模式,并在提取后添加實體消歧步驟。
,上傳文件,后端插入數據,將文件保存到數據庫)
)
——pinctrl GPIO)



)





)


一個博客帶你了解所有問題)



