
- 作者: Shuo Wang1,3^{1,3}1,3, Yongcai Wang1^{1}1, Wanting Li1^{1}1 , Xudong Cai1^{1}1, Yucheng Wang3^{3}3, Maiyue Chen3^{3}3, Kaihui Wang3^{3}3, Zhizhong Su3^{3}3, Deying Li1^{1}1, Zhaoxin Fan2^{2}2
- 單位:1^{1}1中國人民大學,2^{2}2北京微芯區塊鏈與邊緣計算研究院,3^{3}3地平線機器人
- 論文標題:Aux-Think: Exploring Reasoning Strategies for Data-Efficient Vision-Language Navigation
- 論文鏈接:https://arxiv.org/pdf/2505.11886
- 項目主頁:https://horizonrobotics.github.io/robot_lab/aux-think/
- 代碼鏈接:https://github.com/HorizonRobotics/robo_orchard_lab/tree/master/projects/aux_think
主要貢獻
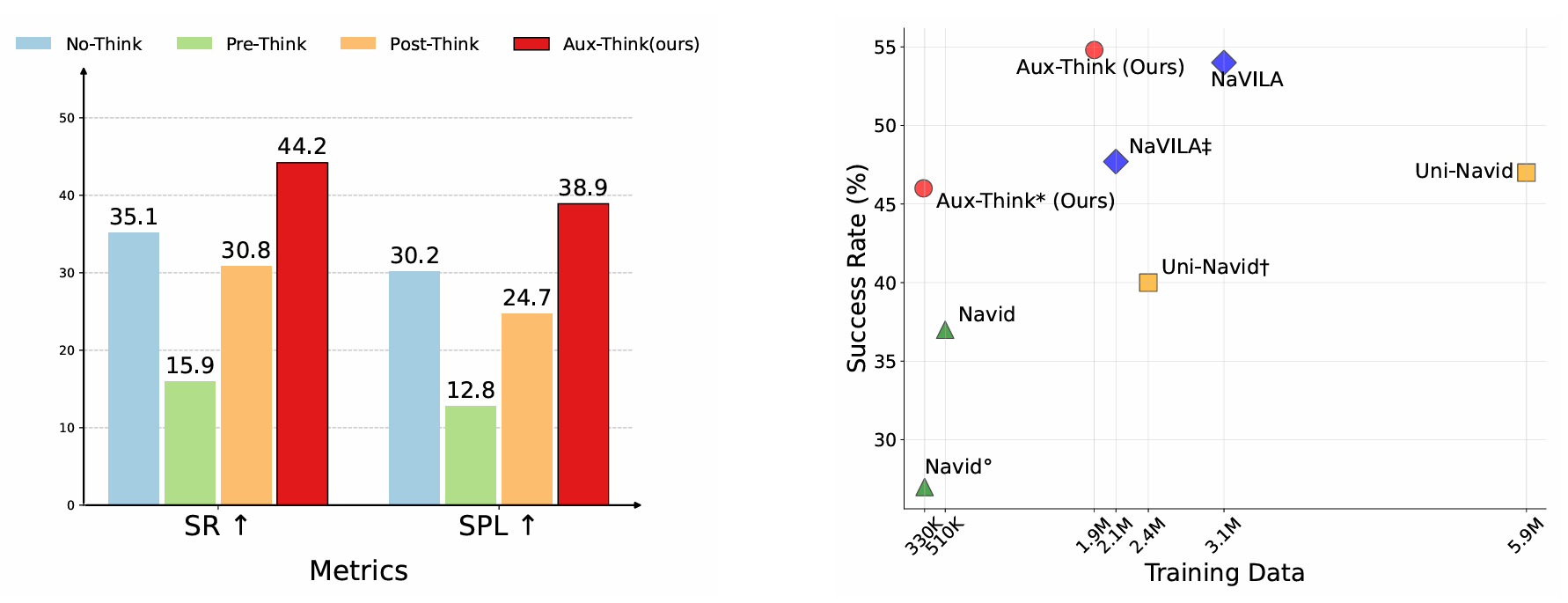
- 首次系統地比較了視覺語言導航(VLN)任務中不同推理策略的性能,揭示了推理時間推理崩塌(Inference-time Reasoning Collapse,IRC)問題,即在推理時引入顯式推理會降低導航性能。
- 提出了Aux-Think框架,該框架在訓練時使用思維鏈(Chain-of-Thought,CoT)作為輔助監督信號,而在推理時直接預測動作,避免了推理錯誤對導航性能的影響,實現了在數據效率和成功率之間的最佳權衡。
- 發布了R2R-CoT-320k數據集,這是首個針對VLN任務的思維鏈標注數據集,包含超過32萬條多樣化的推理軌跡,為研究推理在VLN中的作用提供了豐富資源。
研究背景
- 視覺語言導航(VLN)是讓機器人能夠理解自然語言指令并在復雜真實環境中導航的關鍵任務。近年來,基于大型預訓練模型(LLMs)和視覺語言模型(VLMs)的研究取得了顯著進展,提高了模型的泛化能力和指令對齊能力。
- 然而,推理策略在導航任務中的作用尚未得到充分研究,盡管思維鏈(CoT)在靜態任務(如視覺問答)中取得了成功,但其在VLN中的應用仍面臨挑戰。
方法
問題設定
論文研究了連續環境中的單目視覺語言導航(VLN-CE),目標是讓智能體根據自然語言指令在逼真的室內環境中導航。該任務強調對未見環境的泛化能力,并支持正向和反向導航,全面測試空間推理和語言理解能力。在每個時間步,智能體接收以下輸入:
- 自然語言指令(通常是一段短文本,指定導航目標);
- 當前視角的RGB圖像;
- 歷史觀測(從所有歷史幀中均勻采樣的8幀,始終包括第一幀)。
智能體需要選擇一個動作(例如前進、左轉/右轉特定角度或停止),目標是生成盡可能準確和高效的動作序列,直到到達目標位置。
R2R-CoT-320k 數據集構建
論文發布了R2R-CoT-320k數據集,首個針對VLN任務的思維鏈(CoT)標注數據集。該數據集基于R2R-CE基準構建,使用Habitat模擬器重建導航軌跡。
- 每個樣本包含當前視角、歷史視覺上下文、對應指令和真實動作。使用Qwen-2.5-VL-72B模型為每個導航樣本生成詳細的CoT標注。
- CoT標注的格式為帶有
<think>和<answer>標簽的推理軌跡,以符合近期推理模型的標準。
系統性研究推理策略對VLN的影響
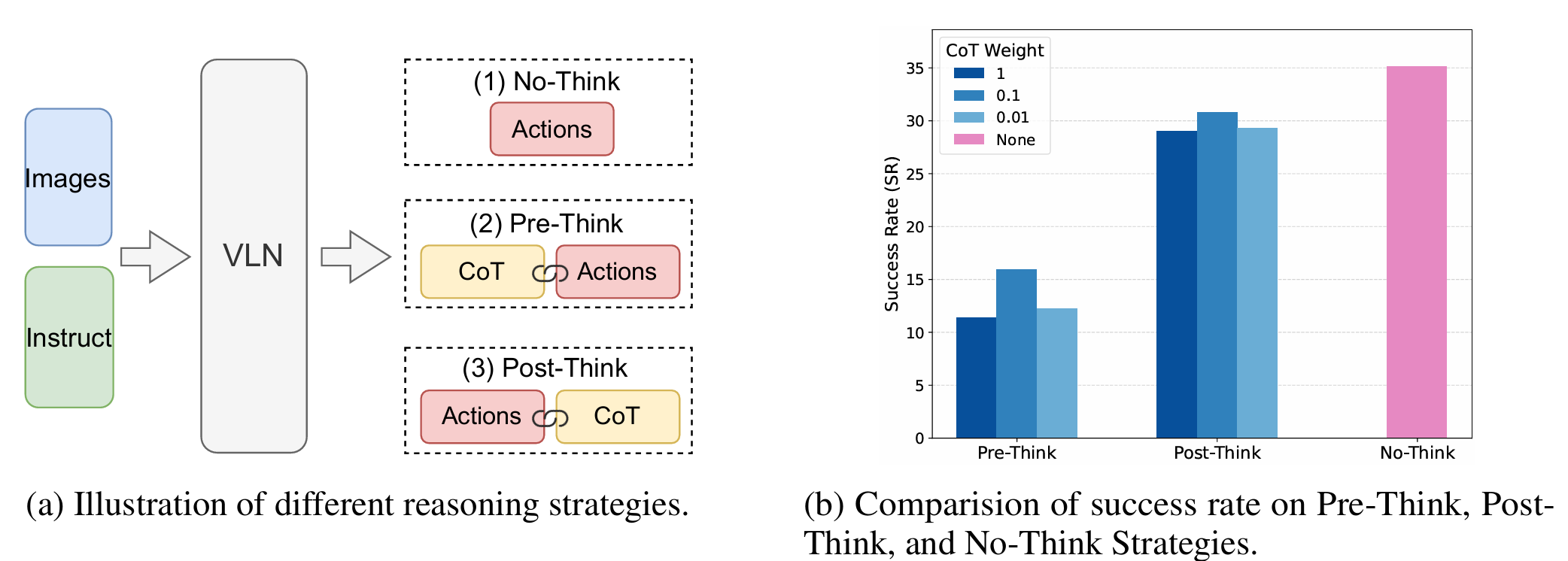
本文系統地研究了三種推理策略對VLN的影響:
- No-Think(無思考):智能體直接根據當前觀測和指令預測下一個動作,不進行中間推理。
- Pre-Think(先思考):智能體首先根據指令和當前觀測生成顯式推理軌跡,然后基于推理結果預測動作。
- Post-Think(后思考):智能體首先預測動作,然后生成解釋決策的推理軌跡。
通過實驗發現,Pre-Think和Post-Think策略的表現顯著低于No-Think策略,這表明在動態環境中,推理時間推理(CoT)是不可靠的。本文將這種現象稱為“推理時間推理崩塌”(IRC)。此外,文章還發現,在訓練時適度降低CoT部分的損失權重可以略微提升性能,這表明在訓練時對推理的重視程度是一個關鍵因素。
Aux-Think:推理感知協同訓練策略
為了解決CoT訓練對VLN的挑戰,提出了Aux-Think框架。該框架在訓練時僅使用CoT作為輔助監督信號,而在推理時直接預測動作,避免了推理錯誤對導航性能的影響。具體來說,Aux-Think框架包括以下三個任務:
- 基于CoT的推理:訓練模型根據指令、當前觀測和歷史觀測生成CoT軌跡,以加強語言、視覺和動作之間的聯系。
- 基于指令的推理:訓練模型根據一系列視覺觀測重構對應的指令,提供額外的語義監督。
- 遞推水平動作規劃:作為主要任務,模型根據指令、當前觀測和導航歷史預測接下來的n個動作,鼓勵短期預測并保持對新觀測的反應能力。
在訓練過程中,通過改變提示(prompt)在不同任務之間切換。最終的損失函數是上述三個任務損失的總和。在推理時,僅激活動作預測部分,模型直接預測接下來的n個動作并執行第一個動作,確保快速、反應式的導航,避免推理開銷。
實驗結果
實驗設置
- 在VLN-CE基準(R2R-CE和RxR-CE)上進行評估,遵循標準的VLN-CE設置。所有方法都在R2R的val-unseen分割和RxR的val-unseen分割上進行評估。
- 評估指標包括導航成功率(SR)、路徑長度加權成功率(SPL)、導航誤差等。
實現細節
- 使用NVILA-lite 8B作為基礎預訓練模型,該模型包括一個視覺編碼器(SigLIP)、一個投影器和一個語言模型(Qwen 2)。
- 通過監督微調從NVILA-lite的第二階段開始訓練VLN模型,總共訓練了一個epoch(約60小時),學習率為1e-5。
- 動作空間設計為四個類別:前進、左轉、右轉和停止,其中前進動作包括25cm、50cm和75cm的步長,轉向動作的旋轉角度為15°、30°和45°。
在VLN-CE基準上的比較
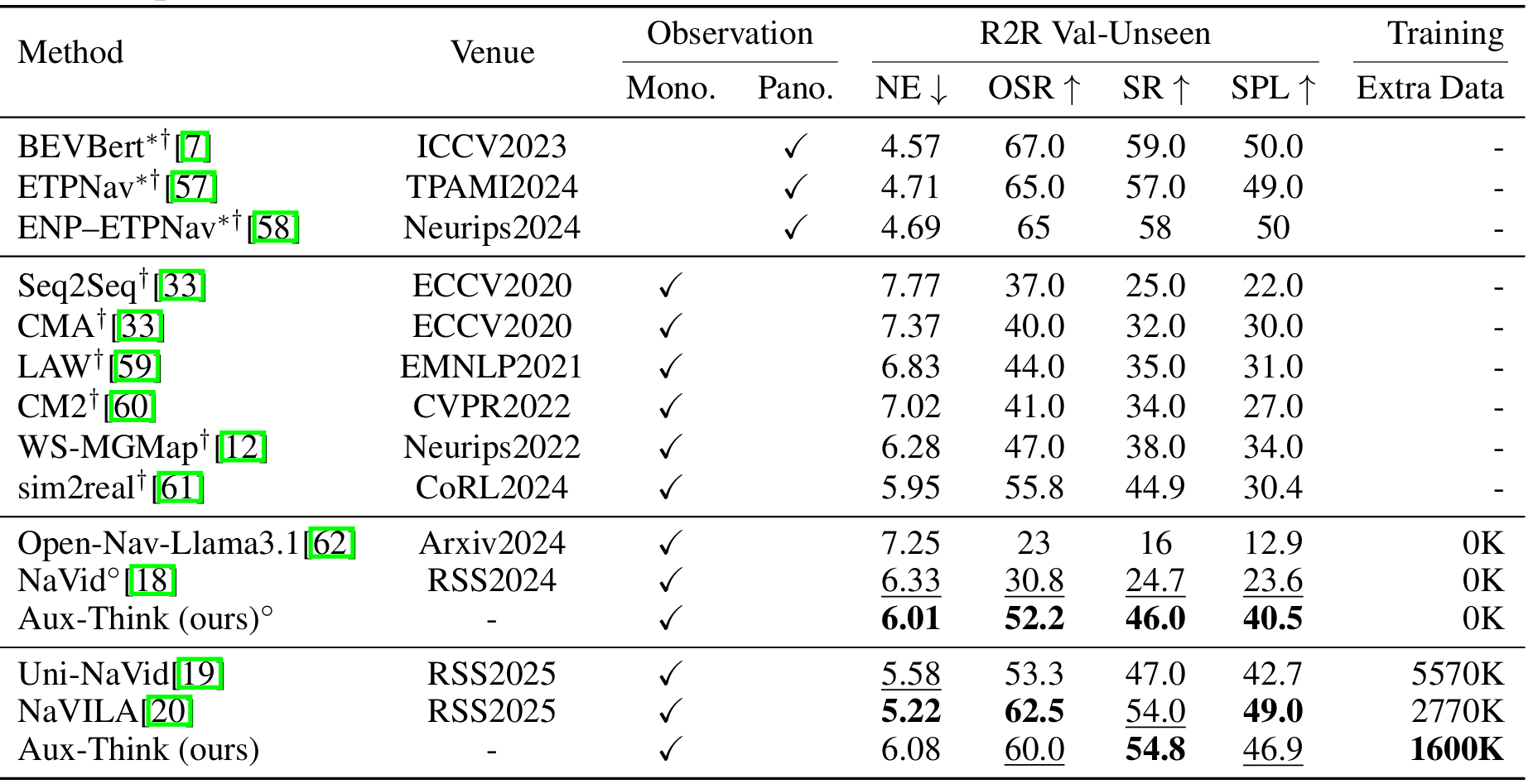
- 在R2R-CE數據集的val-unseen分割上,Aux-Think在不使用額外數據時取得了46.0%的成功率,在使用1600K額外數據時取得了54.8%的成功率,均優于其他基于大型模型的方法。
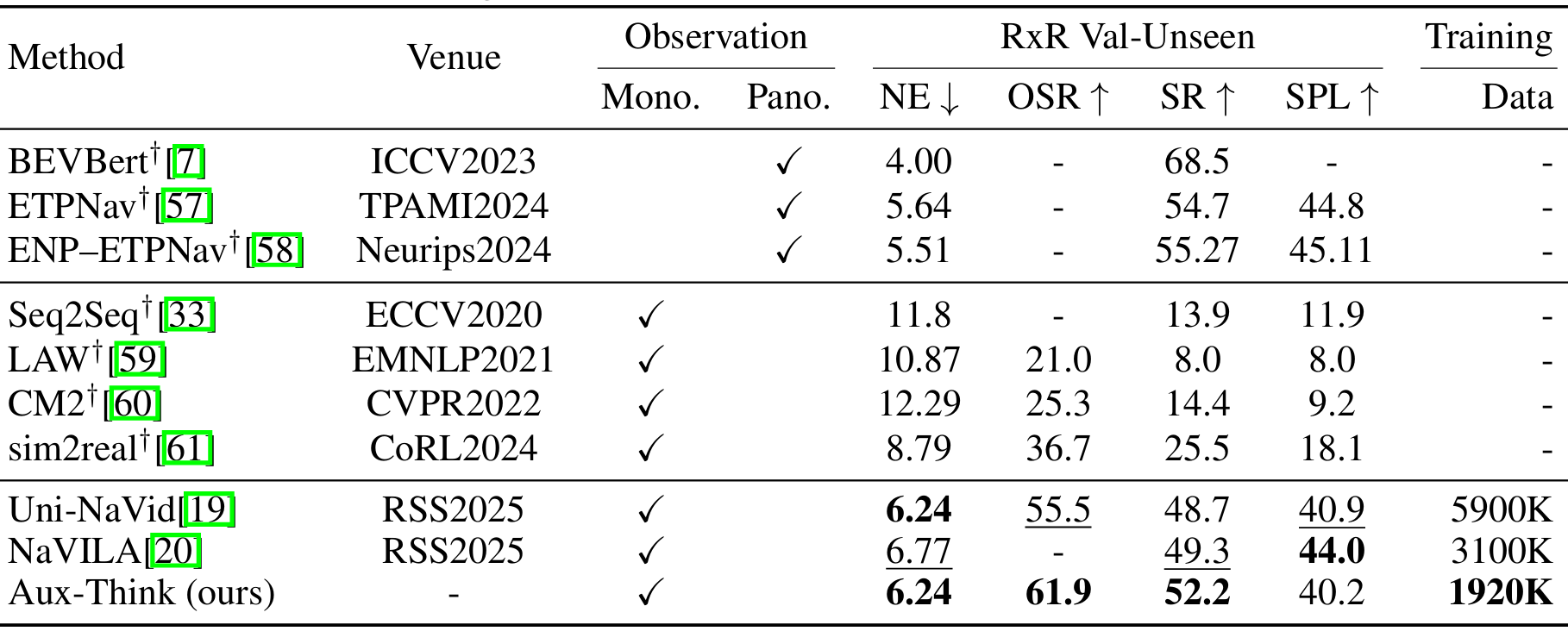
- 在RxR-CE數據集的val-unseen分割上,Aux-Think在成功率上超過了Uni-NaVid和NaVILA,同時使用的訓練數據更少(1920K vs. 5900K和3100K)。
- 這些結果表明,Aux-Think在有限數據下通過多級推理監督信號實現了更好的泛化能力。
不同推理策略的比較
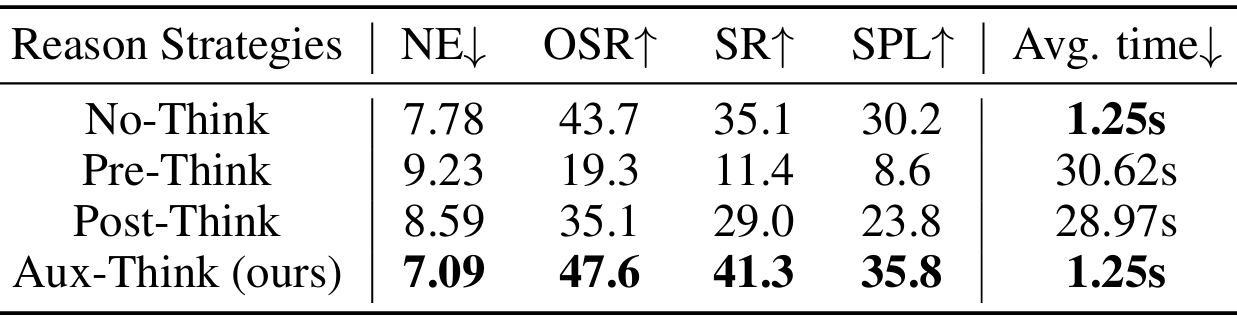
本文在R2R-CE數據集上比較了不同推理策略的性能。
- 結果表明,Pre-Think和Post-Think策略的成功率顯著低于No-Think策略。
- Pre-Think策略由于動作預測依賴于生成的CoT,因此低質量或學習不佳的CoT會直接影響動作的準確性。
- Post-Think策略雖然在一定程度上緩解了這個問題,但次優的CoT表示仍然會降低整體性能。
- 相比之下,Aux-Think通過將CoT和動作學習解耦,并將CoT知識隱式地內化到特征中,從而避免了推理錯誤對導航性能的影響。
消融研究
不同輔助任務和遞推水平動作規劃的影響
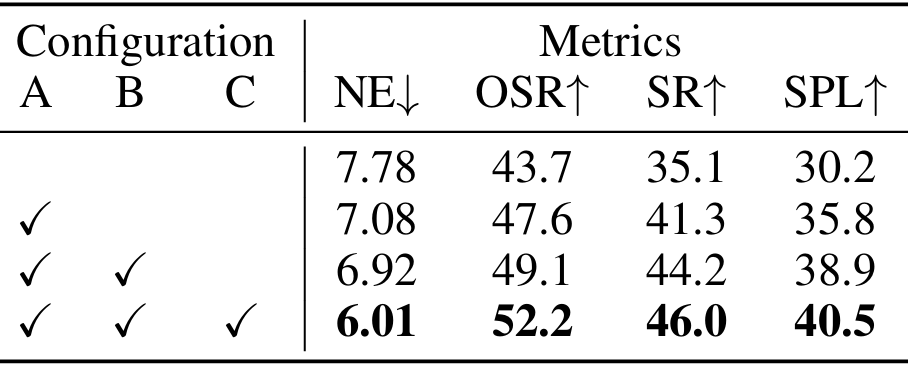
- 引入CoT推理可以顯著提升模型性能。
- 進一步添加非CoT推理可以進一步增強性能。
- 完整的模型(包含遞推水平動作規劃)在SPL和SR等指標上取得了最佳結果,表明長期規劃與隱式推理相結合可以產生最穩健的行為。
遞推水平動作規劃中步數的影響
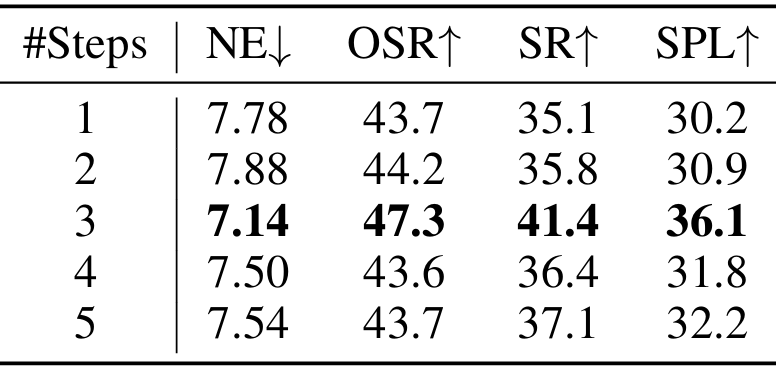
- 當預測步數為3時,模型取得了最佳性能。增加預測步數會導致性能下降,這可能是由于單目觀測的感知范圍有限,缺乏額外的全局知識,使得長水平預測更具挑戰性,可能導致模型生成次優或坍塌的導航策略。
結論與未來工作
- 結論:
- 通過系統研究VLN中的推理策略,發現了推理時間推理崩塌問題,并提出了Aux-Think框架來解決這一問題。
- 該框架通過在訓練時使用CoT作為輔助監督信號,在推理時直接預測動作,實現了在數據效率和導航性能之間的良好平衡。R2R-CoT-320k數據集的發布也為相關研究提供了重要資源。
- 未來工作:
- 目前的研究在受控的、廣泛采用的設置下評估了Aux-Think的數據效率,未來可以擴展到更大的導航數據集,并引入更豐富的輸入(如深度、全景、定位等)。
- 此外,本文尚未找到一種有效的方法通過強化學習同時提高CoT和動作質量,未來可以探索使用輕量級VLMs(如SmolVLM2)進行更可擴展的策略學習。













![[激光原理與應用-252]:理論 - 幾何光學 - 傳統透鏡焦距固定,但近年出現的可變形透鏡(如液態透鏡、彈性膜透鏡)可通過改變自身形狀動態調整焦距。](http://pic.xiahunao.cn/[激光原理與應用-252]:理論 - 幾何光學 - 傳統透鏡焦距固定,但近年出現的可變形透鏡(如液態透鏡、彈性膜透鏡)可通過改變自身形狀動態調整焦距。)


)



