庖丁解牛:基于YOLO12與OpenCV的車輛部件級實例分割實戰(附完整代碼)
摘要: 告別“只見整車不見細節”!本文將帶您深入實戰,利用YOLO12-seg訓練實例分割模型,結合OpenCV的強大圖像處理能力,實現對車輛23個精細部件(從前后保險杠到左右后視鏡、車輪等)的像素級精準識別與分割。我們將完整展示從模型加載、推理到結果可視化與信息提取的全流程,代碼即學即用,助您構建下一代智能車輛分析系統!
關鍵詞: YOLO12, 實例分割, 車輛部件檢測, OpenCV, 計算機視覺, 深度學習, Python
【圖像算法 - 16】庖丁解牛:基于YOLO12與OpenCV的車輛部件級實例分割實戰
1. 引言:駛向精細化的車輛感知新時代
在自動駕駛、智能維修、保險定損、工業質檢等前沿領域,對車輛的感知已從“有沒有車”進化到“車的哪個部件出了問題”。傳統的整車檢測或粗略的目標檢測已無法滿足需求。我們需要一種技術,能夠像“庖丁解牛”一樣,精確地識別并分割出車輛的每一個獨立部件。
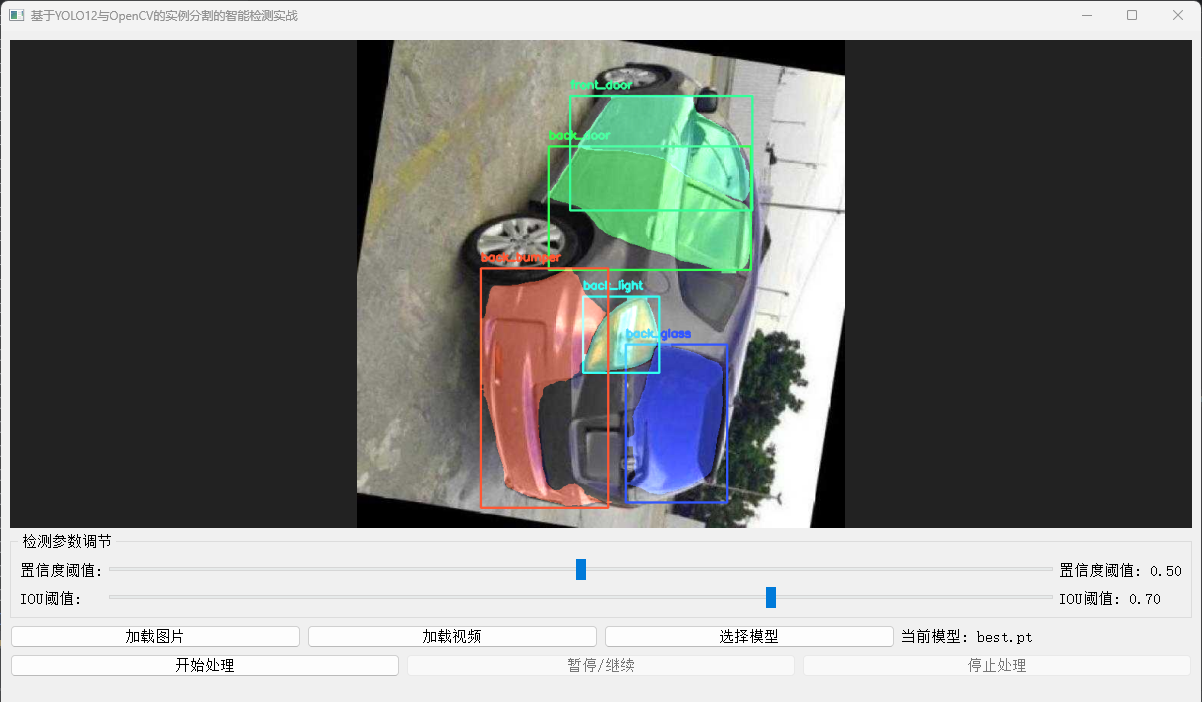
實例分割 (Instance Segmentation) 技術正是為此而生。它不僅能告訴您“這里有輛車”,更能精確指出“這是左前大燈”、“那是右后輪”,并描繪出它們真實的、像素級的輪廓。
本文將揭秘:一個基于YOLO12架構、在自定義高質量數據集上訓練的YOLO12-seg模型。該模型能夠精準識別您提供的23個車輛部件類別。我們將結合OpenCV,將這一強大的AI能力轉化為直觀、可量化的視覺結果。
2. 我們的利器:YOLO12-seg模型與OpenCV
- YOLO12-seg 模型:
- 高度定制化: 該模型并非通用模型,而是專門針對車輛部件識別任務,在包含23個精細類別的數據集上進行端到端訓練。模型深度理解了車輛部件的形態、紋理和空間關系。
- 卓越精度: YOLO12架構的先進性(如更高效的特征提取網絡、優化的分割頭設計)確保了在復雜場景下對細小部件(如車燈)和易混淆部件(如不同車門)的高精度分割。
- 生產就緒: 模型已通過充分驗證,可直接部署于實際應用場景。
- OpenCV:
- 結果呈現大師: 負責將模型輸出的抽象掩碼數據,轉化為人類可直觀理解的彩色疊加圖、清晰輪廓線。
- 信息提取引擎: 利用其強大的圖像處理函數,我們可以輕松計算每個部件的面積、周長,甚至進行形態學分析。
- 流程集成樞紐: 作為連接AI模型與應用系統的橋梁,實現無縫的圖像處理流水線。
3. 數據基石:23類精細車輛部件數據集
3.1數據集介紹
模型的卓越性能源于高質量的數據。訓練數據集經過精心構建,包含:
-
車輛部件分割數據集中的數據分布組織如下(下載鏈接):
- 訓練集: 包括 3156 張圖像,每張圖像都附有相應的注釋。該集合用于訓練深度學習模型。
- 測試集:包含 276 張圖像,每張圖像都與其各自的注釋配對。此集合用于在使用測試數據進行訓練后評估模型的性能。
- 驗證集:包含 401 張圖像,每張圖像都有相應的注釋。此集合在訓練期間用于調整超參數,并使用驗證數據防止過擬合。
-
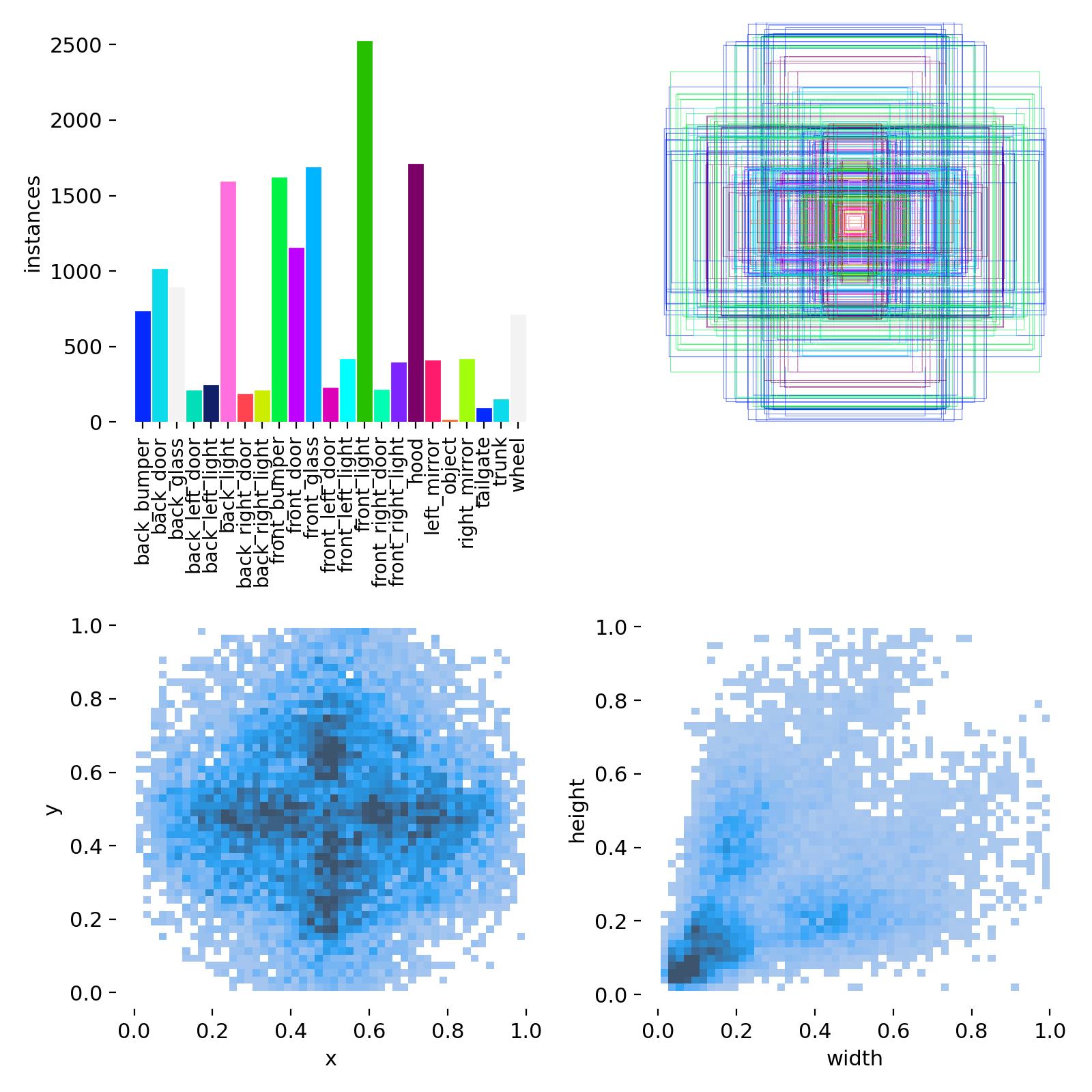
類別 (23類):
覆蓋了車輛的主要外部部件,定義清晰,無歧義。
names:0: back_bumper # 后保險杠1: back_door # 后車門 (整體)2: back_glass # 后擋風玻璃3: back_left_door # 左后車門4: back_left_light # 左后尾燈5: back_light # 后尾燈 (整體,若存在)6: back_right_door # 右后車門7: back_right_light # 右后尾燈8: front_bumper # 前保險杠9: front_door # 前車門 (整體)10: front_glass # 前擋風玻璃11: front_left_door # 左前車門12: front_left_light # 左前大燈13: front_light # 前大燈 (整體,若存在)14: front_right_door # 右前車門15: front_right_light # 右前大燈16: hood # 發動機蓋17: left_mirror # 左后視鏡18: object # (可能為背景或其他物體,使用時注意)19: right_mirror # 右后視鏡20: tailgate # 后備箱門 (SUV/兩廂車)21: trunk # 行李箱蓋 (三廂車)22: wheel # 車輪 (所有)
-
標注質量: 采用多邊形工具進行像素級精確標注,確保掩碼邊緣與部件真實邊界高度吻合。
-
數據多樣性: 包含不同品牌、型號、顏色、光照條件、拍攝角度(正面、側面、斜角、俯視)和部分遮擋場景的車輛圖像,保證了模型的泛化能力。


4.2 數據標注(如需)
- 工具推薦: LabelMe, CVAT, Roboflow。
- labelme數據標注保姆級教程:從安裝到格式轉換全流程,附常見問題避坑指南(含視頻講解)
- 標注要求: 為每一張圖像中的每一個汽車部件繪制精確的多邊形輪廓(Polygon)。標注工具會生成對應的JSON或COCO格式的標注文件。
- 數據格式: YOLO12支持 COCO格式 或其自定義的 YOLO格式(文本文件,每行代表一個實例:
class_id center_x center_y width height+ 多個x y坐標對表示分割點)。我們通常使用COCO格式。
4.3 數據增強 (Data Augmentation)
YOLO12在訓練時默認應用了強大的數據增強策略(如Mosaic, MixUp, 隨機旋轉、縮放、裁剪、色彩抖動等),這有助于提高模型的泛化能力,防止過擬合,尤其在數據量有限時效果顯著。
- Mosaic
- 當你看到 mosaic: 1.0,這意味著在數據增強過程中使用了 Mosaic 技術,并且其強度或概率設置為最大值(1.0)。Mosaic 數據增強方法通過將四張圖片隨機裁剪并拼接成一張圖片來創建新的訓練樣本。這有助于模型學習如何在不同的環境中識別目標,特別是當對象只占據了圖像的一部分時。
- MixUp
- 對于 mixup: 0.0,這表示不使用 Mixup 方法或者該方法的應用概率為最低(0.0)。Mixup 是一種更溫和的數據增強策略,它通過線性插值的方式在兩張圖片及其標簽之間生成新的訓練樣本。例如,如果你有兩張圖片 A 和 B,Mixup 可能會生成一個新的圖片 C,其中 C 的像素是 A 和 B 像素的加權平均值,
5. 環境準備
【圖像算法 - 01】保姆級深度學習環境搭建入門指南:硬件選型 + CUDA/cuDNN/Miniconda/PyTorch/Pycharm 安裝全流程(附版本匹配秘籍+文末有視頻講解)
5.1模型訓練
5.1.1 配置文件 (carparts-seg.yaml) 創建一個 carparts-seg.yaml 文件,描述數據集路徑和類別信息:
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]path: ../datasets/carparts-seg # dataset root dir
train: images/train # train images (relative to 'path') 3516 images
val: images/val # val images (relative to 'path') 276 images
test: images/test # test images (relative to 'path') 401 images# Classesnames:0: back_bumper1: back_door2: back_glass3: back_left_door4: back_left_light5: back_light6: back_right_door7: back_right_light8: front_bumper9: front_door10: front_glass11: front_left_door12: front_left_light13: front_light14: front_right_door15: front_right_light16: hood17: left_mirror18: object19: right_mirror20: tailgate21: trunk22: wheel
5.1.2 開始訓練 使用一行命令即可啟動訓練!Ultralytics提供了豐富的參數供調整。
from ultralytics import YOLO# 加載已訓練的YOLO12分割模型
model = YOLO('yolo12-seg.yaml') # 推薦使用s或m版本在精度和速度間平衡# 開始訓練
results = model.train(data='carparts-seg.yaml', # 指定數據配置文件epochs=100, # 訓練輪數imgsz=640, # 輸入圖像尺寸batch=16, # 批次大小 (根據GPU顯存調整)name='carparts_seg_v1', # 實驗名稱,結果保存在 runs/segment/carparts_seg_v1/device=0, # 使用GPU 0, 多GPU用 [0, 1, 2]# 以下為可選高級參數# optimizer='AdamW', # 優化器# lr0=0.01, # 初始學習率# lrf=0.01, # 最終學習率 (lr0 * lrf)# patience=20, # EarlyStopping 耐心值# augment=True, # 是否使用Mosaic等增強 (默認True)# fraction=1.0, # 使用數據集的比例# project='my_projects', # 結果保存的項目目錄
)
訓練結束后內容生成:
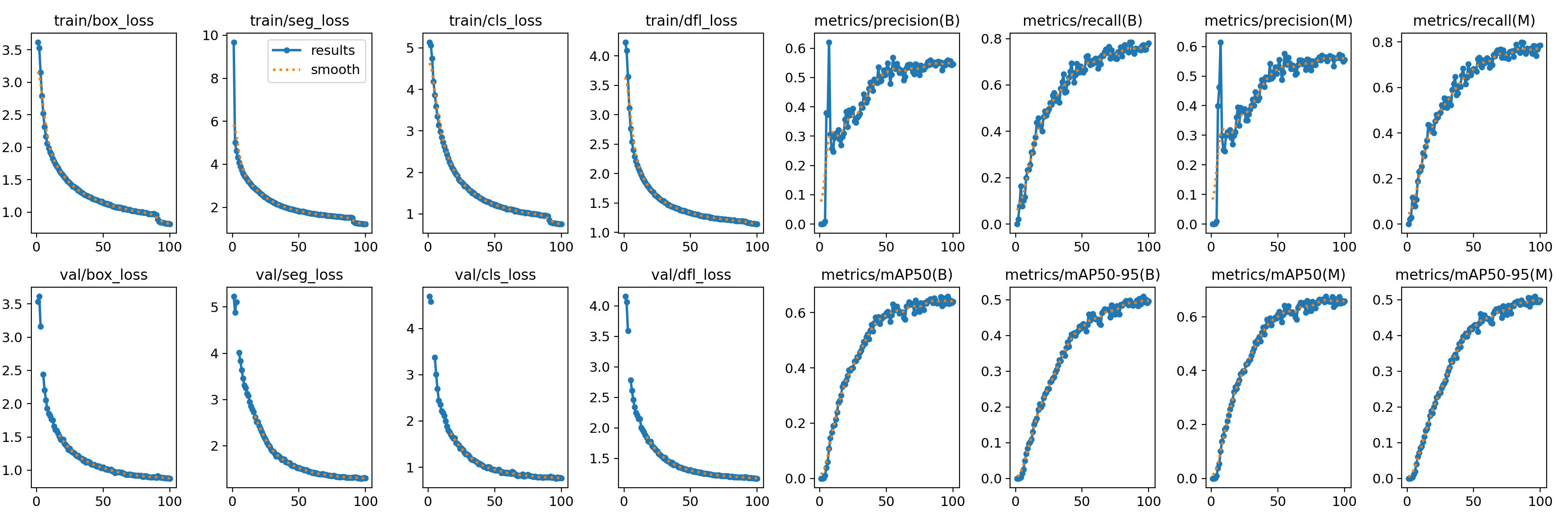
5.1.3 訓練過程監控
- 訓練過程中,Ultralytics會實時打印損失值(
box_loss,seg_loss,cls_loss,dfl_loss)和評估指標(precision,recall,mAP50,mAP50-95)。 - 在
runs/segment/carparts_seg_v1/目錄下會生成詳細的訓練日志、指標曲線圖(如results.png)和最佳權重文件(weights/best.pt)。
6. 核心代碼實現:車輛部件分割全流程
以下代碼展示了如何加載我們的模型并進行推理與可視化。
car_parts_with_colors = {0: {"name": "back_bumper", "color": (51, 87, 255)}, # 橙色 (BGR)1: {"name": "back_door", "color": (87, 255, 51)}, # 綠色2: {"name": "back_glass", "color": (255, 87, 51)}, # 藍色3: {"name": "back_left_door", "color": (51, 255, 243)},# 黃色4: {"name": "back_left_light", "color": (243, 51, 255)},# 粉色5: {"name": "back_light", "color": (243, 255, 51)}, # 青色6: {"name": "back_right_door", "color": (255, 51, 243)},# 紫色7: {"name": "back_right_light", "color": (51, 153, 255)},# 橙黃色8: {"name": "front_bumper", "color": (255, 51, 153)}, # 紫羅蘭色9: {"name": "front_door", "color": (153, 255, 51)}, # 青綠色10: {"name": "front_glass", "color": (51, 255, 153)}, # 淡綠色11: {"name": "front_left_door", "color": (51, 51, 255)},# 紅色12: {"name": "front_left_light", "color": (255, 51, 51)},# 深藍色13: {"name": "front_light", "color": (255, 51, 102)}, # 靛藍色14: {"name": "front_right_door", "color": (102, 255, 51)},# 淺綠色15: {"name": "front_right_light", "color": (51, 102, 255)},# 橙紅色16: {"name": "hood", "color": (51, 255, 102)}, # 淡黃綠色17: {"name": "left_mirror", "color": (255, 102, 51)}, # 天藍色18: {"name": "object", "color": (153, 153, 153)}, # 灰色19: {"name": "right_mirror", "color": (153, 153, 255)},# 淡紅色20: {"name": "tailgate", "color": (153, 255, 153)}, # 淡青色21: {"name": "trunk", "color": (255, 153, 153)}, # 淡紫色22: {"name": "wheel", "color": (0, 0, 0)} # 黑色
}def process_frame(self, frame, conf=None, iou=None):"""處理單幀圖像并統計目標數量"""current_conf = conf if conf is not None else self.confcurrent_iou = iou if iou is not None else self.iouoriginal_h, original_w = frame.shape[:2]# 目標檢測results = self.model(frame,conf=current_conf,iou=current_iou,stream=False)carparts_count = 0# 繪制邊界框并計數for result in results:boxes = result.boxes.xyxy.cpu().numpy()classes = result.boxes.cls.cpu().numpy().astype(int)# 檢查是否有掩碼if result.masks is not None:masks = result.masks.data.cpu().numpy() # (N, 640, 640)else:masks = []for i, (box, cls_id) in enumerate(zip(boxes, classes)):x1, y1, x2, y2 = map(int, box)label = car_parts_with_colors[cls_id]['name']carparts_count+= 1# 繪制邊界框cv2.rectangle(frame, (x1, y1), (x2, y2), car_parts_with_colors[cls_id]['color'], 2)# # ? 使用 masks.data 繪制掩碼if i < len(masks): # 安全檢查mask640 = masks[i] # (H, W),值為 0~1# mask = (mask > 0.5).astype(np.uint8) * 255 # 二值化mask = cv2.resize(mask640, (original_w, original_h), interpolation=cv2.INTER_NEAREST)mask = (mask > 0.5).astype(np.uint8) * 255color_mask = np.zeros_like(frame)color_mask[mask == 255] = car_parts_with_colors[cls_id]['color']frame = cv2.addWeighted(frame, 1.0, color_mask, 0.5, 0)cv2.putText(frame, label, (x1, y1 - 10),cv2.FONT_HERSHEY_SIMPLEX, 0.5, car_parts_with_colors[cls_id]['color'], 2)# 發送統計結果self.update_stats_signal.emit(carparts_count)return frame, results6. 代碼詳解與關鍵點
- 模型加載 (
YOLO(MODEL_PATH)): 這是核心,MODEL_PATH必須指向您訓練好的.pt文件。Ultralytics庫會自動識別YOLO12架構。 - 掩碼尺寸調整 (
cv2.resize): 這是最容易出錯的地方。masks.data的尺寸是模型的輸入尺寸(如640x640),必須使用cv2.resize并配合INTER_NEAREST插值法,將其精確縮放到原始輸入圖像的尺寸(original_width, original_height),否則可視化和面積計算將完全錯誤。 - 類別處理: 代碼中
names字典直接來自您訓練模型時的數據配置,包含了全部23個類別。通過interested_ids可以靈活篩選關注的部件。 - 可視化融合:
cv2.addWeighted實現了優雅的半透明疊加。cv2.drawContours繪制的黃色輪廓線使得部件邊界在復雜背景下依然清晰可辨。 - 信息量化:
mask_resized.sum()給出了該部件在圖像中的像素覆蓋面積,這是進行后續分析(如相對大小比較、損傷評估)的基礎。
7. 應用場景與價值
- 智能維修診斷: 上傳車輛照片,AI自動識別所有部件并高亮,維修人員可快速定位問題區域。計算破損部件的面積以估算維修成本。
- 保險定損自動化: 快速、客觀地評估事故車輛的損傷部件和程度,生成標準化報告,減少人為爭議。
- 自動駕駛感知增強: 讓自動駕駛系統“看清”周圍車輛的細節,例如判斷前車是否打轉向燈(通過識別對應側尾燈狀態)、是否開啟雙閃等。
- 車輛生產與質檢: 在生產線終端自動檢測車輛部件是否齊全、安裝是否正確、有無劃痕或凹陷。
- AR汽車展示/改裝: 在手機或平板上,用戶可以看到車輛各部件的名稱,并預覽更換不同部件(如輪轂、車燈)后的效果。
8. 總結
本文成功展示了如何利用我們自主訓練的YOLO12-seg實例分割模型和OpenCV,實現對車輛23個精細部件的精準識別與分割。這套方案不僅提供了“是什么”的答案,更給出了“在哪里”和“有多大”的精確信息。



詳解和完整示例)




變量的梯度)



摘自Openloong社區)
 查找速度深度對比)

)

包括機器學習方法預測缺失值的實踐)

