目錄
- 第一部分:程序編譯
- 第二部分:函數解讀
- 1)Golang 核心初始化過程
- 2)創建第一個協程
- 3)啟動系統調度
- 4)跳轉main函數
- 5)總結
- 第三部分:GMP模型
- Goroutine
- 流程解讀
- 第四部分:內存分配與管理機制
- 第五部分:知識拓展
- 1)MMP
- 2)Channel解讀
- 第六部分:參考資料
第一部分:程序編譯
有如下代碼:
package main
import "fmt"
func main() {fmt.Println("Hello World!")
}#編譯運行
go build main.go
./main
Hello World!
我們通過readelf來讀main,結果如下:
readelf --file-header main 這個命令的意思是:
它使用 readelf 工具讀取并顯示 ELF(Executable and Linkable Format
可執行與可鏈接文件格式)文件 main 的 文件頭(ELF header) 信息。
# readelf命令解釋:
1)一個專門用來查看 ELF 格式文件信息的工具(屬于 binutils 工具集)。
2)可以讀取目標文件(object file)、可執行文件(executable)、共享庫(shared library)等。
3)它與 objdump 類似,但 readelf 只處理 ELF 文件,不依賴系統的運行時環境,因此輸出更精確和穩定。
# 參數--file-header 解釋
表示只顯示 ELF 文件頭(不是全部內容,比如節表、符號表等就不顯示)。
ELF 文件頭位于文件最開始,描述了文件的整體結構,比如文件類型、架構、入口地址、節表偏移量等。
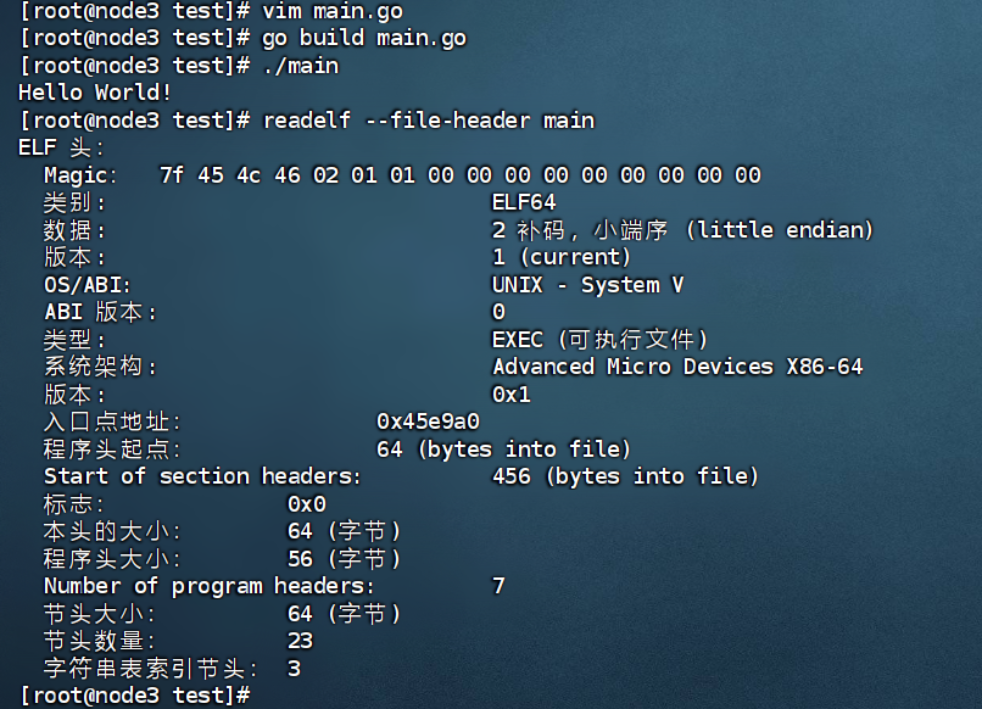
上圖的一些參數解釋:
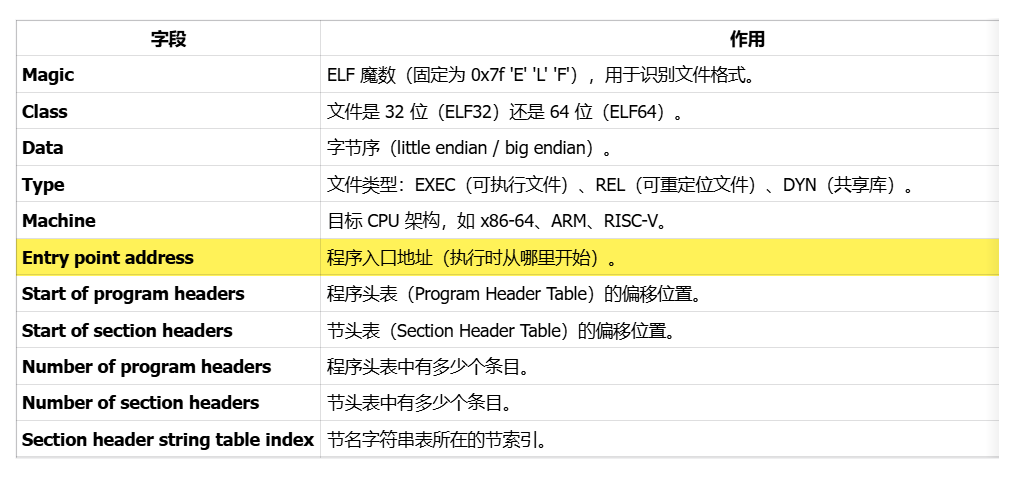
主要看到這個main函數的程序入口地址是:0x45e9a0
nm:這是一個用于列出二進制文件(如可執行文件、目標文件、庫文件等)中符號表的命令,通常用于程序調試和分析。
-n:nm 命令的選項,指定按符號的地址(數值)從小到大排序輸出,而不是默認按符號名稱排序。[root@node3 test]# nm -n main | grep 45e9a0
000000000045e9a0 T _rt0_amd64_linux結果解釋:
T 表示這個符號位于 .text 段(代碼段)并且是全局符號(全局可見的函數)。
這個地址 0x45e9a0 是程序加載到內存后的虛擬地址,不是文件的物理偏移。
我們需要進一步查看這個_rt0_amd64_linux符號的內容:
用gdb直接調試查看:
gdb main
(gdb) disassemble _rt0_amd64_linux
主要結果如下:
Dump of assembler code for function _rt0_amd64_linux:0x000000000045e9a0 <+0>: jmpq 0x45af80 <_rt0_amd64>
End of assembler dump._rt0_amd64_linux 只是一個跳板,最終跳轉到_rt0_amd64。我們進一步查看_rt0_amd64內容(通過地址直接跳轉):
(gdb) disassemble /r _rt0_amd64
Dump of assembler code for function _rt0_amd64:0x000000000045af80 <+0>: 48 8b 3c 24 mov (%rsp),%rdi0x000000000045af84 <+4>: 48 8d 74 24 08 lea 0x8(%rsp),%rsi0x000000000045af89 <+9>: e9 12 00 00 00 jmpq 0x45afa0 <runtime.rt0_go.abi0>
End of assembler dump.rt0_amd64 只是將參數簡單地保存一下后就 JMP 到 runtime·rt0_go 中了。繼續查看runtime.rt0_go的主要內容:
(gdb) disassemble /r runtime.rt0_go
---Type <return> to continue, or q <return> to quit---0x45b0b2 <runtime.rt0_go.abi0+274>: callq 0x45f660 <runtime.osinit.abi0>0x45b0b7 <runtime.rt0_go.abi0+279>: callq 0x45f7a0 <runtime.schedinit.abi0>0x45b0bc <runtime.rt0_go.abi0+284>: lea 0x5cb9d(%rip),%rax # 0x4b7c60 <runtime.mainPC>0x45b0c3 <runtime.rt0_go.abi0+291>: push %rax0x45b0c4 <runtime.rt0_go.abi0+292>: callq 0x45f800 <runtime.newproc.abi0>0x45b0c9 <runtime.rt0_go.abi0+297>: pop %rax0x45b0ca <runtime.rt0_go.abi0+298>: callq 0x45b140 <runtime.mstart.abi0>0x45b0cf <runtime.rt0_go.abi0+303>: callq 0x45d140 <runtime.abort.abi0>0x45b0d4 <runtime.rt0_go.abi0+308>: retq
解釋:
1)Golang 核心初始化過程(對 golang 運行時進行關鍵的初始化如GMP的初始化,與調度邏輯)
callq 0x45f660 <runtime.osinit.abi0>
callq 0x45f7a0 <runtime.schedinit.abi0>
2)調用 runtime·newproc 創建第一個協程(創建一個主協程,并指明 runtime.main 函數是其入口函數)
callq 0x45f800 <runtime.newproc.abi0>
3)啟動線程,啟動調度系統(真正開啟運行)callq 0x45b140 <runtime.mstart.abi0>
4)指定主函數的入口地址
runtime.mainPC 就是一個保存了 runtime.main 函數地址的全局變量,
它的主要用途就是——在 runtime.rt0_go 里作為參數傳給 runtime.newproc,
從而讓調度器創建一個 goroutine 去執行 runtime.main,也就是最終執行用戶的 main.main()。
第二部分:函數解讀
1)Golang 核心初始化過程
- runtime.osinit
#主要是獲取CPU數量,頁大小和操作系統初始化工作
func osinit() {ncpu = getproccount()physHugePageSize = getHugePageSize()osArchInit()
}
- runtime.schedinit
// file:runtime/proc.go
// The bootstrap sequence is:
//
// call osinit
// call schedinit
// make & queue new G
// call runtime·mstart
//
// The new G calls runtime·main.
func schedinit() {......// 默認情況下 procs 等于 cpu 個數// 如果設置了 GOMAXPROCS 則以這個為準procs := ncpuif n, ok := atoi32(gogetenv("GOMAXPROCS")); ok && n > 0 {procs = n}// 分配 procs 個 Pif procresize(procs) != nil {throw("unknown runnable goroutine during bootstrap")}......
} 注:
golang 的 bootstrap(啟動)流程步驟分別是
call osinit、call schedinit、make & queue new G 和 call runtime·mstart 四個步驟。
runtime.GOMAXPROCS 真正制約的是 GMP 中的 P,而不是 M
2)創建第一個協程
- runtime.newproc
//file:runtime/proc.go
func newproc(fn *funcval) {...systemstack(func() {newg := newproc1(fn, gp, pc)_p_ := getg().m.p.ptr()runqput(_p_, newg, true)if mainStarted {wakep()}})
}
[解釋]
1)runtime 代碼經常通過調用 systemstack 臨時性的切換到系統棧去執行一些特殊的任務
2)newproc1 創建一個協程
3)runqput 將協程添加到運行隊列
4)akep 喚醒一個線程去執行運行隊列中的協程
- newproc1
// file:runtime/proc.go
func newproc1(fn *funcval, callergp *g, callerpc uintptr) *g {...//從緩存中獲取或者創建 G 對象newg := gfget(_p_)if newg == nil {newg = malg(_StackMin)...}newg.sched.sp = spnewg.stktopsp = sp...newg.startpc = fn.fn...return newg
}
[解釋]
1)gfget 中是嘗試從緩存中獲取一個 G 對象出來
2)在調用 malg 時傳入了一個 _StackMin,這表示默認的棧大小,在 Golang 中的默認值是 2048
3)在 malg 創建完后,對新的 gorutine 對象進行一些設置后就返回了
- malg
// file:runtime/proc.go
func malg(stacksize int32) *g {newg := new(g)if stacksize >= 0 {//這里會在 stacksize 的基礎上為每個棧預留系統調用所需的內存大小 \_StackSystemstacksize = round2(_StackSystem + stacksize)}// 切換到 G0 為 newg 初始化棧內存systemstack(func() {newg.stack = stackalloc(uint32(stacksize))})// 設置 stackguard0 ,用來判斷是否要進行棧擴容 newg.stackguard0 = newg.stack.lo + _StackGuardnewg.stackguard1 = ^uintptr(0)
} //round2 函數會將傳入的值舍入為 2 的指數
- stackalloc
//file:runtime/stack.go
func stackalloc(n uint32) stack {thisg := getg()...//對齊到整數頁n = uint32(alignUp(uintptr(n), physPageSize))v := sysAlloc(uintptr(n), &memstats.stacks_sys)return stack{uintptr(v), uintptr(v) + uintptr(n)}
}
- sysAlloc
// file:runtime/mem_darwin.go
func sysAlloc(n uintptr, sysStat *sysMemStat) unsafe.Pointer {v, err := mmap(nil, n, _PROT_READ|_PROT_WRITE, _MAP_ANON|_MAP_PRIVATE, -1, 0)if err != 0 {return nil}sysStat.add(int64(n))return v
}
- runqput
// file:runtime/proc.go
// runqput tries to put g on the local runnable queue.
// If next is false, runqput adds g to the tail of the runnable queue.
// If next is true, runqput puts g in the _p_.runnext slot.
// If the run queue is full, runnext puts g on the global queue.
// Executed only by the owner P.
func runqput(_p_ *p, gp *g, next bool) {...//將新 goroutine 添加到 P 的 runnext 中if next {retryNext:oldnext := _p_.runnextif !_p_.runnext.cas(oldnext, guintptr(unsafe.Pointer(gp))) {goto retryNext}if oldnext == 0 {return}// 將原來的 runnext 添加到運行隊列中gp = oldnext.ptr()}//將新協程或者被從 runnext 上踢下來的協程添加到運行隊列中
retry:h := atomic.LoadAcq(&_p_.runqhead) // load-acquire, synchronize with consumerst := _p_.runqtail//如果 P 的運行隊列沒滿,那就添加到尾部if t-h < uint32(len(_p_.runq)) {_p_.runq[t%uint32(len(_p_.runq))].set(gp)atomic.StoreRel(&_p_.runqtail, t+1) // store-release, makes the item available for consumptionreturn}//如果滿了,就添加到全局運行隊列中if runqputslow(_p_, gp, h, t) {return}
}[解釋]
在 runqput 中首先嘗試將新協程放到 runnext 中,這個有優先執行權。
然后會將新協程,或者被新協程從 runnext 上踢下來的協程加入到當前 P(運行隊列)的尾部去。
但還有可能當前這個運行隊列已經任務過多了,那就需要調用 runqputslow 分一部分運行隊列中的協程到全局隊列中去。
- wakep
通過上面的函數已經創建了GMP模型當中的 G和P了。還剩一個M。// file:runtime/proc.go
func wakep() {...startm(nil, true)
}
- startm
// file:runtime/proc.go
// Schedules some M to run the p (creates an M if necessary).
func startm(_p_ *p, spinning bool) {mp := acquirem()//如果沒有傳入 p,就獲取一個 idel pif _p_ == nil {_p_ = pidleget()}//再獲取一個空閑的 mnmp := mget()if nmp == nil {//如果獲取不到,就創建一個出來newm(fn, _p_, id)...return}...
}
3)啟動系統調度
- runtime.mstart
// file:runtime/proc.go
func mstart0() {...mstart1()
}// file:runtime/proc.go
func mstart1() {...// 進入調度循環schedule()
}
- schedule
// file:runtime/proc.go
func schedule() {_g_ := getg()...
top:pp := _g_.m.p.ptr()//每 61 次從全局運行隊列中獲取可運行的協程if gp == nil {if _g_.m.p.ptr().schedtick%61 == 0 && sched.runqsize > 0 {lock(&sched.lock)gp = globrunqget(_g_.m.p.ptr(), 1)unlock(&sched.lock)}}if gp == nil {//從當前 P 的運行隊列中獲取可運行gp, inheritTime = runqget(_g_.m.p.ptr())}if gp == nil {//當前P或者全局隊列中獲取可運行協程//嘗試從其它P中steal任務來處理//如果獲取不到,就阻塞gp, inheritTime = findrunnable() // blocks until work is available}//執行協程execute(gp, inheritTime)
}4)跳轉main函數
在第一部分有如下的代碼:
0x45b0bc <runtime.rt0_go.abi0+284>: lea 0x5cb9d(%rip),%rax # 0x4b7c60 <runtime.mainPC>0x45b0c3 <runtime.rt0_go.abi0+291>: push %rax0x45b0c4 <runtime.rt0_go.abi0+292>: callq 0x45f800 <runtime.newproc.abi0>[解釋]1)runtime.mainPC 變量在編譯時被賦值為 runtime.main 的代碼地址2)push 的值就是要作為新 goroutine 入口的函數地址
- Main
// file:runtime/proc.go
// The main goroutine.
func main() {g := getg()// 在系統棧上運行 sysmonsystemstack(func() {newm(sysmon, nil, -1)})// runtime 內部 init 函數的執行,編譯器動態生成的。doInit(&runtime_inittask) // Must be before defer.// gc 啟動一個goroutine進行gc清掃gcenable()// 執行main initdoInit(&main_inittask)// 執行用戶mainfn := main_main // make an indirect call, as the linker doesn't know the address of the main package when laying down the runtimefn()// 退出程序exit(0)
}
5)總結
OS 加載程序 → _rt0_amd64_linux → _rt0_amd64 → runtime.rt0_go├─ osinit() # 初始化 OS 層信息├─ schedinit() # 初始化調度器和內存分配├─ newproc(mainPC=runtime.main) # 創建主協程└─ mstart() # 啟動調度循環└─ 調度器調度主協程 → runtime.main├─ 啟動 sysmon├─ 啟動 GC 清掃├─ 執行 runtime init├─ 執行用戶 init└─ 執行用戶 main.main()
第三部分:GMP模型
- 問題: 為什么需要協程?
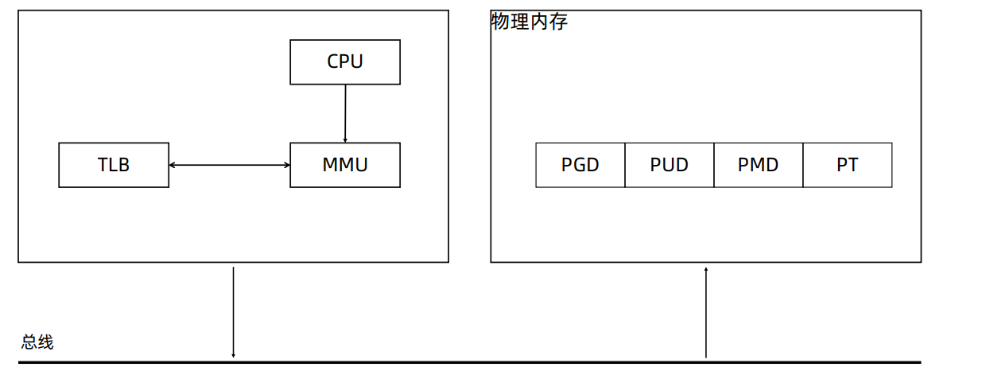
? CPU 上有個 Memory Management Unit(MMU) 單元
? CPU 把虛擬地址給 MMU,MMU 去物理內存中查詢頁表,得到實際的物理地址
? CPU 維護一份緩存 Translation Lookaside Buffer(TLB),緩存虛擬地址和物理地址的映射關系
進程/線程切換的開銷?
1)直接開銷
切換頁表全局目錄(PGD)
切換內核態堆棧
切換硬件上下文(進程恢復前,必須裝入寄存器的數據統稱為硬件上下文)
刷新 TLB
系統調度器的代碼執行
2)間接開銷
CPU 緩存失效導致的進程需要到內存直接訪問的 IO 操作變多
3)進程 vs 線程
線程切換相比進程切換,主要節省了虛擬地址空間的切換 - 協程
無需內核幫助,應用程序在用戶空間創建的可執行單元,創建銷毀完全在用戶態完成
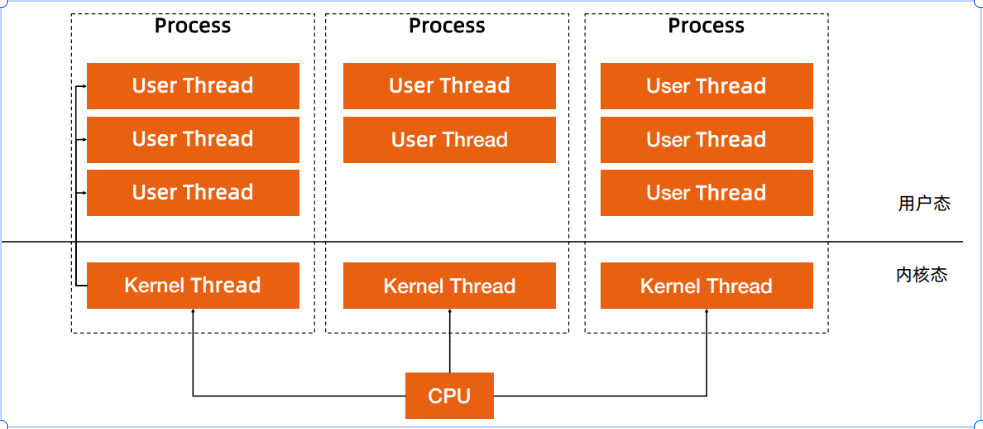
Goroutine
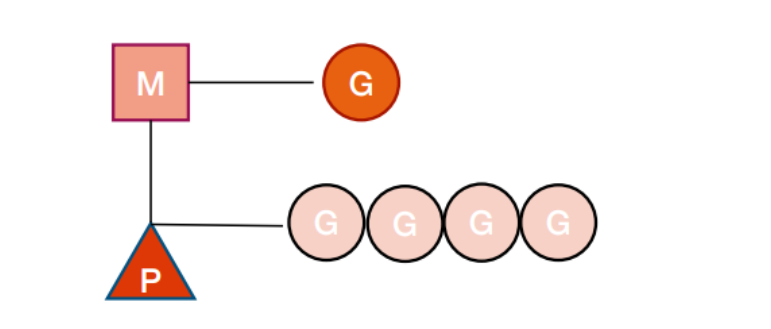
- G:表示 goroutine,每個 goroutine 都有自己的棧空間,定時器, 初始化的棧空間在 2k 左右,空間會隨著需求增長。
- M:抽象化代表內核線程,記錄內核線程棧信息,當 goroutine 調度 到線程時,使用該 goroutine 自己的棧信息。
- P:代表調度器,負責調度 goroutine,維護一個本地 goroutine 隊 列,M 從 P 上獲得 goroutine 并執行,同時還負責部分內存的管理。
流程解讀
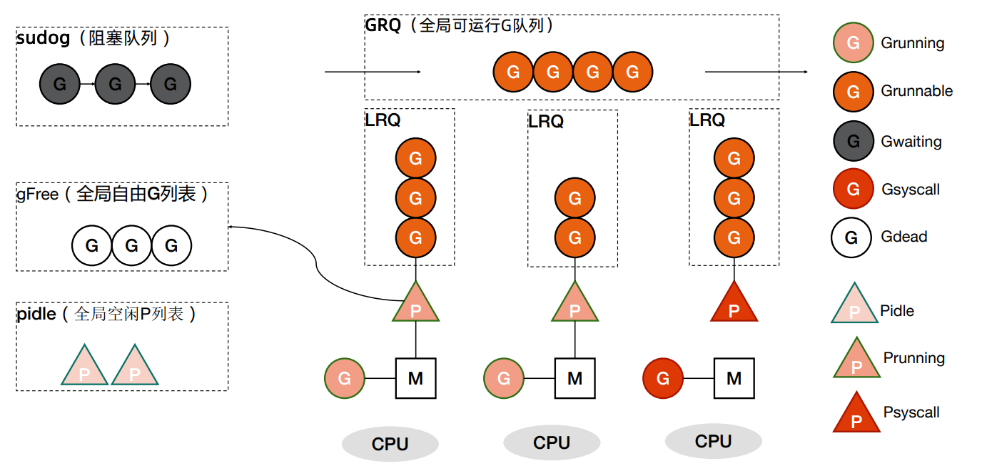
新建 G → 本地隊列↓ 隊列滿?——是——→ 搬一半到全局隊列↓ 否
調度循環:本地有任務?——是——→ 執行↓ 否全局有任務?——是——→ 批量取到本地↓ 否竊取其他 P 的一半任務↓ 全無釋放 P,M 休眠等待喚醒
- 創建 G(newproc)
runtime 會創建一個新的 G 結構,包含執行函數、初始棧、調度狀態等。
這個 G 會被加入當前 P 的本地隊列(runq)。
設計原因:
本地隊列無鎖訪問,速度快。
先放本地隊列可以提高 CPU cache 命中率(新創建的 goroutine 往往與當前 G 相關聯)。
- 本地隊列滿了 → 把一半 goroutine 放到全局隊列
每個 P 的本地隊列有固定長度(默認 256 個 G)。
如果隊列已滿:
從本地隊列中取一半 goroutine 移動到 全局隊列(gqueue)。
把新 G 放回剩下的一半。
設計原因:
全局隊列是所有 P 共享的,必須加鎖;減少訪問全局隊列的頻率。
把一半搬走而不是全部,保證本地隊列還有任務繼續跑。
- 調度循環:本地隊列有 G → 直接取來運行
M 綁定 P 后,會進入調度循環:
從 P 的本地隊列取一個 G。
切換到該 G 的棧,執行其函數。
執行完一個時間片(或被阻塞、主動讓出),調度器切回 M/P,繼續取下一個 G。
設計原因:
本地隊列是 M 綁定的 P 專用,取任務無需加鎖 → 非常快。
- 本地隊列為空 → 從全局隊列獲取 G
本地隊列為空 → 從全局隊列獲取 G
如果本地隊列沒任務:
嘗試從全局隊列取一批 G(最多取本地隊列一半的空間)。
設計原因:
讓長時間空閑的 P 能盡快參與調度其他 goroutine。
批量取可以減少鎖競爭。
- 全局隊列也空 → 從其他 P 偷(Work Stealing)
如果全局隊列也沒任務:
隨機選擇一個鄰居 P,從它的本地隊列偷一半 goroutine。
設計原因:
Work Stealing 保證了負載均衡。
隨機偷而不是按順序,減少多個 P 同時爭搶同一個 P 的概率。
- 仍然沒有任務 → M 進入休眠
如果本地隊列、全局隊列、鄰居隊列都沒任務:
M 會解除與 P 的綁定,把 P 放回空閑隊列。
M 進入休眠狀態(阻塞在 park)。
等待新任務到來時,P 被喚醒并綁定空閑的 M(或新建 M)。
設計原因:
避免空轉浪費 CPU。
節省線程資源,降低系統調用負擔。
- 總結
Go 調度器優先用 P 的本地隊列 運行 G,本地沒任務就去全局隊列或鄰居 P 偷任務,全都沒任務就讓 M 休眠;這種 本地優先 + 全局補充 + 工作竊取 + 休眠喚醒 的模式,讓 goroutine 在多核上高效、均衡地運行。
【注】更詳細的流程解讀,可以看參考資料部分的文章!!!
第四部分:內存分配與管理機制
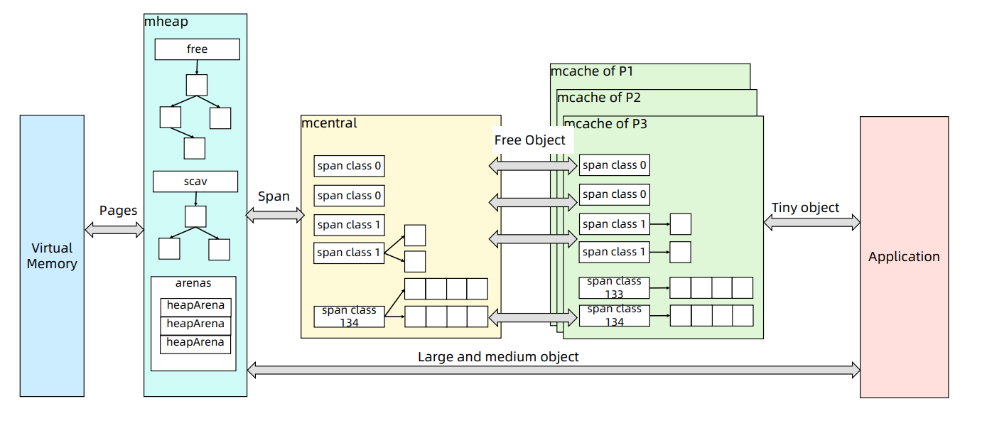
流程解讀:
- 三層架構
[OS] <-- 系統調用 mmap/brk -->↑
[mheap] # 全局堆管理(大對象 / 跨 P/M 的共享資源)↑
[mcentral]# 按 size class 組織的 span 中央池(每個 size class 兩個鏈表)↑
[mcache] # 每個 P 的本地緩存(小對象快速分配)
- mcache:P 本地緩存
位置:每個 P(Processor)都有一個 mcache,即 goroutine 調度中的本地內存分配器。
作用:負責小對象(< 32KB)的快速分配。
原理:
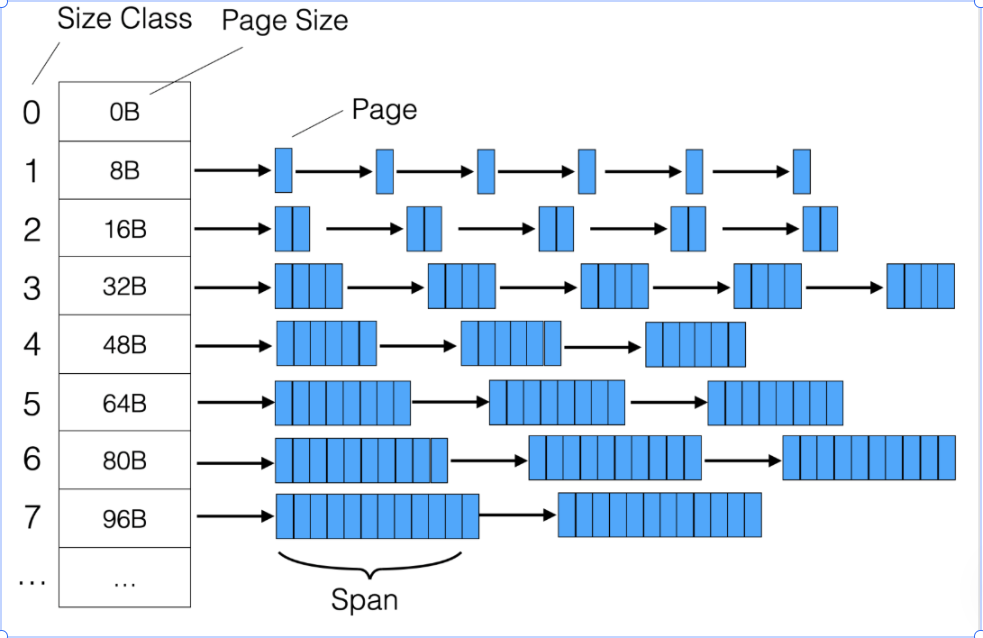
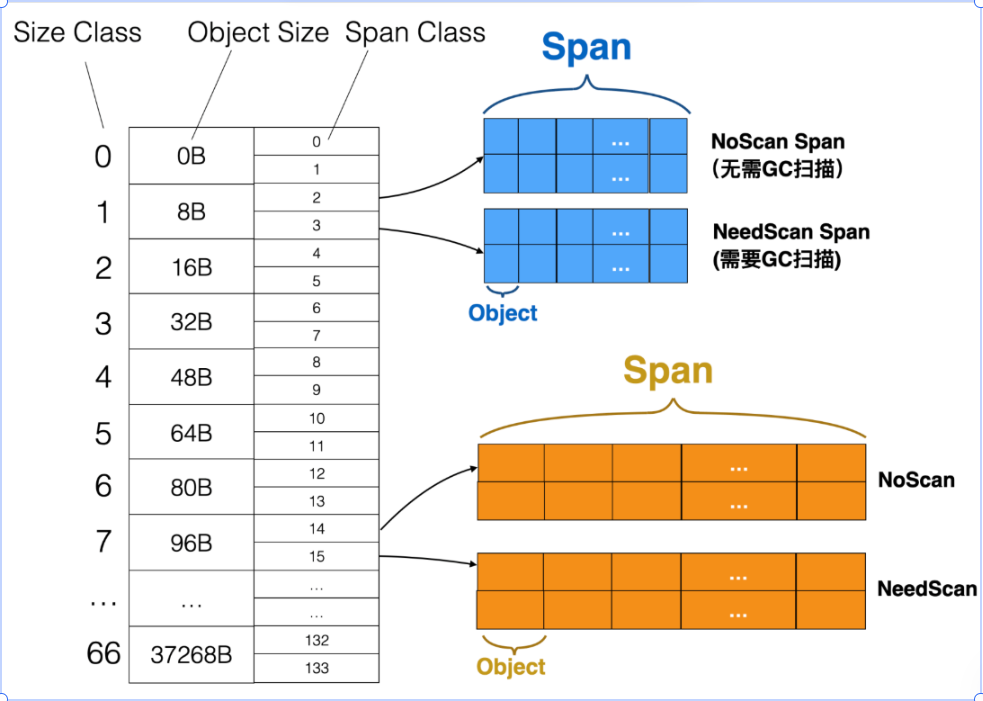
mcache 維護 66 個 size class(從 8B 到 32KB,每個 class 對應一種對象大小)。
每個 size class 在 mcache 中有兩個 span(分別用于不同 GC 標記顏色的分配,避免 GC 混淆)。
分配時:直接從當前 size class 對應 span 的空閑 slot 中取一個,不加鎖。
特點:
減少全局鎖競爭。
缺點是可能短期浪費一些內存(因為每個 P 都有自己的緩存)。
這里的size class 如下:
- mcentral:全局按 size class 管理的 span 池
位置:每個 size class 有一個 mcentral。
作用:管理所有屬于該 size class 的 span。
原理:
mcentral 有兩個鏈表:
非空鏈表:有空閑 slot 的 span
已滿鏈表:所有 slot 已分配出去的 span
當某個 P 的 mcache 發現本地 span 用完:
從 mcentral 的非空鏈表取一個 span。
如果非空鏈表也沒有可用 span,就向 mheap 申請一個新的 span。
- mheap:全局堆管理
位置:所有 P/M 共享的全局內存管理器。
作用:負責大對象分配(>= 32KB)和 span 的全局管理。
原理:
mheap 管理一組 free list + treap 樹結構(按 span 數量和地址組織),比單純鏈表查找更高效。
當 mcentral 要新的 span 時,mheap 會提供指定大小的 span。
如果 mheap 自己也沒有空閑內存:
通過 mmap 或 sbrk 向操作系統申請大塊虛擬內存(通常 64KB 或更大)。
這些內存被劃分成 heapArena 區塊(管理虛擬地址范圍、指針位圖等)。
- heapArena:虛擬地址映射與 GC 輔助
作用:heapArena 是 Go 堆的元數據管理單元。
內容:
地址映射表(從虛擬地址到 span 的映射)
指針位圖(標記 span 內哪些位置存的是指針,用于 GC 根掃描)
- 總結
以小對象分配為例(< 32KB):
- goroutine 在某個 P 上運行,調用 new 或 make 觸發分配。
- mcache 直接在本地 span 分配 slot(O(1),無鎖)。
- 如果當前 span 用完 → 向 mcentral 請求一個新 span(需加鎖)。
- mcentral 沒有可用 span → 向 mheap 申請一個新的 span。
- mheap 沒有可用內存 → 向 OS 申請一大塊內存(mmap)。
- OS 返回內存 → mheap 劃分成 span → mcentral 提供給 mcache → mcache 返回 slot。
第四部分:GC
用戶代碼 ──────────────────────────────────────────────?┌─ STW ──┐ ┌─ STW ─┐▼ ▼ ▼ ▼Mark Prepare → 并行 Mark → Mark Term → 并行 Sweep → Sweep Term
1)初識
Go 運行時的垃圾回收(GC)是:
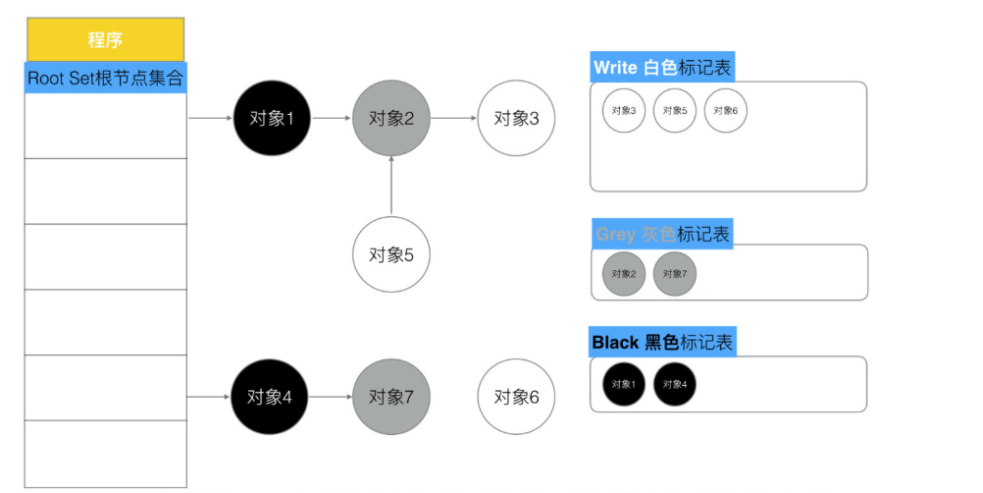
三色標記法(Tri-color marking):對象分為白、灰、黑三類:
白色:未標記,可回收。
灰色:已標記但其子對象還未處理。
黑色:已標記且子對象已全部處理。
并發標記:絕大多數標記和清掃工作與用戶代碼(mutator)并行進行,減少停頓。
寫屏障(write barrier):并行標記時,為了不漏標新產生或修改的引用,需要在賦值語句中記錄變化。
STW(Stop The World):只有少數關鍵階段需要全局暫停用戶代碼,其他階段后臺執行。
2)GC 的工作階段
- Mark Prepare(標記準備階段)
STW 階段(短暫停頓)
初始化本輪 GC 的各種數據結構。
開啟 寫屏障(write barrier),保證在并行標記過程中,新產生或被修改的引用不會漏掉。
啟用 Mutator Assist:讓用戶代碼在分配內存時,分攤一部分標記工作(避免 GC 線程跟不上分配速度)。
統計 root 對象(GC 從這些地方開始掃描),包括:
全局變量(全局指針)
所有正在運行的 goroutine 棧上的指針
為什么要 STW:
要一次性切換到 GC 模式(打開屏障、記錄 root 集)必須在一致的世界狀態下做。
- GC Drains(并行標記階段)
并行執行(GC goroutine 與用戶 goroutine 同時運行)
掃描 root 對象:
遍歷全局指針和所有 goroutine 棧,找到可達對象,把它們放到灰色隊列。
如果要掃描某個 goroutine 棧,必須短暫停該 goroutine。
處理灰色隊列:
循環取出灰色對象,掃描它引用的其他對象:
如果引用的對象是白色 → 變灰并加入灰色隊列。
當前對象處理完 → 變黑。
持續處理直到灰色隊列為空。
期間寫屏障會不斷把新創建或新引用的對象加到灰色隊列,防止漏標。
- Mark Termination(標記終止階段)
STW 階段(短暫停頓)
重新掃描(re-scan):
再次掃描全局指針和 goroutine 棧。
因為標記階段與用戶代碼是并行的,可能在標記期間分配了新對象或產生了新引用,這些變化通過寫屏障記錄下來,在這一步統一處理。
標記階段徹底完成,所有存活對象都已變黑,其他都是白色(可回收)。
為什么要 STW:
確保標記結束時沒有漏標的存活對象。
- Sweep(并行清掃階段)
并行執行
遍歷所有 span(Go 堆內存的基本分配單元,8KB):
把其中白色對象回收(釋放 slot 給下一次分配)。
保留黑色對象(活對象)。
這個過程是增量式的,不會一次性清理全部,而是分批清掃。
注意:
清掃是按需觸發的(懶清掃),即下一次分配時發現 span 未清掃才清掃,減少一次性延遲。
- Sweep Termination(清掃終止階段)
確保上一次 GC 的清掃任務完全結束。
只有當上一輪 Sweep 完全結束,才能開始新一輪 GC(保證數據一致性)。
這個階段不一定 STW,但會等待清掃 goroutine 完成。
- GC的觸發機制
【1】自動觸發機制1)基于內存增長比例(GOGC)當堆內存(heap)分配量比上一次 GC 結束時的堆大小增加了 GOGC% 時,觸發下一次 GC2)基于定時觸發(最大暫停間隔)如果距離上次 GC 時間太長,runtime 也會強制啟動 GC3)輔助 GC(Mutator Assist)如果分配速度過快,GC 跟不上,runtime 會在分配路徑上讓分配者幫忙做一部分 GC 標記工作
【2】手動觸發(顯示調用)runtime.GC()
第五部分:知識拓展
1)MMP
mmap(memory map)是 內存映射機制:
- 它可以把 文件 或 匿名內存 的一部分映射到進程的虛擬地址空間。
- 映射之后,文件的內容 就好像是進程的一段內存,你可以用普通的指針來讀寫它。
- 所有讀寫操作都是直接作用于內存,由操作系統負責把修改同步到文件(或從文件加載到內存)。
- 這就是為什么可以不用 read/write 系統調用:因為訪問內存本身就會觸發底層的頁面加載(缺頁中斷)。
#include <stdio.h>
#include <fcntl.h>
#include <sys/mman.h>
#include <unistd.h>
#include <string.h>
int main() {int fd = open("test.txt", O_RDWR);if (fd < 0) { perror("open"); return 1; }// 獲取文件大小off_t size = lseek(fd, 0, SEEK_END);// 映射整個文件到內存char *data = mmap(NULL, size, PROT_READ | PROT_WRITE, MAP_SHARED, fd, 0);if (data == MAP_FAILED) { perror("mmap"); return 1; }// 直接修改內存,相當于修改文件內容strcpy(data, "Hello mmap!\n");// 解除映射munmap(data, size);close(fd);
}
[原理解釋]
調用 mmap:
1)內核在進程虛擬地址空間中劃出一段連續的地址范圍。
2)把這段虛擬內存的頁表映射到文件對應的物理頁(通過磁盤緩存頁)。這些物理頁數據并不會馬上全部加載,而是按需加載(缺頁中斷)。
3)訪問映射區的內存時:如果該頁不在內存,觸發缺頁中斷,內核從文件中讀取該頁數據。如果修改數據,內核會標記該頁為臟頁,稍后回寫到文件(MAP_SHARED)
2)Channel解讀
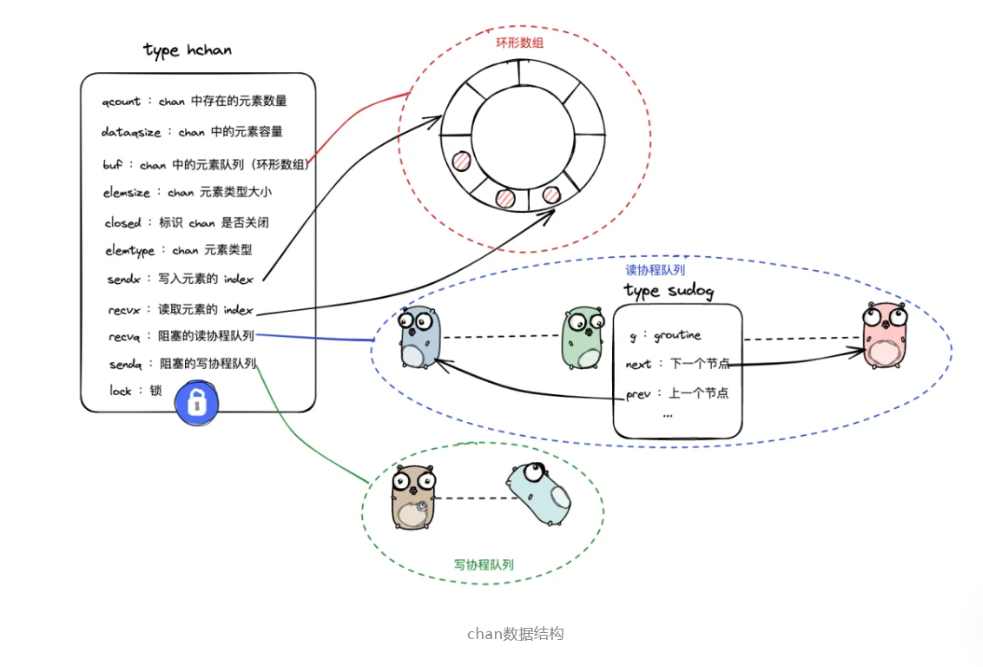
- 數據結構
type hchan struct {qcount uint // 隊列中當前元素個數dataqsiz uint // 循環隊列的容量(緩沖區大小)buf unsafe.Pointer // 緩沖區指針(環形隊列)elemsize uint16 // 每個元素的大小(字節數)closed uint32 // 是否已關閉(0/1)elemtype *_type // 元素類型信息(用于內存分配/GC)sendx uint // 下一個發送位置索引(環形隊列下標)recvx uint // 下一個接收位置索引(環形隊列下標)recvq waitq // 等待接收的 goroutine 隊列sendq waitq // 等待發送的 goroutine 隊列lock mutex // 互斥鎖,保護上述字段
}
2. 寫流程
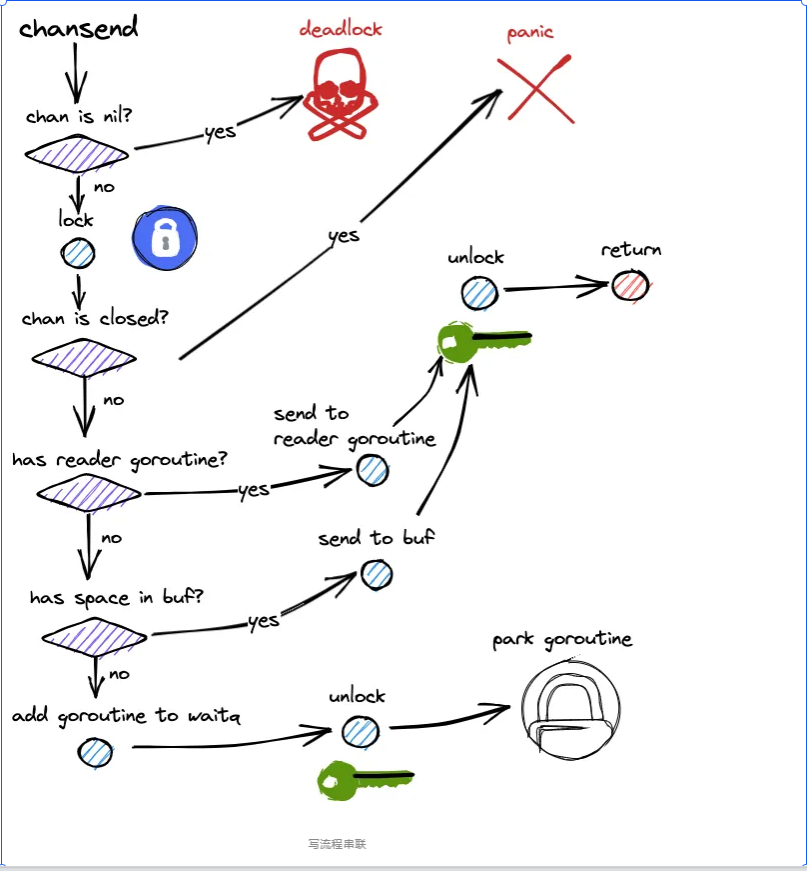
1)nil 通道檢查
若 ch == nil:當前 goroutine 永久阻塞(park),只有當整個程序再無可運行 G 時,
runtime 才判定 死鎖 并崩潰。否則,繼續。
2)加鎖
獲取 hchan.lock,保護后續對隊列與等待隊列的訪問。
3)關閉檢查
若 ch.closed != 0:解鎖后立刻 panic("send on closed channel")。
4)是否有等待接收者(recvq 非空)
有:走 直接配對傳遞(handoff) 路徑:
從 recvq 取出一個阻塞接收者 sudog;
將待發送元素 直接拷貝 到接收者的目標地址;
將該接收者 喚醒(goready 進入可運行隊列);解鎖并返回。
5)緩沖區是否有空間(qcount < dataqsiz)
有:走 入環形緩沖 路徑:
將元素拷貝到 buf[sendx];sendx = (sendx + 1) % dataqsiz;qcount++;解鎖并返回。
否則:緩沖已滿且無等待讀者 → 阻塞發送者
構造當前 goroutine 的 sudog,記錄:
關聯的通道指針、待發送元素地址、元素大小/類型信息等;
將 sudog 掛入 sendq;
調用 goparkunlock;釋放鎖并 park 當前 goroutine;
6)被喚醒后(可能因為接收者到來完成配對,或通道被關閉):重新加鎖并重新檢查狀態:
若通道已關閉:按規則 panic;否則配對已完成,解鎖并返回。
- 讀流程
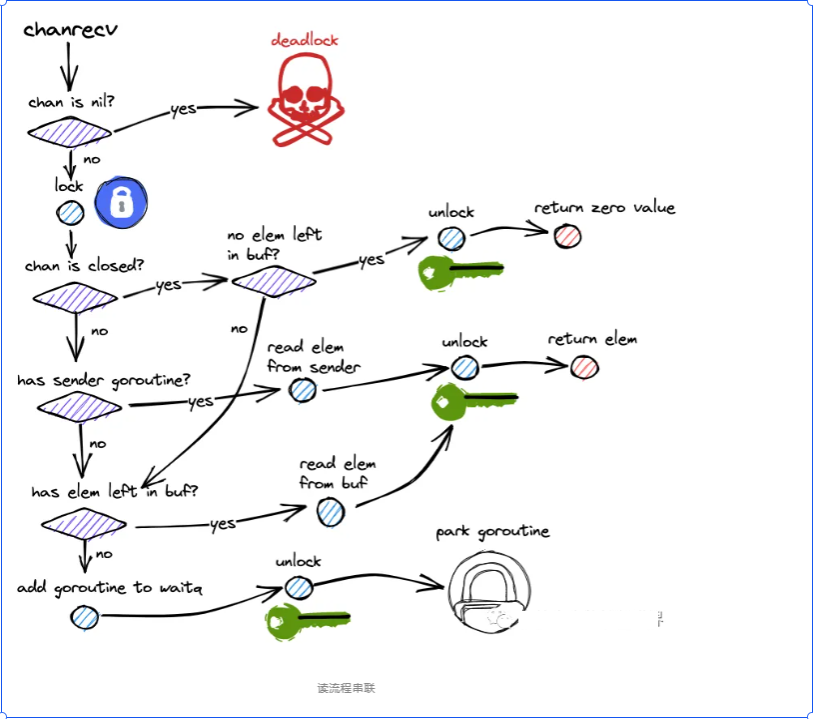
1)nil 通道檢查
若 ch == nil:當前 goroutine 永久阻塞(park)。
僅當進程內所有 goroutine 都不可運行時,runtime 判定 死鎖 并崩潰。否則繼續。
2)加鎖 lock(&c.lock)。
3)緩沖區是否有數據(qcount > 0)?
有:從環形緩沖取出一個元素:
從 buf[recvx] 復制到接收方目標;
recvx = (recvx+1) % dataqsiz,qcount--;
若此時存在等待發送者(sendq 非空):
可立即將一個發送者的數據寫入剛空出的緩沖格(出一個、補一個的優化),并喚醒該發送者;解鎖并返回(ok=true)。
否則緩沖區為空:是否存在等待發送者(sendq 非空)?
有:走直接配對(handoff)路徑:
從 sendq 取一個阻塞發送者 sudog;
將其待發送元素直接拷貝到接收方目標(無緩沖通道必經此路;有緩沖通道在空時也優先直配以降低延遲);
喚醒該發送者(goready);解鎖并返回(ok=true)。
否則:無數據且無等待發送者
4)通道已關閉(closed != 0)?
是:接收元素類型的零值并返回(ok=false)。
否:當前接收者阻塞:
構造當前 goroutine 的 sudog,掛入 recvq;
goparkunlock釋放鎖并 park;
被喚醒后(由發送者直配或 close 觸發)重新加鎖。
- 關閉
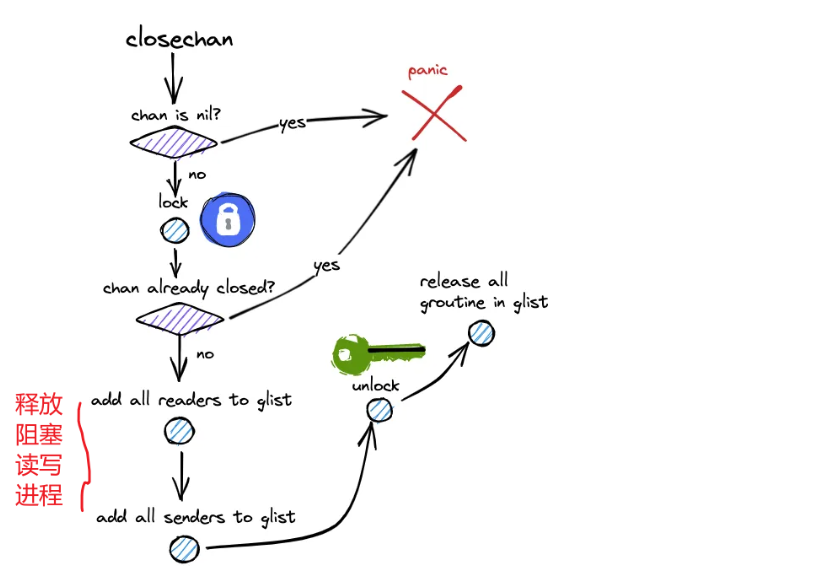
0)入口與判錯
通道是否為 nil?
是:panic("close of nil channel")(不能關閉 nil 通道)。
否:繼續。
加鎖 lock(&c.lock),保護 hchan 的內部狀態。
是否已關閉?
c.closed != 0:解鎖后 panic("close of closed channel")(重復關閉會 panic)。
否:c.closed = 1,標記已關閉,繼續。1)處理等待的接收者(recvq)——“先滿足讀者”
關閉時,優先處理接收方隊列;因為緩沖里可能還有未讀數據:
循環從 recvq 取出阻塞的接收者 r:
如果緩沖里還有數據(qcount > 0):
從環形緩沖 buf[recvx] 取出一條寫給該接收者,更新 recvx/qcount;
該接收者被喚醒后會拿到正常元素,ok=true。
如果緩沖已空:
直接給該接收者元素零值,并標記 ok=false;
這就是關閉后“讀到零值并且 ok=false”的來源。
無論哪種,先把要喚醒的 G 加到一個臨時 glist,暫不立即喚醒(避免持鎖喚醒)。2)處理等待的發送者(sendq)——“全部喚醒并讓其失敗”
關閉后不允許再發送;對已經阻塞在 sendq 的發送者,需要統一處理:
循環從 sendq 取出阻塞的發送者 s:
把它加入 glist,稍后統一喚醒。
它被喚醒后會回到發送路徑繼續執行,看到通道已關閉從而觸發 panic("send on closed channel")。
也就是說:close 會把所有正在阻塞的發送者全部喚醒并最終讓它們 panic。3)解鎖并統一喚醒
解鎖 unlock(&c.lock)。
統一喚醒 glist 里的所有 goroutine(接收者與發送者都在里面):
接收者要么得到緩沖里的元素(ok=true),要么得到零值(ok=false);
發送者恢復后立即走到“通道已關閉”的分支并 panic。
第六部分:參考資料
- https://learnku.com/articles/68142
- https://mp.weixin.qq.com/s/QgNndPgN1kqxWh-ijSofkw
- https://mp.weixin.qq.com/s/0EZCmABsMEV3TFVmDZmzZA




Crypto節點、js timestamp代碼、Crypto node)






: 論文解讀)







